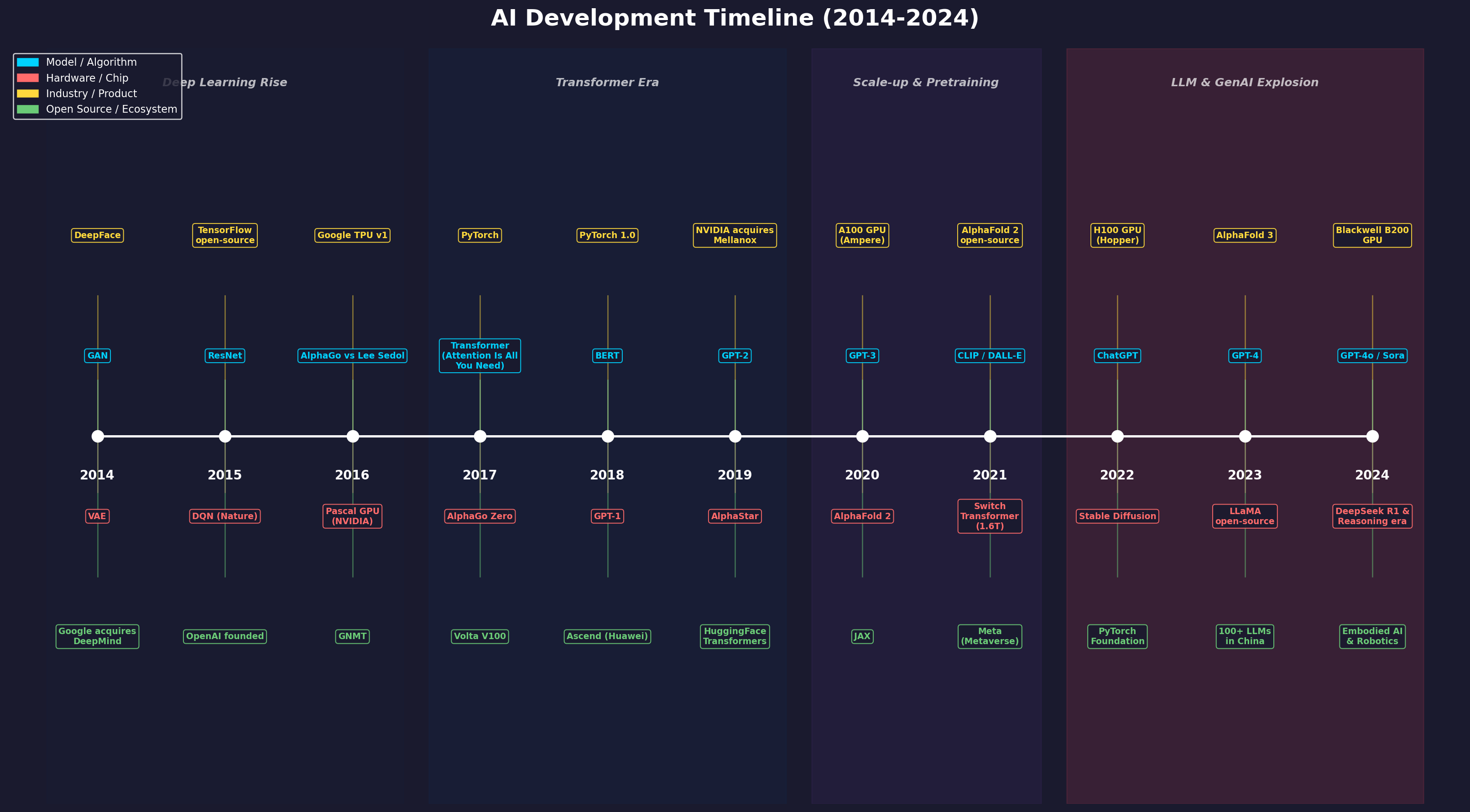
附录C:AI 发展十年回顾(2014-2024)
过去十年是人工智能从实验室走向现实世界、从学术概念走向全面商业化的关键时期。2012 年 AlexNet 在 ImageNet 竞赛中的惊艳亮相拉开了深度学习革命的序幕,此后的每一年都在模型架构、硬件算力和产业生态三条主线上涌现出标志性事件。从 2014 年 GAN 的诞生到 2017 年 Transformer 的横空出世,从 2020 年 GPT-3 开启大模型时代到 2024 年多模态与推理模型的全面爆发,AI 技术以指数级速度重塑着计算范式和产业格局。
本附录以编年体形式梳理 2014-2024 年间的关键里程碑,覆盖模型算法、芯片硬件、产业事件和开源生态四个维度,帮助读者建立对 AI 十年发展的宏观历史视角。
前奏:2012-2013 年——深度学习崛起
在正式进入 2014 年之前,有必要回顾两个奠基性事件:
2012 年:AlexNet 与深度学习的崛起。 2012 年 6 月,吴恩达及其团队展示了"谷歌猫"项目,通过大规模无监督学习证明神经网络能够自主识别图像中的概念。同年 10 月,多伦多大学 Geoffrey Hinton 团队提出的 AlexNet 在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中以 84% 的准确率夺冠,远超第二名。AlexNet 采用卷积神经网络(CNN)和 GPU 加速训练,标志着深度学习在计算机视觉领域的突破,引发了学术界和产业界对深度学习的高度关注。李飞飞团队创建的 ImageNet 数据集为深度学习提供了大规模训练数据,英伟达的 GPU 迅速成为 AI 研究的核心硬件。
2013 年:深度学习技术的进一步推广。 DeepMind 引入深度强化学习,提出 DQN(深度 Q 网络),通过结合深度学习和强化学习,展示 AI 系统在 Atari 游戏中的超人类表现。谷歌研究员 Tomas Mikolov 及其同事引入了 Word2Vec,通过将词语表示为向量,为 NLP 任务提供了高效的文本编码方式。百度在 2013 年 1 月宣布成立深度学习研究院 IDL,标志着中国科技巨头开始押注 AI。微软研究院使用深度学习技术大幅提升了语音识别准确率。
2014 年:AI 算法高速发展与巨头布局
2014 年是 AI 算法创新井喷的一年,多个经典模型和架构在这一年诞生,科技巨头也开始大规模布局 AI 领域。
模型与算法里程碑:
生成对抗网络(GAN)的提出。 Ian Goodfellow 及其同事创造了生成对抗网络(Generative Adversarial Network, GAN),这是一种通过生成器和判别器相互博弈来生成逼真数据的框架,成为后续图像生成、风格迁移等领域的基础范式。
变分自编码器(VAE)的引入。 Diederik Kingma 和 Max Welling 引入了变分自编码器(Variational Autoencoder, VAE),为生成图像、视频和文本提供了概率建模框架。
DeepFace 人脸识别。 Facebook 开发了深度学习面部识别系统 DeepFace,能够以接近人类的准确度识别数字图像中的人脸,准确率达到 97.35%。
Seq2Seq 模型。 谷歌提出序列到序列(Sequence-to-Sequence)学习框架,为机器翻译和对话系统奠定了基础。
硬件与芯片进展:
神经形态芯片突破。 2014 年,《麻省理工科技评论》评选出的"十大突破性技术"中包括神经形态芯片,标志着 AI 硬件领域的重要进展。GPU 开始被广泛用于深度学习训练,英伟达的 CUDA 生态逐步成为 AI 计算的事实标准。
产业事件:
谷歌以 6 亿美元收购 DeepMind。 这是 AI 领域的重要并购事件,DeepMind 后续推出了 AlphaGo,进一步推动了 AI 的普及和公众关注。
百度硅谷 AI 实验室成立。 百度在硅谷设立深度学习实验室,并聘请吴恩达担任首席科学家,标志着中国科技巨头在 AI 领域的全面布局。
谷歌无人驾驶汽车进展。 2014 年,谷歌成为第一个通过美国州自驾车测试的公司,推动了自动驾驶技术的发展。
2015 年:从实验室走向商业化
2015 年是 AI 技术从实验室走向商业化的重要一年,深度学习、开源工具、伦理讨论和产品创新成为这一年的关键热词。
模型与算法里程碑:
深度残差网络 ResNet。 何凯明及其团队提出了 ResNet(深度残差网络),通过引入残差连接解决了深度神经网络中的梯度消失问题,使得训练数百层的网络成为可能,极大推动了图像识别和分类任务的性能,成为计算机视觉领域最重要的突破之一。
深度强化学习突破(DQN 登上 Nature)。 DeepMind 在 Nature 杂志上发表了深度强化学习 DQN 的研究成果,通过结合卷积神经网络和 Q-Learning 算法,让 AI 能够直接从游戏画面的像素输入中学习控制策略,并在 Atari 2600 多个游戏中取得超越人类玩家的水平。
开源框架生态:
TensorFlow 开源。 2015 年 11 月,谷歌开源了 TensorFlow,成为第一个正式商业化的深度学习框架,为开发者提供了构建和训练神经网络的 API,迅速成为 AI 研究和应用领域的核心工具,推动了全球 AI 技术的发展。
Torch 神经网络库。 同年 Facebook 开源了基于 Lua 实现的 Torch 神经网络库(PyTorch 的前身,2017 年基于 Python 重新实现)。微软开源了分布式机器学习工具包 DMTK,IBM 开源了机器学习平台 SystemML,进一步推动了 AI 技术的普及。
产业事件:
OpenAI 成立。 2015 年 12 月,Elon Musk 和 Sam Altman 等人共同出资 10 亿美元,成立了非盈利性 AI 研究机构 OpenAI,旨在推动 AI 的安全研究和开发,确保 AI 技术对人类有益。这一事件为后续 OpenAI 的崛起奠定了基础。
特斯拉发布 Autopilot 系统。 首次将部分自动驾驶功能引入商用车辆,标志着自动驾驶技术的重大商业化突破。
谷歌推出 Google Photos。 基于深度学习的谷歌相册服务能够自动分类和识别图片中的人物和场景。
中国 AI 四小龙崛起。 以计算机视觉为核心的商汤科技、旷视科技、云从科技和依图科技迅速崛起。商汤凭借深度学习算法在图像识别领域取得领先,旷视的人脸识别技术用于安防和金融领域,云从在金融和安防领域落地,依图在医疗影像领域表现出色。2015 年全球 AI 领域投资超过 300 笔,总体估值超过 87 亿美元。
2016 年:AlphaGo 震惊世界
2016 年是 AI 走入公众视野的标志性一年,AlphaGo 的胜利让全世界认识到了 AI 的强大潜力。
模型与算法里程碑:
AlphaGo 战胜李世石。 2016 年 3 月,谷歌 DeepMind 开发的 AlphaGo 在韩国首尔以 4:1 的成绩战胜世界围棋大师李世石。围棋因其极高的复杂性长期被视为人类智慧的最后堡垒,AlphaGo 的胜利展示了深度学习与强化学习结合的强大能力,引起了全球范围的广泛关注,极大加速了深度学习技术在各领域的应用。
谷歌神经机器翻译(GNMT)。 2016 年 9 月,谷歌推出完整的基于神经网络的机器翻译系统 GNMT,取代传统的基于概率的翻译方法,大幅降低翻译错误率,提升翻译质量,支持多种语言的即时翻译。
微软语音识别达到人类水平。 2016 年 10 月,微软宣布其语音识别系统错误率首次达到人类专业转录员的水平,成为语音识别领域的重要里程碑。
硬件与芯片进展:
NVIDIA Pascal 架构 GPU。 2016 年 4 月,英伟达发布基于 16nm FinFET 工艺的 Pascal 架构显卡,GPU 正式成为深度学习和 AI 训练的核心硬件。同年发布了第一台 DGX 超级计算机,内置 8 张 Tesla P100,性能相当于 25 台传统 CPU 服务器。
谷歌 TPU 发布。 2016 年 5 月,谷歌在 I/O 开发者大会上宣布了 TPU(Tensor Processing Unit),这是专门为机器学习设计的 ASIC 芯片,也是背后支撑 AlphaGo 取得胜利的关键硬件。TPU 专门为 TensorFlow 框架优化,推出了计算图优化功能。
英特尔收购 Nervana Systems。 2016 年 8 月,英特尔宣布收购深度学习创业公司 Nervana Systems,计划推出深度学习定制芯片,同时通过 FPGA 技术推动 AI 硬件创新。
寒武纪推出商用 AI 处理器 IP。 中国寒武纪推出 1A 处理器,每秒能够处理 160 亿个神经元,标志着国产 AI 芯片的起步。
产业事件:
Waymo 独立运营。 谷歌的自动驾驶项目 Waymo 在 2016 年年底宣布正式独立运营。
白宫发布 AI 政策。 2016 年 10 月,白宫发布了两个重要的 AI 政策文件,将 AI 提升为美国国家战略,探讨了 AI 的发展规划和对社会的影响。新加坡 nuTonomy 公司开始测试无人驾驶出租车,成为第一家向公众开放自动驾驶汽车的公司。
2017 年:Transformer 改变一切
2017 年是 AI 技术从实验室走向商业化最重要的一年。Transformer 架构的提出彻底改变了自然语言处理乃至整个深度学习的发展方向,AlphaGo 的持续胜利和国家级 AI 战略的出台共同推动了 AI 技术的快速发展。
模型与算法里程碑:
Transformer 架构的提出。 谷歌在 2017 年发表了论文"Attention Is All You Need",首次提出 Transformer 架构。其核心机制是自注意力(Self-Attention),使得模型能够同时考虑输入序列中所有位置的信息,而不像传统的 RNN 或 CNN 那样逐步处理。Transformer 架构不仅提高了模型训练效率,还显著提升了处理长距离依赖关系的能力。后续的 BERT(2018)和 GPT 系列(2018-2024)都基于 Transformer 架构,它成为了现代所有大模型的基石。
AlphaGo 再胜人类。 2017 年 5 月,AlphaGo Master 以 3:0 战胜世界排名第一的围棋选手柯洁。同年 10 月,DeepMind 在 Nature 上发表 AlphaGo Zero 的研究成果,以 100:0 击败 AlphaGo Master。AlphaGo Zero 不需要任何人类棋谱数据,完全通过自我学习从零开始超越所有人类棋手和之前的 AlphaGo 版本,进一步展示了强化学习的强大潜力。
胶囊网络(CapsNet)。 深度学习之父 Geoffrey Hinton 等人提出胶囊网络,旨在解决 CNN 对图像中对象姿态和空间关系处理能力不足的问题。
GAN 变体涌现。 出现 WGAN 等多种变体,解决了 GAN 训练不稳定和生成多样性不足的问题。
开源框架生态:
PyTorch 发布。 2017 年初,Facebook 发布了基于 Python 的深度学习框架 PyTorch,其动态计算图(Define-by-Run)机制使其在处理 NLP 和 GAN 等复杂模型时具有显著优势,迅速吸引了大量研究者和开发者。PyTorch 的开源和快速发展促使 TensorFlow 也引入了动态图机制(Eager 模式)。
TensorFlow 1.0 发布。 引入 Eager 模式和 Keras API,扩展移动端和嵌入式设备支持。
MXNet 成为 Apache 孵化器项目。 亚马逊大力推广 MXNet 框架(后逐渐淡出历史舞台)。
硬件与芯片进展:
谷歌发布第二代 TPU。 2017 年 5 月发布 TPU v2,专门为 AI 训练和推理优化。
NVIDIA Volta 架构 Tesla V100。 12 月发布,进一步提升 AI 训练和推理性能,开始大规模商用。
华为发布麒麟 970。 2017 年 9 月发布全球首款集成 NPU 的手机芯片,应用于 Mate 10。
英特尔推出 Nervana NNP 和 Loihi 芯片。 NNP 专门为深度学习优化;Loihi 采用类脑计算架构,能效比比 CPU 提升高达 1000 倍。
寒武纪完成 1 亿美元 A 轮融资。 成为全球 AI 芯片领域首个独角兽企业。
产业事件:
中国发布"新一代人工智能发展规划"。 2017 年 7 月,国务院发布规划,提出到 2030 年使中国成为全球 AI 创新中心,拟定三步走战略。这是中国首次将 AI 发展提到国家战略高度。
阿里巴巴成立达摩院。 在杭州云栖大会上宣布,未来三年投入 1000 亿人民币用于基础科学和颠覆性科技创新研究。
智能音箱百箱大战。 阿里推出天猫精灵、百度推出 DuerOS、小米推出小米 AI 音箱,智能音箱被视为智能家居的入口,市场进入激烈竞争阶段。其普及推动了语音识别技术和自然语言处理技术的发展。
谷歌在北京设立 AI 中国中心,由李飞飞和李佳领导。多个语音合成技术取得突破:谷歌 WaveNet、Tacotron 以及百度 Deep Voice 等系列模型显著提升了语音合成的自然度和流畅度。前微软亚研常务院长马维英出任今日头条副总裁管理 AI Lab,京东成立 AI 研究院,腾讯宣布成立西雅图 AI 实验室,微软成立 Microsoft Research AI——科技巨头全面布局 AI 研发。
2018 年:BERT 引爆 NLP,AI 欣欣向荣
2018 年是 AI 全面开花的一年,NLP 领域迎来里程碑式突破,AI 芯片创业热潮兴起,但也埋下了后续两年落地不及预期的伏笔。
模型与算法里程碑:
BERT 发布。 谷歌推出 BERT(Bidirectional Encoder Representations from Transformers),基于 Transformer 的双向编码架构,提出了预训练加微调(Pre-training + Fine-tuning)的范式。BERT 在 11 项 NLP 任务中刷新记录,成为 NLP 领域新的里程碑。这一模型的出现彻底改变了语言模型的设计思路,2018 年被称为"NLP 的 ImageNet 时刻"。后续的 ELMo、ULMFiT 等模型进一步推动了迁移学习在 NLP 领域的应用。
GPT-1 发布。 OpenAI 发布了 GPT(Generative Pre-trained Transformer)的第一个版本,基于 Transformer 的 Decoder 部分,展示了语言模型通过大规模预训练获得通用文本生成能力的可能性。
BigGAN。 DeepMind 发布 BigGAN,在图像生成领域表现出色,生成图像的逼真度远超以往模型。
开源框架生态:
PyTorch 1.0 发布。 Facebook 将 PyTorch 与 Caffe2 整合,推出 PyTorch 1.0,其灵活性和动态计算图机制使其在 AI 研究领域迅速普及,逐渐巩固了在深度学习框架中的领先地位。现在几乎所有的大模型都构建在 PyTorch 框架之上。
ONNX 走向成熟。 微软主导的开放神经网络交换格式(ONNX)逐渐成熟,促进了不同框架之间模型的互操作和转换。TensorFlow 发布多个重要版本,推出 TensorFlow.js 和 TensorFlow Lite 等工具。
硬件与芯片进展:
谷歌 TPU v3 发布。 2018 年 5 月在谷歌 I/O 大会上发布,性能对比 TPU v2 提升 8 倍。TPU v3 Pod 由 1024 个芯片组成,计算能力达到每秒 100 PFLOPS。同年发布 Edge TPU,面向 IoT 设备和边缘计算。
NVIDIA DGX-2。 全球首款性能达到 2 PFLOPS 的 AI 超级计算机,由 16 块 Tesla V100 GPU 组成。同年推出 Tesla V100 32GB 版本和 Jetson AGX 边缘计算模块。英伟达的 AI 产品形态从"卖卡"转向"卖节点"。
华为发布昇腾芯片和 Atlas 平台。 打造面向端、边、云全场景的 AI 基础设施。寒武纪推出 MLU100。 首款面向云端的智能推理 AI 芯片。AI 芯片创业热潮兴起,全球 AI 芯片创业公司吸引超过 15 亿美元投资,覆盖神经形态芯片、边缘计算设备等多个方向。深鉴科技在 2018 年被 FPGA 巨头赛灵思收购(赛灵思后又被 AMD 收购)。
产业事件:
谷歌 Duplex 惊艳亮相。 在谷歌 I/O 大会上展示了能够代替用户打电话预约餐馆和理发店的 AI 对话系统,其流畅度和自然语音合成技术引起巨大轰动,同时也引发了 AI 伦理和透明性的讨论。
Waymo 推出商业化自动驾驶服务。 标志着自动驾驶技术从测试阶段迈向实际应用。百度 Apollo 无人驾驶在央视春晚亮相。AI 落地进入"智慧城市"热潮,华为发布智慧城市数字平台,地平线发布基于 AI 芯片的未来城市解决方案。智慧医疗也进一步崛起,飞利浦推出智能互联睡眠呼吸管理解决方案。
OpenAI 发布强化学习教程 Spinning Up。 并推出 Dopamine 框架,简化了强化学习的研究和应用门槛。
2019 年:GPT-2 与 Transformer 统治 NLP
2019 年,自然语言处理领域在 Transformer 架构的推动下取得了全面突破,但 AI 的商业化落地速度开始放缓,行业出现理想与现实的落差。
模型与算法里程碑:
GPT-2 发布。 2019 年 2 月,OpenAI 发布 GPT-2,作为预训练通用大模型,只使用 Transformer 的 Decoder 部分,能够生成高度逼真的文本。OpenAI 出于安全考虑,最初只发布了较小版本,11 月才发布完整版本。GPT-2 的文本生成能力令业界震惊。
BERT 成为 NLP 标杆。 BERT 的预训练加微调模式被广泛应用到问答系统、文本分类等多任务中。百度基于 BERT 提出 ERNIE,通过外部知识图谱提升了语义理解能力。
Transformer 统治 NLP。 RoBERTa、ALBERT、XLNet 等各种变体全部基于 Transformer 架构,在 GLUE 等标准测试集中超越人类平均水平。Facebook 的 XLM 和 mBERT 等模型支持超过 100 种语言。
GAN 走向成熟。 BigGAN 和 StyleGAN 等模型在图像生成任务中表现出色,生成图像的逼真度远超以往,推动了 AI 在艺术创作和内容生成领域的应用。虽然后来 Stable Diffusion 取代了 GAN 成为图像生成的主流技术,但生成式 AI 的火种是由 GAN 点燃的。
CV 领域精细化发展。 Mask Scoring R-CNN 和 SOLO 等算法在图像分割领域超越了传统的 Mask R-CNN。谷歌提出 EfficientNet,大幅减少模型计算量和参数量的同时保持高准确率。
DeepMind AlphaStar。 在星际争霸 2 中击败顶级职业选手,展示了强化学习在不完全信息博弈中的能力。OpenAI 在 Dota 2 中也取得显著进展。OpenAI 还收购了 Atari,获取了强化学习研究中常用的游戏环境。
开源框架生态:
TensorFlow 2.0 发布。 引入 Eager 模式和 Keras 作为默认 API,简化模型开发流程。但 Eager 模式和 Keras 的混合导致用户开发变得混乱,TensorFlow 用户逐渐流失,PyTorch 一枝独大。
HuggingFace 发布 Transformers 库。 专注于 Transformer 架构的模型,迅速成为 NLP 领域的标杆工具和社区。此后所有大模型的发布和分享都离不开 HuggingFace 平台。
百度飞桨(PaddlePaddle)崛起。 发布 Paddle Lite 2.0 和 PaddleOCR 等套件,正式开源框架。
硬件与芯片进展:
华为发布昇腾 910。 全球算力最强的 AI 训练芯片,算力是英伟达 V100 的两倍,标志着中国在 AI 芯片领域的重大突破。
NVIDIA 收购 Mellanox。 以 69 亿美元收购网络技术公司 Mellanox,增强数据中心和高性能计算能力,为后续 AI 集群的网络互联奠定基础。
英特尔收购 Habana Labs。 以 20 亿美元收购以色列 AI 芯片制造商,后续推出 Gaudi 系列。NVIDIA 推出 DGX SuperPod 超级计算机,内置 96 台 DGX 系统。
产业事件:
自动驾驶遭遇瓶颈。 商业化扩展速度明显放缓,Waymo CEO 表示自动驾驶汽车可能永远无法在全路况条件下行驶。
DeepFake 技术滥用引发关注。 利用 AI 生成虚假视频和音频引发安全担忧,Facebook 启动 1000 万美元竞赛推动 DeepFake 检测技术研究。旧金山成为美国第一个禁止政府人员使用人脸识别的大城市。这些事件促使科技公司和社会各界加强了对 AI 技术的监管和防范。
谷歌 AutoML 降低 AI 开发门槛。 推出 AutoML 工具,使非专业用户也能构建高性能模型,但由于计算资源消耗过大,且 Transformer 架构逐渐统一了模型设计,AutoML 技术路线后来逐渐式微。
2020 年:GPT-3 开启大模型时代
2020 年,新冠疫情席卷全球,但 AI 领域仍然诞生了多项突破性进展。GPT-3 的发布标志着大模型时代的开启,AlphaFold 2 在生命科学领域取得了革命性突破。
模型与算法里程碑:
GPT-3 发布。 2020 年 5 月,OpenAI 发布了拥有 1750 亿参数(175B)的 GPT-3,成为当年参数量最大的 NLP 模型。GPT-3 在文本生成、代码编写和对话系统等任务中表现出色,展现了无监督学习和自监督学习的强大潜能。与之前的深度学习模型大多依赖有监督学习(需要人工标注数据)不同,GPT-3 证明了模型能够从海量无标注数据中学习,大幅降低了训练成本并提升了泛化能力。GPT-3 的发布标志着"规模越大,效果越好"的 Scaling Law 成为大模型发展的核心信条。
AlphaFold 2。 DeepMind 的 AlphaFold 2 在国际蛋白质结构预测竞赛(CASP)中夺冠,能够基于氨基酸序列精确预测蛋白质的三维结构,准确度达到实验水平,为药物研发和生物学研究提供了革命性工具。
MuZero。 DeepMind 发布 MuZero 算法并登顶 Nature 主刊,在 Atari、围棋、国际象棋等多种游戏中表现出色。
AI 助力新冠抗疫。 中国多个机构合作开发了基于 CT 扫描检测新冠的 AI 模型,准确度超过 90%。
开源框架生态:
JAX 崛起。 谷歌开发的 JAX 以高性能和灵活的 API 在科研领域获得关注。后续谷歌的 AlphaFold 系列全部基于 JAX 框架开发,JAX 成为 AI4Science 领域的主流框架。
硬件与芯片进展:
NVIDIA A100 GPU 发布。 2020 年 5 月,英伟达在 GTC 大会上发布基于 Ampere 架构的 A100 GPU,引入结构化稀疏性,AI 训练峰值算力达到 312 TFLOPS,推理峰值算力达到 1248 TOPS,同比 Volta 架构性能提升 20 倍。重要的是,A100 首次支持 BF16 数据格式,后来成为大模型训练的标准精度格式。
百度昆仑芯量产。 自研云端 AI 通用芯片昆仑芯量产 2 万片,性能对比 T4 GPU 提升 1.5-3 倍。
NVIDIA 发起 400 亿美元收购 ARM。 希望结合 GPU 与 ARM 架构优势布局 AI 和物联网领域,最终因中国反垄断法等原因未能达成。英伟达后续推出基于 ARM 的 Grace CPU。
寒武纪登陆科创板。 2020 年 7 月正式上市,成为国内首个完全聚焦于 AI 专用芯片研发的科创板上市公司,上市首日市值暴增接近 600 亿。
产业事件:
DeepFake 技术进一步扩散。 能够生成虚假视频和音频,"数字人"概念出现。 AI 数据集偏见问题。 ImageNet 因包含种族主义和性别歧视的标签被下架,Facebook 和谷歌因 AI 偏见问题陷入争议,推动了数据集公平性和透明性的研究,研究人员对数据集进行了重新梳理和校正。 国家标准委等五部门印发《国家新一代人工智能标准体系建设指南》,推动人工智能产业技术研发和标准制定。 AI 在修复历史影像方面取得突破,DAIN 插帧算法、ESRGAN 和 DeOldify 等技术修复并上色了百年前的黑白照片。
2021 年:大模型前夜,多模态崛起
2021 年是大模型爆发的前夜,超大规模预训练模型开始涌现,多模态 AI 迎来崛起,元宇宙概念横扫科技圈。然而 AI 的商业化落地仍未达到预期。
模型与算法里程碑:
AlphaFold 2 开源。 DeepMind 发布 AlphaFold 2 的开源版本(基于 JAX 框架),成功预测了 98% 的人类蛋白质结构,在 Science 杂志公布了 35 万种蛋白质结构的预测结果,直接解决了生物学领域长期困扰的难题。 超大规模预训练模型爆发前夜。 谷歌的 Switch Transformer 使用 MoE(混合专家)架构,模型参数高达 1.6 万亿,成为首个万亿级语言大模型。北京智源人工智能研究院发布全球规模最大的预训练模型"悟道 2.0",参数达到 1.75 万亿,标志着中国在大模型领域的重要突破。 CLIP 和 DALL-E。 OpenAI 发布 CLIP(图像到文本匹配)和 DALL-E(文本到图像生成),推动了多模态 AI 的发展,展示了 AI 在跨模态领域的巨大潜力。这两个模型为 2022 年 Stable Diffusion 等文生图技术的爆发奠定了基础。
硬件与芯片进展:
全球 AI 芯片市场规模达到 101 亿美元,预计 2025 年增长到 726 亿美元。 寒武纪发布训练芯片思元 290。 百度昆仑芯完成第二代产品。 NVIDIA 基于 Ampere 架构的 A100 系列全面铺开,RTX 30 系列支持光线追踪和 DLSS。 地平线完成 C2 轮 4 亿美元融资,推动边缘计算和终端 AI 芯片布局。 腾讯发布三款芯片:紫霄(AI 计算)、沧海(视频处理)、玄灵(高性能网络)。
产业事件:
Facebook 改名 Meta,全面转向元宇宙。 元宇宙概念成为 2021 年最热门的科技话题,国内也成立了元宇宙产业委员会(Meta 两年后发现元宇宙不太行,又全面转向 AI)。 商汤科技在港交所上市。 成为全球最大的 AI 公司 IPO 之一,但 2021-2023 年累计亏损超过 250 亿元。云从科技、旷视和依图的上市之路也充满波折。 自动驾驶商业化试点。 百度 Apollo 在北京、广州等地开始常态化运营。 全球多国发布 AI 治理策略:欧盟起草了基于风险分级的 AI 应用条例,中国发布"新一代人工智能伦理规范",美国提出 AI 权利法案。这些政策为 AI 的健康发展提供了法律和伦理框架,推动了全球 AI 治理共识的形成。 自动驾驶进入商业化试点。 百度 Apollo 在北京、广州等地开始常态化运营(2023 年萝卜快跑才真正出圈),小鹏汽车也在多个地区开展自动驾驶试点服务。不过 2021 年的自动驾驶领域烧了很多钱,技术路线尚未探明——直到特斯拉 FSD V12 出来后,业界才发现大模型可以做端到端自动驾驶。
2022 年:ChatGPT 横空出世
2022 年是 AI 领域的分水岭,也是最戏剧性的一年。年初 AI 产业经历低谷期,AI 四小龙业务萎靡,资本市场降温,业界弥漫着"AI 落地难"的悲观情绪。然而,年底 ChatGPT 的横空出世彻底扭转了局面,为 AI 领域注入了前所未有的活力,开启了大模型和生成式 AI 的新纪元。
模型与算法里程碑:
ChatGPT 发布。 2022 年 11 月,OpenAI 发布了基于 GPT-3.5 的对话式 AI 大模型 ChatGPT,能够生成高质量的自然语言回复,完成撰写邮件、代码、文案等多种任务。ChatGPT 引发了全球范围内的广泛关注和讨论,展示了大语言模型在通用任务中的巨大潜力,推动了 AI 助手技术的发展。这是 AI 从技术圈走向大众视野的标志性时刻。 DALL-E 2 和 Stable Diffusion。 文生图技术迎来爆发。OpenAI 发布 DALL-E 2,分辨率比前一代提高 4 倍。Stability AI 开源发布 Stable Diffusion,使用 VAE、CLIP 文本编码和扩散模型技术,使任何人都能根据文本描述生成逼真图片。AIGC(AI 生成内容)时代正式开启。 AlphaCode 代码生成。 DeepMind 发布 AlphaCode,在 Codeforces 编程挑战赛中击败 46% 的参赛者,登上 Science 封面,标志着 AI 在代码生成领域的重大突破。 多模态模型探索。 DeepMind 的 Gato 全能型智能体和 Meta 的 Data2Vec 展示了多模态大模型的能力。 Meta 发布 OPT-175B 大模型,效果一般但其训练过程的 debug 记录为社区提供了宝贵的学习资料。
开源框架生态:
PyTorch 基金会成立。 2022 年 9 月,Linux 基金会宣布正式成立 PyTorch 基金会,PyTorch 从 Meta 转移到 Linux 基金会运作。截至 2022 年 8 月,PyTorch 已与 Linux 内核和 K8s 并列成为世界上增长最快的五个开源社区之一。2023 年 10 月,华为昇腾作为首个 Premier 会员加入 PyTorch 基金会。
硬件与芯片进展:
NVIDIA H100 GPU 发布。 2022 年 3 月发布基于 Hopper 架构的 H100 GPU,采用台积电 4nm 工艺。H100(及其退化国产版本 H800)成为后续大模型训练的核心硬件。 AMD 以 500 亿美元收购赛灵思。 芯片行业历史上规模最大的交易之一。 谷歌发布 TPU v4。 支持 4096 个芯片组成 Pod 集群,提供 1 EFLOPS 算力。 壁仞科技发布首款通用 GPU 芯片 BR100,阿里平头哥发布 RISC-V 芯片平台。 美国半导体出口管制。 2022 年 10 月,美国商务部发布多项半导体出口管制措施,限制中国获得先进计算芯片和制造设备。这对华为昇腾、寒武纪等造成较大影响,但也加速了国产替代的进程。
产业事件:
AI 低谷期与资本降温。 2022 年初出现 AI 低谷期,AI 四小龙业务萎靡,缺乏增量但人力成本高企。全球 AI 领域融资金额 458 亿美元,同比下降 34%。商汤科技因限售股解禁导致股价暴跌 50%,市值蒸发 915 亿港元;旷视、依图的 IPO 进程也屡屡受挫。AI 企业普遍面临高额研发投入和长期亏损的困境——算法泛化能力不足,每个场景需要独立的算法工程师优化,导致企业需要为不同场景做定制化开发,商业化效率低下。云计算市场也处于低迷期,"一张卡恨不得掰成两半来卖"。 受俄乌战争、疫情等因素影响,全球芯片供应链面临较大波动,稀有气体供应不稳定和晶圆厂减产对 AI 芯片的生产和交付造成挑战。 年底 ChatGPT 的发布彻底扭转了这一颓势,给 AI 领域注入了新的生命力,也让资本市场重新审视 AI 的商业价值。
2023 年:百模大战,大模型元年
2023 年是 AI 领域取得重大突破的一年。ChatGPT 的热度持续发酵,引发了全球范围内的"百模大战"。大模型从实验室走向实际应用,开源生态蓬勃发展,AI 技术的商业化进程加速推进。与此同时,AI 监管也成为全球关注的焦点。
模型与算法里程碑:
GPT-4 发布。 OpenAI 发布 GPT-4,能够处理文本和图像,在复杂任务中表现出色,证明了多模态大模型的可行性。GPT-4 的训练使用了约 1 万张 NVIDIA A100,训练一次成本高达约 1 亿美元。ChatGPT 月活突破 1 亿,成为历史上用户增长最快的消费级应用。 百模大战爆发。 截至 2023 年 10 月,中国已发布超过 130 个大模型。百度率先发布文心一言,阿里推出通义千问,华为发布盘古大模型 3.0。AI 六小虎崛起——百川智能(王小川创立,开源 7B/13B 模型)、零一万物(李开复孵化)、月之暗面(杨植麟创立 Kimi,凭借超长上下文一鸣惊人)、MiniMax(商汤出走团队,专注海外市场)、阶跃星辰(微软前副总裁姜大昕创立)和智谱 AI(国内最早探索大模型的公司,发布 GLM-130B)。 AlphaFold 3。 DeepMind 发布 AlphaFold 3,成功预测 2.14 亿个蛋白质结构,几乎涵盖整个"蛋白质宇宙",为 2024 年诺贝尔奖颁给计算机科学家埋下伏笔。 生成式视频萌芽。 2023 年下半年出现 Runway Gen-2 和 Pika 等工具,可以生成数秒钟的短视频。
开源生态:
LLaMA 开源引爆热潮。 2023 年 3 月,Meta 发布 LLaMA 大模型并被开源社区泄露,引起了整个开源大模型的热潮。7 月又正式发布免费商用版本 LLaMA 2,成为众多创业公司大模型的基座。许多国内公司的 7B、13B、34B 参数规格都沿用了 LLaMA 的设定。开源文化的盛行真正推动了大模型技术的快速共享和进步,降低了技术门槛。 Stable Diffusion 等开源文生图工具繁荣发展。
硬件与芯片进展:
NVIDIA H200 发布。 2023 年 10 月发布,内存达到 141GB HBM3e,带宽 4.8 TB/s,分别为 H100 的 1.8 倍和 1.4 倍,为大模型训练提供更强硬件支撑。 微软、Meta、亚马逊、阿里、腾讯、字节等互联网大厂纷纷开始自研 AI 芯片。 算力成本成为制约大模型发展的核心因素,抢购 NVIDIA 芯片成为常态,企业开始关注国产 AI 算力。
产业事件:
大模型价格战。 2023 年下半年,字节豆包等企业通过大幅降价争夺市场。 特斯拉展示 FSD V12 端到端自动驾驶。 2023 年 8 月,马斯克通过直播展示了特斯拉 FSD V12 的端到端自动驾驶能力,标志着大模型对传统自动驾驶算法的全面冲击。百度发布第六代量产无人车 Apollo RT6,成本降至 25 万元。 AI 监管加速。 欧盟推出《人工智能法案》,美国在拜登领导下发布 AI 行政命令,进一步限制对中国出口先进 AI 芯片。 大模型应用开始从实验室走向实际,文心一言在教育和金融领域率先落地,通义千问在电商和营销场景落地。不过实际落地效果参差不齐——百度没有用大模型革新其搜索引擎的根基,阿里后来将通义千问实验室拆分到不同业务部门。 大模型训练成本高昂。 GPT-4 的训练使用约 1 万张 A100 GPU,单次训练成本约 1 亿美元。算力成本成为制约大模型发展的核心瓶颈,各家企业开始关注训练效率优化和国产算力替代方案。 北京智源人工智能研究院、上海人工智能研究院以及众多高校科研机构也在大模型领域取得重要进展,推动了技术的开源和普及。
2024 年:多模态元年与推理革命
2024 年是 AI 技术全面爆发的一年,也是多模态技术的元年。多模态大模型成为主流范式,推理模型开辟了新的 Scaling Law 方向,具身智能和自动驾驶迎来商业化突破。生成式 AI 从文本和图像扩展到视频、音频和 3D 全领域,AI 正以前所未有的速度重塑世界。大模型从通用走向专用,从执行走向思考,AI Agent 也开始成为新的发展热点。
模型与算法里程碑:
GPT-4o 与多模态全面爆发。 OpenAI 推出 GPT-4o,支持文本、音频、图像等多种模态的实时处理和生成,展示了强大的多模态理解能力。注意这里从"生成"进化到了"理解"。 Sora 视频生成。 2024 年 2 月,OpenAI 推出视频生成大模型 Sora,能够根据文本提示生成高质量视频,支持多角度镜头转换和复杂物体运动,被誉为"世界模型"。Sora 的出现引发了视频生成领域的全面竞赛,国内外多家公司跟进推出类似产品。 推理模型革命。 2024 年圣诞节,OpenAI 在连续 12 天发布会中推出 O3 推理模型,接近人类水平的推理能力,标志着 AI 从简单生成走向自主决策的转变。2025 年 1 月,月之暗面的 Kimi K1.5 和 DeepSeek R1 相继发布,基于"强化学习 + 大模型"的 Test-Time Reasoning 模式成为新的 Scaling Law 方向。 生成式 AI 全面开花。 Suno AI 发布 Suno V3 文本生成音乐;Luma AI 发布 Genie 文本生成 3D 模型。生成式 AI 从文本、图像扩展到视频、音频和 3D 全领域。
具身智能与自动驾驶:
具身智能元年。 特斯拉发布 Optimus 人形机器人,Figure AI 发布 Figure 02 在宝马工厂展示工业应用。中国宇树科技发布 B2-W 机器狗,展现了托马斯旋转、侧空翻等极限动作。具身智能加上大模型迎来新春天,各地纷纷成立具身智能创新中心。 端到端自动驾驶全面推进。 特斯拉 FSD V12 系统全面推进,标志着大模型在量产车上的自动驾驶落地成为可能。小鹏、华为、蔚来、理想等公司都开始使用大模型布局端到端自动驾驶技术。 萝卜快跑商业化。 百度旗下萝卜快跑在武汉试点后,2024 年三季度订单接近 100 万单,标志着自动驾驶从测试阶段迈向实际应用。
硬件与芯片进展:
NVIDIA Blackwell 架构 B200 GPU。 2024 年 3 月在 GTC 大会上发布,AI 性能在 FP8 和 FP6 格式上分别达到 20 PFLOPS 和 40 PFLOPS,是 Hopper 架构的 2.5 倍和 5 倍。 谷歌量子计算芯片 Willow。 用 5 分钟完成传统计算机需要
产业事件:
AI 六小虎竞争白热化。 智谱、月之暗面、MiniMax 等初创企业在技术和商业化上取得显著成果。零一万物出局(2025 年初宣布解散/被阿里并购),幻方量化(DeepSeek)成为新的六小虎之一。六小虎整体融资金额超过 200 亿元。 AI 应用全面普及。 豆包 APP、Kimi APP、智谱开放平台等产品快速铺开。AI 助手类产品占总流量的 62.93%,AI 应用访问量年度增幅超过 111%。 Meta Ray-Ban 智能眼镜。 Meta 与 Ray-Ban 合作的第二代智能眼镜大受欢迎,销售量突破 300 万台。其 AI 助手功能支持语音控制、拍照和导航等任务,成为 AI 硬件普及的重要里程碑。国内也有多家创业公司进入智能眼镜赛道。 全球 AI 产业融资超过 4000 亿元,同比增长 77%。传统搜索引擎开始受到大模型 APP 的威胁,越来越多用户转向使用 AI 助手进行信息检索。 AI 应用深入日常生活。 越来越多的普通用户了解大模型、懂得 Prompt 工程,大语言模型成为日常工作中的得力助手。AI 从娱乐工具真正变成了生产力工具。
趋势总结:十年演进的五条主线
回顾 2014-2024 这十年,AI 的发展可以从以下五条主线来理解:
1. 模型架构的范式迁移。 从 CNN(2012-2016 的主导架构,AlexNet → VGG → ResNet)到 RNN/LSTM(2014-2017 的序列建模主流),再到 Transformer(2017 至今的通用架构),每一次范式迁移都带来了性能的飞跃。Transformer 以其并行化能力和对长距离依赖的建模优势,逐步统一了 NLP、CV 和多模态领域,成为大模型时代的基石。Vision Transformer(ViT)的出现更是打破了"CNN 做视觉、Transformer 做语言"的固有分工。
2. Scaling Law 驱动的规模竞赛。 从 GPT-1(1.17 亿参数,2018)到 GPT-3(1750 亿参数,2020),再到 Switch Transformer(1.6 万亿参数,2021),模型规模呈指数级增长。OpenAI 的研究表明,模型性能与参数量、数据量和计算量之间存在幂律关系(Scaling Law),这成为了大模型发展的核心理论基础。2024 年开始,Test-Time Reasoning 开辟了新的 Scaling 方向——不再只是增大预训练规模,而是在推理阶段通过强化学习进行更深层次的思考,DeepSeek R1 等模型的成功证明了这一方向的可行性。
3. 硬件算力的持续军备竞赛。 从 NVIDIA Pascal(2016)到 Volta(2017)、Ampere(2020)、Hopper(2022)再到 Blackwell(2024),每一代 GPU 架构都为大模型训练提供了数量级的算力提升。英伟达的产品形态也经历了从"卖卡"到"卖节点"(DGX)再到"卖集群"(SuperPod)的演进。与此同时,谷歌 TPU(从 v1 到 v4)、华为昇腾、寒武纪等替代方案的涌现使得 AI 芯片市场从英伟达一家独大走向多元竞争。美国的芯片出口管制(2022)加速了中国国产 AI 芯片的替代进程。
4. 开源生态的繁荣。 从 TensorFlow(2015)和 PyTorch(2017)的框架之争,到 HuggingFace(2019)成为模型分发的标准平台,再到 LLaMA(2023)引爆开源大模型热潮,开源文化极大加速了 AI 技术的普及和创新。PyTorch 基金会的成立(2022)标志着 AI 开源治理走向成熟。但开源与闭源之间始终存在张力——OpenAI 从最初的开源理念转向闭源商业化,而 Meta 的 LLaMA 则逆向推动了开源大模型的繁荣。这种开闭源的博弈在很大程度上塑造了整个行业的生态格局。
5. 从感知到认知,从生成到推理。 AI 能力的演进可以划分为三个阶段:2014-2018 年是感知智能时代,AI 在图像识别、语音识别等感知任务上达到甚至超越人类水平;2019-2022 年是生成智能时代,GPT 系列和 Stable Diffusion 等模型展示了强大的文本和图像生成能力;2023-2024 年则进入了认知智能和推理智能的新阶段,O3 和 DeepSeek R1 等推理模型展示了接近人类的逻辑推理能力。AI 正在从"识别模式"走向"理解世界",从"生成内容"走向"自主思考",从"执行指令"走向"主动规划"。
下表汇总了十年间各维度的代表性里程碑:
| 年份 | 模型/算法 | 硬件/芯片 | 产业/开源 |
|---|---|---|---|
| 2014 | GAN, VAE, DeepFace | 神经形态芯片 | 谷歌收购 DeepMind |
| 2015 | ResNet, DQN (Nature) | GPU 成为 AI 标配 | TensorFlow 开源, OpenAI 成立 |
| 2016 | AlphaGo 胜李世石 | Pascal GPU, TPU v1 | Waymo 独立, 美国 AI 国家战略 |
| 2017 | Transformer, AlphaGo Zero | Volta V100, TPU v2 | PyTorch, 中国 AI 发展规划 |
| 2018 | BERT, GPT-1 | TPU v3, DGX-2 | PyTorch 1.0, ONNX, Duplex |
| 2019 | GPT-2, AlphaStar | 昇腾 910, NVIDIA 收购 Mellanox | HuggingFace Transformers, TF 2.0 |
| 2020 | GPT-3, AlphaFold 2 | A100 (Ampere) | JAX, 寒武纪上市 |
| 2021 | CLIP, DALL-E, Switch Transformer | AI 芯片市场 101 亿美元 | Meta 元宇宙, 商汤上市 |
| 2022 | ChatGPT, Stable Diffusion | H100 (Hopper), TPU v4 | PyTorch 基金会, 美国芯片管制 |
| 2023 | GPT-4, AlphaFold 3, 百模大战 | H200 | LLaMA 开源, AI 六小虎 |
| 2024 | GPT-4o, Sora, O3, DeepSeek R1 | B200 (Blackwell), Willow | 具身智能, 萝卜快跑, AIPC |
这十年的发展告诉我们:AI 的进步从来不是线性的,而是由关键技术突破(AlexNet、Transformer、ChatGPT)引发的阶梯式跃迁。每一次跃迁都伴随着算法创新、硬件升级和产业变革的共振——新的模型架构催生对更强算力的需求,更强的算力又反过来使得更大规模的模型成为可能,而开源生态则加速了这一正向循环。
回望过去十年,2018 年的 AI 欣欣向荣后曾迎来两年的落地低谷(2019-2021),当时许多人对 AI 的商业价值产生了怀疑。但 ChatGPT 的出现证明,真正的技术范式转移需要的是耐心积累,而非急于求成。正如 2015 年成立的 OpenAI 花了七年才推出 ChatGPT,2017 年提出的 Transformer 也用了五年才通过 ChatGPT 展现其全部潜力。
展望未来,多模态理解、推理决策、具身智能和 AI Agent 将成为下一个十年的核心战场。AI 技术正从"能做什么"走向"该怎么做"的新阶段,如何让 AI 安全、可控、负责任地服务于人类社会,将是技术发展之外最重要的命题。