19.4 投机采样(Speculative Decoding)
大语言模型的自回归推理有一个反直觉的事实:GPU 的计算单元大部分时间不是在算数,而是在等数据。每生成一个 Token,就需要从显存中加载一次全量模型权重,而实际的矩阵乘法运算量极小——这就是推理阶段的内存墙(Memory Wall) 问题。投机采样(Speculative Decoding)正是为打破这堵墙而设计的无损加速技术:它用一个小模型快速"猜"多个 Token,再让大模型一次性"验",把串行的访存瓶颈转化为可并行的计算任务。
19.4.1 核心动机:推理为何受限于内存带宽
要理解投机采样的动机,首先需要区分推理中两个阶段的计算特性。
Prefill 阶段处理用户的完整输入提示,所有 Token 同时可见,可以在序列维度上并行计算——此时 GPU 的算力被充分利用,属于计算受限(Compute-Bound) 场景。
Generation(解码)阶段则完全不同。由于自回归特性,每一步只生成一个 Token,必须等前一个 Token 生成完毕才能开始下一个。每生成一个 Token,GPU 需要将整个模型的权重(对于 70B 模型约 140 GB)从显存加载到计算单元,但实际只做了一次向量-矩阵乘法。用算术强度(Arithmetic Intensity) 来衡量——每传输一个字节所执行的浮点运算次数——解码阶段的算术强度接近 1 FLOP/Byte,远低于 GPU 的平衡点(通常在 100 FLOP/Byte 以上),落入 Roofline 模型的内存受限区域。
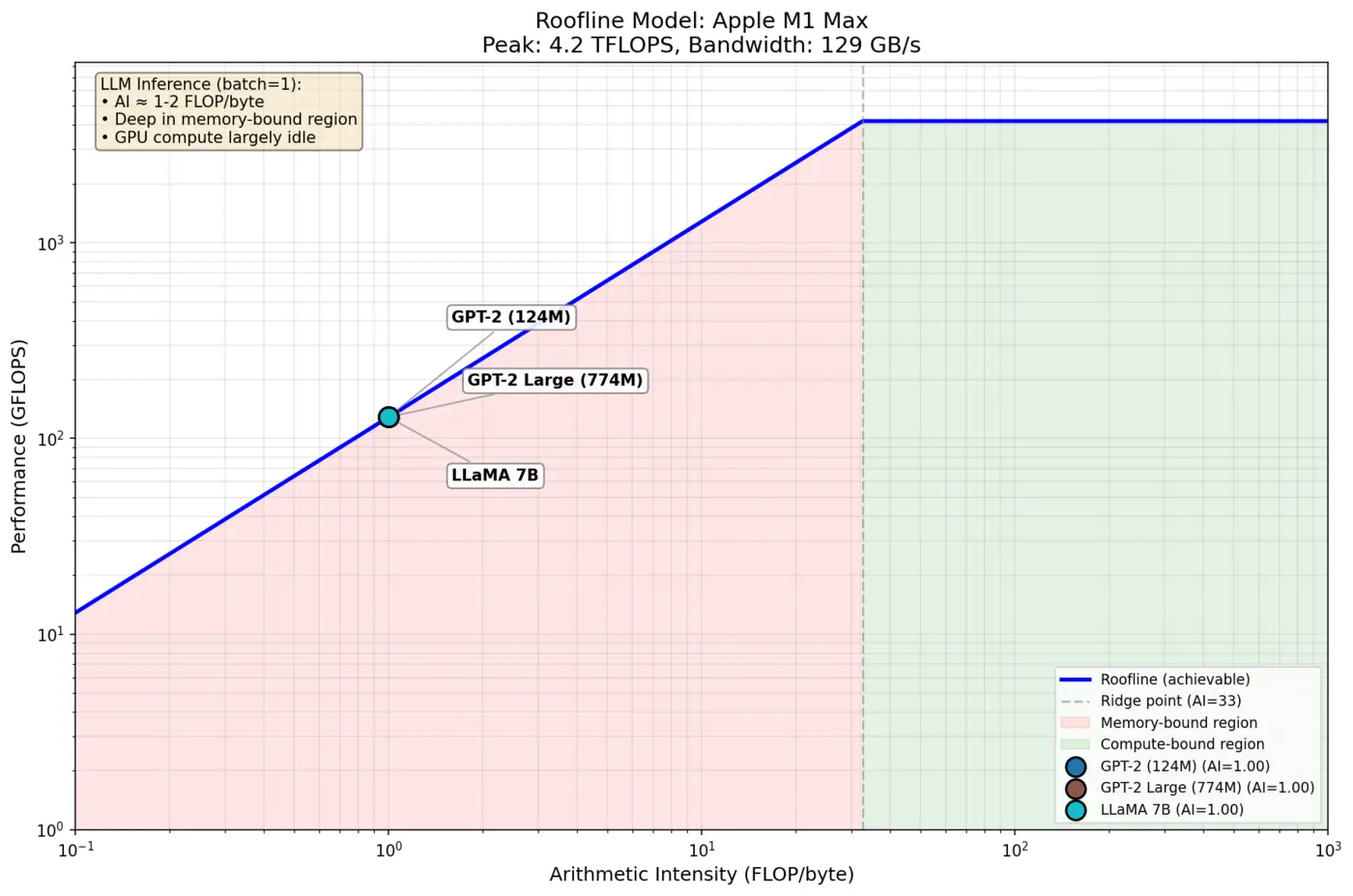
图 19-4:Roofline 模型下的 LLM 推理。解码阶段的算术强度极低,性能完全受限于内存带宽,GPU 的计算峰值无法发挥。
这意味着一个关键的不对称性:生成一个 Token 很慢(受访存限制),但验证一批 Token 很快(可以并行计算,类似 Prefill)。投机采样正是利用了这种不对称性:用一个参数量小、推理速度快的草稿模型(Draft Model)
19.4.2 两阶段算法:草稿生成与并行验证
设目标大模型的条件概率分布为
阶段一:草稿生成。 给定当前已生成的前缀序列,草稿模型
阶段二:并行验证。 将前缀序列与
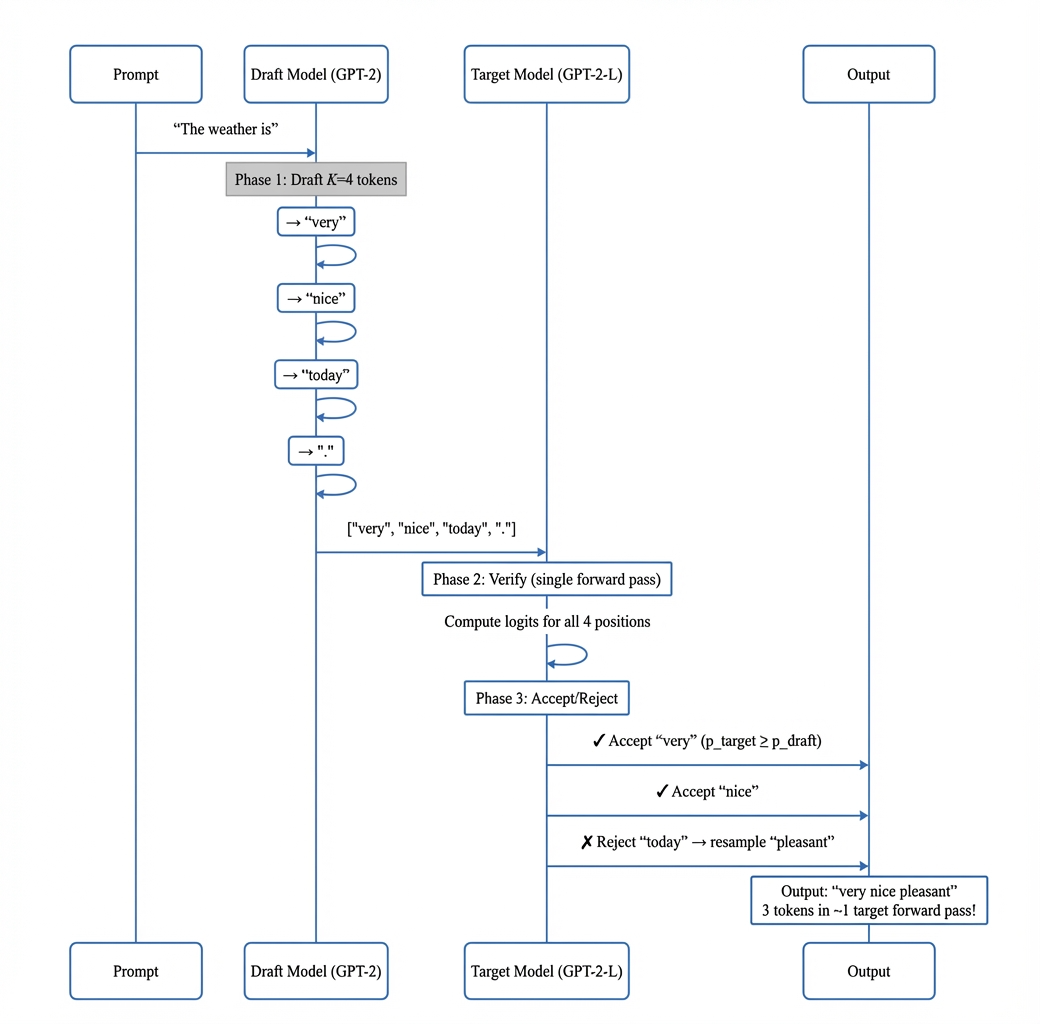
图 19-5:投机采样的两阶段流程。草稿模型生成 4 个候选 Token,目标模型一次前向传播验证所有位置,接受前两个、拒绝第三个并从修正分布中重采样。
拿到目标模型的概率分布后,算法从左到右逐个检查候选 Token
- 若接受:保留
,继续检查 。 - 若拒绝:丢弃
及其后所有候选,从修正分布中重采样一个 Token 替换 ,本轮结束。 - 若全部接受:额外从大模型在位置
的分布中采样一个新 Token,本轮共生成 个有效 Token。
下图展示了一个实际运行的示例:大模型验证了 9 次就生成了 37 个 Token——因为每次验证都一次性确认了多个由小模型生成的候选。

图 19-6:Token 级别的接受与拒绝。绿色 Token 由草稿模型生成并被大模型接受,红色/蓝色 Token 被拒绝后由大模型重采样替换。
19.4.3 无损生成的数学证明 [必读]
投机采样最精妙之处在于:它在数学上严格保证最终输出的 Token 分布与单独运行大模型
拒绝采样准则。 对于草稿模型采样得到的候选 Token
这意味着:
- 当
时(大模型认为该 Token 至少和草稿模型一样好),无条件接受。 - 当
时(草稿模型"过度自信"),以概率 接受,以概率 拒绝。
修正重采样分布。 当 Token 被拒绝时,需要从一个残差分布
为什么这保证了无损? 我们来严格证明:对于词表中任意 Token
总概率由两条路径贡献:
路径一(直接接受): 草稿模型采样到
路径二(拒绝后重采样到
从修正分布重采样到
注意到一个关键等式:
两条路径相加:
最后一步成立是因为:
直觉总结: 总采样概率可以看作两个区域的叠加——
与 重叠的部分( ,由接受路径贡献)加上 超出 的残差部分( ,由重采样路径贡献),二者恰好拼合成完整的 。
具体数值示例。 为了让证明更加直观,我们用一个只有两个 Token
- 草稿模型分布:
- 目标模型分布:
草稿模型对
计算采样
- 路径一:草稿采样到
(概率 0.8),接受概率 。贡献 = 。 - 路径二:草稿采样到
(概率 0.2),接受概率 ,不会拒绝,所以路径二不会给 贡献重采样概率。 - 总概率
。
计算采样
- 路径一:草稿采样到
(概率 0.2),接受概率 。贡献 = 。 - 路径二:草稿采样到
(概率 0.8),拒绝概率 。修正分布 (因为 ,只有 有残差)。贡献 = 。 - 总概率
。
结果完美还原了目标分布
19.4.4 效率分析:接受率与加速比
投机采样的加速效果由两个核心参数决定:前瞻步数
接受率的定义。 在草稿模型的分布下,每个候选 Token 被大模型接受的期望概率为:
每轮期望生成的有效 Token 数。 在一轮投机迭代中(草稿模型生成
推导过程。 设
- 恰好前
个被接受、第 个被拒绝的概率为 ( )。 - 全部
个候选都被接受的概率为 。
无论哪种情况,一轮至少产出一个 Token(要么接受的候选、要么拒绝后重采样的 Token、要么全部接受后的 bonus Token)。因此期望有效 Token 数为:
最后的化简利用了几何级数求和公式
| 场景 | 期望有效 Token 数 | 含义 | ||
|---|---|---|---|---|
| 理想情况 | 5 | 草稿模型几乎完美,一轮生成 | ||
| 良好匹配 | 0.7 | 5 | 2.94 | 典型的同系列大小模型组合 |
| 匹配较差 | 0.3 | 5 | 1.40 | 草稿模型太弱,加速有限 |
| 最差情况 | 5 | 退化为标准自回归,还额外浪费了草稿模型的计算 |
表 19-3:不同接受率下的期望有效 Token 数。
加速比分析。 设大模型一次前向传播的延迟为
当
一个具体的数值示例。 假设使用 Qwen3-0.6B(
- 标准自回归生成 50 个 Token 需要:
- 每轮投机采样耗时:
- 每轮期望有效 Token 数:
- 生成 50 个 Token 约需
轮 - 总耗时:
- 加速比约
如果接受率提升到
19.4.5 贪婪模式 vs 采样模式
一个重要的实践发现:贪婪解码(Greedy Decoding)下的投机采样比随机采样模式更快。
- 贪婪模式:大模型和草稿模型都取
。只要两者预测的最高概率 Token 一致就接受。对于常见的下一个词,两个模型的 往往相同,接受率很高。 - 随机采样模式:即使两个模型的概率分布几乎相同,随机抽样也可能碰巧抽到不同的 Token,导致本不该拒绝的候选被拒绝,接受率显著下降。
实验数据表明,在某些任务上贪婪模式可以带来约 1.1x 的额外加速,而随机采样模式可能反而比标准自回归还慢(约 0.85x),原因是随机性导致大量无谓的拒绝,同时还多付出了草稿模型的计算开销。
直觉上可以这样理解:在贪婪模式下,接受条件简化为"大小模型的
19.4.6 工程实践要点
KV Cache 回滚。 当大模型拒绝了第
草稿模型的选择。 理想的草稿模型应满足两个条件:(1)推理速度远快于目标模型,通常参数量为目标模型的 1/10 到 1/5;(2)与目标模型的分布尽量一致,通常选择同系列的小规模版本效果最佳(如用 Qwen3-0.6B 配合 Qwen3-4B,或用 Llama-1B 配合 Llama-70B)。
前瞻步数
自草稿(Self-Drafting)变体。 除了使用独立的小模型作为草稿器,近年来还出现了不依赖外部草稿模型的方案:Medusa 为目标模型额外训练多个预测头,每个头独立预测未来第
19.4.7 完整实现:投机采样代码
下面给出一个自包含的投机采样实现,包含草稿生成、拒绝采样、修正分布重采样的完整逻辑。
import torch
import torch.nn.functional as F
from typing import Tuple
def speculative_decode(
target_model, # 目标大模型(callable, 输入 token ids -> logits)
draft_model, # 草稿小模型(callable, 输入 token ids -> logits)
prefix: torch.Tensor, # 初始前缀序列, shape: (seq_len,)
gamma: int = 5, # 每轮草稿生成的候选 Token 数
max_tokens: int = 50, # 最大生成 Token 数
temperature: float = 1.0,
) -> Tuple[torch.Tensor, dict]:
"""
投机采样生成算法。
保证输出分布与单独使用 target_model 完全一致(无损)。
"""
generated = prefix.clone()
stats = {"total_draft": 0, "total_accepted": 0, "num_rounds": 0}
while generated.shape[0] - prefix.shape[0] < max_tokens:
# ========== 阶段一:草稿模型串行生成 γ 个候选 ==========
draft_tokens = []
draft_probs = []
current = generated.clone()
for _ in range(gamma):
with torch.no_grad():
logits = draft_model(current.unsqueeze(0)) # (1, seq_len, vocab)
logits_last = logits[0, -1, :] / temperature
prob_q = F.softmax(logits_last, dim=-1)
# 从草稿分布中采样
token = torch.multinomial(prob_q, num_samples=1) # (1,)
draft_tokens.append(token.item())
draft_probs.append(prob_q)
current = torch.cat([current, token])
stats["total_draft"] += gamma
# ========== 阶段二:目标模型一次前向并行验证 ==========
verify_input = current.unsqueeze(0) # prefix + γ 个候选
with torch.no_grad():
target_logits = target_model(verify_input) # (1, seq_len+γ, vocab)
# ========== 阶段三:逐个拒绝采样 ==========
n_accepted = 0
for i in range(gamma):
pos = generated.shape[0] + i - 1 # 对应目标 logits 的位置
p_logits = target_logits[0, pos, :] / temperature
p = F.softmax(p_logits, dim=-1)
q = draft_probs[i]
x = draft_tokens[i]
# 接受概率: min(1, p(x)/q(x))
p_x = p[x].item()
q_x = q[x].item()
accept_prob = min(1.0, p_x / max(q_x, 1e-10))
if torch.rand(1).item() < accept_prob:
# 接受该候选 Token
generated = torch.cat([generated, torch.tensor([x], device=generated.device)])
n_accepted += 1
else:
# 拒绝:从修正分布 p'(x) = norm(max(0, p-q)) 中重采样
residual = torch.clamp(p - q, min=0)
residual_sum = residual.sum()
if residual_sum > 1e-10:
p_prime = residual / residual_sum
else:
p_prime = p # 退化为直接使用目标分布
new_token = torch.multinomial(p_prime, num_samples=1)
generated = torch.cat([generated, new_token.to(generated.device)])
break
else:
# 所有 γ 个候选均被接受,从大模型最后一个位置再采样一个
bonus_logits = target_logits[0, -1, :] / temperature
bonus_prob = F.softmax(bonus_logits, dim=-1)
bonus_token = torch.multinomial(bonus_prob, num_samples=1)
generated = torch.cat([generated, bonus_token.to(generated.device)])
n_accepted += 1 # 计入 bonus token
stats["total_accepted"] += n_accepted
stats["num_rounds"] += 1
# 截断到目标长度
generated = generated[: prefix.shape[0] + max_tokens]
stats["acceptance_rate"] = stats["total_accepted"] / max(stats["total_draft"], 1)
return generated, stats代码关键点解读:
- 草稿生成循环:逐步调用草稿模型生成
个 Token,同时保存每一步的概率分布 ,供后续验证使用。 - 目标模型并行验证:将完整序列(前缀 +
个候选)一次性输入目标模型,利用因果注意力掩码,一次前向传播获得所有位置的概率分布 。 - 拒绝采样:按照
的接受概率逐个检查候选 Token。一旦拒绝,立即从修正分布 中重采样并终止本轮。 - 全部接受的 bonus:若
个候选全部通过验证,目标模型在最后一个位置的输出可以额外提供一个"免费"Token。 torch.clamp(p - q, min=0)实现了的向量化计算,避免逐元素循环。
19.4.8 小结
本节介绍了投机采样(Speculative Decoding)的完整理论与实践。回顾要点如下:
| 要素 | 核心内容 |
|---|---|
| 动机 | 自回归推理受限于内存带宽而非计算能力,GPU 大部分时间在等待数据搬运 |
| 方法 | 小模型 |
| 无损保证 | 拒绝采样 + 修正分布 |
| 效率 | 接受率 |
| 实践 | 贪婪模式优于随机采样; |
投机采样的核心洞察是利用**"生成慢、验证快"** 的不对称性——这一思想不仅限于大小模型配对,也催生了 Medusa、EAGLE 等自草稿变体,以及与 MTP(Multi-Token Prediction)训练头结合的方案。理解了本节的数学原理,读者可以更深入地评估和选择适合自身场景的推理加速策略。