17.5 自改进(Self-Refinement)
上一节的自一致性通过"广撒网,多投票"来提升推理可靠性,但它有一个根本局限:每条路径都是独立生成的,后一条路径无法从前一条的错误中吸取教训。 如果模型对某个知识点存在系统性盲区,采样再多次也只会得到相同的错误。自改进(Self-Refinement) 正是为了突破这一瓶颈而提出的推理时间缩放策略——它让模型自己审视已有回答、指出不足,然后据此生成修正版本,通过迭代反馈循环不断逼近正确答案。
更进一步,自改进框架天然需要一种评分机制来判断"修正后的回答是否比原来更好"。本节将从两种核心评分方法——基于规则的启发式评分和基于对数概率(Log-probability)的置信度评分——讲起,然后介绍迭代反馈改进循环的完整流程,最后讨论另一种互补策略 Best-of-N 方法,并结合实验数据分析各种方案的效果。
17.5.1 评分机制:如何判断回答质量
自改进的核心在于"改了之后是否更好"。为此需要一个评分函数(Scoring Function),对模型生成的每条回答打分。以下介绍两种无需额外模型即可实现的评分方式。
启发式评分(Heuristic Scoring)。 最简单的评分方式是基于规则设计的启发式打分。核心思想是:一个好的数学推理回答通常会包含结构化的最终答案(如 \boxed{83}),并且不会过于冗长。据此可以设计如下评分规则:
import math
import re
def heuristic_score(
answer: str,
brevity_bonus: float = 500.0,
boxed_bonus: float = 2.0,
extract_bonus: float = 1.0,
) -> float:
"""
基于规则的启发式评分函数。
- 若答案包含 \\boxed{} 格式,给予较高奖励
- 若仅包含可提取数字,给予较低奖励
- 附加简洁性奖励:答案越短,奖励越高
"""
score = 0.0
# 检查是否有 \boxed{...} 格式的最终答案
if re.search(r"\\boxed\{.*?\}", answer):
score += boxed_bonus
# 退而求其次,检查是否有可提取的数字
elif re.search(r"\d+", answer):
score += extract_bonus
# 简洁性奖励:指数衰减,答案越长得分越低
score += 1.5 * math.exp(-len(answer) / brevity_bonus)
return score简洁性奖励使用指数衰减函数
启发式评分实现简单、计算成本为零,但局限性同样明显——它只看"格式"不看"内容",无法判断推理过程是否正确。为此需要一种更深层的评分方式。
17.5.2 对数概率置信度评分
Token 概率的直觉。 语言模型在生成每个 Token 时都会输出一个概率分布。如果模型对某个答案非常"自信",那么它为该答案中每个 Token 分配的概率就会较高。我们可以将这种概率信息作为回答质量的代理指标。
给定一个长度为
其中
从概率到对数概率。 为了避免数值下溢,我们取对数,将连乘转化为求和:
对数概率(Log-probability,简称 logprob)始终为非正数(因为
| 文本 | 各 Token logprob | 联合 logprob |
|---|---|---|
| "The capital of Germany is Berlin" | [-9.69, -0.77, -4.09, -0.30, -1.78] | -16.63 |
| "The capital of Germany is Hamburg" | [-9.69, -0.77, -4.09, -0.30, -3.53] | -18.38 |
| "The capital of Germany is Bridge" | [-9.69, -0.77, -4.09, -0.30, -15.00] | -29.88 |
可以看到,"Berlin" 的联合 logprob 最高(最接近 0),模型对它最有信心;"Bridge" 几乎不可能出现在这个上下文中,logprob 极低。
平均对数概率评分。 直接用联合 logprob 会偏向短回答(Token 越少,累加项越少,得分自然越高)。为了公平比较不同长度的回答,我们只对答案部分(不含 Prompt)的 Token 取平均:
其中
import torch
@torch.inference_mode()
def avg_logprob_score(
model,
tokenizer,
prompt: str,
answer: str,
device: str = "cpu",
) -> float:
"""
计算模型对 answer 部分的平均对数概率。
值越高(越接近 0)代表模型越自信。
"""
# 分别编码 prompt 和 answer 以确定答案起始位置
prompt_ids = tokenizer.encode(prompt)
answer_ids = tokenizer.encode(answer)
full_ids = torch.tensor(prompt_ids + answer_ids, device=device)
# 一次前向传播获取所有位置的 logits
logits = model(full_ids.unsqueeze(0)).squeeze(0)
logprobs = torch.log_softmax(logits, dim=-1)
# 只取答案部分的 token 对应的 logprob
start = len(prompt_ids) - 1
end = full_ids.shape[0] - 1
t_idx = torch.arange(start, end, device=device)
next_tokens = full_ids[start + 1 : end + 1]
answer_logprobs = logprobs[t_idx, next_tokens]
return torch.mean(answer_logprobs).item()两种评分的互补性。 启发式评分关注格式和简洁性,logprob 评分关注模型内部置信度。实验表明,在自一致性的平票打破场景中,logprob 评分(44.8%)略优于启发式评分(43.4%)和纯多数投票(43.2%),但差距并不悬殊。真正发挥评分威力的场景是接下来要介绍的自改进循环和 Best-of-N。
17.5.3 迭代反馈改进循环
有了评分函数,就可以构建自改进的核心机制——"生成-批评-修正"循环。整个流程如下图所示:
问题 ──→ [初始生成] ──→ 草稿回答
│
┌─────┴─────┐
│ 评分函数 │
└─────┬─────┘
▼
┌───────────┐
┌────→│ 批评提示 │──→ 模型生成批评意见
│ └───────────┘
│ │
│ ┌─────┴─────┐
│ │ 修正提示 │──→ 模型生成修正回答
│ └─────┬─────┘
│ │
│ ┌─────┴─────┐
│ │ 评分比较 │──→ 修正版更好?采纳 : 保留原版
│ └─────┬─────┘
│ │
└───────────┘ (下一轮迭代)步骤一:生成初始草稿。 模型对原始问题生成第一版回答。
步骤二:批评(Critique)。 将问题和草稿回答拼接为"批评提示",让模型以审阅者身份指出逻辑错误、缺失步骤或算术错误,并给出修正计划。批评提示的构造如下:
def make_critique_prompt(question: str, draft: str) -> str:
"""构造批评提示,让模型以审阅者身份指出草稿中的问题。"""
return (
"You are a meticulous reviewer. Identify logical errors, "
"missing steps, or arithmetic mistakes. If the answer seems "
"correct, say so briefly. Then propose a concise plan to "
"fix issues.\n\n"
f"Question:\n{question}\n\n"
f"Draft answer:\n{draft}\n\n"
"Write a short critique and bullet-point fix plan "
"(under ~120 words).\n"
"Critique:"
)步骤三:修正(Refine)。 将原始问题、草稿和批评意见一同拼接为"修正提示",让模型据此生成改进版回答:
def make_refine_prompt(
question: str, draft: str, critique: str
) -> str:
"""构造修正提示,让模型根据批评意见改进回答。"""
return (
"Revise the answer using the critique. Keep it concise "
"and end with a final boxed result: \\boxed{ANSWER}\n\n"
f"Question:\n{question}\n\n"
f"Previous answer:\n{draft}\n\n"
f"Critique:\n{critique}\n\n"
"Revised answer:"
)步骤四:评分与门控。 用评分函数分别对原始回答和修正回答打分。只有修正版得分不低于原版时才采纳,否则保留原版。这是一个关键的保护机制——防止"越改越差"。
完整循环实现。 将上述步骤封装为可迭代的循环:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
from typing import Callable, Optional
def self_refinement_loop(
generate_fn: Callable,
question: str,
score_fn: Optional[Callable] = None,
iterations: int = 2,
temperature: float = 0.7,
top_p: float = 0.9,
) -> dict:
"""
自改进循环:生成 → 批评 → 修正 → 评分门控,迭代 n 轮。
参数:
generate_fn: 文本生成函数,接受 prompt 并返回生成文本
question: 原始问题
score_fn: 评分函数,接受 (answer, prompt) 返回 float
iterations: 迭代轮数
返回:
包含最终回答和每轮详情的字典
"""
# 初始生成
current_answer = generate_fn(question)
current_score = score_fn(current_answer, question) if score_fn else 0.0
history = []
for i in range(iterations):
# 批评阶段
critique_prompt = make_critique_prompt(question, current_answer)
critique = generate_fn(critique_prompt)
# 修正阶段
refine_prompt = make_refine_prompt(
question, current_answer, critique
)
revised_answer = generate_fn(refine_prompt)
revised_score = (
score_fn(revised_answer, question) if score_fn else 0.0
)
history.append({
"iteration": i + 1,
"draft": current_answer,
"critique": critique,
"revised": revised_answer,
"score_before": current_score,
"score_after": revised_score,
})
# 门控:只在修正版不差于原版时采纳
if revised_score >= current_score:
current_answer = revised_answer
current_score = revised_score
return {"final_answer": current_answer, "history": history}一个具体例子。 对问题 "Half the value of
| 阶段 | 回答摘要 | Logprob 得分 |
|---|---|---|
| 初始生成 | 错误地得到 | -0.855 |
| 第 1 轮修正 | 批评指出等式建立有误,修正后得到 | -0.226 |
| 第 2 轮修正 | 再次修正,仍得 | -1.320 |
门控机制发挥了作用:第 2 轮修正的得分(-1.320)低于第 1 轮(-0.226),因此被拒绝。最终采纳第 1 轮的修正结果
- 纠错能力:模型能够发现自己的错误并加以修正
- 门控保护:评分机制防止了"过度修正"导致的退化
- 迭代的边际递减:通常 1-2 轮修正即可捕获主要改进,更多轮次的收益有限
17.5.4 Best-of-N 方法
与自改进的"串行迭代"思路不同,Best-of-N 采用"并行竞争"策略:对同一问题独立生成
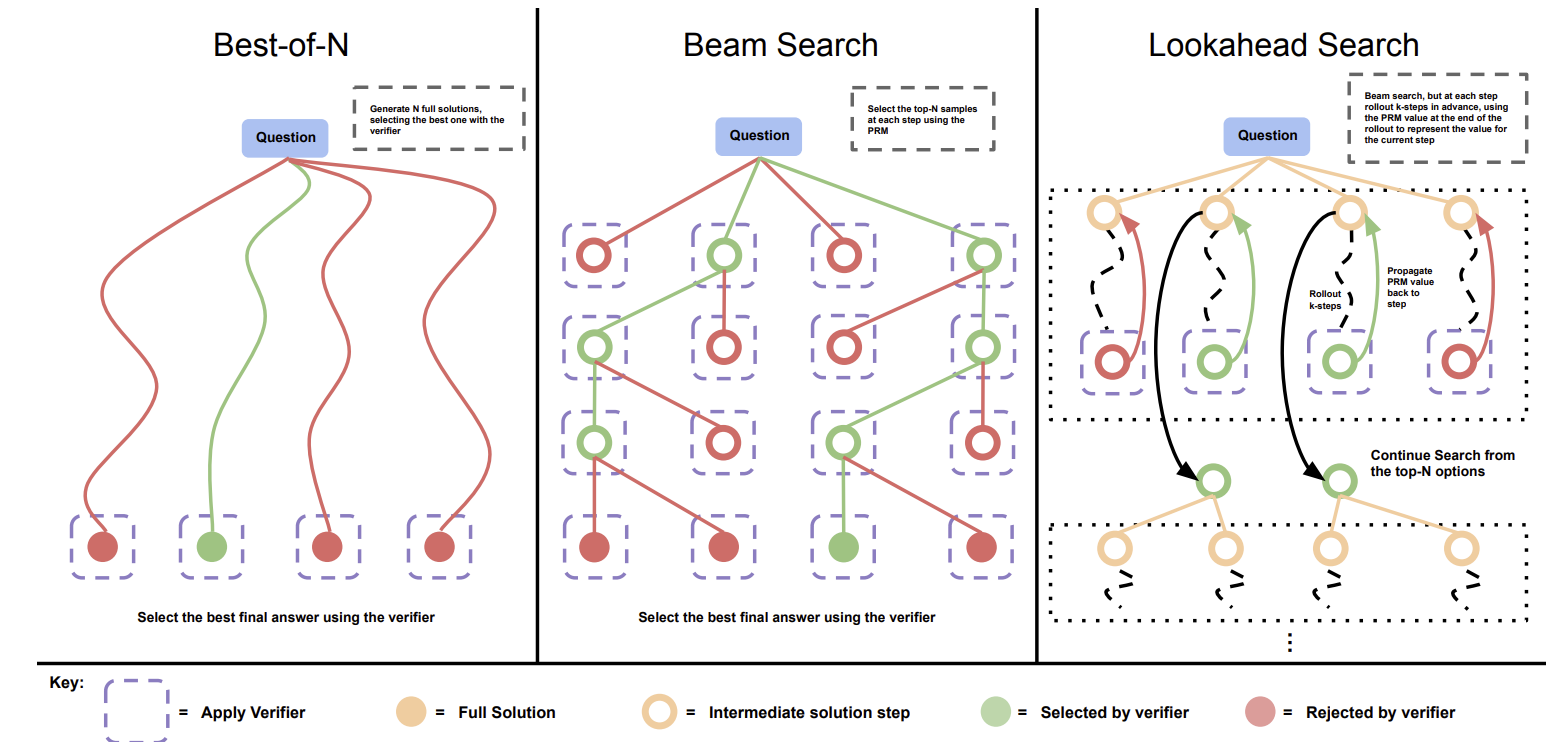
图 17-8:三种推理时搜索策略对比。Best-of-N(左)独立采样多条完整路径后选最优;Beam Search(中)在每一步维持 M 个最优候选;Lookahead Search(右)通过预演未来步骤评估当前选择。
Best-of-N 与自一致性的区别。 两者都生成多条回答,但选择机制不同:
| 特征 | 自一致性 | Best-of-N |
|---|---|---|
| 选择依据 | 多数投票(答案频率) | 评分函数(回答质量) |
| 核心假设 | 正确答案出现频率最高 | 好回答的评分更高 |
| 对评分函数的依赖 | 无(可选作平票打破) | 强(评分是唯一决策依据) |
| 适用场景 | 答案空间离散且有限 | 答案可评分、开放式任务 |
Best-of-N 的实现非常直接:
from typing import Callable, List
def best_of_n(
generate_fn: Callable,
question: str,
score_fn: Callable,
n: int = 3,
) -> dict:
"""
Best-of-N: 生成 N 条回答,选评分最高的。
参数:
generate_fn: 文本生成函数
question: 原始问题
score_fn: 评分函数
n: 采样数量
返回:
最优回答及所有候选的评分
"""
candidates = []
for _ in range(n):
answer = generate_fn(question)
score = score_fn(answer, question)
candidates.append({"answer": answer, "score": score})
# 按评分降序排列,取最优
candidates.sort(key=lambda x: x["score"], reverse=True)
return {
"best_answer": candidates[0]["answer"],
"best_score": candidates[0]["score"],
"all_candidates": candidates,
}实验效果对比。 在 MATH-500 数据集上(使用 0.6B 参数的基座模型),各方法的准确率如下:
| 方法 | 评分方式 | 准确率 | 相对基线提升 |
|---|---|---|---|
| Baseline(CoT 提示) | — | 33.4% | — |
| 自一致性( | 投票 | 43.2% | +9.8 |
| 自一致性( | Logprob | 44.8% | +11.4 |
| Best-of-N( | 启发式 | 40.6% | +7.2 |
| Best-of-N( | Logprob | 43.2% | +9.8 |
| 自改进(1 轮)+ 启发式 | 启发式 | 21.6% | — |
| 自改进(1 轮,推理模型) | 启发式 | 57.8% | +9.6* |
注:推理模型(经过 SFT 的模型)的基线为 48.2%。
表 17-8:各推理时间缩放方法在 MATH-500 上的效果对比。
几个关键观察:
- 自一致性 + logprob 表现最优:在基座模型上,这种组合以 44.8% 的准确率领先
- Best-of-N + logprob 紧随其后:43.2% 的表现接近自一致性,说明 logprob 是一个有效的评分信号
- 自改进对基座模型效果有限:基座模型自改进后仅 21.6%,低于基线的 33.4%。这并非方法本身的问题,而是因为小型基座模型的"自我批评"能力太弱,批评内容可能误导而非纠正
- 自改进在推理模型上效果显著:经过 SFT 的推理模型从 48.2% 提升到 57.8%,增幅达 9.6 个百分点,说明自改进的效果强依赖于模型的基础推理能力
17.5.5 数据筛选迭代与自改进的规模化
前面讨论的自改进发生在单次推理过程中。如果将时间尺度从"一次推理"拉长到"训练-推理"的完整循环,自改进的思想可以进一步规模化为数据筛选迭代。
核心思路。 让模型生成大量候选推理路径,用评分机制(PRM 或其他验证器)筛选出高质量路径作为训练数据,然后在这些数据上微调模型,再重复此过程。每一轮迭代中,模型既是数据的"生产者"也是"消费者",形成正反馈循环。
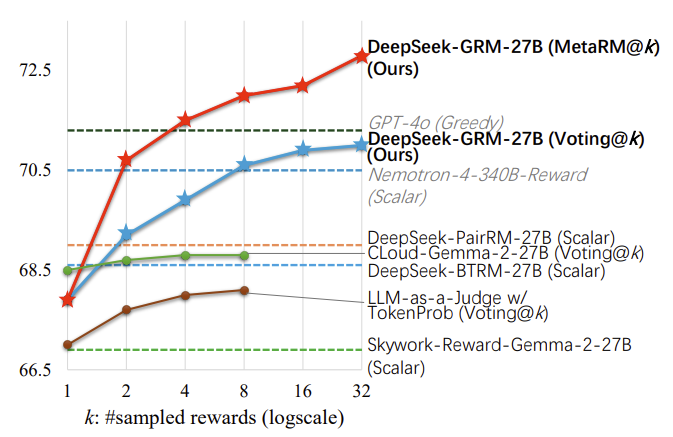
图 17-9:不同奖励模型架构在增加采样次数(
这种数据筛选迭代的典型范式包含以下步骤:
- 生成:让当前模型对一批问题生成多条候选回答
- 筛选:使用评分函数(启发式/logprob/PRM/规则验证器)过滤掉低质量回答
- 训练:在高质量回答上对模型进行微调(SFT 或 RL)
- 回到步骤 1:用更新后的模型重复上述过程
这与 §17.0 中介绍的 DeepSeek-R1 训练管线中的拒绝式微调(Rejective Fine-Tuning) 异曲同工:在 R1 的训练流程中,先通过 RL 冷启动获得初步推理能力,然后用这个模型大量采样、筛选正确且推理过程优质的样本,再进行下一阶段的微调。这本质上就是自改进思想在训练层面的体现。
评分函数的选择至关重要。 上图展示了一个关键发现:标量奖励模型(如 Bradley-Terry 模型)是确定性输出,对相同输入总是返回同一个分数,因此无法通过增加采样次数来提升性能。而生成式奖励模型(如 DeepSeek-GRM)每次采样时会生成不同的文本评语和分数,多次采样后通过聚合(投票或元奖励模型筛选)可以持续提升评分准确性。这一洞察揭示了一个更深层的原则:能够从推理时间缩放中获益的评分机制,本身也应当具备多样性和可扩展性。
17.5.6 小结
本节围绕"如何让模型自我改进"这一主题,介绍了推理时间缩放的三种互补策略:
| 策略 | 核心思想 | 优势 | 局限 |
|---|---|---|---|
| 启发式/Logprob 评分 | 用规则或模型置信度为回答打分 | 无需额外模型,计算开销小 | 无法判断推理正确性 |
| 自改进循环 | 生成-批评-修正的迭代优化 | 能纠正具体推理错误 | 依赖模型自我批评能力 |
| Best-of-N | 并行采样,选最优 | 简单有效,易并行化 | 计算量线性增长 |
三者并非互斥。实际系统中常将它们组合使用:先用 Best-of-N 或自一致性获得多个候选,再用自改进对最优候选进一步打磨,最终用 logprob 评分或更高级的奖励模型做最终裁决。这种层层递进的策略组合,正是推理时间缩放从"理论概念"走向"工程实践"的关键一步。