22.2 向量数据库
"当你搜索'猫咪'时,传统数据库只能返回包含'猫咪'这两个字的结果;而向量数据库能同时找到'布偶'、'银渐层'和'橘猫'——因为它理解的是语义,而非字面。"
在 §22.1 中,我们介绍了 RAG 的整体框架:检索器负责从外部知识库中获取相关信息,生成器负责将检索结果融合进 LLM 的输出。但检索器的效率和质量,在很大程度上取决于底层的存储与索引系统——这正是**向量数据库(Vector Database)**的核心职责。本节将系统讲解向量数据库的基本原理、索引算法、相似度度量方法和架构设计,帮助读者从"知道有这么个东西"跃迁到"理解其内部机理并能在工程中做出合理选型"。
本节的学习目标如下:(1)理解向量数据库与传统数据库的本质区别;(2)掌握四类主流向量索引算法(IVF、HNSW、LSH、PQ)的核心思想与适用场景;(3)熟悉三种常用相似度度量方法的数学定义与选型策略;(4)了解向量数据库的通用架构设计。
22.2.1 从传统数据库到向量数据库
传统数据库的边界。 关系型数据库(MySQL、PostgreSQL)和非关系型数据库(MongoDB、Redis)都以精确匹配为核心搜索范式。它们的索引结构(B-Tree、倒排索引)和排序算法(BM25、TF-IDF)服务于一个目标:给定一个查询条件,返回完全满足该条件的记录。SQL 语句 SELECT * FROM animals WHERE name = '猫咪' 只能找到 name 字段恰好等于"猫咪"的行——"布偶"和"银渐层"永远不会出现在结果中,除非你事先手动打上关联标签。
向量数据库的突破。 向量数据库的核心理念完全不同:它存储的不是结构化的行列数据,而是由 Embedding 模型生成的高维向量。每个向量是一段非结构化数据(文本、图像、音频)在语义空间中的坐标。搜索时,不再做精确匹配,而是计算查询向量与库中向量的距离或相似度,返回距离最近的 Top-K 个结果。
两者的差异可以用下表概括:
| 维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据形态 | 结构化行列 | 高维浮点向量 |
| 检索方式 | 精确匹配(点查/范围查) | 近似最近邻(ANN) |
| 索引结构 | B-Tree、倒排索引 | HNSW、IVF、LSH、PQ |
| 返回结果 | 符合/不符合条件的记录 | 与查询最相似的 Top-K 向量 |
| 典型场景 | 关键字搜索、事务处理 | 语义搜索、以图搜图、推荐系统 |
关键认知:向量数据库本身并不"理解"语义。 这一点必须强调——向量数据库只做位置近似搜索,即在高维空间中寻找距离最近的点。"语义近似"的能力来自上游的 Embedding 模型:只有当模型把语义相近的内容映射到空间中距离相近的位置时,向量数据库的近似搜索才等价于语义搜索。换言之,向量数据库是"执行器",Embedding 模型才是"语义理解器"。
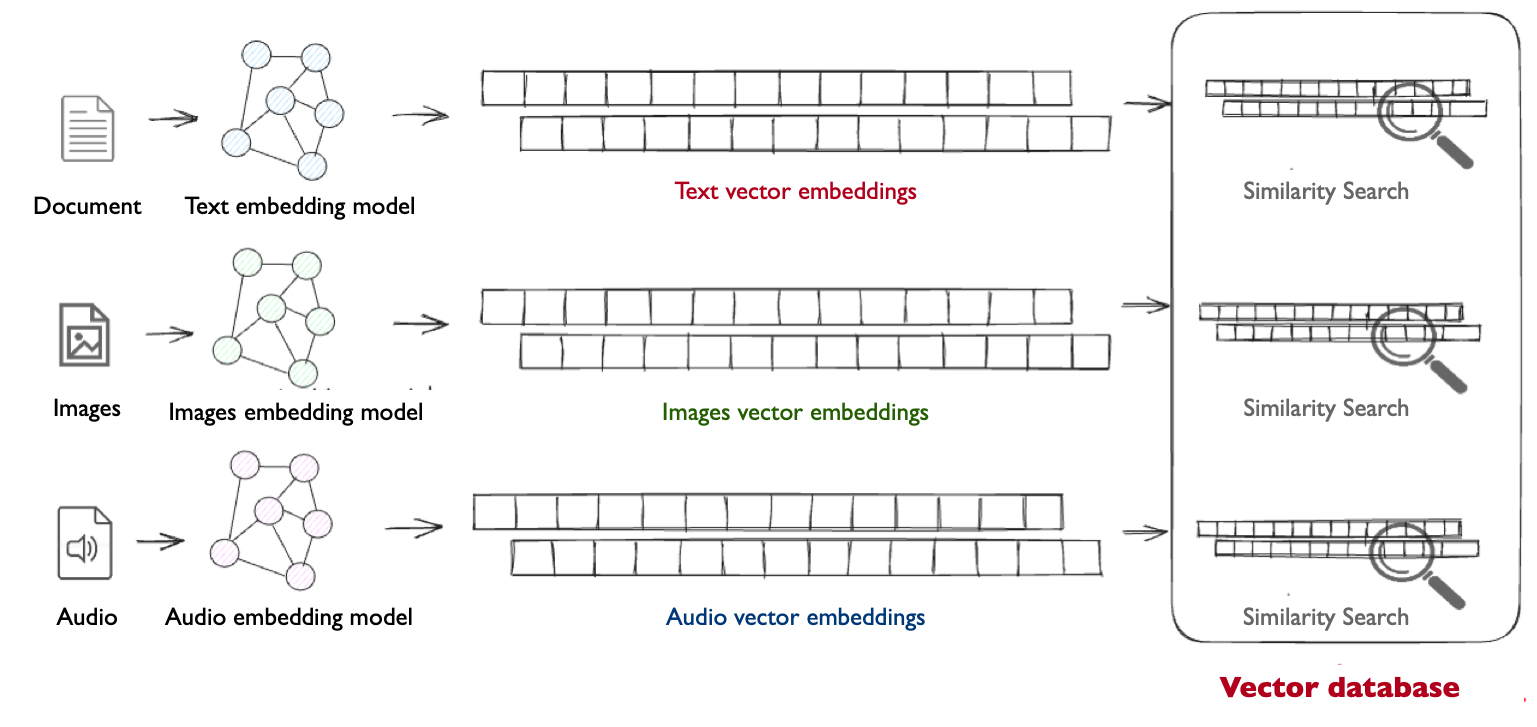
图 22-3:向量数据库的端到端工作流。文本、图像、音频等非结构化数据分别通过对应的 Embedding 模型转换为高维向量,存入向量数据库并建立索引。查询时,输入同样被向量化,在数据库中进行相似度搜索(Similarity Search),返回最相似的 Top-K 结果。
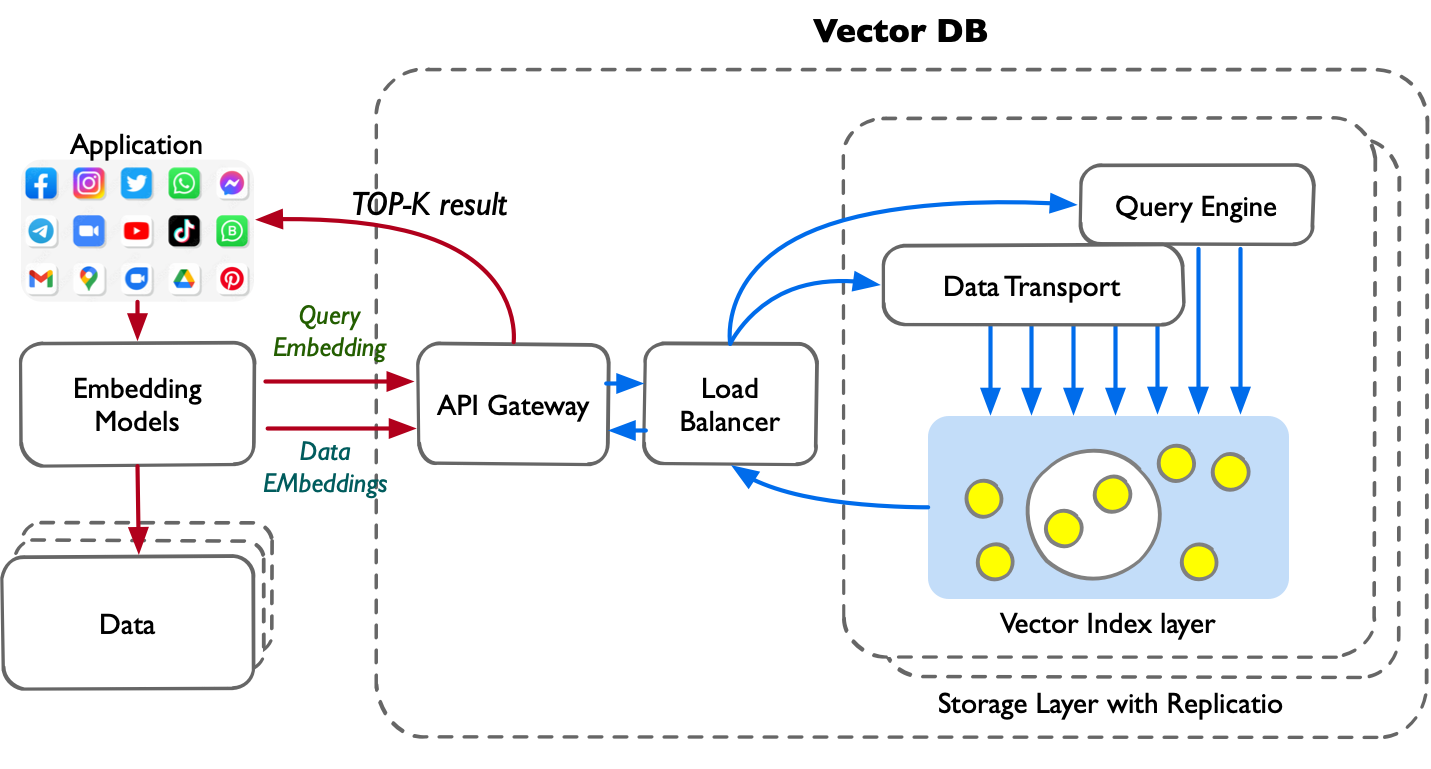
图 22-3b:向量数据库系统架构概览。应用端通过 Embedding 模型将数据/查询向量化后,经 API 网关和负载均衡器进入数据库内核。核心包括查询引擎、数据传输层和向量索引层,底层通过带副本的存储层保证数据持久化和高可用。
22.2.2 为什么需要专门的向量数据库?
一个自然的疑问是:为什么不直接用 NumPy 或 PyTorch 做暴力搜索?答案在于规模。
暴力搜索的复杂度。 给定
向量数据库通过索引算法将搜索范围从
下面用一段 Python 代码直观对比暴力搜索与 FAISS 索引搜索的性能差异:
import numpy as np
import time
# 构造数据:100万个128维向量
np.random.seed(42)
N, d = 1_000_000, 128
database = np.random.randn(N, d).astype("float32")
query = np.random.randn(1, d).astype("float32")
# === 暴力搜索 ===
start = time.time()
distances = np.linalg.norm(database - query, axis=1)
top_k_brute = np.argsort(distances)[:10]
brute_time = time.time() - start
print(f"暴力搜索耗时: {brute_time:.4f}s, Top-1 索引: {top_k_brute[0]}")
# === FAISS 索引搜索 ===
import faiss
index = faiss.IndexIVFFlat(
faiss.IndexFlatL2(d), # 量化器
d, # 向量维度
100 # 聚类中心数 nlist
)
index.train(database) # 训练聚类中心
index.add(database) # 添加数据
index.nprobe = 10 # 搜索时探查的聚类数
start = time.time()
D, I = index.search(query, 10) # 搜索 Top-10
faiss_time = time.time() - start
print(f"FAISS 搜索耗时: {faiss_time:.4f}s, Top-1 索引: {I[0][0]}")
print(f"加速比: {brute_time / faiss_time:.1f}x")在百万级数据上,FAISS 的 IVF 索引通常能带来 10-100 倍的加速,同时保持 95%+ 的召回率。
22.2.3 向量索引算法
向量索引算法是向量数据库的核心引擎。所有索引算法都在搜索速度、召回率(Recall)和内存占用三者之间做权衡——不存在三者同时最优的方案(暴力搜索除外,但它的搜索速度是
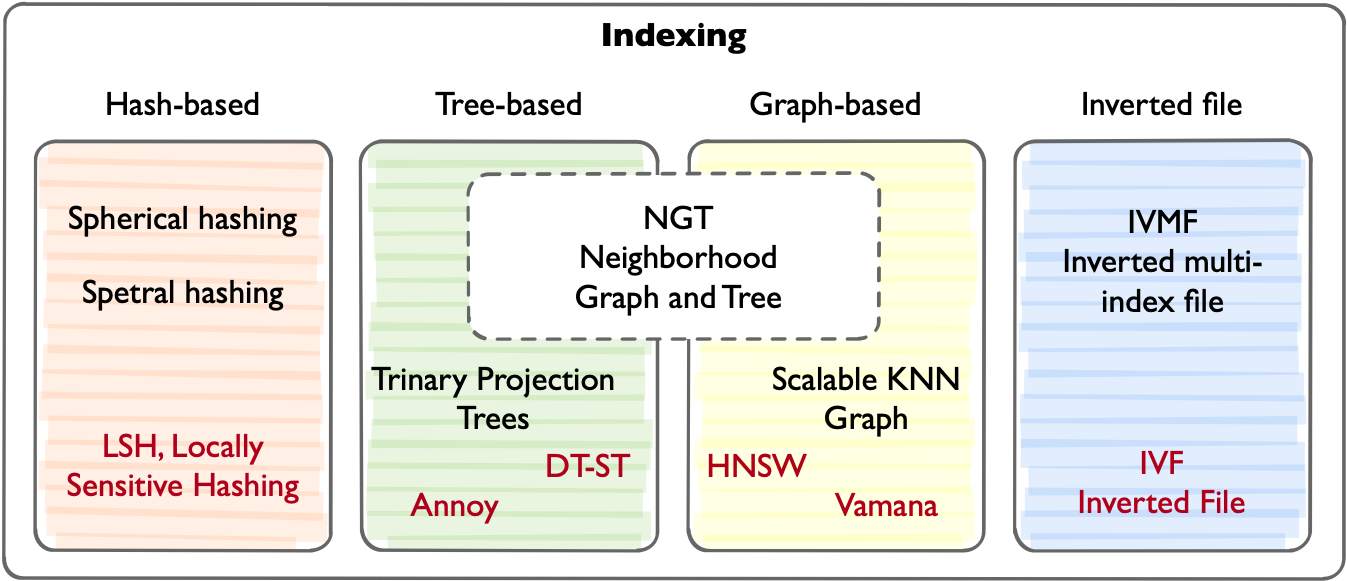
图 22-4:向量索引算法的分类全景。按数据结构可分为四大类:基于哈希(LSH 等)、基于树(Annoy 等)、基于图(HNSW、Vamana 等)和基于倒排文件(IVF 等)。工业实践中 HNSW 和 IVF 使用最为广泛。
下面按照从简单到复杂的顺序,逐一讲解四类主流索引算法。
A. 倒排文件索引(IVF, Inverted File Index)
IVF 的核心思想来自一个直觉:先用聚类缩小搜索范围,再在小范围内精确比较。
具体步骤如下:
- 训练阶段:用 K-Means 将
个向量聚为 个簇(Voronoi 单元),每个簇有一个聚类中心(centroid)。 - 构建倒排表:为每个聚类中心维护一个列表,记录属于该簇的所有向量 ID。
- 搜索阶段:对查询向量
,先计算 与 个聚类中心的距离,选出最近的 nprobe个簇,然后只在这些簇的向量中做精确比较。
搜索范围从 nprobe = 10 时,搜索量减少为原来的 1%。
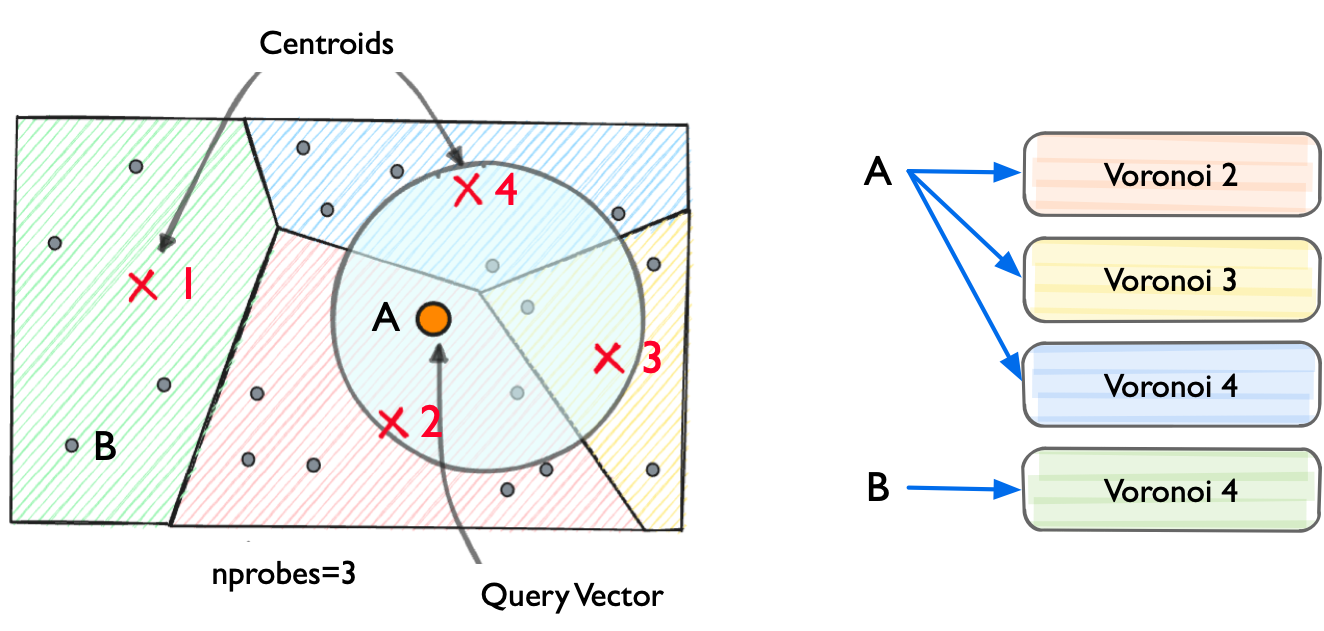
图 22-5:IVF 索引示意。左图展示了向量空间被 K-Means 划分为多个 Voronoi 单元(彩色区域),每个单元有一个聚类中心(红色 X)。查询向量(橙色点)首先定位到最近的 nprobe 个聚类中心(图中 nprobe=3),然后只在这些单元内进行精确搜索。右图展示了 A、B 两个不同查询分别探查的 Voronoi 单元。
IVF 的边界问题。 当查询向量恰好落在两个簇的边界附近时,真正的最近邻可能在"隔壁"簇中。增大 nprobe 可以缓解但会降低速度——这正是速度与召回率的经典权衡。
B. 分层可导航小世界图(HNSW, Hierarchical Navigable Small World)
HNSW 是目前工业界使用最广泛的向量索引算法之一。它的灵感来自小世界网络理论(六度分隔):在一个充分连接的图中,任意两点之间只需少量"跳转"即可到达。
HNSW 的核心设计分为两步:
构图阶段:
- 构建多层图结构。每一层是一个近似的小世界图(NSW),层数从高到低,节点数从少到多。
- 最底层(Layer 0)包含所有向量节点,构成完整图。
- 上层是下层的"稀疏快速通道":高层包含少量节点和长距离边(用于快速跨越大片空间),低层包含更多节点和短距离边(用于精确定位)。
- 每个节点在每层最多连接
个邻居。
搜索阶段:
- 从最高层的入口点开始。
- 在当前层中贪心搜索——沿着边移动到距离查询向量更近的邻居。
- 当在当前层无法继续接近时,下降一层,从同一节点继续搜索。
- 到达 Layer 0 后,返回找到的 Top-K 最近邻。
HNSW 的搜索复杂度为
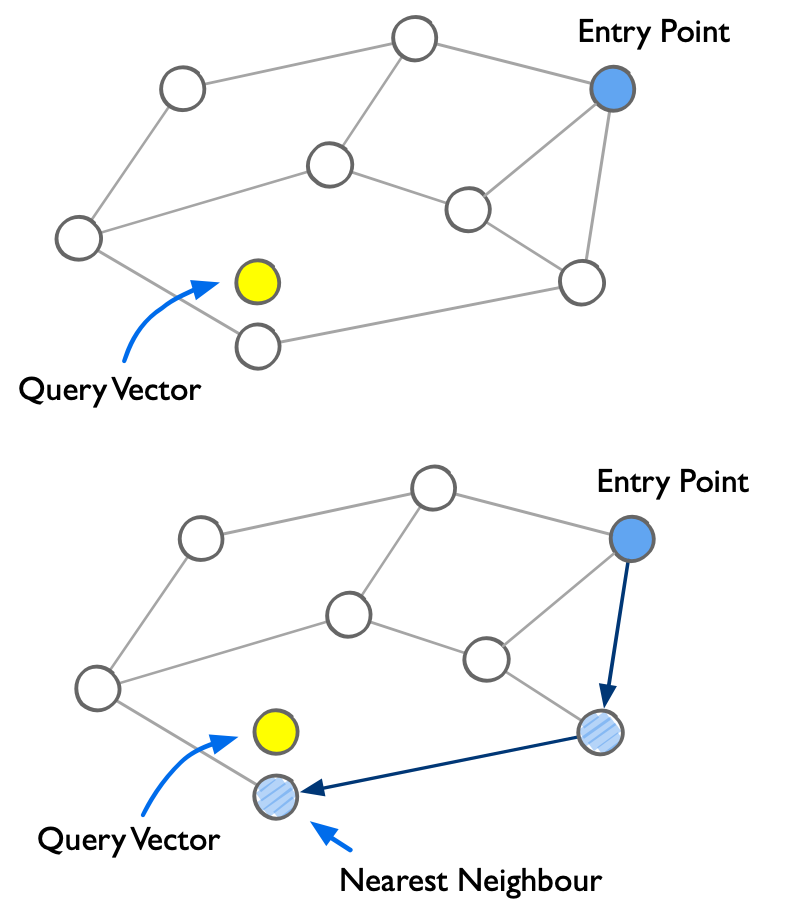
图 22-6:HNSW 搜索过程示意。上图展示了可导航小世界图(NSW)的基本结构——节点间通过边相连,查询向量(黄色点)需要在图中找到最近邻。下图展示贪心搜索过程:从入口点(蓝色)出发,沿着边逐步移向距离查询向量更近的节点(带阴影的节点为搜索路径),最终到达最近邻。
C. 局部敏感哈希(LSH, Locality-Sensitive Hashing)
LSH 的策略与前两者完全不同——它不构建树或图,而是用哈希函数将相似向量映射到同一个"桶"中。
核心原理:设计一族特殊的哈希函数,使得距离越近的向量,哈希碰撞的概率越高(这与传统哈希"尽量避免碰撞"的目标恰好相反)。搜索时,对查询向量计算哈希值,直接在对应桶中查找候选集。
最常用的 LSH 实现是随机投影(Random Projection):
- 生成多个随机超平面,将高维空间划分为多个区域。
- 每个向量根据它落在各超平面哪一侧,得到一个二进制编码(哈希值)。
- 编码相同的向量被分到同一个桶。
- 搜索时,查询向量的编码对应的桶就是候选集。
LSH 的优势是速度极快且可扩展(尤其在海量数据下),但召回率相对较低——因为落在不同桶中的相似向量会被遗漏。工程中通常使用多个独立的哈希表来提高召回率。
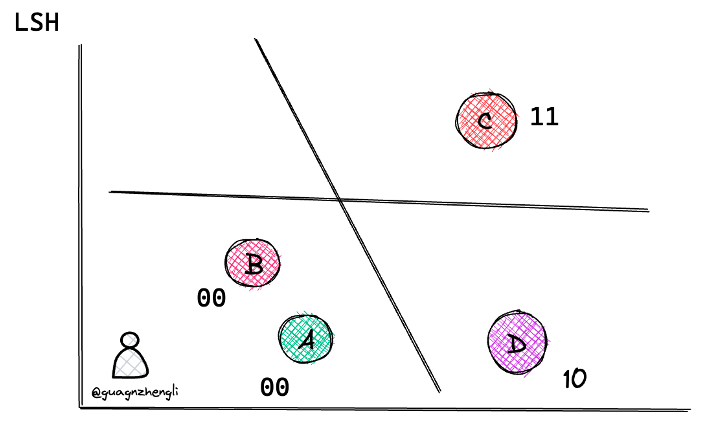
图 22-7:LSH 随机超平面划分示意。两条随机超平面(黑色线)将二维空间划分为四个区域,每个向量根据落在各超平面的哪一侧获得二进制编码(如 00、10、11)。编码相同的向量(如 A 和 B 均为 00)被认为是候选近邻。D(编码 10)与 C(编码 11)编码不同,因此不会被互相检索到。
D. 乘积量化(PQ, Product Quantization)
前面三种算法都在"如何组织搜索结构"上做文章。PQ 则从另一个角度切入——压缩向量本身,减少每次距离计算的开销和内存占用。
PQ 的核心思想:将一个
以 128 维向量为例:
- 切分为 8 个 16 维子向量。
- 每个子空间用 256 个聚类中心量化。
- 原本 128 个 float32 值(512 字节)被压缩为 8 个 uint8 编码(8 字节)——压缩比 64 倍。
搜索时,用查表法替代逐维计算:预先算好查询向量与每个子空间所有聚类中心的距离,存入查找表,然后对每个数据库向量只需做
PQ 通常不单独使用,而是与 IVF 组合成 IVF-PQ——IVF 缩小搜索范围,PQ 加速距离计算并节省内存。这是工业级向量数据库中最常见的组合策略。
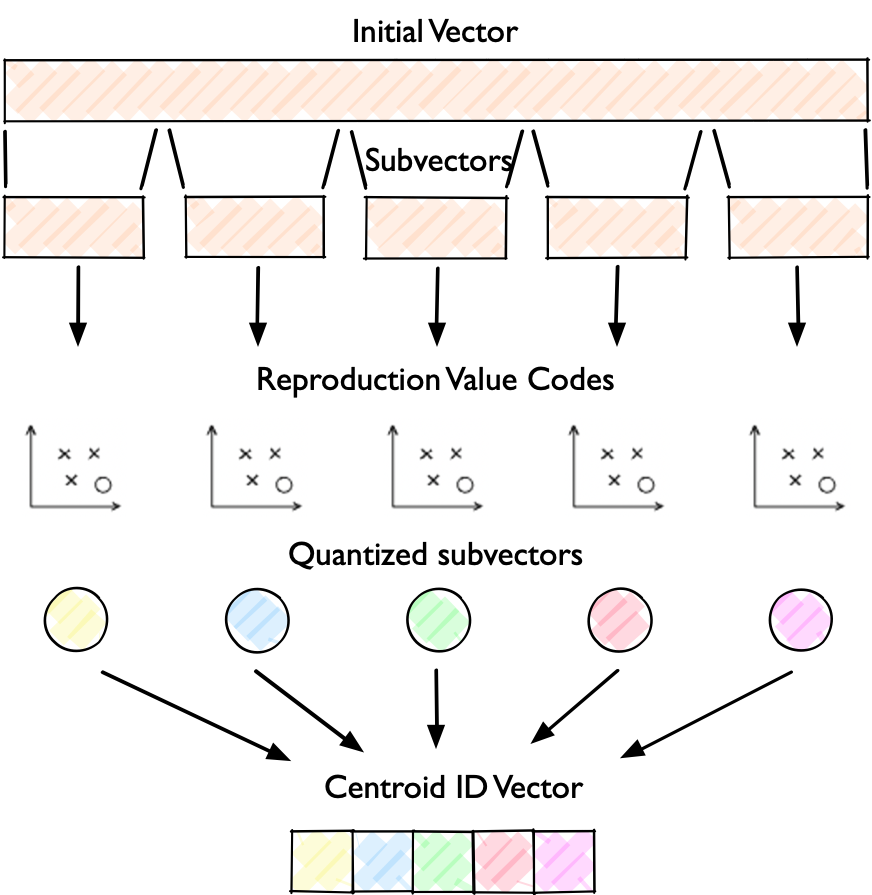
图 22-8:乘积量化(PQ)编码过程。一个完整的原始向量(Initial Vector)被切分为多个子向量(Subvector),每个子向量通过 K-Means 聚类得到 Reproduction Value Codes(量化码本),再映射为量化后的子向量(Quantized subvectors)。最终,每个子向量只需用一个聚类中心 ID 表示,组成极为紧凑的 Centroid ID Vector。
四类算法的横向对比:
| 算法 | 索引类型 | 搜索复杂度 | 召回率 | 内存占用 | 适用场景 |
|---|---|---|---|---|---|
| IVF | 聚类+倒排 | 高 | 中 | 中等规模,平衡场景 | |
| HNSW | 多层图 | 很高 | 高 | 高召回率、低延迟场景 | |
| LSH | 哈希桶 | 较低 | 中 | 海量数据、容忍低召回 | |
| PQ | 量化压缩 | 中 | 很低 | 内存受限、超大规模 | |
| IVF-PQ | 组合 | 中-高 | 低 | 工业级部署首选 |
22.2.4 相似度度量方法
索引算法解决了"如何高效搜索"的问题,而**相似度度量(Similarity Metric)**则定义了"什么叫相似"。选错度量方法,即使索引再快也会返回错误的结果。
A. 欧氏距离(L2 Distance)
最直观的度量方式——两点在空间中的直线距离:
- 特点:反映向量的绝对位置差异,同时受方向和长度(模长)影响。
- 适用场景:计算机视觉中的图像特征比较,因为图像特征的绝对量值通常有物理意义。
- 注意:如果两个向量方向相同但模长不同(如一个向量是另一个的 2 倍缩放),欧氏距离会认为它们"不相似"。
B. 余弦相似度(Cosine Similarity)
只关注两个向量的方向,忽略长度:
- 取值范围:
。 表示方向完全一致, 表示正交, 表示方向完全相反。 - 适用场景:NLP 中的语义搜索和文档分类。文本 Embedding 的模长通常与语义无关(更多取决于文本长度),因此用余弦相似度可以剥离长度干扰。
- 工程技巧:如果所有向量都预先做了 L2 归一化(
),余弦相似度退化为内积,且与欧氏距离单调等价。此时用 L2 索引搜索等价于余弦搜索,但避免了实时归一化的开销。
C. 内积(Inner Product / Dot Product)
- 特点:同时考虑方向和长度。内积越大,两个向量越"对齐"且模长越大。
- 适用场景:推荐系统中,用户向量和物品向量的内积直接表示"用户对该物品的偏好强度";最大内积搜索(MIPS, Maximum Inner Product Search)是推荐系统的核心操作。
- 注意:内积不是距离度量(不满足三角不等式),因此不能直接用于所有索引算法。FAISS 等库提供了专门的
IndexFlatIP来支持内积搜索。
三种度量的选择策略:
┌─ 特征模长有意义? ─ 是 → 欧氏距离 (L2)
│
如何选择度量方法? ──┤
│
└─ 特征模长无意义? ─ 是 ─┬─ 搜索"最相似" → 余弦相似度
│
└─ 搜索"最强匹配" → 内积 (IP)下面用代码演示三种度量在同一数据集上的行为差异:
import numpy as np
# 三个向量:A 和 B 方向相同但模长不同,C 方向不同
A = np.array([1.0, 2.0, 3.0])
B = np.array([2.0, 4.0, 6.0]) # A 的 2 倍
C = np.array([3.0, 1.0, 0.5]) # 方向不同
def l2_distance(x, y):
return np.sqrt(np.sum((x - y) ** 2))
def cosine_similarity(x, y):
return np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
def dot_product(x, y):
return np.dot(x, y)
print("=== A vs B(方向相同,模长不同)===")
print(f" L2 距离: {l2_distance(A, B):.4f}") # 较大(模长差异)
print(f" 余弦相似度: {cosine_similarity(A, B):.4f}") # = 1.0(方向完全一致)
print(f" 内积: {dot_product(A, B):.4f}") # 较大
print("\n=== A vs C(方向不同)===")
print(f" L2 距离: {l2_distance(A, C):.4f}") # 中等
print(f" 余弦相似度: {cosine_similarity(A, C):.4f}") # < 1(方向有差异)
print(f" 内积: {dot_product(A, C):.4f}") # 较小运行结果会清晰展示:余弦相似度完全忽略了 A 与 B 的模长差异(相似度 = 1.0),而欧氏距离则认为它们距离较远。选错度量会直接导致搜索结果失真。
22.2.5 元数据过滤(Metadata Filtering)
在实际业务中,我们很少需要对整个向量库做无差别搜索。例如,在一个多租户的企业知识库中,用户 A 的查询应该只在用户 A 的文档中搜索,而非跨越所有用户的数据。这就需要元数据过滤(Metadata Filtering)。
向量数据库通常维护两套索引:
- 向量索引(HNSW/IVF/PQ):负责近似最近邻搜索。
- 元数据索引(倒排索引/B-Tree):负责对
user_id、doc_type、timestamp等标量字段进行过滤。
过滤可以在搜索前或搜索后执行:
- Pre-filtering(前置过滤):先用元数据缩小候选集,再做向量搜索。优势是搜索空间小,但可能因为过度过滤而遗漏相关结果。
- Post-filtering(后置过滤):先做全量向量搜索得到 Top-K 候选,再用元数据条件筛选。优势是不遗漏,但如果过滤掉的比例很高,需要检索更多的 Top-K'(
)才能凑够 条结果。
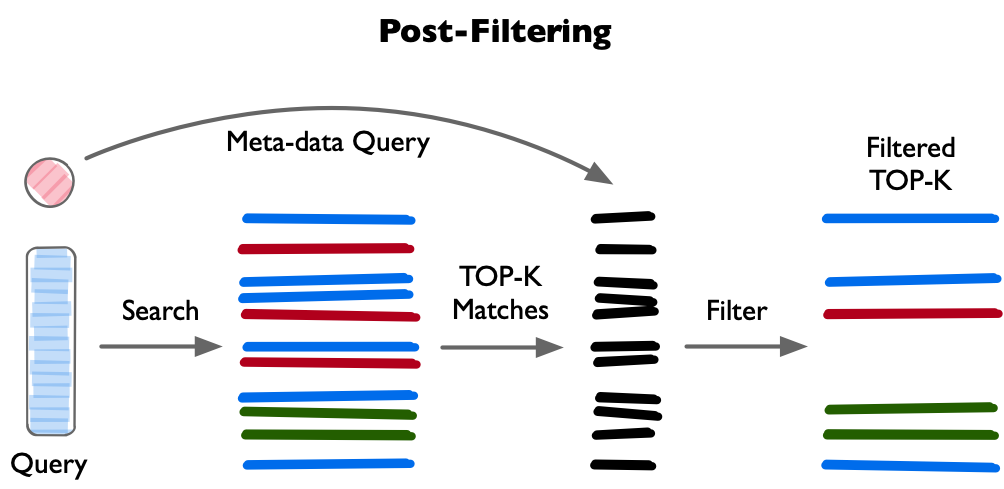
图 22-9a:Post-Filtering(后置过滤)。先对全量数据执行向量搜索得到 Top-K 候选(含多种颜色的条表示不同类别),再用元数据条件(Meta-data Query)过滤掉不符合条件的结果,最终得到 Filtered Top-K。缺点是当过滤比例高时需要检索更多候选。
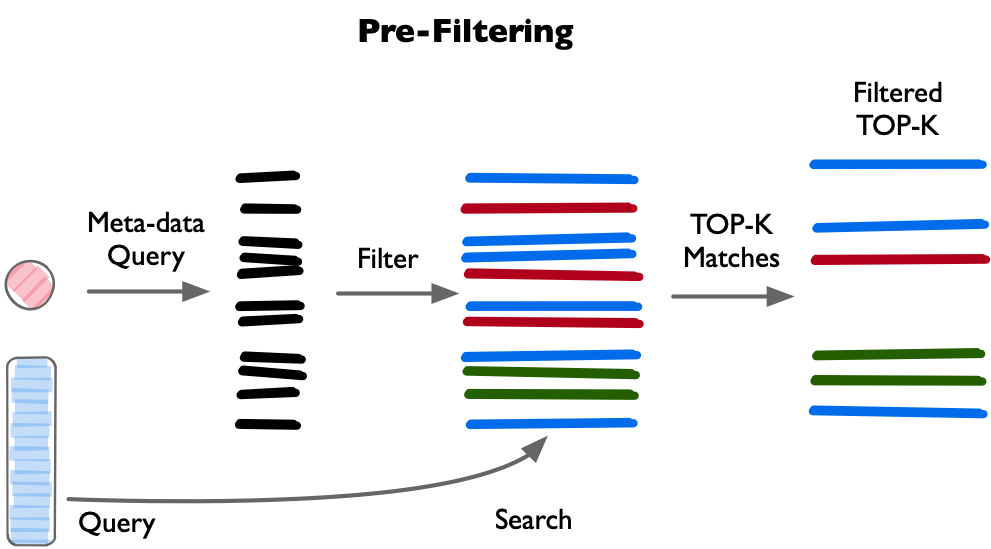
图 22-9b:Pre-Filtering(前置过滤)。先用元数据条件(Meta-data Query)筛选出符合条件的子集,再在子集上执行向量搜索得到 Top-K Matches,最终输出 Filtered Top-K。搜索空间更小、速度更快,但可能因过度过滤而遗漏边界附近的相关结果。
工程实践中,大多数向量数据库(Milvus、Qdrant、Weaviate)都支持将两者结合的混合过滤策略,由查询优化器根据过滤条件的选择性自动选择最优执行路径。
22.2.6 向量数据库的架构设计
一个生产级向量数据库的架构远不止"存向量 + 建索引"这么简单。它需要处理数据持久化、分布式扩展、实时更新、容灾备份等一系列工程问题。下面以通用架构为脉络进行讲解。
四层架构模型:
┌─────────────────────────────────────────────────┐
│ 接入层(Access Layer) │
│ REST API / gRPC / SDK (Python, Java, Go) │
├─────────────────────────────────────────────────┤
│ 协调层(Coordinator) │
│ 查询路由、负载均衡、分布式事务 │
├─────────────────────────────────────────────────┤
│ 计算层(Worker Nodes) │
│ 索引构建(HNSW/IVF/PQ) + 相似度计算 + 过滤 │
│ SIMD 加速 / GPU 加速 │
├─────────────────────────────────────────────────┤
│ 存储层(Storage) │
│ 向量数据 + 元数据 + WAL日志 + 对象存储 │
│ 分片(Sharding) + 多副本(Replica) │
└─────────────────────────────────────────────────┘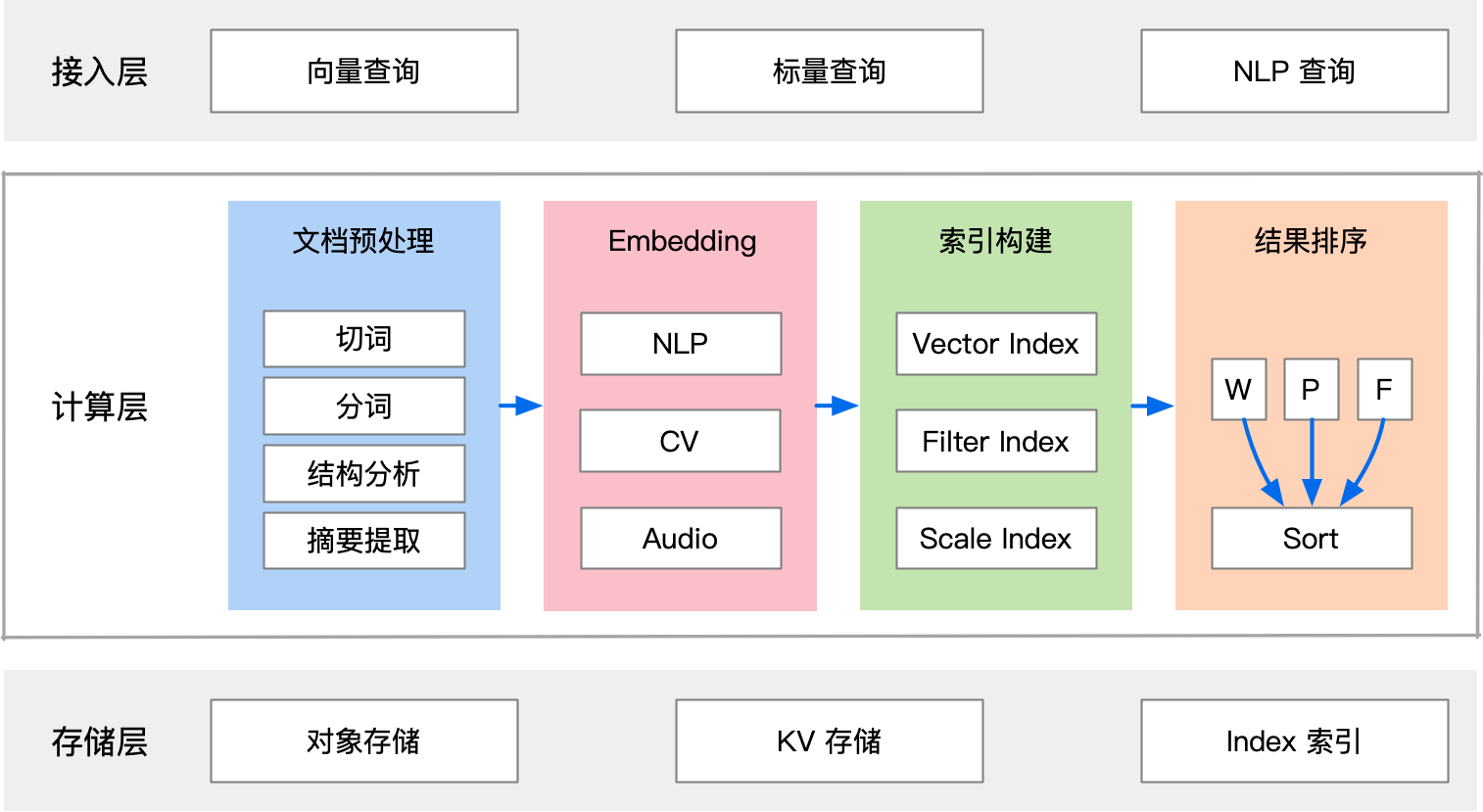
图 22-10:向量数据库三层架构详细设计。接入层支持向量查询、标量查询和 NLP 查询;计算层包括文档预处理(切词、分词、结构分析、摘要提取)、Embedding(NLP/CV/Audio)、索引构建(Vector Index、Filter Index、Scale Index)和结果排序;存储层包括对象存储、KV 存储和 Index 索引。
各层的职责:
接入层:提供 API 网关,将用户的写入请求(Insert/Update/Delete)和查询请求(Search/Query)路由到后端集群。无状态设计,可水平扩展。
协调层:集群的"大脑",负责分片调度(将数据按 hash 或 range 分配到不同节点)、查询规划(将一次查询拆分为多个子查询下发到各分片)和结果聚合(合并各分片的 Top-K 结果,取全局 Top-K)。
计算层:执行具体的索引构建和搜索计算。关键优化包括:
- SIMD 指令加速:利用 AVX2/AVX-512 等 CPU 向量指令集加速距离计算。
- 列式存储:将向量数据按维度方向连续存放,提高缓存命中率。
- 多级缓存:热点数据常驻内存,冷数据存储在 SSD/对象存储。
存储层:负责数据持久化和容灾。通常采用 WAL(Write-Ahead Log)保证写入的原子性和持久性,数据分片存储在多副本上实现高可用。
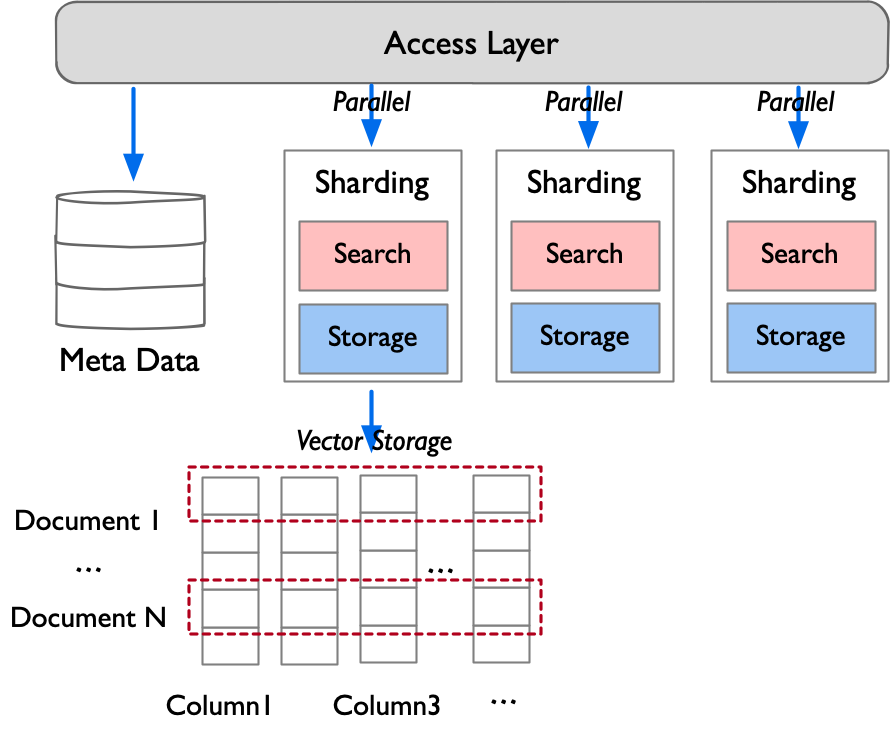
图 22-11:向量数据库分布式部署架构。接入层(Access Layer)将请求并行分发到多个分片(Sharding),每个分片独立承担搜索(Search)和存储(Storage)职责。元数据(Meta Data)单独管理。底层的向量存储采用列式布局(Column1, Column3, ...),将同一维度的数据连续存放以提高缓存命中率。
Milvus 架构示例。 Milvus 是目前最成熟的开源向量数据库之一,采用存算分离架构:
- 访问层(Proxy):无状态代理,处理客户端连接和请求验证。
- 协调服务:分为 Root Coord(元数据管理)、Data Coord(数据分配)、Query Coord(查询调度)和 Index Coord(索引管理),各司其职。
- 工作节点:分为 Data Node(负责数据写入和持久化)、Query Node(负责搜索查询)和 Index Node(负责后台索引构建)。
- 存储层:元数据存储在 etcd,日志流存储在 Pulsar/Kafka,向量数据存储在 MinIO/S3 等对象存储。
这种存算分离的设计使得各组件可以独立扩缩容:写入压力大时增加 Data Node,查询并发高时增加 Query Node,而存储容量只需扩展对象存储。
22.2.7 主流向量数据库横向对比
面对众多向量数据库产品,如何选型?以下从几个关键维度进行对比:
| 产品 | 开源 | 支持索引 | 分布式 | 混合搜索 | 托管服务 | 适用场景 |
|---|---|---|---|---|---|---|
| FAISS | 是(库) | Flat, IVF, HNSW, PQ | 否 | 否 | 否 | 研究实验、嵌入应用 |
| Milvus | 是 | Flat, IVF, HNSW, DiskANN | 是 | 是 | Zilliz Cloud | 大规模生产部署 |
| Qdrant | 是 | 定制 HNSW | 是 | 是 | Qdrant Cloud | 高性能在线服务 |
| Weaviate | 是 | HNSW, HNSW+PQ | 是 | 是 | Weaviate Cloud | 多模态搜索 |
| Pinecone | 否 | 专有复合索引 | 是 | 是 | 全托管 | 快速上手、无运维 |
| Chroma | 是 | HNSW | 否 | 否 | 否 | 轻量原型、本地开发 |
| pgvector | 是 | IVF, HNSW | 依赖 PG | 是 | 各 PG 云 | 已有 PG 基础设施 |
选型建议:
- 原型验证阶段:Chroma(零配置,pip 安装即用)或 FAISS(纯 Python 集成)。
- 生产部署、需要分布式:Milvus(功能最全)或 Qdrant(API 设计优雅、性能优异)。
- 不想自运维:Pinecone(全托管 SaaS)。
- 已有 PostgreSQL 基础设施:pgvector(作为 PG 扩展,无需引入新系统)。
下面用 Chroma 演示一个最小化的向量数据库使用示例:
import chromadb
# 创建内存模式的 Chroma 客户端
client = chromadb.Client()
# 创建集合(Collection = 向量数据库中的"表")
collection = client.create_collection(
name="demo_docs",
metadata={"hnsw:space": "cosine"} # 使用余弦相似度
)
# 插入文档(Chroma 内置 Embedding 模型,自动向量化)
collection.add(
documents=[
"向量数据库是专为高维向量设计的数据库系统",
"HNSW 算法通过分层图结构实现高效近似搜索",
"RAG 将检索与生成结合提升大模型回答质量",
"Transformer 的自注意力机制是现代 NLP 的基石",
],
ids=["doc1", "doc2", "doc3", "doc4"],
metadatas=[
{"topic": "database"},
{"topic": "algorithm"},
{"topic": "rag"},
{"topic": "model"},
],
)
# 查询:语义搜索 + 元数据过滤
results = collection.query(
query_texts=["如何快速检索相似文本"],
n_results=2,
where={"topic": {"$in": ["database", "algorithm", "rag"]}},
)
print("查询结果:")
for doc, dist in zip(results["documents"][0], results["distances"][0]):
print(f" [{dist:.4f}] {doc}")这段代码展示了向量数据库的完整使用流程:创建集合、写入数据、语义搜索、元数据过滤——全程不到 30 行代码。
22.2.8 向量数据库在大模型生态中的角色
向量数据库在大模型生态中扮演着多重角色,远不止"给 RAG 提供检索"这么简单:
1. 知识增强(Knowledge Augmentation)。 这是最核心的应用场景。将企业私域文档、产品手册、FAQ 等知识切分为 chunks,Embedding 后存入向量数据库。用户提问时,先从向量库中检索相关 chunks,拼接进 Prompt 送给 LLM。这种方式无需微调模型即可让 LLM 回答领域特定问题,且知识可实时更新。
2. 语义缓存(Semantic Cache)。 对于高频出现的相似问题,可以将问题-回答对缓存在向量数据库中。新问题到来时,先在缓存中搜索语义相似的历史问题,如果相似度超过阈值则直接返回缓存答案,避免重复调用 LLM,显著降低推理成本。
3. Agent 长期记忆(Long-term Memory)。 LLM 的上下文窗口有限,无法记住所有历史对话和用户偏好。向量数据库可以作为 Agent 的外部长期记忆——将对话摘要、用户画像、历史决策等信息向量化存储,在每次对话开始时检索相关记忆注入上下文,实现跨会话的"记忆力"。
4. 多模态检索。 借助多模态 Embedding 模型(如 CLIP),图像、音频和文本可以被映射到同一个向量空间。向量数据库因此成为多模态检索的统一后端——用文本搜图像、用图像搜视频、用语音搜文档,都可以通过同一个向量检索接口实现。
本节小结。 向量数据库是连接 Embedding 模型与下游应用的关键基础设施。它的核心能力是在海量高维向量中高效执行近似最近邻搜索。索引算法(IVF、HNSW、LSH、PQ)在速度、召回率和内存之间做权衡;相似度度量(L2、余弦、内积)定义了"相似"的含义,必须根据数据特性正确选择;架构设计需要处理分布式、持久化、实时更新等工程问题。在大模型生态中,向量数据库承担着知识增强、语义缓存、Agent 记忆和多模态检索等多重职责。理解这些基础,将为下一节深入 RAG 的检索策略与优化打下坚实的地基。