8.1 MoE 完整演进史(1991-2025)
混合专家模型(Mixture of Experts, MoE)是大语言模型时代最重要的稀疏化架构。它的核心思想出人意料地简洁:在不增加推理计算量的前提下,大幅扩展模型的总参数量。一个拥有 256 个专家但每次只激活 8 个的 MoE 模型,其总参数量可达稠密模型的数十倍,而单次推理的计算成本几乎持平。这种"用更多参数记忆更多知识,但只按需调用"的范式,已成为 GPT-4、DeepSeek 系列、Grok、Llama 4 等前沿模型的共同选择。
本节将从 1991 年的原始论文出发,沿时间线梳理 MoE 架构的完整演进,然后深入剖析三个核心技术问题——几何直观(为什么 Top-k 路由是最优的)、负载均衡(三种数学方案的对比)和架构级改进(共享专家与细粒度专家的组合爆炸),最后以 DeepSeek MoE 系列为案例展示这些技术如何在工程中融合。
8.1.1 演进时间线:从 Adaptive Mixtures 到 DeepSeek V3
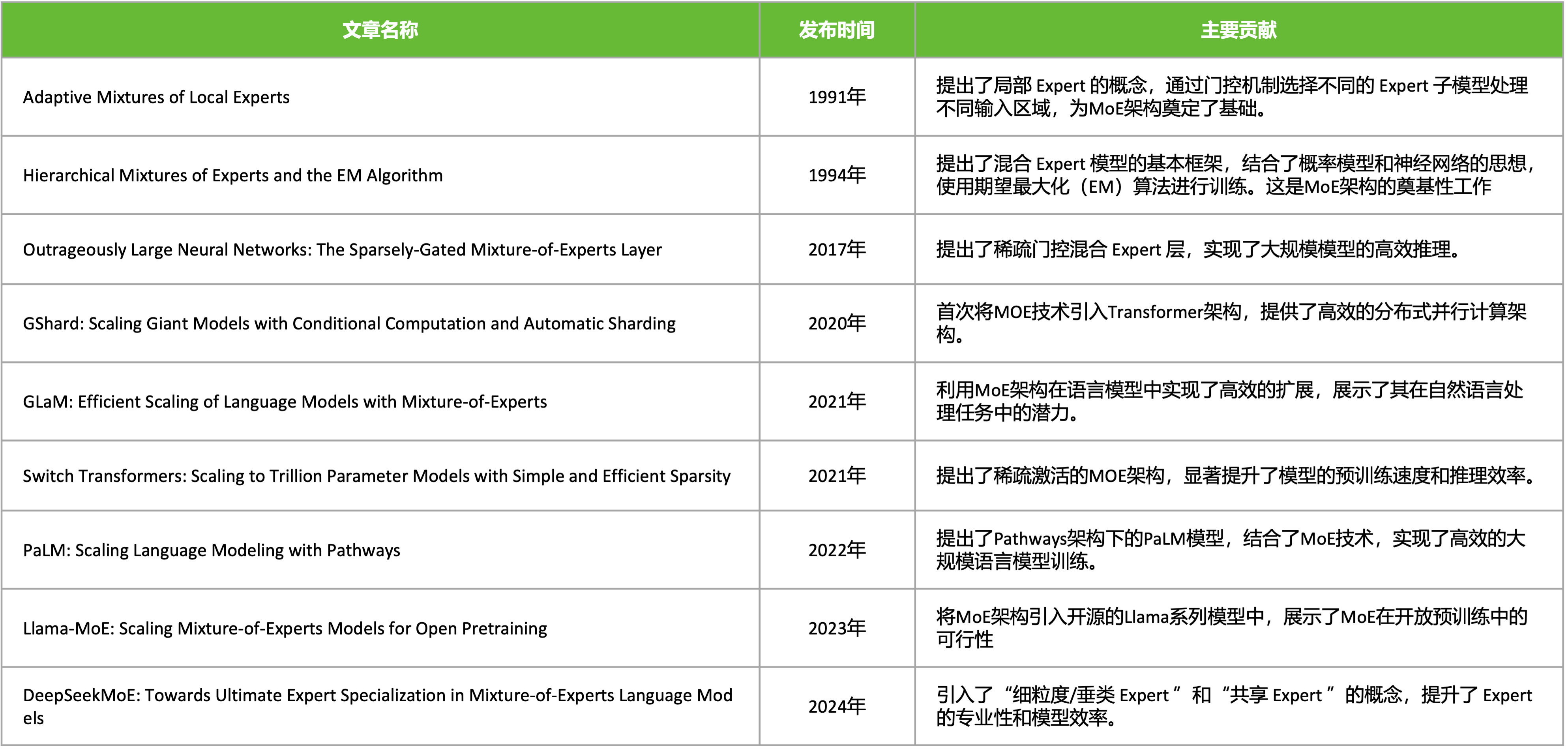
图 8-4:MoE 架构的关键演进节点。从 1991 年 Adaptive Mixtures of Local Experts 的原始提出,到 2024 年 DeepSeekMoE 引入细粒度/共享专家范式,MoE 经历了三十余年的发展。
1991:Adaptive Mixtures of Local Experts。 Jacobs 等人提出了 MoE 的原型——将多个"局部专家"网络与一个门控网络组合,门控网络根据输入决定每个专家的激活权重。这一工作为后续所有 MoE 方法奠定了"门控路由 + 专家并行"的基本范式。但受限于当时的计算条件和网络规模,MoE 长期停留在传统机器学习的领域内,未能在深度学习时代早期引起足够重视。
2017:Outrageously Large Neural Networks(Shazeer et al.)。 这是 MoE 在深度学习中的里程碑式复兴。Shazeer 等人将 MoE 层引入 LSTM 和 Transformer 架构,证明了稀疏激活可以在保持计算量不变的条件下,将模型参数扩大到数千亿级别。该工作首次在大规模 NLP 任务上展示了 MoE 的优势,提出了 Top-k 门控机制和噪声注入策略,并暴露了专家负载不均衡这一核心问题。论文中的实验表明,MoE 模型的容量优势随专家数量的增加而持续提升。
2020:GShard。 Google 将 MoE 扩展到 6000 亿参数规模,首次在多语言机器翻译任务上实现了大规模 MoE 训练。GShard 的关键贡献在于工程层面:引入了**专家并行(Expert Parallelism)**的分布式训练方案——将不同专家部署在不同 TPU 上,通过 All-to-All 通信完成 Token-Expert 的路由分发。GShard 还提出了容量因子(capacity factor)机制来处理负载不均衡问题:每个专家在一个 batch 中能接收的 token 数量有上限,超出容量的 token 通过残差连接直接跳过本层。
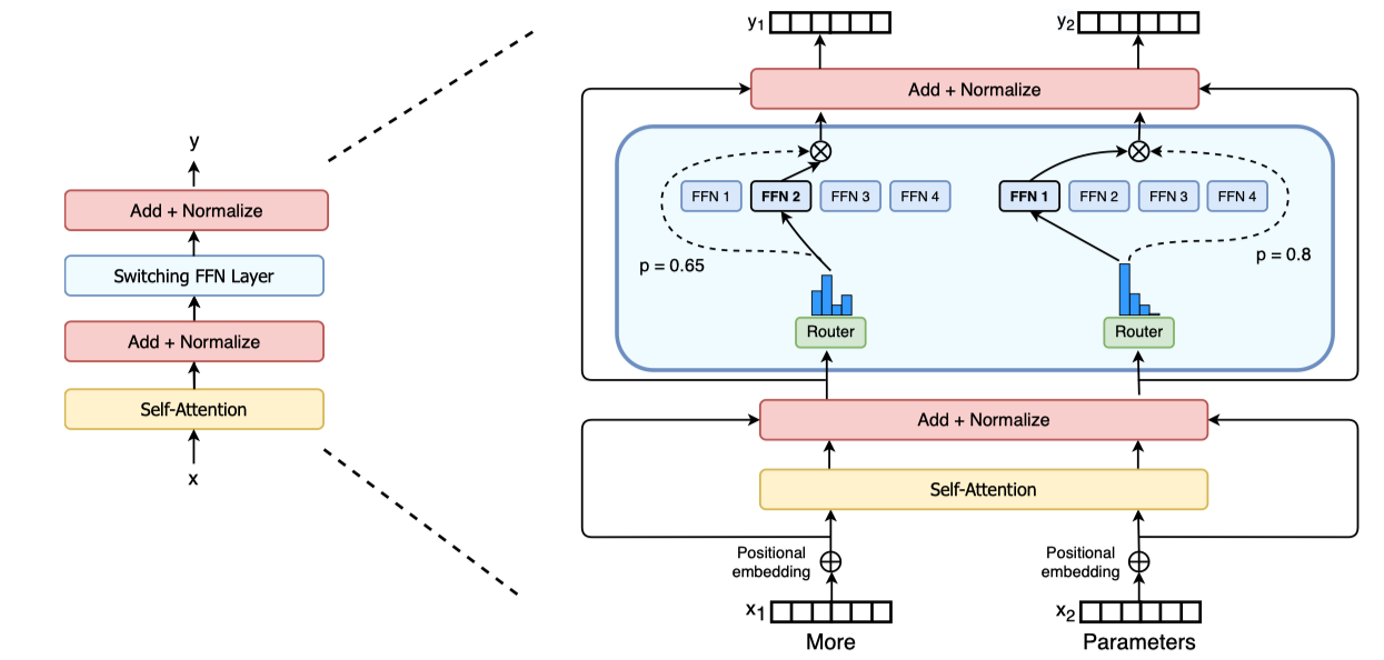
图 8-3:Switch Transformer 架构。左侧为 Switching FFN Layer 的位置(替换标准 FFN),右侧展示了路由器对不同 token 分配到不同专家(FFN 1-4)的过程。每个 token 仅选择概率最高的一个专家(Top-1 路由),大幅简化了通信开销。
2022:Switch Transformer。 Fedus 等人将 MoE 推向极致简化——每个 token 只选择 1 个专家(Top-1 路由)。这一大胆的简化不仅降低了通信开销,还意外地提升了训练稳定性。Switch Transformer 成功训练了 1.6 万亿参数的模型,并提出了经典的辅助负载均衡损失(Auxiliary Load Balancing Loss),其公式
2022:GLaM。 Google 的 GLaM 模型拥有 1.2 万亿参数,每次推理仅激活约 967 亿参数。GLaM 在多项 few-shot 基准上超越了 GPT-3,同时训练能耗仅为 GPT-3 的 1/3。这进一步验证了 MoE 架构在性能-效率权衡上的巨大优势。
2022:ST-MoE(Stable and Transferable MoE)。 Zoph 等人系统地研究了 MoE 模型的训练稳定性问题,提出了 Router z-loss 等正则化技术来缓解训练中的数值不稳定性(如路由器 logits 过大导致的溢出)。ST-MoE 还深入分析了 MoE 模型在微调阶段的迁移能力,发现 MoE 模型虽然预训练效率高,但在小数据集上微调时可能出现过拟合,需要更精细的正则化策略。
2024:DeepSeek MoE V1。 DeepSeek 奠定了"共享专家 + 细粒度专家"的全新范式。在 16B 总参数 / 2.8B 激活参数的规模下,DeepSeek MoE V1 使用 2 个共享专家 + 64 个路由专家,每次激活 6 个路由专家。两项关键创新使其性能超越了同规模的 Mixtral:(1) 细粒度专家——缩小单个专家的尺寸、增加专家数量,在总参数不变的前提下指数级增加路由路径的组合多样性;(2) 共享专家——指定部分专家对所有 token 强制激活,吸收公共知识,让路由专家专注于差异化特征。
2024:DeepSeek V2。 规模扩展至 236B / 21B 激活参数,沿用 V1 的共享+细粒度范式,但引入了设备感知路由——先选择亲和度最高的 M 个设备,再在设备内做 Top-k 选择,从而控制超大规模训练时的通信开销。同时增加了通信均衡损失,不仅平衡计算负载,还平衡设备间的数据传输。
2024-2025:DeepSeek V3。 671B / 37B 激活参数。核心 MoE 结构不变(256 个路由专家 + 1 个共享专家,激活 8 个),但在负载均衡上实现了质的飞跃——引入 Loss-Free 负载均衡,通过可学习的偏置项取代辅助损失,彻底隔离均衡优化与主任务优化。路由层使用 Sigmoid 替代 Softmax,呼应了 MoE 几何直观中"模长"而非"概率"的理论洞察。
下表总结了主要 MoE 模型的架构参数对比:
| 模型 | 年份 | 总参数 | 激活参数 | 路由专家数 | 激活专家数 | 共享专家 | 细粒度比例 | 路由策略 | 负载均衡 |
|---|---|---|---|---|---|---|---|---|---|
| Outrageously Large | 2017 | — | — | 数千 | Top-k | 0 | 标准 | Noisy Top-k | 重要性损失 |
| GShard | 2020 | 600B | — | 2048 | Top-2 | 0 | 标准 | Top-2 | 容量因子 |
| Switch Transformer | 2022 | 1.6T | — | 128-2048 | Top-1 | 0 | 标准 | Top-1 | Aux Loss |
| GLaM | 2022 | 1.2T | 97B | 64 | Top-2 | 0 | 标准 | Top-2 | Aux Loss |
| ST-MoE | 2022 | 269B | — | 32 | Top-2 | 0 | 标准 | Top-2 | Aux Loss + z-loss |
| Mixtral 8x7B | 2024 | 47B | 13B | 8 | 2 | 0 | 标准 | Top-2 | Aux Loss |
| DeepSeek MoE V1 | 2024 | 16B | 2.8B | 64 | 6 | 2 | 1/4 | Top-k | Aux Loss(专家+设备) |
| Qwen 1.5 MoE | 2024 | — | — | 60 | 4 | 4 | 1/8 | Top-k | Aux Loss |
| DeepSeek V2 | 2024 | 236B | 21B | 160 | 6 | 2 | 1/4 | 设备感知 Top-k | Aux Loss + 通信均衡 |
| DeepSeek V3 | 2025 | 671B | 37B | 256 | 8 | 1 | 1/14 | Sigmoid + Top-k | Loss-Free + 序列级 Aux |
| Llama 4 | 2025 | — | — | 128 | 1 | 1 | 1/2 | Top-1 | Aux Loss |
表 8-1:主要 MoE 模型架构参数对比。"细粒度比例"指单个专家的中间维度相对于标准 FFN 的缩小倍数。
从这张表可以清晰地观察到三个趋势:(1) 路由专家数量从个位数增长到数百个,但每次激活数量保持在个位数;(2) 共享专家从无到有,成为 2024 年以后的标配;(3) 细粒度切分越来越激进,单个专家越来越小,组合路径越来越多。
8.1.2 MoE 的几何直观:为什么选"模长最大的 k 个"
要真正理解 MoE 路由的数学本质,需要回到最基础的问题:MoE 是如何从稠密模型中"长出来"的?
从 Dense 到 Sparse 的等价变换。 标准 FFN 层的计算为
每个
近似问题与正交假设。 MoE 的核心诉求是:能否只用
要最小化这个误差,显然应该将
为什么 Router 输出是"模长"而非"概率"。 上述分析揭示了一个关键洞察:最优路由策略是比较各专家输出的"模长"大小,而非比较"概率"。然而,直接计算所有
- 归一化方向:令
,使所有专家的方向向量模长归一; - Router 预测模长:引入轻量级路由网络,直接预测每个专家的模长
,其中 , 为值域非负的激活函数。
MoE 的前向计算公式化为:
重要推论:
8.1.3 [必读] 负载均衡:三种方案的数学对比
如果任由模型自由路由,极易出现少数专家被频繁激活、大量专家长期闲置("死亡专家")的局面。这不仅造成算力浪费,也使大参数量的优势无法发挥。因此,必须引入负载均衡机制。本节对比三种方案的数学原理,从工程启发式逐步演进到解析最优解。
方案一:辅助损失(Auxiliary Loss)
核心思想:在主任务损失之外,添加一个正则化项来惩罚不均衡的路由分配。
定义归一化后的 Router 打分为
目标是最小化均方差
其中
因此,等效的辅助损失为
优点:实现简单,是 Switch Transformer 以来的行业标准。
缺点:权重超参数
方案二:Loss-Free 负载均衡(独立偏置项)
核心思想:彻底隔离均衡优化与主任务优化——不改变 Router 的打分,而是引入一个输入无关的偏置项来干预分配。
引入偏置
关键点:
应用符号梯度下降(SignSGD):
或使用收敛更平稳的 RMS 归一化形式:
优点:主干网络专注模型能力,偏置项专注负载均衡,两者互不干扰。
缺点:仍依赖超参数学习率
方案三:Quantile Balancing(分位数均衡)
核心思想:从数学最优分配的角度出发,通过拉格朗日对偶给出解析解,完全消除超参数和迭代过程。
线性规划建模。 设有
第一个约束要求每个 token 选
Minimax 求解。 松弛
这揭示了一个深刻结论:最优负载均衡可以通过给 Token 加偏置
动态路由的极简解。 如果放宽"每个 token 必须选
此时
算法流程:
- 维护上一步的
和衰减率 ; - 前向激活:若
,则 token 激活 expert ; - 统计当前 batch 每列的
分位数 ,更新 。
优点:无需对所有 token 的分数做 Top-k 排序(只需逐元素比较阈值),且动态决定每个 token 激活的专家数量——是负载均衡的理论最优解。
缺点:动态激活数量给硬件调度带来挑战(不同 token 激活不同数量的专家,难以保证算子的 padding 效率);分位数的在线估计在小 batch 下可能不够稳定。
三种方案对比总结
| 维度 | Auxiliary Loss | Loss-Free(偏置项) | Quantile Balancing |
|---|---|---|---|
| 数学基础 | STE 近似梯度 | STE + 独立更新 | 拉格朗日对偶解析解 |
| 是否影响主任务梯度 | 是(正则项叠加) | 否(完全隔离) | 否(仅修改路由阈值) |
| 超参数 | 权重 | 学习率 | 衰减率 |
| 收敛方式 | 梯度下降迭代 | SignSGD 迭代 | 一步分位数估计 |
| 每 token 激活数 | 固定 | 固定 | 动态(期望为 |
| 硬件友好度 | 高(固定计算图) | 高(固定计算图) | 较低(动态形状) |
| 代表模型 | Switch Transformer, Mixtral | DeepSeek V3 | 理论前沿(实验验证中) |
表 8-2:三种负载均衡方案的数学对比。从左到右,数学严谨性递增,工程易用性递减。
三种方案的演进脉络清晰:Auxiliary Loss 是工程启发式的起点,Loss-Free 通过隔离优化参数解决了梯度冲突问题,Quantile Balancing 则从拉格朗日对偶理论给出了无超参数的解析解。实践中,DeepSeek V3 的 Loss-Free + 序列级辅助损失的混合方案是目前工程效果最好的选择。
8.1.4 架构级改进:共享专家与细粒度专家
前述负载均衡方案的数学目标都是达到均匀分布
共享专家(Shared Expert)
结构定义。 在
残差视角。 共享专家充当公共基底向量,吸收所有 token 的共有基础特征(公共知识)。路由专家仅需拟合减去公共均值后的残差。这一设计的数学优雅之处在于:剥离共性成分后,剩余的特征残差向量之间更容易满足两两正交的假设(8.1.2 节的几何直观),从而使路由策略更逼近最优理论界。
比例控制。 为避免共享专家权重过大致使路由专家边缘化,需要在初始化或前向传播中引入比例因子,对齐两类专家输出的总模长期望。
细粒度专家(Fine-Grained Expert)
结构定义。 在保持模型总参数量和每次前向激活参数量不变的前提下,成倍缩小单个专家的尺寸,同比例增加专家总数和每次激活数。例如,标准 FFN 的中间维度为
组合爆炸。 细粒度切分的核心收益是路由路径的组合多样性呈指数级增长。设原始配置为
- 原始:
种路径 - 2 倍细粒度:
种路径 - 4 倍细粒度:
种路径
从 28 到 1820 再到千万级别,组合多样性的爆炸意味着模型可以用更精细的"微元"去覆盖知识流形的不规则表面,减少大块专家被迫打包不相关知识的冗余。
参数效率。 细粒度切分在总参数和总 FLOPs 均不变的前提下完成,付出的代价仅仅是路由器的输出维度增大(从
下表展示了各模型在细粒度切分上的选择:
| 模型 | 路由专家数 | 激活专家数 | 细粒度比例 | 路由路径数 |
|---|---|---|---|---|
| Mixtral 8x7B | 8 | 2 | 标准 | 28 |
| DeepSeek MoE V1 | 64 | 6 | 1/4 | |
| Qwen 1.5 MoE | 60 | 4 | 1/8 | |
| DeepSeek V3 | 256 | 8 | 1/14 | |
| Llama 4 | 128 | 1 | 1/2 | 128 |
表 8-3:细粒度切分的组合多样性对比。DeepSeek V3 的路由路径数比 Mixtral 多出十余个数量级。
8.1.5 DeepSeek MoE:专家区隔化设计详解
DeepSeek MoE 系列是上述所有技术的集大成者。以下以 DeepSeek V3 的架构为例,结合下图详细解析其设计。
图 8-1:DeepSeek MoE 架构。左侧为 Transformer Block 的整体结构(FFN 层被 MoE 层替换),右侧展示了 MoE 层内部的共享专家(绿色)与路由专家(橙色)的组合方式。Router 基于输入
专家区隔化的三层机制。 DeepSeek MoE 的设计不仅仅是简单地增加专家数量,而是通过三层机制确保专家之间的功能分化(Specialization):
第一层:共享-路由分离。 共享专家负责所有 token 都需要的基础语言能力(语法、常见搭配等),路由专家负责特定领域或特定语义模式的处理。这种分离确保了路由专家不必浪费容量去学习公共知识,可以全力发展差异化能力。
第二层:细粒度切分。 DeepSeek V3 将单个专家的中间维度缩小到标准 FFN 的 1/14,对应 256 个路由专家。每个专家的参数量极小,被迫专注于非常狭窄的功能片段。这种"强制专精"使得不同专家之间的知识重叠大幅减少。
第三层:路由激活函数的选择。 DeepSeek V3 使用 Sigmoid 而非 Softmax 作为路由激活函数。如 8.1.2 节分析,Softmax 的归一化约束强制专家之间零和竞争——一个专家的分数上升必然伴随其他专家的下降。Sigmoid 解除了这一约束,允许多个专家同时获得高分(模长大),路由器只需选出最大的若干个,而非在零和博弈中优胜劣汰。这降低了路由器的学习难度,也减少了"赢家通吃"式塌缩的风险。
DeepSeek V3 的完整 MoE 前向流程:
- 输入
经过共享专家 (所有 token 强制通过),得到基础输出 ; - 输入
经过 Router ,计算 ; - 选出
中最大的 8 个位置,对应的路由专家被激活; - 8 个路由专家分别计算,输出按
加权求和得到 ; - 最终输出
。
Loss-Free 与序列级辅助损失的混合。 在训练过程中,偏置项
8.1.6 本节总结
MoE 架构的三十余年演进史,本质上是围绕三个核心问题的不断深化:
"选谁"——路由机制。 从 1991 年的软门控到 2017 年的 Top-k 硬路由,再到 DeepSeek V3 的 Sigmoid + 动态偏置路由,路由机制的演进方向是从"概率分配"转向"模长排序",这一转向有着严格的几何最优性支撑——在正交假设下,选模长最大的
"怎么均"——负载均衡。 从 Switch Transformer 的辅助损失到 DeepSeek V3 的 Loss-Free 偏置项,再到 Quantile Balancing 的解析最优解,三种方案在数学严谨性上层层递进。实践中的最佳策略是混合使用:Loss-Free 处理全局均衡,轻量级辅助损失兜底局部异常。
"怎么分"——专家架构。 从统一规格的大专家到共享+路由的功能分离,再到细粒度切分带来的组合爆炸(
三者并非独立:几何直观解释了路由策略的最优性,负载均衡保证了大量专家都能被有效利用,而共享+细粒度的架构设计则从根源上增强了专家间的正交性——让理论假设更贴近现实。这三条技术线索在 DeepSeek V3 中交汇,形成了当前最先进的 MoE 架构设计范式。