17.3 采样多样性控制
上一节介绍了思维链提示如何通过"让模型一步一步地思考"来提升推理准确率。然而,要让 CoT 与自一致性(Self-Consistency)等技术真正发挥威力,有一个不可或缺的前提:模型必须能够对同一个问题生成多条不同的推理路径。 如果每次生成的答案都完全相同——如贪心解码(Greedy Decoding)所做的那样——就无法通过多数投票来筛选最优答案。
这就引出了本节的核心主题:采样多样性控制。我们将依次讨论温度缩放(Temperature Scaling)、Top-k 采样和 Top-p(Nucleus)采样三种技术,理解它们如何在"确定性"与"多样性"之间精确调节,以及如何将它们组合应用于推理场景。
17.3.1 从贪心到随机:理解 Token 选择过程
在深入采样策略之前,先回顾一下模型是如何选择下一个 Token 的。给定输入序列,语言模型的最后一层会输出一个与词表大小相同的向量,称为 logits(对数值)。每个元素对应词表中某个 Token 的"得分"——得分越高,模型认为该 Token 出现在此位置的可能性越大。
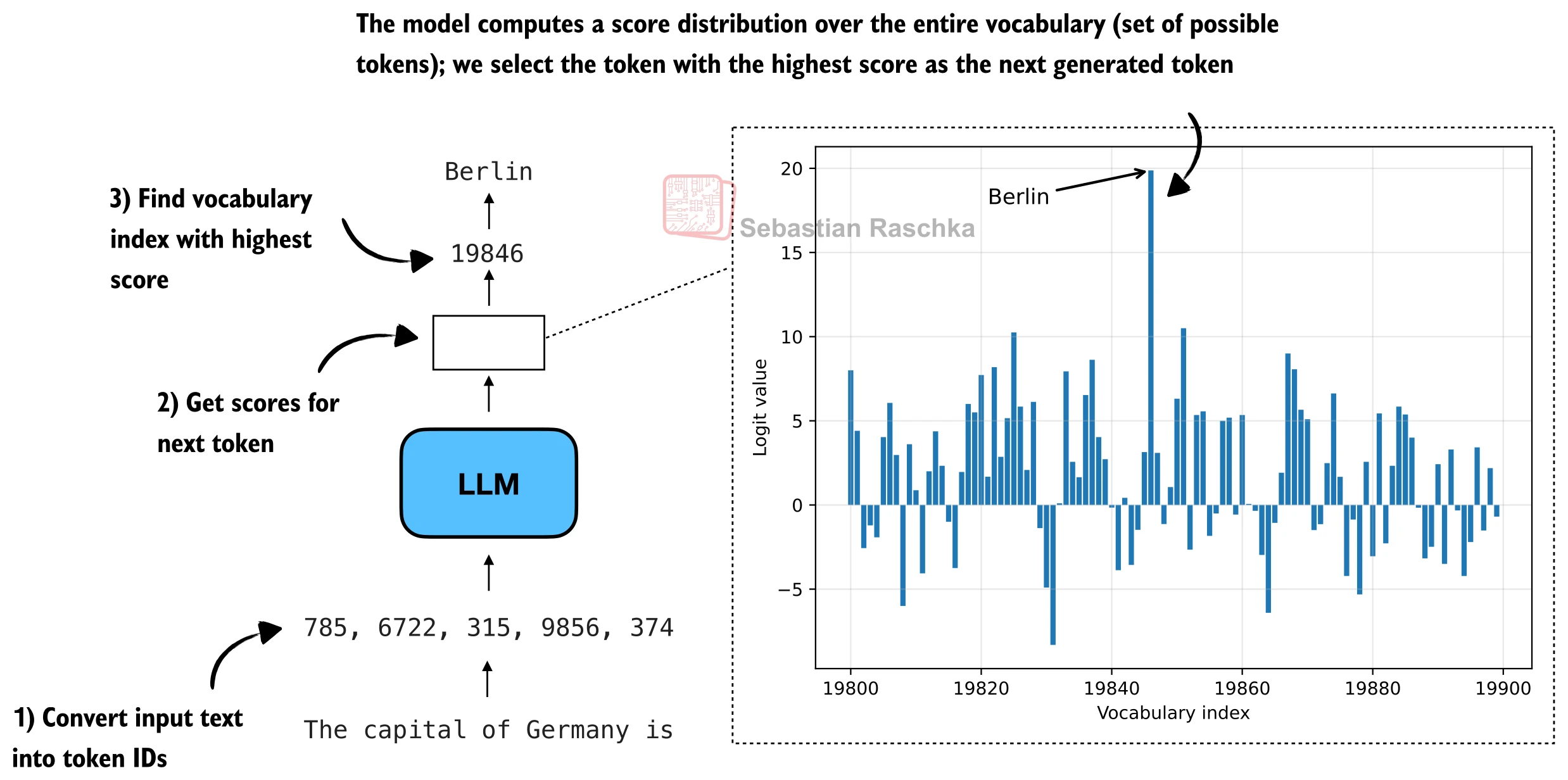
图 17-5:下一个 Token 的选择流程。模型接收输入序列,输出词表大小的 logits 向量,通过 argmax 选择得分最高的 Token 作为下一个输出。
贪心解码(Greedy Decoding) 是最简单的策略:直接取 logits 中最大值对应的 Token。这种策略是确定性的——相同输入永远产出相同输出。对于事实性问答等场景,这种确定性是优势;但对于需要多样化输出的推理场景,它成了障碍。
import torch
# 假设 logits 是模型对 9 个候选 Token 的得分
logits = torch.tensor([4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79])
vocab = ["closer", "every", "effort", "forward", "inches", "moves", "pizza", "toward", "you"]
# 贪心解码:总是选择得分最高的 Token
greedy_token = vocab[torch.argmax(logits).item()]
print(f"贪心解码选择: {greedy_token}") # 输出: forward随机采样(Stochastic Sampling) 则将 logits 转换为概率分布,然后按概率抽样。这引入了随机性,使每次生成的结果可能不同:
# 示意代码(承接上方代码块中的 logits 和 vocab)
probas = torch.softmax(logits, dim=0)
# 随机采样:按概率抽取
torch.manual_seed(42)
sampled_token = vocab[torch.multinomial(probas, num_samples=1).item()]
print(f"随机采样选择: {sampled_token}") # 可能输出: forward 或 toward在这个例子中,"forward" 和 "toward" 的概率分别约为 57.8% 和 36.1%,合计超过 93%。随机采样大概率选中它们之一,但也有小概率选到 "pizza" 这样的低概率 Token——这就是纯随机采样的问题:它允许非常不合理的 Token 被选中。温度缩放和 Top-k/Top-p 采样正是为了解决这一问题。
17.3.2 温度缩放(Temperature Scaling)
温度缩放的本质极为简单:在将 logits 传入 softmax 之前,先除以一个正数
其中
图 17-6:温度缩放的效果。低温(T=0.5)使 logits 差异放大,分布更尖锐;高温(T=5.0)使 logits 差异缩小,分布更平坦。
温度参数的直觉可以用"信心调节器"来理解:
| 温度 | 效果 | 类比 |
|---|---|---|
| 概率集中在最高分 Token,趋近贪心解码 | 极其自信,只选"最好的" | |
| 保持原始 logits 不变 | 原样输出模型的判断 | |
| 概率分布变平坦,低分 Token 也有机会被选中 | 放宽标准,愿意尝试 | |
| 趋近均匀分布,完全随机选择 | 完全放弃偏好,随机抽签 |
下面通过代码可视化温度对采样分布的影响:
import torch
import matplotlib.pyplot as plt
def softmax_with_temperature(logits, temperature):
"""对 logits 进行温度缩放后计算 softmax"""
return torch.softmax(logits / temperature, dim=0)
# 9 个候选词的 logits
logits = torch.tensor([4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79])
vocab = ["closer", "every", "effort", "forward", "inches", "moves", "pizza", "toward", "you"]
# 三种温度下的概率分布
temperatures = [0.1, 1.0, 5.0]
fig, axes = plt.subplots(1, 3, figsize=(14, 4), sharey=True)
for ax, T in zip(axes, temperatures):
probas = softmax_with_temperature(logits, T)
bars = ax.bar(range(len(vocab)), probas.numpy())
ax.set_title(f"Temperature = {T}", fontsize=13)
ax.set_xticks(range(len(vocab)))
ax.set_xticklabels(vocab, rotation=45, ha="right")
ax.set_ylim(0, 1.05)
# 高亮最大概率的柱子
max_idx = torch.argmax(probas).item()
bars[max_idx].set_color("darkorange")
axes[0].set_ylabel("Probability")
plt.tight_layout()
plt.show()运行上述代码可以直观观察到:当 "forward" 的概率接近 1.0(其他词几乎为 0);当 "forward" 和 "toward" 各占约 58% 和 36%;当 "pizza" 也有约 3% 的机会被选中。
推理场景中温度的选择。 在推理模型和数学推理任务中,温度的选择需要在准确性和多样性之间权衡。DeepSeek-R1 等推理模型的推荐温度为
17.3.3 Top-k 采样
温度缩放调节了概率分布的"陡峭程度",但即使在适中的温度下,词表中数十万个 Token 中的极低概率 Token 仍有被选中的可能。Top-k 采样 通过一种简单粗暴的方式解决这个问题:只保留概率最高的
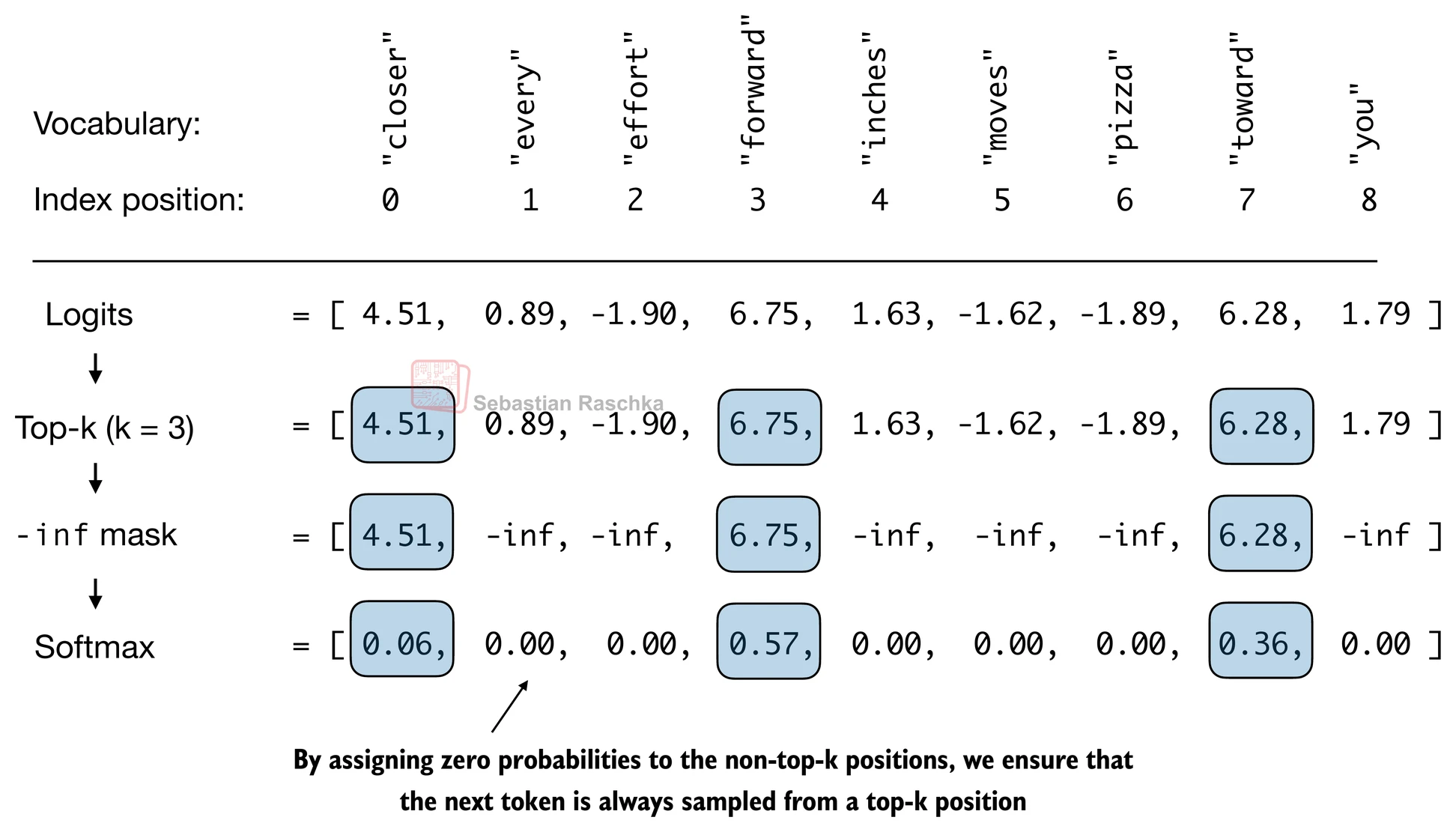
图 17-7:Top-k 采样示意图。对 logits 排序后只保留前 k 个,其余置为
import torch
def top_k_filter(logits, k):
"""Top-k 过滤:只保留前 k 个最大 logit,其余设为 -inf"""
top_values, _ = torch.topk(logits, k)
min_top_value = top_values[-1] # 第 k 大的值
# 将低于阈值的 logit 置为 -inf
filtered = torch.where(
logits < min_top_value,
torch.tensor(float("-inf")),
logits
)
return filtered
# 示例
logits = torch.tensor([4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79])
filtered_logits = top_k_filter(logits, k=3)
print("过滤后的 logits:", filtered_logits)
# 输出: tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])
probas = torch.softmax(filtered_logits, dim=0)
print("归一化概率:", probas)
# 输出: tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])Top-k 的优点是实现简单、计算开销极低。但它有一个内在缺陷:
17.3.4 Top-p 采样(Nucleus Sampling)
Top-p 采样(又称核采样,Nucleus Sampling)由 Holtzman et al. (2020) 在论文 "The Curious Case of Neural Text Degeneration" 中提出,优雅地解决了 Top-k 的固定候选集问题。其核心思想是:不固定候选 Token 的数量,而是固定候选 Token 的累积概率质量。
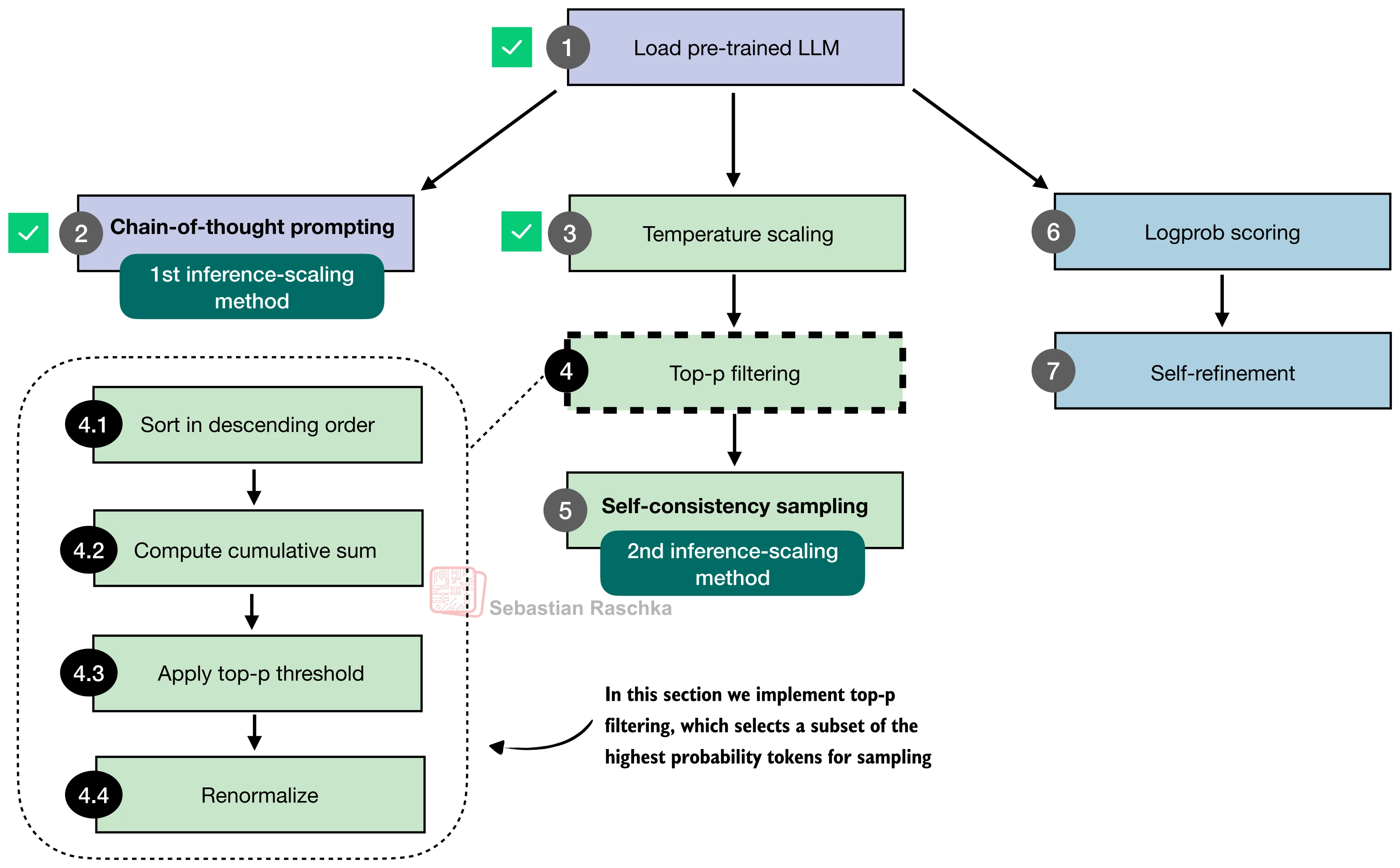
图 17-8:Top-p 采样的核心思想。将 Token 按概率从高到低排序,依次累加,保留累积概率首次超过阈值
具体步骤如下:
- 排序:将所有 Token 的概率从高到低排列。
- 累积求和:依次累加概率值。
- 截断:保留使累积概率首次达到或超过
的最小 Token 集合。 - 重新归一化:在保留的候选集中重新归一化概率,然后采样。
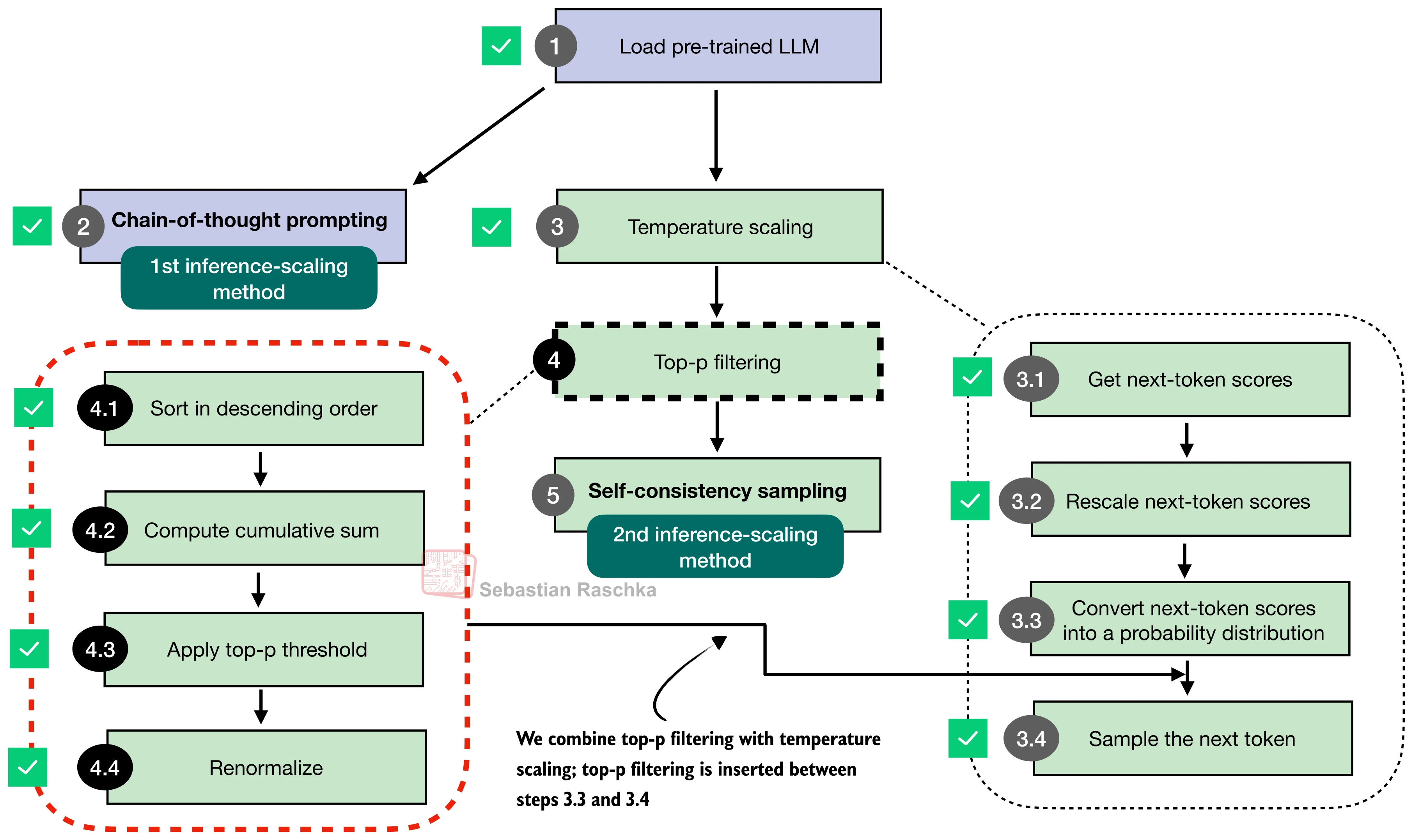
图 17-9:Top-p 采样的完整流程。从温度缩放后的 logits 出发,经 softmax → 排序 → 累积概率截断 → 重新归一化 → 采样。
下面给出一个完整的、自包含的 Top-p 采样实现:
import torch
def top_p_sample(logits, temperature=1.0, top_p=0.9):
"""
温度缩放 + Top-p 采样的完整实现。
参数:
logits: 模型输出的原始 logits,形状 [vocab_size]
temperature: 温度参数,> 0
top_p: 累积概率阈值,范围 (0, 1]
返回:
采样得到的 Token 索引
"""
# Step 1: 温度缩放
scaled_logits = logits / temperature
# Step 2: 转换为概率
probas = torch.softmax(scaled_logits, dim=-1)
# Step 3: 按概率降序排列
sorted_probas, sorted_indices = torch.sort(probas, descending=True)
# Step 4: 计算累积概率
cumulative_probas = torch.cumsum(sorted_probas, dim=-1)
# Step 5: 找到累积概率超过 top_p 的截断点
# 保留"前缀累积概率 < top_p"的所有 Token,以及恰好越过阈值的那个
prefix_cumsum = cumulative_probas - sorted_probas # 每个 Token 之前的累积概率
keep_mask = prefix_cumsum < top_p
keep_mask[0] = True # 始终保留概率最高的 Token
# Step 6: 将被过滤掉的 Token 概率置零
sorted_probas[~keep_mask] = 0.0
# Step 7: 映射回原始词表顺序
filtered_probas = torch.zeros_like(probas)
filtered_probas.scatter_(0, sorted_indices, sorted_probas)
# Step 8: 重新归一化
filtered_probas = filtered_probas / filtered_probas.sum().clamp(min=1e-12)
# Step 9: 按概率采样
return torch.multinomial(filtered_probas, num_samples=1).item()
# 使用示例
logits = torch.tensor([4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79])
vocab = ["closer", "every", "effort", "forward", "inches", "moves", "pizza", "toward", "you"]
torch.manual_seed(42)
for i in range(5):
idx = top_p_sample(logits, temperature=1.0, top_p=0.9)
print(f"第 {i+1} 次采样: {vocab[idx]}")Top-p 的自适应特性。 Top-p 的核心优势在于候选集大小会随上下文自动调整。当模型对某个位置非常确定(如概率 0.95 集中在一个 Token 上)时,Top-p=0.9 会只保留那 1 个 Token,等效于贪心解码。当模型面临高度不确定的选择(概率分散在数十个 Token 上)时,候选集自动扩大。这种自适应行为使得 Top-p 在实践中比固定的 Top-k 更为稳健。
17.3.5 温度与 Top-p 的组合策略
在实际推理系统中,温度缩放和 Top-p 通常组合使用。它们各自控制不同层面的多样性:
- 温度控制的是概率分布的"形状"——多尖锐还是多平坦。
- Top-p控制的是候选集的"范围"——允许多少个 Token 参与采样。
两者的组合可以精细调控输出的确定性-多样性光谱:
| 组合策略 | 温度 | Top-p | 效果 | 适用场景 |
|---|---|---|---|---|
| 高确定性 | 0.0-0.3 | 0.5-0.7 | 极少变化,近似贪心 | 事实性问答、翻译 |
| 适度多样性 | 0.5-0.8 | 0.8-0.95 | 生成多样但连贯 | 推理任务自一致性投票 |
| 高创造性 | 1.0-1.5 | 0.95-1.0 | 高度多样,偶有惊喜 | 创意写作、头脑风暴 |
在推理模型的典型使用中,常见的参数组合为
下面的代码展示了不同参数组合对采样分布的影响:
import torch
from collections import Counter
def sample_with_config(logits, temperature, top_p, num_samples=1000):
"""给定参数组合,统计 1000 次采样的 Token 频率"""
counts = Counter()
for _ in range(num_samples):
# 温度缩放
scaled = logits / temperature if temperature > 0 else logits
probas = torch.softmax(scaled, dim=-1)
# Top-p 过滤
sorted_p, sorted_idx = torch.sort(probas, descending=True)
cum_p = torch.cumsum(sorted_p, dim=-1)
prefix = cum_p - sorted_p
keep = prefix < top_p
keep[0] = True
sorted_p[~keep] = 0.0
filtered = torch.zeros_like(probas).scatter_(0, sorted_idx, sorted_p)
filtered = filtered / filtered.sum().clamp(min=1e-12)
token_id = torch.multinomial(filtered, num_samples=1).item()
counts[token_id] += 1
return counts
logits = torch.tensor([4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79])
vocab = ["closer", "every", "effort", "forward", "inches", "moves", "pizza", "toward", "you"]
configs = [
(0.3, 0.7, "低温+窄范围"),
(0.8, 0.9, "适中(推理常用)"),
(1.5, 0.95, "高温+宽范围"),
]
for T, p, label in configs:
torch.manual_seed(42)
counts = sample_with_config(logits, T, p, num_samples=1000)
top3 = counts.most_common(3)
summary = ", ".join(f"{vocab[tid]}={cnt}" for tid, cnt in top3)
print(f"[{label}] T={T}, top_p={p}: {summary}")17.3.6 推理场景中的采样实践
将上述采样策略应用于推理模型时,有几个值得注意的实践要点。
自一致性投票依赖采样多样性。 在 §17.2 中介绍的自一致性(Self-Consistency)方法,其核心前提是能通过随机采样生成多条不同的推理路径。下表展示了采样参数对 MATH-500 基准测试准确率的影响:
| 方法 | 采样参数 | 准确率 | 耗时 |
|---|---|---|---|
| 贪心解码(无采样) | 15.2% | 10.1 min | |
| 温度+Top-p(单次) | 17.8% | 30.7 min | |
| 温度+Top-p + CoT + 自一致性 (n=5) | 48.0% | 452.9 min | |
| 温度+Top-p + CoT + 自一致性 (n=10) | 52.0% | 862.6 min |
表 17-3:采样策略与推理准确率的关系。数据来源:Raschka (2025) 使用 Qwen3-0.6B 基座模型在 DGX Spark 上的实验。
一个重要的观察是:单次随机采样(17.8%)甚至不如贪心解码的 CoT 版本(40.6%),但当采样与 CoT 和多数投票组合时,准确率飙升至 52.0%。 这表明采样的价值不在于单次生成更好的答案,而在于通过多次采样产生多样化的候选答案,让投票机制筛选出最可靠的结果。
温度过高的风险。 如果温度设置过高(如
- 对需要精确计算的数学/代码任务:
- 对需要创意推理的开放式任务:
- Top-p 通常固定在
范围内
与 Top-k 的关系。 虽然 Top-k 和 Top-p 解决的是同一个问题(缩小候选集),但在现代推理系统中 Top-p 更为常用,因为它的自适应特性更适合推理过程中上下文不断变化的场景。OpenAI、DeepSeek 等主流 API 默认提供的也是 Top-p(而非 Top-k)参数。不过,两者也可以组合使用——先用 Top-k 做粗过滤,再用 Top-p 做精细截断。
本节总结
采样多样性控制是推理时间缩放的技术基础。温度缩放通过调整 softmax 前的 logits 比例来控制概率分布的尖锐程度;Top-k 采样通过保留固定数量的最高概率 Token 来排除噪声候选;Top-p 采样通过动态控制累积概率阈值实现自适应的候选集大小。在推理模型的实际应用中,温度与 Top-p 通常组合使用(如