26.5 策略优化改进
上一节我们从零实现了完整的 GRPO 训练管线,并在数学推理任务上观察到了模型能力的提升。然而,"能跑起来"只是起点——基础版 GRPO 在训练稳定性、收敛效率和输出质量方面仍有大量改进空间。本节围绕三个核心改进方向展开:裁剪策略比率(Clipped Policy Ratio) 稳定训练更新、KL 散度惩罚(KL Divergence Penalty) 控制策略偏移、格式奖励(Format Reward) 引导结构化输出。最后,我们还将系统梳理社区涌现的一系列高级技巧,为读者构建一幅完整的 GRPO 改进全景图。
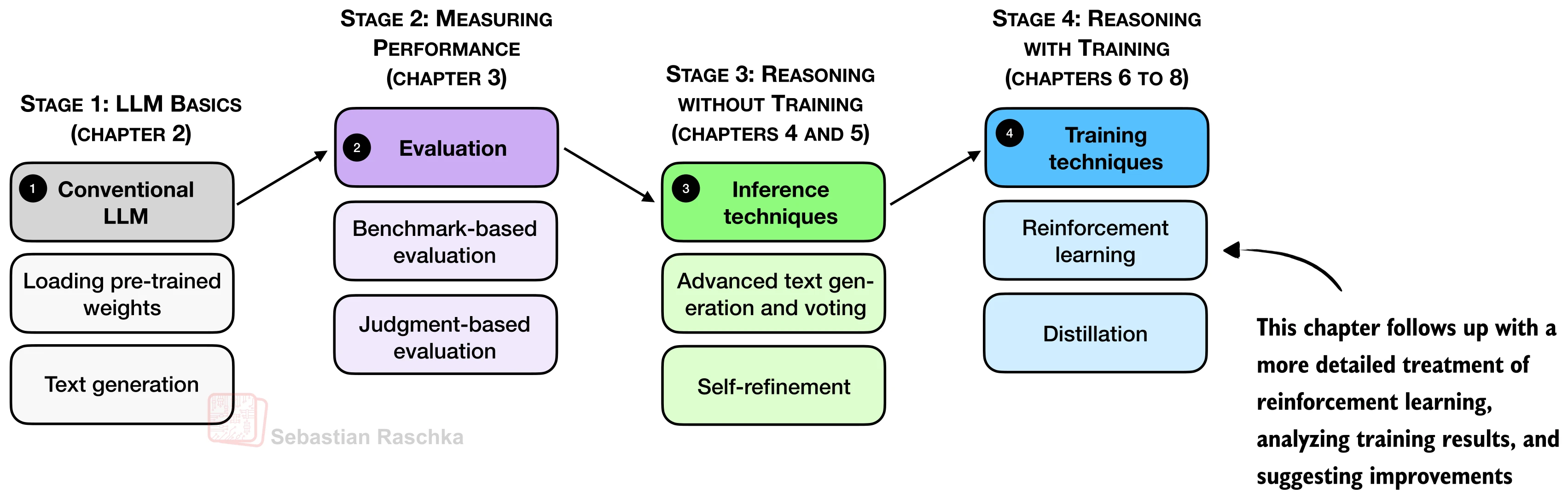
26.5.1 训练诊断:优势统计量与熵
在实施具体改进之前,我们需要先建立一套更精细的训练诊断工具。上一节我们只追踪了 loss、平均奖励和响应长度等基本指标,而要真正理解训练动态,还需要关注两个关键信号:优势统计量(Advantage Statistics) 和策略熵(Entropy)。
优势的均值与标准差
回顾 GRPO 算法:对同一道题生成多个 rollout,计算各自的奖励,然后通过组内归一化得到优势值。优势的两个汇总统计量能告诉我们训练信号的质量。
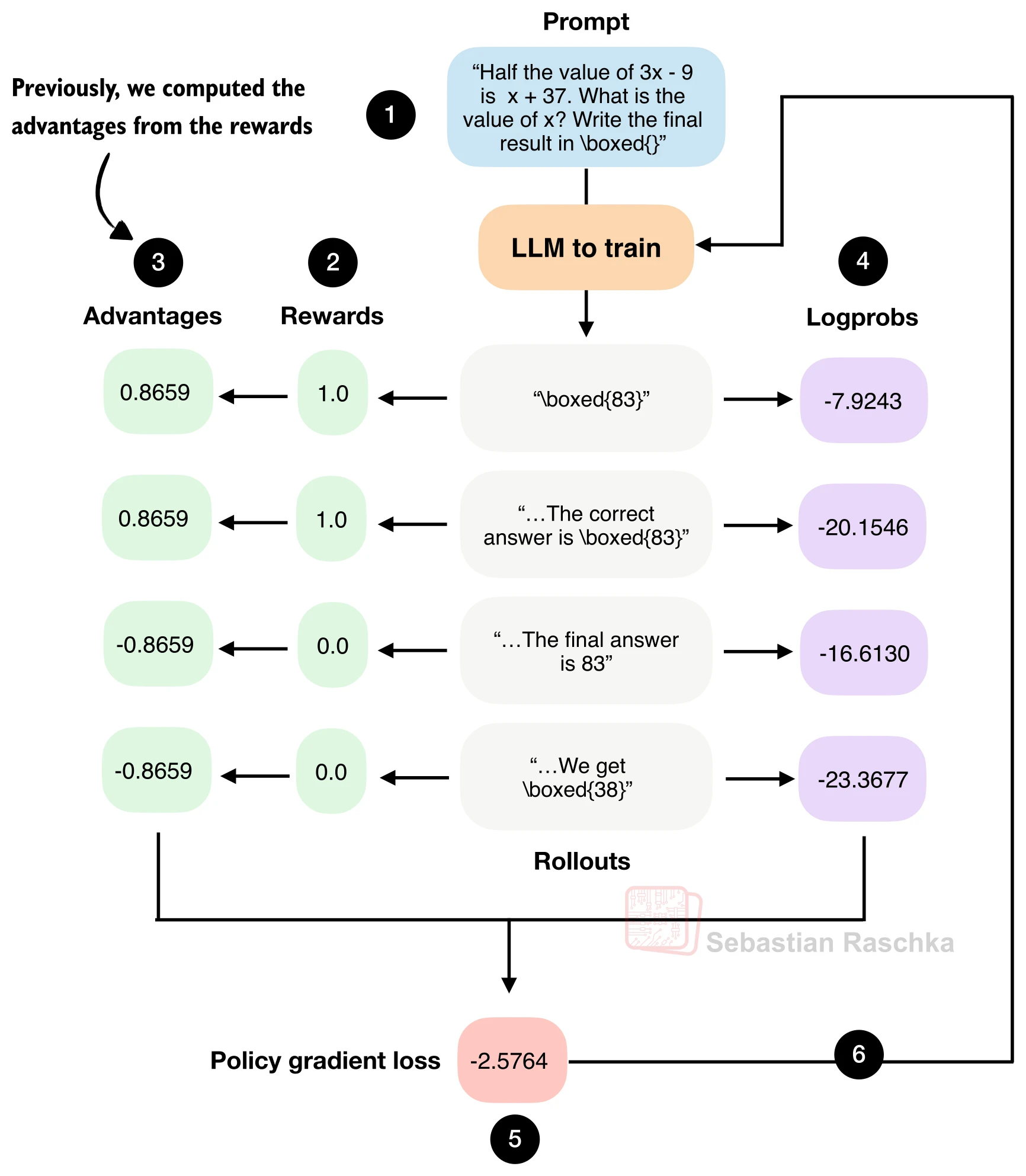
import torch
rewards = torch.tensor([0.0, 0.0, 1.0, 0.0])
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)
print(f"优势均值: {advantages.mean():.4f}") # ≈ 0.0(归一化的数学必然)
print(f"优势标准差: {advantages.std():.4f}") # ≈ 1.0(信号尺度正常)- 均值恒为 0:GRPO 的组内归一化(减均值除标准差)保证了优势均值始终为零。如果观察到非零偏移,大概率是代码 bug。
- 标准差是关键信号:
说明梯度信号尺度合理,训练稳定; 说明所有 rollout 获得几乎相同的奖励(要么全对要么全错),梯度信号消失; 则意味着更新幅度过大,可能导致训练不稳定。
一个特殊但值得关注的情况是
策略熵
熵(Entropy)衡量 LLM 在生成下一个 token 时的不确定性。具体计算方式如下:对模型输出的 logits 做 softmax 得到概率分布
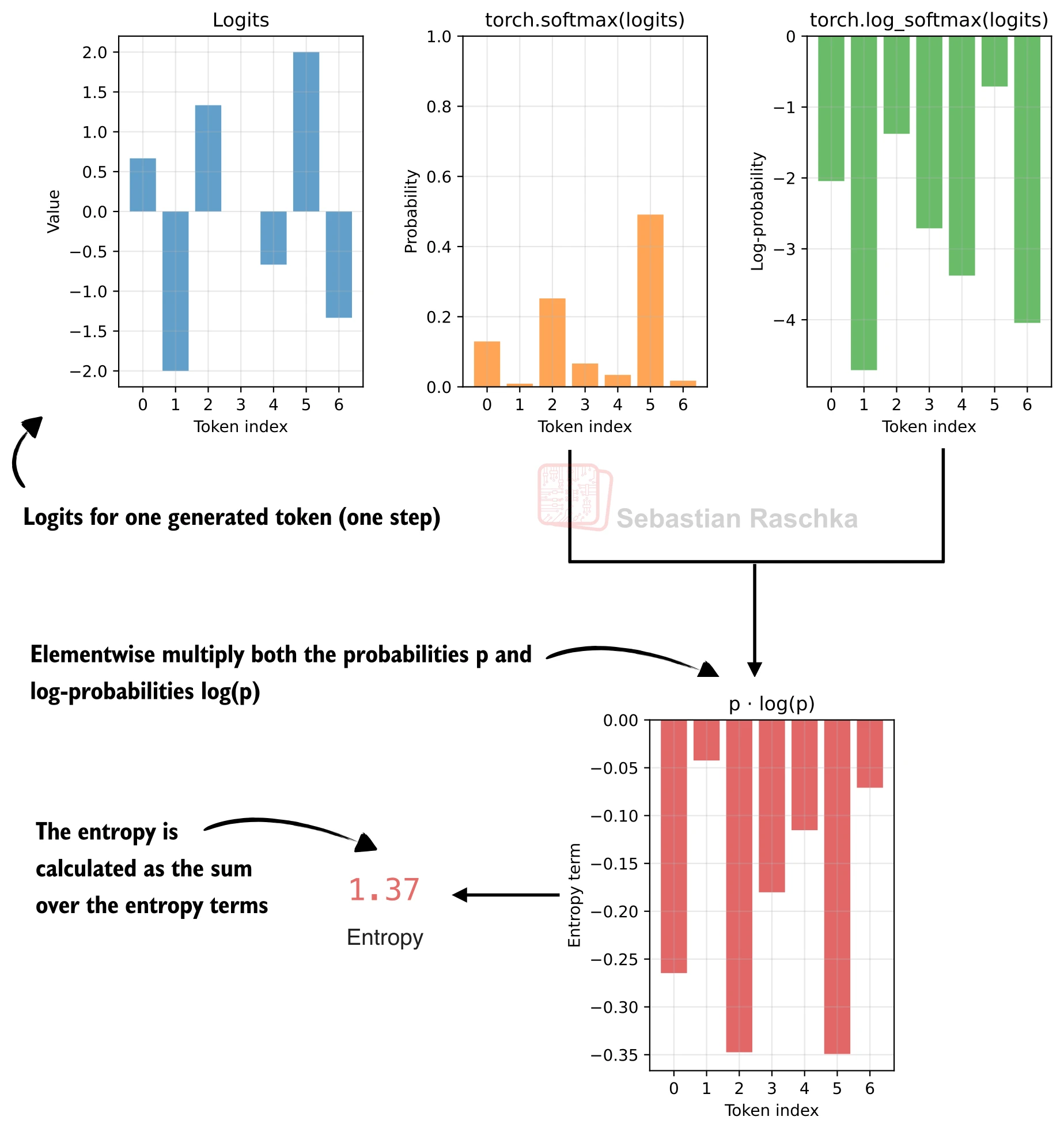
def sequence_logprob_and_entropy(model, token_ids, prompt_len):
"""计算序列对数概率和平均熵"""
logits = model(token_ids.unsqueeze(0)).squeeze(0).float()
logprobs = torch.log_softmax(logits, dim=-1)
targets = token_ids[1:]
selected = logprobs[:-1].gather(1, targets.unsqueeze(-1)).squeeze(-1)
# 生成部分的序列对数概率
answer_logprobs = selected[prompt_len - 1:]
logp = torch.sum(answer_logprobs)
# 生成部分的平均熵
all_logprobs = logprobs[:-1][prompt_len - 1:]
if all_logprobs.numel() == 0:
entropy = logp.new_tensor(0.0)
else:
probs = torch.exp(all_logprobs)
step_entropy = -torch.sum(probs * all_logprobs, dim=-1)
entropy = torch.mean(step_entropy)
return logp, entropy如何解读熵值?作为经验法则:
| 熵范围 | 含义 |
|---|---|
| 极低(接近 0) | 模型高度确定,几乎确定性地输出某个 token——可能出现模式坍缩 |
| 适中(1~2) | 概率质量分布在少数几个 token 上,训练通常稳定 |
| 极高(接近 $\log | \mathcal |
在实际训练中,若观察到熵持续下降至接近零,往往意味着模型正在过拟合到某种固定的输出模式,需要引起警惕。
26.5.2 裁剪策略比率
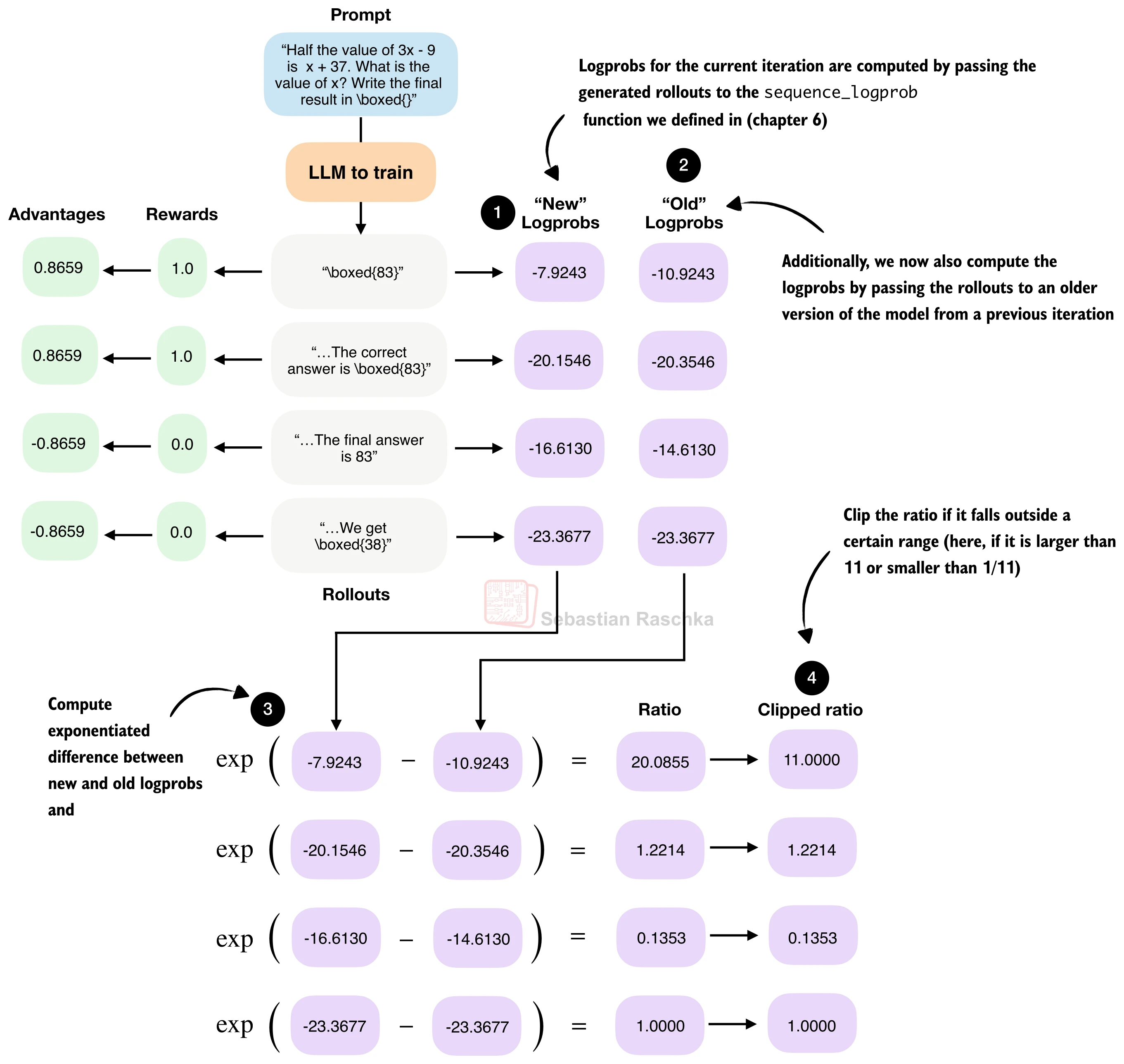
基础版 GRPO 直接用优势值乘以对数概率来计算策略梯度损失。这种做法有一个风险:单次更新可能过于激进,导致当前策略与生成 rollout 时的旧策略偏差过大,从而破坏训练稳定性。裁剪策略比率(Clipped Policy Ratio) 借鉴了 PPO(Proximal Policy Optimization)的思想,通过限制新旧策略之间的偏离幅度来解决这一问题。
策略比率的定义
策略比率衡量的是:对于同一组 token,当前策略分配的概率与旧策略分配的概率之间的比值。由于概率值通常很小,我们在对数空间中计算差值后取指数:
当新旧策略完全一致时,
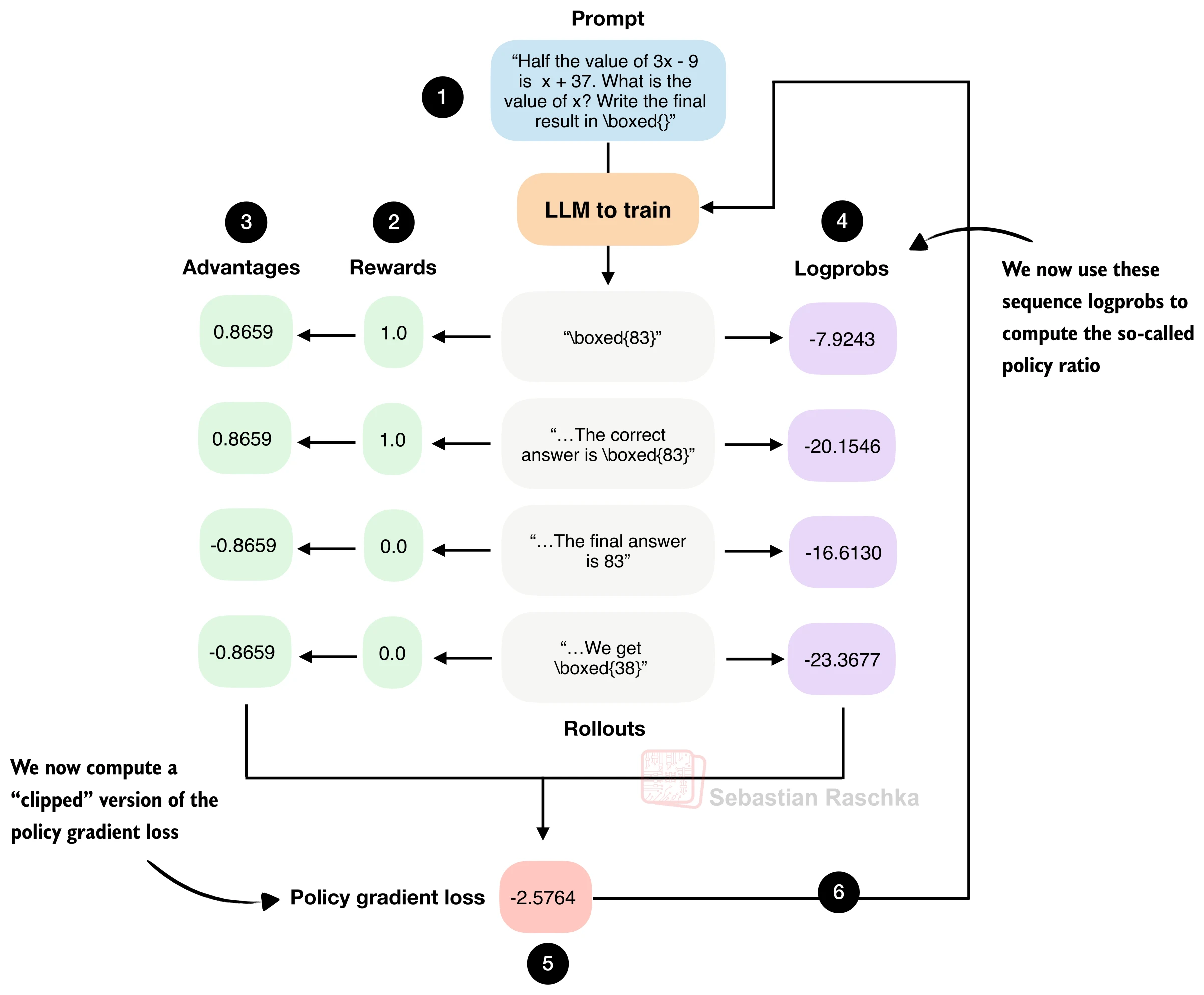
裁剪目标函数
PPO 风格的裁剪将策略比率限制在
直觉上:当优势为正(好的 rollout)且策略比率已经很大时,裁剪阻止模型继续"放大"这个方向的更新;当优势为负(差的 rollout)且策略比率已经很小时,裁剪阻止模型过度"远离"这个方向。
def compute_clipped_grpo_loss(new_logps, old_logps, advantages, clip_eps=10.0):
"""带裁剪的 GRPO 策略梯度损失"""
log_ratio = new_logps - old_logps
ratio = torch.exp(log_ratio)
clipped_ratio = torch.clamp(ratio, 1.0 - clip_eps, 1.0 + clip_eps)
unclipped = ratio * advantages
clipped = clipped_ratio * advantages
objective = torch.where(
advantages >= 0,
torch.minimum(unclipped, clipped),
torch.maximum(unclipped, clipped),
)
return -objective.mean()clip_eps 的选择:DeepSeek-R1 使用了
训练效果:加入裁剪后,训练曲线通常更加平滑,之前在 400 步左右出现的性能骤降现象得到有效缓解。
26.5.3 KL 散度惩罚
裁剪限制的是单次更新的幅度,而 KL 散度惩罚(KL Divergence Penalty) 关注的是全局偏移——当前策略
KL 惩罚的计算
对每个 rollout,在相同 token 序列上分别用当前策略和参考策略计算对数概率,两者之差的期望即为 KL 散度的近似:
其中 kl_coeff)。最终损失为策略梯度损失与 KL 损失之和:
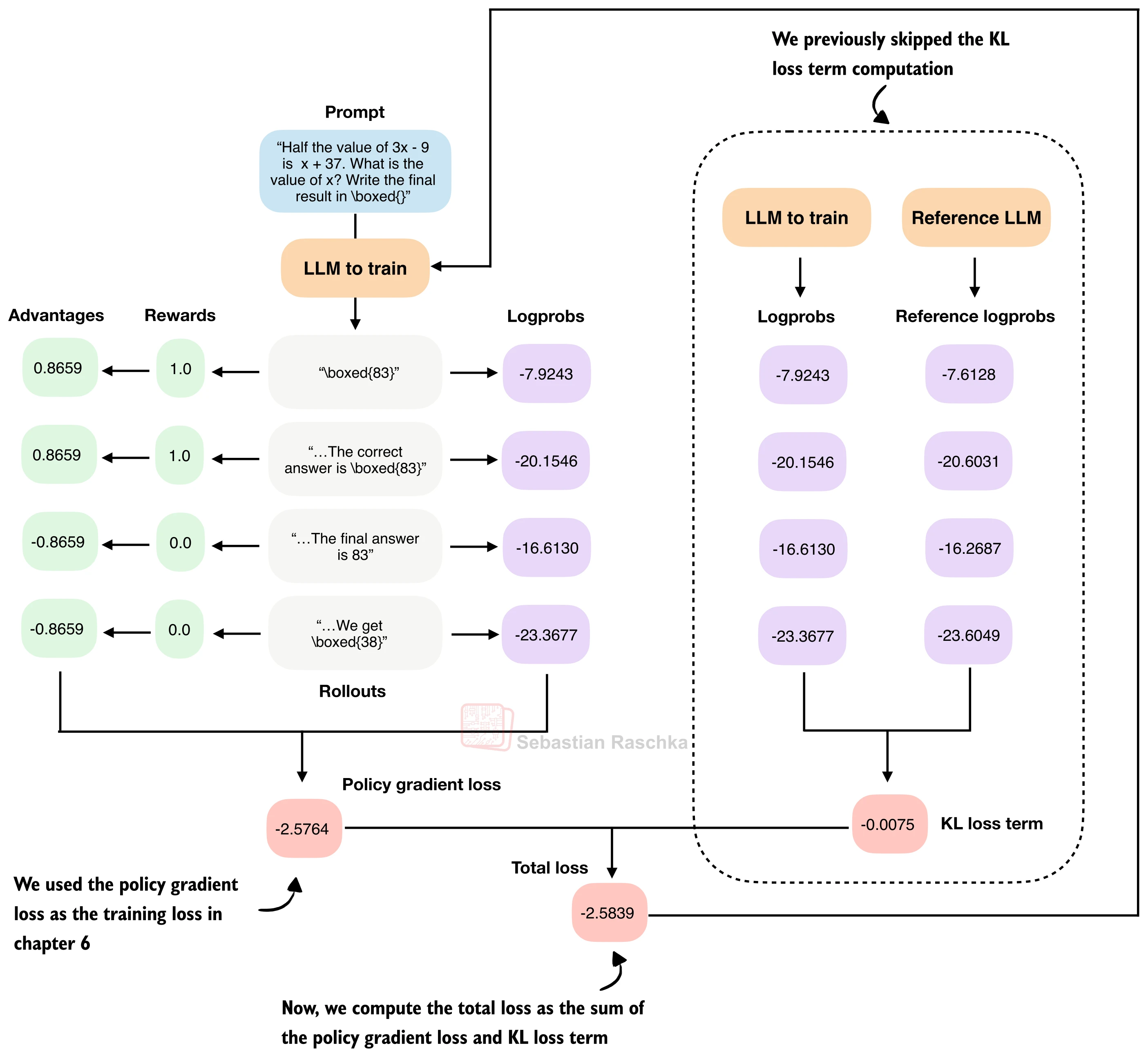
def compute_grpo_loss_with_kl(
model, old_model, ref_model, token_ids_list, prompt_lens,
advantages, clip_eps=10.0, kl_coeff=0.001
):
"""带 KL 惩罚的 GRPO 损失"""
new_logps, ref_logps_list = [], []
for token_ids, prompt_len in zip(token_ids_list, prompt_lens):
new_logp, _ = sequence_logprob_and_entropy(model, token_ids, prompt_len)
new_logps.append(new_logp)
with torch.no_grad():
ref_logp, _ = sequence_logprob_and_entropy(
ref_model, token_ids, prompt_len
)
ref_logps_list.append(ref_logp)
new_logps = torch.stack(new_logps)
ref_logps = torch.stack(ref_logps_list)
# 策略梯度损失(带裁剪)
old_logps = torch.stack([
sequence_logprob_and_entropy(old_model, t, p)[0]
for t, p in zip(token_ids_list, prompt_lens)
]).detach()
pg_loss = compute_clipped_grpo_loss(new_logps, old_logps, advantages, clip_eps)
# KL 惩罚
kl_loss = kl_coeff * torch.mean(new_logps - ref_logps)
return pg_loss + kl_loss, pg_loss, kl_loss实际注意事项
加入 KL 惩罚需要在内存中额外维护一份参考模型的副本,对 GPU 显存有显著影响。更关键的是,kl_coeff 的取值需要谨慎调节:
- 过大(如 0.02):KL 约束过强,模型几乎无法偏离参考策略,难以学到新能力。实验表明,在小规模模型上使用较大的 KL 系数可能导致训练在几十步后完全崩溃,模型输出退化为乱码。
- 过小(如 0.0001):KL 约束形同虚设,无法防止灾难性遗忘。
- 设为 0:完全去掉 KL 项。多项研究(Dr. GRPO (Liu et al., 2025)、OLMo 3、DeepSeek-V3.2)发现,在数学推理任务上去掉 KL 项反而效果更好,因为数学任务有明确的正确性奖励作为锚定,不太需要 KL 来防止漂移。
[选读] KL 惩罚的三种改进方案
当 KL 惩罚表现不佳时,可以从以下三个方向修复:
- 长度归一化:将序列级对数概率除以生成长度后再计算 KL,消除长序列天然获得更大 KL 值的偏差。
- 降低
kl_coeff:从 0.02 降到 0.001 甚至更低,但需要仔细实验。 - 重加权 KL(DeepSeek-V3.2 方案):用旧策略的重要性采样权重对 KL 进行加权,公式为
,使 KL 惩罚聚焦于策略变化最大的样本。
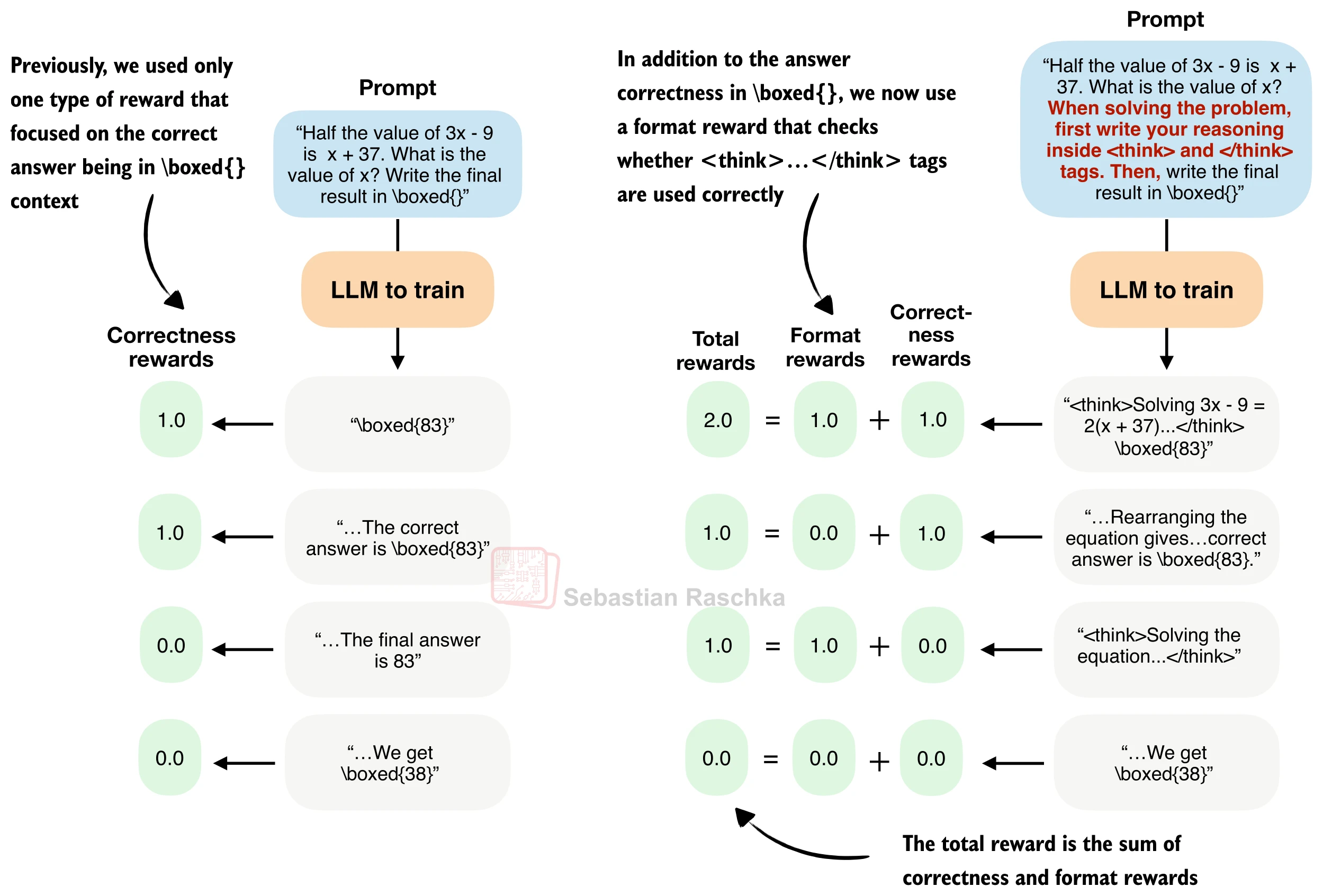
26.5.4 格式奖励
到目前为止,我们只使用了单一的正确性奖励(答案对得 1 分,错得 0 分)。然而,仅凭正确性奖励无法引导模型学会使用结构化的推理格式——比如 <think>...</think> 标签来分隔中间推理过程和最终答案。格式奖励(Format Reward) 正是为此而设计的辅助奖励信号。
格式奖励函数
格式奖励检查生成的 token 序列中是否包含正确排列的 <think> 和 </think> 标记。如果 <think> 出现在 </think> 之前,返回 1.0;否则返回 0.0:
THINK_TOKEN_ID = 151667 # <think> 的 token ID
END_THINK_TOKEN_ID = 151668 # </think> 的 token ID
def reward_format(token_ids, prompt_len):
"""检查生成的 token 中是否包含正确排列的 <think>...</think>"""
try:
gen = token_ids[prompt_len:].tolist()
return float(gen.index(THINK_TOKEN_ID) < gen.index(END_THINK_TOKEN_ID))
except ValueError:
return 0.0组合奖励
将格式奖励与正确性奖励加权组合,得到最终奖励信号:
其中 format_reward_weight),默认为 1.0。一个可选策略是条件格式奖励——仅在答案正确时才给予格式分:
def combined_reward(text, ground_truth, token_ids, prompt_len,
format_weight=1.0, conditional=False):
"""组合正确性奖励和格式奖励"""
correctness = reward_rlvr(text, ground_truth)
fmt = reward_format(token_ids, prompt_len)
if conditional:
fmt *= correctness # 仅正确答案获得格式奖励
return correctness + format_weight * fmt实践经验
使用格式奖励训练时需要注意以下要点:
- 基座模型 vs 推理模型:基座模型从未见过
<think>标记,直接加格式奖励效果很差。应使用已经通过指令微调熟悉这些标记的推理变体模型(如 Qwen3 的 reasoning 版本)。 - 权重平衡:格式奖励权重过高(
)可能导致模型过度追求格式而忽视正确性,表现为模型很快学会输出 <think>...</think>标签但推理质量下降。将降至 0.1 或使用条件格式奖励可以缓解此问题。 - 监控分离:训练时应分别追踪正确性奖励和格式奖励的变化趋势,以便及时发现奖励信号的失衡。
26.5.5 社区改进技巧全景
DeepSeek-R1 于 2025 年 1 月引爆 GRPO 热潮后,短短数月内社区提出了大量改进方案。这些改进可以按来源分为三个流派:DAPO 流派(主打探索效率)、Dr. GRPO 流派(主打理论简洁)、和 DeepSeek-V3.2 流派(主打工程精细化)。下面逐一介绍关键技巧。
DAPO 流派(Yu et al., 2025)
DAPO(Decoupled Alignment via Policy Optimization)提出了一揽子改进,其核心洞察是:标准 GRPO 过于保守,限制了模型的探索能力。
零梯度信号过滤:当一组 rollout 的奖励完全相同时(全对或全错),优势全为零,此时的梯度更新毫无意义。DAPO 在检测到这种情况时直接跳过更新步,节省计算。
主动采样(Active Sampling):与零梯度过滤配合——当某道题的 rollout 全部零梯度时,自动换一道题重新采样,确保每个训练步都有有效的学习信号。
Token 级损失:标准 GRPO 将整个序列的对数概率求和后作为一个标量参与损失计算。DAPO 改为在每个 token 位置独立计算策略比率和裁剪,使梯度信号更精细:
def token_level_clipped_loss(new_token_logps, old_token_logps, advantage,
clip_low=0.2, clip_high=10.0):
"""Token 级裁剪损失(DAPO 风格)"""
log_ratio = new_token_logps - old_token_logps
ratio = torch.exp(log_ratio)
# 截断重要性采样(防止极端比率)
ratio = torch.clamp(ratio, max=1.0 + clip_high)
clipped_ratio = torch.clamp(ratio, 1.0 - clip_low, 1.0 + clip_high)
unclipped = ratio * advantage
clipped = clipped_ratio * advantage
token_obj = torch.where(
advantage >= 0,
torch.minimum(unclipped, clipped),
torch.maximum(unclipped, clipped),
)
return -token_obj.mean()去掉 KL 惩罚:DAPO 发现在数学推理任务上,KL 项反而阻碍了学习,直接设
kl_coeff = 0。非对称裁剪(Clip Higher):下界
严格限制减小概率的幅度,上界 放得很宽(如 10.0),鼓励模型大胆增加好序列的概率。
Dr. GRPO 流派(Liu et al., 2025)
Dr. GRPO(Decoupled Regularization for GRPO)的核心改进更为精炼:
- 去掉标准差归一化:标准 GRPO 将优势除以标准差进行归一化,Dr. GRPO 发现仅减均值而不除标准差反而更稳定,因为标准差归一化在奖励方差极小时会放大噪声:
# 标准 GRPO
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)
# Dr. GRPO
advantages = rewards - rewards.mean()DeepSeek-V3.2 流派
DeepSeek-V3.2 针对大规模分布式训练场景做了一系列精细化调整:
分领域 KL 系数:对数学领域设 KL 系数为 0(数学有明确的对错信号,不需要 KL 锚定),对代码和通用领域保留 KL 惩罚。
重加权 KL:如前所述,用重要性采样权重对 KL 进行加权,使惩罚聚焦于策略变化最大的样本。
离策略序列掩码(Off-Policy Sequence Masking):当某个负优势样本的 KL 散度超过阈值
时,将其优势置零,相当于忽略这个"过时"的样本:
# 计算每个序列的平均 KL
seq_kl = (old_logps - new_logps) / gen_lens
# 掩码:负优势 + 高 KL = 离策略太远,忽略
off_policy_mask = torch.ones_like(advantages)
off_policy_mask[(advantages < 0) & (seq_kl > delta)] = 0
advantages = advantages * off_policy_mask- 保留采样掩码(Keep Sampling Mask):在 top-p/top-k 采样时记录每步的有效 token 集合,训练时用该掩码遮盖未被采样器选中的 token 的 logits,确保训练和采样看到的概率空间一致。
更多方案
除上述三个主要流派外,社区还提出了其他有价值的改进:
- GDPO(Liu et al., 2026):当使用多个奖励信号(如正确性 + 格式)时,在聚合之前对每个奖励维度分别做组内归一化,避免某个奖励的尺度压制另一个。
- GSPO(Zheng et al., 2025):在序列级引入重要性采样和裁剪,介于标准 GRPO(无 IS)和 DAPO(token 级 IS)之间。
- CISPO(MiniMax et al., 2025):直接裁剪重要性采样权重而非 token 级更新量,理论上更接近原始 PPO 的设计意图。
下表总结了各改进技巧及其来源:
| 编号 | 改进技巧 | 来源 |
|---|---|---|
| 1 | 零梯度信号过滤 | DAPO |
| 2 | 主动采样 | DAPO |
| 3 | Token 级损失 | DAPO |
| 4 | 去掉 KL 惩罚 | DAPO, Dr. GRPO |
| 5 | 非对称裁剪 | DAPO |
| 6 | 截断重要性采样 | Yao et al., 2025 |
| 7 | 去掉标准差归一化 | Dr. GRPO |
| 8 | 分领域 KL 系数 | DeepSeek-V3.2 |
| 9 | 重加权 KL | DeepSeek-V3.2 |
| 10 | 离策略序列掩码 | DeepSeek-V3.2 |
| 11 | 保留采样掩码 | DeepSeek-V3.2 |
| 12 | 保留标准 GRPO 优势归一化 | DeepSeek-V3.2 |
| 13 | 多奖励分组归一化 | GDPO |
| 14 | 序列级重要性采样 | GSPO |
| 15 | 裁剪重要性采样权重 | CISPO |
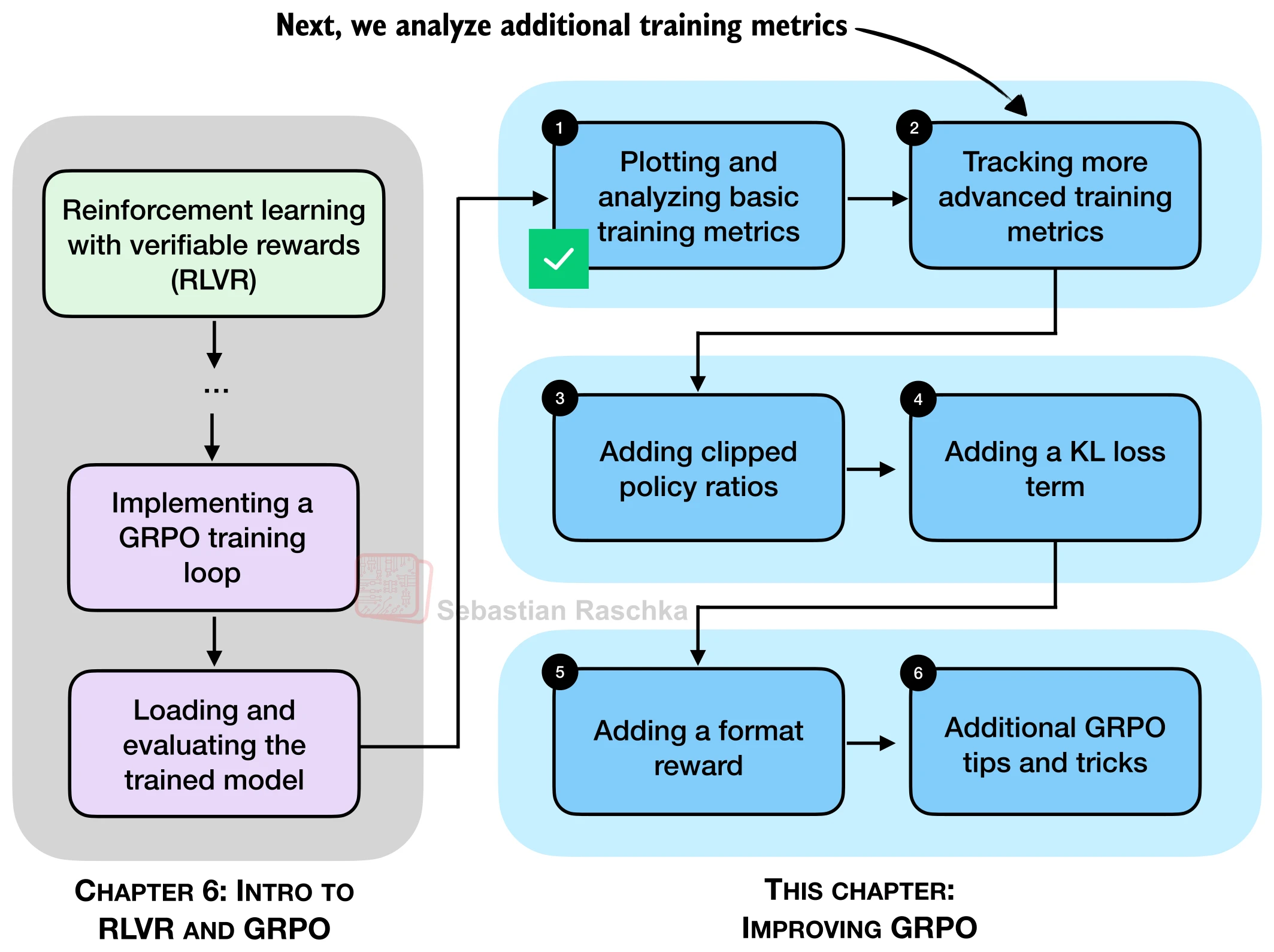
26.5.6 改进方案的组合与选择
面对如此多的改进技巧,实践中该如何选择?根据社区经验和源码分析,以下是两种经过验证的组合配方:
配方一:OLMo 3 风格(适合快速实验)
整合 DAPO 和 Dr. GRPO 的核心改进:零梯度过滤 + 主动采样 + Token 级损失 + 去掉 KL + 非对称裁剪 + 截断重要性采样 + 去掉标准差归一化。该配方实现简单,不需要额外维护参考模型,内存开销最小:
# OLMo 3 风格的核心超参数
config = {
"clip_eps_low": 0.2, # 非对称裁剪下界
"clip_eps_high": 10.0, # 非对称裁剪上界
"kl_coeff": 0.0, # 去掉 KL
"active_sampling": True, # 主动采样
"token_level_loss": True, # Token 级损失
"normalize_std": False, # 去掉标准差归一化
}配方二:DeepSeek-V3.2 风格(适合大规模训练)
保留 KL 惩罚但做精细化处理:分领域 KL 系数 + 重加权 KL + 离策略序列掩码 + 保留采样掩码 + 标准优势归一化。该配方适用于多领域混合训练,且对超参数不那么敏感:
# DeepSeek-V3.2 风格的核心超参数
config = {
"clip_eps": 10.0,
"kl_coeff_math": 0.0, # 数学领域关闭 KL
"kl_coeff_code": 0.02, # 代码领域保留 KL
"off_policy_delta": 0.1, # 离策略掩码阈值
"reweighted_kl": True, # 重加权 KL
"keep_sampling_mask": True, # 保留采样掩码
}无论选择哪种配方,建议始终保留裁剪策略比率(几乎零成本但显著提升稳定性)和完整的训练指标追踪(优势统计量 + 熵 + 策略比率),以便及时发现训练异常。
本节从诊断工具出发,逐步引入裁剪、KL 惩罚、格式奖励三大改进,并系统梳理了社区涌现的 15 项高级技巧。这些改进并非孤立存在——它们共同构成了一个工具箱,读者可以根据自己的任务特点和资源条件灵活组合。核心原则是:先确保训练稳定(裁剪 + 诊断),再根据需要添加约束(KL)或信号(格式奖励),最后按需引入社区最新方案提升效率。