15.4 奖励模型
在 RLHF 流程中,奖励模型(Reward Model, RM) 扮演着"裁判"的角色——它将人类偏好的判断能力封装为一个可微分的标量函数,为策略优化提供梯度信号。没有奖励模型,强化学习便无从知晓"什么是好的回答"。本节从奖励模型的基本原理出发,依次讨论结果监督(ORM)与过程监督(PRM)两种范式,系统梳理奖励信号的四大来源,最后介绍 LLM-as-a-Judge 与 WinRate 评测的工程实现。
15.4.1 奖励模型的基本原理
奖励模型的核心任务是:给定一个提示
架构设计。 奖励模型通常由预训练语言模型(如 GPT 或 Llama)加上一个标量投影头构成。具体地,将
其中 num_labels=1),而非生成模型。
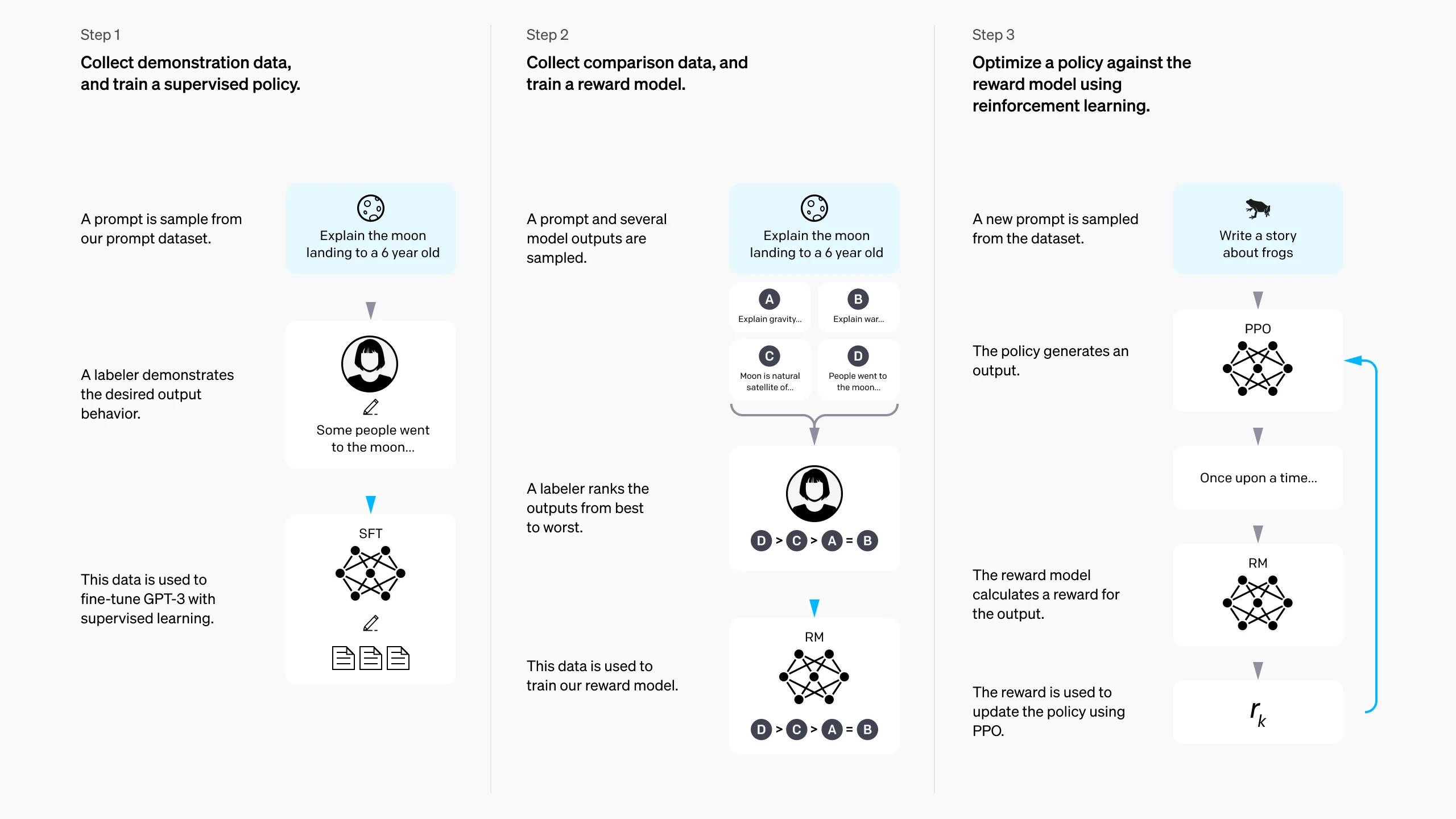
图 15-4-1:InstructGPT 的三阶段后训练流程。Step 2 展示了奖励模型的训练过程:标注员对多个模型输出进行排序,排序数据被转换为成对偏好,用于训练奖励模型。
15.4.2 Bradley-Terry 模型与训练损失
奖励模型的训练建立在 Bradley-Terry 偏好模型之上。该模型假设:给定提示
其中
由此导出负对数似然损失:
这个损失的梯度方向清晰:当模型给
奖励中心化。 Bradley-Terry 模型具有平移不变性——对所有奖励加同一常数不影响偏好概率。实践中,这可能导致奖励值漂移到极端范围。为此,可添加辅助正则项,鼓励奖励值围绕零中心分布:
推荐系数
下面是一个完整的 Bradley-Terry 成对损失实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PairwiseRewardLoss(nn.Module):
"""Bradley-Terry 成对偏好损失,用于训练奖励模型"""
def __init__(self, margin: float = 0.0):
super().__init__()
self.margin = margin # 可选:要求 chosen 比 rejected 至少高 margin
def forward(
self,
chosen_reward: torch.Tensor, # [batch_size]
rejected_reward: torch.Tensor, # [batch_size]
) -> torch.Tensor:
# 核心公式:-log σ(r_chosen - r_rejected - margin)
diff = chosen_reward - rejected_reward - self.margin
loss = -F.logsigmoid(diff)
return loss.mean()
# 使用示例
loss_fn = PairwiseRewardLoss(margin=0.0)
chosen_scores = torch.tensor([1.2, 0.8, 1.5])
rejected_scores = torch.tensor([0.3, 1.1, 0.2])
loss = loss_fn(chosen_scores, rejected_scores)
print(f"RM Loss: {loss.item():.4f}")
# chosen_scores > rejected_scores 的样本 loss 较小
# chosen_scores < rejected_scores 的样本(第2个)贡献较大 loss15.4.3 使用 TRL 训练奖励模型
TRL(Transformer Reinforcement Learning)库提供了开箱即用的 RewardTrainer,支持标准偏好数据集格式:
from trl import RewardTrainer, RewardConfig
from datasets import load_dataset
# 1. 准备偏好数据(需包含 chosen 和 rejected 字段)
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# 数据格式示例:
# {"chosen": [{"role":"user","content":"..."}, {"role":"assistant","content":"好回答"}],
# "rejected": [{"role":"user","content":"..."}, {"role":"assistant","content":"差回答"}]}
# 2. 配置训练参数
config = RewardConfig(
output_dir="reward-model-output",
per_device_train_batch_size=8,
num_train_epochs=1,
learning_rate=1e-5,
center_rewards_coefficient=0.01, # 奖励中心化系数
)
# 3. 启动训练
trainer = RewardTrainer(
model="Qwen/Qwen3-0.6B", # 基座模型,自动添加分类头
args=config,
train_dataset=dataset,
)
trainer.train()训练过程中,RewardTrainer 自动将基座模型转换为 AutoModelForSequenceClassification(num_labels=1),并在内部实现了 Bradley-Terry 损失计算。关键监控指标包括:accuracy(模型是否正确判断 chosen > rejected)和 margin(chosen 与 rejected 的平均分差)。
15.4.4 结果监督奖励模型(ORM)
结果监督奖励模型(Outcome-supervised Reward Model, ORM) 是最常见的范式:模型只对最终回答给出一个整体评分,不关心中间推理过程。
工作方式:
| 维度 | ORM |
|---|---|
| 监督粒度 | 整句/整段回答 |
| 输出 | 单一标量 |
| 训练数据 | 成对偏好 |
| 典型应用 | 通用对话、指令遵循 |
| 优势 | 标注成本低,实现简单 |
| 局限 | 无法定位错误步骤 |
在 PPO-RLHF 流程中,ORM 充当打分器:策略模型生成回答后,ORM 为整个回答打一个分数
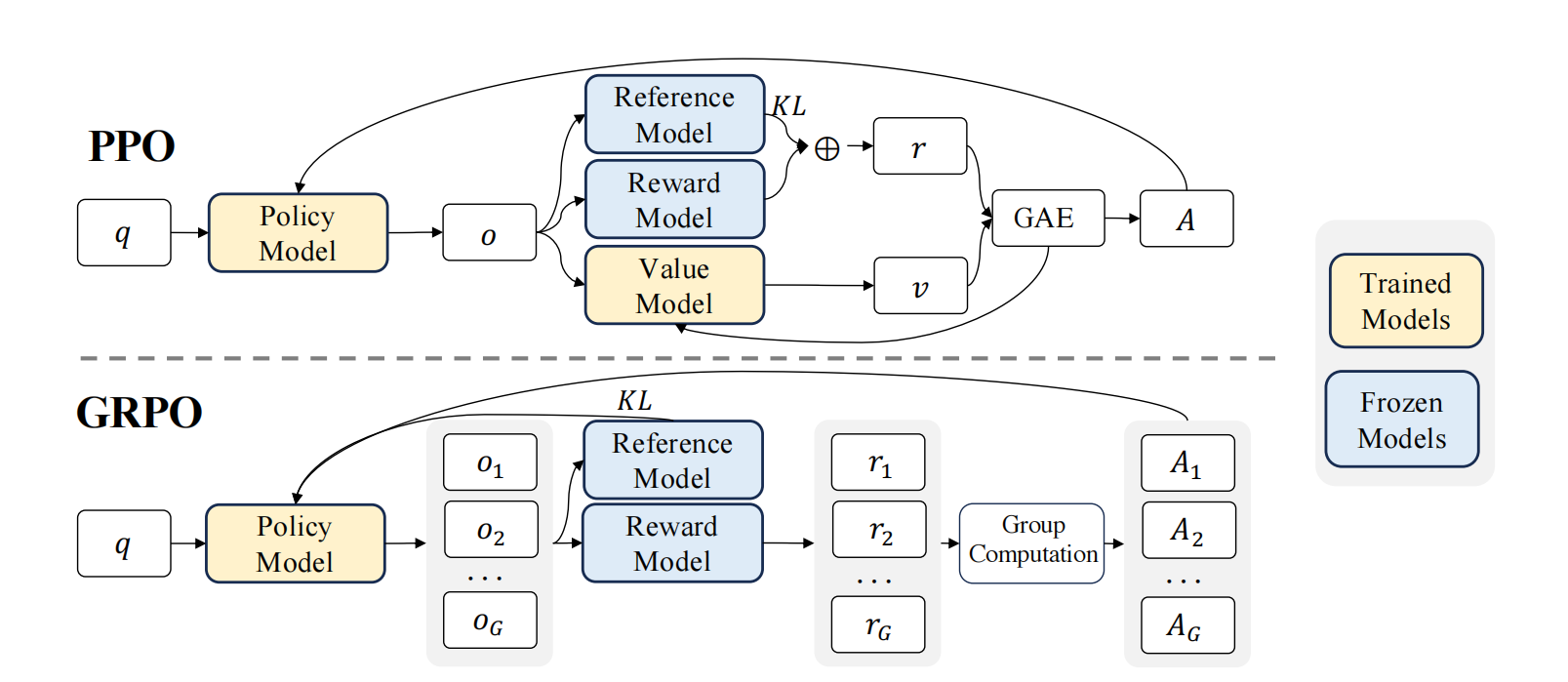
图 15-4-2:PPO 与 GRPO 中奖励模型的作用对比。PPO 中 Reward Model 为单个输出打分,结合 Value Model 通过 GAE 估计逐 token 优势;GRPO 中 Reward Model 为同一 prompt 的 G 个输出分别打分,通过组内标准化直接得到优势,省去了 Value Model。
15.4.5 过程监督奖励模型(PRM)
对于数学推理、代码生成等需要多步推理的任务,过程监督奖励模型(Process-supervised Reward Model, PRM) 提供了更精细的信号:它对推理过程中的每一步给出正确/错误的判断。
ORM 与 PRM 的核心区别:
| 维度 | ORM(结果监督) | PRM(过程监督) |
|---|---|---|
| 监督粒度 | 最终答案 | 每个推理步骤 |
| 输出 | 单一标量 | 每步一个标签(正确/错误) |
| 标注成本 | 低 | 高(需要逐步标注) |
| 错误定位 | 无法定位 | 可精确定位首个错误步骤 |
| 适用场景 | 通用对话 | 数学推理、代码、逻辑链 |
PRM 的训练方法。 PRM 通常建模为 Token 分类任务:在每个推理步骤的结束位置,预测该步骤是否正确(二分类)。训练数据格式为:
# PRM 训练数据示例
example = {
"prompt": "小明有45本书,分给3个班级...",
"completions": [
"Step 1: 每个班级分到 45/3 = 15 本书", # 正确
"Step 2: 第一个班级额外得到 15 * 2 = 30 本", # 错误(逻辑跳跃)
"Step 3: 所以答案是 30 本。答案:30", # 错误(基于错误前提)
],
"labels": [True, False, False], # 每步的正确性标签
}使用 TRL 训练 PRM:
from trl.experimental.prm import PRMConfig, PRMTrainer
from transformers import AutoModelForTokenClassification, AutoTokenizer
from datasets import load_dataset
# PRM 使用 Token 分类模型(num_labels=2:正确/错误)
model = AutoModelForTokenClassification.from_pretrained(
"Qwen/Qwen2-0.5B", num_labels=2
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
# Math Shepherd 数据集包含逐步标注
dataset = load_dataset("trl-lib/math_shepherd", split="train[:10%]")
config = PRMConfig(output_dir="prm-math-shepherd")
trainer = PRMTrainer(
model=model,
args=config,
processing_class=tokenizer,
train_dataset=dataset,
)
trainer.train()PRM 的推理使用。 训练完成后,PRM 可以用于:(1)在搜索时剪枝错误分支(如 Best-of-N 采样中只保留每步都正确的路径);(2)为 RL 训练提供密集奖励信号(每步一个奖励,而非只在最后一步给奖励)。
from transformers import pipeline
# 加载训练好的 PRM
pipe = pipeline("token-classification", model="trl-lib/Qwen2-0.5B-Reward-Math-Sheperd")
# 逐步验证推理过程
prompt = "求解:45 除以 3 等于多少?"
steps = [
"Step 1: 45 / 3 = 15",
"Step 2: 所以答案是 15",
]
separator = "\n"
for idx in range(1, len(steps) + 1):
text = separator.join([prompt] + steps[:idx]) + separator
pred = pipe(text)[-1]["entity"]
is_correct = {"LABEL_0": False, "LABEL_1": True}[pred]
print(f"Step {idx}: {'正确' if is_correct else '错误'}")
# 输出:
# Step 1: 正确
# Step 2: 正确15.4.6 奖励来源分类
奖励信号不一定来自训练过的神经网络模型。根据来源不同,可将奖励分为四大类:
| 奖励来源 | 定义 | 示例 | 优势 | 局限 |
|---|---|---|---|---|
| Model-based | 由训练过的 RM 打分 | Bradley-Terry RM、PRM | 可泛化到开放域 | 需要偏好数据训练,存在 reward hacking 风险 |
| Rule-based | 由预定义规则判定 | 答案精确匹配、格式检查、长度约束 | 100% 准确,无需训练 | 只适用于有明确标准的任务 |
| Environment-based | 由外部环境反馈 | 代码执行结果、单元测试通过率、数学验证器 | 客观可靠 | 需要可执行环境,仅限可验证任务 |
| 混合(Hybrid) | 组合多种来源 | DeepSeek-R1 的 accuracy + format reward | 兼顾精度与覆盖面 | 权重调节复杂 |
Rule-based 奖励函数示例。 TRL 内置了若干实用的规则奖励函数:
import re
def accuracy_reward(completions: list[str], answers: list[str]) -> list[float]:
"""精确匹配奖励:答案正确得 1.0,否则得 0.0"""
rewards = []
for completion, answer in zip(completions, answers):
# 提取模型输出中的最终答案
match = re.search(r"答案[是为::]\s*(.+?)(?:\s|$)", completion)
predicted = match.group(1).strip() if match else ""
rewards.append(1.0 if predicted == answer.strip() else 0.0)
return rewards
def format_reward(completions: list[str]) -> list[float]:
"""格式奖励:检查输出是否包含 <think>...</think> 标签"""
rewards = []
for c in completions:
has_think = bool(re.search(r"<think>.*?</think>", c, re.DOTALL))
rewards.append(1.0 if has_think else 0.0)
return rewards
def length_penalty(completions: list[str], max_len: int = 2048) -> list[float]:
"""超长惩罚:超过 max_len 的部分线性扣分"""
rewards = []
for c in completions:
excess = max(0, len(c) - max_len)
penalty = -excess / max_len # 超长越多,惩罚越重
rewards.append(min(0.0, penalty))
return rewards混合奖励的典型设计。 在数学推理的 RLVR(Reinforcement Learning with Verifiable Rewards)场景中,常见的做法是将准确性奖励与格式奖励加权组合:
其中
15.4.7 Judges 与 WinRate 评测
当人类标注成本过高或需要大规模评测时,可以用另一个强大的语言模型充当"裁判(Judge)"来代替人类进行偏好评估。这种方法被称为 LLM-as-a-Judge。
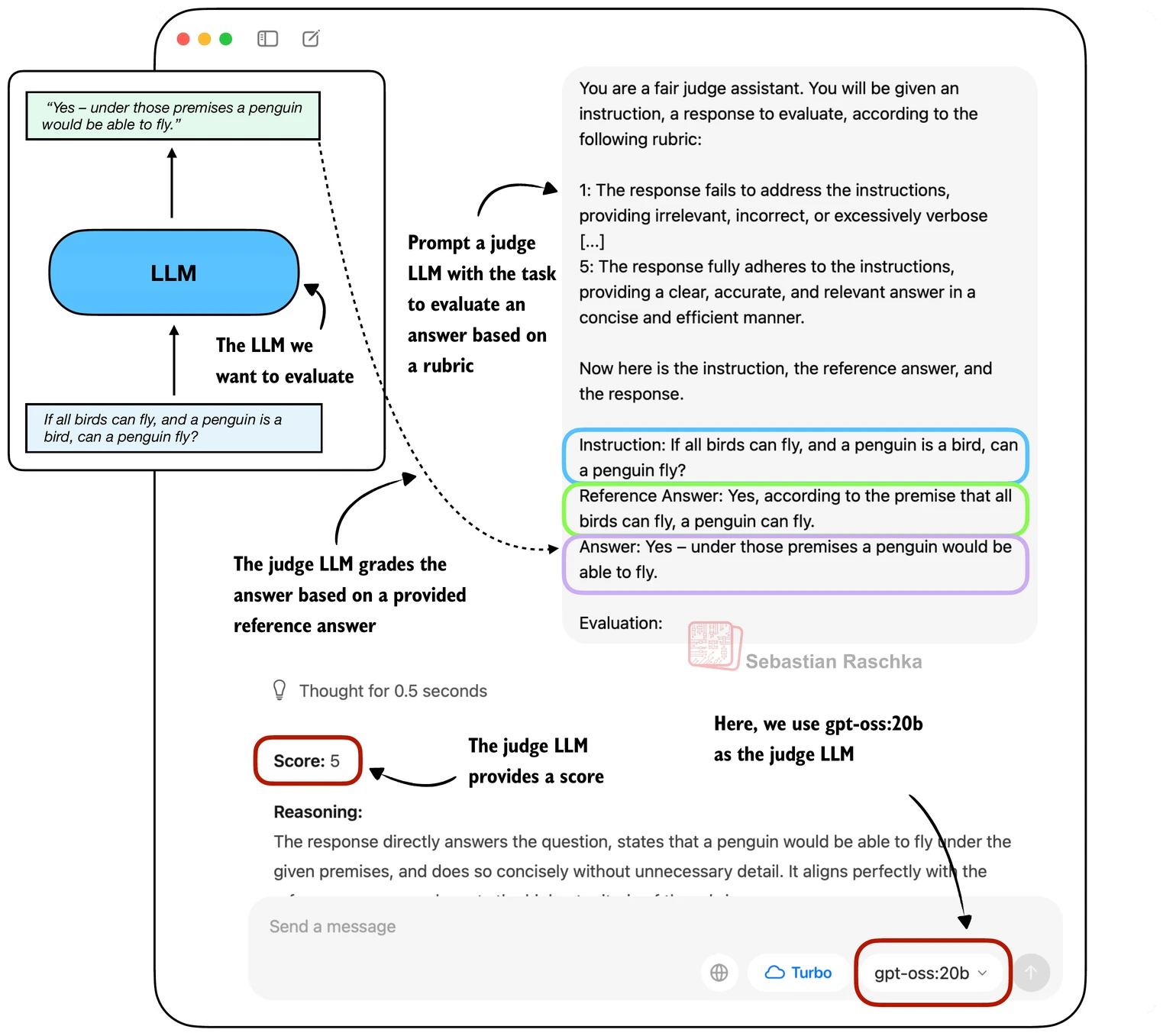
图 15-4-3:LLM-as-a-Judge 评测流程。候选模型(Candidate)生成回答后,裁判模型(Judge)根据预定义的评分量表(Rubric)对回答质量进行 1-5 分评分。
Pairwise Judge(成对裁判)。 给裁判模型同时展示两个回答,让它判断哪个更好。TRL 提供了多种内置裁判:
from trl.experimental.judges import HfPairwiseJudge
# 使用 Hugging Face 模型作为裁判
judge = HfPairwiseJudge()
results = judge.judge(
prompts=[
"法国的首都是哪里?",
"太阳系最大的行星是什么?",
],
completions=[
["巴黎,法兰西共和国的首都和最大城市。", "里昂"],
["土星", "木星,太阳系中体积和质量最大的行星。"],
],
)
print(results) # [0, 1] — 第一题选第0个回答,第二题选第1个回答自定义裁判。 可以通过继承基类实现任意评判逻辑:
from trl.experimental.judges import BasePairwiseJudge
# 简洁性裁判:直接按回答长度判断
class ConcisenessJudge(BasePairwiseJudge):
"""偏好更简洁的回答"""
def judge(self, prompts, completions, shuffle_order=False):
return [
0 if len(pair[0]) < len(pair[1]) else 1
for pair in completions
]
# 量表裁判:通过 LLM API 调用实现更复杂的评判逻辑
class RubricJudge(BasePairwiseJudge):
"""基于评分量表的裁判(调用外部 LLM API)"""
def __init__(self, api_client):
self.client = api_client
def judge(self, prompts, completions, shuffle_order=False):
results = []
for prompt, (a, b) in zip(prompts, completions):
rubric_prompt = (
f"比较以下两个回答的质量。\n"
f"问题:{prompt}\n"
f"回答A:{a}\n回答B:{b}\n"
f"哪个更好?只回答 A 或 B。"
)
verdict = self.client.generate(rubric_prompt).strip()
results.append(0 if "A" in verdict else 1)
return resultsWinRate 评测。 WinRate 是一种基于 Judge 的模型比较方法:让两个模型分别回答同一批问题,再由裁判逐对判定胜负,统计胜率。
def compute_winrate(
judge,
prompts: list[str],
model_a_responses: list[str],
model_b_responses: list[str],
) -> dict:
"""计算 Model A 相对于 Model B 的 WinRate"""
completions = list(zip(model_a_responses, model_b_responses))
verdicts = judge.judge(prompts=prompts, completions=completions)
wins_a = sum(1 for v in verdicts if v == 0)
wins_b = sum(1 for v in verdicts if v == 1)
total = len(verdicts)
return {
"model_a_winrate": wins_a / total,
"model_b_winrate": wins_b / total,
"total_comparisons": total,
}
# 使用示例
# results = compute_winrate(judge, test_prompts, gpt4_responses, llama_responses)
# print(f"GPT-4 WinRate: {results['model_a_winrate']:.1%}")Rubric-based 评分(量表评分)。 除了成对比较,还可以让 Judge 按照预定义量表对单个回答打分(如 1-5 分),这在不需要两两比较的场景中更高效:
def rubric_score_prompt(instruction: str, reference: str, answer: str) -> str:
"""构造评分量表提示"""
return (
"你是一个公正的评审。请根据以下评分标准评价候选回答:\n\n"
"1分:回答完全偏题或错误\n"
"2分:回答部分正确但有重大错误\n"
"3分:回答基本正确但不够完整\n"
"4分:回答大体正确,仅有小瑕疵\n"
"5分:回答完全正确、清晰、简洁\n\n"
f"题目:{instruction}\n"
f"参考答案:{reference}\n"
f"候选回答:{answer}\n\n"
"请只输出一个 1-5 的整数评分。"
)Judge 的已知偏差。 使用 LLM-as-a-Judge 需注意以下系统性偏差:
- 长度偏好:裁判模型倾向给更长的回答更高分(即使内容冗余)
- 位置偏好:在成对比较中,裁判可能偏好先出现的回答(可通过随机交换顺序缓解)
- 自我偏好:模型倾向于给自己(或同系列模型)生成的回答更高分
- 格式偏好:包含列表、Markdown 格式的回答可能获得不成比例的高分
15.4.8 奖励模型在 RLHF 中的角色
在完整的 RLHF/PPO 流程中,奖励模型的位置如下图所示:
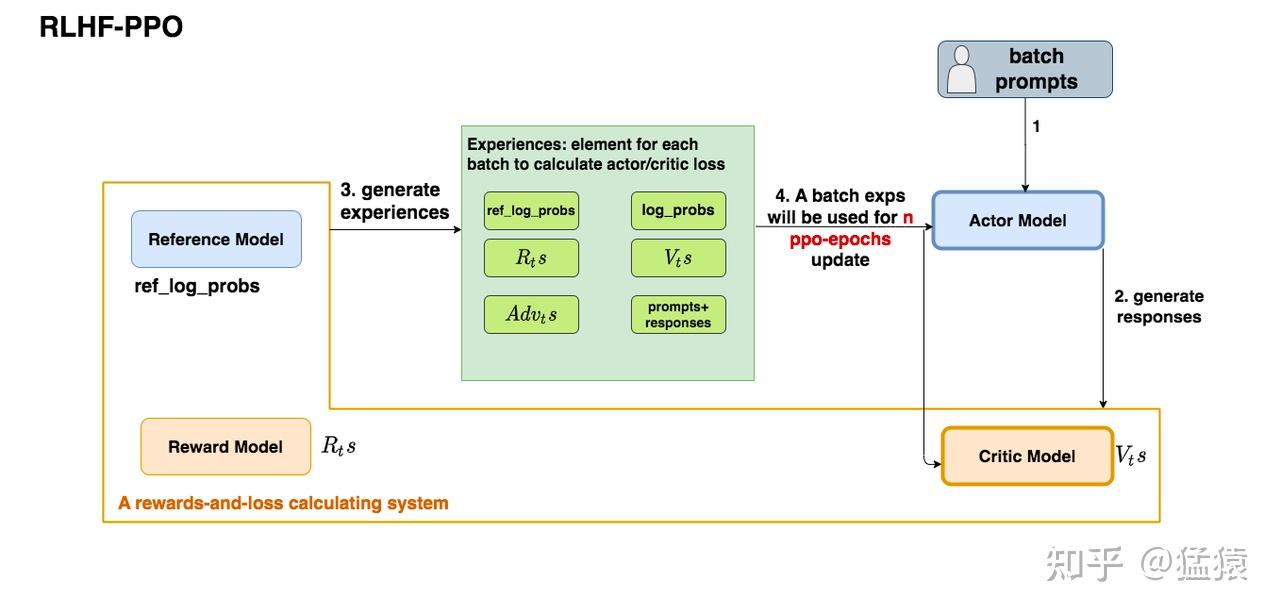
图 15-4-4:RLHF-PPO 训练流程。Reward Model 为生成的回答计算即时奖励
奖励模型参与的具体计算步骤:
- 打分:
,奖励模型对 prompt 和回答 输出标量分数 - KL 修正:在每个 token 位置计算 KL 惩罚,最后一个 token 叠加 RM 分数:
- 中间 token:
- 最后 token:
- 中间 token:
- 优势估计:结合 Critic 的价值估计,通过 GAE 计算每个 token 的优势
- 策略更新:用 PPO-Clip 目标更新 Actor
Reward Hacking 与对策。 奖励模型并非完美的人类偏好代理。随着 RL 训练进行,策略模型可能学会"欺骗"奖励模型——生成高分但低质量的输出。常见对策包括:
- KL 约束:限制策略偏离参考模型的幅度
- 奖励裁剪:
torch.clamp(reward, -clip_value, clip_value)防止极端分数 - 奖励集成:使用多个 RM 取平均,减少单一模型的偏差
- 定期更新 RM:用新策略生成的数据重新训练奖励模型
小结
本节系统介绍了奖励模型的原理与实践。ORM 对最终回答整体打分,适用于通用场景;PRM 对每个推理步骤逐步评判,在数学和代码推理中能提供更精准的信号。奖励信号可以来自训练过的模型(Model-based)、预定义规则(Rule-based)、外部环境(Environment-based)或它们的组合(Hybrid)。LLM-as-a-Judge 和 WinRate 提供了大规模自动化评测的手段,但需注意 Judge 的系统性偏差。在 RLHF 流程中,奖励模型是连接人类偏好与策略优化的桥梁——它的质量直接决定了对齐训练的效果上限。