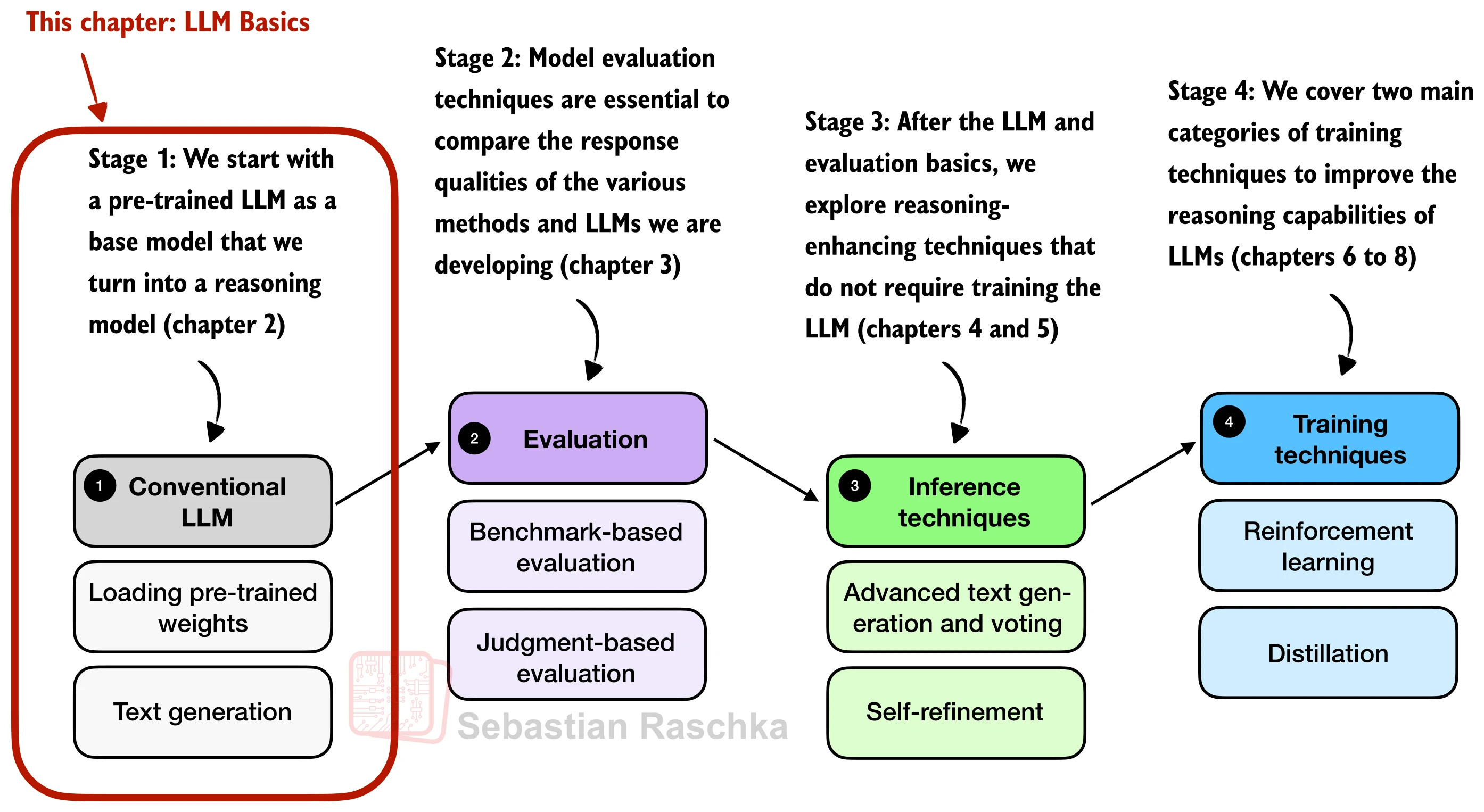
26.1 文本生成基础
在前面的章节中,我们从理论和训练两个维度深入剖析了大语言模型的内部机制。从本章开始,我们切换到另一个视角——将一个预训练好的 LLM 当作"黑盒",在其上构建推理(reasoning)能力。第一步,是理解 LLM 如何将一段输入文本逐步"续写"成完整的回答。本节将完整走通从分词(tokenization)到自回归生成(autoregressive generation)的全流程,并介绍两项关键的推理加速技术:KV 缓存(KV Cache) 和 torch.compile。
学完本节后,读者将能够:加载预训练 LLM 并使用分词器处理输入输出;理解自回归生成的逐 token 工作机制;实现带有 KV 缓存的高效生成函数;使用 torch.compile 进一步提升推理速度。
26.1.1 分词与输入准备
LLM 无法直接处理原始文本字符串,需要先通过分词器(Tokenizer) 将文本编码为整数 ID 序列,推理完成后再将 ID 序列解码回人类可读的文本。这一 encode-decode 往返构成了所有 LLM 交互的基础:
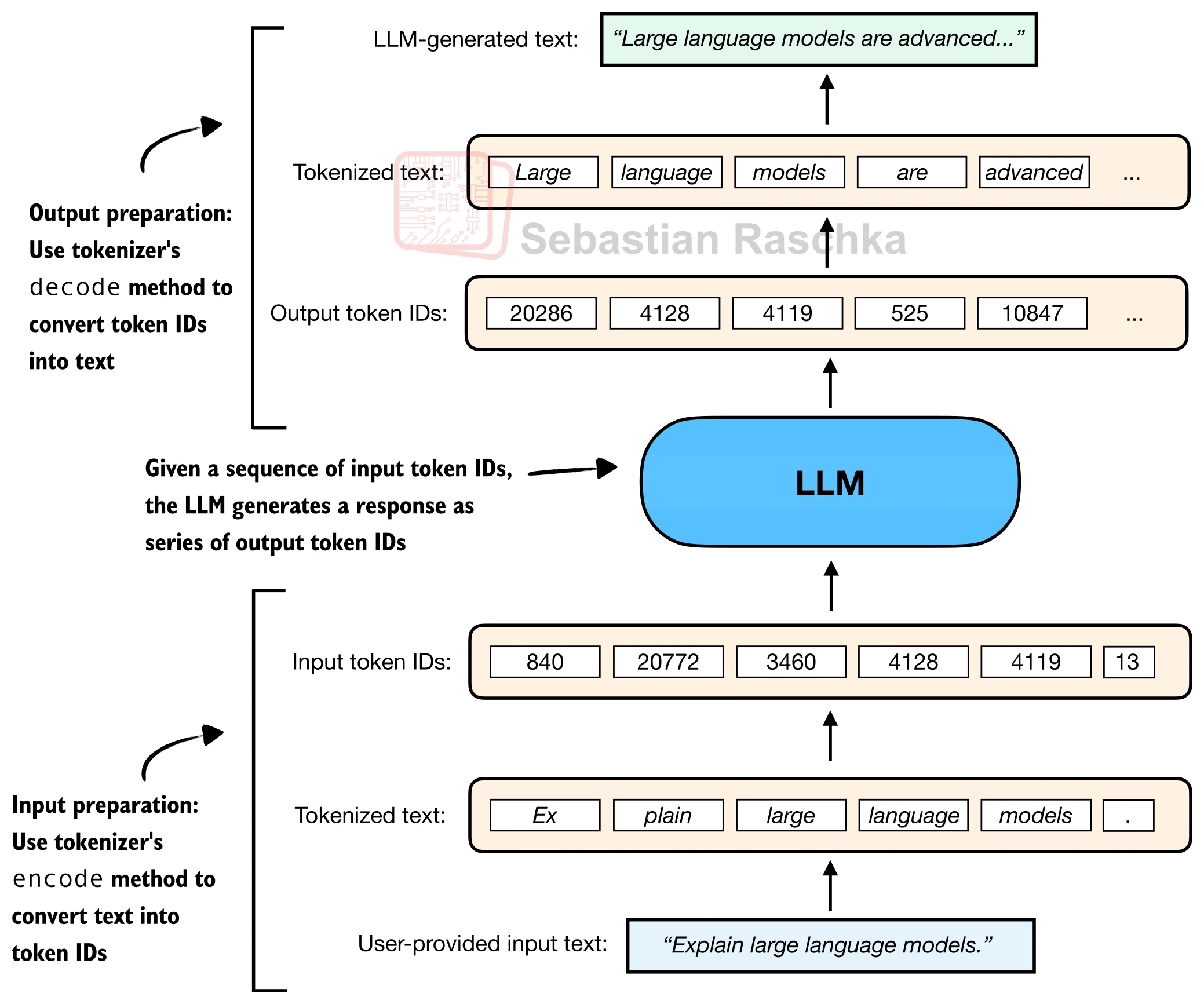
以 Qwen3 的 BPE 分词器为例,其词表大小约 151,936 个 token。一句简单的英文会被拆分为若干子词 token:
from tokenizers import Tokenizer
# 加载 BPE 分词器(此处以 Qwen3 为例)
tokenizer = Tokenizer.from_file("tokenizer.json")
prompt = "Explain large language models."
token_ids = tokenizer.encode(prompt).ids
print(token_ids)
# 输出: [840, 20772, 3460, 4128, 4119, 13]
# 逐 token 查看对应的文本片段
for tid in token_ids:
print(f"{tid} --> {tokenizer.decode([tid])}")
# 840 --> Ex
# 20772 --> plain
# 3460 --> large
# 4128 --> language
# 4119 --> models
# 13 --> .可以看到,"Explain" 被拆成了 "Ex" 和 "plain" 两个子词,而 "large"、"language"、"models" 各自独立成 token。分词粒度取决于训练语料中各子串的出现频率——高频词保持完整,低频词被进一步拆分。
关键概念:分词器定义了模型的"语言单元"。不同模型家族使用不同的分词器和词表大小(如 Llama 3 约 128K,Qwen3 约 152K),因此分词器与模型必须配套使用。词表大小直接影响模型的 Embedding 层和输出层参数量——词表越大,这两层越"重"。对于小模型而言,选择合适的词表大小是一个关键的设计决策(详见第 25 章对 MiniMind 词表设计的讨论)。
26.1.2 自回归生成的原理
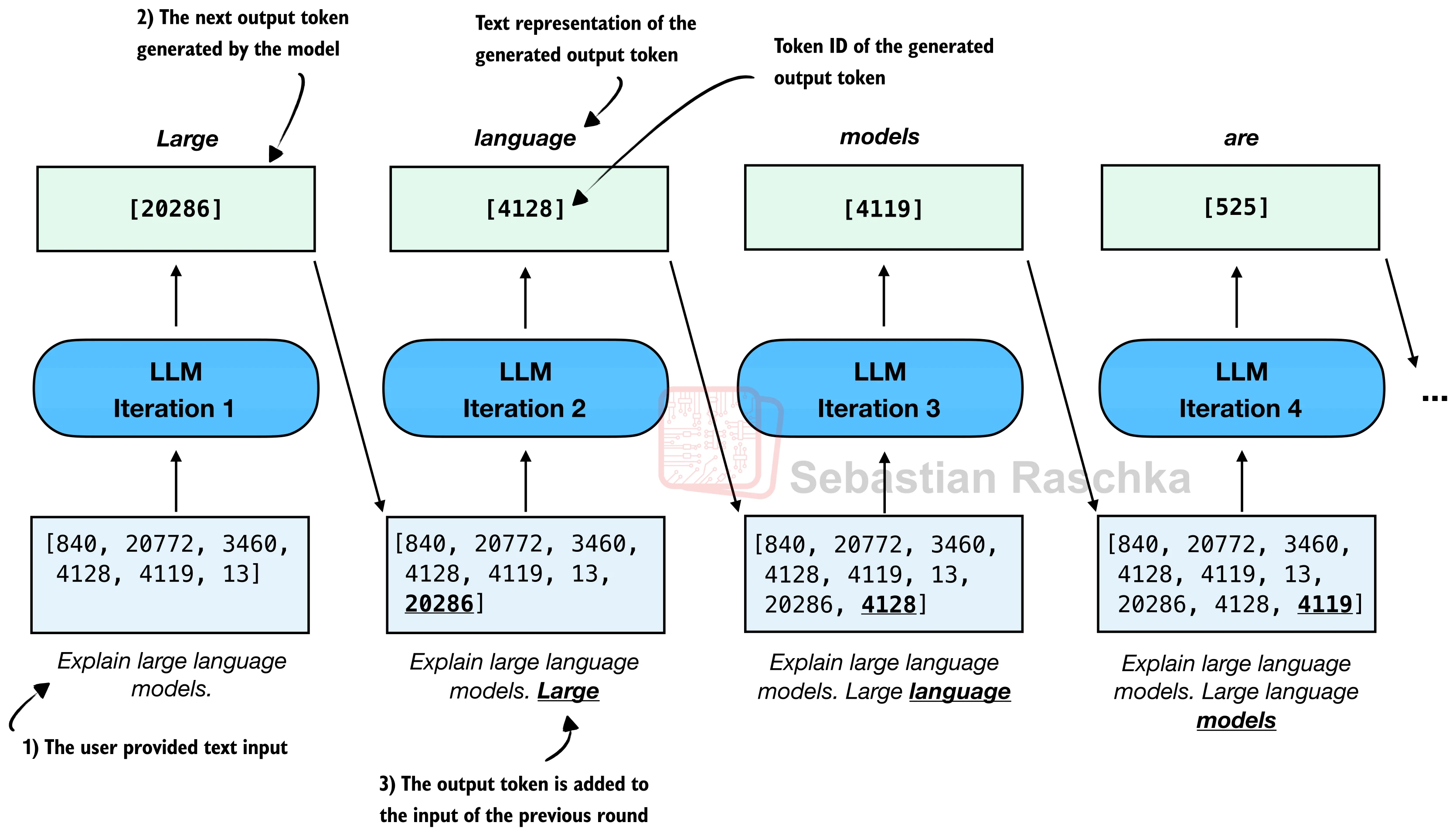
LLM 的文本生成遵循自回归(Autoregressive) 范式:每次只生成一个 token,然后将其追加到输入序列末尾,作为下一步的输入。如此循环,直到满足停止条件(达到最大长度或遇到特殊的结束符 <|endoftext|>)。这与人类写作的过程颇为相似——写下一个词之后,根据已有的上下文决定下一个词。
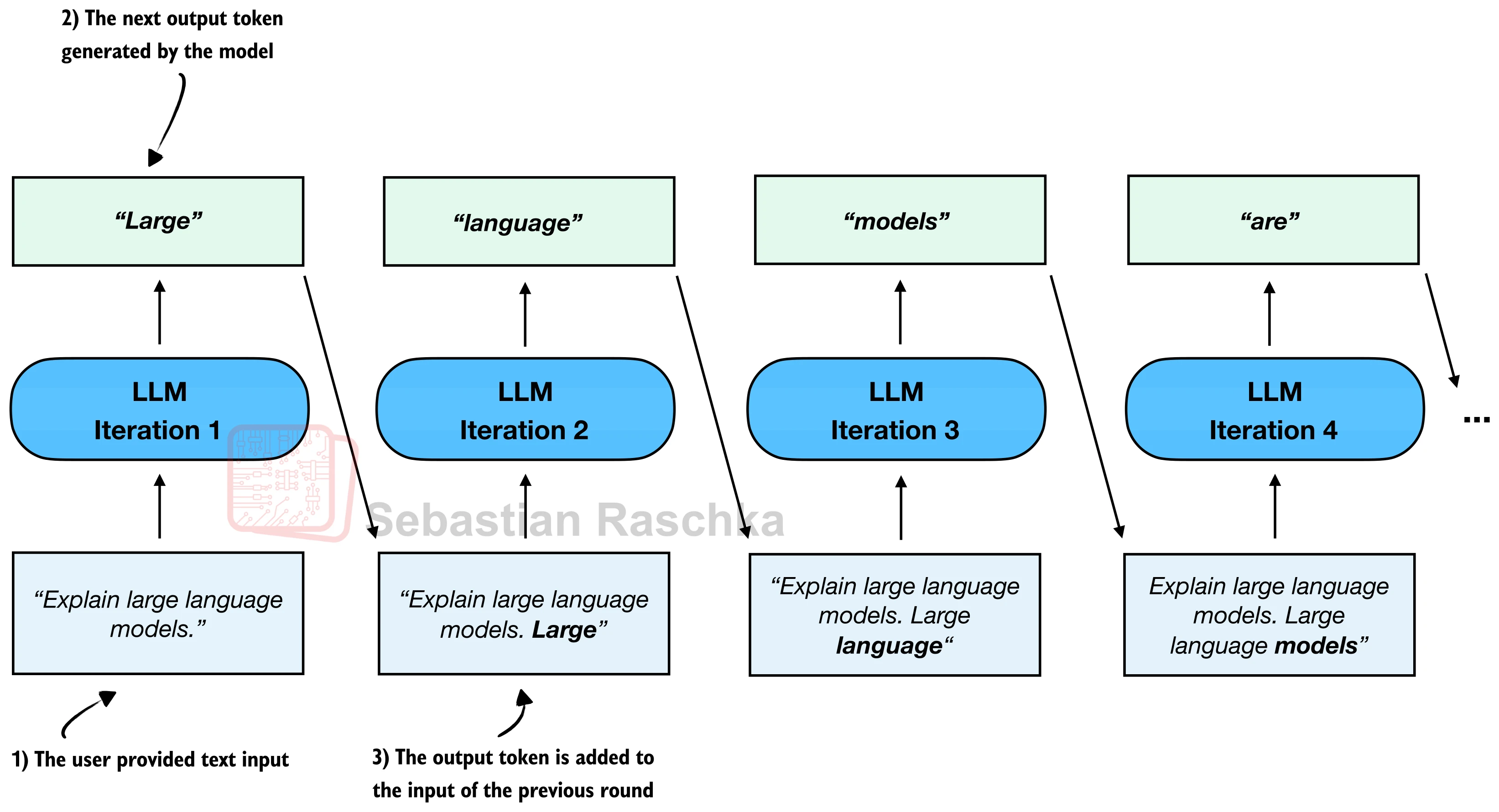
让我们放大第一次迭代的内部细节,看看 LLM 到底在做什么:
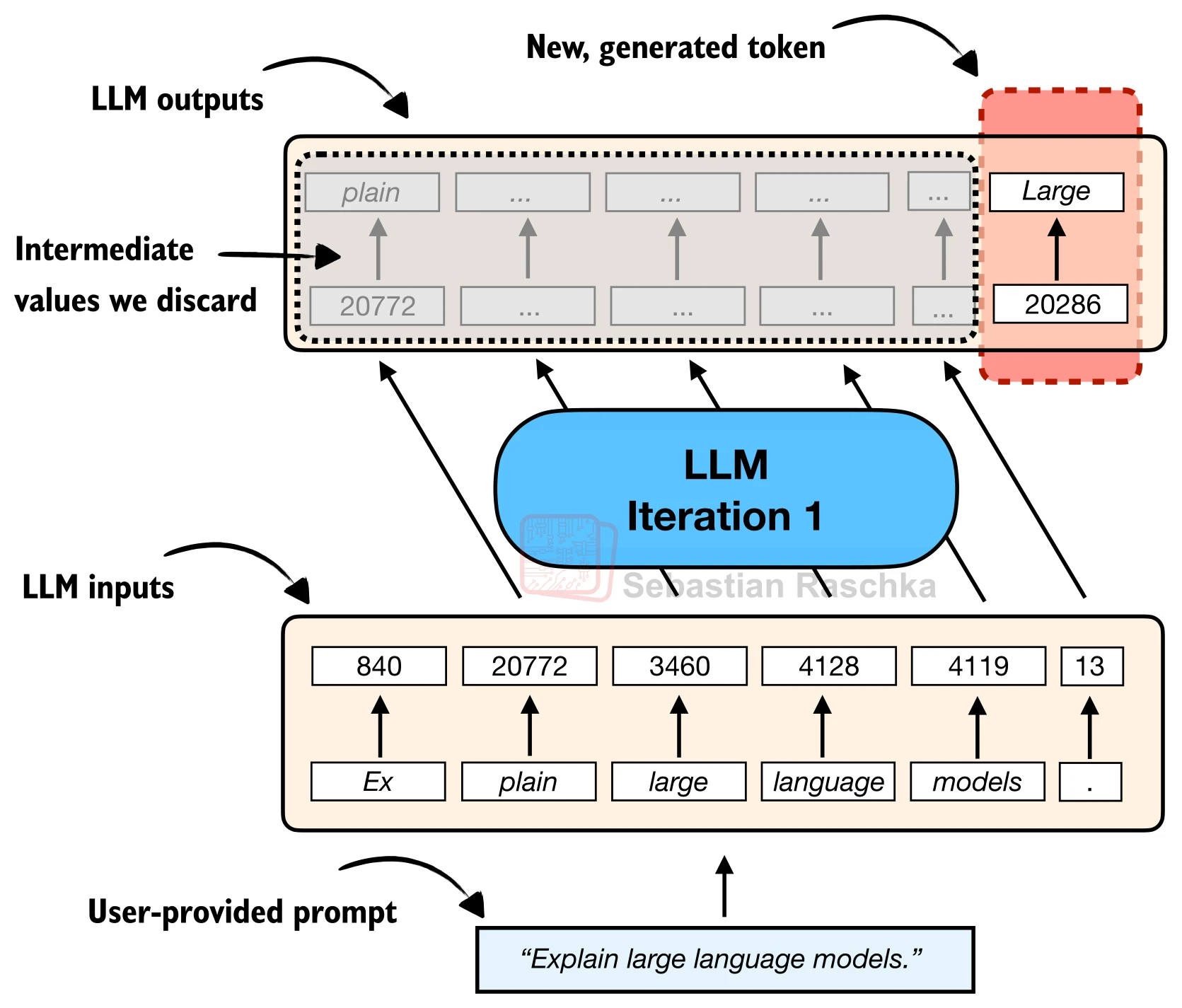
一次前向传播的流程如下:
- 张量化:将 token ID 列表转为 PyTorch 张量,添加批次维度(
unsqueeze(0))后送入模型。批次维度是必须的,即使只处理一条输入,模型也期望接收 2D 张量(batch_size, seq_len)。 - 前向传播:模型输出形状为
(batch_size, seq_len, vocab_size)的 logits 张量——对词表中每个 token 的未归一化得分。之所以每个位置都有输出,是因为 Transformer 的因果注意力掩码允许每个位置基于其左侧上下文做预测。 - 取末位:取最后一个位置的 logits(
output[:, -1, :]),这代表模型综合了全部输入信息后,对"下一个 token 应该是什么"的预测。 - 解码:通过
argmax选择得分最高的 token ID 作为生成结果。

import torch
# 假设 model 已加载,tokenizer 已准备好
prompt = "Explain large language models."
input_ids = tokenizer.encode(prompt).ids
input_tensor = torch.tensor(input_ids).unsqueeze(0) # (1, seq_len)
with torch.inference_mode():
logits = model(input_tensor) # (1, seq_len, vocab_size)
# 取最后一个位置的 logits
last_logits = logits[0, -1, :] # (vocab_size,)
next_token_id = torch.argmax(last_logits).item()
print(tokenizer.decode([next_token_id]))
# 输出: " Large"这里使用了贪心解码(Greedy Decoding)——直接选概率最高的 token。在后续章节中我们会引入温度采样、Top-k/Top-p 等更灵活的解码策略,但贪心解码是理解生成机制的最佳起点。
这里 torch.inference_mode() 上下文管理器必不可少——它告诉 PyTorch 不需要为反向传播记录计算图,从而显著减少内存开销和计算时间。在所有纯推理场景中,都应使用该上下文管理器(或等价的 torch.no_grad(),但 inference_mode 更彻底,额外禁用了版本跟踪)。
26.1.3 编写最小文本生成函数
将上述逻辑封装为循环,就得到了一个完整的文本生成函数。下面的实现采用 Python 生成器(yield),每生成一个 token 就立即返回,便于实现流式输出(streaming)。这种设计在交互式应用中非常重要——用户不必等待全部 token 生成完毕,就能看到逐步出现的文本:
@torch.inference_mode()
def generate_text_stream(model, token_ids, max_new_tokens, eos_token_id=None):
"""最小文本生成函数(流式输出)"""
model.eval()
for _ in range(max_new_tokens):
logits = model(token_ids)[:, -1] # 取最后位置
next_token = torch.argmax(logits, dim=-1, keepdim=True)
if eos_token_id is not None and torch.all(next_token == eos_token_id):
break # 遇到终止符则停止
yield next_token # 流式返回
token_ids = torch.cat([token_ids, next_token], dim=1) # 追加到输入调用时,逐 token 打印即可实现"打字机"效果:
prompt = "Explain large language models in a single sentence."
input_tensor = torch.tensor(tokenizer.encode(prompt).ids).unsqueeze(0)
for token in generate_text_stream(model, input_tensor, max_new_tokens=100,
eos_token_id=151643):
print(tokenizer.decode([token.item()]), end="", flush=True)
# 输出: Large language models are artificial intelligence systems that can
# understand, generate, and process human language, enabling them to
# perform a wide range of tasks, from answering questions to writing
# articles, and even creating creative content.注意 eos_token_id=151643 对应 <|endoftext|> 标记。如果不传入该参数,模型会在生成完有意义的内容后继续"胡言乱语"——因为它会把 <|endoftext|> 当作普通分隔符,接着生成训练语料中下一篇文档的内容。这个行为并非 bug,而是预训练数据组织方式的直接反映:多篇文档用 <|endoftext|> 拼接成长序列进行训练,模型学会了在该符号之后"切换话题"。
还有一个细节值得关注:model.eval() 必须在生成前调用。虽然 Qwen3 的架构中没有使用 Dropout(现代 LLM 通常不用),但 eval() 仍然会影响某些层的行为(如 BatchNorm,虽然此处不涉及),养成这个习惯是良好的工程实践。
性能基线:在 CPU 上运行 Qwen3-0.6B(约 6 亿参数),上述朴素实现的吞吐量约为 5 tokens/sec。对于需要生成数百甚至数千 token 的推理任务来说,这远远不够实用。以一个典型的 Chain-of-Thought 推理场景为例,模型可能需要生成 500-2000 个 token 才能完成一次完整的推理过程——5 tokens/sec 意味着需要等待 1.5 到 7 分钟。因此,接下来我们引入两项关键优化。
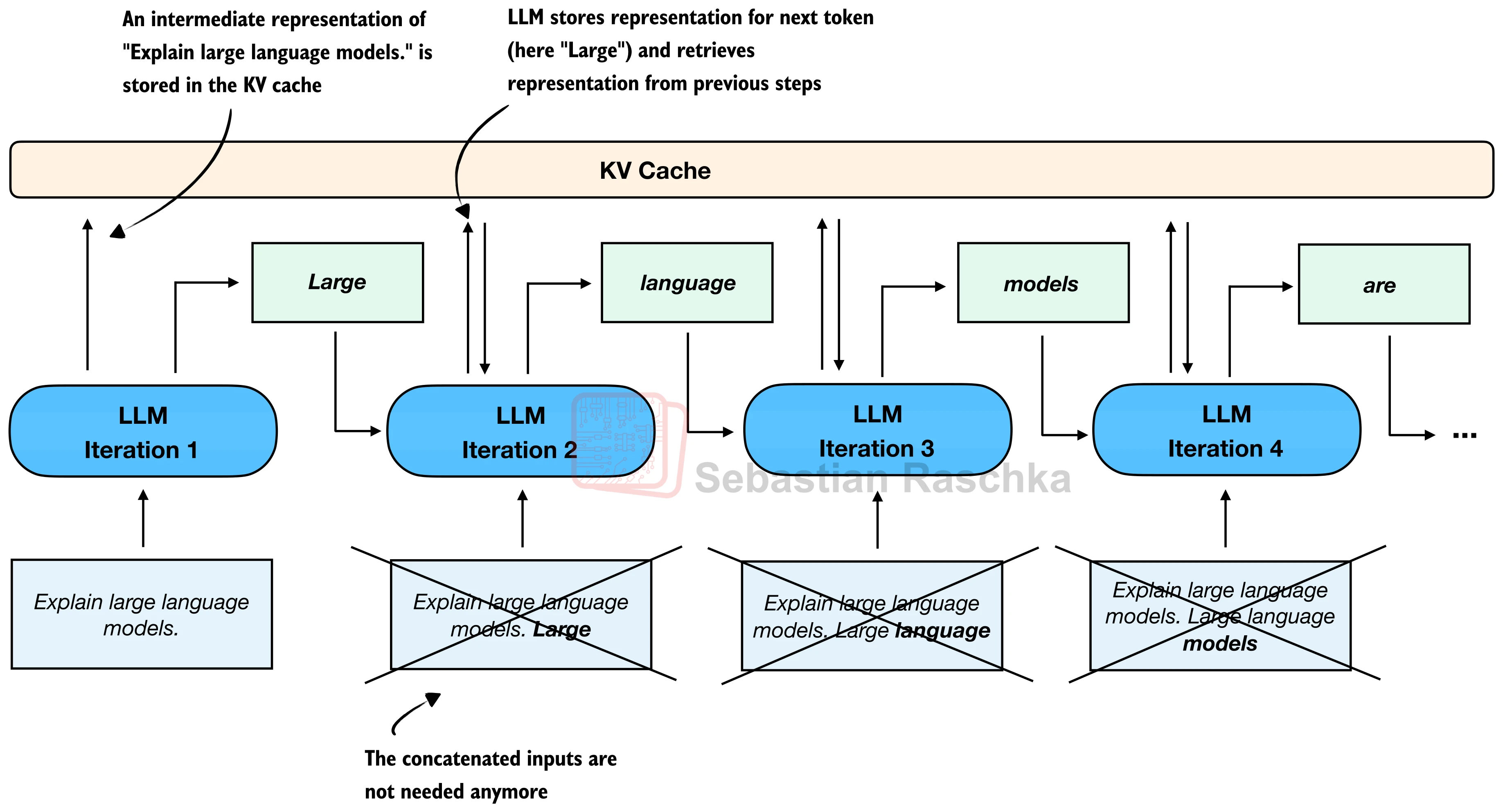
26.1.4 KV 缓存加速推理
观察上面的生成循环,每一步都将完整的 token 序列(包括所有历史 token)重新送入模型进行前向传播。这意味着第
KV 缓存(KV Cache)的思路非常直接:在注意力层中,将每一步计算得到的 Key 和 Value 向量缓存起来,下一步只需对新增的那一个 token 计算 QKV,然后与缓存中的历史 KV 拼接即可。
[选读] 从计算复杂度看:假设生成
- 无缓存:每步处理完整序列,注意力计算复杂度为
,总计 。 - 有缓存:每步只处理 1 个新 token,注意力复杂度降为
,总计 。
代价是内存:需要为每一层存储 Key 和 Value 张量。对于 Qwen3-0.6B(28 层、1024 维),假设 bfloat16 精度、序列长度 1024,KV 缓存约占用:
这在消费级硬件上完全可以接受。但对于更大的模型和更长的上下文,KV 缓存的内存占用会快速增长。例如,一个 70B 参数的模型(80 层、8192 维)在 32K 上下文下,KV 缓存约占用 80 GB——这也是为什么 GQA(Grouped Query Attention)等技术如此重要,它们通过减少 KV 头数来压缩缓存大小(详见第 3 章对注意力变体的讨论)。
修改后的生成函数如下:
@torch.inference_mode()
def generate_text_stream_cache(model, token_ids, max_new_tokens, eos_token_id=None):
"""带 KV 缓存的文本生成函数"""
model.eval()
cache = KVCache(n_layers=model.n_layers) # 初始化空缓存
# 第一步:处理完整的输入序列(prefill 阶段)
logits = model(token_ids, cache=cache)[:, -1]
for _ in range(max_new_tokens):
next_token = torch.argmax(logits, dim=-1, keepdim=True)
if eos_token_id is not None and torch.all(next_token == eos_token_id):
break
yield next_token
# 后续步骤:只送入新 token(decode 阶段)
logits = model(next_token, cache=cache)[:, -1]核心区别在于:循环内部 model(next_token, cache=cache) 只传入最新的 1 个 token,而非整个历史序列。cache 对象在模型内部自动累积历史的 Key 和 Value。
实测效果:在相同的 CPU 环境下,KV 缓存将吞吐量从 5 tokens/sec 提升到约 29 tokens/sec,加速比接近 6 倍。这也揭示了一个重要事实——朴素实现的瓶颈主要在于注意力层的重复计算,而非模型参数本身的大小。
Prefill 与 Decode 两阶段:生产环境中,LLM 推理通常分为两个阶段——Prefill(并行处理整个输入序列,填充 KV 缓存)和 Decode(逐 token 自回归生成)。KV 缓存优化的核心收益体现在 Decode 阶段。Prefill 阶段虽然也需要计算 KV 值,但由于整个输入序列可以并行处理(利用 GPU 的大规模并行性),其耗时占比通常远小于 Decode 阶段。
KV 缓存还有一种预分配(Pre-allocation) 变体:在 Prefill 之前就为最大上下文长度分配好固定大小的张量,避免在 Decode 阶段反复动态扩展。预分配方式占用更多初始内存,但在 GPU 上避免了频繁的内存分配和拷贝,适合长序列生成场景。本书的实现采用更简洁的动态拼接方式,在教学和中等长度序列场景下已经足够高效。
26.1.5 torch.compile 编译加速
PyTorch 2.0 引入的 torch.compile 提供了另一种维度的加速——它将 Python 层面的 eager 执行转化为优化后的计算图,通过算子融合(operator fusion)、内存布局优化等手段减少内核调用开销和内存搬运次数。
使用方式极为简洁,只需一行代码:
model_compiled = torch.compile(model)需要注意的是,首次调用编译后的模型时会触发 JIT 编译,耗时可能长达数十秒甚至数分钟(取决于模型规模和硬件),但后续调用的速度会显著提升。因此在性能评测中,通常先做一次"热身"(warm-up)运行,再统计后续运行的吞吐量。
torch.compile 底层依赖 TorchInductor 作为编译后端,它会将 Python 级别的操作转译为 C++/CUDA 内核代码。在 CUDA GPU 上,Inductor 还依赖 Triton(由 OpenAI 开源的 GPU 编程语言)来生成高效的 GPU 内核。在 CPU 上则使用 C++ 编译器。这意味着:
- Linux/macOS 通常开箱即用,无需额外配置。
- Windows 需要安装 Visual Studio Build Tools 的 C++ 工作负载,并从 Developer Command Prompt 启动 Python。如果使用 CUDA,还需要手动安装
triton-windows包。 - 如果编译环境配置困难,可以放心跳过——
torch.compile是可选优化,所有代码在不编译的情况下均可正常运行。
torch.compile 与 KV 缓存是正交的优化——前者优化单次前向传播的计算效率,后者减少不必要的重复计算。两者可以叠加使用。下表展示了在不同硬件和配置下,Qwen3-0.6B 的实测吞吐量(单位:tokens/sec):
| 模式 | Mac Mini M4 CPU | Mac Mini M4 GPU | NVIDIA H100 GPU |
|---|---|---|---|
| 朴素(无优化) | 5 | 27 | 51 |
| + KV 缓存 | 29 | 41 | 48 |
| + torch.compile | 5 | 43 | 164 |
| + KV 缓存 + torch.compile | 68 | 71 | 141 |
几个关键观察:
- CPU 上 KV 缓存效果最显著:从 5 提升到 29,这是因为 CPU 的计算带宽有限,减少冗余计算带来的收益远大于 GPU。
- GPU 上 torch.compile 效果最显著:H100 从 51 提升到 164(仅 compile、无缓存),这是因为 GPU 的算子调度开销在高频小内核调用时占比很大,compile 的融合优化正好解决了这个瓶颈。
- 两者叠加时 GPU 上的收益并非简单相加:H100 上 KV 缓存 + compile 为 141,低于纯 compile 的 164。这是因为 KV 缓存将每步的输入从完整序列缩减为单个 token,导致矩阵运算的尺寸变小,GPU 的大规模并行优势反而没有充分发挥。在更长的序列或更大的模型上,KV 缓存 + compile 的组合收益会更加显著。
- Apple Silicon GPU 表现均衡:M4 的统一内存架构使得 CPU 和 GPU 共享同一块物理内存,数据无需在设备间搬运,因此各种优化组合都能带来稳定的提升。
[选读] TF32 精度提示:在 NVIDIA Ampere(A100)及更新架构的 GPU 上,启用 TF32 精度可以在几乎不影响生成质量的情况下进一步加速矩阵运算。TF32 使用 19 位浮点格式(8 位指数 + 10 位尾数),在保持 FP32 动态范围的同时提供接近 FP16 的计算速度。PyTorch 中可通过以下代码开启:
pythontorch.backends.cuda.matmul.allow_tf32 = True torch.backends.cudnn.allow_tf32 = True
在实际部署中,torch.compile 还支持多种编译模式。默认模式在编译时间和运行速度之间取得平衡;mode="max-autotune" 会尝试更多的内核调优策略,编译时间更长但可能获得额外的加速(Windows 用户尤其推荐使用此模式);mode="reduce-overhead" 则专注于减少 Python 调度开销,适合小模型或短序列场景。
# 不同编译模式的选择
model_compiled = torch.compile(model) # 默认模式
model_compiled = torch.compile(model, mode="max-autotune") # 最大调优
model_compiled = torch.compile(model, mode="reduce-overhead") # 减少开销此外,使用 torch.compile 时需要注意动态形状(Dynamic Shapes) 的问题。在 KV 缓存模式下,每一步输入的序列长度固定为 1(只有新 token),不会触发重新编译。但在无缓存模式下,序列长度随生成步骤不断增长,如果不配置动态形状,PyTorch 可能会为每个新长度重新编译一次,导致性能急剧下降。PyTorch 2.8+ 版本通过 torch._dynamo.config.allow_unspec_int_on_nn_module = True 等配置项改善了这一问题,但这也从侧面说明了 KV 缓存与 torch.compile 的良好兼容性——前者将 Decode 阶段的输入形状固定化,天然避免了重新编译。
26.1.6 关于模型选择的说明
本章的实验使用 Qwen3-0.6B 作为基座模型。选择它的理由有三:
- 性能领先:Qwen3 是截至本书写作时在同参数量级下综合性能最强的开源模型之一。
- 内存友好:0.6B 参数在 bfloat16 精度下仅占约 1.2 GB 显存(
),消费级硬件即可运行。 - 生态完整:Qwen3 同时提供 base 模型和官方推理(reasoning)变体,后者可作为我们自己训练推理能力时的参考基准。
Qwen3-0.6B 的架构为标准的 Decoder-Only Transformer,包含 28 层 TransformerBlock、1024 维隐藏层、16 个 Query 头和 8 个 KV 头(GQA),使用 RMSNorm、RoPE 位置编码和 SwiGLU 前馈网络——这些都是我们在第 3 章详细讨论过的现代 Transformer 标准组件。尽管参数量不大,但它在短文本生成任务上已经能产出连贯、合理的回答——这正是我们后续实验所需要的基础能力。
26.1.7 小结
本节建立了从预训练 LLM 生成文本的完整基础:
- 分词器是 LLM 的"翻译器",在文本与 token ID 之间做双向转换。词表设计直接影响模型的参数分布和多语言能力。
- 自回归生成是 LLM 的核心工作模式——逐 token 预测、追加、再预测,循环往复。贪心解码是最简单的策略,后续章节将扩展到采样方法。
- KV 缓存通过存储注意力层的中间结果避免重复计算,在 CPU 上可带来约 6 倍加速。其本质是用空间换时间,代价是线性增长的内存占用。
torch.compile通过 JIT 编译和算子融合优化单步前向传播的效率,在 GPU 上效果尤为突出。它是可选优化,不影响生成结果的正确性。- 两种优化可以叠加使用,在实际部署中几乎是标配组合。在推理模型场景中,由于单次生成的 token 数量通常远多于普通对话(可达数千 token),推理加速的重要性更加突出。
掌握了这些基础设施之后,我们就拥有了高效运行推理实验的能力。一个自然的问题是:如何量化地衡量不同推理策略的好坏?下一节我们将搭建评估框架——包括数学答案验证器和标准化的评分流程——为系统地对比各种推理时间缩放(Inference-Time Scaling)方法做好准备。