6.2 GQA(分组查询注意力)
标准多头注意力(MHA)为每个查询头分配独立的 Key 和 Value 投影,这意味着 KV 缓存的大小与注意力头数成正比。当模型规模增大、上下文长度拉长时,KV 缓存会迅速膨胀为推理阶段的内存瓶颈。分组查询注意力(Grouped-Query Attention, GQA)通过让多个查询头共享同一组 Key/Value 投影,在几乎不损失建模能力的前提下大幅压缩 KV 缓存体积。GQA 最早由 Ainslie 等人在 2023 年的论文 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 中系统提出,此后迅速成为 Llama 2/3、Mistral、Gemma 等主流大语言模型的标准配置。
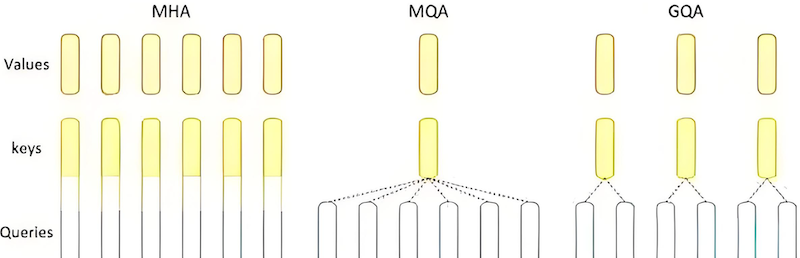
图 6-6:GQA 分组查询注意力。多个 Query 头共享同一组 Key/Value,在保持注意力多样性的同时大幅减少 KV 缓存内存。
6.2.1 从 MHA 到 GQA:核心思想
在标准 MHA 中,假设共有
GQA 引入一个超参数 num_kv_groups),将
这一设计形成了一个连续的谱系:
(每组一个查询头):退化为标准 MHA,无压缩效果。 :GQA,平衡性能与效率。 (所有查询头共享同一组 KV):退化为多查询注意力(MQA),压缩最激进但可能损失建模能力。
以一个具体例子说明:假设模型有 8 个查询头、2 个 KV 分组。查询头 1-4 共享第一组 Key/Value,查询头 5-8 共享第二组 Key/Value。每组内的查询头计算各自独立的 Query 投影,但使用同一份 Key 和 Value 进行注意力计算。
6.2.2 投影维度的变化
GQA 对三个投影矩阵的维度产生了不同影响:
| 投影矩阵 | MHA 输出维度 | GQA 输出维度 | 变化 |
|---|---|---|---|
| 不变 | |||
| 缩减为 | |||
| 缩减为 |
表 6-2:MHA 与 GQA 投影矩阵维度对比。
Query 投影保持不变——每个查询头仍然拥有独立的 Query 向量,保留了多头注意力的表达能力。Key 和 Value 投影的参数量减少为原来的
6.2.3 repeat_interleave 扩展机制
GQA 的 Key/Value 头数(repeat_interleave 方法可以精确完成这一操作。
假设 group_size = H / G = 4。Key 张量的形状为 (batch, G, seq_len, head_dim),经过 repeat_interleave(group_size, dim=1) 后变为 (batch, H, seq_len, head_dim):
扩展前 (dim=1): [K1, K2]
扩展后 (dim=1): [K1, K1, K1, K1, K2, K2, K2, K2]这里的关键在于使用 repeat_interleave 而非 repeat。repeat 会产生 [K1, K2, K1, K2, ...] 的交错排列,导致第 repeat_interleave 会将每个元素就地重复,确保第 1-4 个查询头对应 K1,第 5-8 个查询头对应 K2,与分组语义一致。
需要注意的是,repeat_interleave 在逻辑上创建了数据的副本,但现代深度学习框架在反向传播时会自动将梯度正确聚合回原始的
6.2.4 PyTorch 实现
以下是一个完整的 GQA 注意力模块实现,剥离了 KV 缓存逻辑以突出核心机制:
import torch
import torch.nn as nn
class GroupedQueryAttention(nn.Module):
def __init__(self, d_in, d_out, num_heads, num_kv_groups,
dropout=0.0, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
assert num_heads % num_kv_groups == 0, \
"num_heads must be divisible by num_kv_groups"
self.num_heads = num_heads
self.num_kv_groups = num_kv_groups
self.head_dim = d_out // num_heads
self.group_size = num_heads // num_kv_groups # 每组共享的查询头数
# Query 投影:维度不变,仍为 num_heads * head_dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
# Key/Value 投影:维度缩减为 num_kv_groups * head_dim
self.W_key = nn.Linear(
d_in, num_kv_groups * self.head_dim, bias=qkv_bias)
self.W_value = nn.Linear(
d_in, num_kv_groups * self.head_dim, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
b, seq_len, _ = x.shape
# 线性投影
Q = self.W_query(x) # (b, seq_len, num_heads * head_dim)
K = self.W_key(x) # (b, seq_len, num_kv_groups * head_dim)
V = self.W_value(x) # (b, seq_len, num_kv_groups * head_dim)
# 拆分为多头形式
Q = Q.view(b, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(b, seq_len, self.num_kv_groups, self.head_dim).transpose(1, 2)
V = V.view(b, seq_len, self.num_kv_groups, self.head_dim).transpose(1, 2)
# Q: (b, num_heads, seq_len, head_dim)
# K, V: (b, num_kv_groups, seq_len, head_dim)
# 扩展 K/V 以匹配查询头数
K = K.repeat_interleave(self.group_size, dim=1)
V = V.repeat_interleave(self.group_size, dim=1)
# K, V: (b, num_heads, seq_len, head_dim)
# 缩放点积注意力 + 因果掩码
scale = self.head_dim ** 0.5
attn_scores = Q @ K.transpose(-2, -1) / scale
mask = torch.triu(
torch.ones(seq_len, seq_len, device=x.device, dtype=torch.bool),
diagonal=1
)
attn_scores = attn_scores.masked_fill(mask, float("-inf"))
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 加权求和并合并多头
context = (attn_weights @ V).transpose(1, 2).contiguous()
context = context.view(b, seq_len, -1) # (b, seq_len, d_out)
return self.out_proj(context)代码要点解读:
- 两个 assert 约束:
d_out必须被num_heads整除(保证每个头维度为整数);num_heads必须被num_kv_groups整除(保证每组包含相同数量的查询头)。 - W_key 和 W_value 的输出维度为
num_kv_groups * head_dim,而非num_heads * head_dim——这是 GQA 节省参数和 KV 缓存的根源。 - repeat_interleave 位于注意力计算之前,将 KV 从
(b, num_kv_groups, ...)扩展到(b, num_heads, ...),使后续的矩阵乘法无需任何改动。 - out_proj 保持不变——多头注意力的输出拼接维度仍为
d_out,GQA 不影响输出投影。
6.2.5 KV 缓存内存估算
图 6-7:MHA、GQA、MQA 三种注意力机制的头结构对比。从 MHA 到 GQA 再到 MQA,KV 头数逐步减少,内存效率逐步提升。
KV 缓存的总字节数可以用以下公式精确计算:
其中各符号含义如下:
| 符号 | 含义 |
|---|---|
| batch size | |
Transformer 层数(n_layers) | |
序列长度(context_length) | |
每个头的维度(emb_dim / n_heads) | |
KV 头数(MHA 为 n_heads,GQA 为 n_heads / num_kv_groups) | |
| Key 和 Value 两个缓存 | |
| 每个元素的字节数(bf16/fp16 为 2,fp32 为 4) |
对于 MHA,
6.2.6 MHA vs GQA 内存对比
以一个典型的中大规模模型配置为例进行对比计算:
模型配置: emb_dim=4096,n_heads=32,n_layers=32,context_length=32768,batch_size=1,dtype=bf16(2 字节/元素),head_dim=128。
代入公式计算 MHA 的 KV 缓存:
对于 GQA(num_kv_groups=4,KV 头数为
| 配置 | KV 头数 | KV 缓存大小 | 相对 MHA 比例 | 节省比例 |
|---|---|---|---|---|
| MHA( | 32 | 17.18 GB | 1.00x | — |
| GQA( | 8 | 4.29 GB | 0.25x | 75.00% |
| GQA( | 4 | 2.15 GB | 0.125x | 87.50% |
| MQA( | 1 | 0.54 GB | 0.03x | 96.88% |
表 6-3:不同 KV 分组数下的 KV 缓存内存对比(emb_dim=4096, n_heads=32, n_layers=32, context_length=32768, bf16)。
从表中可以看出,仅需将 KV 分组数从 32(MHA)降至 4,KV 缓存便从 17.18 GB 骤降至 4.29 GB,节省了 75% 的内存。这 75% 的节省直接换算为:在相同的 GPU 显存预算下,可以支持 4 倍的上下文长度,或者 4 倍的 batch size,对推理吞吐量的提升是实质性的。
上述计算仅涉及 KV 缓存部分。在完整模型中,前馈网络(FFN)的参数和激活值通常占据更大比例的显存,因此整个模型层面的实际节省百分比会低于 75%。但由于 KV 缓存是随序列长度线性增长的动态开销,在长上下文推理场景下,GQA 的收益会越来越显著。
6.2.7 实际应用中的分组选择
主流开源模型的 GQA 配置反映了工程实践中的经验选择:
- Llama 2 70B:
n_heads=64,num_kv_groups=8(每组 8 个查询头共享 1 组 KV)。 - Llama 3 8B:
n_heads=32,num_kv_groups=4(每组 8 个查询头共享 1 组 KV)。 - Mistral 7B:
n_heads=32,num_kv_groups=4。
这些配置的共同特征是分组数
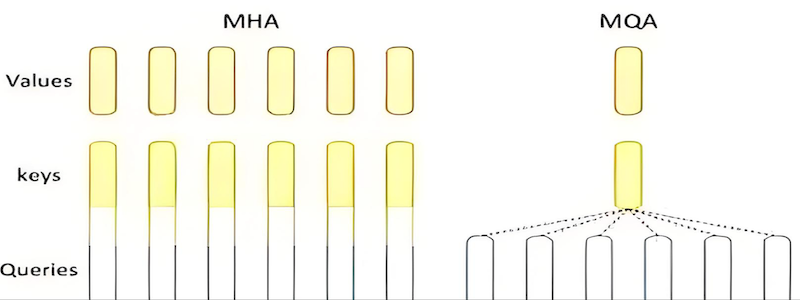
图 6-8:MQA(多查询注意力)与 GQA 的对比。MQA 是 GQA 的极端情况(G=1),所有 Query 头共享一组 KV,内存压缩最大但可能牺牲性能。
本节小结
本节介绍了分组查询注意力(GQA)的原理与实现:
- 核心思想:多个查询头共享同一组 Key/Value 投影,将 KV 缓存从
组压缩为 组,其中 为 KV 分组数。MHA( )和 MQA( )是 GQA 的两个极端特例。 - 投影维度变化:Query 投影不变(
),Key/Value 投影缩减为 ,参数量和 KV 缓存同比例缩减。 - 扩展机制:通过
repeat_interleave在注意力计算前将组 KV 扩展为 组,保证 Q/K/V 头维度对齐,后续计算逻辑与标准 MHA 完全一致。 - 内存收益:KV 缓存节省比例为
。在典型配置(4 分组、32 头、32768 上下文、bf16)下,KV 缓存从 17.18 GB 降至 4.29 GB,节省 75%。 - 工程实践:Llama 2/3、Mistral 等主流模型均采用 GQA,分组数通常为 4 或 8,在消融实验中表现出与 MHA 几乎无差异的建模性能。