3.1 Transformer 全景
2017 年,Vaswani 等人在 "Attention Is All You Need" 中提出了 Transformer 架构。这一模型彻底摒弃了循环(Recurrence)和卷积(Convolution)结构,完全依赖注意力机制来捕捉序列内的依赖关系。由于不存在循环依赖,Transformer 的计算可以高度并行化,极大地缩短了在现代 GPU 上的训练时间,为训练规模空前的语言模型铺平了道路。今天几乎所有大型语言模型——BERT、GPT 系列、T5、LLaMA 等——都建立在 Transformer 架构或其变体之上。
本节将以原始 Transformer 的 Encoder-Decoder 架构为主线,从宏观到微观,完整追踪一条数据从输入到输出的全部流程。理解这条数据流是掌握所有后续变体(Encoder-only、Decoder-only)的前提。
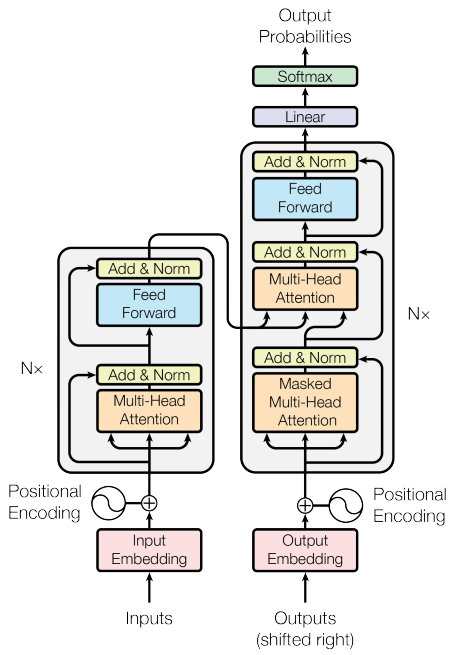
图 3-1:Transformer 的 Encoder-Decoder 架构。左侧为编码器栈,右侧为解码器栈,二者通过编码器-解码器注意力连接。编码器栈的每一层包含多头自注意力和前馈网络两个子层;解码器栈的每一层在此基础上增加了掩码自注意力子层。每个子层都配有残差连接和层归一化。
3.1.1 宏观结构:编码器与解码器
Transformer 遵循经典的编码器-解码器(Encoder-Decoder)框架。编码器负责将输入序列转换为一组连续的表示向量,解码器则基于这些表示向量,逐步生成输出序列。二者都由
在宏观层面,数据的流动可以概括为以下路径:
接下来,我们沿着这条路径逐步展开。
3.1.2 输入表示:词嵌入与位置编码
词嵌入(Token Embedding)。 输入序列首先经过分词器(Tokenizer)被切分为离散的词元(Token),每个词元被映射为一个词汇表中的整数索引。嵌入层(Embedding Layer)将这些整数索引转换为
位置编码(Positional Encoding)。 自注意力机制本身是置换不变的——它并不关心输入词元的顺序。这对于自然语言处理是致命的,因为 "猫追狗" 和 "狗追猫" 的语义截然不同。为此,必须额外注入位置信息。原始 Transformer 使用正弦-余弦函数定义的固定位置编码:
其中
这一设计使得不同位置的向量在向量空间中具有可区分的表示,同时保留了相对位置关系的某些数学性质。
3.1.3 编码器栈
编码器由
子层 1:多头自注意力(Multi-Head Self-Attention)。 这是 Transformer 的核心引擎。输入序列中的每个位置都可以"关注"序列中的所有位置(包括自身),从而捕捉任意距离的依赖关系。具体而言,输入
然后计算缩放点积注意力(参见 2.3 节)。"多头"(Multi-Head)意味着上述过程被并行执行
在编码器的自注意力中,
子层 2:位置前馈网络(Position-wise Feed-Forward Network, FFN)。 自注意力完成了位置之间的信息交互,而 FFN 则对每个位置独立地施加非线性变换。它是一个简单的两层全连接网络:
其中中间层的维度
残差连接与层归一化(Add & Norm)。 每个子层都包裹在一个残差连接中,其后紧跟层归一化(Layer Normalization)。形式上:
残差连接确保了梯度可以直接回传到浅层,缓解深层网络的梯度消失问题。层归一化在特征维度上对每个样本独立地重新中心化和缩放,稳定训练过程。为了使残差加法可行,所有子层的输出维度必须与输入维度一致,即始终保持
经过
3.1.4 解码器栈
解码器同样由
子层 1:掩码多头自注意力(Masked Multi-Head Self-Attention)。 与编码器的自注意力结构相同,但增加了"掩码"(Mask)机制。在生成位置
实现上,掩码是一个上三角矩阵,在计算注意力分数之后、softmax 之前,将所有未来位置对应的分数设为
子层 2:编码器-解码器注意力(Encoder-Decoder Attention)。 这是连接编码器和解码器的桥梁。在这一层中,查询(Q)来自上一个解码器子层的输出,而键(K)和值(V)来自编码器栈的最终输出
这种设计与 2.3 节介绍的 Bahdanau 注意力在功能上是一致的——都是让解码器能够有选择地"回看"编码器的输出。不同之处在于,Transformer 的编码器-解码器注意力使用多头缩放点积机制,而非加性注意力。
子层 3:位置前馈网络(FFN)。 与编码器中的 FFN 完全相同。
每个子层同样采用残差连接和层归一化。注意,原始 Transformer 中层归一化放在子层之后(Post-Norm),这是一个重要的设计细节,将在后续章节讨论其与 Pre-Norm 的区别。
3.1.5 输出层:从隐状态到概率分布
解码器栈的输出是一个
其中
3.1.6 完整数据流:从输入到输出
下面我们将上述所有环节串联起来,追踪一条完整的数据流。以机器翻译为例,将英文句子 "The cat sits on the mat" 翻译为法文。
图 3-2:Transformer 内部数据流可视化。图示展示了词元从输入嵌入层出发,经过多头自注意力和前馈网络的逐层变换,最终输出下一词元概率分布的全过程。
编码器侧的数据流:
- 分词:输入句子被分词为词元序列
,经查表转为整数索引。 - 嵌入 + 位置编码:每个索引通过嵌入层转为
维向量,乘以 后与对应位置的正弦-余弦编码相加,形成初始表示矩阵 。 - 第 1 层编码器:
首先进入多头自注意力子层。每个词元(如 "sits")同时关注所有 6 个位置,通过 个注意力头在不同子空间中计算注意力权重并汇聚信息。输出经残差连接和层归一化后,送入 FFN 子层进行逐位置的非线性变换,再次经过残差连接和层归一化,得到 。张量形状不变,但每个位置的向量已经融合了来自其他位置的上下文信息。 - 第 2 至第
层编码器:重复上述过程。随着层数加深,每个位置的表示越来越丰富——浅层可能捕捉局部语法特征,深层可能编码全局语义关系。 - 编码器输出:最终得到
,这是输入句子的完整上下文表示,将作为解码器中编码器-解码器注意力的键和值。
解码器侧的数据流:
- 目标输入准备:训练时,目标序列
向右移位一个位置,作为解码器的输入。推理时则逐步生成:先输入 ,生成第一个词,再将已生成的序列作为输入,如此循环。 - 嵌入 + 位置编码:与编码器侧相同的流程,生成解码器的初始表示。
- 第 1 层解码器:
- 子层 1(掩码自注意力):解码器对已生成的词元序列施加自注意力,但通过掩码确保每个位置只能看到它自身及之前的位置。
- 子层 2(编码器-解码器注意力):查询来自子层 1 的输出,键和值来自编码器输出
。这一步让解码器得以"查阅"源句子的完整信息,例如在生成 "chat"(法文的"猫")时,注意力会集中在编码器输出中 "cat" 对应的位置。 - 子层 3(FFN):逐位置的非线性变换。
- 每个子层均有残差连接和层归一化。
- 第 2 至第
层解码器:逐层深化表示。 - 线性层 + Softmax:解码器栈的输出经过线性投影和 Softmax,在每个位置产生词汇表上的概率分布。训练时,所有位置的预测可以并行计算(因为目标序列是已知的,掩码保证了因果性)。推理时则逐位置生成,每步取概率最高的词元(或使用束搜索等策略)。
下表总结了数据在 Transformer 各主要组件中的维度变化:
| 组件 | 输入维度 | 输出维度 | 说明 |
|---|---|---|---|
| 词嵌入层 | 查表操作 | ||
| 位置编码 | 逐元素相加,维度不变 | ||
| 编码器层 | 每一层保持维度不变 | ||
| 解码器层 | 每一层保持维度不变 | ||
| 输出线性层 | 投影到词汇表大小 | ||
| Softmax | 归一化为概率分布 |
表 3-1:Transformer 数据流中的维度变化。
3.1.7 原始设计的关键超参数
原始论文 "Attention Is All You Need" 中使用的 Base 模型配置如下:
| 超参数 | 符号 | 值 |
|---|---|---|
| 模型维度 | 512 | |
| FFN 内部维度 | 2048 | |
| 注意力头数 | 8 | |
| 每头维度 | 64 | |
| 编码器/解码器层数 | 6 | |
| Dropout 率 | — | 0.1 |
表 3-2:原始 Transformer Base 模型的超参数配置。
这些超参数之间存在内在关联:
3.1.8 小结
本节完整梳理了 Transformer 的 Encoder-Decoder 架构及其数据流。核心要点如下:
- 架构对称性:编码器和解码器都由
个相同的层堆叠而成,每层的核心组件是多头注意力和前馈网络,辅以残差连接和层归一化。 - 三种注意力:编码器使用自注意力;解码器使用掩码自注意力(确保自回归性)和编码器-解码器注意力(连接编码器与解码器)。
- 维度不变性:从输入嵌入到解码器输出,张量的隐藏维度始终保持
不变,直到最后的线性投影层。 - 位置编码的必要性:自注意力本身是置换不变的,位置编码是使 Transformer 能够感知词序的唯一机制。
- 并行性:编码器可以对所有位置并行计算;解码器在训练时借助掩码实现并行,在推理时则逐步生成。
原始 Transformer 采用的 Post-Norm 层归一化、ReLU 激活函数和正弦-余弦位置编码在后续研究中逐渐被 Pre-Norm、SwiGLU 和旋转位置编码(RoPE)等改进所取代,我们将在后续章节逐一介绍这些演进。