16.2 PPO(近端策略优化)
在 15.2 节中,我们从 RLHF 全流程的视角介绍了 PPO 的基本角色——它是连接奖励模型与策略优化的"最后一公里"。但当时对 PPO 算法本身的讨论仅停留在公式层面。本节将深入 PPO 的内部机理:从 TRPO 到 PPO 的演进动机、裁剪机制的分类讨论、Actor-Critic 在 LLM 场景下的工程实现,以及一个从零构建的完整 PPO 训练循环。
16.2.1 从 TRPO 到 PPO:信赖域的简化
策略梯度的根本矛盾。 朴素的策略梯度算法(如 REINFORCE)有一个致命缺陷——它是纯在策略(On-Policy) 的:每次采样只能更新一次参数,然后必须丢弃数据重新采样。这导致了极低的样本效率。
为了复用已采集的数据,TRPO(Trust Region Policy Optimization) 引入了重要性采样(Importance Sampling),允许用旧策略
其中
但直接最大化
这需要计算 KL 散度的二阶近似(Fisher 信息矩阵),并用共轭梯度法求解,实现复杂且计算开销大。
PPO 的核心洞察。 Schulman 等人在 2017 年提出了一个优雅的替代方案:用裁剪(Clipping)代替 KL 约束。与其费力计算二阶信息来限制 KL 散度,不如直接对概率比
16.2.2 裁剪机制的深度剖析
PPO-Clip 的精妙之处在于:只在"有利方向"上限制更新幅度,在"纠错方向"上不设上限。让我们逐一分析所有情形。
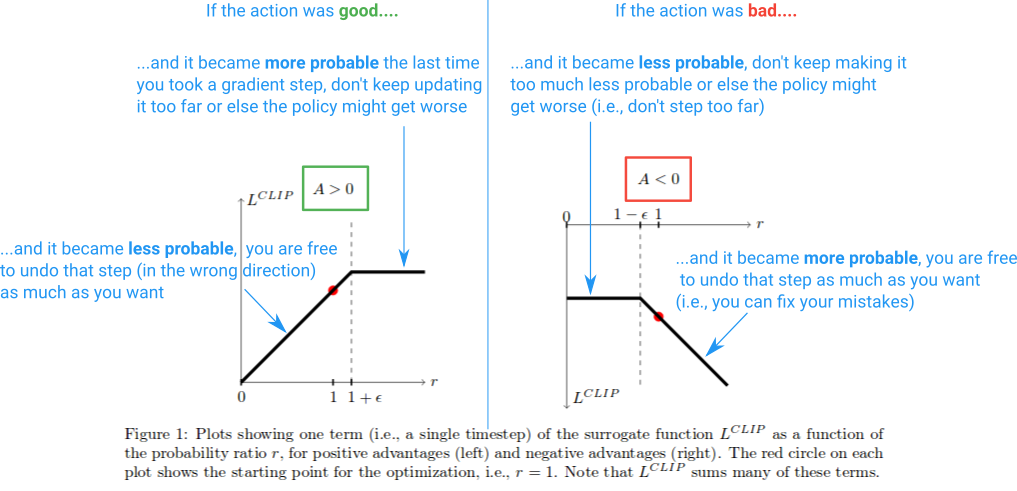
图 16-1:PPO-Clip 的核心机制。左图:好动作(A>0)概率增长被截断在 1+epsilon,防止过度乐观;右图:坏动作(A<0)概率下降被截断在 1-epsilon,防止矫枉过正。纠错方向(好动作概率降低了、坏动作概率升高了)不受限制。
情形 1:
- 若
:概率已经增长过多。 ,取 后使用裁剪项,梯度被截断,阻止继续增大 - 若
:好动作的概率反而降低了,这是"错误",不应限制修复。取 后使用原始项 (值更小),梯度不受限,自由恢复
情形 2:
- 若
:概率已经下降过多。 ,此时 (两个负数比较),取 使用裁剪项,梯度被截断 - 若
:坏动作的概率反而升高了,这是"错误"。取 使用原始项(值更小即更负),梯度不受限,自由修正
核心设计哲学: PPO 采取了一种"悲观更新"策略——对策略改进方向设置天花板(防止过度优化),对纠错方向则放开限制(允许快速修复错误)。
下面用代码验证上述分析:
import torch
def ppo_clip_loss(log_probs, old_log_probs, advantages, epsilon=0.2):
"""
PPO-Clip 损失函数。
Args:
log_probs: 当前策略的 log 概率, shape [batch, seq_len]
old_log_probs: 旧策略的 log 概率, shape [batch, seq_len]
advantages: 优势函数值, shape [batch, seq_len]
epsilon: 裁剪范围
Returns:
标量损失值(取负号,因为 PyTorch 最小化 loss)
"""
# 计算概率比: r_t = pi_new / pi_old = exp(log_new - log_old)
ratio = torch.exp(log_probs - old_log_probs)
# 未裁剪的代理目标
surr1 = ratio * advantages
# 裁剪后的代理目标
surr2 = torch.clamp(ratio, 1.0 - epsilon, 1.0 + epsilon) * advantages
# 取 min 实现"悲观更新",取负号转为最小化问题
policy_loss = -torch.min(surr1, surr2).mean()
return policy_loss
# 验证: 好动作 + ratio 过大 -> 应被裁剪
adv_pos = torch.tensor([1.0])
ratio_high = torch.tensor([1.5]) # 超过 1+0.2
log_new = torch.log(ratio_high)
log_old = torch.zeros(1)
loss = ppo_clip_loss(log_new, log_old, adv_pos)
print(f"好动作 ratio=1.5: loss={loss.item():.3f}")
# 裁剪后 min(1.5*1, 1.2*1) = 1.2, loss = -1.216.2.3 四模型架构与工程实现
PPO 在 LLM 对齐中的实现需要同时维护四个模型,这也是其工程复杂度远高于 DPO 的根源。
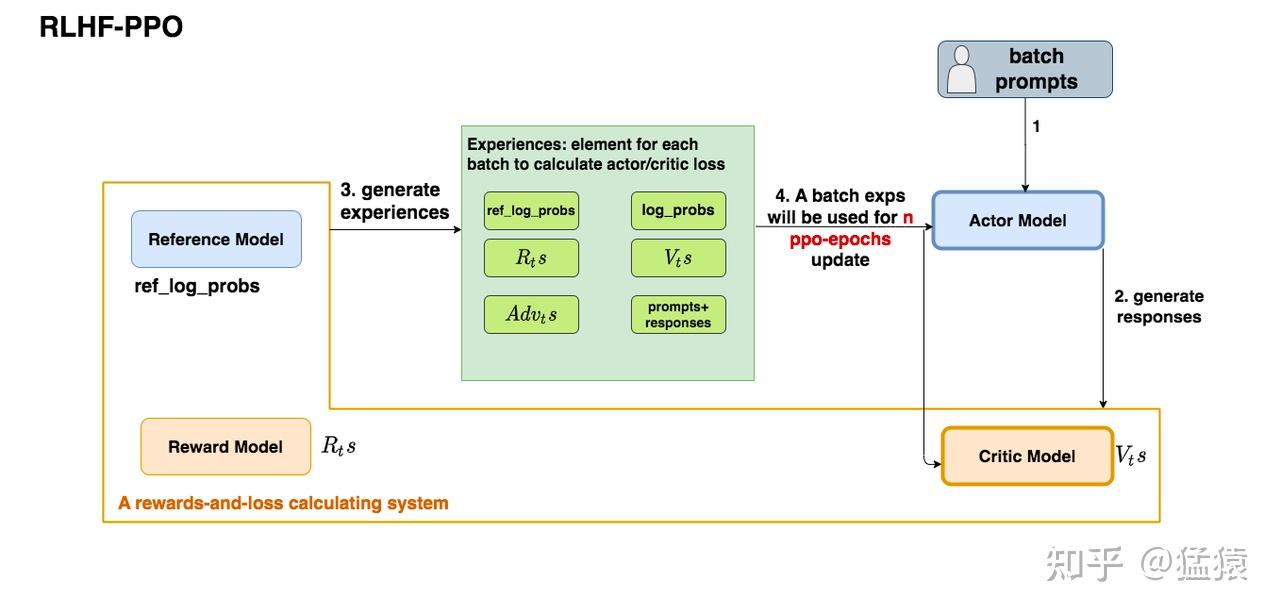
图 16-2:RLHF-PPO 的数据流。Actor 模型根据 prompt 生成回答,Reference 模型和 Reward 模型分别提供 KL 约束和奖励信号,Critic 模型估计状态价值,四者协同计算出 experience 后进行多轮策略更新。
| 模型 | 符号 | 初始化来源 | 训练状态 | 输出 |
|---|---|---|---|---|
| Actor(策略模型) | SFT 模型 | 训练中 | 给定 prompt,生成 response | |
| Critic(价值模型) | SFT 或 RM 模型 | 训练中 | 估计每个 token 位置的状态价值 | |
| Reference(参考模型) | SFT 模型 | 冻结 | 提供 KL 约束基准 | |
| Reward(奖励模型) | 偏好数据训练 | 冻结 | 对完整回答打分 |
Critic 的特殊设计。 Critic 模型的结构与 Actor 几乎相同,唯一区别是输出头:Actor 使用 lm_head(输出词表大小的 logits),Critic 则将其替换为一个输出标量的线性层 nn.Linear(hidden_size, 1),用于预测每个 token 位置的状态价值。
import torch
import torch.nn as nn
class CriticModel(nn.Module):
"""
Critic 模型:基于语言模型骨架,替换输出头为标量价值预测。
"""
def __init__(self, base_model, hidden_size):
super().__init__()
self.backbone = base_model # Transformer 骨架(共享 Actor 的结构)
# 替换 lm_head 为标量输出
self.value_head = nn.Linear(hidden_size, 1, bias=False)
def forward(self, input_ids, attention_mask=None):
# 获取最后一层隐状态
hidden_states = self.backbone(
input_ids, attention_mask=attention_mask
).last_hidden_state # [batch, seq_len, hidden_size]
# 映射为标量价值
values = self.value_head(hidden_states).squeeze(-1) # [batch, seq_len]
return valuesReference 模型的作用。 Reference 模型是 SFT 模型的一份冻结副本,它的唯一职责是提供
显存挑战。 以 7B 参数模型为例,四个模型在 FP16 下需要约 56 GB 显存,这还不包括激活值、梯度和优化器状态。常用的缓解策略包括:
- DeepSpeed ZeRO-3:将参数分片到多卡,按需聚合
- LoRA:仅训练 Actor 和 Critic 的低秩适配器,大幅减少可训练参数
- 共享骨架:Actor 和 Critic 共享 Transformer 骨架,仅各自维护独立的输出头
16.2.4 奖励组装与优势计算
在 RLHF 中,PPO 使用的奖励信号并非直接来自 Reward Model,而是经过精心组装的复合信号。
逐 token 奖励的组装公式。 对于生成序列中的第
- KL 惩罚是逐 token 的稠密信号,约束每一步都不偏离参考模型太远
- RM 打分是句子级别的稀疏信号,仅在序列末尾给出整体评价
这种"稠密 KL + 稀疏 RM"的设计,既提供了逐步的方向引导(避免 Reward Hacking),又在全局层面追求高质量输出。
import torch
def compute_rewards(actor_log_probs, ref_log_probs, rm_scores,
action_mask, kl_coef=0.1):
"""
组装 PPO 训练用的逐 token 奖励。
Args:
actor_log_probs: Actor 的 log 概率, [batch, seq_len]
ref_log_probs: Reference 的 log 概率, [batch, seq_len]
rm_scores: Reward Model 打分, [batch] (标量)
action_mask: response 部分的 mask, [batch, seq_len]
kl_coef: KL 惩罚系数 beta
Returns:
rewards: 逐 token 的奖励, [batch, seq_len]
"""
# 1) 稠密 KL 惩罚: 每个 token 都有
kl_penalty = -kl_coef * (actor_log_probs - ref_log_probs)
rewards = kl_penalty
# 2) 找到每个序列的最后一个有效 token 位置
eos_indices = (action_mask.sum(dim=1) - 1).long() # [batch]
# 3) 在 EOS 位置叠加 RM 打分(稀疏信号)
for i in range(rewards.size(0)):
rewards[i, eos_indices[i]] += rm_scores[i]
return rewardsGAE 优势计算。 有了逐 token 的奖励后,下一步是利用 GAE 计算优势函数(15.1 节已推导公式,这里聚焦实现)。在 LLM 场景中,GAE 的计算仅在 response 部分进行,prompt 部分不参与:
import torch
def compute_gae_for_llm(rewards, values, action_mask,
gamma=1.0, lam=0.95):
"""
为 LLM 的 PPO 训练计算 GAE 优势和回报值。
仅计算 response 部分(由 action_mask 标记)。
Args:
rewards: 逐 token 奖励, [batch, seq_len]
values: Critic 预测的价值, [batch, seq_len]
action_mask: response 部分 mask, [batch, seq_len]
gamma: 折扣因子(LLM 中通常取 1.0)
lam: GAE lambda
Returns:
advantages: 优势值, [batch, seq_len]
returns: 回报值(用于训练 Critic), [batch, seq_len]
"""
batch_size, seq_len = rewards.shape
advantages = torch.zeros_like(rewards)
for b in range(batch_size):
last_gae = 0.0
# 从后往前递归计算
for t in reversed(range(seq_len)):
if action_mask[b, t] == 0:
continue
next_value = values[b, t + 1] if t + 1 < seq_len else 0.0
delta = rewards[b, t] + gamma * next_value - values[b, t]
last_gae = delta + gamma * lam * last_gae
advantages[b, t] = last_gae
returns = advantages + values
return advantages.detach(), returnsLLM 的 PPO 训练中
16.2.5 完整 PPO 训练循环
将上述所有组件组装在一起,就构成了一轮完整的 PPO 迭代。以下代码展示了核心训练逻辑(简化自 MiniMind 的 train_ppo.py 实现):
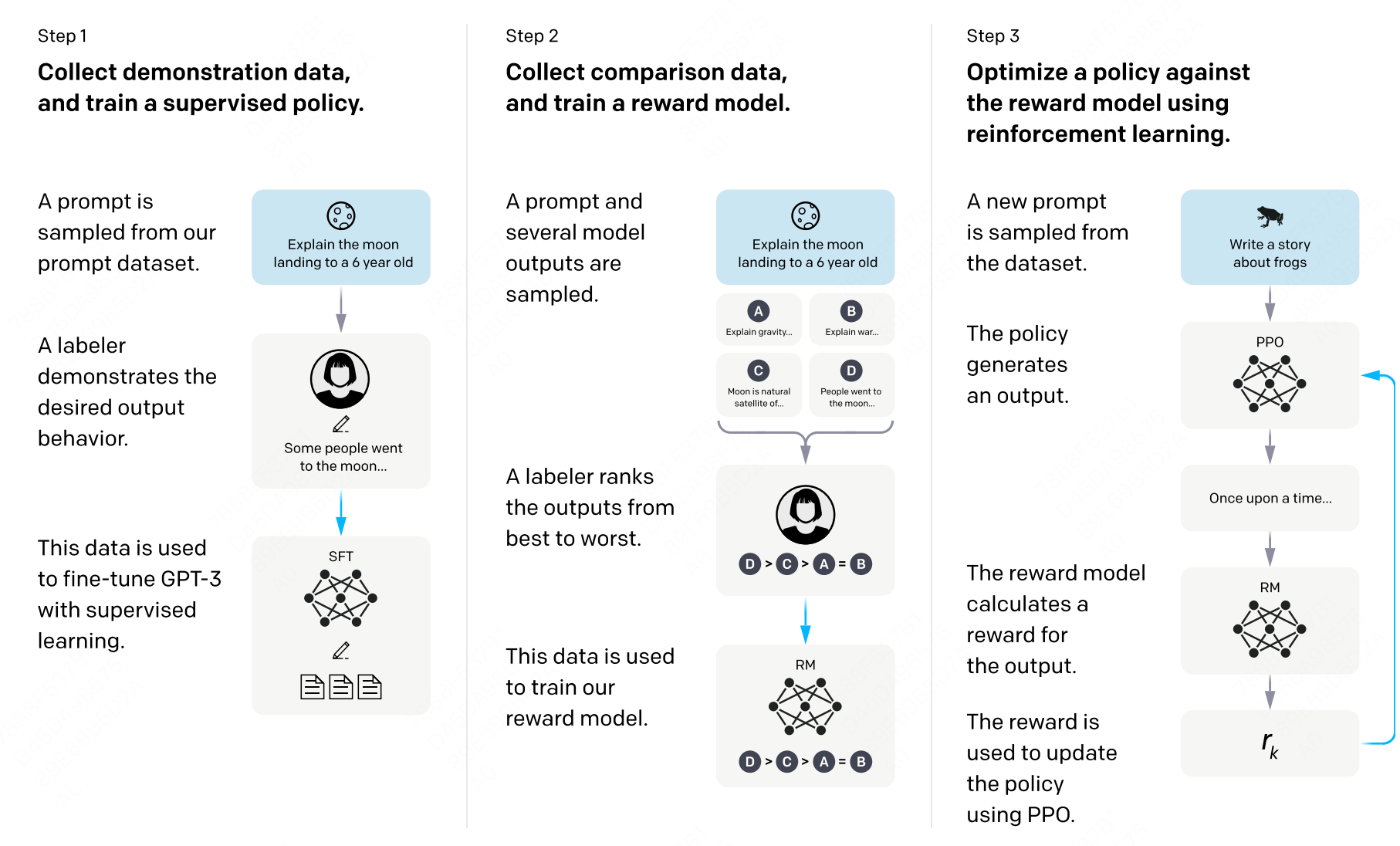
图 16-3:InstructGPT 三阶段流程。PPO 训练阶段(第三阶段)需要 Actor、Critic、Reward、Reference 四个模型协同工作。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
import torch.nn.functional as F
def ppo_train_step(actor, critic, ref_model, reward_model,
prompts, tokenizer,
clip_epsilon=0.2, vf_coef=0.5, kl_coef=0.02,
ppo_epochs=4):
"""
PPO 单步训练(一个 batch)。
Args:
actor: 策略模型(可训练)
critic: 价值模型(可训练)
ref_model: 参考模型(冻结)
reward_model: 奖励模型(冻结)
prompts: 输入 prompt 的 token ids, [batch, prompt_len]
tokenizer: 分词器
clip_epsilon: PPO 裁剪范围
vf_coef: 价值损失权重
kl_coef: KL 惩罚系数
ppo_epochs: 每批数据的训练轮数
"""
actor.eval()
# ===== Phase 1: 采样(Rollout)=====
with torch.no_grad():
# Actor 生成回答
generated = actor.generate(prompts, max_new_tokens=256,
do_sample=True, temperature=0.7)
response_ids = generated[:, prompts.size(1):]
# 计算 old_log_probs(作为后续 ratio 的分母)
full_ids = generated
actor_output = actor(full_ids)
old_log_probs = get_per_token_log_probs(
actor_output.logits, full_ids
).detach()
# Reference 的 log_probs
ref_output = ref_model(full_ids)
ref_log_probs = get_per_token_log_probs(
ref_output.logits, full_ids
)
# Reward Model 打分
rm_scores = reward_model.score(full_ids) # [batch]
# Critic 估值
values = critic(full_ids).detach() # [batch, seq_len]
# ===== Phase 2: 计算优势 =====
action_mask = build_response_mask(full_ids, prompts.size(1))
rewards = compute_rewards(old_log_probs, ref_log_probs,
rm_scores, action_mask, kl_coef)
advantages, returns = compute_gae_for_llm(
rewards, values, action_mask, gamma=1.0, lam=0.95
)
# 优势标准化
adv_mean = advantages[action_mask.bool()].mean()
adv_std = advantages[action_mask.bool()].std() + 1e-8
advantages = (advantages - adv_mean) / adv_std
# ===== Phase 3: 多轮更新 =====
actor.train()
for epoch in range(ppo_epochs):
# 当前策略的 log_probs
new_output = actor(full_ids)
new_log_probs = get_per_token_log_probs(
new_output.logits, full_ids
)
# Critic 当前估值
new_values = critic(full_ids)
# --- Policy Loss (PPO-Clip) ---
ratio = torch.exp(new_log_probs - old_log_probs)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_epsilon,
1 + clip_epsilon) * advantages
policy_loss = -torch.min(surr1, surr2)
policy_loss = (policy_loss * action_mask).sum() \
/ action_mask.sum()
# --- Value Loss (MSE with optional clip) ---
value_loss = F.mse_loss(
new_values * action_mask, returns * action_mask
)
# --- 总损失 ---
loss = policy_loss + vf_coef * value_loss
loss.backward()
# ... optimizer.step(), scheduler.step() ...
# 早停: 若 KL 过大则退出内循环
approx_kl = (old_log_probs - new_log_probs).mean()
if approx_kl > 0.02:
break
def get_per_token_log_probs(logits, input_ids):
"""提取每个 token 对应的 log 概率。"""
log_probs = F.log_softmax(logits[:, :-1, :], dim=-1)
labels = input_ids[:, 1:]
per_token = torch.gather(
log_probs, dim=-1, index=labels.unsqueeze(-1)
).squeeze(-1)
return per_token
def build_response_mask(full_ids, prompt_len):
"""构建 response 部分的 mask。"""
mask = torch.zeros_like(full_ids, dtype=torch.float)
mask[:, prompt_len:] = 1.0
return mask关键实现细节解读:
- 采样用当前策略,分母固定不变。 标准 PPO 实践中,先用 Actor 生成数据,立刻计算一遍 log_probs 并 detach 作为
old_log_probs。这保证了 ratio 初始值为 1,后续多轮更新中 ratio 逐渐偏离 1,clip 机制限制偏离幅度 - 优势标准化。 在计算完 GAE 后,对整个 batch 的优势值做 z-score 标准化(减均值除标准差),可以稳定训练
- 多轮更新(PPO Epochs)。 一批采样数据通常被复用 3-5 轮,每轮重新计算 ratio 和梯度。KL 早停机制防止复用过多导致策略偏移
- 仅计算 response 部分。 通过
action_mask确保 loss 只作用在 response token 上,prompt 部分不参与梯度计算
16.2.6 Value Loss 的裁剪
与 Policy Loss 类似,Critic 的 Value Loss 也可以引入裁剪来稳定训练。这一技术被称为 Clipped Value Loss:
其中
这里取
def clipped_value_loss(values, old_values, returns, clip_eps=0.2):
"""带裁剪的 Critic 损失函数。"""
# 将新 value 限制在旧 value 的 ±epsilon 邻域内
values_clipped = old_values + torch.clamp(
values - old_values, -clip_eps, clip_eps
)
# 两个候选 loss
loss_unclipped = (values - returns) ** 2
loss_clipped = (values_clipped - returns) ** 2
# 取较大者: 即使 clip 后更准也不奖励,防止 value 更新过快
loss = 0.5 * torch.max(loss_unclipped, loss_clipped).mean()
return loss16.2.7 KL 散度的蒙特卡洛估计
在 PPO-RLHF 中,KL 散度惩罚是防止 Reward Hacking 的核心机制。然而精确计算
蒙特卡洛近似。 由于 KL 散度的定义本身就是一个期望:
而生成的 token 正好是从
这就是代码中 (actor_log_probs - ref_log_probs).mean() 的数学基础——它是 KL 散度的无偏估计量(Unbiased Estimator),无需遍历词表,计算量极小。
此外,trl 等工业级框架通常采用更精确的 Schulman KL 估计器:
该估计器的方差更低,且始终非负。
16.2.8 使用 trl PPOTrainer
HuggingFace 的 trl 库提供了生产级的 PPO 训练器,封装了上述所有细节。以下是一个典型的使用示例:
# 安装: pip install trl
# 启动 PPO 训练
accelerate launch --config_file deepspeed_zero2.yaml \
ppo_train.py \
--model_name_or_path EleutherAI/pythia-1b-deduped \
--sft_model_path <your_sft_model> \
--reward_model_path <your_reward_model> \
--learning_rate 3e-6 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 4 \
--total_episodes 100000 \
--num_ppo_epochs 4 \
--num_mini_batches 1 \
--missing_eos_penalty 1.0 \
--stop_token eos关键超参数解读:
| 参数 | 默认值 | 含义 |
|---|---|---|
--num_ppo_epochs | 4 | 每批数据的 PPO 内循环轮数 |
--cliprange | 0.2 | 裁剪范围 |
--missing_eos_penalty | 1.0 | 未生成 EOS 的惩罚(引导完整回答) |
--learning_rate | 3e-6 | 学习率(通常比 SFT 小一个数量级) |
--total_episodes | 10000 | 总训练 episode 数 |
训练监控。 PPO 训练需要关注以下指标判断是否健康:
objective/rlhf_reward:最终 RLHF 奖励(RM 分数 - KL 惩罚),应持续上升val/ratio:概率比的均值,应浮动在 1.0 附近。若飙升到 2.0+,说明策略更新过猛 policy/clipfrac_avg:被裁剪的更新比例,过高意味着策略变化过大objective/kl:策略与参考模型的 KL 散度,应缓慢增长,不能爆炸
图 16-4:PPO 训练后模型的生成效果对比。经过 PPO 训练的模型能生成更符合人类偏好的回答。
16.2.9 On-Policy 与工程权衡
PPO 是严格的 On-Policy 算法——训练数据必须由当前策略生成。这带来了一个根本性的工程挑战:采样与训练必须交替进行,无法像 SFT 那样预先准备好全部数据。
标准流程 vs 滚动更新。 严格的 PPO 实现遵循以下流程:
- 用当前 Actor 生成一批数据
- 立即计算 log_probs 并 detach 为
old_log_probs(保证 ratio 初始为 1) - 在这批数据上训练 K 个 epoch,期间
old_log_probs不变 - 回到步骤 1,重新采样
而部分轻量级实现(如 MiniMind)采用了滚动更新(Rolling Update) 方式:维护一个 old_actor_model,每隔若干步同步一次 Actor 的参数。这种做法的 ratio 初始值可能不严格等于 1,但 clip 机制能兜底处理偏差,且实现更简单。
采样效率的关键数字。 在实际训练中,一个 7B 模型的 PPO 迭代中,采样(生成回答)通常占据 60-70% 的时间,训练只占 30-40%。因此工业级框架(如 DeepSpeed-Chat、veRL)会将采样和训练分配到不同的 GPU 组上并行执行,以提高整体吞吐。
16.2.10 小结
PPO 通过一个看似简单的裁剪操作,优雅地解决了策略优化中"步子太大容易扯着"的核心问题。其完整实现涉及四个模型的协同管理、复合奖励信号的组装、GAE 优势估计、以及多轮策略更新与早停机制。尽管工程复杂度较高(四个模型同时驻留 GPU、采样与训练交替进行),PPO 仍然是当前 RLHF 流程中最经典、最广泛验证的算法。理解 PPO 的每一个组件,是掌握后续 GRPO(去掉 Critic)和 DPO(去掉 RM + RL)等简化方案的前提——只有知道"什么都要"时每个部件的作用,才能判断"去掉哪个"是安全的。