1.2 神经网络基础
大语言模型的底层构件是神经网络。无论是千亿参数的 GPT-4 还是开源的 LLaMA,其前向计算的本质仍然可以追溯到最经典的多层感知机(Multilayer Perceptron, MLP)结构——线性变换加非线性激活,再通过反向传播更新参数。与此同时,卷积神经网络(Convolutional Neural Network, CNN)在计算机视觉领域的演进历程,为深度学习积累了一系列至今仍在使用的核心设计范式:批量归一化、残差连接、深层架构等。
本节将从 MLP 的数学形式出发,深入剖析激活函数的设计演进(从 ReLU 到 GELU 再到 SwiGLU),给出前向传播与反向传播的完整推导,最后系统回顾 CNN 架构的演进史——从 AlexNet 到 ResNet,这段历史不仅是计算机视觉的发展主线,更是理解当代大模型设计哲学的重要背景。
1.2.1 多层感知机
线性模型的局限。 考虑一个简单的分类任务:给定输入特征向量
更根本的问题在于:仿射变换的复合仍然是仿射变换。假设一个两层网络不使用任何非线性激活:
将两式合并得到
引入非线性。 解决方案是在每个隐藏层的线性变换之后施加一个逐元素的非线性激活函数
其中
万能近似定理。 Cybenko (1989) 和 Hornik (1991) 分别证明了一个重要理论结果:给定足够多的隐藏单元,即使是单隐藏层的 MLP 也可以以任意精度逼近任何连续函数。这个结论的深刻之处在于它保证了 MLP 的表达能力是充分的。但需要注意,"能表达"并不等于"能学到"——万能近似定理不保证梯度下降能够找到合适的参数,也不告诉我们需要多少隐藏单元。实践表明,使用更深(而非更宽)的网络通常能以更少的参数实现相同的逼近精度 (Simonyan 和 Zisserman, 2014)。
下面是一个完整的 PyTorch MLP 示例,用于 MNIST 手写数字分类:
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, input_dim=784, hidden_dim=256, num_classes=10):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_classes),
)
def forward(self, x):
return self.net(x.view(x.size(0), -1))
model = MLP()
print(f"参数总量: {sum(p.numel() for p in model.parameters()):,}")
# 参数总量: 269,3221.2.2 激活函数:从 ReLU 到 SwiGLU
激活函数的选择直接影响网络的训练效率和最终性能。深度学习发展至今,激活函数经历了从 Sigmoid/Tanh 到 ReLU、再到 GELU 和 SwiGLU 的演进,每一步都对应着对训练难题的更深刻理解。
Sigmoid 与 Tanh 的衰落。 早期神经网络普遍使用 Sigmoid 函数
ReLU:简洁高效的里程碑。 ReLU(Rectified Linear Unit)由 Nair 和 Hinton (2010) 引入深度学习:
ReLU 的优势很明显:当
然而 ReLU 存在一个已知缺陷——Dying ReLU 问题:如果某个神经元的输入在训练过程中恒为负值,其输出和梯度都为零,对应的权重将永远无法更新,该神经元"死亡"。Leaky ReLU(
GELU:平滑的概率门控。 GELU(Gaussian Error Linear Unit)由 Hendrycks 和 Gimpel (2016) 提出:
其中
GELU 被 GPT、GPT-2、GPT-3 以及 BERT 等模型广泛采用,在 Transformer 架构的 FFN(Feed-Forward Network)模块中取代了 ReLU。
SwiGLU:门控机制的胜利。 [选读] SwiGLU 是当前大语言模型中最主流的激活方案,由 Shazeer (2020) 在系统实验中确立。它是两个思想的组合:Swish 激活函数和门控线性单元(Gated Linear Unit, GLU)。
Swish 函数定义为
GLU 的核心思想是引入一个可学习的门控向量来动态调节信息流。标准 FFN 的计算为
其中
注意 SwiGLU 引入了三个权重矩阵(
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLU_FFN(nn.Module):
"""LLaMA 风格的 SwiGLU 前馈网络"""
def __init__(self, hidden_dim, multiple_of=256):
super().__init__()
mid_dim = int(8 * hidden_dim / 3)
mid_dim = multiple_of * ((mid_dim + multiple_of - 1) // multiple_of)
self.gate = nn.Linear(hidden_dim, mid_dim, bias=False)
self.up = nn.Linear(hidden_dim, mid_dim, bias=False)
self.down = nn.Linear(mid_dim, hidden_dim, bias=False)
def forward(self, x):
return self.down(F.silu(self.gate(x)) * self.up(x))
ffn = SwiGLU_FFN(hidden_dim=512)
x = torch.randn(2, 10, 512) # (batch, seq_len, hidden_dim)
print(ffn(x).shape) # torch.Size([2, 10, 512])以下表格总结了各激活函数的关键特性和典型应用:
| 激活函数 | 公式 | 特点 | 典型应用 |
|---|---|---|---|
| ReLU | 简单高效,正区梯度恒为 1 | 原始 Transformer, T5 | |
| GELU | 平滑可微,概率门控 | GPT 系列, BERT | |
| SwiGLU | 门控机制,三矩阵结构 | LLaMA, PaLM, Mistral |
激活函数的演进揭示了一个清晰的趋势:从简单的硬阈值(ReLU),到平滑的概率门控(GELU),再到可学习的动态门控(SwiGLU),模型获得了越来越强的表达能力。2023 年之后发布的几乎所有主流 LLM 都采用了 SwiGLU。
1.2.3 前向传播与反向传播
理解前向传播与反向传播的数学机制是深度学习的必修课。虽然现代框架(PyTorch、JAX 等)已经实现了自动微分,但掌握反向传播的原理有助于理解梯度消失/爆炸、学习率选择、参数初始化等核心问题。
前向传播。 考虑一个含单隐藏层的 MLP(为简化,省略偏置项)。给定输入
其中
前向传播的过程就是按照从输入到输出的顺序,逐层计算并存储每个中间变量(
反向传播。 [必读] 反向传播基于微积分的链式法则,从输出层向输入层逆序计算目标函数对每个参数的梯度。以上述网络为例,完整的反向传播推导如下:
第一步,计算目标函数对输出层变量的梯度:
若使用交叉熵损失配合 Softmax 输出,可以证明这等于
第二步,计算对输出层权重
第三步,将梯度信号传递到隐藏层:
第四步,经过激活函数反传(逐元素乘法):
其中
第五步,计算对隐藏层权重
一般公式。 对于具有
其中
关于内存的注意事项。 前向传播需要存储所有中间激活值以供反向传播使用。这意味着训练时的显存占用远大于推理:中间激活的存储量与网络层数和批量大小成正比。这也是训练深层网络容易出现 OOM(Out of Memory)的根本原因,理解这一点对后续的混合精度训练、梯度检查点等优化技术至关重要。
1.2.4 卷积神经网络演进史
虽然大语言模型的主干架构是 Transformer,但 CNN 在 2012-2015 年间的演进历程为深度学习积累了许多关键设计范式——包括深层网络的可行性论证、残差连接的发明、批量归一化等。这些思想被直接继承到了 Transformer 架构中。
AlexNet:深度学习的起点(2012)。 2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 提出的 AlexNet 在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中以压倒性优势获胜,将 Top-5 错误率从上一年的 26% 降低到 15%,领先第二名超过 10 个百分点。这一结果震动了整个计算机视觉界,标志着深度学习时代的正式开启。

图 1-4:AlexNet 三位作者合影。Hinton 后来被誉为"深度学习之父"并获诺贝尔物理学奖,Sutskever 成为 OpenAI 联合创始人。
AlexNet 的架构包含 5 个卷积层和 3 个全连接层,总参数量约 6000 万。它有若干关键创新:
- ReLU 激活函数:首次在大型网络中使用 ReLU 替代 Sigmoid/Tanh,训练速度提升数倍且有效缓解了梯度消失问题。
- Dropout 正则化:在全连接层以 50% 的概率随机丢弃神经元,大幅减少过拟合。
- GPU 并行训练:首次利用两块 GPU 分模型并行训练,开创了 GPU 加速深度学习的先河。
- 数据增强:通过随机裁剪、水平翻转和颜色扰动扩充训练数据。
AlexNet 的意义远超一次竞赛的胜利——它向世界证明了"更深的网络 + 大规模数据 + 强大算力"这一组合的威力,直接催生了后续 CNN 的快速迭代。
VGG:深度与简洁的力量(2014)。 来自牛津大学视觉几何组(Visual Geometry Group)的 Simonyan 和 Zisserman 提出了 VGG 网络。VGG 的核心思想极其简洁:用重复堆叠的

图 1-5:从 AlexNet 到 VGG 的架构演进。VGG 将网络组织为重复的"卷积块",每个块包含若干个
这一设计蕴含着精妙的参数效率考量:两个
VGG 的另一个贡献是确立了"网络家族"的概念:通过一个统一的配置模板(arch 参数)定义一系列不同复杂度的网络变体,供使用者在速度和精度之间灵活权衡。这种模块化设计思想至今仍是深度学习架构设计的标准做法。
Inception/GoogLeNet:多尺度并行(2014)。 同年,Google 的 Szegedy 等人提出了 Inception 模块。其核心思想是在同一层中并行使用不同尺度的卷积核(
ResNet:残差连接的革命(2015)。 到了 2015 年,深度网络的训练遇到了一个令人困惑的现象:随着网络层数的增加,训练误差反而上升。注意,这不是过拟合(过拟合表现为训练误差低但测试误差高),而是更深的网络在训练集上的表现就不如更浅的网络。这被称为退化问题(Degradation Problem)。
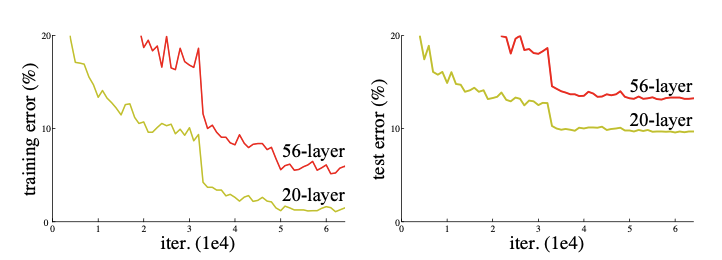
图 1-6:退化问题的实验证据。左图为训练误差,右图为测试误差。56 层网络在两个指标上均劣于 20 层网络,这说明问题不在于过拟合,而在于优化困难。
何恺明等人对此给出了一个优雅的解决方案——残差连接(Residual Connection)。其核心观察是:如果我们希望某些层学习恒等映射
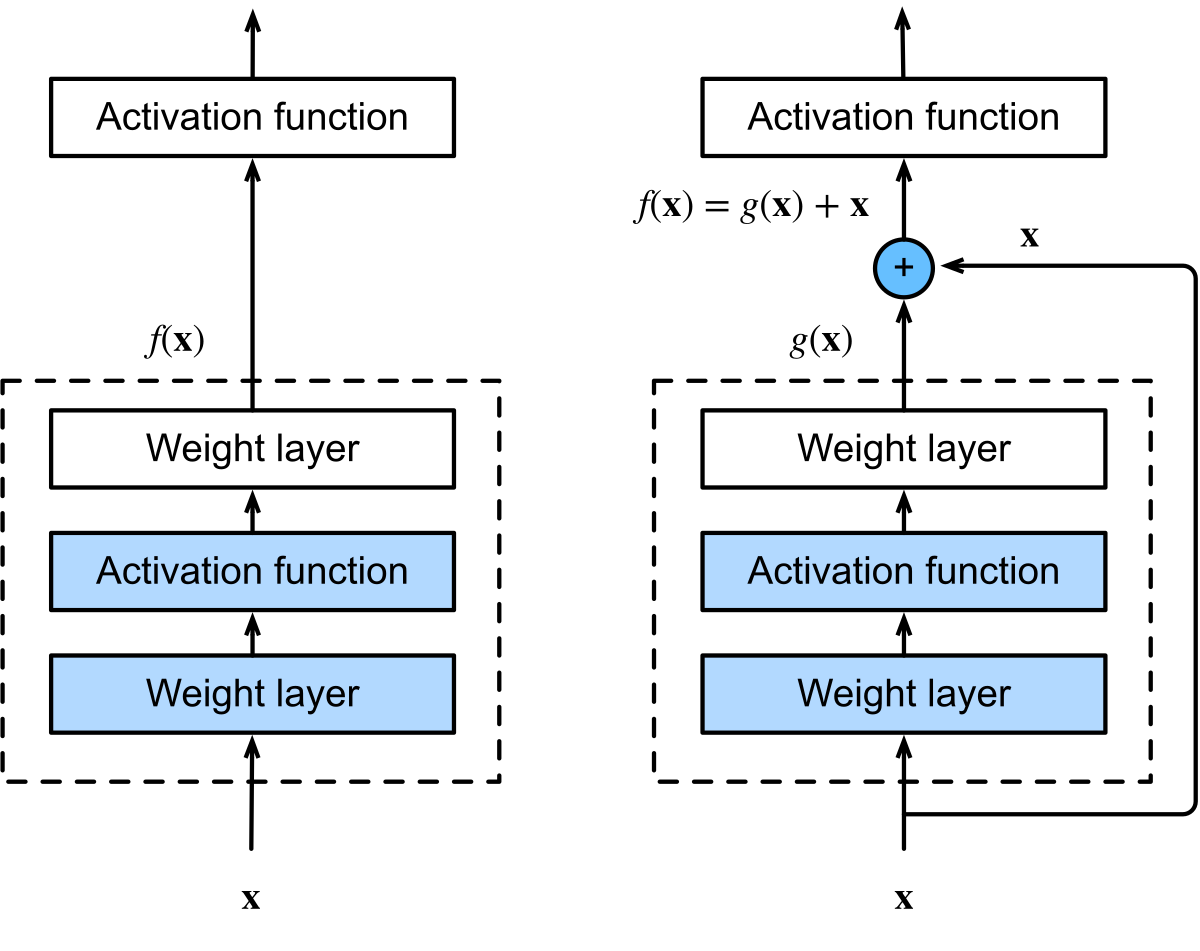
图 1-7:残差块(Residual Block)。输入
残差连接带来了两个根本性的好处:
- 梯度直通:反向传播时,梯度可以通过捷径直接传递到浅层,避免了深层网络中梯度经过层层连乘而衰减的问题。
- 表达能力单调递增:如果新增的层不能提升性能,它只需要学习将
置零,网络就退化为更浅的版本。因此更深的 ResNet 至少不会比更浅的版本差。
ResNet 在 2015 年 ILSVRC 中以 3.57% 的 Top-5 错误率夺冠,首次超越了人类水平(约 5.1%)。其网络深度突破性地达到 152 层(后续研究甚至尝试了 1000 层以上的变体)。ResNet 论文成为 21 世纪引用量最高的学术论文之一。
更深远的影响在于,残差连接已经超越了 CNN 的范畴,成为几乎所有深度神经网络的标准组件。在 Transformer 架构中,每个注意力子层和 FFN 子层都采用了残差连接(
下面给出一个 PyTorch 残差块的实现:
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += residual # 残差连接
return self.relu(out)
block = ResidualBlock(channels=64)
x = torch.randn(1, 64, 32, 32)
print(block(x).shape) # torch.Size([1, 64, 32, 32])以下表格梳理了 CNN 架构演进的关键里程碑:
| 年份 | 模型 | 深度 | 参数量 | ILSVRC Top-5 | 核心贡献 |
|---|---|---|---|---|---|
| 2012 | AlexNet | 8 层 | ~60M | 15.3% | ReLU, Dropout, GPU 训练 |
| 2014 | VGG-16 | 16 层 | ~138M | 7.3% | |
| 2014 | GoogLeNet | 22 层 | ~5M | 6.7% | Inception 多尺度并行, |
| 2015 | ResNet-152 | 152 层 | ~60M | 3.57% | 残差连接, 超越人类水平 |
1.2.5 本节小结
本节从 MLP 的基础数学形式出发,系统梳理了神经网络的三大支柱:网络结构、激活函数和训练算法。激活函数从 ReLU 的硬阈值截断,到 GELU 的平滑概率门控,再到 SwiGLU 的可学习门控机制,每一步演进都在追求更强的表达能力和更稳定的训练动态,SwiGLU 已成为当代 LLM 的标准配置。反向传播通过链式法则将损失信号逆向传递至每个参数,是所有梯度优化方法的数学基础。CNN 的演进史则展示了深度学习领域的核心设计哲学——通过更深的网络、更精巧的模块化设计和残差连接来扩展模型能力。尤其是残差连接,它从 ResNet 出发,已成为包括 Transformer 在内的几乎所有深度架构的标配组件,是连接经典 CNN 时代与大模型时代的关键桥梁。