8.5 大模型参数设计
大语言模型的参数配置——隐层维度、注意力头数、层数、FFN 中间维度——看似只是几个数字的选择,实际上蕴含着模型容量、训练效率与硬件利用率之间的深层博弈。一组好的超参数配置不仅决定了模型的表达能力上限,还直接影响训练吞吐量和推理延迟。本节系统梳理主流大模型的参数配置规律,提炼设计原则,并讨论那些常被忽视却至关重要的工程约束。
8.5.1 主流模型参数配置一览
在讨论设计原则之前,先通过一张全景表格建立直观认知。下表收录了从 GPT-3 到 Qwen3 的代表性模型,涵盖不同参数量级和架构选择:
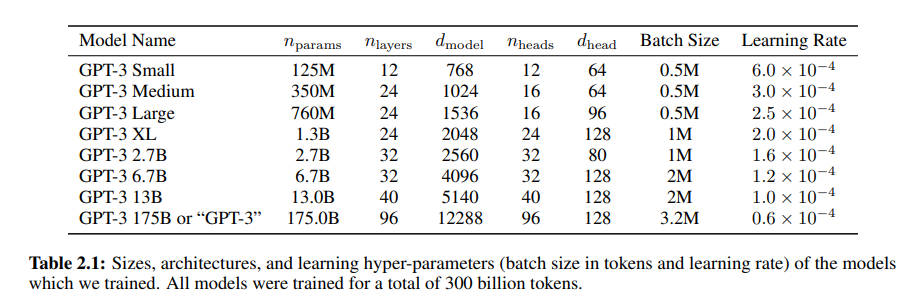
图 8-10:GPT-3 论文(Brown et al., 2020)中的模型参数配置表。从 125M 到 175B,展示了
| 模型 | 总参数量 | FFN 中间维度 | ||||||
|---|---|---|---|---|---|---|---|---|
| GPT-3 Small | 125M | 768 | 12 | 12 | 12 | 64 | 3072 | 64 |
| GPT-3 Medium | 350M | 1024 | 24 | 16 | 16 | 64 | 4096 | 43 |
| GPT-3 Large | 760M | 1536 | 24 | 16 | 16 | 96 | 6144 | 64 |
| GPT-3 XL | 1.3B | 2048 | 24 | 32 | 32 | 64 | 8192 | 85 |
| GPT-3 | 175B | 12288 | 96 | 96 | 96 | 128 | 49152 | 128 |
| Llama 3.1 8B | 8B | 4096 | 32 | 32 | 8 | 128 | 14336 | 128 |
| Llama 3.2 1B | 1B | 2048 | 16 | 32 | 8 | 64 | 8192 | 128 |
| Llama 3.1 70B | 70B | 8192 | 80 | 64 | 8 | 128 | 28672 | 102 |
| Llama 3.1 405B | 405B | 16384 | 126 | 128 | 8 | 128 | 53248 | 130 |
| Qwen3 0.6B | 0.6B | 1024 | 28 | 16 | 8 | 128 | 3072 | 37 |
| Qwen3 8B | 8B | 4096 | 36 | 32 | 8 | 128 | 12288 | 114 |
| OLMo 3 7B | 7B | 4096 | 32 | 32 | 32 | 128 | 11008 | 128 |
| OLMo 3 32B | 32B | 5120 | 64 | 40 | 8 | 128 | 27648 | 80 |
| MiniMind2-Small | 26M | 512 | 8 | 8 | 2 | 64 | ~1365 | 64 |
| MiniMind2 | 104M | 768 | 16 | 8 | 2 | 96 | 2048 | 48 |
表 8-8:主流大语言模型参数配置对比。
从这张表中可以提炼出若干高度一致的设计模式,下面分别展开。
8.5.2 核心超参数的设计原则
一、隐层维度
- 7B~8B 级别的模型几乎都选择
。Llama 3.1 8B、Qwen3 8B、OLMo 3 7B 均如此,这已成为该量级的事实标准。 的增长速度慢于参数量的增长。从 8B 到 70B,参数量增长约 9 倍,但 仅从 4096 增长到 8192(2 倍)。差距主要由层数吸收。 - 小模型存在
的最低阈值。当 时,每个注意力头分到的维度 过小,导致注意力机制的区分能力严重退化,增加层数也无法弥补这一底层表征瓶颈。MiniMind 的实践印证了这一点:小模型的 下限约为 512。
二、层数
层数决定了模型构建多层次抽象表示的能力。每增加一层,模型就多一次对信息进行非线性变换和重组的机会。
- 主流大模型的层数范围在 32~128 之间。8B 级别通常为 32~36 层,70B 级别为 64~80 层,405B 则达到 126 层。
- 在小模型(< 1B)中,深度优先于宽度。MobileLLM 的系统实验表明,当参数量固定在 125M 或 350M 时,30~42 层的"狭长"模型在常识推理、问答等 8 项基准上均显著优于 12 层的"矮胖"模型。这一发现突破了传统认知——以往为 100M 量级的小模型设计架构时,几乎没人尝试过叠加超过 12 层。
- 但"深而窄"的窄也有极限。当
时,增加的层数无法弥补嵌入维度坍塌带来的劣势;当 时,继续增加层数的优先级才明显高于增加宽度。
三、注意力头数与头维度:
多头注意力的经典约束是
已成为主流大模型的标准。Llama 3 全系列、Qwen3 全系列、OLMo 3 均采用此设置。128 维的注意力头提供了足够的表征空间,同时恰好是 GPU Tensor Core 友好的尺寸。 是小模型和早期模型的常见选择。GPT-3 系列大部分变体和 MiniMind2-Small 均采用 。 - Qwen3 打破了严格的
等式。例如 Qwen3 0.6B 的 , , ,Q 投影的输出维度为 ,是 的两倍。这种"解耦 head_dim"的做法允许在不增加 的前提下提升注意力的表达能力,但代价是 Q 投影参数量翻倍。
四、FFN 中间维度:
前馈网络(FFN)是 Transformer 中参数量占比最大的组件。FFN 中间维度
- 对于使用 ReLU/GELU 的非门控 FFN,
是经典比例。GPT-3 全系列严格遵循这一比例(如 对应 )。 - 对于使用 SwiGLU 的门控 FFN,
。SwiGLU 引入了第三个线性层(门控投影),参数量变为标准 FFN 的 1.5 倍。为保持总参数量大致不变,将 缩减至 倍。MiniMind 和 Llama 系列均遵循此原则。 - 实际工程中存在偏差。Llama 3.1 8B 的
,与 的比值为 3.5,高于理论的 2.67。OLMo 3 32B 的比值更是高达 5.4。这些偏差通常源于参数预算对齐(如要达到特定的总参数量级别)或硬件效率考量。
8.5.3 宽深比:Aspect Ratio 的设计考量
宽深比(Aspect Ratio)定义为
经验黄金区间:100~200。 CS336 课程基于 Kaplan et al.(2020)的 Scaling Law 研究指出,
但小模型需要更低的比值。 MobileLLM 和 MiniMind 的实践表明,在数亿参数量级下,传统的 Scaling Law 对架构形状的"不敏感"结论不再成立。Qwen3 0.6B 的比值仅为 37(
宽深比影响并行策略选择。
- 比值较高(矮胖):参数集中在每层的矩阵乘法中,天然适合张量并行(Tensor Parallelism)——将每层的大矩阵切分到多张 GPU 上。但层数较少意味着流水线并行的段数有限,调度灵活性受限。
- 比值较低(瘦长):层数较多,有利于流水线并行(Pipeline Parallelism)——将不同层分配到不同设备上。但推理延迟与层数成正比(每层的计算必须串行完成),过深的模型会导致生成延迟增大。
因此,宽深比的选择需要在模型能力(深度带来的抽象层次)和系统效率(并行策略、推理延迟)之间找到平衡。
8.5.4 工程约束:64 对齐与硬件适配
超参数配置不仅要满足模型能力的需求,还必须适配底层硬件的计算特性。现代 GPU 的 Tensor Core 以固定大小的矩阵块(tile)为单位进行计算,如果矩阵维度不是 tile 大小的整数倍,硬件要么需要填充(padding)浪费算力,要么无法触发 Tensor Core 加速而回退到低效的 CUDA Core 计算。
一、维度对齐到 64 的倍数
这是最普遍的工程约束。观察表 8-8 中所有模型的
NVIDIA GPU 的 Tensor Core 在执行矩阵乘法时,要求矩阵维度对齐到特定粒度:
| 数值精度 | 最小 tile 尺寸 | 推荐对齐粒度 |
|---|---|---|
| FP32 | 8 × 8 | 8 的倍数 |
| FP16 / BF16 | 16 × 16 | 64 的倍数 |
| INT8 | 32 × 32 | 64 或 128 的倍数 |
当前大模型训练普遍使用 BF16 混合精度,因此 64 的倍数是最基本的对齐要求。更保守的选择是对齐到 128 或 256,以在多级缓存和多 SM(Streaming Multiprocessor)调度中获得更均匀的负载分布。
二、FFN 中间维度的自动对齐
在 SwiGLU FFN 中,
以
这一对齐操作的性能影响不容忽视。实测表明,一个维度为 1365 的矩阵乘法与维度为 1408 的矩阵乘法相比,后者虽然多算了约 3% 的元素,但由于 Tensor Core 利用率从约 85% 提升到接近 100%,实际耗时反而更短。
三、词表大小的对齐
同样的逻辑也适用于词表维度。输出投影层(LM Head)的权重矩阵形状为
- Llama 3 将词表大小设为 128,256(
,同时是 64 的倍数)。 - Qwen3 的词表大小为 151,936(
)。 - MiniMind 的词表为 6,400(
)。
对于词表大小不满足对齐要求的模型,常见的补救措施是在词表末尾填充(pad)若干从不使用的 dummy token,使总维度对齐到 64 的倍数。这一操作在训练速度优化中可带来 10~30% 的额外加速。
四、注意力头数的约束
必须能被张量并行度整除。若使用 8 卡并行,则 应为 8 的倍数。 (GQA 中的 KV 头数)同样必须能被张量并行度整除,否则 KV 缓存无法均匀切分。
这解释了为什么 Llama 3.1 所有规模的
8.5.5 从经验法则到系统化设计
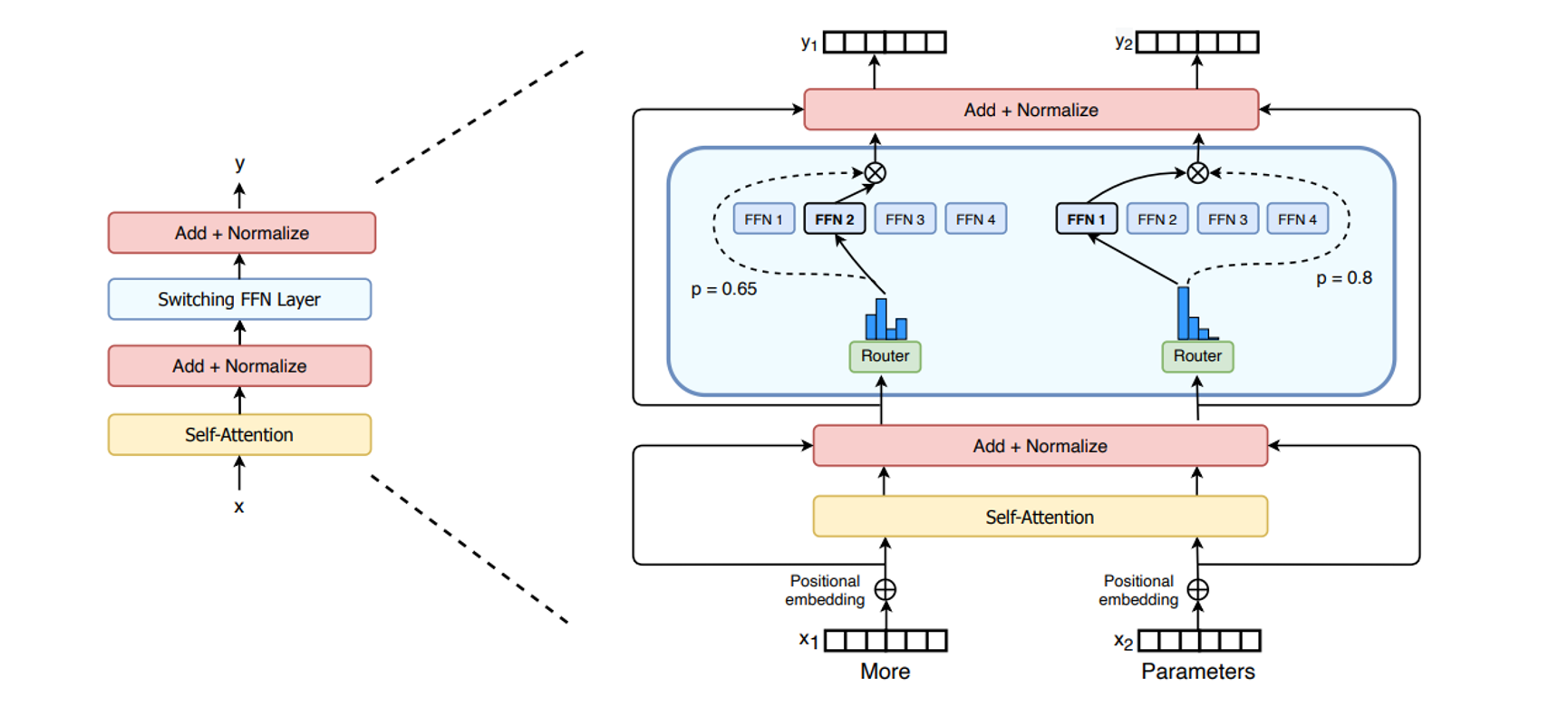
图 8-11:MoE 架构与稠密模型的对比示意。MoE 通过路由器将不同 token 分配给不同专家(Switching FFN Layer),在不增加推理计算量的前提下大幅扩展模型总参数。这种稀疏激活策略是 8.1 节所述 DeepSeek V3 等模型能够突破万亿参数的关键,也直接影响了参数设计中 FFN 层规模的选择。
将上述设计原则和工程约束综合起来,可以归纳出一套系统化的参数配置流程:
第一步:确定参数预算。 根据训练算力、推理成本和目标性能确定总参数量
第二步:选择
为 128 的倍数(更严格地,为目标张量并行度 的倍数)。 - 大模型的
落在 100~200 区间;小模型可以降低至 40~80 以换取更深的架构。 - 粗估公式:Transformer 每层的参数量约为
(注意力层 + SwiGLU FFN ),总参数约 (不含嵌入层)。
第三步:设定注意力头配置。 在
- 选择
(128 为首选,小模型可降至 64)。 (或在解耦设计中独立设定)。 根据 GQA 组数选择,须同时满足整除 和张量并行度的约束。
第四步:计算 FFN 中间维度。 对于 SwiGLU,先按
第五步:对齐检查。 逐一验证
8.5.6 总结
大模型参数设计是经验法则与硬件约束共同塑造的工程艺术。本节的核心要点如下:
FFN 扩展比:非门控 FFN 使用
,SwiGLU 门控 FFN 使用 ,是在参数量等价条件下的自然推导结果。 宽深比 100~200:这是大模型性能-效率甜点区的经验共识(GPT-3、Llama 3 均落在此区间)。但小模型应主动降低宽深比(至 40~80),选择"深而窄"的架构以获取更好的抽象能力。
是当代标准:从 Llama 3 到 Qwen3,几乎所有主流模型都采用 128 维的注意力头。Qwen3 进一步解耦了 与 的等式关系,为小模型提供了更灵活的设计空间。 64 对齐是底线:
、 、词表大小必须对齐到 64 的倍数(BF16 训练下的 Tensor Core 最小粒度要求)。不满足此约束的维度将导致 GPU 利用率大幅下降,宁可多算 3% 的冗余元素也不要浪费 15% 的硬件算力。 并行度决定头数下界:
和 必须能被目标张量并行度整除,这是分布式训练对超参数的硬性约束。
参数配置没有唯一正确答案,但有大量"明显错误"的选项。遵循上述原则可以规避绝大多数陷阱,将设计空间从无限可能缩减到少数几个合理候选,剩余的微调则交给小规模实验验证。