26.2 评估框架搭建
训练推理模型的前提是能够自动判断模型生成的答案是否正确。如果没有可靠的评估器,后续的强化学习训练将无从获取奖励信号,推理时间缩放实验也无法量化收益。本节以数学推理评估为核心场景,从零搭建一个完整的验证流水线:从模型原始输出中提取答案、将多样化的 LaTeX 表达式规范化为统一格式、最终借助符号计算引擎判定数学等价性。
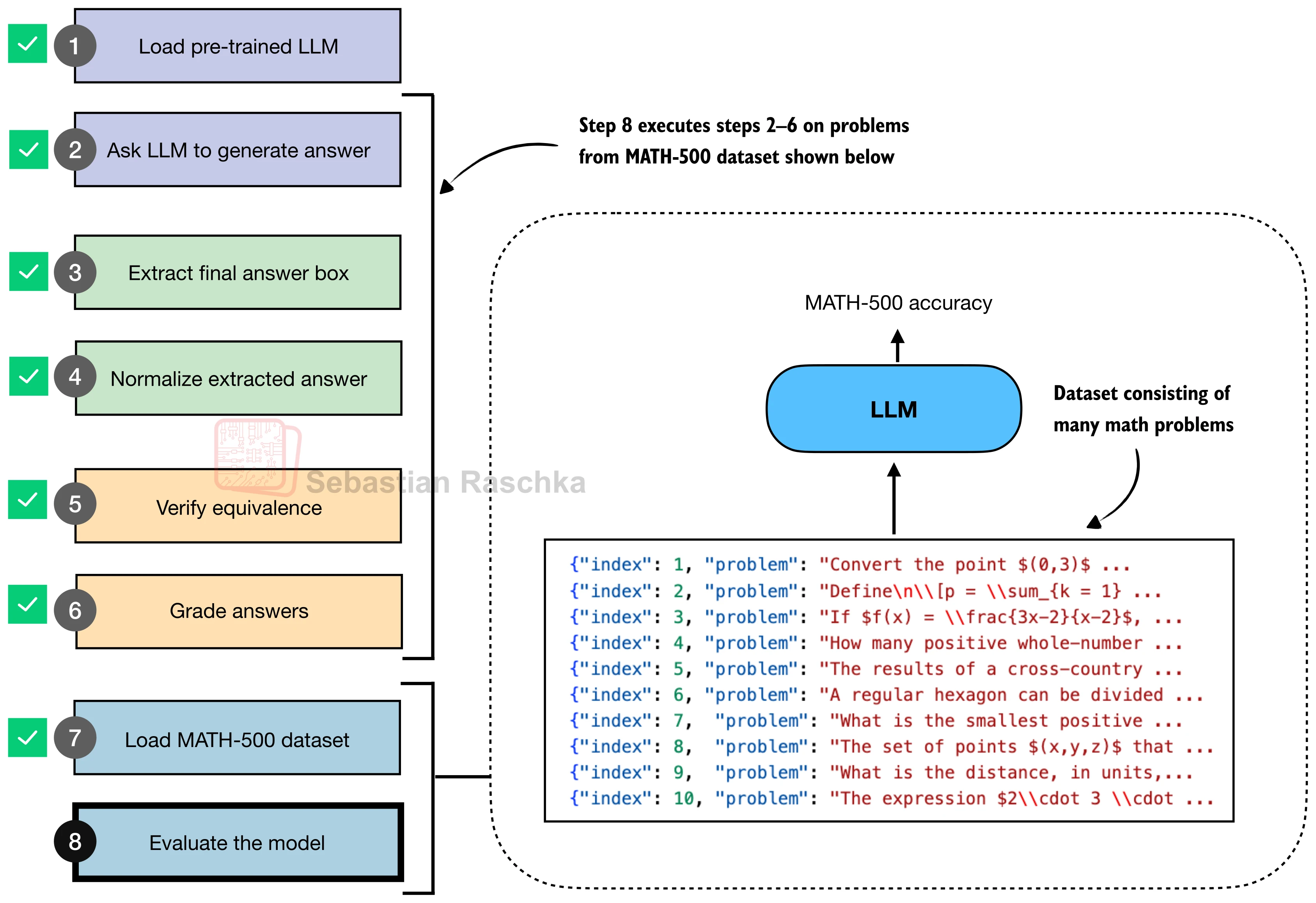
整条流水线可分为六个步骤,如下图所示:
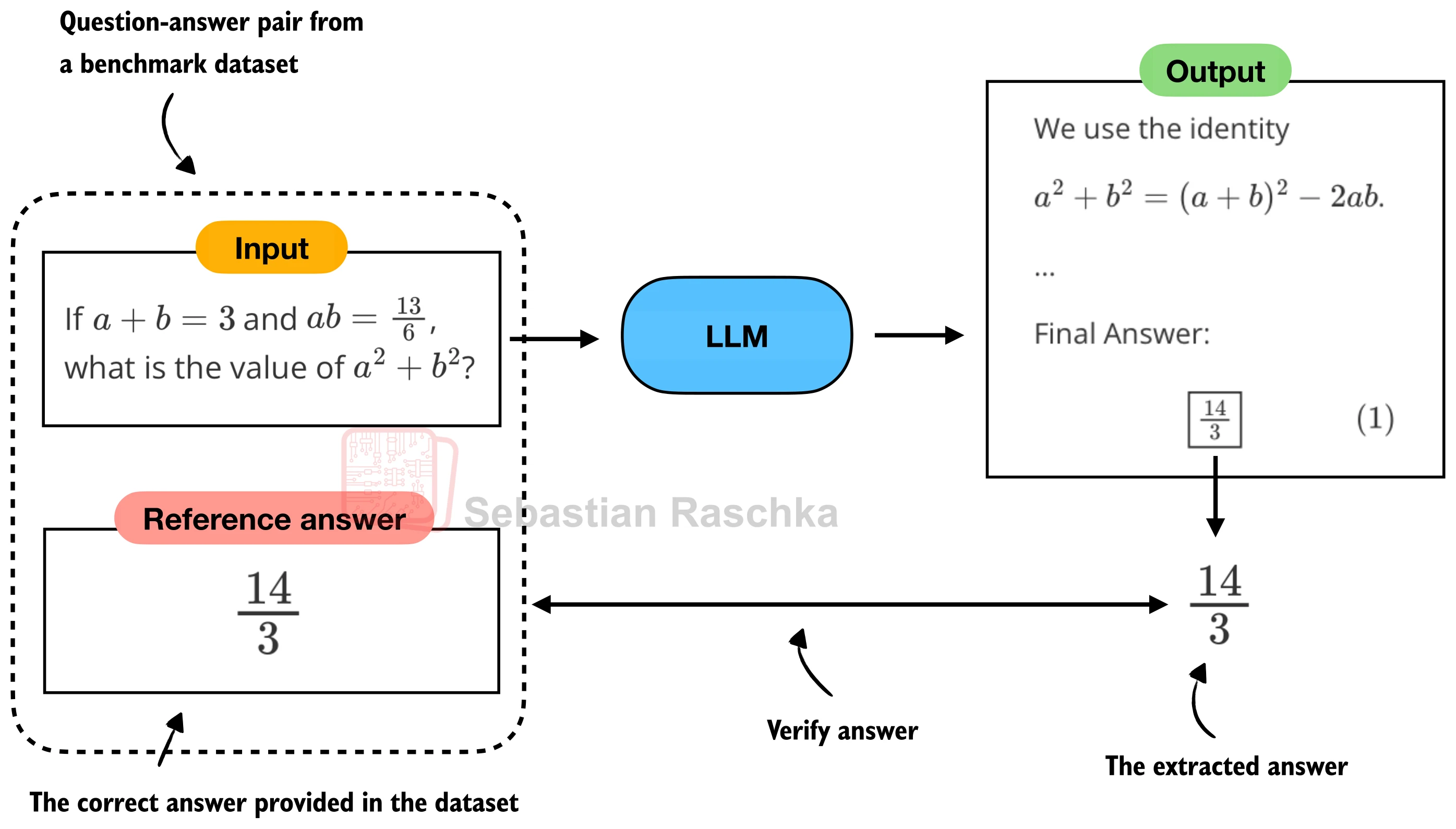
模型生成文本后,依次经过答案提取(从 \boxed{} 中取出内容)、文本规范化(去除 LaTeX 修饰、统一格式)、符号解析与等价判定(用 SymPy 判断数学表达式是否相等),最终输出布尔值表示答案是否正确。下面逐一实现每个环节。
一、提取答案框
数学推理模型通常被要求将最终答案写在 \boxed{} 中。我们的第一步是从模型生成的完整文本中提取这个"答案框"的内容。
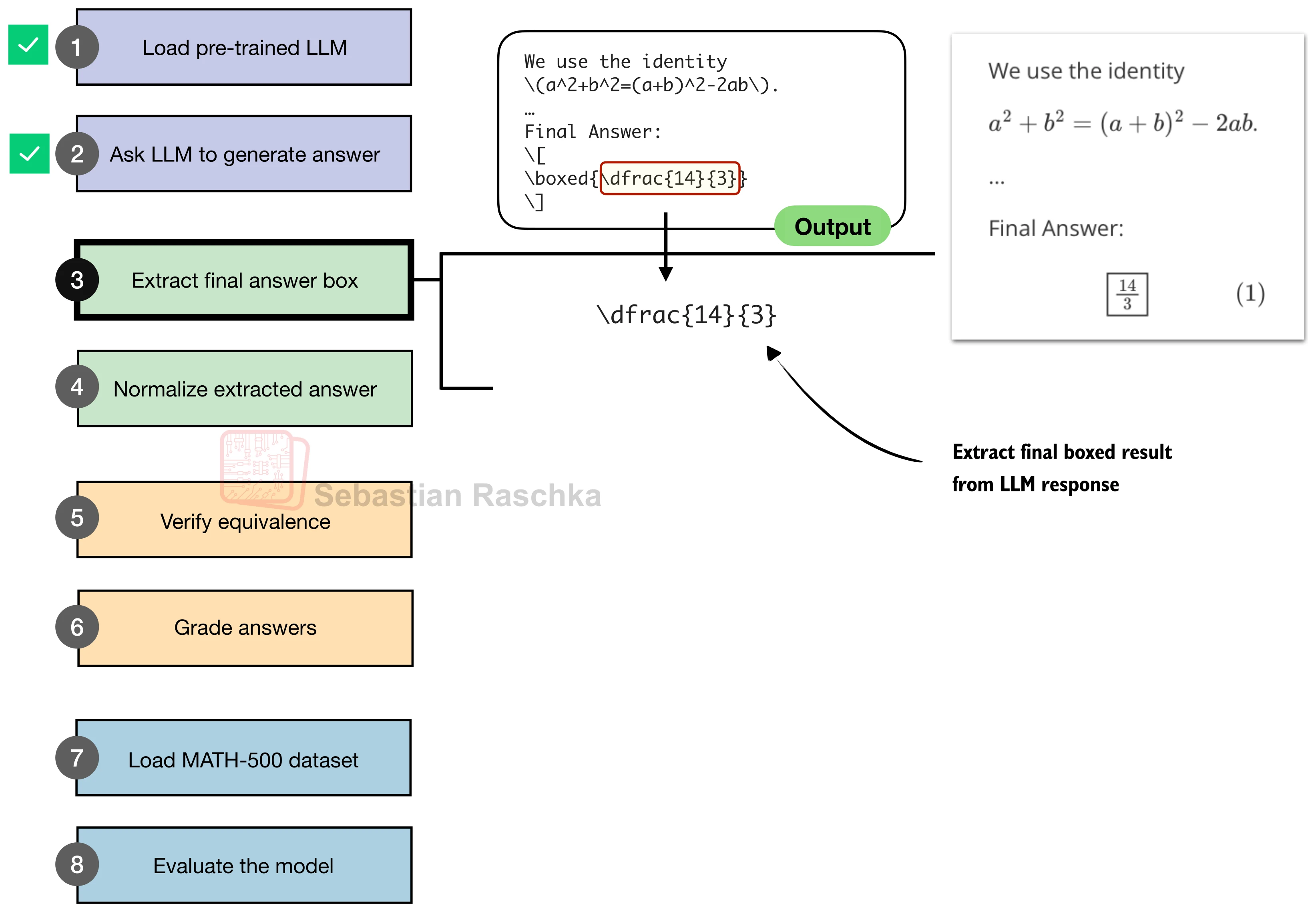
核心难点在于 \boxed{} 内部可能包含嵌套花括号(如 \boxed{\frac{14}{3}}),因此不能简单地用正则表达式匹配最近的 },而需要追踪花括号的嵌套深度:
def get_last_boxed(text):
"""从文本中提取最后一个 \\boxed{...} 的内容,支持嵌套花括号"""
# 找到最后一个 \boxed 的位置(取最后一个是因为模型可能多次修正答案)
boxed_start_idx = text.rfind(r"\boxed")
if boxed_start_idx == -1:
return None
current_idx = boxed_start_idx + len(r"\boxed")
# 跳过空白字符
while current_idx < len(text) and text[current_idx].isspace():
current_idx += 1
if current_idx >= len(text) or text[current_idx] != "{":
return None
# 追踪花括号嵌套深度
current_idx += 1
brace_depth = 1
content_start_idx = current_idx
while current_idx < len(text) and brace_depth > 0:
char = text[current_idx]
if char == "{":
brace_depth += 1
elif char == "}":
brace_depth -= 1
current_idx += 1
if brace_depth != 0:
return None # 花括号不平衡
return text[content_start_idx : current_idx - 1]当模型输出中没有 \boxed{} 时(例如基座模型直接给出数字),需要一个回退策略。extract_final_candidate 函数实现了三级回退:优先取 \boxed{},其次取文本中最后一个数字,最后返回全文:
import re
RE_NUMBER = re.compile(
r"-?(?:\d+/\d+|\d+(?:\.\d+)?(?:[eE][+-]?\d+)?)"
)
def extract_final_candidate(text, fallback="number_then_full"):
"""提取最终答案候选:boxed > 最后一个数字 > 全文"""
result = ""
if text:
boxed = get_last_boxed(text.strip())
if boxed:
result = boxed.strip().strip("$ ")
elif fallback in ("number_then_full", "number_only"):
m = RE_NUMBER.findall(text)
if m:
result = m[-1] # 取最后一个数字
elif fallback == "number_then_full":
result = text
return resultfallback 参数提供了灵活的控制:"number_then_full" 适合基座模型(可能不生成 boxed 格式);"number_only" 适合严格评估;"none" 则只接受 boxed 格式。
二、答案规范化
提取出的原始答案可能包含各种 LaTeX 修饰符。例如 \dfrac{14}{3}、\left(\frac{3}{4}\right)、90^\circ 本质上分别等价于 14/3、3/4、90。规范化的目标是将这些多样化的表示统一为可供符号计算引擎解析的纯文本格式。
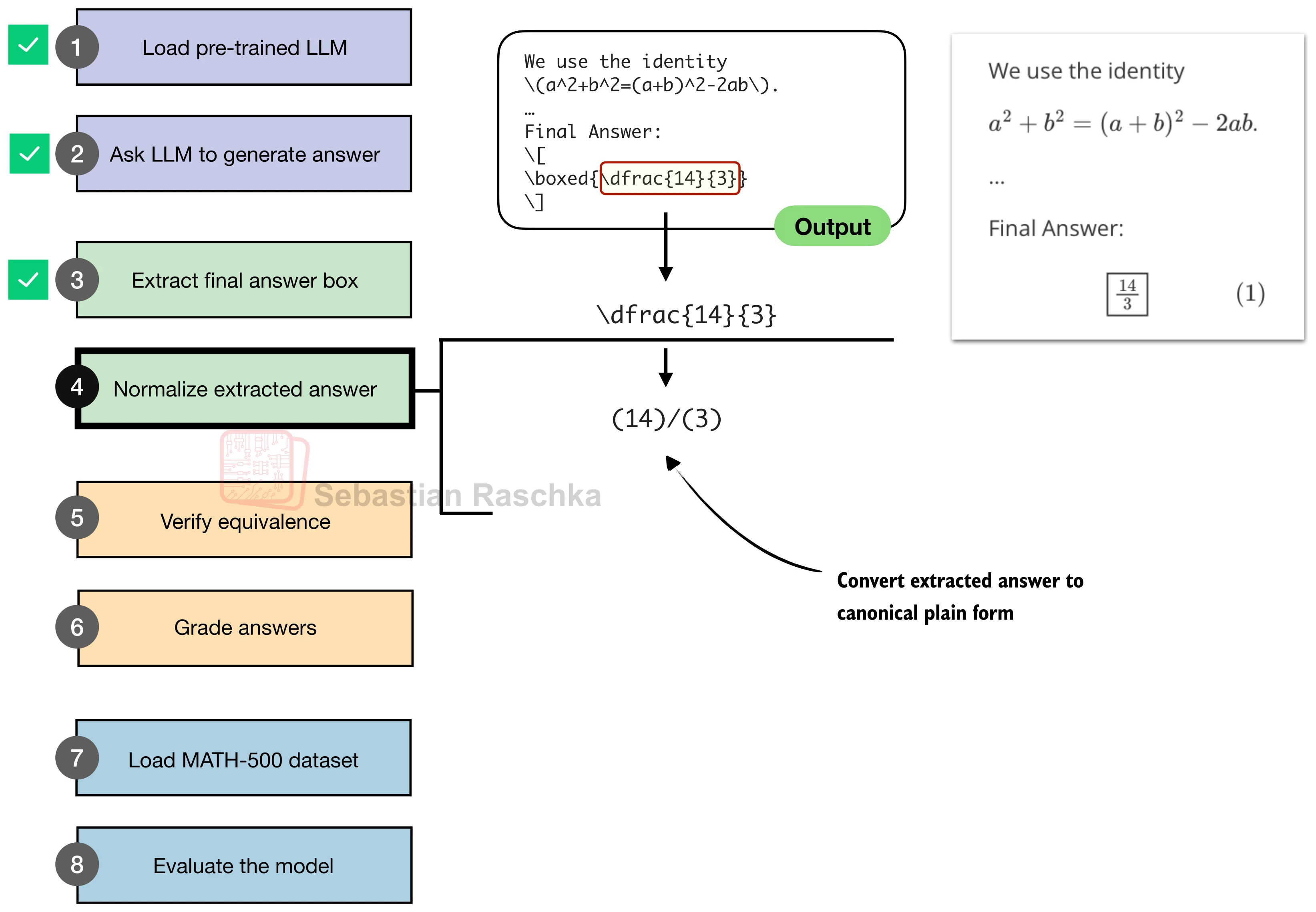
规范化函数按以下顺序依次处理:
# LaTeX 格式替换表
LATEX_FIXES = [
(r"\\left\s*", ""), # 去除 \left
(r"\\right\s*", ""), # 去除 \right
(r"\\,|\\!|\\;|\\:", ""), # 去除 LaTeX 间距命令
(r"\\cdot", "*"), # \cdot → *
(r"\u00B7|\u00D7", "*"), # Unicode 乘号 → *
(r"\\\^\\circ", ""), # 度数符号
(r"\\dfrac", r"\\frac"), # 统一分数命令
(r"\\tfrac", r"\\frac"),
(r"°", ""),
]
RE_SPECIAL = re.compile(r"<\|[^>]+?\|>") # 去除聊天特殊 token
def normalize_text(text):
"""将 LaTeX 数学表达式规范化为可解析的纯文本"""
if not text:
return ""
text = RE_SPECIAL.sub("", text).strip()
# Unicode 上标转为指数形式(如 2² → 2**2)
SUPERSCRIPT_MAP = {
"⁰": "0", "¹": "1", "²": "2", "³": "3", "⁴": "4",
"⁵": "5", "⁶": "6", "⁷": "7", "⁸": "8", "⁹": "9",
"⁺": "+", "⁻": "-",
}
# 去除多选题前缀(如 "c. 3" → "3")
match = re.match(r"^[A-Za-z]\s*[.:]\s*(.+)$", text)
if match:
text = match.group(1)
# 去除角度标记
text = re.sub(r"\^\s*\{\s*\\circ\s*\}", "", text)
text = re.sub(r"\^\s*\\circ", "", text)
text = text.replace("°", "")
# 解开 \text{...} 包装
match = re.match(r"^\\text\{(?P<x>.+?)\}$", text)
if match:
text = match.group("x")
# 去除行内/行间数学分隔符
text = re.sub(r"\\\(|\\\)|\\\[|\\\]", "", text)
# 应用 LaTeX 格式替换
for pat, rep in LATEX_FIXES:
text = re.sub(pat, rep, text)
# 处理 Unicode 上标
def convert_superscripts(s, base=None):
converted = "".join(
SUPERSCRIPT_MAP.get(ch, ch) for ch in s
)
return f"{base}**{converted}" if base else converted
text = re.sub(
r"([0-9A-Za-z\)\]\}])([⁰¹²³⁴⁵⁶⁷⁸⁹⁺⁻]+)",
lambda m: convert_superscripts(m.group(2), base=m.group(1)),
text,
)
# 处理百分号、根号、分数
text = text.replace("\\%", "%").replace("$", "").replace("%", "")
text = re.sub(
r"\\sqrt\s*\{([^}]*)\}",
lambda m: f"sqrt({m.group(1)})", text,
)
text = re.sub(
r"\\frac\s*\{([^{}]+)\}\s*\{([^{}]+)\}",
lambda m: f"({m.group(1)})/({m.group(2)})", text,
)
# 指数符号统一、千分位逗号去除
text = text.replace("^", "**")
text = re.sub(r"(?<=\d),(?=\d\d\d(\D|$))", "", text)
return text.replace("{", "").replace("}", "").strip().lower()来看几个规范化效果:
| 输入 | 规范化结果 |
|---|---|
\dfrac{14}{3} | (14)/(3) |
\left(\frac{3}{4}\right) | (3)/(4) |
90^\circ | 90 |
\text{2/3} | 2/3 |
2² | 2**2 |
1,234 | 1234 |
这套规则覆盖了 MATH-500 数据集中绝大多数常见格式。对于更复杂的 LaTeX(如区间、集合、矩阵),可以在此基础上扩展为混合解析器(Hybrid Parser),在保持简洁性的同时提升边界情况的覆盖率。
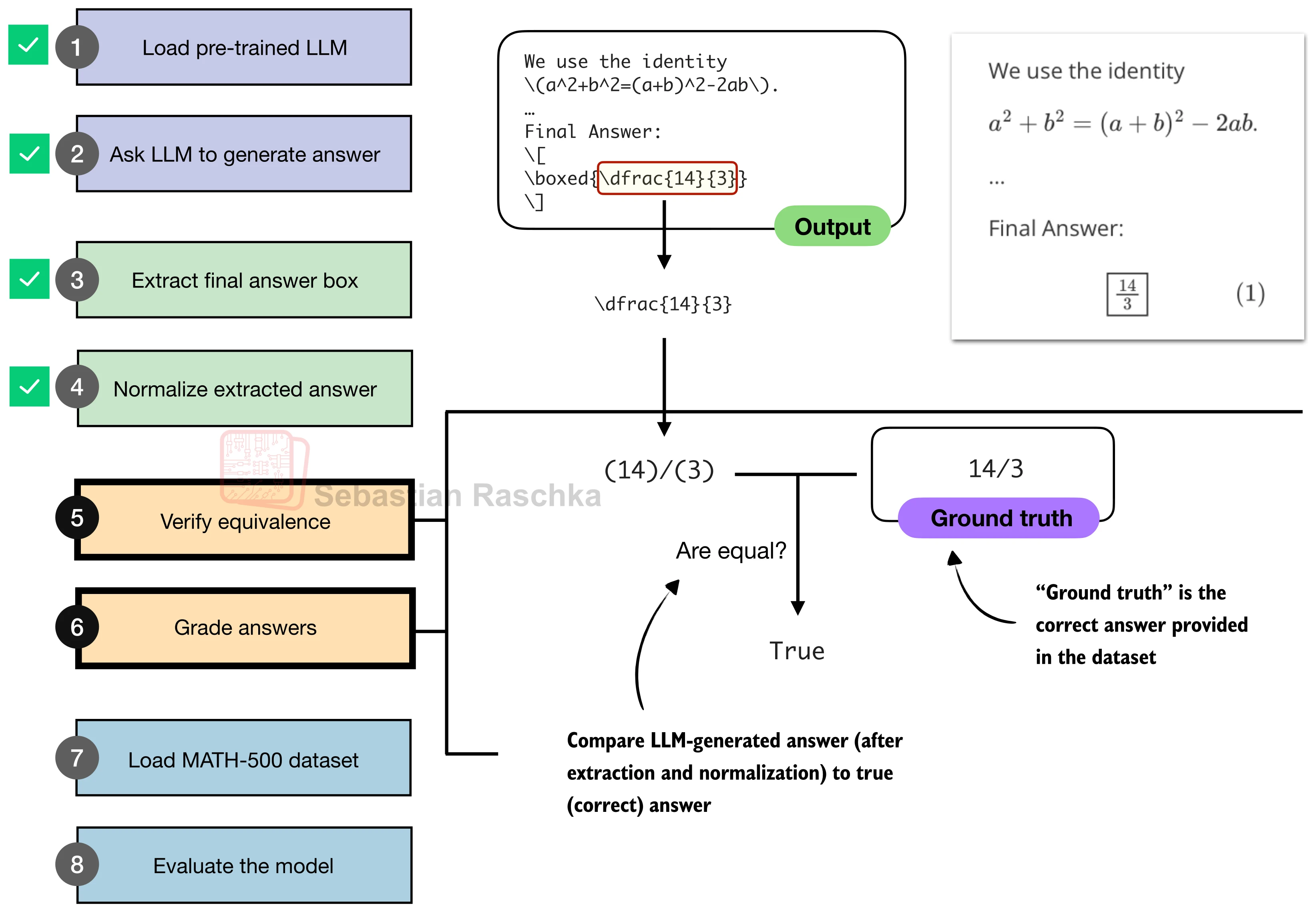
三、符号等价判定
规范化后的文本仍可能存在形式差异。例如 (14)/(3) 和 28/6 是不同的字符串,但数学上完全等价。这一步借助 SymPy 符号计算库,将文本解析为符号表达式后进行等价判定。
from sympy.parsing import sympy_parser as spp
from sympy.core.sympify import SympifyError
from sympy import simplify
from tokenize import TokenError
from sympy.polys.polyerrors import PolynomialError
def sympy_parser(expr):
"""将文本解析为 SymPy 符号表达式"""
if expr is None or len(expr) > 2000:
return None # 防止垃圾输出导致解析器卡死
try:
return spp.parse_expr(
expr,
transformations=(
*spp.standard_transformations,
spp.implicit_multiplication_application, # "2x" → 2*x
),
evaluate=True, # 解析时自动化简(如 2+3 → 5)
)
except (SympifyError, SyntaxError, TypeError, AttributeError,
IndexError, TokenError, ValueError, PolynomialError):
return None异常处理的广度并非过度设计——在对 500 道数学题进行评估时,模型生成的非标准格式会触发各种解析错误。每一种 except 都是真实遇到的情况。
等价判定逻辑分两步:先比较字符串,再进行符号化简比较:
def equality_check(expr_gtruth, expr_pred):
"""判断两个数学表达式是否等价"""
# 快速路径:字符串完全相同
if expr_gtruth == expr_pred:
return True
# 慢速路径:符号化简后比较差值
gtruth, pred = sympy_parser(expr_gtruth), sympy_parser(expr_pred)
if gtruth is not None and pred is not None:
try:
return simplify(gtruth - pred) == 0
except (SympifyError, TypeError):
pass
return Falsesimplify(gtruth - pred) == 0 是核心判定条件:SymPy 会对差值进行代数化简,如果结果为零则两个表达式数学等价。例如 simplify(parse("28/6") - parse("14/3")) 返回 0,因此 28/6 和 14/3 被正确判定为等价。
四、组合评分与元组支持
数学题的答案不一定是单个数值,也可能是有序对(如 (3, pi/2))或列表。评分函数需要将答案拆分为独立部分,逐一比较:
def split_into_parts(text):
"""将元组/列表形式的答案拆分为各个分量"""
if not text:
return []
result = [text]
if (len(text) >= 2
and text[0] in "([" and text[-1] in ")]"
and "," in text[1:-1]):
items = [p.strip() for p in text[1:-1].split(",")]
if all(items):
result = items
return result
def grade_answer(pred_text, gt_text):
"""完整评分:规范化 → 拆分 → 逐部分等价判定"""
if pred_text is None or gt_text is None:
return False
gt_parts = split_into_parts(normalize_text(gt_text))
pred_parts = split_into_parts(normalize_text(pred_text))
if (gt_parts and pred_parts
and len(gt_parts) == len(pred_parts)):
return all(
equality_check(gt, pred)
for gt, pred in zip(gt_parts, pred_parts)
)
return False元组比较是有序的——(1, 2) 和 (2, 1) 会被判定为不等,这对坐标等有序答案是正确行为。同时,len(gt_parts) == len(pred_parts) 的检查确保 (1, 2, 3) 不会与 (1, 2) 匹配。
用一组测试用例验证评分系统的正确性:
| 预测 | 标准答案 | 期望 | 实际 |
|---|---|---|---|
3/4 | \frac{3}{4} | True | True |
\frac{\sqrt{8}}{2} | sqrt(2) | True | True |
(1, 2) | (1, 2) | True | True |
(2, 1) | (1, 2) | False | False |
0.5 | 1/2 | True | True |
0.3333333333 | 1/3 | False | False |
2\cdot 3/4 | 3/2 | True | True |
90^\circ | 90 | True | True |
2² | 2**2 | True | True |
注意 0.3333... 与 1/3 被判定为不等——这是有意为之的设计。浮点近似值在符号计算中不等于精确分数,这避免了将"碰巧接近"的错误答案误判为正确。
五、端到端评估
有了评分函数,就可以将整条流水线串联起来,在标准基准(如 MATH-500)上评估模型。
提示模板(Prompt Template) 对评估结果有显著影响。一个典型的模板如下:
def render_prompt(prompt):
return (
"You are a helpful math assistant.\n"
"Answer the question and write the final result on a new line as:\n"
"\\boxed{ANSWER}\n\n"
f"Question:\n{prompt}\n\nAnswer:"
)模板的选择对基座模型和推理模型的影响截然不同:
| 提示模板 | 基座模型准确率 | 推理模型准确率 |
|---|---|---|
带角色 + \boxed{} 指令 | ~20% | ~90% |
| 简洁版("Problem" 替代 "Question") | ~40% | ~60% |
| 无模板(直接传入题目) | ~70% | ~50% |
基座模型在无模板时表现反而最好,因为它接近预训练时的补全模式;而推理模型经过指令微调,更依赖规范的提示格式。这提醒我们:评估结果与提示模板强耦合,跨模型比较时必须统一模板。
完整的评估循环将所有组件串联:
import json
import time
def evaluate_math500(model, tokenizer, math_data, device,
max_new_tokens=2048):
"""在 MATH-500 上评估模型,返回准确率"""
num_correct = 0
results = []
for i, row in enumerate(math_data, start=1):
# 1. 构造提示
prompt = render_prompt(row["problem"])
# 2. 生成回复
generated_text = generate_text(
model, tokenizer, prompt, device,
max_new_tokens=max_new_tokens
)
# 3. 提取答案
extracted = extract_final_candidate(generated_text)
# 4. 评分
is_correct = grade_answer(extracted, row["answer"])
num_correct += int(is_correct)
results.append({
"index": i,
"problem": row["problem"],
"gtruth_answer": row["answer"],
"generated_text": generated_text,
"extracted": extracted,
"correct": bool(is_correct),
})
acc = num_correct / len(math_data)
print(f"Accuracy: {acc*100:.1f}% ({num_correct}/{len(math_data)})")
return results, acc在 MATH-500(500 道竞赛级数学题)上的实测结果:
| 模型 | 设备 | 准确率 | 耗时 |
|---|---|---|---|
| Qwen3-0.6B 基座 | CUDA (H100) | 15.6% | 13.3 min |
| Qwen3-0.6B 推理 | CUDA (H100) | 50.8% | 185.4 min |
推理模型的准确率是基座模型的 3 倍以上,但耗时也增加了约 14 倍——这是因为推理模型会生成长思维链(Chain-of-Thought)。这正是后续章节中推理时间缩放实验和 GRPO 训练要解决的核心权衡:如何在推理质量和计算成本之间找到最优平衡点。
六、评估器的工程考量
在实际使用中,还有几个工程层面的注意事项:
1. 结果持久化。将每道题的生成文本、提取结果和判定结果逐条写入 JSONL 文件。这样即使评估中途中断也不会丢失已有结果,且便于事后分析错误模式。
2. 批量评估加速。逐条生成的评估速度受限于单序列推理吞吐。通过左填充(Left Padding)+ 批量生成,可以在 H100 上将基座模型的评估耗时从 13.3 分钟压缩到 3.3 分钟(batch size=128),推理模型从 185 分钟压缩到 14.6 分钟。批量评估的具体实现将在 26.7 节展开。
3. 验证器的局限性。基于规则和符号计算的验证器只适用于有确定答案的数学问题。对于证明题、开放式推理或自然语言回答,需要引入 LLM-as-Judge 等更灵活的评估方案。不过对于 RLVR(Reinforcement Learning with Verifiable Rewards)训练场景,确定性验证器恰恰是最理想的选择——它提供的奖励信号没有噪声,不会引入"奖励黑客"问题。
本节搭建的评估框架——答案提取、规范化、符号等价判定——构成了后续所有实验的基础设施。无论是下一节的推理时间缩放实验,还是第 26.4 节的 GRPO 训练,都将调用这里实现的 grade_answer 函数作为奖励信号的来源。