16.7 算法选型指南
经过前面六节的讨论,我们已经系统学习了 DPO、PPO、GRPO、DAPO、GSPO 等一系列后训练对齐算法。每种算法都有各自的设计哲学和适用边界——没有"万能药",只有"对症下药"。本节将从全局视角出发,梳理这些算法之间的继承与改进关系,在计算成本、训练稳定性、数据需求三个维度进行系统对比,并给出面向不同场景的选型建议。作为第四篇(对齐篇)的收尾,我们还将提供一个可运行的算法选择器函数,帮助读者在实战中快速定位合适的算法。
16.7.1 算法族谱:从策略梯度到序列级优化
理解算法选型的第一步,是厘清各算法之间的继承与改进关系。下面用一棵"族谱树"来呈现这一脉络:
策略梯度 (REINFORCE)
│
├── Actor-Critic
│ │
│ └── PPO (clip + GAE, 四模型, token 级)
│ │
│ ├── VAPO (价值增强 PPO, 推理 SOTA)
│ │
│ └── GRPO (去 Critic, 组相对优势)
│ │
│ ├── RLOO (leave-one-out 基线)
│ │
│ ├── DAPO (非对称 clip + 动态采样 + 归一化)
│ │
│ ├── GMPO (几何平均聚合, 抑制 outlier)
│ │
│ ├── Dr.GRPO (修正长度归一化偏差)
│ │
│ ├── GFPO (采样过滤, 控制输出长度)
│ │
│ └── GSPO (序列级重要性采样, 降方差)
│
└── DPO 分支 (无 RM/RL, Bradley-Terry 闭式解)
│
├── IPO (区间偏好优化)
├── KTO (知识蒸馏偏好优化)
└── SimPO (简化偏好优化)这棵族谱揭示了三条核心演化路径:
价值型路径(PPO → VAPO):保留 Critic(价值模型),通过改进价值估计来实现细粒度信用分配,适合需要精确定位"哪一步出错"的推理任务。代价是显存和算力开销最高。
去价值型路径(PPO → GRPO → DAPO/GSPO/GMPO 等):丢弃 Critic,用组内相对奖励替代价值估计。这一路径的演化重点是解决 GRPO 原始设计中的三大痛点——长度偏差、token 级噪声、MoE 不稳定。
无 RL 路径(DPO 及其变体):完全跳过在线采样和强化学习循环,将对齐问题转化为监督式分类损失。简洁高效,但受限于离线偏好数据的分布。
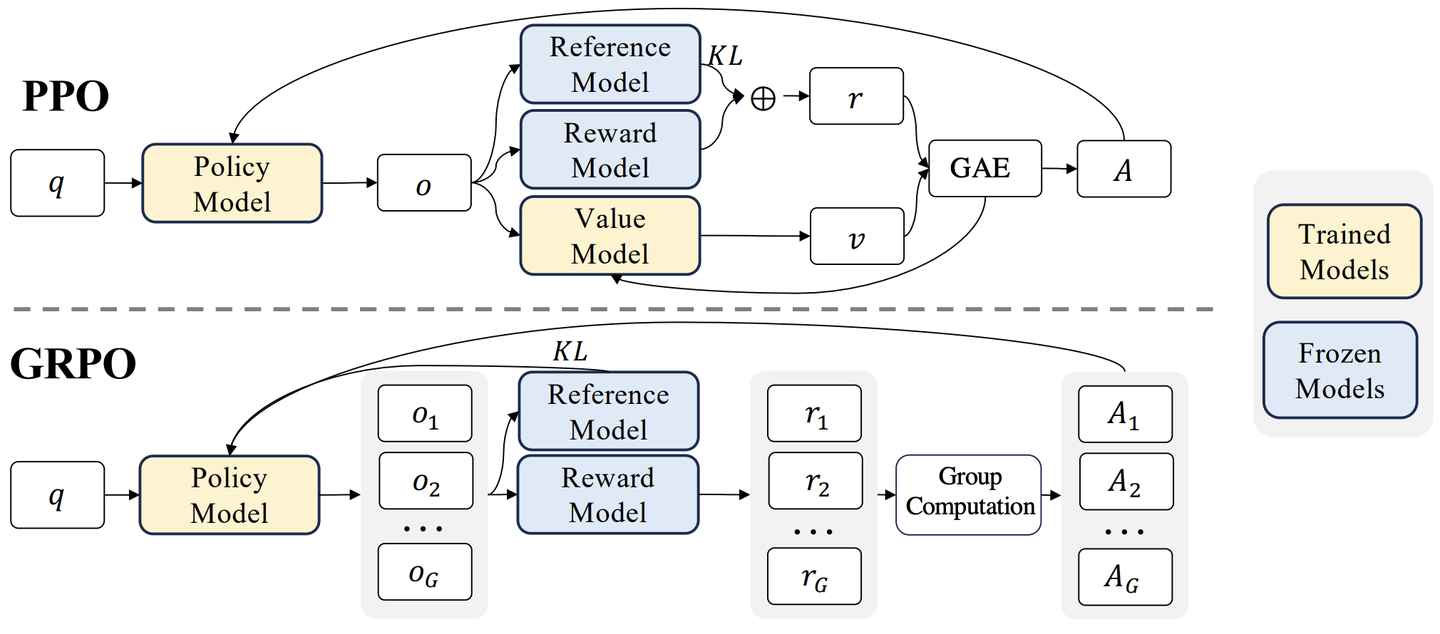
图 16-14:PPO 与 GRPO 的架构对比。PPO 通过 GAE + Critic 估计 token 级优势;GRPO 去掉 Critic,用组内奖励标准化代替。
16.7.2 全面对比:六大算法核心差异
下表从八个维度系统对比本篇介绍的六种主要对齐算法:
| 维度 | DPO | PPO | GRPO | RLOO | VAPO | GSPO |
|---|---|---|---|---|---|---|
| 是否需要 RM | 不需要 | 需要 | 需要 | 需要 | 需要 | 需要 |
| 是否需要 Critic | 不需要 | 需要 | 不需要 | 不需要 | 需要 | 不需要 |
| 优化粒度 | 偏好对(序列级) | token 级 | token 级 | token 级 | token 级 | 序列级 |
| 优势估计 | 隐式(BT 模型) | GAE + Value Model | 组内标准化 | leave-one-out | 增强 GAE | 组内标准化 |
| 训练模型数 | 2(策略 + 参考) | 4(+ Critic + RM) | 3(策略 + 参考 + RM) | 3 | 4 | 3 |
| 数据来源 | 离线偏好对 | 在线采样 | 在线采样 | 在线采样 | 在线采样 | 在线采样 |
| 训练稳定性 | 高(类 SFT) | 中等 | 中等 | 较高 | 高 | 高 |
| 信用分配精度 | 粗(整句) | 细(token) | 粗(整句共享) | 粗(整句) | 细(token) | 粗(整句) |
阅读提示:上表的"训练模型数"直接决定了显存峰值。对于同一基模,PPO 和 VAPO 的显存需求约为 DPO 的 2 倍。
16.7.3 三维度权衡:计算成本、稳定性与数据需求
选择对齐算法本质上是在三个维度之间做权衡:
维度一:计算成本。 计算成本的最大变量是"需要同时加载多少个模型"以及"是否需要在线采样"。DPO 只需两个模型且无需在线生成,计算最轻量——在相同硬件下,DPO 的单步训练速度约为 PPO 的 3-5 倍。PPO 和 VAPO 需要四个模型,其中 Critic 模型通常与策略模型同等规模,显存压力最大。GRPO 家族(含 GSPO、DAPO 等)处于中间地带:虽然去掉了 Critic,但每个 prompt 需要采样 G 个回答(通常
维度二:训练稳定性。 稳定性的核心挑战来自两个方面:一是重要性采样比的方差,二是优势估计的偏差。DPO 完全不涉及在线采样,稳定性最高,但可能过拟合离线数据。PPO 的 GAE 估计依赖 Critic 质量,Critic 偏差会传导到策略更新。GRPO 的 token 级重要性采样权重在长序列上累积噪声,尤其在 MoE 模型上容易触发不可逆的训练崩溃——这正是 GSPO 诞生的动机。GSPO 将重要性采样提升到序列级,从根本上消除了 token 级噪声累积。
维度三:数据需求。 DPO 需要高质量的偏好对数据
下图展示了 GSPO 与 GRPO 在大规模训练中的稳定性和性能差异:
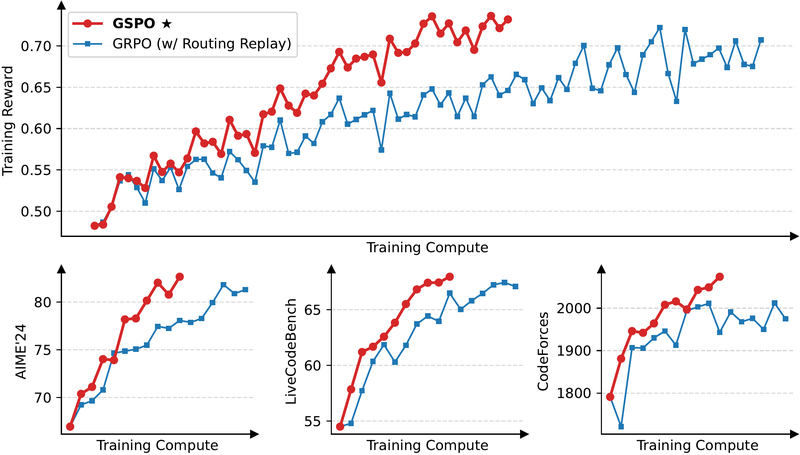
图 16-15:GSPO 与 GRPO 在 Qwen3-30B-A3B 上的训练对比。GSPO 在训练奖励和三个下游 benchmark 上全面领先。
16.7.4 MoE 模型的特殊考量
混合专家模型(Mixture of Experts, MoE) 的稀疏激活特性给 RL 训练带来了独特挑战。在 MoE 架构中,每个 token 只激活少数专家(如 8 选 2),梯度更新后同一 token 可能被路由到不同专家,导致新旧策略在 token 级似然上产生巨大波动。实验表明,每次 RL 梯度更新后约有 10% 的激活专家发生变化。
这对 GRPO 是致命的:token 级重要性比率
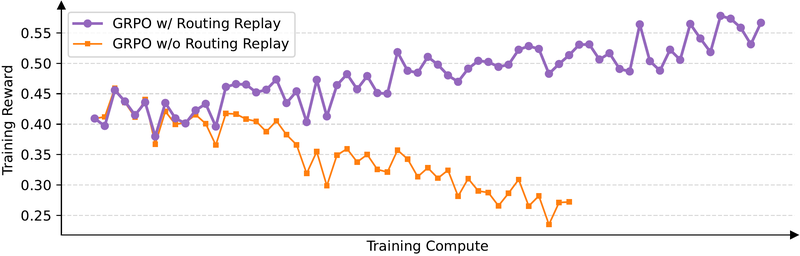
图 16-16:MoE 模型上 GRPO 的训练崩溃现象。没有 Routing Replay 的 GRPO(橙色)呈现明显发散趋势。
GSPO 的根本优势在于:它只关注序列似然
选型结论:MoE 模型的 RL 训练首选 GSPO。如果因实现限制必须使用 GRPO,则务必启用 Routing Replay。
16.7.5 选型决策树
面对具体任务,如何快速选择合适的算法?下面的决策树提供了一个系统化的选型路径:
开始
│
├─ 是否有高质量偏好对数据且不需要在线探索?
│ ├─ 是 → DPO(最简单,计算最轻量)
│ └─ 否 ↓
│
├─ 模型是否为 MoE 架构?
│ ├─ 是 → GSPO(序列级优化,无需 Routing Replay)
│ └─ 否 ↓
│
├─ 任务是否需要细粒度信用分配(如长链推理)?
│ ├─ 是 → VAPO(value-based,推理 SOTA)
│ │ 前提:可承受四模型的显存开销
│ └─ 否 ↓
│
├─ 是否有可验证奖励(数学、代码等)?
│ ├─ 是 → GRPO 或 DAPO
│ │ 若输出冗长 → GFPO(过滤控制长度)
│ │ 若长度偏差明显 → Dr.GRPO
│ │ 若需更稳定 → GMPO(几何平均抑制 outlier)
│ └─ 否 ↓
│
└─ 通用 RLHF、资源充足 → PPO
资源有限、追求简洁 → RLOO将上述逻辑转化为一个可运行的 Python 函数:
def select_alignment_algorithm(
has_preference_data: bool = False,
is_moe: bool = False,
need_fine_credit: bool = False,
has_verifiable_reward: bool = False,
output_too_long: bool = False,
length_bias: bool = False,
resource_limited: bool = False,
) -> str:
"""根据任务特征推荐后训练对齐算法。
Args:
has_preference_data: 是否有高质量偏好对数据 (x, y_w, y_l)
is_moe: 模型是否为 MoE 架构
need_fine_credit: 是否需要细粒度信用分配(如长链推理)
has_verifiable_reward: 是否有可验证奖励(数学/代码正确性)
output_too_long: 模型输出是否存在冗长问题
length_bias: 是否存在明显的长度偏差
resource_limited: 是否受计算资源限制
Returns:
推荐的算法名称及简要理由。
"""
if has_preference_data and not need_fine_credit:
return "DPO — 无需 RM/RL,训练最简单,2 个模型即可"
if is_moe:
return "GSPO — 序列级优化,无需 Routing Replay,MoE 首选"
if need_fine_credit:
return "VAPO — 保留 Value Model 的细粒度信用分配,推理 SOTA"
if has_verifiable_reward:
if output_too_long:
return "GFPO — 在 GRPO 基础上过滤冗长回答,控制输出长度"
if length_bias:
return "Dr.GRPO — 修正 GRPO 的长度归一化偏差"
return "GRPO/DAPO — 无 Critic,组相对优势,适配可验证奖励"
if resource_limited:
return "RLOO — REINFORCE 风格,比 PPO 更轻量,性能不输 DPO"
return "PPO — 通用 RLHF 的经典选择,资源充足时稳健可靠"
# 使用示例
print(select_alignment_algorithm(is_moe=True))
# 输出: GSPO — 序列级优化,无需 Routing Replay,MoE 首选
print(select_alignment_algorithm(has_verifiable_reward=True, output_too_long=True))
# 输出: GFPO — 在 GRPO 基础上过滤冗长回答,控制输出长度
print(select_alignment_algorithm(has_preference_data=True))
# 输出: DPO — 无需 RM/RL,训练最简单,2 个模型即可16.7.6 场景速查表
为方便实战查阅,下表按常见场景直接给出推荐方案:
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 通用对话/指令遵循,资源充足 | PPO | 久经验证,生态完善 |
| 通用对话/指令遵循,资源有限 | RLOO 或 DPO | 更轻量,超参更少 |
| 数学推理 SOTA | VAPO | 细粒度信用分配定位推理错误步骤 |
| 代码生成(可验证奖励) | GRPO / DAPO | 规则验证器 + 组内相对优势 |
| 长文本生成 / 长 CoT 推理 | GRPO + GMPO | 几何平均抑制 outlier,省显存 |
| 输出冗长需控制长度 | GFPO | 采样过滤隐式惩罚冗长 |
| 有充足偏好数据且追求简单 | DPO | 类 SFT 训练,实现最简 |
| MoE 模型 | GSPO | 序列级优化解决专家路由波动 |
| 多目标 / 复杂奖励 | PPO / VAPO | 灵活的奖励塑形能力 |
| 长度偏差显著 | Dr.GRPO | 统一归一化分母修正偏差 |
16.7.7 工程实践建议
最后,从工程视角给出几条跨算法通用的实践建议:
先跑 DPO baseline。 如果已有偏好数据,DPO 的实现和调参成本最低(核心超参仅
),是验证"对齐是否有效"的最快路径。在此基础上再决定是否切换到更复杂的在线算法。 在线算法从小组开始。 GRPO 家族的采样组大小
直接影响计算成本和优势估计质量。建议从 起步,观察组内奖励分布是否有足够区分度(标准差不应太小),再逐步增大到 16 或 32。 关注熵崩溃信号。 无论使用哪种算法,策略熵(即生成分布的多样性)的持续下降都是危险信号。当熵降到接近零时,模型进入"退化循环"——只会生成单一模式的回答。DAPO 的 Clip-Higher 和 GMPO 的几何平均都是对抗熵崩溃的有效手段。
MoE 务必选序列级算法。 如前所述,token 级重要性采样在 MoE 上的失效是系统性的,Routing Replay 只是治标之策。GSPO 是目前已验证的生产级解决方案(Qwen3 采用)。
验证奖励优先于模型奖励。 如果任务允许规则化验证(如数学答案正确性、代码测试通过率),优先使用验证器作为奖励信号而非训练奖励模型。验证器提供的奖励信号是精确的二值信号,不存在奖励模型的分布偏移和过拟合问题。
小结与对齐篇回顾
本节从算法族谱、核心维度对比、三维度权衡、MoE 特殊考量、决策树选型五个层面,系统梳理了后训练对齐算法的选型逻辑。核心结论可以浓缩为一句话:选型的本质是在计算成本、训练稳定性和数据需求之间找到平衡点,同时兼顾模型架构(是否 MoE)和任务特性(是否可验证、是否需要细粒度反馈)。
回顾整个第四篇(对齐篇),我们从 §16.1 的 DPO 出发,经过 §16.2 的 PPO 精讲、§16.3 的 GRPO 变革、§16.4–§16.5 的工程优化(DAPO、GSPO),到 §16.6 的高级变体(GMPO、GFPO 等),最后在本节完成了算法选型的全局视角。这六大类算法构成了一个从简单到复杂、从离线到在线、从粗粒度到细粒度的完整工具箱。面对具体的对齐任务,读者不必拘泥于某一种算法,而应根据任务特征、资源约束和模型架构,灵活组合使用。
对齐不是训练的终点,而是让模型从"能力"走向"可控"的关键一步。掌握了本篇的工具箱,读者已经具备了为大模型实施全链路对齐的理论基础和工程能力。