13.2 LoRA 实践
上一节介绍了多种参数高效微调方法的设计思想,其中 LoRA(Low-Rank Adaptation) 凭借"训练时高效、推理时无损"的特性,已经成为大模型微调的事实标准。本节将从零开始,用纯 PyTorch 代码实现一个完整的 LoRA 层,然后逐步演示如何将它注入到 Transformer 模型中、如何管理权重的保存与加载,以及如何在同一基模型上管理多个 Adapter 以支持不同任务的灵活切换。
13.2.1 从零实现 LoRA 层
回顾 LoRA 的核心公式。对于一个预训练线性层
其中
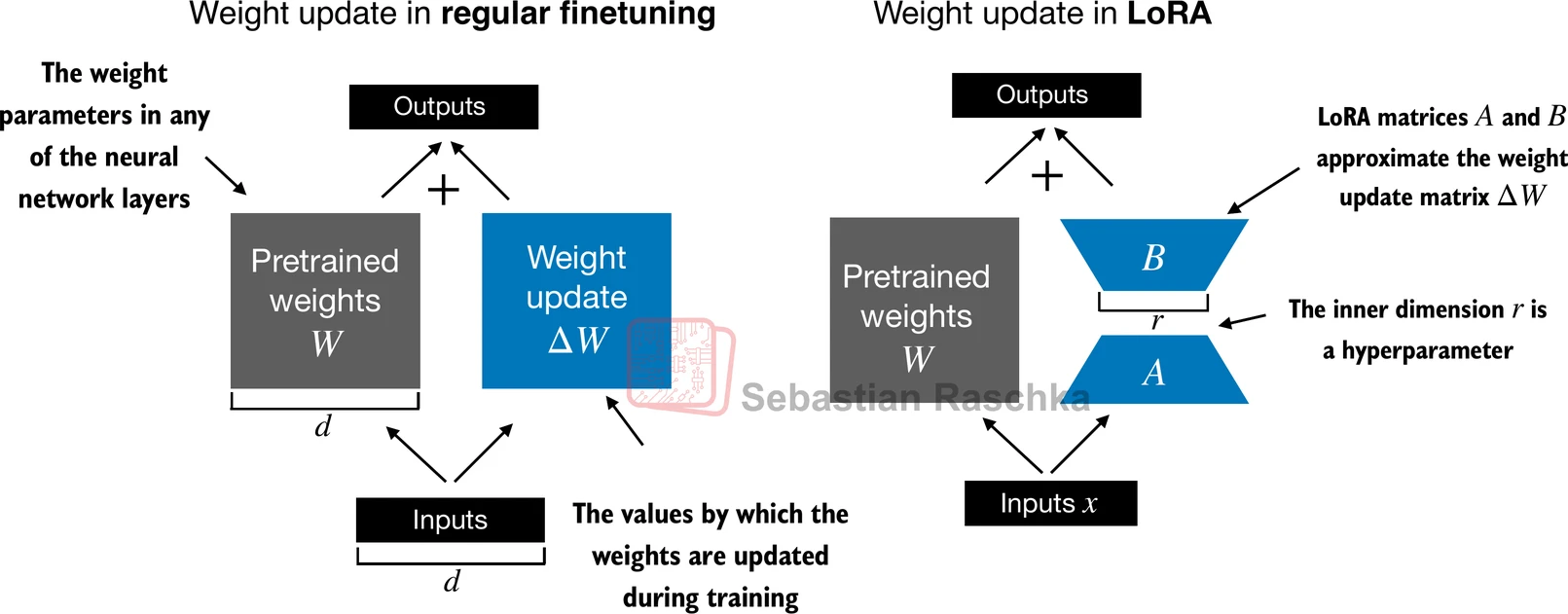
图 13-3:全量微调直接更新整个权重矩阵
初始化策略是 LoRA 训练成功的关键。 标准做法是将
下面用 PyTorch 从零实现 LoRA 层:
import math
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
"""低秩自适应层:学习一对低秩矩阵 A 和 B 来近似权重增量。"""
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
# A: (in_dim, rank),Kaiming 均匀初始化
self.A = nn.Parameter(torch.empty(in_dim, rank))
nn.init.kaiming_uniform_(self.A, a=math.sqrt(5))
# B: (rank, out_dim),全零初始化 → 保证初始 BA = 0
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
self.rank = rank
def forward(self, x):
# x @ A @ B 的形状变化:(batch, in_dim) → (batch, rank) → (batch, out_dim)
return (self.alpha / self.rank) * (x @ self.A @ self.B)alpha / rank 的缩放作用值得解释。这个比值使得在不同秩
13.2.2 将 LoRA 注入 Transformer
有了 LoRA 层之后,需要将它与现有的 nn.Linear 层组合。核心思想是"并行旁路":原始线性层的前向传播不变,LoRA 层并行计算一个增量,两者的输出直接相加。
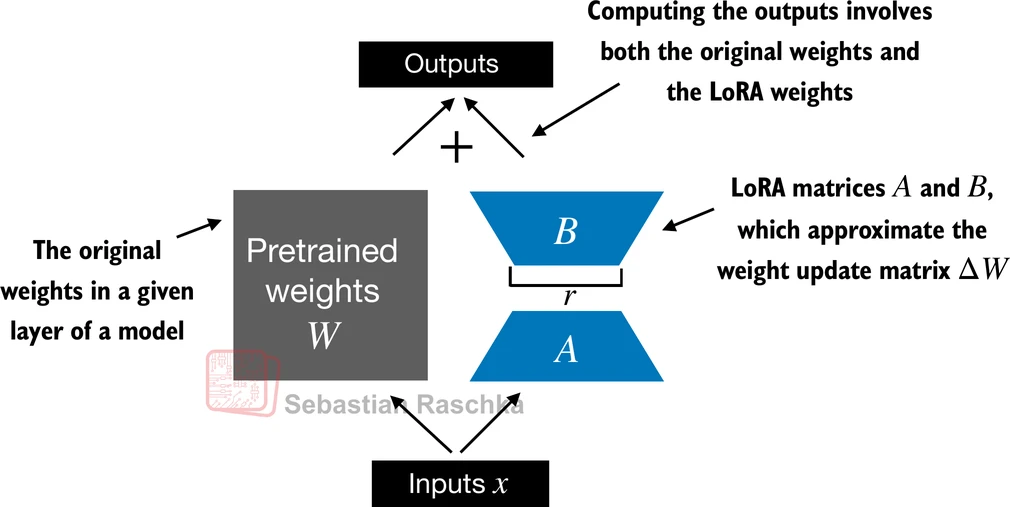
图 13-4:LinearWithLoRA 的内部结构。输入
class LinearWithLoRA(nn.Module):
"""用 LoRA 旁路增强原始线性层,推理时可合并为单个矩阵。"""
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear # 冻结的原始线性层
self.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)
def forward(self, x):
return self.linear(x) + self.lora(x)接下来需要一个递归替换函数,将模型中所有 nn.Linear 层替换为 LinearWithLoRA:
def replace_linear_with_lora(model, rank, alpha):
"""递归遍历模型,将所有 nn.Linear 替换为 LinearWithLoRA。"""
for name, module in model.named_children():
if isinstance(module, nn.Linear):
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else:
replace_linear_with_lora(module, rank, alpha)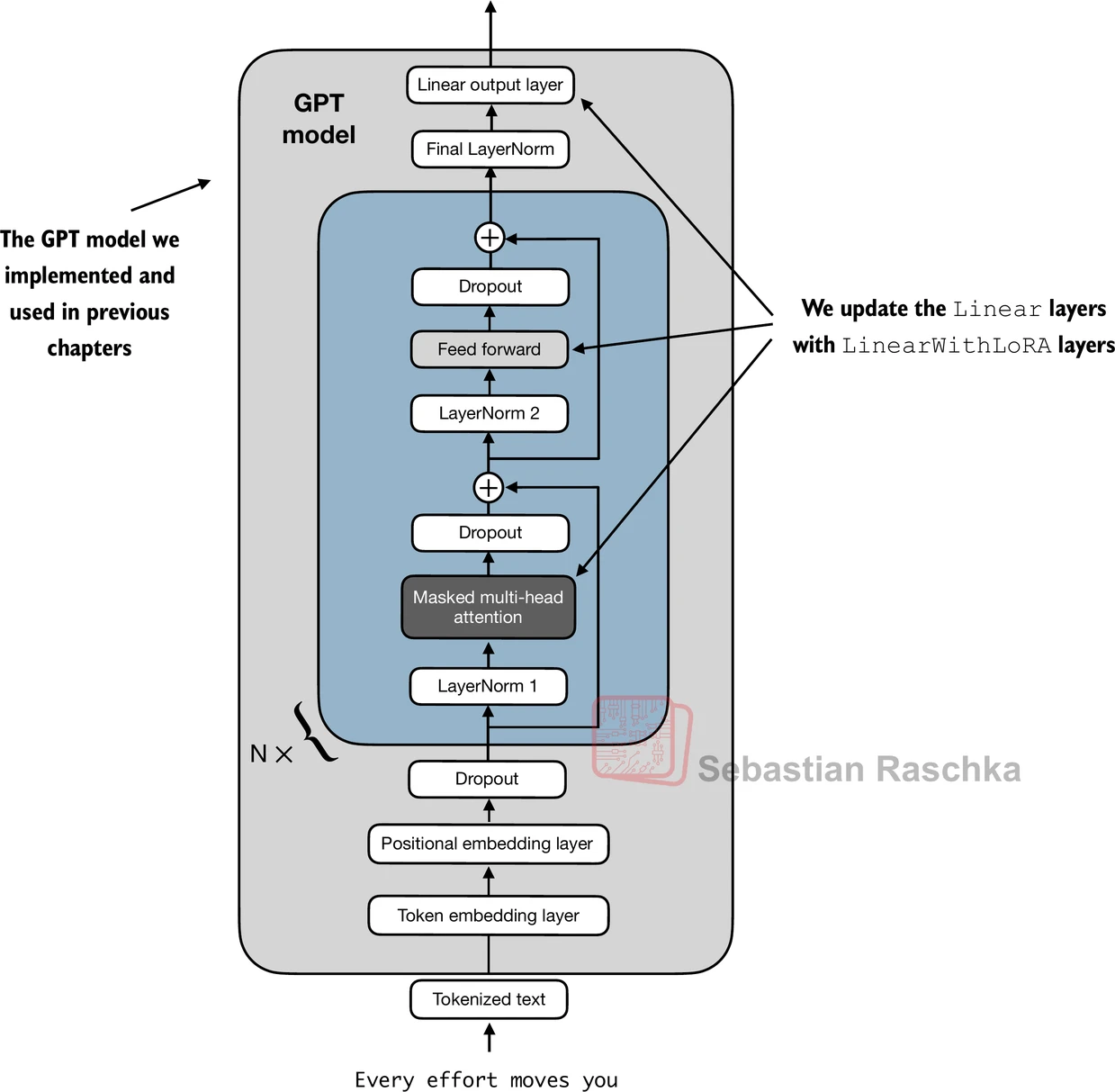
图 13-5:递归替换示意。模型中每个 Linear 层被包裹为 LinearWithLoRA,LoRA 旁路是唯一可训练的部分。
实际注入流程分三步:(1) 冻结原始模型全部参数;(2) 执行替换;(3) 验证可训练参数量。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
# 假设 model 已加载预训练权重
# 第一步:冻结所有原始参数
for param in model.parameters():
param.requires_grad = False
# 第二步:注入 LoRA 旁路(rank=16, alpha=16)
replace_linear_with_lora(model, rank=16, alpha=16)
# 第三步:统计参数量
total = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total:,}")
print(f"可训练 LoRA 参数量: {trainable:,}")
print(f"可训练占比: {trainable / total * 100:.2f}%")以 GPT-2(124M)为例,注入 LoRA 后可训练参数约 267 万,仅占总参数的 2.1%。而对于更小的模型(如 26M 参数的 MiniMind),LoRA 参数约 26 万,占比仅 1%。
注入位置的选择。 LoRA 原论文主要将低秩适配应用于 Transformer 自注意力模块中的 replace_linear_with_lora 函数替换了所有 Linear 层,这是最激进但通常效果最好的策略。在显存受限时,可以有选择地只替换注意力投影层。
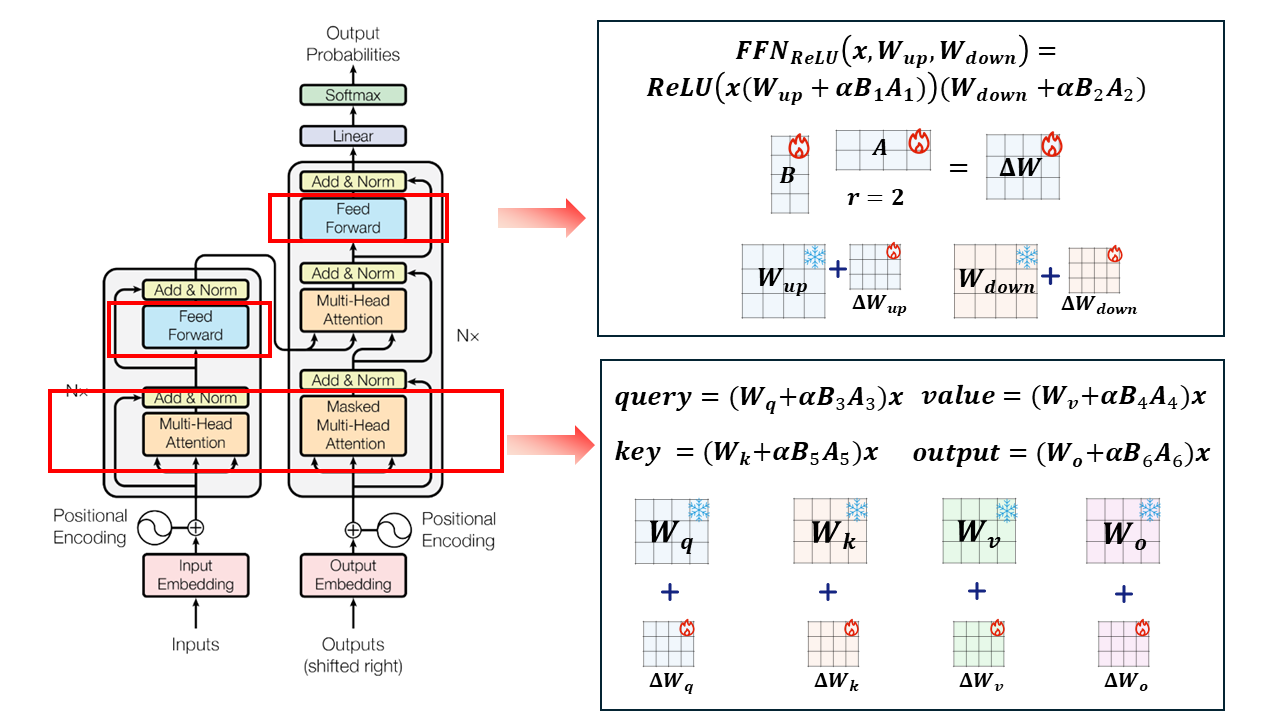
图 13-6:LoRA 可注入到 Transformer 的注意力投影矩阵和 FFN 线性层。注入越多位置,可训练参数越多,但性能通常也越好。
13.2.3 训练循环与参数冻结
LoRA 训练循环与标准微调的唯一区别在于:只有 LoRA 参数参与梯度更新。PyTorch 的 requires_grad 机制会自动跳过冻结参数的梯度计算,因此前向和反向传播中冻结层不会产生梯度存储和优化器状态的额外开销。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch.optim as optim
# 仅收集可训练的 LoRA 参数
lora_params = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.AdamW(lora_params, lr=2e-4, weight_decay=0.1)
# 标准训练循环
model.train()
for epoch in range(num_epochs):
for batch_input, batch_label in train_loader:
batch_input = batch_input.to(device)
batch_label = batch_label.to(device)
optimizer.zero_grad()
logits = model(batch_input)
loss = torch.nn.functional.cross_entropy(logits, batch_label)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")学习率的选择。 使用 LoRA 微调时,通常需要将学习率设为全量微调的 10 倍左右。例如全量微调使用
| 训练方式 | 全量微调学习率 | LoRA 学习率(约 10x) |
|---|---|---|
| SFT(监督微调) | ||
| DPO(偏好优化) | ||
| GRPO / PPO(强化学习) |
表 13-2:不同训练范式下全量微调与 LoRA 微调的推荐学习率对比。
13.2.4 LoRA 权重的保存与加载
LoRA 的一大实用优势是权重文件极小。训练完成后,只需保存 LoRA 参数(即所有
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def save_lora(model, path):
"""只保存模型中 LoRA 层的参数。"""
lora_state = {}
for name, param in model.named_parameters():
if param.requires_grad: # 只有 LoRA 参数是可训练的
lora_state[name] = param.data
torch.save(lora_state, path)
print(f"已保存 {len(lora_state)} 个 LoRA 参数到 {path}")
def load_lora(model, path):
"""加载 LoRA 权重并写入模型对应位置。"""
lora_state = torch.load(path, map_location="cpu")
model_state = model.state_dict()
for key, value in lora_state.items():
if key in model_state:
model_state[key] = value
model.load_state_dict(model_state)
print(f"已从 {path} 加载 {len(lora_state)} 个 LoRA 参数")
# 保存
save_lora(model, "lora_sft.pth")
# 加载:先构建原始模型并注入 LoRA 结构,再加载权重
load_lora(model, "lora_sft.pth")推理时的权重合并。 LoRA 的另一个核心优势是可以在部署前将低秩矩阵合并回原始权重,使推理时的模型结构与原始模型完全一致,不引入任何额外延迟:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def merge_lora(model):
"""将 LoRA 权重合并到原始线性层,消除推理开销。"""
for name, module in model.named_modules():
if isinstance(module, LinearWithLoRA):
# 计算合并后的权重:W_merged = W_original + (alpha/r) * (A @ B)^T
lora = module.lora
delta = (lora.alpha / lora.rank) * (lora.A @ lora.B) # (in, out)
module.linear.weight.data += delta.T # Linear 的 weight 是 (out, in)
# 合并后可以丢弃 LoRA 层
print("LoRA 权重已合并到原始模型")合并后的模型与全量微调后的模型在数学上等价,推理速度也完全相同。这正是 LoRA 优于 Adapter-Tuning 的关键——Adapter 在推理时会引入额外的前向传播延迟,而 LoRA 可以做到零推理开销。
13.2.5 多 Adapter 管理与热切换
LoRA 的模块化特性使得同一基模型可以搭配不同的 Adapter 来服务不同的下游任务。每个 Adapter 只是一组小体积的
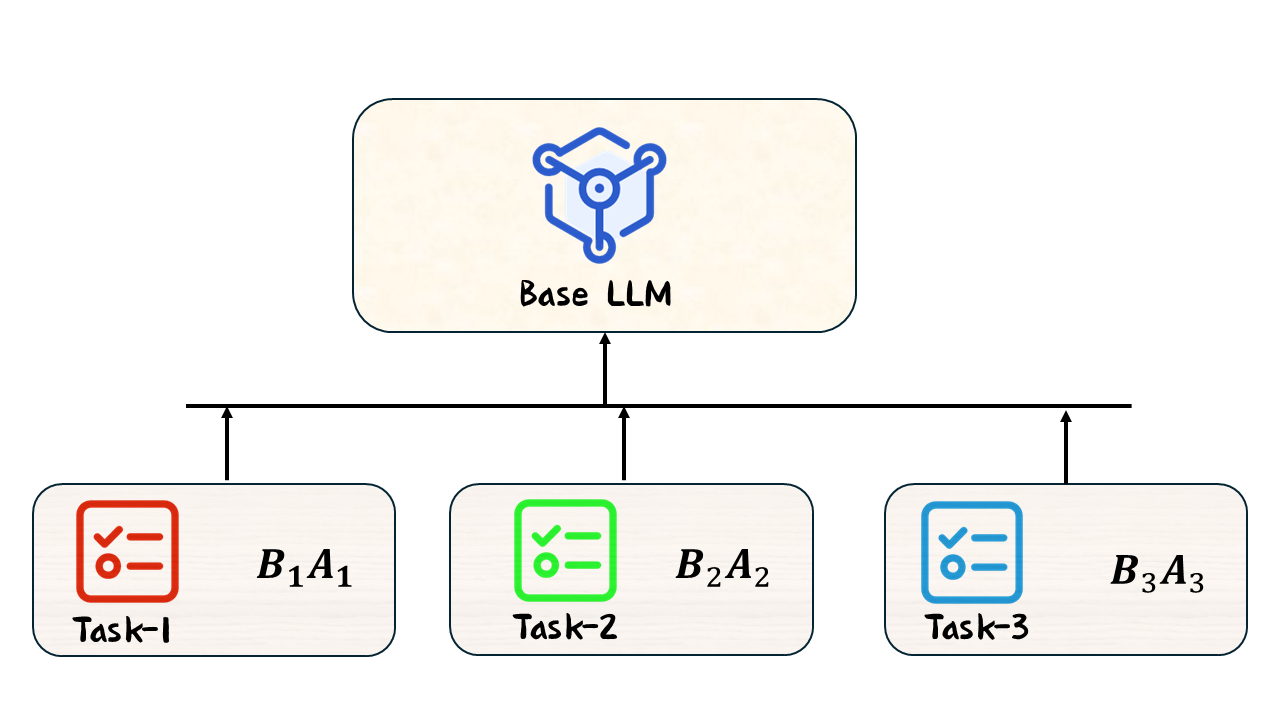
图 13-7:多 Adapter 管理示意。同一基模型可搭配不同的 LoRA 权重,按需切换以适配法律、医疗、金融等不同领域。
下面实现一个完整的多 Adapter 管理器:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
class LoRAAdapterManager:
"""管理多个 LoRA Adapter,支持注册、切换和列表查询。"""
def __init__(self, model):
self.model = model
self.adapters = {} # name -> state_dict
self.active_adapter = None
def register(self, name, path):
"""注册一个 Adapter(延迟加载,只记录路径)。"""
self.adapters[name] = path
print(f"已注册 Adapter: {name}")
def activate(self, name):
"""激活指定 Adapter:加载其 LoRA 权重到模型中。"""
if name not in self.adapters:
raise ValueError(f"未知 Adapter: {name}")
if self.active_adapter == name:
return # 已是当前活跃 Adapter
# 先重置所有 LoRA 参数为零(卸载旧 Adapter)
self._reset_lora_params()
# 加载新 Adapter
load_lora(self.model, self.adapters[name])
self.active_adapter = name
print(f"已激活 Adapter: {name}")
def _reset_lora_params(self):
"""将所有 LoRA 参数归零,等效于卸载当前 Adapter。"""
for name, param in self.model.named_parameters():
if param.requires_grad:
param.data.zero_()
def list_adapters(self):
"""列出所有已注册的 Adapter。"""
for name, path in self.adapters.items():
status = " (active)" if name == self.active_adapter else ""
print(f" {name}: {path}{status}")
# 使用示例
manager = LoRAAdapterManager(model)
manager.register("medical", "lora_medical.pth")
manager.register("legal", "lora_legal.pth")
manager.register("finance", "lora_finance.pth")
manager.activate("medical") # 加载医疗领域 Adapter
# ... 执行医疗领域推理 ...
manager.activate("legal") # 热切换到法律领域 Adapter
# ... 执行法律领域推理 ...使用 HuggingFace PEFT 库管理 Adapter。 在生产环境中,HuggingFace 的 peft 库提供了更成熟的多 Adapter 管理能力。通过 PeftModel,可以在一个基模型上加载、切换和合并多个 LoRA Adapter:
from peft import LoraConfig, get_peft_model, PeftModel
from transformers import AutoModelForCausalLM
# 加载基模型
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B")
# 方式一:从头配置 LoRA 并训练
peft_config = LoraConfig(
r=32,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
)
model = get_peft_model(base_model, peft_config)
model.print_trainable_parameters()
# 输出示例:trainable params: 2,359,296 || all params: 466,291,712 || trainable%: 0.506
# 方式二:加载已有 Adapter 并在推理前合并
model = PeftModel.from_pretrained(base_model, "path/to/saved/adapter")
model = model.merge_and_unload() # 合并后变回普通模型,推理零开销与 TRL(Transformer Reinforcement Learning)库配合使用时,只需在 Trainer 中传入 peft_config 即可自动完成 LoRA 注入:
from peft import LoraConfig
from trl import SFTConfig, SFTTrainer
peft_config = LoraConfig(r=32, lora_alpha=16, lora_dropout=0.05,
bias="none", task_type="CAUSAL_LM")
training_args = SFTConfig(learning_rate=2e-4, num_train_epochs=3,
per_device_train_batch_size=4)
trainer = SFTTrainer(
model="Qwen/Qwen2-0.5B",
args=training_args,
train_dataset=dataset,
peft_config=peft_config, # 自动注入 LoRA
)
trainer.train()
trainer.save_model("qwen2-sft-lora") # 只保存 Adapter 权重(几 MB)13.2.6 秩
秩
![]()
图 13-8:LoRA 原论文中对秩
LoRA 原论文中一个令人惊讶的发现是:即使
| 任务复杂度 | 推荐秩 | 典型场景 |
|---|---|---|
| 简单适配 | 1 -- 4 | 情感分类、风格迁移 |
| 中等复杂 | 8 -- 16 | SFT 指令微调、领域适配 |
| 高复杂 | 32 -- 64 | 多任务学习、复杂推理能力注入 |
表 13-3:秩
另一个实用的调参技巧是 lora_alpha 与 r 的比值。当
13.2.7 小结
本节从零构建了 LoRA 的完整实践流程。核心要点回顾:
- LoRA 层实现:两个低秩矩阵
(Kaiming 初始化)和 (零初始化),保证初始输出与预训练模型一致。 - 注入策略:通过
LinearWithLoRA包装原始线性层,递归替换模型中的所有nn.Linear。注入位置越多通常效果越好。 - 训练要点:冻结原始参数,只优化 LoRA 参数。学习率通常设为全量微调的 10 倍。
- 保存与合并:训练完成后只需保存 LoRA 权重(几 MB)。部署时可将
合并回原始权重,实现零推理开销。 - 多 Adapter 管理:同一基模型可搭配多个 LoRA Adapter 按需热切换,适配不同领域任务。
- 秩
选择:简单任务 即可,复杂任务可用 甚至 ; 的内在秩通常远低于预期。