2.3 注意力机制
在序列建模任务中,模型需要判断"当前应该关注哪里"。传统的循环网络将整个输入序列压缩为一个固定长度的上下文向量,当序列较长时,早期的信息不可避免地被稀释甚至丢失。注意力机制(Attention Mechanism)的核心思想是:不再依赖单一的压缩表示,而是让模型在每一步都能动态地、有选择地"回看"输入序列的所有位置,根据当前需求为不同位置分配不同的权重。这一思想最终发展为 Transformer 架构的基石,彻底改变了自然语言处理乃至整个深度学习的面貌。
本节将从注意力机制的基本框架出发,依次介绍 Query-Key-Value 抽象、三种主要的注意力计分函数、Bahdanau 注意力的历史背景,以及 Transformer 中最核心的多头注意力设计。
2.3.1 Query-Key-Value 框架
注意力机制可以用一个统一的抽象来描述:查询(Query)、键(Key) 和 值(Value)。
一个直观的比喻是:想象你走进一家自助餐厅。你带着个人口味偏好(Query)去审视每道菜的标签和外观(Key),根据匹配程度决定拿取多少(注意力权重),最终盘子里装的是实际的食物(Value)的加权组合。
形式化地,设有一组键值对
- 计算注意力分数:用某种评分函数
衡量查询与每个键的匹配程度,得到原始分数 。 - 归一化为权重:通过 softmax 将分数转化为概率分布,即
,确保所有权重非负且和为 1。 - 加权汇聚:用权重对值进行加权求和,得到注意力输出
。
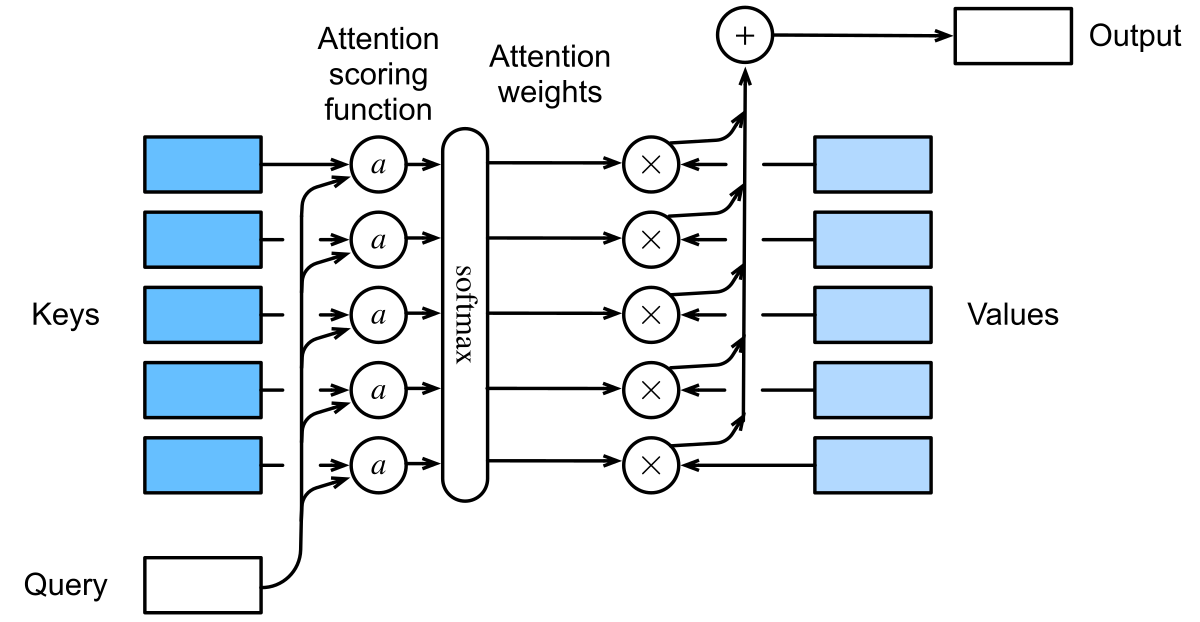
图 2-6:注意力机制的计算流程。查询(Query)与每个键(Key)计算注意力分数,经 softmax 归一化后作为权重对值(Value)进行加权求和,得到最终输出。
整个过程可以简洁地表达为:
其中
2.3.2 注意力计分函数
评分函数
加性注意力(Additive Attention)。 也称为 Bahdanau 注意力中使用的计分方式。它通过一个前馈网络来学习查询与键之间的匹配关系:
其中
点积注意力(Dot-Product Attention)。 当查询和键的维度相同(
点积的几何意义是衡量两个向量的方向一致性:方向越一致,点积越大,注意力权重越高。点积注意力无需额外参数,计算效率高,且能够充分利用矩阵乘法的硬件加速优势。
缩放点积注意力(Scaled Dot-Product Attention)。 纯点积注意力存在一个隐患:当向量维度
为此,Vaswani 等人(2017)在 "Attention Is All You Need" 中提出了除以
缩放后,点积的方差被重新归一化为 1,softmax 的输入维持在合理范围内,梯度更加稳定。这就是 缩放点积注意力,也是现代 Transformer 中的标准选择。
将上述公式推广到矩阵形式——设查询矩阵
其中
三种计分函数的对比如下:
| 计分函数 | 公式 | 额外参数 | 适用场景 |
|---|---|---|---|
| 加性注意力 | |||
| 点积注意力 | 无 | 低维场景 | |
| 缩放点积注意力 | 无 | Transformer 标准选择 |
表 2-3:三种注意力计分函数的对比。
2.3.3 Bahdanau 注意力
注意力机制的概念在 Bahdanau 等人(2015)的工作中被首次系统地引入到序列到序列模型中。在传统的编码器-解码器架构中,编码器将输入序列
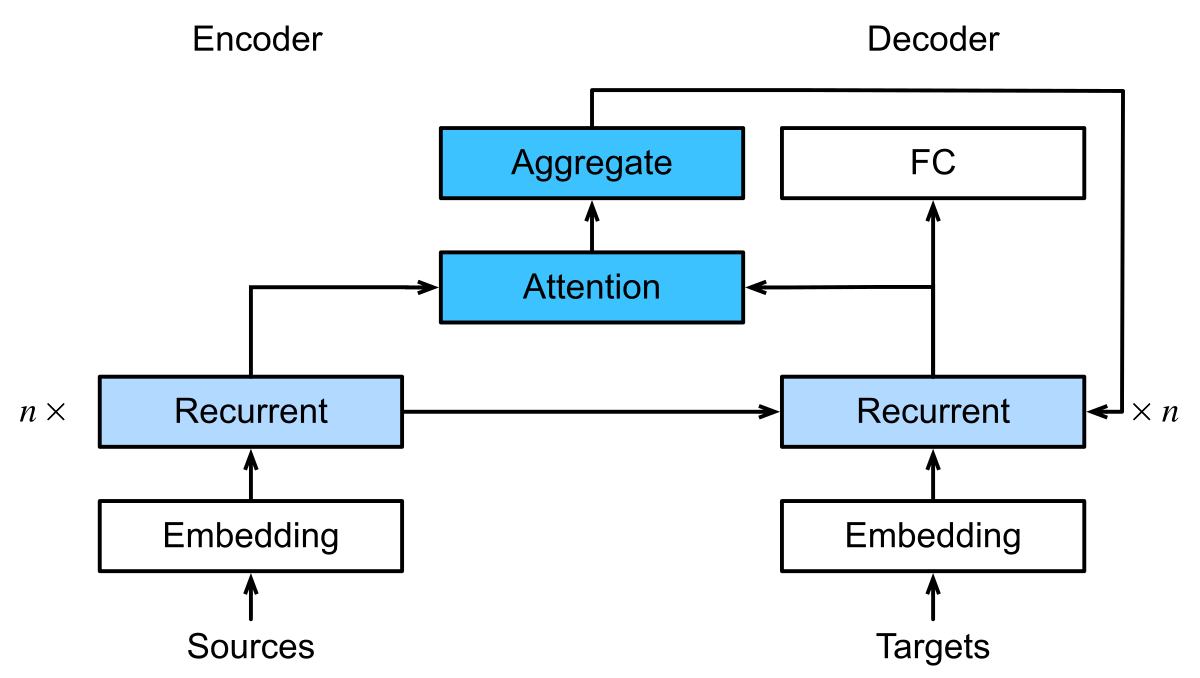
图 2-7:带有注意力机制的编码器-解码器架构(Bahdanau 注意力)。解码器在每一步生成输出时,不再仅依赖固定的上下文向量,而是通过注意力机制动态地关注编码器各位置的隐状态,生成当前步特有的上下文向量。
Bahdanau 注意力的核心改进是:为解码器的每一步生成一个专属的上下文向量。具体而言,设编码器在位置
最终,上下文向量
Bahdanau 注意力属于交叉注意力(Cross-Attention)的范畴——查询来自解码器,键和值来自编码器,是两个不同序列之间的注意力交互。这与后来 Transformer 中的自注意力(Self-Attention)有本质区别:自注意力中,查询、键和值都来自同一个序列内部,每个位置都在与同序列的其他位置(包括自身)进行交互。
从 QKV 框架的视角来看,Bahdanau 注意力使用的是加性计分函数,且键和值是共享的(都是编码器隐状态)。虽然加性计分函数的表达能力强,但由于涉及额外的可学习参数矩阵和非线性运算,在序列长度较大时计算效率不如点积方式。这也是 Transformer 最终采用缩放点积注意力的重要原因之一。
2.3.4 自注意力与矩阵运算
在 Transformer 架构中,注意力机制被应用于一种全新的场景——自注意力(Self-Attention)。不同于 Bahdanau 注意力中查询和键分属不同序列,自注意力中查询、键和值都从同一个输入序列派生而来。每个位置的 token 都在与序列中所有其他位置(包括自身)进行交互,从而根据上下文动态更新自身的表示。
以句子"我爱吃苹果"为例。对于"苹果"这个 token,我们希望它能注意到"吃"这个词,从而理解这里的"苹果"是水果而非品牌。自注意力正是通过让每个 token 携带的查询向量与所有 token 的键向量进行匹配来实现这一点。
具体地,设输入序列的嵌入矩阵为
其中
这个过程可以完全通过矩阵乘法实现,没有任何循环依赖——所有 token 的注意力更新可以同步并行计算,这正是 Transformer 能够充分利用 GPU 并行能力的关键优势。
在注意力矩阵
Mask 机制。 在实际应用中,注意力计算往往需要配合掩码(Mask)。例如在自回归语言模型中,第
2.3.5 多头注意力
单一的注意力函数只能从一种"视角"捕捉序列内的依赖关系。然而在自然语言中,一个词可能同时承载多种维度的信息——句法角色、语义关联、单复数、时态等。如果只用一组 Q、K、V 进行注意力计算,很难同时捕捉所有这些层面的关系。
多头注意力(Multi-Head Attention)的思想是:与其用一个"大注意力"做所有事情,不如将查询、键和值分别投影到
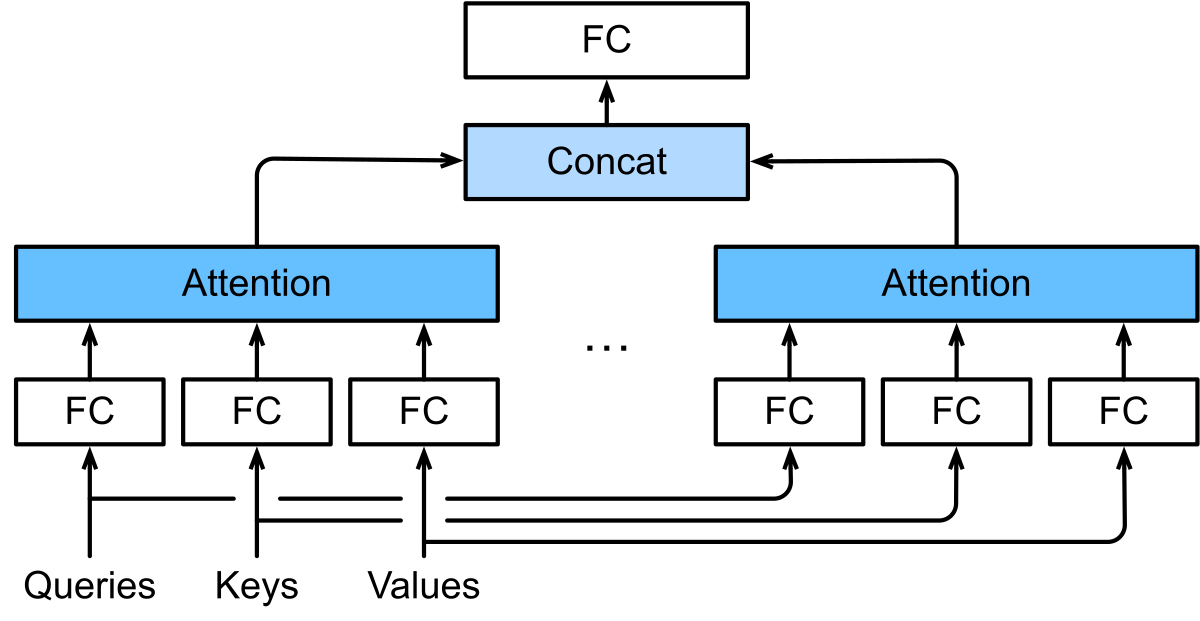
图 2-8:多头注意力机制。输入的 Q、K、V 经线性投影后分成多个头,各头独立执行缩放点积注意力,最后拼接并通过线性变换得到最终输出。
形式化地,给定查询
其中
所有头的输出拼接后,再通过一个线性变换映射回原始维度:
其中
展开完整的计算过程:以
多头注意力的关键优势在于:不同的头可以自发地学习到不同类型的注意力模式。研究者通过可视化发现,部分头倾向于捕捉局部的相邻词依赖,部分头关注长距离的语法结构,还有一些头会聚焦于特定的语义角色。这种"分工合作"机制使得 Transformer 的表达能力远超单头注意力。
2.3.6 PyTorch 实现
以下提供一个自包含的 PyTorch 实现,涵盖缩放点积注意力和多头注意力。
import torch
import torch.nn as nn
import math
def scaled_dot_product_attention(
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor | None = None,
dropout: nn.Dropout | None = None,
) -> tuple[torch.Tensor, torch.Tensor]:
"""缩放点积注意力。
Args:
query: 形状 (batch, ..., seq_q, d_k)
key: 形状 (batch, ..., seq_k, d_k)
value: 形状 (batch, ..., seq_k, d_v)
mask: 可选,形状可广播至 (batch, ..., seq_q, seq_k),
值为 0 的位置将被屏蔽
dropout: 可选的 Dropout 层,作用于注意力权重
Returns:
output: 形状 (batch, ..., seq_q, d_v)
attn_weights: 形状 (batch, ..., seq_q, seq_k)
"""
d_k = query.size(-1)
# (batch, ..., seq_q, seq_k)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attn_weights = torch.softmax(scores, dim=-1)
if dropout is not None:
attn_weights = dropout(attn_weights)
output = torch.matmul(attn_weights, value)
return output, attn_weights
class MultiHeadAttention(nn.Module):
"""多头注意力模块。
Args:
d_model: 模型隐藏维度
num_heads: 注意力头数
dropout: 注意力权重的 dropout 概率
bias: 线性投影是否包含偏置项
"""
def __init__(
self,
d_model: int,
num_heads: int,
dropout: float = 0.0,
bias: bool = False,
):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
self.W_q = nn.Linear(d_model, d_model, bias=bias)
self.W_k = nn.Linear(d_model, d_model, bias=bias)
self.W_v = nn.Linear(d_model, d_model, bias=bias)
self.W_o = nn.Linear(d_model, d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0 else None
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor | None = None,
) -> torch.Tensor:
"""
Args:
query: (batch, seq_q, d_model)
key: (batch, seq_k, d_model)
value: (batch, seq_k, d_model)
mask: 可选,(batch, 1, seq_q, seq_k) 或可广播形状
Returns:
output: (batch, seq_q, d_model)
"""
batch_size = query.size(0)
# 线性投影: (batch, seq, d_model) -> (batch, seq, d_model)
Q = self.W_q(query)
K = self.W_k(key)
V = self.W_v(value)
# 拆分多头: (batch, seq, d_model) -> (batch, num_heads, seq, d_k)
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 缩放点积注意力: (batch, num_heads, seq_q, d_k)
output, _ = scaled_dot_product_attention(Q, K, V, mask, self.dropout)
# 合并多头: (batch, num_heads, seq_q, d_k) -> (batch, seq_q, d_model)
output = (
output.transpose(1, 2)
.contiguous()
.view(batch_size, -1, self.d_model)
)
# 输出投影
return self.W_o(output)代码解读。 scaled_dot_product_attention 函数实现了标准的缩放点积注意力:计算 MultiHeadAttention 类在此基础上实现了多头机制:通过四个线性层分别生成 Q、K、V 和输出投影,利用 view 和 transpose 操作将 (batch, seq, d_model) 重塑为 (batch, num_heads, seq, d_k) 以实现多头的并行计算,最后再拼接回原始维度。
可以用以下代码快速验证:
# 验证多头注意力的输入输出形状
batch_size, seq_len, d_model, num_heads = 2, 10, 512, 8
mha = MultiHeadAttention(d_model, num_heads, dropout=0.1)
x = torch.randn(batch_size, seq_len, d_model)
output = mha(x, x, x) # 自注意力: Q=K=V=x
print(output.shape) # torch.Size([2, 10, 512])当 query、key、value 传入相同的张量时,这就是自注意力;当 query 来自解码器、key 和 value 来自编码器时,这就是交叉注意力。同一个 MultiHeadAttention 类可以同时支持这两种用法。
本节小结
本节系统介绍了注意力机制的核心概念和实现:
- QKV 框架 是注意力机制的统一抽象:查询与键计算匹配分数,softmax 归一化为权重后对值加权求和。
- 三种计分函数 各有适用场景:加性注意力灵活但较慢,点积注意力高效但高维时不稳定,缩放点积注意力通过除以
解决了方差问题,成为 Transformer 的标准选择。 - Bahdanau 注意力 首次将注意力机制引入序列到序列模型,让解码器在每一步动态关注编码器的不同位置,突破了固定长度上下文向量的瓶颈。
- 自注意力 让序列内部的 token 互相交互,可以完全通过矩阵运算并行计算,是 Transformer 摒弃循环结构的关键。
- 多头注意力 通过在多个子空间中独立执行注意力计算,使模型能够同时捕捉不同类型的依赖关系——局部语法、长距离语义、句法结构等——大幅增强了模型的表达能力。
这些概念共同构成了 Transformer 架构的注意力基础。下一节将在此基础上,完整介绍 Transformer 的编码器-解码器结构、位置编码、层归一化等组件,展示这些零件如何组装成一个完整的模型。