16.5 其他偏好优化算法
前几节我们深入讨论了 PPO、DPO 和 GRPO 三大主线。然而,偏好优化算法的发展远不止于此——围绕这三条主线,社区衍生出了大量变体和全新思路。它们有的从 REINFORCE 回归简洁,有的从 前景理论出发放宽数据要求,有的从 优化粒度和聚合方式 入手解决 GRPO 的固有缺陷。本节按照算法之间的继承关系组织:先介绍独立于 GRPO 体系的三类方法(RLOO、KTO、ORPO),再回到 GRPO 族谱,沿 聚合方式改进 → 工程优化 → 粒度提升 → 长度控制 → 对抗学习 的脉络逐一展开 GMPO、DAPO、GSPO、GFPO、GAPO 等算法,最后补充 OnlineDPO、CPO、BCO 等其他常见训练器。
16.5.1 RLOO:回归 REINFORCE 的简洁
RLOO(REINFORCE Leave-One-Out) 的核心主张是:在 RLHF 场景下,PPO 中许多复杂组件(价值模型、GAE、多轮 epoch)并非必要。回到最朴素的 REINFORCE 风格,反而能以更低的计算成本获得更好的效果。
算法思路。 对每个 prompt
优势估计为
损失函数。 在纯在线(单步更新)设定下,RLOO 的损失就是标准 REINFORCE:
如果进行多步梯度更新(数据变为离策略),则引入 PPO 风格的裁剪:
与 GRPO 的区别。 RLOO 和 GRPO 都采用多回答采样 + 无价值模型的设计,但 RLOO 的优势估计使用留一法基线(每个样本的基线不同),而 GRPO 使用组内均值和标准差做 z-score 标准化(所有样本共享同一基线)。RLOO 保持序列级操作,不展开到 token 级;GRPO 则在每个 token 上计算重要性采样比。
关键优势:
- 无需价值模型,显存占用与 GRPO 相当
- 实现极简,可直接用 TRL 的
RLOOTrainer上手 - 在 1B 到 72B 规模均有验证,支持 vLLM 加速生成
快速上手。 以下是使用 TRL 库训练 RLOO 模型的最小示例:
from datasets import load_dataset
from trl import RLOOTrainer
from trl.rewards import accuracy_reward
# 加载数据集(仅需 prompt 列)
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
# 创建 RLOO 训练器:指定模型、奖励函数和数据集即可
trainer = RLOOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=accuracy_reward, # 基于规则的正确性奖励
train_dataset=dataset,
)
trainer.train()只需一个模型、一个奖励函数和一个 prompt 数据集,RLOO 就能完成在线 RL 训练——这是目前入门成本最低的在线强化学习方案之一。
16.5.2 KTO:只需二进制反馈
KTO(Kahneman-Tversky Optimization) 的出发点是:现实中获取偏好对(chosen vs. rejected)的成本很高,但获取 "这个回答好不好" 的二进制信号要容易得多——用户的点赞/点踩就够了。
理论基础。 KTO 借鉴行为经济学中 Kahneman 和 Tversky 的 前景理论(Prospect Theory):人类对损失的敏感度高于对同等收益的敏感度(损失厌恶),且对概率的感知是非线性的。KTO 将这些偏差显式建模到损失函数中,用 Kahneman-Tversky 效用函数替代标准的对数似然。
数据要求。 KTO 只需要 非配对偏好数据(unpaired preference):每条数据包含一个 prompt、一个回答,以及一个二进制标签
与 DPO 的对比:
| 特性 | DPO | KTO |
|---|---|---|
| 数据格式 | 配对 | 非配对 |
| 理论基础 | Bradley-Terry 偏好模型 | Kahneman-Tversky 前景理论 |
| 参考模型 | 需要 | 需要 |
| 数据获取难度 | 高(需配对标注) | 低(点赞/点踩即可) |
| 规模验证 | 1B-30B | 1B-30B |
损失函数直觉。 KTO 的核心思想是:对于"好回答"(desirable),最大化其相对于参考模型的隐式奖励
实践要点。 使用 KTO 时需注意:(1)每步 batch size 至少为 4,有效 batch size 在 16-128 之间——batch 太小会导致 KL 估计不准确;(2)学习率不宜超过 desirable_weight 和 undesirable_weight 参数进行补偿,使加权后的正负比例保持在 1:1 到 4:3 之间。
16.5.3 ORPO:无参考模型的一体化优化
ORPO(Odds Ratio Preference Optimization,赔率比偏好优化) 更进一步——不仅不需要奖励模型,连参考模型也不需要。它将 SFT 和偏好对齐合并为一个训练阶段。
核心思路。 ORPO 发现,在偏好对齐的 SFT 过程中,只需对不良生成风格施加一个 轻微惩罚 就足以实现偏好对齐。具体做法是在标准的 NLL(负对数似然)损失后面追加一个基于 赔率比(odds ratio) 的对比项:
其中赔率比项利用 chosen 和 rejected 回答的对数概率比来区分好坏风格。这个设计使得一次训练就能同时完成 SFT 和偏好对齐,省去了独立的对齐阶段。
赔率比的含义。 在统计学中,赔率(odds)定义为事件发生的概率除以不发生的概率:
关键优势:
- 无参考模型:不需要冻结一份参考模型,显存占用最低
- 单阶段训练:SFT + 偏好对齐一步完成,工程流程最简
- 在 Phi-2 (2.7B)、Llama-2 (7B)、Mistral (7B) 上均有验证
- 在 AlpacaEval 2.0 上达到 12.20%,IFEval 上达到 66.19%
16.5.4 SPO:自适应 baseline 的单流优化
SPO(Self-Play Preference Optimization) 属于"在线自博弈"范式。模型在每轮训练中与自身的历史版本对弈,通过自适应 baseline 来估计优势。与 GRPO 需要固定组大小不同,SPO 的 baseline 随训练动态调整——当模型能力提升时,baseline 相应提高,避免了"刷简单题得高分"的退化现象。
SPO 的关键设计是 单流架构(single-stream):同一个模型既充当策略(生成回答)又充当对手(提供比较基准),通过维护一个历史性能的 移动平均值 作为自适应 baseline。这种设计使得 SPO 不需要额外维护参考模型或价值模型,同时避免了固定组大小带来的采样效率问题。
16.5.5 VAPO:价值增强的 PPO
回到 value-based(基于价值模型) 这条路线。GRPO/DAPO 等 value-free 方法虽然省去了 Critic,但代价是丧失了 细粒度信用分配(credit assignment) 能力——整句共享同一个优势值
VAPO(Value-based Augmented PPO) 针对长链推理(long CoT)场景,保留价值模型并系统解决其三大痛点:
- 价值模型偏差(Value Model Bias):价值模型估计的
常常出现系统性偏高或偏低,导致 GAE 算出的优势 失真。VAPO 通过在训练数据中混入不同难度和长度的样本(数据增强),并对 施加正则化,约束其输出范围,从而减轻偏差。 - 异质序列长度(Heterogeneous Sequence Lengths):推理任务中,正确回答可能只有 50 个 token,错误回答可能有 2000 个 token。如果不做处理,长序列的梯度累积量远大于短序列,导致短序列的学习信号被淹没。VAPO 对不同长度的序列做归一化处理,确保梯度贡献的公平性。
- 稀疏奖励(Sparse Rewards):数学推理任务中,奖励通常只在最终答案处给出(0 或 1),中间步骤没有任何反馈。VAPO 结合 过程奖励(process reward) 或回报塑形技术,在推理链的中间步骤提供辅助信号——例如,当模型完成一个正确的中间推导时给予小额正奖励。
VAPO 仍使用 PPO 的 clip 目标与 GAE,但这些针对性设计使其在推理任务上表现卓越——基于 Qwen 32B,在 AIME 2024 达到 60.4 分,优于 DeepSeek-R1-Zero 和 DAPO 超过 10 分,且 5000 步内收敛、全程无训练崩溃。VAPO 的成功证明了一个重要观点:value-based 方法并非不可用于长链推理,关键是解决其固有的工程挑战。
value-based vs. value-free 的权衡:
| value-based (PPO/VAPO) | value-free (GRPO/DAPO) | |
|---|---|---|
| 信用分配 | 逐 token,精细 | 整句,粗糙 |
| 显存占用 | 高(需价值模型) | 低 |
| 适用场景 | 长 CoT、中间步骤很重要 | 可验证奖励(数学、代码) |
| 训练稳定性 | 依赖价值模型质量 | 依赖组采样质量 |
16.5.6 GMPO:几何均值替代算术均值
从这里开始,我们进入 GRPO 的变体族谱。回顾 GRPO 的聚合方式:对一个回答
其中
GMPO(Geometric-Mean Policy Optimization) 将算术平均替换为 几何平均:
取绝对值后开
为什么更稳定? 考虑一个简单例子:4 个 token 的 clip 后值为
关键设计。 GMPO 同时放宽了 clip 范围至
16.5.7 DAPO:三项工程优化
DAPO(Dynamic sampling Policy Optimization) 由字节跳动提出,是 GRPO 最有影响力的工程优化变体。基于 Qwen2.5-32B,在 AIME 2024 达到 50 分,仅用 50% 的训练步骤就超越了 DeepSeek-R1-Zero(47 分)。DAPO 在 GRPO 的框架上做了三处针对性改进:
(1)Clip-Higher(非对称裁剪)。 标准 PPO/GRPO 使用对称的 clip 区间
为什么这有用?考虑一个正确路径上原本概率很低的 token(
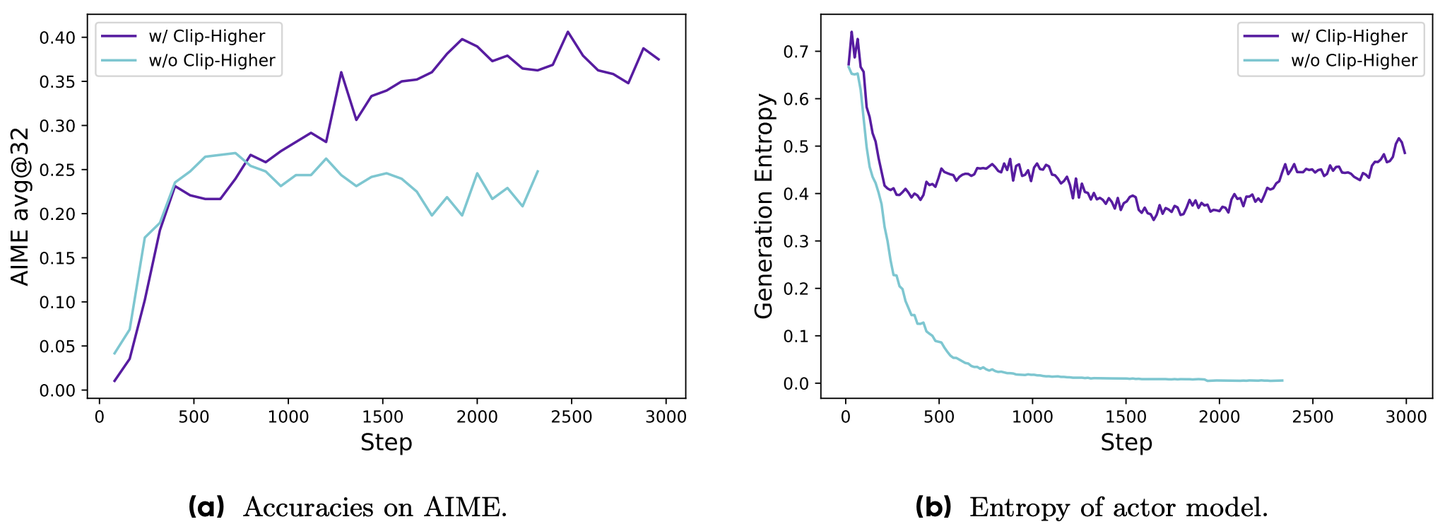
图 16-9:DAPO Clip-Higher 的效果。左图为 AIME 准确率,右图为策略熵。使用 Clip-Higher 后熵保持在健康水平,模型持续探索和提升;不使用时熵迅速坍塌至接近零,模型丧失探索能力。
(2)Dynamic Sampling(动态采样)。 当某个 prompt 的所有
虽然需要采样更多数据,但因为每个 batch 的有效梯度更强,总训练步数反而减少,整体收敛时间缩短。
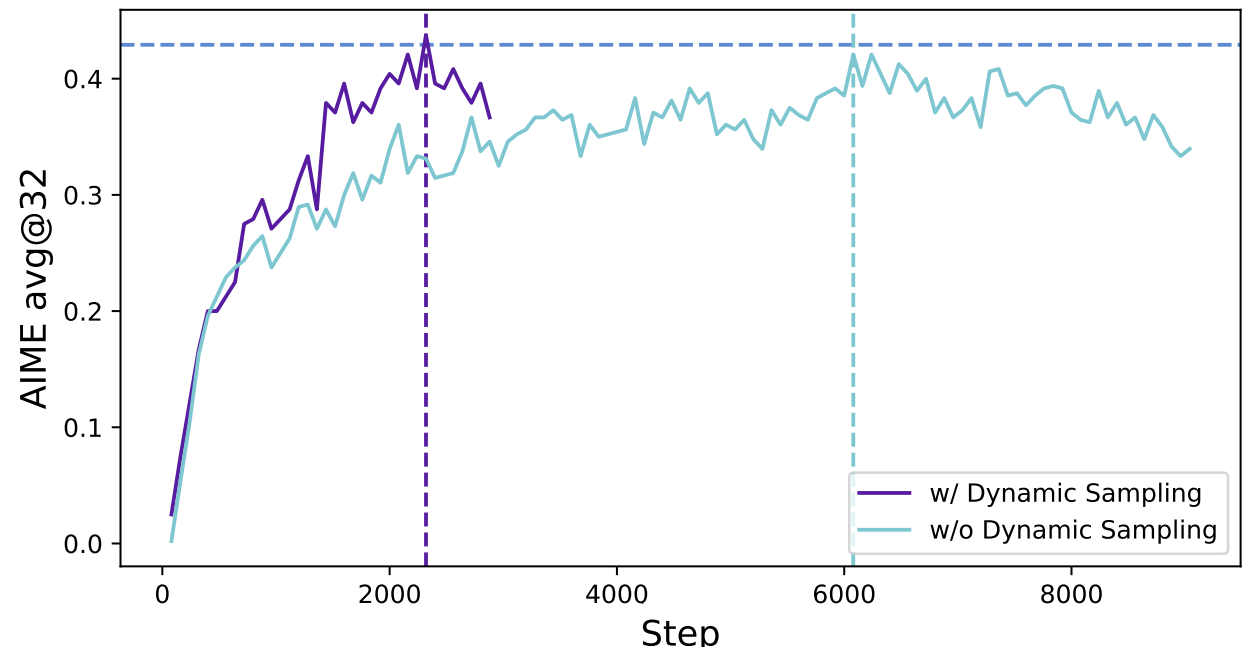
图 16-10:DAPO Dynamic Sampling 的效果。紫色线在约 2500 步处达到的准确率,浅蓝线需要约 6000 步才能接近,且最终性能更低。
(3)Token 级长度归一化。 GRPO 对每个回答按
这样不同长度的回答中,每个 token 对梯度的贡献都是均等的,缓解了长度偏差。
完整 DAPO 目标函数:
性能消融。 以下消融实验展示了每项改进的独立贡献(基于 Qwen2.5-32B,AIME 2024 avg@32):
| 配置 | 得分 | 增益 |
|---|---|---|
| 朴素 GRPO | 30 | — |
| + 超长过滤 | 36 | +6 |
| + Clip-Higher | 38 | +2 |
| + 软超长惩罚 | 41 | +3 |
| + Token 级损失 | 42 | +1 |
| + 动态采样(完整 DAPO) | 50 | +8 |
动态采样的贡献最大(+8 分),这验证了"有效梯度比数据量更重要"的核心洞察。
16.5.8 GSPO:序列级优化
GSPO(Group Sequence Policy Optimization) 由 Qwen 团队提出,直接服务于 Qwen3 系列模型的 RL 训练。GSPO 的出发点是一个深层的理论问题:GRPO 中 token 级重要性采样权重在本质上是失效的。
核心问题诊断。 重要性采样要求从行为分布中采样 多个样本 才能有效修正分布偏差。但 GRPO 在每个 token 位置
解决方案。 既然奖励是授予整个序列的,优化也应在序列级进行。GSPO 定义序列级重要性比率:
取
梯度对比。 省略 clipping 后,GSPO 的梯度为:
注意内层求和中,所有 token 的
Clipping 范围的反直觉发现。 GSPO 的 clipping 范围仅为
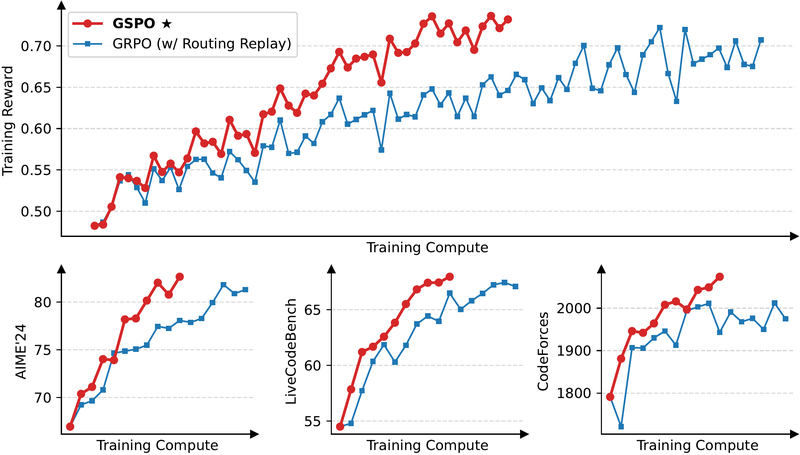
图 16-11:GSPO 与 GRPO 的训练对比(基于 Qwen3-30B-A3B)。上方为训练奖励曲线,GSPO(红色)全程领先;下方为三个基准的表现,GSPO 在 AIME'24(~83 vs ~81)、LiveCodeBench(~68 vs ~64)、CodeForces Elo(~2050 vs ~1950)上均占优。
对 MoE 模型的独特优势。 MoE 模型的稀疏激活特性使 token 级方法的问题更加严重——每次梯度更新后,约 10% 的被激活专家发生变化,导致
GSPO 完全不需要路由回放——它只关注序列似然
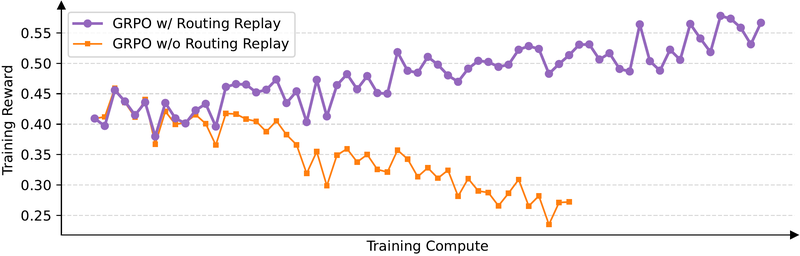
图 16-12:MoE 模型上的训练稳定性。不使用 Routing Replay 的 GRPO(橙色)从约 0.42 持续下降至约 0.27,呈明显崩溃趋势;使用 Routing Replay 的 GRPO(紫色)才能稳定上升。GSPO 则无需此类技巧即可稳定训练。
DAPO vs. GSPO。 两者都是 GRPO 的改进,但切入角度完全不同:
| DAPO | GSPO | |
|---|---|---|
| 优化粒度 | Token 级 | 序列级 |
| 改进方式 | 工程优化(clip、采样、归一化) | 理论修正(重要性采样粒度) |
| Clip 范围 | ||
| MoE 支持 | 需额外处理 | 天然支持 |
| 代表模型 | DAPO-Math-17K 实验 | Qwen3 系列 |
16.5.9 GFPO:过滤控长度
GFPO(Group Filtered Policy Optimization) 解决的是 GRPO 系算法的一个常见副作用——输出膨胀(output inflation):模型学会通过"写更长"来提高获得奖励的概率,导致生成冗余啰嗦的内容。
GFPO 的做法是在 GRPO 的基础上增加一个 过滤阶段:
- 对每个 prompt 采样更大的组(如
) - 按过滤策略筛选部分回答参与训练
常见过滤策略:
- Shortest-k:只取组内最短的
个正确回答,鼓励简洁 - Token Efficiency:按
(单位 token 奖励)排序,取效率最高的回答 - Adaptive Difficulty:根据当前模型能力动态调整过滤阈值
过滤等价于隐式的 奖励塑形(reward shaping)——不直接修改奖励函数,而是通过筛选训练样本来间接惩罚冗长。Phi-4-reasoning 等技术报告显示,GFPO 可抑制输出膨胀约 46-71%。
与 DAPO 的长度控制对比。 DAPO 通过超长奖励塑形(Overlong Reward Shaping)直接在奖励函数中惩罚过长输出,属于"显式惩罚";GFPO 通过过滤训练样本,属于"隐式选择"。两种策略可以叠加使用——先用 GFPO 过滤掉冗长样本,再用 DAPO 的奖励塑形进一步惩罚接近长度上限的输出。
16.5.10 GAPO:GAN + PPO 的对抗学习
GAPO(Generative Adversarial Policy Optimization) 走了一条完全不同的路——将 GAN(生成对抗网络)与 PPO 结合,用 encoder-only 的判别器(RM) 在对抗训练中学习细粒度约束。
适用场景。 当任务涉及 约束满足(如格式要求、关键词包含、长度限制)时,传统 RM 难以精确判别是否满足约束。GAPO 训练一个二分类 RM 判别"满足/不满足约束",然后在对抗循环中:
- Generator(策略) 生成回答,试图骗过 RM
- RM 判别回答是否满足约束,试图更准确
- 通过 PPO 目标将 RM 的判别信号注入策略更新
这种博弈机制使模型在细粒度约束遵循上优于 PPO、DPO 和 KTO。
训练流程。 GAPO 分为两阶段:(1)Warmup 阶段,用标注数据训练 encoder-only RM,使其学会区分满足/不满足约束的回答;(2)对抗阶段,交替更新策略(通过 PPO + RM 信号)和 RM(用策略的新生成数据),直到收敛。这种设计特别适合需要精确控制输出格式、关键词覆盖、字数限制等场景。
16.5.11 OnlineDPO、CPO 与 BCO
除上述算法外,还有几种常见的偏好优化训练器值得了解:
Online DPO(在线 DPO)。 标准 DPO 使用离线收集的偏好数据,存在两个问题:(1)偏好数据通常来自与当前模型不同的模型,存在分布偏移;(2)数据在训练前收集且不再更新,模型能力提升后数据就过时了。Online DPO 在每轮训练中从当前模型采样两个回答,然后用 LLM 或奖励模型在线判断偏好,提供即时反馈。这种"边训练边生成数据"的方式确保了数据分布与当前模型始终一致。实验表明,在线反馈相比离线 DPO 有显著提升(例如在 TL;DR 摘要任务上,6.9B 模型的胜率从 70.1% 提升至 79.6%)。
CPO(Contrastive Preference Optimization,对比偏好优化)。 CPO 是 DPO 的一般化近似,最初为机器翻译任务设计。它的核心思路是弥补 SFT 的两个短板:(1)SFT 的性能上限受制于训练数据质量;(2)SFT 缺乏阻止模型犯错的机制。CPO 在 DPO 基础上增加了对 chosen 回答的 NLL 损失(BC 正则化),同时支持多种损失变体(sigmoid、hinge、IPO)。其变体 SimPO 使用长度归一化的平均对数概率作为隐式奖励,不需要参考模型——在 AlpacaEval 2 上相比 DPO 提升多达 6.4 分。
BCO(Binary Classifier Optimization,二分类器优化)。 BCO 训练一个二分类器,将
这三种方法与前述算法的定位有所不同:Online DPO 解决的是 数据新鲜度 问题,CPO/SimPO 解决的是 损失函数设计 问题,BCO 解决的是 数据分布不平衡 问题。在实际项目中,它们常常作为 DPO 的增强方案出现。
16.5.12 算法族谱与选型指南
经过本节的梳理,我们可以绘制出完整的偏好优化算法继承关系图:
策略梯度 / REINFORCE
├─→ RLOO(留一法基线,序列级,无 Critic)
└─→ PPO(clip + GAE + Critic)
├─→ VAPO(价值增强,推理 SOTA)
└─→ GRPO(组相对优势,无 Critic)
├─→ GMPO(几何平均聚合)
├─→ DAPO(非对称 clip + 动态采样 + 归一化)
├─→ GSPO(序列级优化,Qwen3 采用)
├─→ GFPO(过滤控长度)
└─→ Dr.GRPO / λ-GRPO(修正长度偏差)
DPO(独立分支:无 RM/RL,Bradley-Terry)
├─→ Online DPO(在线反馈)
├─→ CPO / SimPO(对比偏好 / 无参考模型)
└─→ KTO(非配对,前景理论)
ORPO(独立分支:无参考模型,SFT + 偏好一体化)
BCO(独立分支:二分类器优化)
GAPO(独立分支:GAN + PPO,约束学习)下表汇总了本节所有算法的核心属性对比:
| 算法 | 奖励模型 | 价值模型 | 参考模型 | 优化粒度 | 主要创新点 |
|---|---|---|---|---|---|
| RLOO | 需 | 不需 | 需 | 序列 | 留一法基线,REINFORCE 简化 |
| KTO | 不需 | 不需 | 需 | 偏好 | 前景理论,仅需二进制标签 |
| ORPO | 不需 | 不需 | 不需 | 偏好 | 赔率比,SFT+对齐一体化 |
| VAPO | 需 | 需 | 需 | Token | 价值增强三机制,推理 SOTA |
| GMPO | 需 | 不需 | 需 | Token | 几何平均,抑制 outlier |
| DAPO | 需 | 不需 | 不需 | Token | 非对称 clip + 动态采样 + 归一化 |
| GSPO | 需 | 不需 | 需 | 序列 | 序列级重要性采样,适配 MoE |
| GFPO | 需 | 不需 | 需 | Token | 大组采样 + 过滤,控制长度 |
| GAPO | Encoder-only | 有 | 需 | Token | GAN + PPO,对抗约束学习 |
| Online DPO | 需 | 不需 | 需 | 偏好 | 在线反馈,解决分布偏移 |
| CPO/SimPO | 不需 | 不需 | 可选 | 偏好 | 对比损失 + BC 正则化 |
| BCO | 不需 | 不需 | 需 | 偏好 | 二分类器,底层分布匹配 |
面对如此多的选择,下表提供一个实用的选型指南:
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 通用 RLHF,资源充足 | PPO | 最成熟,生态最完整 |
| 推理 SOTA,可接受额外显存 | VAPO | 细粒度信用分配,长 CoT 最优 |
| 偏好数据充足,追求简单 | DPO / Online DPO | 无 RM、无 RL 循环 |
| 只有二进制反馈 | KTO | 不需要配对数据 |
| 一步训练,最小资源 | ORPO | 无参考模型,SFT + 对齐合一 |
| 可验证奖励(数学/代码) | GRPO / GMPO / DAPO | 无 Critic,组采样 |
| MoE 模型、序列级评估 | GSPO | 序列级优化,天然适配 MoE |
| 输出冗长、需控长度 | GFPO | 采样过滤,隐式惩罚冗余 |
| 细粒度约束遵循 | GAPO | 对抗学习,约束判别 |
小结
本节从 RLOO 的 REINFORCE 回归出发,经过 KTO 的二进制反馈、ORPO 的无参考模型设计,再到 GRPO 族谱中 GMPO(几何平均)、DAPO(工程三优化)、GSPO(序列级理论修正)、GFPO(长度过滤)、GAPO(对抗约束)等一系列变体,最后补充了 OnlineDPO/CPO/BCO 等常用训练器。这些算法并非孤立发展,而是围绕几个核心矛盾不断演进:有无价值模型(PPO/VAPO vs. GRPO 族)、优化粒度(token vs. 序列)、数据要求(配对偏好 vs. 二进制标签 vs. 可验证奖励)、训练稳定性(clip 设计、聚合方式、长度控制)。理解这些矛盾的本质,比记住每个算法的公式更重要——因为新算法还在不断涌现,但它们回答的始终是同一组问题。
一个值得注意的趋势是:工业界的选择正在收敛。DeepSeek-R1 选择 GRPO,Qwen3 选择 GSPO,字节选择 DAPO——这些选择背后的共同方向是"去掉价值模型 + 可验证奖励 + 大规模组采样"。对于从业者而言,掌握 GRPO 及其变体(DAPO/GSPO),再根据具体场景(数据类型、模型架构、资源预算)选择合适的辅助方法(KTO、ORPO、GFPO 等),是当前最实用的技术路线。