12.1 微调策略概览
经过大规模预训练后,语言模型已经在海量无标注语料中习得了丰富的语法结构、世界知识和基础推理能力。然而,预训练模型就像一个博览群书却从未上过讲台的学者——它拥有广博的知识,但还不会以人类期望的方式回答问题、执行特定任务或遵循自然语言指令。微调(Fine-Tuning) 正是将这位学者"训练上岗"的关键一步:在预训练模型的基础上,利用规模更小、质量更高的标注数据集进行再次训练,使其适配特定的下游任务或对齐人类意图。
本节将从宏观视角梳理微调策略的全景图:微调技术是如何一步步发展的?当前主流的微调方法有哪些分类维度?全参数微调和参数高效微调各有什么优劣?分类微调与指令微调的本质区别是什么?理解这些问题,是深入学习后续 SFT 数据、LoRA、RLHF 等具体技术的前提。
12.1.1 从迁移学习到微调:历史脉络
微调并非大模型时代的发明,它的思想根植于迁移学习(Transfer Learning)——将在源任务上习得的知识迁移到目标任务中。在计算机视觉领域,这一范式早已成熟:在 ImageNet 上预训练一个 ResNet,然后冻结浅层特征提取器、替换分类头,用少量标注数据微调最后几层,就能快速获得高性能的领域分类器。NLP 领域沿着类似的路径演进,但走出了自己独特的发展曲线。
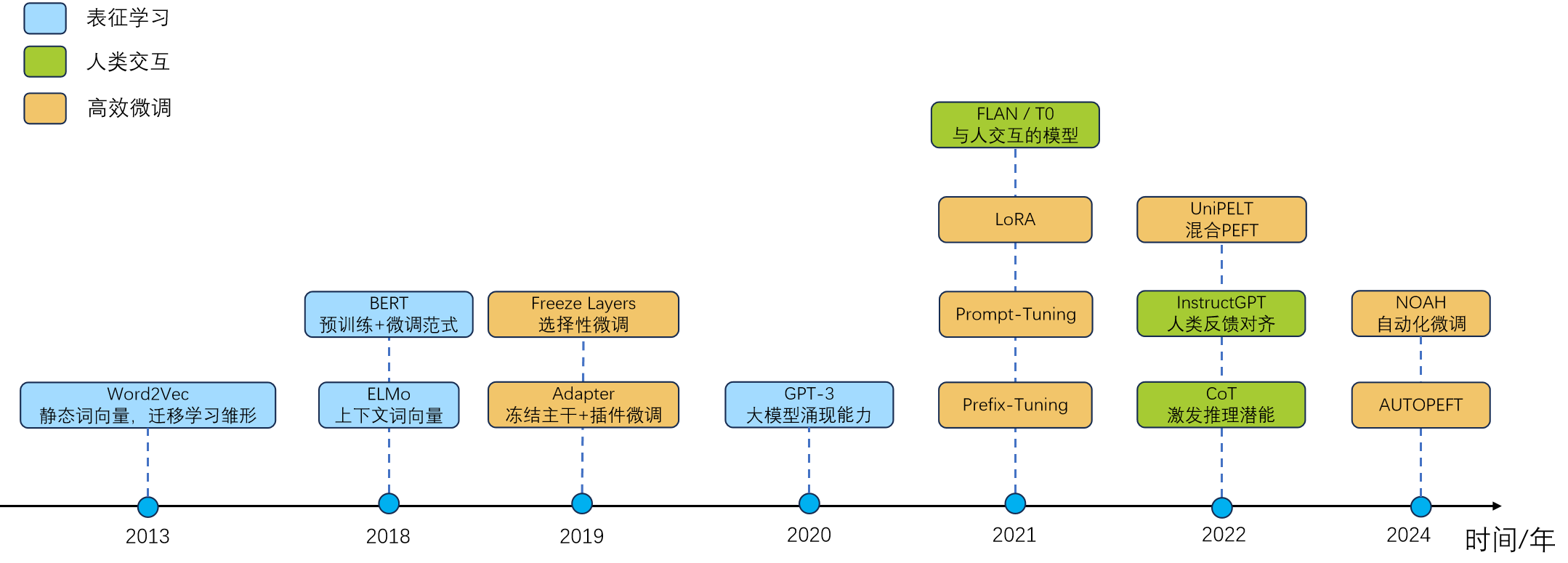
图 12-1:微调技术发展时间线。蓝色节点代表表征学习里程碑,绿色节点代表人类交互里程碑,橙色节点代表高效微调里程碑。
微调的发展大致分为三个阶段:
第一阶段:特征迁移时代(2013--2017)。 Word2Vec(2013)和 GloVe 开创了静态词向量时代,预训练模型提供通用的词嵌入表示,下游任务在其基础上训练 CNN 或 RNN 等浅层网络。此时的"微调"本质上是冻结词向量、只训练任务特定网络。局限也很明显——静态词向量无法处理一词多义("苹果"是水果还是公司?),知识迁移效率有限。
第二阶段:任务微调时代(2018--2020)。 2018 年是转折点。ELMo 引入了上下文相关的动态词表示,BERT 通过双向 Transformer 和掩码语言建模任务,正式确立了**"预训练 + 全参数微调"** 的标准流程。在这一范式下,模型先在海量文本上预训练,再在特定任务的标注数据上端到端微调所有参数,仅需更换任务头(如分类层)。BERT 及其后继者(RoBERTa、ALBERT)在 GLUE、SQuAD 等基准上刷新纪录,微调成为提升任务性能的黄金标准。与此同时,GPT-1 提出了另一条路径——用自回归 Decoder-only 架构预训练,然后在下游任务上微调。GPT-1 的微调方式极其简洁:只需在输入序列中加入特殊 token(如分隔符、开始/结束标记),取最后一个 token 的输出向量接线性分类器即可。这种将"任务指令融入输入格式"的思想,已经埋下了指令微调的种子。
第三阶段:快速发展时代(2021--至今)。 GPT-3 展示了强大的上下文学习能力,研究者意识到语言模型的核心价值不在完成单一任务,而在于作为通用智能体与人类交互协作。这一阶段沿两条主线并行发展:
- 人类意图对齐主线: FLAN 和 T0(2021--2022)验证了指令微调的有效性,使模型真正能"听懂人话"。InstructGPT(2022)引入 RLHF,首次实现大规模人类偏好对齐。DPO(2023)提出无需显式奖励模型的简洁替代方案,迅速成为开源社区主流。
- 高效微调主线: 面对百亿、千亿参数模型带来的显存压力,2019 年的 Adapter 率先验证"冻结主干 + 插件微调"的可行性,2021 年迎来 PEFT 的黄金元年——Prefix-Tuning、Prompt Tuning 和 LoRA 三大方法相继提出。
12.1.2 微调在训练流程中的定位
理解微调,首先需要明确它在大模型完整训练流程中的位置。下图展示了一个典型的训练管线:
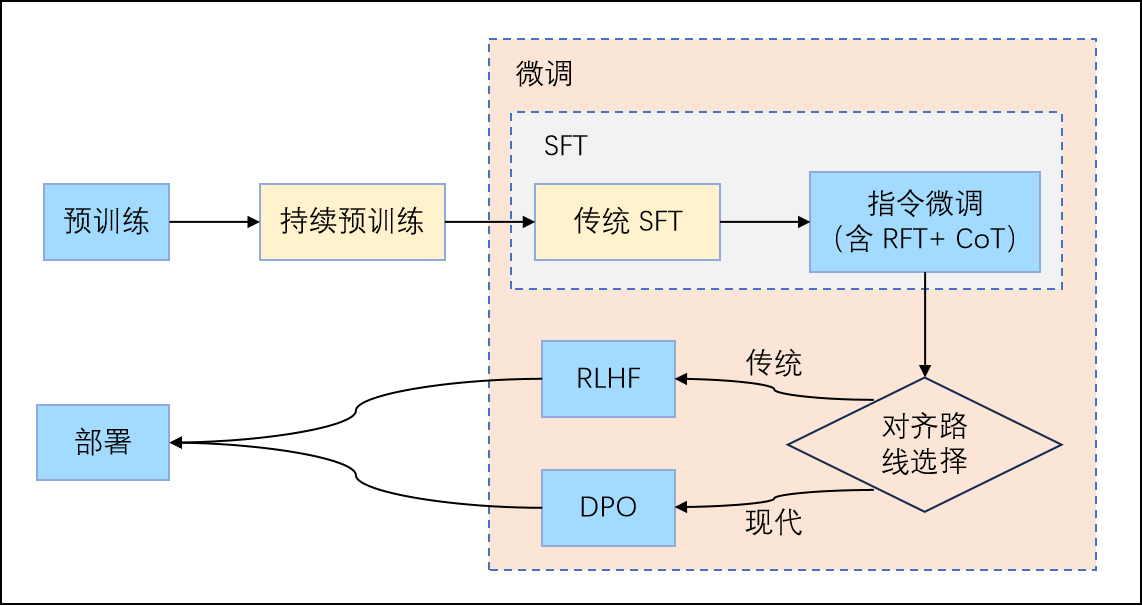
图 12-2:大模型训练全流程。蓝色方框为常规步骤,微调(SFT + 对齐)是预训练之后、部署之前的核心环节。
各阶段的职责如下:
- 预训练(Pre-training): 在大规模无标注文本上通过自监督学习优化模型参数,使其习得语言统计规律、语法结构和世界知识。
- 持续预训练(Continual Pre-training): 当目标领域与预训练数据分布差距很大时(如需要从英文扩展到中文),可在领域数据上继续预训练,弥补域间差距。
- 有监督微调(Supervised Fine-Tuning, SFT): 使用标注数据进行有监督训练,使模型适配特定任务或学会遵循指令。
- 人类偏好对齐(Alignment): 通过 RLHF 或 DPO 等算法,使模型输出符合人类价值观和偏好。
- 部署(Deployment): 模型上线服务。
广义上,微调涵盖了预训练之后的所有训练阶段(SFT + 对齐);狭义上,社区常将微调直接等同于指令微调(Instruction Tuning)。本章及后续章节将聚焦于 SFT 阶段,对齐技术则留待后续篇章讨论。
在实际工程中,不同角色的微调起点也有所不同。以 DeepSeek-V3 为例:
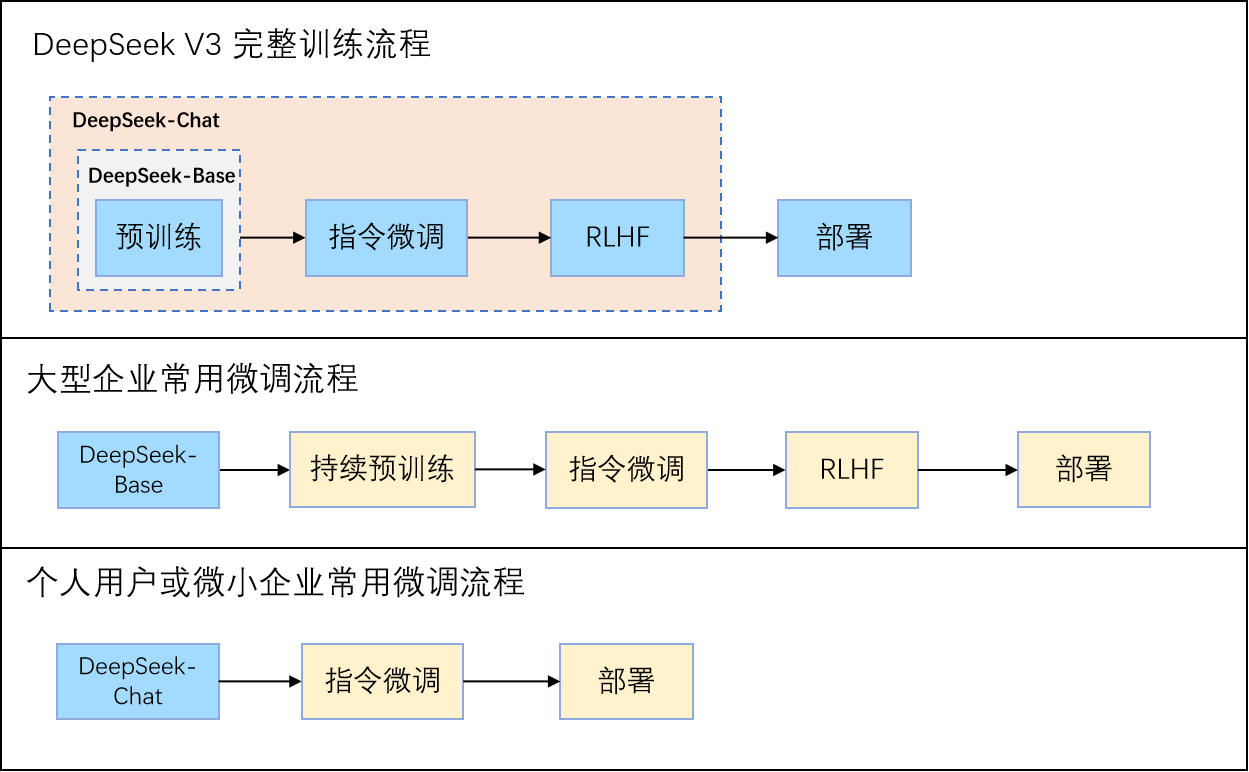
图 12-3:不同场景下的微调起点选择。大型企业从 Base 模型出发进行完整训练;个人用户从 Chat 模型出发,用领域数据进行指令微调即可。
- 大型企业拥有充足算力,通常从 Base 模型开始,依次执行持续预训练、指令微调和 RLHF。
- 个人用户或中小团队受限于硬件资源,通常直接从 Chat 模型(已经过一轮指令微调和对齐的成品模型)出发,用特定领域数据进行轻量化的指令微调。
12.1.3 分类微调 vs 指令微调
SFT 是一个广泛的概念,按照训练目标和数据组织方式的不同,可以分为传统分类微调和指令微调两大范式。
传统分类微调(Classification Fine-Tuning) 源于 BERT 时代,其目标是在单一特定任务上达到最优性能。典型流程是在预训练模型顶部添加一个任务头(如线性分类层),然后用任务特定的标注数据端到端训练。数据格式为简单的"输入 → 输出"对,每个数据集只包含一种任务类型:
# 分类微调的数据格式示例
# 情感分类任务
{"text": "这部电影真的太好看了!", "label": "positive"}
{"text": "剧情拖沓无聊", "label": "negative"}
# 文本蕴含任务
{"premise": "猫在垫子上", "hypothesis": "有动物在垫子上", "label": "entailment"}微调后的模型变成了一个专用工具(如情感分类器),无法处理其他任务。如果需要同时处理情感分类、命名实体识别和机器翻译,就需要分别微调三个独立的模型。
指令微调(Instruction Tuning) 源于大语言模型时代,目标是让模型具备通用的"听懂自然语言指令并执行"的能力。数据格式是"指令 + 输入 → 输出"三元组,且包含多种异构任务的混合:
# 指令微调的数据格式示例
# 翻译任务
{"instruction": "将英文翻译成中文。",
"input": "I love this movie.",
"output": "我喜欢这部电影。"}
# 摘要任务
{"instruction": "用一句话总结以下段落。",
"input": "量子计算利用量子力学原理...",
"output": "量子计算通过量子叠加和纠缠实现超越经典计算的能力。"}
# 代码生成任务
{"instruction": "写一个 Python 函数计算斐波那契数列第 n 项。",
"input": "",
"output": "def fib(n):\n if n <= 1: return n\n return fib(n-1) + fib(n-2)"}下表总结了两种范式的核心差异:
| 维度 | 传统分类微调 | 指令微调 |
|---|---|---|
| 目标 | 单一任务最优性能 | 通用指令遵循能力 |
| 数据 | 同质、单任务(如 1 万条"文本→情感标签") | 异构、多任务混合(摘要+翻译+问答+改写) |
| 模型结构 | 预训练模型 + 任务特定头 | 统一生成接口,无任务特定结构 |
| 微调后能力 | 专用工具(如情感分类器) | 通用助手,支持零样本泛化 |
| 代表时期 | BERT 时代(2018--2020) | LLM 时代(2021--至今) |
表 12-1:传统分类微调与指令微调对比。
需要注意的是,在当前社区中,人们通常将 SFT 直接等同于指令微调,因为分类微调已随着 BERT 时代的结束而逐渐退出主流。但理解这一历史演进有助于把握微调技术的本质——从"为每个任务设计模板+任务头"到"统一生成接口+用自然语言本身传达意图"的范式转换。
12.1.4 全参数微调 vs 参数高效微调
按照微调过程中更新的参数数量,微调方法分为两大类:全参数微调(Full Fine-Tuning, FFT) 和参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。
图 12-4:PEFT 方法全景。右半部分展示了四类主流 PEFT 策略的基本思想:Selective(选择性冻结/解冻层)、Additive(插入 Adapter 等小模块)、Prompt(添加可学习的提示向量)、Reparameterization(LoRA 低秩分解)。
全参数微调是最直接的思路——在微调阶段更新模型的所有参数。优点是能最大程度适配下游任务,通常在数据充足、算力充裕时取得最优性能。InstructGPT 和 Llama 2 Chat 在官方训练流程中均采用 FFT。然而代价极高:
- 显存消耗大: 微调一个 7B 模型通常需要多张 80GB 显存的 GPU。模型参数之外,梯度和优化器状态(Adam 的一阶矩、二阶矩通常是参数量的 4 倍以上)占据了大量显存。
- 存储成本高: 每微调一个任务就需保存一套完整的模型权重副本。
- 过拟合风险: 在小数据集上容易过拟合或因学习率不当导致灾难性遗忘(Catastrophic Forgetting)。
下面的代码展示了全参数微调的基本模式——所有参数都参与梯度更新:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 全参数微调:所有参数的 requires_grad 默认为 True
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
print(f"可训练参数: {trainable_params:,} / {total_params:,} = 100.00%")
# 输出: 可训练参数: 124,439,808 / 124,439,808 = 100.00%参数高效微调的核心思想是冻结预训练模型的绝大部分参数,仅引入少量可训练参数(通常不到总参数量的 1%),通过轻量级模块注入任务特定知识。当前主流的 PEFT 方法可按策略分为四类:
| 类别 | 代表方法 | 核心思想 | 典型参数量占比 |
|---|---|---|---|
| 加性方法 | Adapter(2019) | 在 Transformer 层中串行插入瓶颈结构(降维→激活→升维+残差) | ~3.6% |
| 提示方法 | Prefix-Tuning、Prompt Tuning(2021) | 在输入或注意力层前添加可学习的连续向量 | ~0.1% |
| 重参数化方法 | LoRA(2021) | 将权重更新分解为两个低秩矩阵 | ~0.5% |
| 选择性方法 | BitFit、Freeze Layers | 仅解冻部分层(如最后几层)或特定参数(如偏置项) | 视配置而定 |
表 12-2:四类 PEFT 方法对比。
其中 LoRA 因其简洁、高效、可合并(推理时无额外延迟)等优点,成为当前最主流的 PEFT 方法。以下代码展示了使用 PEFT 库将 LoRA 应用于模型的典型方式:
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained("gpt2")
# 配置 LoRA:只在注意力层的 q_proj 和 v_proj 上插入低秩适配器
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=16, # 缩放因子
target_modules=["c_attn"], # 目标模块
lora_dropout=0.1,
)
# 将 LoRA 注入模型,冻结原始参数
model = get_peft_model(base_model, lora_config)
model.print_trainable_parameters()
# 输出示例: trainable params: 294,912 || all params: 124,734,720 || trainable%: 0.24%可以看到,LoRA 仅需训练原始参数量的 0.24%,却能达到接近全参数微调的效果。
两类方法并非互斥。在实际工程中,选择策略取决于资源条件和任务需求:
- 追求性能上限(如训练官方旗舰模型)→ 全参数微调;
- 资源有限但需要领域适配(如个人用户在 Chat 模型上微调)→ PEFT(尤其是 LoRA)。
12.1.5 SFT 的训练机制
无论采用全参数微调还是 PEFT,SFT 的训练机制在底层是一致的。对于自回归语言模型,SFT 的本质是Next Token Prediction(下一个 Token 预测)——模型学习根据已有上下文预测下一个 token,训练目标是最小化负对数似然损失:
其中
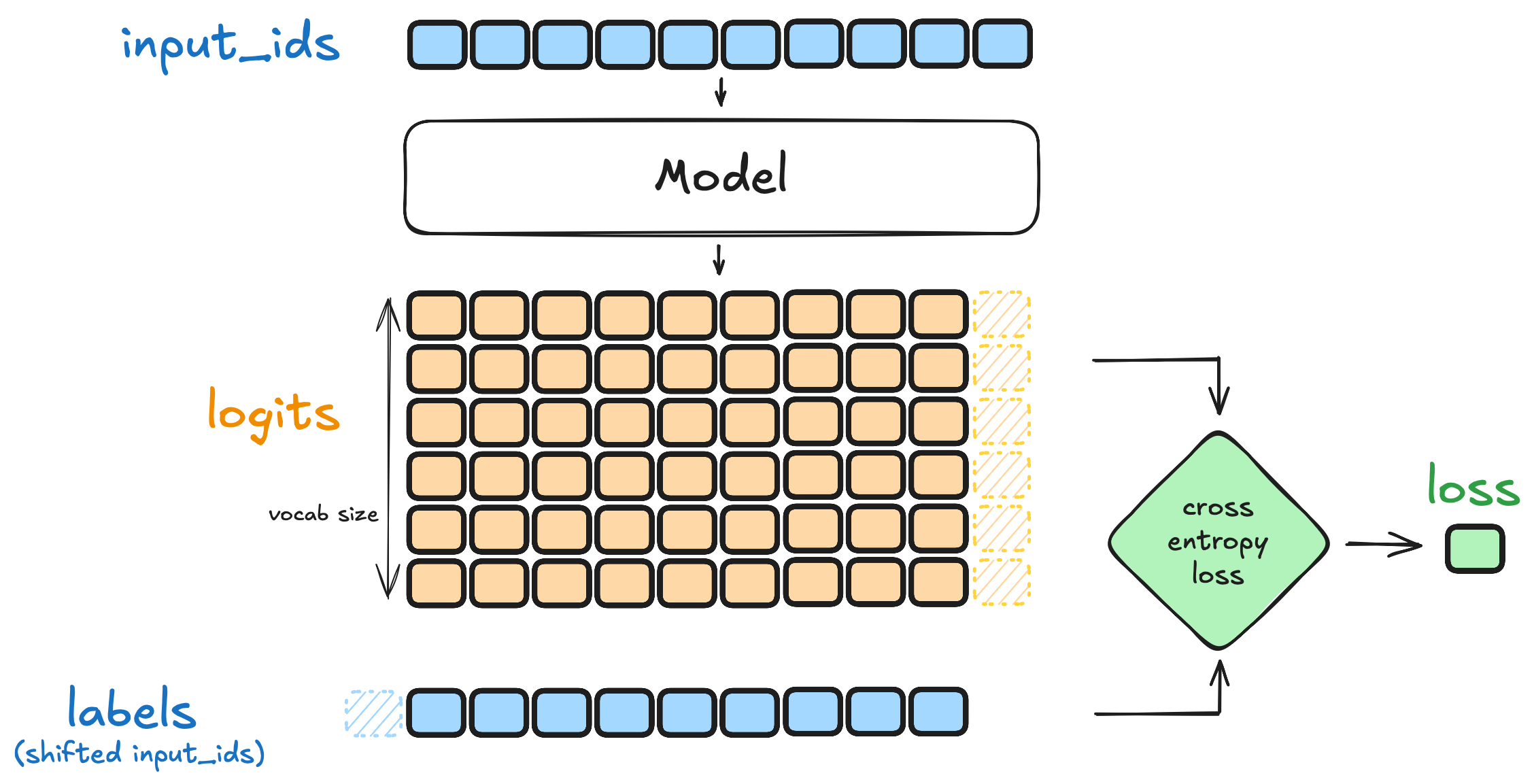
图 12-5:SFT 损失计算流程。输入序列经模型产生每个位置的词表概率分布(logits),与右移一位的标签序列计算交叉熵损失。
仅在助手回复上计算损失。 在指令微调中,一个关键的实践技巧是只对模型的回复部分计算损失,而屏蔽用户提问和系统指令部分。直觉上很好理解:我们希望模型学习"如何回答",而不是学习"如何提问"——后者是预训练阶段已经处理的事情。
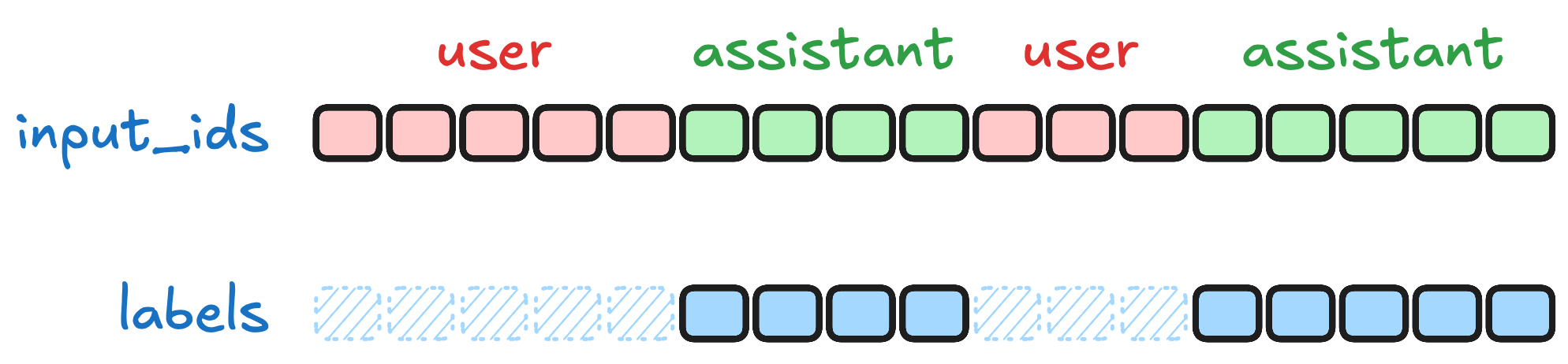
图 12-6:仅对 assistant 回复部分计算损失。粉色为 user 消息 token,绿色为 assistant 回复 token。labels 中只有 assistant 部分保留真实 token id(实色),其余位置设为 -100(阴影)表示忽略。
下面的代码展示了这一机制的核心逻辑——构建 loss mask,使得只有助手回复部分参与损失计算:
import torch
import torch.nn.functional as F
def compute_sft_loss(logits, input_ids, loss_mask):
"""
计算仅对助手回复部分的 SFT 损失。
Args:
logits: 模型输出, shape [batch, seq_len, vocab_size]
input_ids: 输入 token id, shape [batch, seq_len]
loss_mask: 标记哪些位置计算损失, shape [batch, seq_len], 1=计算 0=忽略
"""
# 构建 next-token prediction 的输入和标签
shift_logits = logits[:, :-1, :] # 预测位置: [0, T-2]
shift_labels = input_ids[:, 1:] # 目标位置: [1, T-1]
shift_mask = loss_mask[:, 1:] # mask 与标签对齐
# 逐 token 计算交叉熵(不做内部 reduction)
loss_per_token = F.cross_entropy(
shift_logits.reshape(-1, shift_logits.size(-1)),
shift_labels.reshape(-1),
reduction="none"
).reshape(shift_labels.shape)
# 只对 mask=1 的位置求平均
masked_loss = (loss_per_token * shift_mask).sum() / shift_mask.sum()
return masked_loss12.1.6 SFT 数据格式
SFT 的效果在很大程度上取决于数据质量和格式。当前主流框架(如 TRL 的 SFTTrainer)支持两种基本格式:
语言建模格式(Language Modeling): 直接提供完整文本,模型学习预测序列中的每一个 token:
# 标准格式
{"text": "量子计算是一种利用量子力学原理的计算范式。"}
# 对话格式(自动应用 chat template)
{"messages": [
{"role": "user", "content": "什么是量子计算?"},
{"role": "assistant", "content": "量子计算是一种利用量子叠加和纠缠等量子力学原理的计算范式。"}
]}提示-补全格式(Prompt-Completion): 明确区分提示和回复,训练时默认只对回复部分计算损失:
# 标准格式
{"prompt": "什么是量子计算?", "completion": "量子计算是一种利用量子力学原理的计算范式。"}
# 对话格式
{"prompt": [{"role": "user", "content": "什么是量子计算?"}],
"completion": [{"role": "assistant", "content": "量子计算是一种利用量子力学原理的计算范式。"}]}在多轮对话场景中,每个 user → assistant 的回合都被标记为需要计算损失的区间。数据预处理的核心挑战在于正确构建 loss mask,确保每一轮助手回复的内容都被标注为"需要学习",而用户提问和特殊 token 则被屏蔽。
使用 TRL 的 SFTTrainer 可以极大地简化这一流程:
from trl import SFTConfig, SFTTrainer
from datasets import load_dataset
# 三行代码完成指令微调
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B",
args=SFTConfig(
output_dir="./sft_output",
assistant_only_loss=True, # 仅对 assistant 回复计算损失
max_length=512,
),
train_dataset=load_dataset("trl-lib/Capybara", split="train"),
)
trainer.train()12.1.7 SFT 工程实践要点
在实际微调中,以下几点工程经验至关重要:
数据质量优先于数量。 SFT 不需要预训练那样的海量数据。Alpaca 仅用 5.2 万条 GPT 生成的指令数据就微调出了可用的指令模型。关键在于数据的多样性(覆盖多种任务类型)、准确性(答案正确无歧义)和格式一致性(统一的 chat template)。
防止灾难性遗忘。 在垂直领域数据上微调时,模型容易"遗忘"通用能力。常见缓解策略包括:
- 在领域数据中混入一定比例(如 10-20%)的通用指令数据
- 使用较小的学习率(如
)和较少的训练轮次(1--3 epoch) - 采用 PEFT 而非全参数微调,天然减少对原始知识的干扰
加入拒答样本。 为防止模型对超出能力范围的问题"迷之自信"地胡编乱造,应在训练数据中混入拒答样本——面对不当或越界请求时,模型应输出标准化的拒绝回复(如"很抱歉,我无法协助此请求")。
合理划分 SFT 与 RAG 的职责。 SFT 擅长让模型学习推理模式和业务流程结构,但不适合承载大量时效性强或高频更新的事实信息。后者应交给 RAG(Retrieval-Augmented Generation,检索增强生成)处理。"SFT + RAG"的组合可以有效减少幻觉问题。
12.1.8 小结
本节从宏观视角梳理了微调策略的全景图。核心要点回顾如下:
- 微调的本质是迁移学习的延伸——在预训练知识的基础上,用高质量标注数据适配特定任务或对齐人类意图。
- 按训练流程,微调定位于预训练之后、部署之前,包括 SFT 和人类偏好对齐两大阶段。
- 按任务类型,微调经历了从分类微调(单任务、任务头)到指令微调(多任务、统一生成接口)的范式转换。
- 按参数规模,微调分为全参数微调(FFT,追求性能上限)和参数高效微调(PEFT,追求效率与可及性)。
- SFT 的训练机制是 next-token prediction + 仅对助手回复计算损失。
- 工程实践中,数据质量、防遗忘策略和拒答样本是保障微调效果的关键。
后续章节将在此基础上深入展开:§12.2 讨论 SFT 数据构造与 chat template 设计,§12.3 详解 LoRA 等 PEFT 技术的原理与实现,§12.4 介绍微调的工程实操流程。