6.5 MoE(混合专家)从零实现
标准 Transformer 中,每个 token 都要经过同一个前馈网络(FFN),所有参数在每次前向传播中全量激活。当模型规模从 7B 增长到 70B 乃至更大时,这种"稠密"架构的训练和推理成本都以参数量线性增长。混合专家(Mixture of Experts, MoE)提供了一种截然不同的扩展路径:用多个并行的小型 FFN(专家)替换单一的大型 FFN,每个 token 只激活其中少数几个专家。这样,模型的总参数量(即知识容量)可以大幅增加,而每个 token 实际使用的计算量和激活参数量保持可控。以 DeepSeek-V3 为例,其总参数量为 671B,但每个 token 推理时仅激活 37B 参数——不到总量的 6%。
本节将从几何直觉出发,逐步构建一个完整的 MoE 层(含路由器、路由专家和共享专家),并分析其参数效率。
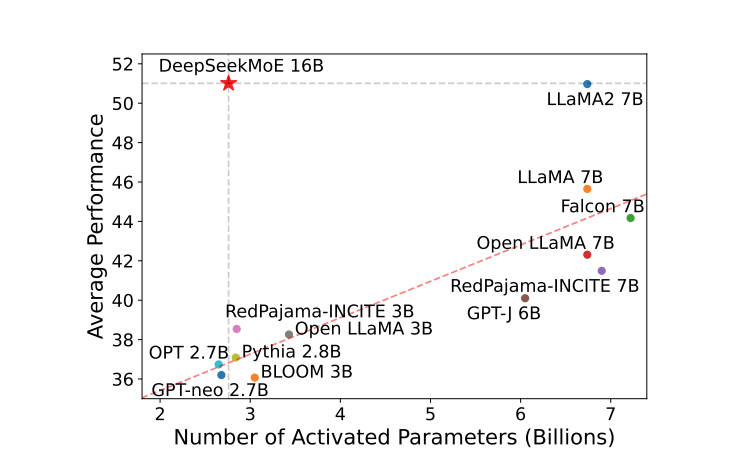
图 6-16:MoE 架构概览。路由器为每个 token 选择最相关的 Top-K 专家,未被选中的专家不参与计算,实现以极低激活比使用大量总参数。
6.5.1 从单一 FFN 到多专家 FFN
稠密 FFN 的等价拆分。 回顾标准 FFN 的前向计算:对于输入
其中
每个小 FFN(输出为
稀疏激活的核心思想。 MoE 的关键一步是:既然
6.5.2 路由机制:从 logits 到 Top-K 选择
路由器的结构。 路由器的输入是 token 的隐藏表示
其中
Top-K 选择。 对
MoE 层的最终输出为选中专家的加权和:
关于激活函数的选择。 从几何视角来看,
路由是逐 token 进行的。 需要特别强调:专家的选择对序列中的每个 token 独立进行,而非对整个序列统一选择。同一个序列中,不同位置的 token 可能激活完全不同的专家组合。
下面实现路由器。它的结构极其简单——一个线性层加上 Top-K 选择:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Router(nn.Module):
"""路由器:为每个 token 选择 top_k 个专家。"""
def __init__(self, d_model: int, num_experts: int, top_k: int):
super().__init__()
self.top_k = top_k
self.gate = nn.Linear(d_model, num_experts, bias=False)
def forward(self, x: torch.Tensor):
# x: (batch, seq_len, d_model)
router_logits = self.gate(x) # (batch, seq_len, num_experts)
# 选出 top_k 个专家的索引和对应 logits
topk_logits, topk_indices = torch.topk(
router_logits, self.top_k, dim=-1
) # 均为 (batch, seq_len, top_k)
# 将选中专家的 logits 归一化为权重
topk_weights = F.softmax(topk_logits, dim=-1)
return topk_weights, topk_indicesRouter 的输出有两个张量:topk_weights 是形状为 (batch, seq_len, top_k) 的权重矩阵,topk_indices 是同形状的专家索引矩阵。后续 MoE 层将根据这两个张量分发 token 到对应专家。
6.5.3 专家网络
每个专家本质上就是一个小型 FFN。为了与现代 LLM 保持一致,这里使用 SwiGLU 激活函数(参见 §3.2):
class Expert(nn.Module):
"""单个专家:一个 SwiGLU FFN。"""
def __init__(self, d_model: int, d_intermediate: int):
super().__init__()
self.w_gate = nn.Linear(d_model, d_intermediate, bias=False)
self.w_up = nn.Linear(d_model, d_intermediate, bias=False)
self.w_down = nn.Linear(d_intermediate, d_model, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# SwiGLU: down(silu(gate(x)) * up(x))
return self.w_down(F.silu(self.w_gate(x)) * self.w_up(x))每个专家的参数量为
6.5.4 共享专家:始终激活的通用模式学习器
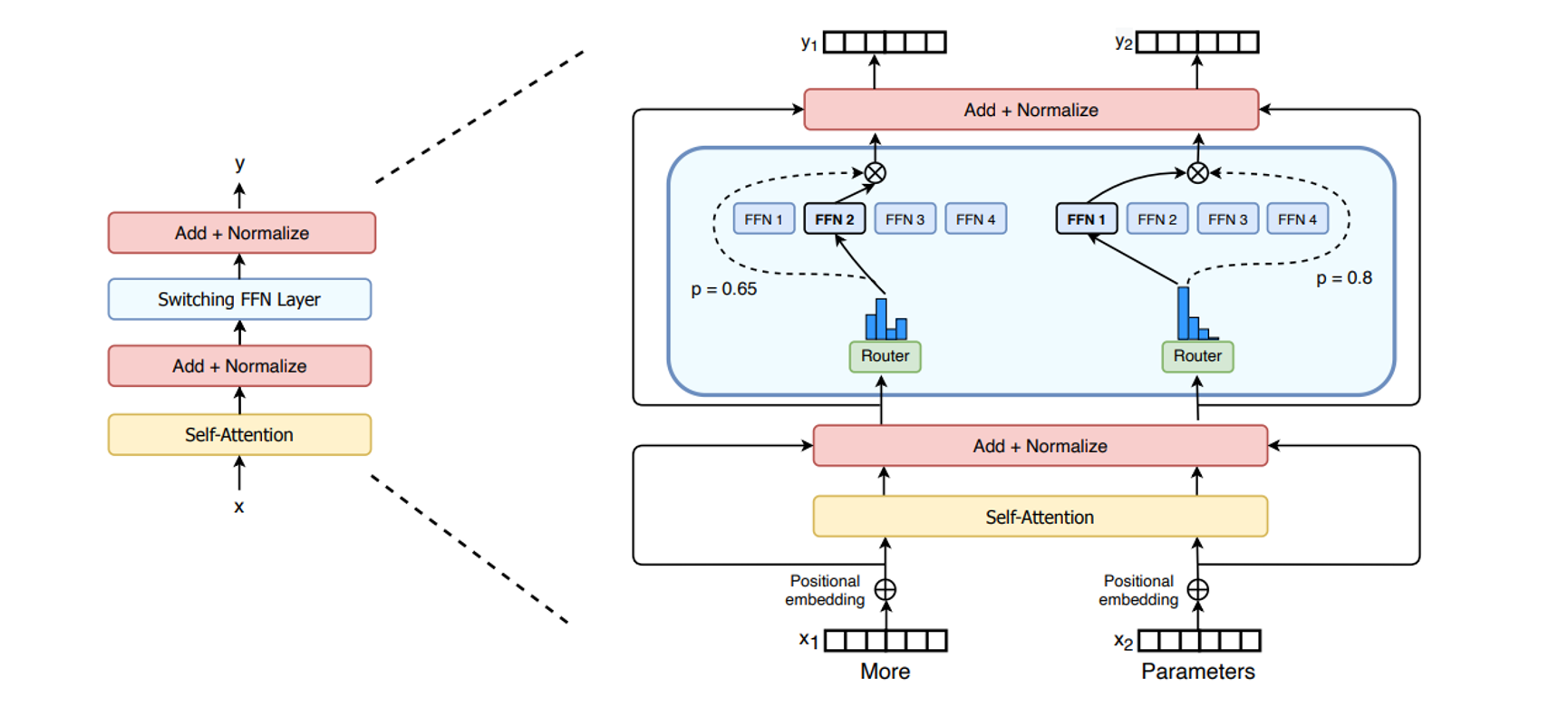
图 6-17:MoE 的基本概念。路由器为每个 token 计算专家亲和力分数,选择 Top-K 个专家进行加权计算,未被选中的专家不参与前向传播。
在纯路由 MoE 中,所有专家都通过 Top-K 选择来激活。这意味着一些在所有 token 中普遍出现的基础模式(如语法结构、常用表达)必须被多个专家重复学习,造成参数浪费。
共享专家(Shared Expert) 的思路很直接:指定若干个专家为"共享专家",它们对每一个 token 都强制激活,不参与路由选择。剩余的专家称为"路由专家(Routed Expert)",仍然通过 Top-K 动态选择。
从几何角度理解,共享专家相当于一个公共基底向量,吸收了所有 token 的共有基础特征。路由专家只需拟合减去这一公共成分后的残差,残差向量之间更容易满足正交性假设,从而使路由策略更接近理论最优。
实验也验证了这一直觉:在 DeepSpeed-MoE 和 DeepSeekMoE 的消融实验中,引入共享专家后模型整体性能显著优于无共享专家的版本。这是因为共享专家承担了通用模式的学习任务,使路由专家有更多"容量"去学习更专业化的知识。
以 DeepSeek-V3 为例,它有 1 个共享专家和 256 个路由专家,每个 token 从路由专家中选择 8 个,加上 1 个共享专家,共 9 个专家同时活跃。
共享专家的实现非常简单——它就是一个普通的 Expert,只是在 MoE 层中被无条件调用:
class SharedExpert(nn.Module):
"""共享专家:始终激活,学习通用模式。"""
def __init__(self, d_model: int, d_intermediate: int):
super().__init__()
self.ffn = Expert(d_model, d_intermediate)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.ffn(x)6.5.5 完整 MoE 层实现
现在将路由器、路由专家和共享专家组合为一个完整的 MoE 层。前向传播的核心逻辑是:(1) 共享专家处理所有 token;(2) 路由器为每个 token 选择 Top-K 路由专家;(3) 将每个 token 分发到对应的路由专家,加权求和后与共享专家的输出相加。
class MoELayer(nn.Module):
"""
完整的 MoE 层,包含共享专家和路由专家。
Args:
d_model: 隐藏维度
d_intermediate: 每个专家的中间维度
num_experts: 路由专家数量
top_k: 每个 token 激活的路由专家数
num_shared_experts: 共享专家数量(默认 1)
"""
def __init__(
self,
d_model: int,
d_intermediate: int,
num_experts: int,
top_k: int,
num_shared_experts: int = 1,
):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.num_shared_experts = num_shared_experts
# 路由器
self.router = Router(d_model, num_experts, top_k)
# 路由专家
self.experts = nn.ModuleList(
[Expert(d_model, d_intermediate) for _ in range(num_experts)]
)
# 共享专家
self.shared_experts = nn.ModuleList(
[Expert(d_model, d_intermediate) for _ in range(num_shared_experts)]
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: (batch, seq_len, d_model)
batch_size, seq_len, d_model = x.shape
# ---------- 共享专家:所有 token 无条件通过 ----------
shared_out = sum(expert(x) for expert in self.shared_experts)
# ---------- 路由专家:按 Top-K 选择性激活 ----------
topk_weights, topk_indices = self.router(x)
# topk_weights: (batch, seq_len, top_k)
# topk_indices: (batch, seq_len, top_k)
# 展平 batch 和 seq_len 维度,方便按专家分发
x_flat = x.view(-1, d_model) # (batch * seq_len, d_model)
weights_flat = topk_weights.view(-1, self.top_k) # (batch * seq_len, top_k)
indices_flat = topk_indices.view(-1, self.top_k) # (batch * seq_len, top_k)
# 初始化路由专家的输出
routed_out = torch.zeros_like(x_flat) # (batch * seq_len, d_model)
# 逐专家处理:收集分配到该专家的所有 token,批量计算
for expert_idx in range(self.num_experts):
# 找出所有选中了该专家的 (token, slot) 对
# mask: (batch * seq_len, top_k) 布尔矩阵
mask = indices_flat == expert_idx
if not mask.any():
continue
# 获取选中该专家的 token 索引和对应权重
token_indices = mask.any(dim=-1).nonzero(as_tuple=True)[0]
expert_weights = (weights_flat * mask.float()).sum(dim=-1)[token_indices]
# expert_weights: (num_selected_tokens,)
# 批量通过该专家
expert_input = x_flat[token_indices] # (num_selected, d_model)
expert_output = self.experts[expert_idx](expert_input) # (num_selected, d_model)
# 加权累加到输出
routed_out[token_indices] += expert_weights.unsqueeze(-1) * expert_output
routed_out = routed_out.view(batch_size, seq_len, d_model)
# ---------- 合并共享专家和路由专家的输出 ----------
return shared_out + routed_out代码要点解读:
- 逐专家遍历而非逐 token 遍历。 如果对每个 token 逐一选择并调用对应专家,会导致大量零散的小矩阵运算,GPU 利用率极低。正确做法是对每个专家,先收集所有分配到该专家的 token,拼成一个批次后统一送入专家网络。这样每个专家只需一次前向传播,充分利用矩阵乘法的并行性。
- 权重提取。 一个 token 可能在
top_k个 slot 中的某一个选中了当前专家,需要从weights_flat中提取出对应的权重值。这里通过(weights_flat * mask.float()).sum(dim=-1)实现——mask标记了哪些 slot 选中了当前专家,乘以权重后在 slot 维度求和即得该 token 对当前专家的路由权重。 - 共享专家与路由专家的输出直接相加。 在 DeepSeek-V3 等实际模型中,有时会引入一个缩放因子来平衡两者的贡献。为简洁起见,这里采用直接相加。
6.5.6 参数效率分析
MoE 的核心优势在于:总参数量大,但每个 token 的激活参数量小。下面以具体数字说明这一点。
配置示例:
单个专家的参数量:
总参数量(256 路由 + 1 共享 + 路由器):
每个 token 的激活参数量(8 路由 + 1 共享 + 路由器):
激活比例:
| 指标 | 稠密 FFN(等参数) | MoE(256 专家,激活 8 个) |
|---|---|---|
| 总参数量 | 11.3B | 11.3B |
| 每 token 激活参数量 | 11.3B | ~0.4B |
| 每 token 计算量比例 | 100% | ~3.5% |
| 显存占用(推理加载全部参数) | 11.3B 参数 | 11.3B 参数(不变) |
表 6-6:稠密 FFN 与 MoE 的参数效率对比(d_model=7168, d_intermediate=2048, 256 路由专家 + 1 共享专家, top_k=8)。
核心权衡。 MoE 在计算效率上的优势是巨大的——相同的总知识容量,每个 token 的计算成本降低到不足 4%。但显存占用并没有减少:推理时所有 257 个专家的参数都需要加载到显存中,因为任意 token 都可能激活任意专家。这也是 MoE 模型在推理部署时面临的核心挑战:671B 总参数的 DeepSeek-V3 需要分布在多张 GPU 上,不是因为计算量大,而是因为参数存储量大。
更一般地,当路由专家数为
路由组合的多样性。 256 个专家中选 8 个,组合数为
6.5.7 负载均衡问题
在完全自由的路由下,模型很容易陷入专家坍缩:少数几个专家被频繁激活,其余大量专家长期闲置("死专家")。这不仅浪费了参数容量,还会导致被热点专家处理的 token 排队等待,形成计算瓶颈。
解决负载均衡的经典方法是引入辅助损失(Auxiliary Loss)。定义每个专家的实际被选频率为
其中
DeepSeek-V3 进一步提出了 Loss-Free 负载均衡:不再使用辅助损失,而是为每个专家引入一个输入无关的偏置项
负载均衡的具体实现超出本节"从零实现"的范畴,但理解其必要性对于实际部署 MoE 模型至关重要。
6.5.8 完整示例:MoE 替换 Transformer 中的 FFN
图 6-18:MoE 专家路由的实际分布。不同 token 被路由到不同专家,理想情况下各专家的负载应大致均衡,以避免热点专家成为瓶颈。
将 MoE 层集成到 Transformer Block 中只需将 FFN 替换为 MoELayer:
class TransformerBlockWithMoE(nn.Module):
def __init__(self, cfg):
super().__init__()
self.norm1 = nn.RMSNorm(cfg["d_model"])
self.att = MultiHeadAttention(cfg) # 注意力层不变
self.norm2 = nn.RMSNorm(cfg["d_model"])
self.moe = MoELayer(
d_model=cfg["d_model"],
d_intermediate=cfg["d_intermediate"],
num_experts=cfg["num_experts"],
top_k=cfg["top_k"],
num_shared_experts=cfg["num_shared_experts"],
)
def forward(self, x):
# Pre-Norm + Attention + Residual
x = x + self.att(self.norm1(x))
# Pre-Norm + MoE + Residual
x = x + self.moe(self.norm2(x))
return x与标准 Transformer Block 的唯一区别是 self.ff = FeedForward(...) 变为 self.moe = MoELayer(...)。注意力层、残差连接、层归一化全部保持不变。MoE 对 Transformer 架构的侵入性很小——它是一个即插即用的模块替换。
下面用一个简单的例子验证整个 MoE 层的前向传播:
if __name__ == "__main__":
torch.manual_seed(42)
# 配置
d_model = 512
d_intermediate = 1024
num_experts = 8
top_k = 2
num_shared_experts = 1
# 创建 MoE 层
moe = MoELayer(d_model, d_intermediate, num_experts, top_k, num_shared_experts)
# 模拟输入: batch=2, seq_len=10, d_model=512
x = torch.randn(2, 10, d_model)
y = moe(x)
print(f"输入形状: {x.shape}") # (2, 10, 512)
print(f"输出形状: {y.shape}") # (2, 10, 512)
# 参数统计
total_params = sum(p.numel() for p in moe.parameters())
expert_params = sum(p.numel() for p in moe.experts[0].parameters())
router_params = sum(p.numel() for p in moe.router.parameters())
shared_params = sum(p.numel() for p in moe.shared_experts.parameters())
active_params = top_k * expert_params + shared_params + router_params
print(f"\n总参数量: {total_params:,}")
print(f"路由器参数量: {router_params:,}")
print(f"单个专家参数量: {expert_params:,}")
print(f"共享专家参数量: {shared_params:,}")
print(f"每 token 激活参数: {active_params:,}")
print(f"激活比例: {active_params / total_params:.1%}")运行输出:
输入形状: torch.Size([2, 10, 512])
输出形状: torch.Size([2, 10, 512])
总参数量: 14,159,872
路由器参数量: 4,096
单个专家参数量: 1,572,864
共享专家参数量: 1,572,864
每 token 激活参数: 4,722,688
激活比例: 33.4%在这个小规模示例中(8 个路由专家,激活 2 个),激活比例约为 33%。随着专家数量增加和激活比例降低,稀疏性带来的效率优势会越来越明显:256 个专家激活 8 个时,激活比例降至约 3.5%。
图 6-19:MoE 路由机制。输入 token 的隐藏状态经路由器计算各专家的亲和力分数,选择 Top-K 专家进行加权计算。
本节小结
本节从几何直觉出发,完整实现了一个包含路由器、路由专家和共享专家的 MoE 层:
- 核心思想:将单一的大型 FFN 拆分为多个并行的小型 FFN(专家),每个 token 通过路由器选择 Top-K 个专家进行计算。模型的总参数量(知识容量)大幅增加,而每个 token 的实际计算量保持可控。
- 路由机制:路由器是一个线性投影层
,输出每个专家的打分(router logits)。通过 Top-K 选择确定激活的专家索引,再对选中专家的打分做 Softmax 归一化得到加权系数。路由对序列中的每个 token 独立进行。 - 共享专家:指定若干专家对所有 token 始终激活,负责学习通用模式(语法结构、常用表达等)。路由专家则专注于拟合去除公共成分后的残差,专业化程度更高。
- 参数效率:256 个路由专家仅激活 8 个时,每 token 计算量约为总量的 3.5%。细粒度切分(更多更小的专家)在保持总计算量不变的前提下,将路由组合数从数十种提升至数万亿种。
- 核心权衡:MoE 以稀疏激活大幅降低计算成本,但显存占用不变(所有专家参数都需加载),且需要负载均衡机制(辅助损失或 Loss-Free 偏置)防止专家坍缩。