8.3 长上下文技术
大语言模型的上下文窗口从最初的 2k、4k token 迅速扩展到 128k 乃至百万级别。这一演进并非简单地增大训练序列长度即可实现——位置编码的外推失效、注意力计算的二次复杂度、单卡显存的物理上限,三大瓶颈环环相扣。本节从三个层次系统梳理长上下文技术的关键进展:首先是位置编码层面的 RoPE 外推与 YaRN 算法,解决"模型能否理解超出训练长度的位置"这一根本问题;其次是 FlashAttention 在单卡计算层面对长上下文的支撑作用;最后是分布式与稀疏注意力层面的 Ring Attention、Star Attention 和 DeepSeek Native Sparse Attention(NSA),解决"超长序列如何在多卡上高效计算"以及"如何跳过不重要的注意力计算"这两个工程难题。
8.3.1 RoPE 外推的困境
旋转位置编码(RoPE)是当前大语言模型最主流的位置编码方案(第 7 章已详细介绍)。回顾其核心思想:将输入向量
基数
当模型在训练长度
8.3.2 从 Position Interpolation 到 NTK-aware
Position Interpolation(PI) 采用内插策略解决外推问题:将位置
PI 等价于将所有分量的角频率统一缩小为原来的
NTK-aware Interpolation 抓住了问题的核心:高频外推,低频内插。其思路是定义一个与分组
要求
然而 NTK-aware 仍不够精细。对于那些波长
8.3.3 NTK-by-parts 与 YaRN
NTK-by-parts Interpolation 引入波长与序列长度的比值
- 高频区(
):波长远短于训练长度,模型对这些分量的分布非常敏感,完全外推( )。 - 低频区(
):波长长于训练长度,训练时未见过完整周期,完全内插( )。 - 中频区(
):线性插值平滑过渡。
形式化表示为:
修正后的角频率为
YaRN(Yet Another RoPE extensioN) 在 NTK-by-parts 的基础上增加了一个关键组件——注意力得分温度修正(Attention Scaling):
仅修改频率会导致长序列下注意力分布的熵发生变化(注意力过于分散或尖锐)。为抵消这一影响,YaRN 对注意力得分额外除以温度系数
温度系数的经验公式为
YaRN 的完整流程总结如下:
- 确定扩展倍数:
。 - 计算波长与混合权重:
, ,由 与阈值 确定各分量的外推/内插权重 。 - 修正角频率:
。 - 应用旋转:
。 - 温度修正:缩放因子
。
YaRN 的优雅之处在于只需在少量长文本数据上微调(甚至在某些场景下无需微调),即可将模型的上下文窗口扩展数倍乃至数十倍。实践中,DeepSeek、Llama 等模型在长上下文适配阶段均采用了 YaRN 进行继续训练。
8.3.4 FlashAttention:长上下文的单卡基石
位置编码外推解决了"模型能否理解远处位置"的问题,但即使模型能理解 128k 的位置,标准注意力计算仍需物化一个
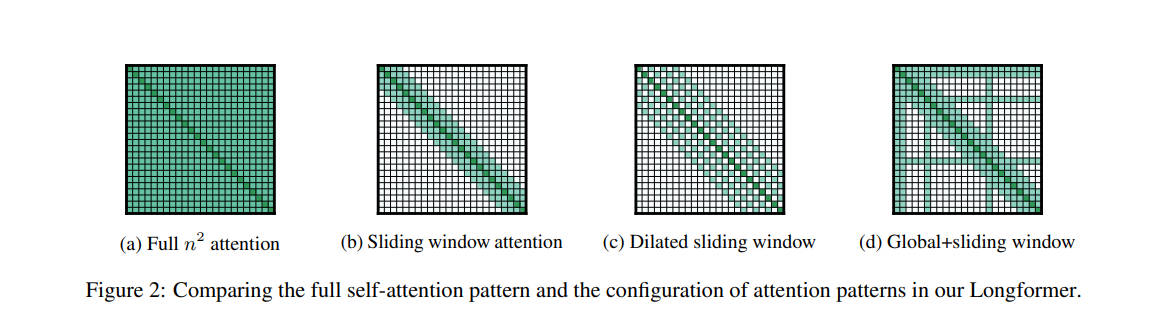
图 8-7:四种注意力模式对比。(a) 标准全注意力(
核心思想。 FlashAttention 的出发点是:标准注意力实现的瓶颈不在于计算量,而在于对 GPU 高带宽内存(HBM)的读写次数。标准实现将
FlashAttention 通过三项技术将注意力计算从内存密集型转变为计算密集型:
(1)分块计算(Tiling)。 将
(2)在线 Softmax。 标准 softmax 需要遍历整行才能获得归一化分母,这与分块计算的局部性矛盾。FlashAttention 采用在线 softmax 算法:处理每个 KV 块时,计算局部最大值和指数和,然后通过伸缩技巧(rescaling trick)校正之前所有块的累积输出。这保证了逐块计算的最终结果与精确 softmax 完全一致——FlashAttention 是精确算法,不存在近似误差。
(3)反向传播重计算。 前向传播时不存储
效果。 FlashAttention 将注意力的内存占用从
8.3.5 Ring Attention:将分块思想推向多卡
FlashAttention 解决了单卡内的注意力效率问题,但当序列长度进一步增长(如 1M token),即使是线性的激活内存也无法放入单卡。Ring Attention 将 FlashAttention 的分块计算思想从单卡推广到多卡,通过在设备间环形传递 KV 块来计算全局注意力。
算法流程。 假设有
- 初始计算:GPU
使用本地的 和 计算局部注意力输出 ,同时维护 softmax 的在线统计量(局部最大值和指数和)。 - 环形传递:GPU
将 发送给环上的下一个 GPU ,同时从上一个 GPU 接收 。 - 增量计算:GPU
用 和新收到的 KV 块计算注意力,并通过在线 softmax 的伸缩技巧更新 。 - 循环:重复步骤 2-3 共
次,直到每个 GPU 的 与所有 KV 块都完成了注意力计算。
计算与通信重叠。 Ring Attention 的关键效率来源在于:当 GPU
因果掩码下的负载均衡。 在因果注意力(Causal Attention)中,序列前部的 token 只能看到少量前序 token,导致朴素的顺序切分下前部 GPU 的有效计算量远小于后部。为此,研究者提出了多种改进:
- Striped Attention:以步长
交错抽取 token 组成块(如 4 卡下分块为 ),使每个 GPU 的块同时包含序列前部和后部的 token,从而均衡计算量。 - Zig-Zag Attention:将序列对称位置的 token 组合成块(如
),可以证明这种切分方式使得每一步每个 GPU 的计算量完全一致,实现理想的负载均衡。
效果。 Ring Attention 将注意力的
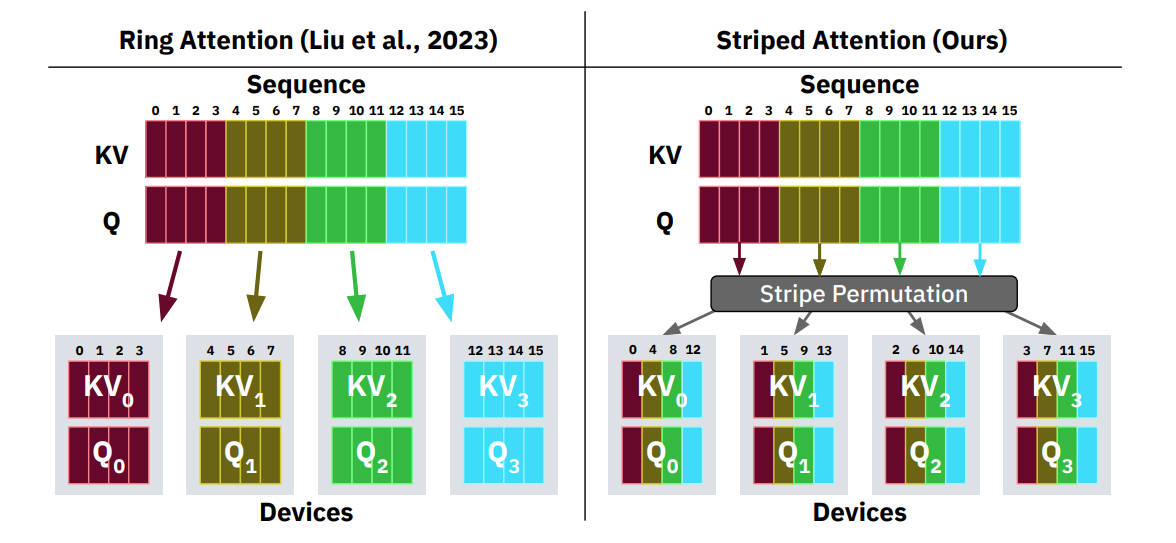
图 8-8:Ring Attention(左)与 Striped Attention(右)的序列分块策略对比。Ring Attention 按连续位置切分 KV 和 Q 到各设备;Striped Attention 通过条纹排列(Stripe Permutation)交错分配 token,使每个设备同时包含序列前部和后部的 token,从而均衡因果掩码下的计算负载。
8.3.6 Star Attention:用锚定块近似全局注意力
Ring Attention 能实现精确的全局注意力,但代价是
上下文编码阶段。 将上下文
每个设备分配一个增强块(共
查询编码阶段。 当新的查询 token 到来时,各设备上缓存的 KV 块恰好构成了 FlashAttention 分块计算的天然输入,可以直接通过在线 softmax 聚合各设备的局部注意力结果。
精度与效率的权衡。 Star Attention 的精度完全取决于锚定块的质量。实验表明,锚定块的内容(而非位置编码)是决定精度的关键因素,且选择序列第一个块作为锚定块的效果最佳。锚定块和上下文块越大,"感受野"越接近全局注意力,精度越高,但通信和内存收益也越小。Star Attention 本质上是对 Ring Attention 的近似优化——牺牲少量精度,换取几乎零跨设备通信的推理效率。
8.3.7 DeepSeek Native Sparse Attention
前述方案都在"如何高效计算完整注意力"上做文章。DeepSeek 的 Native Sparse Attention(NSA)则从另一个角度切入:大部分注意力计算本来就不重要,能否从训练阶段就学会只计算关键的部分?
动机。 在 64k 长度的上下文中,softmax 注意力计算占总推理延迟的 70-80%。现有的推理阶段稀疏注意力方法(如 H2O、Quest)存在两个根本缺陷:一是仅在推理时引入稀疏,偏离了预训练的优化轨迹,性能必然下降;二是离散的 token 选择操作(如 k-means 聚类、哈希选择)阻断梯度流,无法端到端训练。
三路注意力架构。 NSA 将每个查询
三条路径分别为:
(1)压缩路径(Compression)。 将 KV 序列划分为固定大小的块(如块长
压缩路径捕获粗粒度的全局语义信息,将注意力的 token 数量缩减为原来的
(2)选择路径(Selection)。 压缩路径在计算注意力时会产生中间注意力分数
(3)滑动窗口路径(Sliding Window)。 保留最近
硬件对齐的 Kernel 设计。 NSA 基于 Triton 实现了专用的稀疏注意力 kernel。与 FlashAttention 按时间连续的 Query 块加载不同,NSA 的 kernel 按 GQA 组加载同一位置的所有 Query 头(因为它们共享稀疏 KV 块索引),然后顺序加载选中的连续 KV 块。这种"组中心"的加载策略消除了冗余的 KV 传输,平衡了算术强度。
训练与推理统一。 NSA 最显著的特点是从预训练阶段就使用稀疏注意力,而非在预训练后才引入。实验表明,在 27B 参数(3B 激活)的模型上,用 NSA 训练 260B token 后,模型在通用基准、长上下文任务和推理评测上均匹配甚至超越了全注意力基线,同时在 64k 序列上实现了解码、前向传播和反向传播的大幅加速。训练损失曲线显示 NSA 收敛平稳,且始终略低于全注意力模型——这说明稀疏注意力不仅不损失性能,反而可能起到正则化效果。
8.3.8 小结
长上下文技术的发展路径呈现清晰的层次结构:
| 层次 | 技术 | 解决的核心问题 |
|---|---|---|
| 位置编码 | PI → NTK-aware → NTK-by-parts → YaRN | 模型能否理解超出训练长度的位置 |
| 单卡计算 | FlashAttention | 避免物化 |
| 多卡分布式 | Ring Attention(精确)、Star Attention(近似) | 将序列分布到多设备,突破单卡显存上限 |
| 稀疏注意力 | DeepSeek NSA | 从训练阶段就跳过不重要的注意力计算 |
这些技术并非互相替代,而是协同工作。一个典型的长上下文模型(如 DeepSeek V3/R1)可能同时采用 YaRN 进行位置编码外推、FlashAttention 作为底层算子、Ring Attention 实现上下文并行训练、NSA 提供稀疏加速。从 RoPE 外推的数学优雅,到 FlashAttention 对 GPU 存储层级的精妙利用,再到 Ring Attention 的分布式环形通信和 NSA 的层级化稀疏设计,长上下文技术的进步始终遵循一条主线:在不牺牲注意力质量的前提下,尽可能减少计算量、内存占用和通信开销。这条主线还在继续延伸——随着上下文窗口向千万级别推进,更高效的稀疏模式、更精巧的通信拓扑和更紧密的软硬件协同设计,将持续成为大模型基础设施演进的核心方向。