附录I:LLM 可解释性 — Physics of Language Models 系列
定位:本附录系统介绍 Zeyuan Allen-Zhu(Meta AI)与 Yuanzhi Li(MBZUAI)主导的 "Physics of Language Models" 系列研究。该系列借用物理学中实证与理论结合的方法论,通过精心设计的合成任务,在高度可控的实验环境中探究 Transformer 内部"学到了什么"以及"怎么学的"。作者将这一研究范式称为"格物致知"——不满足于观察 LLM 能做什么(现象学),更要理解它们为什么以及如何做到(机理)。本附录按论文发表的 Part 编号依次展开,每个 Part 聚焦一个核心问题。
I.1 系列概览:从"现象"到"机理"
当前 LLM 研究的一个核心困境是:我们能观察到模型展现出令人惊叹的能力(写代码、解数学题、多轮对话),却很难回答"它到底学到了什么内部机制"。传统的可解释性研究往往聚焦于单个注意力头的可视化或特定神经元的激活分析,而 Physics of Language Models 系列采取了一条不同的路径——构建完全可控的合成任务,让研究者能精确地知道"正确答案是什么",从而定量度量模型内部表征与真实结构之间的对应关系。
这一方法论的核心优势在于:
- 消除数据污染:合成数据保证模型不可能"提前见过答案"
- 控制变量:可以精确调节任务难度、数据多样性、训练规模等因素
- 量化度量:由于真实结构已知,探针(Probe)的准确率有明确的物理含义
该系列目前涵盖以下研究主题:
| Part | 核心问题 | 关键概念 |
|---|---|---|
| Part 1 | LLM 如何掌握复杂语法? | CFG 任务、多头线性探测、DP-like 机制 |
| Part 2.1 | LLM 的数学推理是真推理还是模板记忆? | iGSM 数据集、V-Probing、变量追踪 |
| Part 2.2 | 能否教会 LLM "知错能改"? | Retry 数据、[BACK] token、即时纠错 |
| Part 3.1 | 数据多样性如何影响知识提取? | 数据增强、知识编码、OOD 泛化 |
| Part 3.2 | 存储知识等于会用知识吗? | 知识操纵、逆向搜索、CoT 必要性 |
| Part 3.3 | 模型能存多少知识? | ~2 bits/param、容量比率、MoE 效率 |
| Part 4.1 | 如何突破线性模型的推理深度瓶颈? | Canon 层、局部协作、因果卷积 |
接下来,我们逐一深入每个 Part 的研究设计与核心发现。
I.2 Part 1:复杂文法学习 — LLM 能学会动态规划吗?
研究问题
当任务变得非常困难,需要深层逻辑推理和复杂计算链条时,LLM 是如何应对的?具体而言:一个标准的 GPT-2 模型,能否学会解析需要动态规划(Dynamic Programming, DP)算法才能处理的复杂上下文无关文法(Context-Free Grammar, CFG)?
实验设计:cfg3 文法家族
作者设计了一类名为 cfg3 的人工 CFG 家族,其特点使得解析任务极具挑战性:
- 深度大、规则少:例如
cfg3f拥有 7 个层级,但每个层级的非终结符数量很少。规则少意味着每个非终结符的"选择"更加关键,也更容易产生歧义 - 生成长序列:能产生长达数百个 token 的句子
- 局部高度模糊:无法仅凭局部信息确定当前 token 的正确语法角色,必须依赖全局上下文
- 解析需要 DP:即便把完整的 CFG 规则交给人类,要判断一个长句子是否合法,也几乎必须借助纸笔执行动态规划
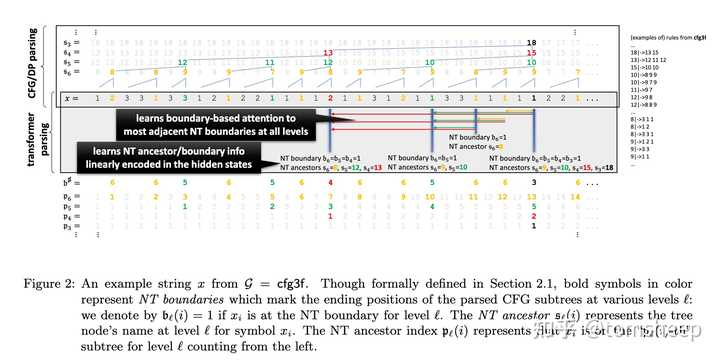
图 I-1:cfg3 文法家族的结构示例。多层级规则和局部模糊性使得解析任务需要类似动态规划的全局推理能力。
为什么选择 CFG 而非自然语言?因为自然语言的"正确解析"本身就有争议,而 CFG 的语法结构是完全确定的——研究者可以精确地知道模型应该学到什么,从而用探针定量验证。这也体现了该系列一以贯之的方法论:用合成数据消除歧义,让实验结论有坚实的基准可对照。
举一个简化的例子来帮助理解 cfg3 的难度。假设有如下 CFG 规则:
S → A B
A → a A b | a b
B → c B d | c d给定一个长序列 a a b b c c d d,判断它是否属于该文法需要尝试多种划分方式——A 的边界在哪里?B 从哪里开始?当规则层级更深、非终结符更多时,这种组合爆炸只能通过 DP 类算法高效解决。cfg3 家族正是将这种复杂度推到了极致。
探针技术
该研究使用了两种主要的内部分析工具:
- 多头线性探测(Multi-head Linear Probing):在模型的隐藏状态上训练简单的线性分类器,检测这些隐藏状态是否线性地编码了特定的语法信息。如果一个线性分类器就能准确读出这些信息,说明模型确实在内部表征了它们
- 注意力模式分析(Attention Pattern Analysis):分析注意力权重的分布,观察模型在计算某个 token 的表示时重点关注了哪些位置的 token
核心发现
作者的实验揭示了以下关键现象(注意:以下均为该研究的实验发现,基于合成任务和特定模型规模):
发现一:GPT 学到了类似 DP 的机制。 通过探针分析,作者发现带有位置编码的 GPT-2 模型在处理 cfg3 任务时,其内部隐藏状态的演化模式与经典 DP 算法的中间状态高度相似。模型并非简单地记忆训练样本的表面模式,而是学到了一种结构化的、逐步积累信息的计算策略。
发现二:位置编码至关重要。 实验对比了使用相对/旋转位置编码(如 RoPE,回顾 §3.3)与不使用位置编码的模型。结果表明,位置编码对于模型学习复杂层级结构至关重要——没有位置编码的模型在 cfg3 任务上表现显著下降。这一发现为 RoPE 等位置编码成为现代 LLM 标配提供了一个机理层面的解释。
发现三:训练数据中的少量结构性错误反而有益。 当训练数据中混入少量不符合语法的"错误样本"时,模型的鲁棒性反而有所提升。这一发现挑战了"训练数据必须完美无瑕"的直觉,暗示适度的噪声可能帮助模型学到更泛化的结构表征。
发现四:LLM 可能不只是"随机鹦鹉"。 该实验间接表明,至少在 cfg3 这类合成任务上,LLM 展现出了比简单模式匹配更深层次的计算能力——它们学到的更像是解决问题的"策略",而非重复训练数据中的表面模式。
I.3 Part 2.1:数学推理 — 真正的泛化还是模板记忆?
研究问题
语言模型在数学推理任务上的出色表现,究竟是真的学会了推理,还是仅仅记住了解题模板?这个问题的重要性在于:如果模型只是在做模板匹配,那么面对分布外的新题型时就会失效;如果模型真的学会了推理,那就意味着语言建模目标本身可以产生某种形式的抽象思维。
实验设计:iGSM 数据集
为什么不直接用 GSM8K 等现有数学推理基准?作者指出了两个关键问题:
- 数据污染(Data Contamination):现有大模型的预训练语料可能已经包含了这些基准的测试题目。模型"恰好见过"答案,高分不代表真正理解
- 解题套路有限(Solution Diversity):GSM8K 虽有 7500 道训练题,但解题"套路"的多样性有限,模型可能只需记住几十种模板就能应付大多数题目
为此,作者构建了 iGSM(improved Grade School Math) 数据集——一个大规模、多样化、难度可控的合成数学问题生成框架。该框架能自动生成无限量的新鲜题目,每道题的依赖结构、变量数量和计算步骤数都可以精确控制。
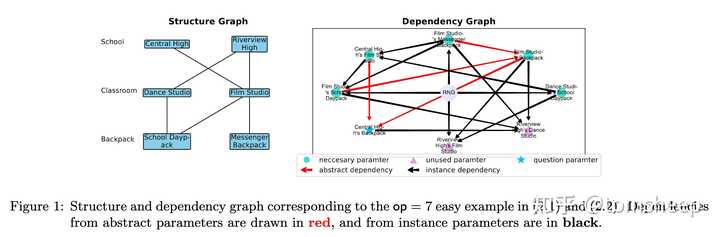
图 I-2:iGSM 数据合成架构示意。通过参数化控制题目的依赖结构与计算复杂度,可以生成无限量的新鲜数学问题。
实验在 iGSM 上从头训练 GPT-2 类模型(位置编码替换为 RoPE),而非使用预训练模型,从而完全排除数据污染的可能。
一个 iGSM 生成的题目可能如下所示:
学校有 3 个年级。每个年级有 4 个班。每个班有 5 名学生。
每名学生带了 2 支铅笔。问:学校共有多少支铅笔?该题的依赖链为:总铅笔数 → 学生总数 → 班级总数 → 年级数,需要逐层回溯计算。通过调节层级深度和分支数量,iGSM 可以精确控制题目的推理步数,从而系统性地测试模型在不同推理深度下的表现。
探针技术:V-Probing
标准的线性探测(Linear Probing)是在模型某层的输出上加线性分类器来预测某种属性。但数学推理涉及多个变量之间的依赖关系,需要更精细的探测手段。为此,作者提出了 V-Probing(Variable Probing):
- 冻结主模型,微调探针:GPT-2 的参数完全冻结,只在输入嵌入层加入一个极小的低秩更新(rank-8),并在最后一层特定 token 的隐藏状态上附加线性分类器
- "指名道姓"地追踪变量:通过特殊标记(如
[START] 参数A的描述 [END])精确询问模型对特定变量的内部表征,例如"模型在读完整个问题后,是否知道参数 A 对最终答案是必需的?"
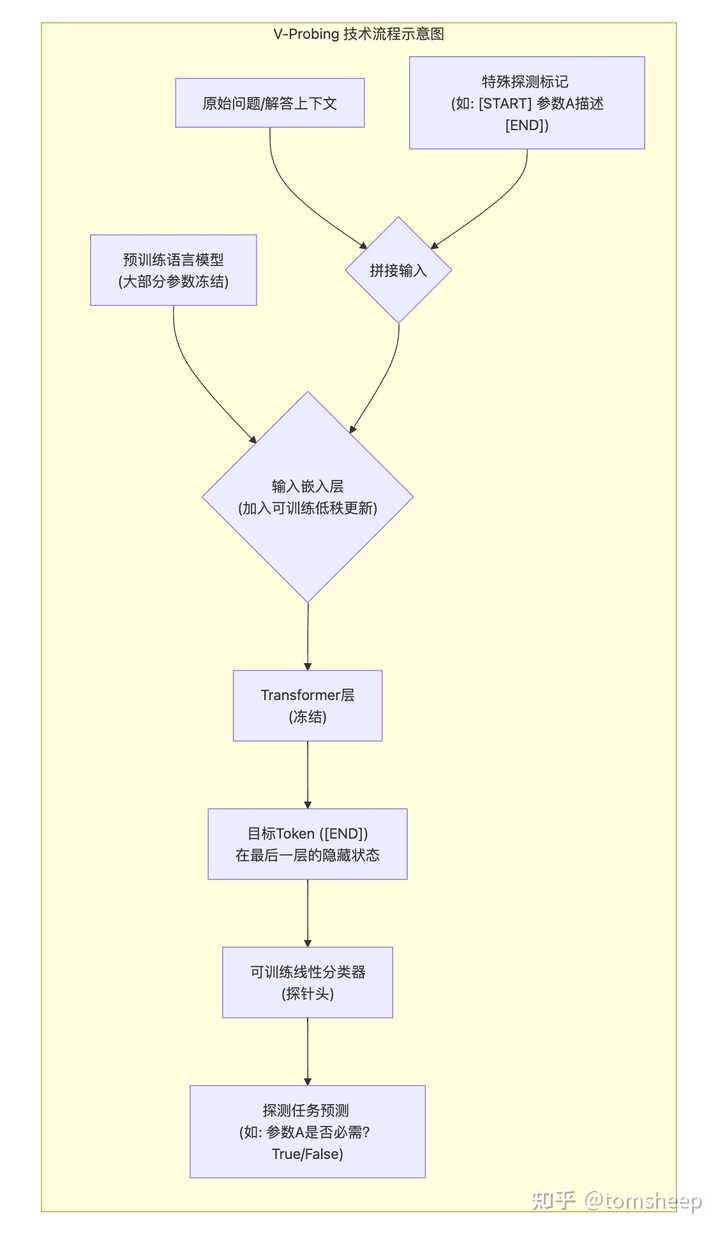
图 I-3:V-Probing 的工作原理。通过在冻结模型上附加轻量级探针,可以精确追踪模型对每个变量的内部表征状态。
核心发现
发现一:超越模板记忆。 在 iGSM 的严格控制下,作者的实验结果表明 GPT-2 规模的模型能够在训练分布之外的新题目上正确推理——即面对从未见过的变量组合和依赖结构时,依然能给出正确解答。作者据此认为,模型学到的是可泛化的推理技能,而非简单的模板记忆。
发现二:"心智规划"的存在。 V-Probing 的实验结果显示,模型在开始逐步输出解答之前,其内部隐藏状态就已经编码了关于解题路径的规划信息。换言之,模型似乎在"开口"之前就已经有了一个模糊的解题计划——这种现象被作者称为"心智规划"(Mental Planning)。
发现三:自主习得 Level-2 推理技能。 作者发现模型不仅学会了完成训练任务本身,还自主地习得了更通用的结构化知识。具体表现为:模型能够追踪变量之间的多跳依赖关系——"我想算 X,X 依赖 Y,Y 依赖 Z,所以我得先算 Z"。这种能力并非训练数据中显式教授的,而是模型在语言建模过程中自发涌现的。
发现四:错误可从内部状态预测。 有些推理错误在模型"开口"之前,就已经能通过探针从其内部状态中预测到。这意味着模型的错误并非随机的,而是与其内部表征的某些缺陷系统性相关。
发现五:"深度"对应"推理距离"。 模型的浅层更擅长识别那些距离最终答案比较"近"的必需参数(只需一步推理),而深层能更准确地识别距离最终答案更"远"的必需参数(需要多步推理)。这一发现与 Transformer 的逐层信息聚合机制一致——每多一层,信息传播的"跳数"就多一步。
I.4 Part 2.2:错误纠正 — 用 Retry 数据教会模型"知错能改"
研究问题
Part 2.1 证明了模型能学会推理,但推理过程中不可避免地会出错。能否让模型在生成过程中实时发现错误并立即修正,而非依赖外部验证器或"事后检查"?
现有方案的局限
在该研究发表时,主流的纠错方案大多是"事后诸葛亮":
- 外部验证器(Verifier):训练另一个模型来判断主模型的输出是否正确,需要额外的模型和推理开销
- 自我验证/修正(Self-Verification):通过提示词(如"请检查你上面的解答")引导模型自行检查,但效果不稳定且依赖于提示设计
这些方案的共同问题是:纠错发生在完整输出之后,而非推理的即时过程中。
实验设计:重试数据(Retry Data)
作者提出了一个直观的假说:LLM 之所以缺乏"即时纠错"能力,很可能是因为预训练语料中几乎不存在"写错了立即修正"的样本——人们在发表文章或代码时,通常会删掉错误痕迹,只留下最终正确版本。
基于这一假说,作者设计了重试数据(Retry Data)——一种包含"错误步骤 + 回退标记 + 正确步骤"的特殊训练数据格式:
正常解题:A → C(直接得出正确结论)
重试数据:A → B(错误结论)[BACK] A → C(正确结论)其中 [BACK] 是一个特殊 token,告诉模型"刚才那步不对,从这里重来"。这些重试数据基于 Part 2.1 的 iGSM 数据集自动生成,通过有意引入错误步骤并标注修正路径。
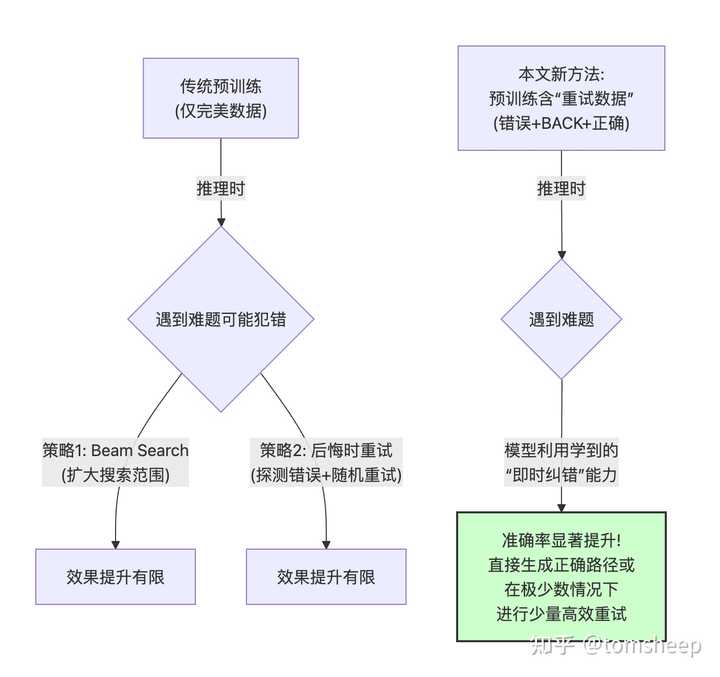
图 I-4:重试数据的预训练流程。模型在预训练阶段就接触包含"错误 → 回退 → 修正"模式的数据,从而习得即时纠错能力。
核心发现
发现一:重试数据显著提升推理准确率。 在预训练阶段引入重试数据的模型,在推理任务上的准确率甚至超过了使用等量完美无误数据训练的模型。这意味着"从错误中学习"不仅不会拖累模型,反而带来了额外的收益。
发现二:即时纠错是一种需要专门训练的深层技能。 实验表明,这种能力具有以下特征:
- 与模型原始的无错推理能力存在本质差异,不会因为模型"推理能力强"就自动具备纠错能力
- 难以通过参数高效微调(如 LoRA)在已预训练好的模型上"嫁接",暗示学习纠错需要对模型权重进行更根本性的调整
- 不同于通过 Beam Search 或随机采样实现的"尝试多次取最优"策略——重试数据训练出的是真正的"在线纠错"能力
发现三:重试数据的预训练是安全的。 一个自然的担忧是:让模型接触大量错误步骤,会不会导致它"学坏"?作者的实验表明这种担忧是多余的:
- 模型在推理时依然倾向于直接生成正确答案,不会主动制造错误
- 通常无需对错误 token 进行标签掩码(label masking)
- 模型生成的解法依然保持简洁
发现四:纠错能力应在预训练阶段培养。 强调了在预训练阶段就应该引入包含纠错模式的数据,而非寄希望于微调阶段或复杂的推理时策略来弥补。这一发现对当前 LLM 的训练数据构建范式具有重要的实践指导意义。
与当前推理模型的联系
有趣的是,Part 2.2 的核心思想与后来 OpenAI o1、DeepSeek-R1 等推理模型中观察到的"自我反思"行为存在有趣的对应关系。这些模型在 CoT 输出中经常出现"Wait, let me reconsider..."或"Actually, that's wrong..."这样的自我纠正模式。Part 2.2 的研究提供了一个理论视角来理解这种现象:如果训练数据中包含足够的纠错样本(无论是人工构造的还是自然产生的),模型确实能学会这种"在线反思"的技能。当然,Part 2.2 使用的是精心设计的合成数据和 [BACK] 标记,与真实推理模型中自发涌现的纠错行为之间的机理联系,仍有待进一步研究。
I.5 Part 3.1–3.3:知识的存储、操纵与容量
Part 3 的三篇论文从不同角度深入研究了 LLM 与"知识"的关系。Part 3.1 关注知识提取中数据多样性的关键作用,Part 3.2 揭示了"储存知识"与"灵活运用知识"之间的鸿沟,Part 3.3 则给出了一个惊人的量化结论:模型的知识存储容量约为 2 bits/param。
I.5.1 Part 3.1:数据多样性是知识提取的关键
研究问题: 模型在预训练阶段"见过"一条知识,是否就意味着它能在下游任务中提取并使用这条知识?
实验设计: 作者构建了两种受控的合成传记数据集:
- bioS(Synthetic Biography):包含 10 万个虚构人物的简介,每人有 6 个固定属性(生日、出生城市、大学、专业、雇主、工作城市),属性值从预设列表中随机抽取
- bioR(Realistic Biography):用 LLaMA 模型根据 bioS 的属性信息生成风格更自然的传记文本
实验范式分为三步:
- 预训练:让模型阅读传记数据
- 指令微调:用一部分人物的问答对教模型如何回答问题
- 分布外测试(OOD Test):用微调阶段从未见过其问答对的人物进行测试
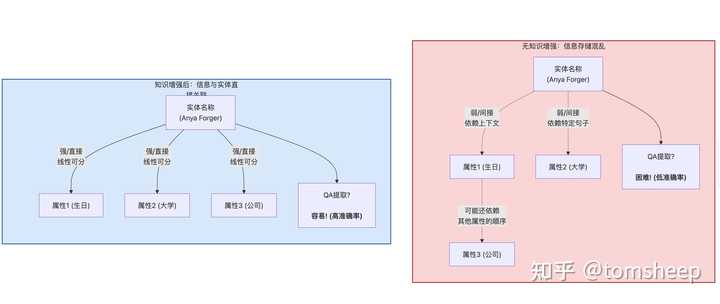
图 I-5:数据增强实验结果。当每个人物的传记只有单一版本时(bioS single),模型的知识提取能力大幅下降;增加表述多样性后,OOD 测试准确率显著提升。
核心发现:
数据增强(重写)至关重要。 当每个人物只有一篇固定格式的传记时,模型虽然能"背诵"原文,却难以在问答场景中灵活提取知识。然而,当同一知识以多种不同的语言表述出现在预训练语料中时(例如打乱句子顺序、改写措辞、甚至通过翻译引入表达多样性),模型的知识提取能力显著提升。
这一发现的实践启示是:
- 对于关键知识(尤其是稀有但重要的信息),应在预训练阶段就进行数据增强——可以使用辅助模型(甚至较小的模型)来改写、释义,生成多样化版本
- 等到微调阶段再解决知识提取问题,往往为时已晚。如果知识在预训练时没有被"正确"编码,后续微调很难弥补
- 在预训练阶段更早地引入类似问答的指令性数据,有助于引导模型采用更利于后续提取的知识存储方式
I.5.2 Part 3.2:储存知识不等于会用知识
研究问题: 即使模型完美地存储了知识,它能否灵活地操纵这些知识来回答非直接检索类的问题?
实验设计: 基于 Part 3.1 的合成数据集,作者设计了四种递进难度的知识操纵任务:
| 任务 | 描述 | 示例 |
|---|---|---|
| 知识检索 | 直接提取某实体的属性 | "Anya 的生日是什么?" |
| 知识分类 | 对检索到的知识进行判断 | "Anya 的出生年份是奇数还是偶数?" |
| 知识比较 | 比较两个实体的同一属性 | "Anya 和 Bob 谁出生更早?" |
| 知识逆向搜索 | 根据属性值反向查找实体 | "哪个 1996 年出生、在 MIT 学通信的人住在普林斯顿?" |
实验的关键变量是 思维链(Chain of Thought, CoT)——对比模型在有无 CoT 辅助下的表现。
图 I-6:四种知识操纵任务的实验设计。从简单的检索到困难的逆向搜索,任务难度逐级递增。
核心发现:
- CoT 对非检索任务是必需的:模型在直接检索知识方面表现出色,但在没有 CoT 引导的情况下,即使是最简单的知识分类和比较任务也难以完成。CoT 的作用不仅仅是"让模型说出中间步骤",更是为模型提供了在自回归生成过程中执行多步计算的"草稿纸"
- 逆向搜索几乎不可能:无论采用何种提示策略(包括 CoT),模型在知识逆向搜索任务上的表现几乎为零。这揭示了自回归 Transformer 的一个结构性限制——它擅长"给定键查值"(前向检索),但极不擅长"给定值查键"(逆向搜索)
- 储存完美 ≠ 运用自如:这些发现表明,语言模型在灵活运用预训练知识方面存在固有的深层局限性,即使知识被完美存储、模型规模充足且训练充分
对实际应用的启示是:
- 对于需要逆向搜索或复杂知识操纵的场景,RAG(Retrieval-Augmented Generation,回顾 §22 章)等外部检索辅助方案可能是比单纯依赖模型内部知识更可靠的选择
- 作者还指出,可以通过预处理训练数据来部分缓解这些局限:例如为文档内容引入行号、唯一 ID 等辅助索引信息,帮助模型进行定位
- 从更宏观的视角看,这些发现暗示当前的自回归 Transformer 架构在知识操纵(尤其是逆向搜索)上存在固有瓶颈,未来可能需要探索能更好支持双向推理或符号操纵的新型架构
I.5.3 Part 3.3:每个参数存储约 2 bits 知识
研究问题: 一个给定规模的语言模型,到底能存储多少知识?有没有一个可度量的上界?
量化框架: 作者提出了一套严谨的度量体系:
知识的定义:将知识具体化为事实元组(Factual Tuples)的形式,如
(美国, 首都, 华盛顿特区)或(爱因斯坦, 出生年份, 1879)。这种定义虽然简化了知识的复杂性,但非常适合量化研究比特复杂度(Bit Complexity):用信息论方法度量存储
条知识元组至少需要多少比特。该度量巧妙地将模型的预测损失(交叉熵)纳入计算——模型预测越准确,其存储的有效知识比特数就越多 容量比率(Capacity Ratio):
这个比率衡量了每个参数平均能"承载"多少比特的知识,是评估参数利用效率的核心指标。
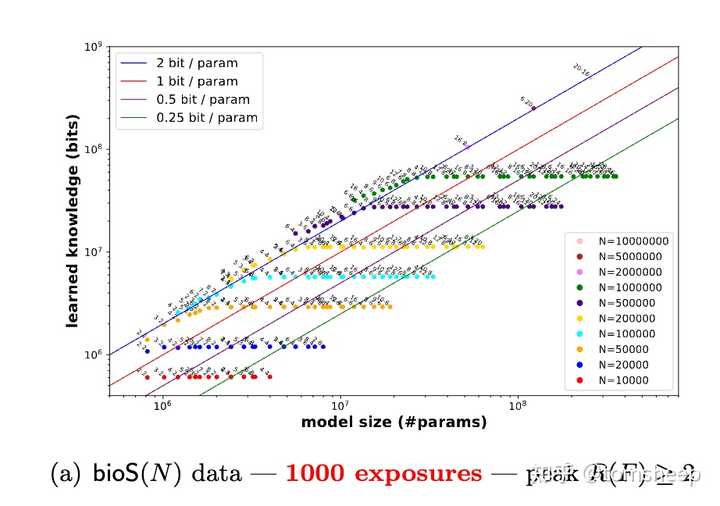
图 I-7:知识容量比率实验。不同规模的 GPT-2 模型在充分训练后,容量比率稳定在约 2 bits/param。图中展示了参数量与知识存储量之间的近似线性关系。
核心发现:
约 2 bits/param 的容量常数。 对于 GPT-2 架构(使用 RoPE 位置编码、去除 dropout),在合成知识数据集上经过充分训练后,峰值知识容量比率稳定在约 2 bits/param。这意味着:
- 模型的知识存储能力与参数数量之间存在近似线性的关系
- 一个 7B 参数的模型理论上可存储约
gigabits 的结构化知识——作者估算这可能超过了英文维基百科和所有英文教科书知识量的总和 - 存储的知识并非"死记硬背"——模型能以灵活的问答形式提取这些知识
影响容量的关键因素:
| 因素 | 影响 |
|---|---|
| 训练充分度 | 训练不足(100 次曝光)时,容量从 2 bits/param 降至 ~1 bit/param |
| 模型架构 | 充分训练时架构差异不大;Attention 层也能存知识(非仅 MLP) |
| GatedMLP | SwiGLU 等门控 MLP 在训练不足时效率稍低(可能更难优化) |
| 量化 | Int8 几乎无损;Int4 损失较大 |
| MoE | 出奇地高效——几乎能利用所有参数(含未激活的)存储知识 |
| 数据质量 | 随机垃圾数据破坏力巨大,但低信息量的重复内容影响不大 |
| 域名标记 | 保留数据来源标记可帮助模型自主优先学习高质量数据 |
需要特别注意的是,"2 bits/param"这一结论来自特定的实验设置(GPT-2 架构、合成元组知识、充分训练)。真实世界的知识远比元组复杂,这一数值在实际场景中可能有所不同。
I.6 Part 4.1:Canon 层 — 突破线性模型的推理深度瓶颈
研究问题
标准 Transformer 的自注意力机制负责全局信息交互,MLP 层则对每个 token 独立地进行非线性变换。但 MLP 在处理每个 token 时是"各自为战"的——如果当前 token 需要与紧邻 token 进行信息协作,这个负担就完全落在注意力机制上。对于需要紧密局部协作的任务,这种设计效率不高。能否通过一种轻量级的架构改进来缓解这一瓶颈?
合成游乐场:五项原子能力测试
作者借鉴物理学的思想,将智能分解为可独立评估的"原子能力",并为每种能力构建了高度可控的合成任务(消除真实数据中的干扰因素):
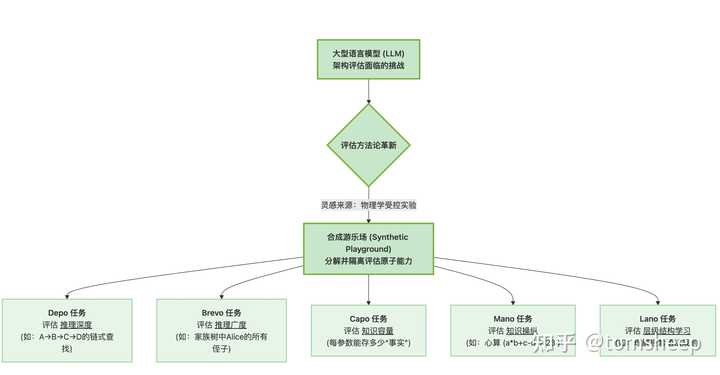
图 I-8:合成游乐场的五项测试任务,分别对应 LLM 的不同核心能力维度。这些任务用于在消除混杂因素的条件下,公平比较不同架构的能力边界。
Canon 层的设计
Canon 层的名称借自音乐中的"卡农"(Canon)——同一段旋律在不同声部先后出现、形成重叠呼应。在技术上,Canon 层的核心思想非常简洁:让每个 token 的隐藏状态能够直接"吸收"其前面几个相邻 token 的隐藏状态,通过一个轻量级的一维因果卷积(1D Causal Convolution)实现:
其中
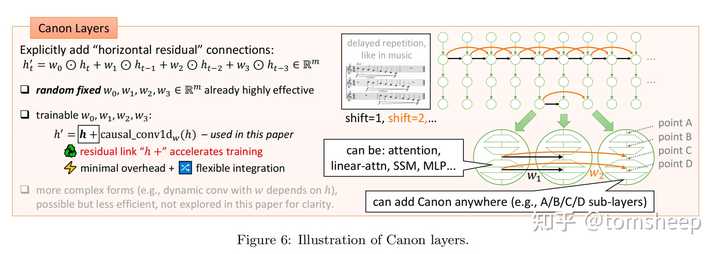
图 I-9:Canon 层的架构示意。通过在 Transformer 块的不同位置插入轻量级的一维因果卷积,实现 token 间的局部信息协作。
Canon 层可以灵活地插入到 Transformer 块的多个位置:
| 变体 | 插入位置 |
|---|---|
| Canon-A | 注意力模块之前 |
| Canon-B | 注意力模块内部(Q/K/V 投影之后) |
| Canon-C | MLP 模块之前 |
| Canon-D | MLP 模块内部 |
将四种变体全部启用(称为 full-score Canon,即 Canon-ABCD),模型的总参数量增加不到 0.5%。这种极低的参数开销使得 Canon 层可以作为一种"即插即用"的增强模块,几乎不影响模型的推理速度和显存占用。
从直觉上理解,Canon 层的作用可以类比为:在一个大型会议中,注意力机制让每个人都能听到会议室里所有人的发言(全局交互),但 Canon 层额外允许相邻座位的人互相交头接耳(局部协作)。这种"交头接耳"在需要紧密局部配合的任务中(如多步推理的中间状态传递)尤为关键。
核心发现
发现一:Canon 层带来显著提升。 在所有测试的架构上,加入 Canon 层后性能均有显著提升。尤其是,即使对于没有位置编码(NoPE)的模型,Canon 层也带来了大幅改善。作者据此提出了一个大胆的猜想:也许可以尝试简化甚至去掉 RoPE,改用 Canon 层来提供位置信息。
发现二:GLA + Canon 达到 Mamba2 水平。 GLA(Gated Linear Attention,一种线性注意力架构)加上 Canon 层后的性能达到了 Mamba2(一种流行的状态空间模型)的水平,在某些任务上甚至超过 Mamba2。更有趣的是,Mamba2 内部的 conv1d 组件本质上就是一种不带残差、带非线性激活、作用于部分坐标的 Canon-B 层——这揭示了 Mamba2 成功背后的一个关键机制。
发现三:公平比较后,Transformer 在推理深度上仍遥遥领先。 当所有主流架构(RoPE Transformer、NoPE Transformer、Mamba2、GLA)都公平地装上完整 Canon 层后:
- 在推理深度上,Transformer 类架构依然远超线性模型
- 在其他能力维度上各有胜负
- 线性模型在深度推理上的瓶颈非常明显
发现四:线性模型的瓶颈在于错误的逐跳累积。 线性模型(如 Mamba2、GLA)在深度推理上的不足,并非因为"记不住"上下文(其记忆容量是足够的),而是因为在信息压缩和检索过程中,错误会逐跳转移和累积。每多一步推理,累积误差就增大一分,最终导致多步推理的可靠性崩塌。这一发现从机理层面解释了为什么 Transformer 的全局注意力机制对深度推理至关重要——它允许任意两个位置之间的直接信息传递,避免了逐跳压缩带来的信息损失。
I.7 方法论反思与局限性
Physics of Language Models 系列的研究方法论本身极具启发性,但在引用其结论时,也需要注意以下局限:
模型规模的外推风险。 该系列的大多数实验在 GPT-2 small 至 1.3B 参数级别的模型上执行。合成任务的可控性虽强,但无法保证相同的规律在数十亿乃至千亿参数的模型、真实海量语料场景下依然完全成立。例如,"2 bits/param"的容量常数是否在 70B 或 405B 模型上仍然精确,目前尚无直接实验验证。
探针方法的固有局限。 线性探测本质上是一个浅层分类器,只能捕捉隐藏状态中线性可分的信息。如果模型以高度非线性的方式编码某些知识或推理模式,探针可能检测不到。因此,探针结果可以证明"模型至少编码了 X",但不能证明"模型没有编码 Y"。
"理解"与"模式记忆"的边界。 尽管作者通过精心设计的 OOD 测试论证了模型具备"真正的推理"能力,但"什么算真正的理解"本身就是一个哲学问题。批评者可能会指出,只要训练数据的分布足够丰富,复杂的模式匹配在统计上可能与"理解"难以区分。这一争论目前尚无定论。
知识定义的简化。 Part 3 系列将"知识"定义为结构化的事实元组,这对量化研究非常方便,但真实世界的知识远比元组复杂——常识推理、因果关系、情感理解等都很难用元组表示。"2 bits/param"的结论应理解为对特定类型知识的度量,而非模型"全部认知能力"的上界。
合成任务的生态效度。 合成任务的优势(完全可控、无数据污染)同时也是其弱点——人工设计的 CFG 和 iGSM 与自然语言的复杂度存在本质差异。模型在合成任务上展现的能力,不一定能直接映射到其处理真实自然语言时的内部机制。
与其他可解释性研究的互补。 该系列的"自上而下"实验路径(设计任务 → 训练 → 探测)与另一类"自下而上"的可解释性研究(如 Anthropic 的 Sparse Autoencoders、机械可解释性中的电路分析等)形成互补。前者擅长回答"模型能学会什么",后者擅长回答"已训练好的模型内部长什么样"。理想的可解释性研究应当同时借鉴两种路径的洞见。
I.8 总结与启示
Physics of Language Models 系列为理解 LLM 的内部工作机制开辟了一条独特的道路。通过"构建合成任务 → 训练模型 → 用探针解剖内部表征"这一方法论,该系列回答了(或至少提供了有力证据去回答)以下核心问题:
- LLM 不只是"随机鹦鹉":至少在合成任务上,模型学到了类似动态规划的结构化计算策略,而非简单的表面模式匹配(Part 1)
- 推理能力可以从语言建模中涌现:只要数据足够丰富且多样,模型能自主习得可泛化的推理技能和内部规划能力(Part 2.1)
- 纠错是一种需要专门培养的技能:在预训练阶段就引入包含纠错模式的数据,效果远优于事后补救(Part 2.2)
- 数据多样性比数据量更重要:同一知识的多种表述方式是知识被有效编码和提取的关键(Part 3.1)
- 存储知识不等于能灵活运用:CoT 对知识操纵是必需的,逆向搜索是自回归架构的结构性弱点(Part 3.2)
- 模型容量存在可度量的上界:约 2 bits/param 的容量常数为估算模型的知识承载能力提供了量化工具(Part 3.3)
- 局部协作机制能以极小代价带来显著提升:Canon 层揭示了 Transformer 深度推理优势的来源,也指明了线性模型的改进方向(Part 4.1)
对于研究者和工程师而言,这些发现的最大价值或许不在于具体的数字(如 2 bits/param),而在于其背后的方法论:当我们想理解一个复杂系统时,构建一个完全可控的简化版本、在其中做精确的因果实验,往往比在真实环境中做相关性分析更有洞察力。这正是"格物致知"的精神所在。
最后,该系列的研究也为 LLM 的实际工程实践提供了若干可操作的建议:
- 训练数据构建:对关键知识进行多样化改写(Part 3.1)、引入包含纠错模式的样本(Part 2.2)、保留数据来源标记以引导模型优先学习高质量数据(Part 3.3)
- 架构选择:在需要深度推理的场景中优先选择 Transformer 架构而非线性模型(Part 4.1);考虑在现有架构中插入 Canon 层以低代价获取性能提升
- 推理策略:在需要知识操纵(而非简单检索)的场景中,CoT 提示是必需的而非可选的(Part 3.2);对于逆向搜索类任务,应优先考虑 RAG 方案而非依赖模型内部知识
- 模型评估:在声称模型"理解"某项能力之前,需要设计分布外测试来排除模板记忆的可能(Part 2.1),不能仅凭基准分数下结论