20.6 评估工具链实战
前几节讨论了评估方法论、基准体系和排行榜设计,但一个现实问题始终悬而未决:拿到一个新训练好的模型,到底怎么用工具跑完一轮完整的评估? 本节将从"能跑起来"出发,聚焦三个主流评估工具——OpenCompass、lm-evaluation-harness 和 TRL Judges/WinRate,给出从安装到出结果的完整操作指南。
20.6.1 OpenCompass:国内最全面的评估框架
OpenCompass 是由上海人工智能实验室开发的开源评测体系,支持 100+ 评测数据集和 30 万+ 测试题目,覆盖知识、推理、语言理解、数学计算和安全对齐等多个维度。它的核心设计理念是**"一套配置、多模型对比、多后端切换"**——你只需要编写一个 Python 配置文件,就能同时对多个模型、在多个数据集上运行标准化评估。
| 特性 | 说明 |
|---|---|
| 全面性 | 支持 C-Eval、MMLU、GSM8K、BBH、HumanEval 等主流基准 |
| 多后端 | 支持 HuggingFace Transformers、LMDeploy(TurboMind)、vLLM 等推理引擎 |
| 并行化 | 支持多卡并行评估,通过 --max-num-workers 控制并发 |
| 标准化 | 统一的评估流程和指标计算,确保结果可复现 |
安装与数据集准备。 安装 OpenCompass 只需一行命令,数据集可以从官方 release 包下载:
# 安装 OpenCompass(基础版)
pip install -U opencompass
# 如需 LMDeploy 加速后端
pip install "opencompass[lmdeploy]"
# 下载离线数据集包
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip命令行快速评估。 对于简单的单模型评估,OpenCompass 提供了开箱即用的 CLI 接口:
# 一行命令:评估 InternLM2.5-1.8B 在 GSM8K 上的表现
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen但真正的生产级评估通常需要更精细的控制——例如同时评估多个模型、指定推理引擎、调整批处理大小。这时就需要编写 Python 配置文件。
编写多模型评估配置。 下面是一个典型的多模型对比配置,同时评估两个不同规模的小模型:
# eval_multi_models.py —— OpenCompass 多模型评估配置
from mmengine.config import read_base
from opencompass.models import TurboMindModelwithChatTemplate
# 第 1 部分:导入数据集配置
with read_base():
from opencompass.configs.datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
from opencompass.configs.datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasets
from opencompass.configs.datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
# 组合数据集(可按需裁剪)
datasets = [*ceval_datasets[:1], *gsm8k_datasets[:1], *mmlu_datasets[:1]]
# 第 2 部分:配置待评估模型
models = [
dict(
type=TurboMindModelwithChatTemplate,
abbr='qwen2.5-0.5b',
path='Qwen/Qwen2.5-0.5B-Instruct',
engine_config=dict(session_len=2048, max_batch_size=128, tp=1),
gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9),
max_out_len=512, max_seq_len=2048, batch_size=128,
run_cfg=dict(num_gpus=1, num_procs=1),
),
dict(
type=TurboMindModelwithChatTemplate,
abbr='internlm2.5-1.8b',
path='internlm/internlm2_5-1_8b-chat',
engine_config=dict(session_len=2048, max_batch_size=64, tp=1),
gen_config=dict(top_k=1, temperature=1e-6, top_p=0.9),
max_out_len=512, max_seq_len=2048, batch_size=64,
run_cfg=dict(num_gpus=1, num_procs=1),
),
]
# 第 3 部分:输出目录
work_dir = './outputs/multi_model_eval'配置文件的结构非常清晰:datasets 列表指定评测哪些基准,models 列表指定评估哪些模型以及对应的推理参数。TurboMindModelwithChatTemplate 是 LMDeploy 推理引擎的标准入口,相比原生 HuggingFace 后端通常能带来 2-5 倍的推理加速。
启动评估。 编写好配置文件后,通过以下命令启动:
# 双卡并行评估,--debug 实时查看日志
opencompass eval_multi_models.py --max-num-workers 2 --debug评估完成后,OpenCompass 会自动在 work_dir 下生成 CSV 格式的汇总报告:
dataset qwen2.5-0.5b internlm2.5-1.8b
---------------------------- ------------- -----------------
ceval-computer_network 31.58 42.11
gsm8k 42.91 53.30
lukaemon_mmlu_college_biology 45.14 56.25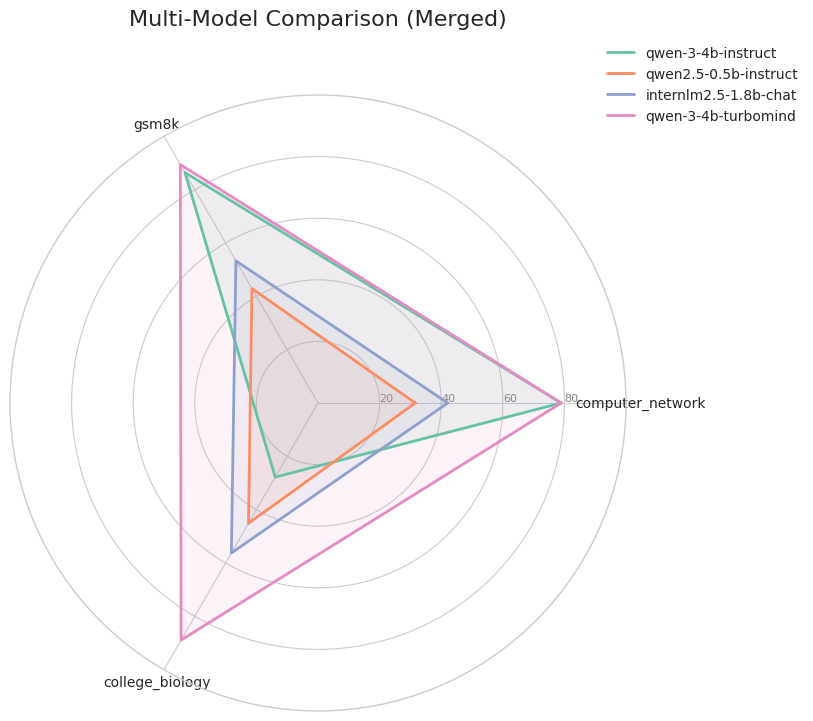
图 20-12:OpenCompass 多模型能力雷达图。不同颜色代表不同模型,图形面积越大代表综合能力越强。参数量的差异在知识类任务上体现得尤为明显。
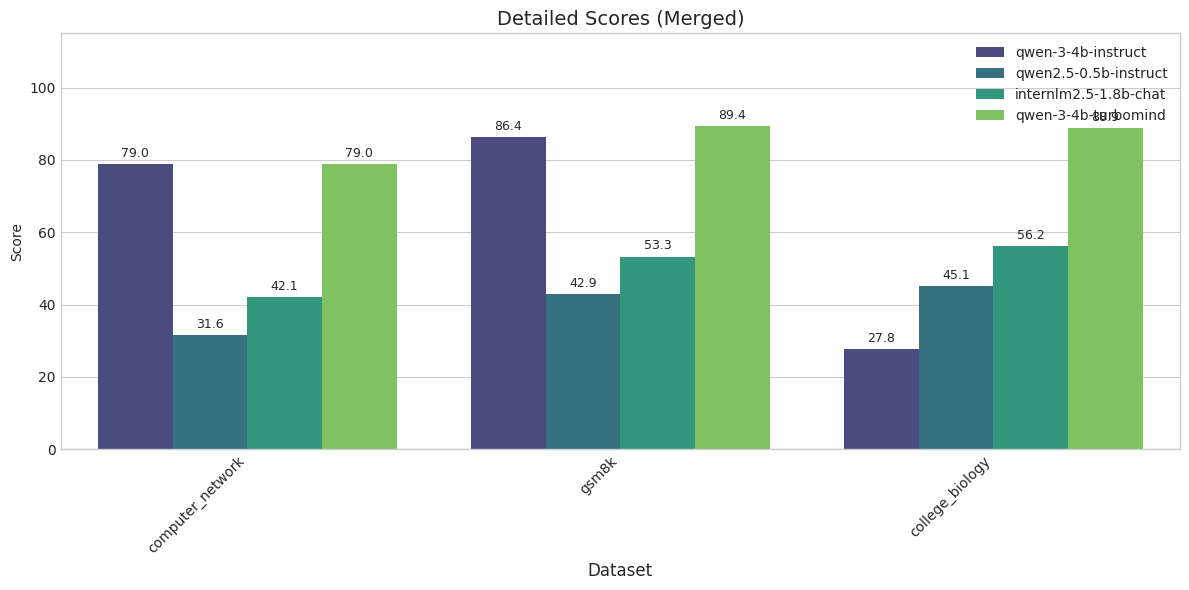
图 20-13:按数据集维度的分数柱状图对比。GSM8K(数学推理)任务上参数量差异带来的性能落差最为突出——4B 模型得分约 89,而 0.5B 仅约 43。
关键实践要点。 使用 OpenCompass 时有几个容易踩的坑:(1)部分模型(如 Qwen 系列)必须设置 trust_remote_code=True,否则无法加载分词器;(2)LMDeploy 后端对 CUDA 和 PyTorch 版本敏感,建议使用独立虚拟环境;(3)batch_size 需根据 GPU 显存合理设置——过大导致 OOM,过小则浪费推理引擎的吞吐优势;(4)评估结果可通过自带的可视化脚本生成雷达图和柱状图,方便团队内部快速对比。
20.6.2 lm-evaluation-harness:学术评估的事实标准
如果说 OpenCompass 是国内生态的首选,那么 EleutherAI 开发的 lm-evaluation-harness(简称 lm-eval)则是国际学术界的事实标准(de facto standard)。绝大多数开源模型论文(Llama、Mistral、RWKV 等)在报告评测结果时使用的都是这个框架,它的评测流程和数值已经成为社区共识。
安装与基本用法。 lm-eval 的安装同样简单:
pip install lm-eval最常用的评估方式是命令行一行搞定:
# 评估本地 HuggingFace 模型在 C-Eval 上的表现
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-0.5B-Instruct,dtype=auto \
--tasks ceval* \
--batch_size 8 \
--trust_remote_code这里 --model hf 表示使用 HuggingFace Transformers 作为推理后端,--tasks 支持通配符匹配多个任务。评估原理与 §20.1 中讨论的一致:对于选择题类任务,lm-eval 会计算候选答案(A/B/C/D)对应 token 的预测概率,选概率最高的作为模型回答,而非让模型自由生成文本。这避免了输出格式不稳定带来的噪声,但也意味着评估结果衡量的是模型的内部知识置信度而非指令遵循能力。
Python API 用法。 除了命令行,lm-eval 也提供了 Python API,方便集成到自动化训练流水线中:
import lm_eval
results = lm_eval.simple_evaluate(
model="hf",
model_args="pretrained=my-model,dtype=auto",
tasks=["mmlu", "gsm8k", "hellaswag"],
batch_size=16,
)
# 提取各任务的准确率
for task, metrics in results["results"].items():
acc = metrics.get("acc,none", metrics.get("acc_norm,none", "N/A"))
print(f"{task}: {acc:.4f}")自定义任务注册。 lm-eval 的任务定义采用 YAML 配置文件。如果你需要在自己的数据集上评估,只需编写一个 YAML 模板:
# my_custom_task.yaml
task: my_chinese_qa
dataset_path: json
dataset_kwargs:
data_files: ./data/my_test.jsonl
output_type: multiple_choice
doc_to_text: "问题:{{question}}\nA. {{A}}\nB. {{B}}\nC. {{C}}\nD. {{D}}\n答案:"
doc_to_target: "{{answer}}"
metric_list:
- metric: acc将这个 YAML 文件放入 lm-eval 的任务目录后,就可以通过 --tasks my_chinese_qa 直接调用。
OpenCompass vs lm-eval-harness:如何选择? 两个框架的定位不同,实际工作中也并非互斥:
| 维度 | OpenCompass | lm-eval-harness |
|---|---|---|
| 生态 | 国内主导,中文基准全面 | 国际主导,英文基准覆盖广 |
| 推理后端 | 原生支持 LMDeploy/vLLM | 以 HuggingFace 为主 |
| 多模型并行 | 内置支持(Slurm/本地) | 需自行编排 |
| 可视化 | 自带结果汇总和对比图表 | 输出 JSON,需自行可视化 |
| 论文复现 | 国内模型论文常用 | 国际模型论文事实标准 |
常见的组合策略是:用 lm-eval 跑一组国际通用基准(MMLU、HellaSwag、ARC)以便与论文对标,再用 OpenCompass 补充中文评估(C-Eval、CMMLU)和推理加速对比。
20.6.3 LLM-as-a-Judge:用大模型评估大模型
基准测试能衡量模型的知识和推理能力,但对于开放式生成任务——写一封邮件、总结一篇文章、创作一首诗——没有标准答案可以比对。这时就需要引入 LLM-as-a-Judge(大模型裁判)的评估范式:用一个能力更强的模型(如 GPT-4)来评判待评估模型的输出质量。
打分模式 vs 配对模式。 两种主要的 Judge 范式各有优劣:
- 逐条打分(Pointwise Scoring):Judge 对单条回复打 1-10 分,适合绝对质量评估。缺点是 Judge 倾向于打高分(宽大偏差,leniency bias),且对 Prompt 措辞敏感。
- 配对比较(Pairwise Comparison):Judge 对比两条回复,选出更好的一个。更稳定可靠,但需要两两比较,评估量为
。
一个关键发现:让大模型"扣分"比"打分"更有效。 研究表明,如果在 Prompt 中要求 Judge 先列出回答的缺陷再给出总分,评分的区分度和与人类判断的一致性会显著提升。这是因为"打分"任务天然存在锚定效应——Judge 倾向于给高分;而"先扣分"策略迫使 Judge 主动寻找问题,打破了这一默认倾向。
实现一个基础的 LLM Judge 并不复杂:
from openai import OpenAI
client = OpenAI()
def judge_response(prompt: str, response: str) -> dict:
"""使用 GPT-4 对模型回复进行评分(先扣分再汇总策略)"""
judge_prompt = f"""你是一个严格的评审专家。请评估以下 AI 助手的回复质量。
【用户提问】
{prompt}
【AI 回复】
{response}
请按以下步骤评审:
1. 逐条列出回复中的缺陷(事实错误、遗漏、表述不清等)
2. 根据缺陷严重程度,从满分 10 分中扣分
3. 给出最终评分和简短理由
输出 JSON 格式:
{{"defects": ["缺陷1", "缺陷2", ...],
"deductions": [{{ "item": "缺陷描述", "points": 扣分值}}, ...],
"final_score": N,
"reasoning": "总结性评语"}}"""
resp = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": judge_prompt}],
temperature=0,
response_format={"type": "json_object"},
)
import json
return json.loads(resp.choices[0].message.content)Judge 的一致性问题。 LLM Judge 并非完美裁判,需要警惕以下偏差:
| 偏差类型 | 表现 | 缓解方法 |
|---|---|---|
| 位置偏差 | 倾向于选择第一个(或最后一个)回复 | 交换回复顺序后重新评估,取平均 |
| 长度偏差 | 倾向于偏好更长的回复 | 在 Prompt 中明确"长度不应影响评分" |
| 自我偏好 | GPT-4 裁判更偏好 GPT-4 生成的内容 | 使用不同家族的模型作为 Judge |
| 宽大偏差 | 倾向于给高分 | 采用"先扣分再汇总"的评分策略 |
图 20-14:LLM 评估维度全景图。知识、推理、指令遵循、安全等维度之间存在交互影响,完整的评估工具链需要覆盖多个维度才能给出可靠结论。
20.6.4 TRL Judges 与 WinRate 回调:训练中的在线评估
前面讨论的评估工具都是离线的——训练结束后再跑评估。但在实际的 RLHF/DPO 训练流程中,我们常常需要在训练过程中实时监控模型质量:模型在第 500 步时比第 100 步好了吗?当前策略模型相比参考模型有多大提升?
HuggingFace 的 TRL 库提供了一套轻量级的 Judges 模块和 WinRateCallback,正是为了解决这个需求。
TRL Judges 模块。 TRL 提供了多种开箱即用的 Judge 实现:
from trl.experimental.judges import HfPairwiseJudge
# 使用 HuggingFace 上的奖励模型作为配对裁判
judge = HfPairwiseJudge()
results = judge.judge(
prompts=[
"What is the capital of France?",
"What is the biggest planet in the solar system?",
],
completions=[
["Paris", "Lyon"], # 第一个 prompt 的两个候选回复
["Saturn", "Jupiter"], # 第二个 prompt 的两个候选回复
],
)
print(results) # [0, 1] —— 第一个 prompt 选回复 0,第二个选回复 1返回值是一个索引列表,每个元素表示对应 prompt 下哪个回复更好(0 或 1)。除了 HfPairwiseJudge,TRL 还提供了 OpenAIPairwiseJudge(调用 OpenAI API)和 PairRMJudge(基于 PairRM 奖励模型)。
自定义 Judge。 通过继承 BasePairwiseJudge 可以快速实现自定义评判逻辑:
from trl.experimental.judges import BasePairwiseJudge
class PrefersConciseJudge(BasePairwiseJudge):
"""偏好更简洁回复的裁判——可用于研究长度偏差"""
def judge(self, prompts, completions, shuffle_order=False):
return [0 if len(c[0]) < len(c[1]) else 1 for c in completions]WinRateCallback:训练中的自动胜率追踪。 WinRateCallback 是 TRL 的一个训练回调(Callback),它在训练过程中周期性地让当前模型和参考模型对同一批 prompt 生成回复,然后通过 Judge 计算胜率(Win Rate)——即当前模型的回复被判定为更好的比例。这个指标直观地反映了"当前模型相比基线提升了多少":
from trl.experimental.winrate_callback import WinRateCallback
from trl.experimental.judges import OpenAIPairwiseJudge
# 创建 Judge 和 WinRate 回调
judge = OpenAIPairwiseJudge()
winrate_callback = WinRateCallback(
judge=judge,
eval_dataset=eval_prompts, # 用于评估的 prompt 集合
ref_model=ref_model, # 参考模型(如 SFT 后的初始模型)
eval_steps=500, # 每 500 步评估一次
)
# 将回调注入 Trainer
trainer = DPOTrainer(
model=model,
ref_model=ref_model,
callbacks=[winrate_callback],
# ... 其他训练参数
)训练过程中,TensorBoard 或 Weights & Biases 上会实时显示胜率曲线。如果胜率稳定上升,说明对齐训练正在有效改善模型;如果胜率停滞或下降,则可能需要调整学习率、检查奖励模型的质量,或排查 reward hacking 问题。
20.6.5 端到端评估流水线
在实际项目中,上述工具通常不会孤立使用,而是串联成一条完整的评估流水线(Evaluation Pipeline)。一个典型的模型发布前评估流程如下:
训练完成
│
├─→ lm-eval-harness → MMLU / HellaSwag / ARC → 学术对标
├─→ OpenCompass → C-Eval / CMMLU / GSM8K → 中文能力 + 推理加速对比
├─→ LLM-as-a-Judge → 开放式问答 / 写作 → 生成质量评估
└─→ WinRate (训练中) → 胜率曲线 → RLHF 实时监控
│
▼
汇总报告 + 可视化 → 发布决策每个环节的输出都是决策的依据:lm-eval 的分数用于论文中的表格对标;OpenCompass 的雷达图帮助定位模型的短板维度;LLM Judge 的评分揭示开放式生成的质量;WinRate 曲线验证对齐训练的有效性。没有任何单一工具能够完整评估一个大模型——这正是需要工具链的原因。
本节小结 / 第 20 章回顾
本节从实操层面走完了大模型评估的"最后一公里":OpenCompass 提供了国内最全面的一站式评测平台,lm-evaluation-harness 是国际学术界的事实标准,LLM-as-a-Judge 将人类偏好评估自动化,TRL Judges/WinRate 则将评估嵌入训练循环实现实时监控。
回顾整个第 20 章,我们从评估方法论(§20.1)出发,理解了"好的评估"需要同时关注效度、信度和抗污染性;接着在自动评估指标(§20.2)中掌握了从 Perplexity 到 Pass@k 的量化工具箱;评估基准全景(§20.3)梳理了从 MMLU 到 AlpacaEval 的基准生态;排行榜与竞技场(§20.4)揭示了 Elo/Bradley-Terry 如何将分散的评测结果聚合为全局排名;数据污染与 Inverse Scaling(§20.5)提醒我们评估本身也可能失效。而本节的工具链实战,则将这些理论知识转化为可执行的操作流程。
评估不是训练的附属品,而是模型开发的核心闭环。一个无法被可靠评估的模型,等同于一个无法被信任的模型。掌握了评估工具链,你就拥有了回答"这个模型到底有多好"这个问题的完整武器库。