14.2 白盒蒸馏
在上一节中我们了解了知识蒸馏的基本思想——让一个小型学生模型(Student Model)通过模仿大型教师模型(Teacher Model)的行为来获取知识。当我们能够直接访问教师模型的内部参数和完整输出分布时,这种蒸馏方式被称为白盒蒸馏(White-box Distillation)。白盒蒸馏的核心武器是 KL 散度损失(KL Divergence Loss),它让学生模型在每个 Token 位置上都去模仿教师的完整概率分布,从而学到比硬标签丰富得多的"暗知识"。
本节将从 KL 散度损失的数学原理出发,逐步推导混合损失函数的设计,并给出完整的代码实现。
14.2.1 为什么需要白盒蒸馏
最直接的蒸馏方式是序列级蒸馏(Sequence-level KD / SeqKD):让教师模型对训练数据生成回答,然后用这些回答作为"硬标签"对学生模型做监督微调(SFT)。DeepSeek-R1 的蒸馏正是采用了这一路线——用经过 RL 优化的 671B MoE 教师模型生成 80 万条高质量推理轨迹,再以纯 SFT 训练 Qwen 和 Llama 系列的学生模型。
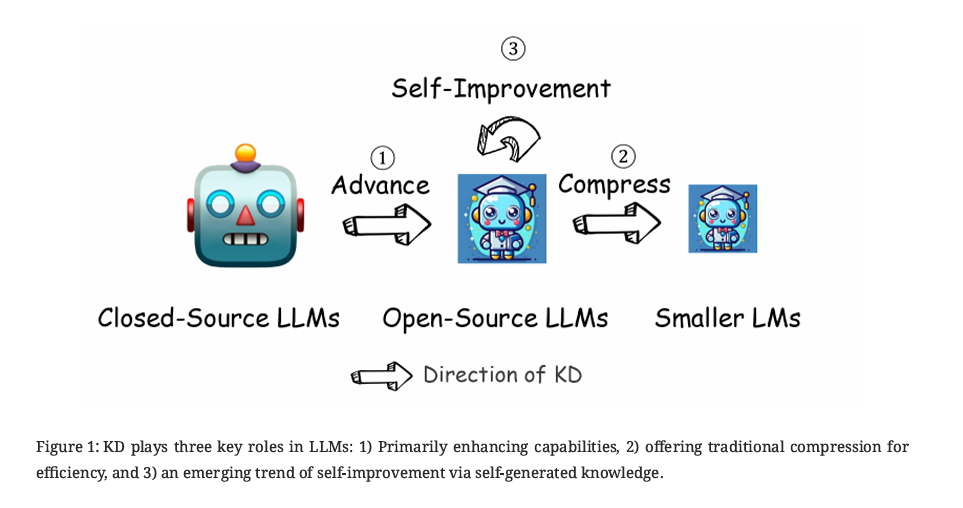
图 14-1:知识蒸馏在大模型中扮演三种角色——能力增强(从闭源模型到开源模型)、模型压缩(从大模型到小模型)、以及自我改进(模型利用自身生成数据迭代提升)。
序列级蒸馏的优势在于简单——学生只需要教师的输出文本,甚至不需要访问教师的权重。然而它有一个根本局限:硬标签只保留了教师最终选择的 Token,丢弃了教师在所有候选 Token 上的概率分布信息。例如,教师在某个位置给出"因此"这个词时,"所以"、"从而"、"故而"等近义词可能也有较高概率——这些概率关系正是 Hinton 所说的暗知识(Dark Knowledge),它编码了类别间的相似性和教师对不确定性的判断。
白盒蒸馏通过直接对齐教师和学生的完整输出分布来保留这些信息,核心工具就是 KL 散度。
14.2.2 温度缩放与软化分布
在计算 KL 散度之前,需要先对教师和学生的原始输出(Logits)进行温度缩放(Temperature Scaling)。标准 Softmax 函数在温度
其中
- 当
时,退化为标准 Softmax,分布集中在概率最高的少数词上。 - 当
时,分布变得更平滑,低概率词的概率被"放大",暗知识更容易被学生学到。 - 当
时,趋向均匀分布,失去区分能力。
实践中通常取
以下代码展示了温度缩放的效果:
import torch
import torch.nn.functional as F
# 模拟教师模型在某个位置的 Logits(词表大小 = 8)
logits = torch.tensor([5.0, 3.0, 1.0, 0.5, 0.1, -1.0, -2.0, -3.0])
# 不同温度下的概率分布
for T in [1.0, 3.0, 5.0, 10.0]:
probs = F.softmax(logits / T, dim=-1)
print(f"T={T:>4.1f}: {probs.numpy().round(3)}")
# T= 1.0: [0.868 0.117 0.016 0.010 ... ] — 极度集中
# T= 3.0: [0.326 0.191 0.112 0.097 ... ] — 开始平滑
# T= 5.0: [0.235 0.170 0.123 0.113 ... ] — 暗知识显现
# T=10.0: [0.168 0.145 0.125 0.120 ... ] — 趋近均匀14.2.3 KL 散度蒸馏损失
有了温度软化后的分布,就可以计算教师分布
其中
为什么要乘以
乘以
以下是 PyTorch 中蒸馏损失的完整实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
def distillation_loss(student_logits, teacher_logits, temperature=4.0):
"""
计算 KL 散度蒸馏损失。
Args:
student_logits: 学生模型输出, shape [batch, seq_len, vocab_size]
teacher_logits: 教师模型输出, shape [batch, seq_len, vocab_size]
temperature: 蒸馏温度
Returns:
标量损失值
"""
# 教师分布:先除以温度再 softmax(无需梯度)
teacher_probs = F.softmax(teacher_logits / temperature, dim=-1)
# 学生分布:先除以温度再 log_softmax(PyTorch 的 kl_div 要求输入为对数概率)
student_log_probs = F.log_softmax(student_logits / temperature, dim=-1)
# KL 散度,reduction="batchmean" 对 batch 维度取平均
kl = F.kl_div(student_log_probs, teacher_probs, reduction="batchmean")
# 乘以 T^2 补偿梯度缩放
return (temperature ** 2) * kl实现细节提示:PyTorch 的
F.kl_div函数要求第一个参数是对数概率(使用log_softmax),第二个参数是概率(使用softmax)。如果顺序搞反,计算结果将是错误的。
14.2.4 混合损失函数
白盒蒸馏的训练目标是将蒸馏损失与标准的交叉熵损失(Cross-Entropy Loss)按比例混合。交叉熵损失让学生模型直接学习真实标签(即训练数据中的下一个 Token),而蒸馏损失让学生模型同时模仿教师的完整输出分布。两者的组合形成了经典的混合损失(Combined Loss):
其中:
是学生对真实标签的交叉熵损失, 是有效 Token 数量。 是上一小节定义的蒸馏损失。 是混合系数,控制"模仿教师"和"拟合真实标签"之间的平衡。
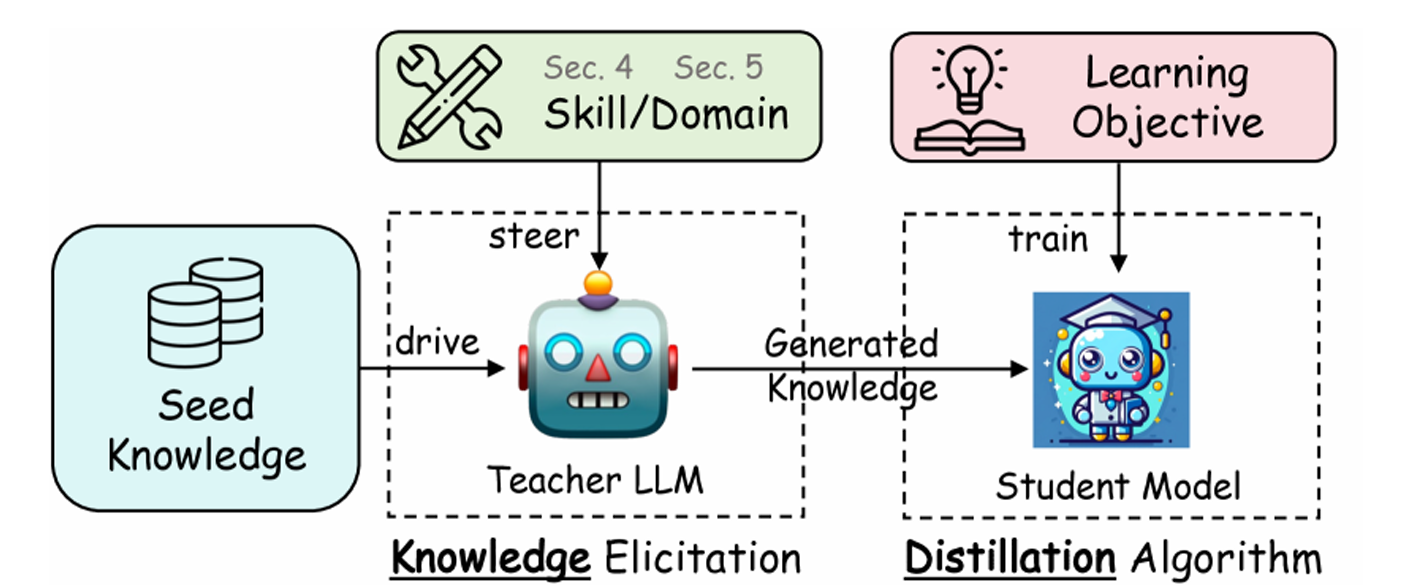
图 14-2:大模型知识蒸馏的通用流程——教师模型在种子知识和目标技能引导下生成蒸馏数据,学生模型通过损失函数约束学习教师的知识。
以下是混合损失函数的完整实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class WhiteBoxDistillationLoss(nn.Module):
"""白盒蒸馏的混合损失:KL 散度 + 交叉熵。"""
def __init__(self, alpha=0.7, temperature=4.0):
super().__init__()
self.alpha = alpha
self.temperature = temperature
self.kl_loss = nn.KLDivLoss(reduction="batchmean")
self.ce_loss = nn.CrossEntropyLoss()
def forward(self, student_logits, teacher_logits, labels):
"""
Args:
student_logits: [batch, seq_len, vocab_size]
teacher_logits: [batch, seq_len, vocab_size](已 detach)
labels: [batch, seq_len] 真实标签
"""
T = self.temperature
# 蒸馏损失
teacher_probs = F.softmax(teacher_logits / T, dim=-1)
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
kd_loss = self.kl_loss(student_log_probs, teacher_probs) * (T ** 2)
# 交叉熵损失(使用原始 logits,不做温度缩放)
ce_loss = self.ce_loss(
student_logits.view(-1, student_logits.size(-1)),
labels.view(-1)
)
# 混合损失
return self.alpha * kd_loss + (1 - self.alpha) * ce_loss14.2.5 完整训练循环
有了混合损失函数,就可以搭建完整的白盒蒸馏训练循环。其核心流程是:对每个训练 Batch,先用教师模型做一次前向传播获取 Logits(不计算梯度),再用学生模型做前向传播,计算混合损失并反向传播更新学生参数。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.cuda.amp import autocast, GradScaler
def train_distillation(
teacher_model,
student_model,
dataloader,
optimizer,
loss_fn, # WhiteBoxDistillationLoss 实例
epochs=3,
accumulation_steps=4,
device="cuda"
):
"""白盒蒸馏训练循环。"""
scaler = GradScaler()
teacher_model.eval() # 教师模型始终处于推理模式
for epoch in range(epochs):
student_model.train()
total_loss = 0.0
for step, batch in enumerate(dataloader):
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = input_ids.clone()
# ---- 教师前向:无梯度,节省显存 ----
with torch.no_grad():
teacher_outputs = teacher_model(
input_ids=input_ids,
attention_mask=attention_mask
)
teacher_logits = teacher_outputs.logits.float()
# ---- 学生前向 + 损失计算 ----
with autocast():
student_outputs = student_model(
input_ids=input_ids,
attention_mask=attention_mask
)
student_logits = student_outputs.logits
loss = loss_fn(student_logits, teacher_logits, labels)
loss = loss / accumulation_steps # 梯度累积
# ---- 反向传播 ----
scaler.scale(loss).backward()
# 每 accumulation_steps 步更新一次参数
if (step + 1) % accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(
student_model.parameters(), max_norm=1.0
)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
total_loss += loss.item() * accumulation_steps
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}")几个关键实现细节:
- 教师模型使用
torch.no_grad():教师参数不更新,禁用梯度可大幅节省显存和计算。 - 混合精度训练(AMP):
autocast()+GradScaler让学生前向使用 FP16/BF16 加速,同时避免梯度下溢。 - 梯度累积:当 GPU 显存不足以承载较大 Batch 时,将多个小 Batch 的梯度累积后再更新参数,等效于增大批次。
- 梯度裁剪:
clip_grad_norm_防止因蒸馏损失和交叉熵损失叠加导致的梯度爆炸。
图 14-3:白盒蒸馏训练曲线示例——损失在前期快速下降后趋于平稳,配合 Cosine 学习率衰减策略可获得更好的收敛效果。
14.2.6 正向 KL 与反向 KL 的选择
上文使用的蒸馏损失是正向 KL 散度
MiniLLM 提出使用反向 KL 散度
| 特性 | 正向 KL | 反向 KL |
|---|---|---|
| 行为 | 模式覆盖:学生试图覆盖教师所有模式 | 模式寻求:学生聚焦教师的主要模式 |
| 优势 | 不会遗漏教师的任何模式 | 生成质量高,分布集中 |
| 劣势 | 可能在长尾区域浪费容量 | 可能丢失教师的部分多样性 |
| 适用场景 | 分类任务、教师分布紧凑 | 开放式生成、教师分布有长尾 |

图 14-4:MiniLLM 蒸馏算法——基于反向 KL 散度,结合单步分解、教师混合采样和长度归一化三项策略,有效缓解了暴露偏差并提升了生成质量。
MiniLLM 通过策略梯度来优化反向 KL(因为反向 KL 需要从学生分布采样,不能直接计算梯度),并引入三项稳定训练的技术:
- 单步分解(Single-step Decomposition):将多步序列的反向 KL 分解为逐步的期望计算,降低方差。
- 教师混合采样(Teacher-mixed Sampling):在学生采样的序列中混合教师的序列,防止学生在自身的低质量样本上"奖励作弊"。
- 长度归一化(Length Normalization):避免模型偏好生成短文本,使蒸馏目标对序列长度不敏感。
14.2.7 大规模 Logits 的显存优化
白盒蒸馏的一个实际难题是显存消耗。教师和学生的 Logits 张量形状为 [batch, seq_len, vocab_size],当词表大小
方案一:Top-K 截断。 只保留教师 Logits 中概率最高的
def topk_distillation_loss(student_logits, teacher_logits,
temperature=4.0, topk=128):
"""
Top-K 截断的蒸馏损失,大幅降低显存占用。
"""
B, S, V = teacher_logits.size()
T = temperature
# 找到教师 Logits 中 Top-K 的值和索引
flat_teacher = teacher_logits.view(B * S, V)
topk_vals, topk_idx = torch.topk(flat_teacher, topk, dim=-1)
# 非 Top-K 位置设为 -inf,softmax 后概率为 0
mask = torch.full_like(flat_teacher, float("-inf"))
mask.scatter_(1, topk_idx, topk_vals)
teacher_trunc = mask.view(B, S, V)
# 使用截断后的分布计算 KL 散度
teacher_probs = F.softmax(teacher_trunc / T, dim=-1)
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
kl = F.kl_div(student_log_probs, teacher_probs, reduction="batchmean")
return (T ** 2) * kl方案二:离线存储教师 Logits。 预先用教师模型对全部训练数据做一次推理,将 Logits(或 Top-K Logits)存储到磁盘。训练时只需加载学生模型,从磁盘读取教师 Logits,避免同时加载两个模型。这种方式将显存需求降低了近一半。
14.2.8 推理蒸馏中的特殊标签加权
当目标是蒸馏推理能力时(如让学生模型学会使用 <think>...</think> 思维链),控制思维流程的特殊标签(如 <think>、</think>、<answer> 等)对生成质量至关重要。一种有效的做法是在交叉熵损失中对这些特殊标签施加更高的权重。
核心思路是:在计算逐 Token 损失后,将特殊标签位置的损失乘以一个放大系数(如 10 倍),迫使模型更精确地预测这些控制推理结构的关键 Token。
def weighted_reasoning_loss(logits, labels, loss_mask, special_token_ids,
weight=10.0):
"""
对推理特殊标签加权的交叉熵损失。
Args:
logits: [batch, seq_len, vocab_size]
labels: [batch, seq_len]
loss_mask: [batch, seq_len], 1 表示有效位置, 0 表示 padding
special_token_ids: 需要加权的特殊 Token ID 列表
weight: 特殊标签的损失放大倍数
"""
loss_fct = nn.CrossEntropyLoss(reduction="none")
# 逐 Token 计算损失 -> [batch, seq_len]
per_token_loss = loss_fct(
logits.view(-1, logits.size(-1)), labels.view(-1)
).view(labels.size())
# 找出特殊标签位置
special_mask = torch.isin(
labels, torch.tensor(special_token_ids, device=labels.device)
)
# 未加权前记录有效 Token 总数(作为分母)
valid_count = loss_mask.sum()
# 对特殊标签位置的 mask 放大权重
weighted_mask = loss_mask.clone().float()
weighted_mask[special_mask] = weight
# 加权求和并归一化
loss = (per_token_loss * weighted_mask).sum() / valid_count
return loss以一个简单的序列为例说明效果:
| Token | 原始损失 | 原始 Mask | 是否特殊 | 加权后 Mask | 最终计算项 |
|---|---|---|---|---|---|
| "首先" | 2.0 | 1 | 否 | 1 | 2.0 |
| <think> | 3.0 | 1 | 是 | 10 | 30.0 |
| "分析" | 1.5 | 1 | 否 | 1 | 1.5 |
| </think> | 2.5 | 1 | 是 | 10 | 25.0 |
分子(加权总和)为
14.2.9 实验效果:蒸馏 vs 纯 RL
白盒蒸馏的实际效果如何?DeepSeek-R1 的实验提供了有力的证据。下表对比了蒸馏模型与其他可比模型在推理基准上的表现:
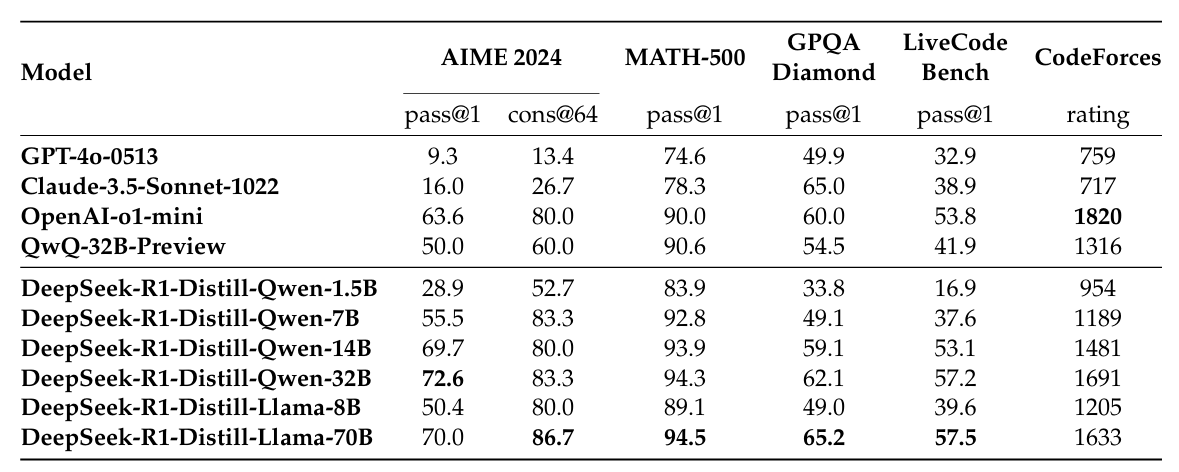
表 14-1:DeepSeek-R1 蒸馏模型在推理基准上的表现——7B 蒸馏模型已全面超越非推理模型 GPT-4o-0513,14B 模型超越 QwQ-32B-Preview,展现了高效能力迁移的威力。
更值得关注的是蒸馏与纯强化学习的对比:

表 14-2:蒸馏 vs 纯 RL——同为 32B 参数的 Qwen 模型,蒸馏版本在所有推理基准上显著优于直接经过大规模 RL 训练的版本,表明高质量教师数据 + SFT 比从零 RL 更经济高效。
这些结果说明:在大模型时代,蒸馏的效果主要取决于教师数据的质量和多样性,而非算法本身的复杂程度。DeepSeek-R1 仅用纯 SFT 蒸馏就大幅超越了纯 RL 训练的同参数模型,关键在于其 80 万条经过严格拒绝采样筛选的高质量推理轨迹。
14.2.10 小结
白盒蒸馏是将大模型知识压缩到小模型的核心技术之一。本节的要点可以归纳为以下几条:
- 温度缩放是暗知识的开关——通过
平滑教师分布,让低概率词的信息浮现出来。 补偿确保蒸馏梯度与交叉熵梯度量级一致,是混合损失能正常工作的前提。 - 混合损失
同时学习教师知识和真实标签, 控制两者的平衡。 - 正向 KL vs 反向 KL 的选择取决于任务:分类和短文本生成用正向 KL,开放式长文本生成更适合反向 KL(如 MiniLLM)。
- 显存优化是工程落地的关键——Top-K 截断和离线教师 Logits 是两种主流策略。
- 推理蒸馏中对特殊标签加权可以强制学生学会思维链的结构化控制。
- 数据质量 > 算法复杂度——DeepSeek-R1 用纯 SFT 蒸馏就超越了纯 RL,背后是 80 万条精筛数据的支撑。