21.1 智能体基础与形式化框架
"The real question is not whether machines can think, but whether machines can act." —— 改编自 Alan Turing
在前面的章节中,我们已经建立了一套完整的大语言模型知识体系:从 Transformer 架构(第3章)到对齐训练(第15-16章),再到推理时间缩放(第17章)和模型评估(第20章)。但一个仅仅能"回答问题"的模型,距离真正的智能还有多远?ChatGPT 可以生成代码片段,但它无法自主运行代码、查看报错、修复 bug、再次运行——这一系列闭环操作恰恰是人类程序员每天都在做的事情。智能体(Agent) 正是为了弥合这一鸿沟而诞生的概念:它不仅能"想",还能"做";不仅能生成文本,还能感知环境、调用工具、执行动作、从反馈中学习。
本节的学习目标如下:(1)理解智能体的形式化定义,将其置于 MDP/POMDP 的经典框架中;(2)掌握感知-规划-动作-反馈-记忆的核心循环;(3)深入理解 ReAct 框架及工具调用协议;(4)认识智能体系统的典型失败模式;(5)建立评估智能体性能的多维指标体系。
21.1.1 什么是智能体
智能体这个词可以直译为"具有智慧的个体"。与传统的 chatbot 相比,智能体的核心区别在于它具备自主行动的能力——它不仅仅等待用户输入然后输出回复,而是能够主动地与环境交互,通过一系列动作来达成某个目标。

图 21-1:智能体的四个核心要素。感知(Perceive)获取环境信息,推理/规划(Reason/Plan)处理信息并制定策略,动作(Act)改变环境状态,记忆(Memory)记录信息以服务后续决策。
一个智能体通常涉及四个关键词:
- 感知(Perception):观测并获取环境信息。对于游戏智能体,这可能是棋盘状态或屏幕画面;对于编码智能体,这可能是代码文件内容和终端输出。
- 推理/规划(Reasoning / Planning):处理获取的信息,为达成目标策划行动方案。这是大语言模型最擅长的环节。
- 动作(Action):做出能够改变环境的行为。落一颗棋子、执行一条 shell 命令、调用一个 API,都是动作。
- 记忆(Memory):记录环境信息和历史经验,服务于上述各项能力。
这些概念抽象且普适。事实上,从 AlphaGo 下围棋到 Claude Code 写代码,从 OpenAI Five 打 Dota2 到医疗诊断系统,都可以用这四个要素来描述。
21.1.2 形式化定义:MDP 与 POMDP
智能体与环境交互的过程可以用马尔可夫决策过程(Markov Decision Process, MDP) 来形式化描述。在第15章强化学习基础中,我们已经接触过 MDP 的定义。这里我们将其与 LLM 智能体的实际场景对应起来。
MDP 的五元组定义:
各分量的含义如下:
| 符号 | 名称 | 通用定义 | LLM 智能体实例化 |
|---|---|---|---|
| 状态空间(State Space) | 环境可能处于的所有状态的集合 | 当前上下文窗口中的全部 token 序列(包括系统提示、对话历史、工具返回结果等) | |
| 动作空间(Action Space) | 智能体可以执行的所有动作的集合 | 生成的文本 token 序列——可能是自然语言回复、函数调用指令、代码片段等 | |
| 转移函数(Transition Function) | 工具执行结果 + 环境变化:例如运行代码后的终端输出、API 返回的 JSON 数据 | ||
| 奖励函数(Reward Function) | 任务是否完成、单元测试是否通过、用户是否满意等信号 | ||
| 折扣因子(Discount Factor) | 越远的步骤对当前决策的影响越小 |
在时刻
对于 LLM 智能体而言,策略
从 MDP 到 POMDP:部分可观测的现实世界
MDP 假设智能体能够完全观测到环境状态,但现实中这一假设很少成立。以围棋为例,棋盘上所有棋子的位置是完全可见的,所以围棋可以建模为 MDP。但在大多数真实场景中,智能体只能获得环境的部分观测:
- 编码智能体只能看到当前打开的文件,而不是整个代码仓库的所有文件;
- 网页浏览智能体只能看到当前页面,而不是整个互联网的状态;
- 医疗诊断智能体只能看到患者主诉和部分检查结果,而不是患者身体的完整状态。
这时我们需要部分可观测马尔可夫决策过程(Partially Observable MDP, POMDP),它在 MDP 的基础上增加了两个要素:
其中
对于 LLM 智能体,POMDP 框架非常自然:
智能体需要通过主动探索(如搜索文件、浏览网页)来缩小信息差距,这也解释了为什么好的智能体需要具备主动信息获取的能力。
下面用一段 Python 代码来具体展示 MDP 框架下智能体与环境交互的基本结构:
from dataclasses import dataclass
from typing import Any
@dataclass
class State:
"""智能体的状态表示"""
context: list[dict] # 对话历史(观测)
tool_results: list[str] # 工具返回结果
step_count: int # 当前步数
task_completed: bool # 任务是否完成
class SimpleAgentLoop:
"""最简化的智能体 MDP 交互循环"""
def __init__(self, llm_call, tools: dict, max_steps: int = 20):
self.llm_call = llm_call # 策略 π:LLM 生成函数
self.tools = tools # 动作空间的一部分:可用工具
self.max_steps = max_steps # 防止无限循环的上限
def run(self, task: str) -> str:
# 初始化状态 s_0
state = State(
context=[{"role": "user", "content": task}],
tool_results=[],
step_count=0,
task_completed=False,
)
while not state.task_completed and state.step_count < self.max_steps:
# 策略 π(a_t | s_t):LLM 根据当前状态生成动作
action = self.llm_call(state.context)
if action["type"] == "tool_call":
# 转移函数 T(s_{t+1} | s_t, a_t):执行工具,环境发生变化
tool_name = action["name"]
tool_args = action["arguments"]
result = self.tools[tool_name](**tool_args)
# 奖励信号 R(s_t, a_t):简化为任务完成检测
state.context.append({"role": "assistant", "content": str(action)})
state.context.append({"role": "tool", "content": result})
state.tool_results.append(result)
elif action["type"] == "final_answer":
state.task_completed = True
return action["content"]
state.step_count += 1
return "任务未在规定步数内完成"这段代码虽然简单,但已经包含了 MDP 的全部要素:状态 State 在每一步被更新,策略 llm_call 根据状态选择动作,工具执行充当转移函数改变环境,任务完成检测充当奖励信号。
21.1.3 核心循环:感知-规划-动作-反馈-记忆
理解了形式化定义之后,我们来看智能体在实际运行中的核心循环。每一轮迭代都包含五个阶段:
┌──────────────────────────────────────────────────┐
│ 智能体核心循环 │
│ │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ 感知 │───▶│ 规划 │───▶│ 动作 │ │
│ │Perceive│ │ Plan │ │ Act │ │
│ └────────┘ └────────┘ └───┬────┘ │
│ ▲ │ │
│ │ ┌────────┐ ┌────▼────┐ │
│ └──────│ 记忆 │◀───│ 反馈 │ │
│ │ Memory │ │Feedback│ │
│ └────────┘ └────────┘ │
└──────────────────────────────────────────────────┘1. 感知(Perceive):智能体从环境中获取当前观测。对于 LLM 智能体,这意味着将相关信息注入到上下文窗口中。信息来源可能包括:用户指令、文件内容、终端输出、网页数据、数据库查询结果等。感知的质量直接决定了后续决策的质量——如果关键信息未被纳入上下文,模型再强也无从发挥。
2. 规划(Plan):基于感知到的信息,智能体进行推理并制定行动计划。这是 LLM 的核心能力所在。规划可以是隐式的(模型直接输出下一步动作),也可以是显式的(模型先输出思维链再决定动作,即 ReAct 模式)。复杂任务中,智能体还需要将大目标分解为多个子目标——例如"修复这个 bug"可能被分解为"阅读报错信息 → 定位相关代码 → 理解逻辑 → 编写修复 → 运行测试"。
3. 动作(Act):将规划转化为实际的环境操作。LLM 智能体的动作通常通过以下方式之一实现:
- 函数调用(Function Calling):模型输出结构化的 JSON 指令,系统解析后调用对应的 API;
- 代码执行(Code Execution):模型生成 Python/Shell 代码,由沙盒环境执行;
- 文本输出:模型直接生成自然语言回复返回给用户。
4. 反馈(Feedback):环境对动作的响应。工具调用的返回值、代码执行的标准输出和标准错误、用户的追加指令,都构成反馈信号。反馈可以是即时的(命令执行结果)或延迟的(任务最终是否成功)。
5. 记忆更新(Memory Update):将本轮的观测、动作和反馈整合到智能体的记忆系统中。最简单的记忆就是将所有对话追加到上下文窗口;更高级的方案包括结构化工作记忆、长期经验库、技能库等(详见 §21.7)。
以 Voyager 智能体为例,它在 Minecraft 游戏中的运行正是对这一循环的经典实现:
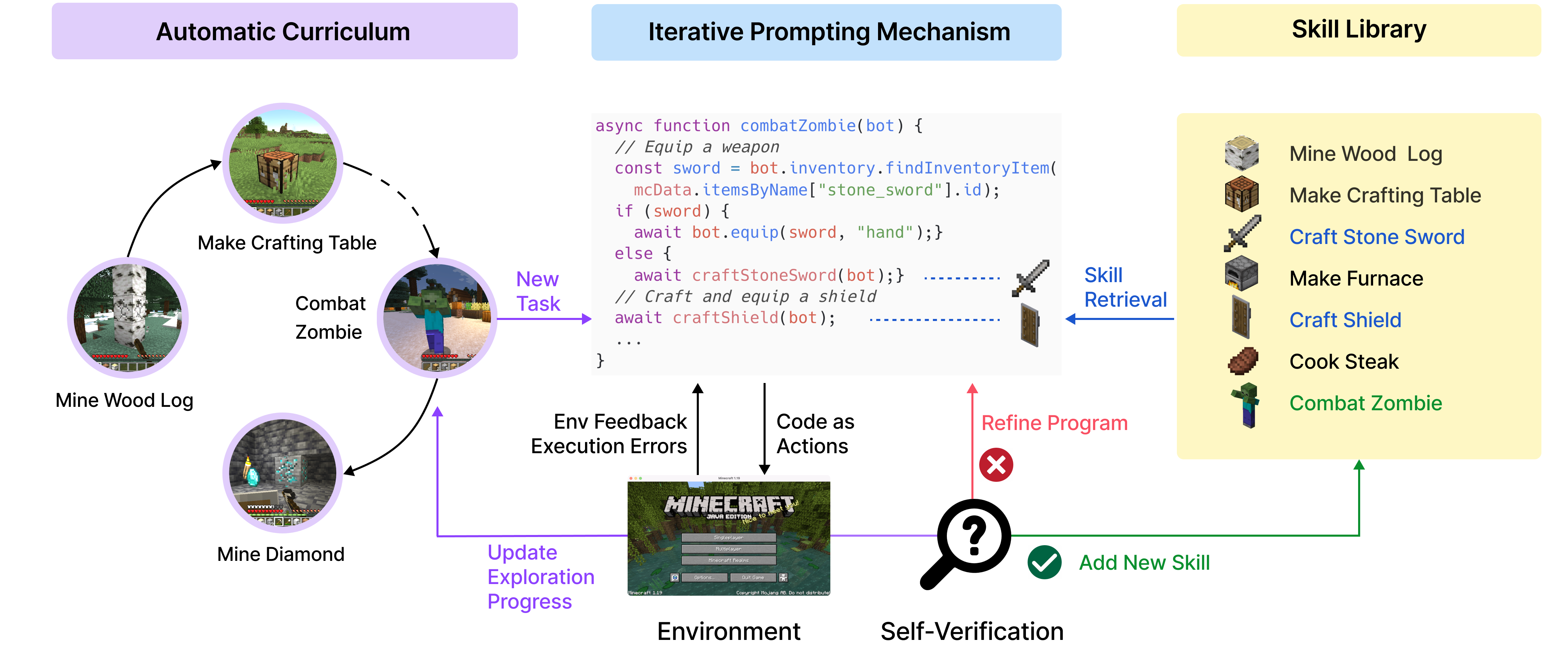
图 21-2:Voyager 智能体的核心架构。自动课程模块(Automatic Curriculum)负责规划下一步任务;迭代提示机制(Iterative Prompting)驱动代码生成;技能库(Skill Library)存储已验证的可复用技能;自我验证(Self-Verification)提供反馈信号。整个系统形成了感知-规划-动作-反馈-记忆的完整闭环。
Voyager 在每一轮迭代中会:(1)根据当前游戏进度和技能库,规划下一步要完成的任务;(2)从技能库中检索相关技能,组合生成新的 JavaScript 代码;(3)将代码提交给 Minecraft 后端执行;(4)获取执行反馈(成功/失败/报错);(5)如果成功,将新技能加入技能库;如果失败,根据错误信息修改代码后重试。
21.1.4 ReAct 框架:推理与动作的交替
在早期的 LLM 智能体中,研究者尝试过两种极端方案:一种是纯推理(Chain-of-Thought),模型只在内部进行推理而不与环境交互;另一种是纯动作(Act-only),模型直接输出工具调用而不解释理由。两种方案各有缺陷——纯推理无法获取外部信息,纯动作缺乏可解释性和规划能力。
ReAct(Reasoning + Acting) 框架(Yao et al., 2022)将这两种能力优雅地统一起来,通过推理(Thought)和动作(Action)的交替来驱动智能体。其核心思想极为简洁:
在每一步中,模型先生成一段思考(Thought),解释自己对当前局面的理解和下一步计划;然后生成一个动作(Action),调用工具或执行操作;最后接收观测(Observation),即工具返回的结果。这三者构成一个"轮次",多个轮次串联形成完整的任务执行链。
下面是一个 ReAct 风格的代码搜索示例:
用户:项目中 calculate_loss 函数在哪里被调用?
Thought 1: 我需要在代码仓库中搜索 calculate_loss 的调用位置。先用 grep
工具进行全局搜索。
Action 1: grep("calculate_loss", path="./src", recursive=True)
Observation 1:
src/train.py:45: loss = calculate_loss(logits, labels)
src/eval.py:32: val_loss = calculate_loss(predictions, targets)
src/utils.py:78: def calculate_loss(output, target, reduction="mean"):
Thought 2: 搜索结果显示 calculate_loss 定义在 src/utils.py:78,
在 src/train.py:45 和 src/eval.py:32 两处被调用。
我已经有了完整的答案。
Action 2: finish("calculate_loss 定义在 src/utils.py 第78行,
被 src/train.py 第45行和 src/eval.py 第32行调用。")ReAct 的关键优势在于:Thought 步骤为模型提供了"草稿纸",让它可以在采取行动之前进行显式推理。这不仅提升了决策质量,还让整个过程对人类可审查、可调试。
工具调用协议:Function Calling
ReAct 框架的工程实现依赖于工具调用协议。当前主流的实现方式是 Function Calling(函数调用),其标准流程如下:
import json
# 1. 定义工具的 JSON Schema(告诉模型有哪些工具可用)
tools = [
{
"type": "function",
"function": {
"name": "search_code",
"description": "在代码仓库中搜索指定模式的代码",
"parameters": {
"type": "object",
"properties": {
"pattern": {
"type": "string",
"description": "要搜索的正则表达式模式"
},
"file_type": {
"type": "string",
"description": "限定搜索的文件类型,如 'py', 'js'"
}
},
"required": ["pattern"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_shell",
"description": "在安全沙盒中执行 shell 命令",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "要执行的 shell 命令"
}
},
"required": ["command"]
}
}
}
]
# 2. 模型生成的工具调用(结构化 JSON 输出)
model_output = {
"role": "assistant",
"tool_calls": [
{
"id": "call_001",
"type": "function",
"function": {
"name": "search_code",
"arguments": json.dumps({
"pattern": "calculate_loss",
"file_type": "py"
})
}
}
]
}
# 3. 系统解析并执行工具调用,将结果返回给模型
tool_result = {
"role": "tool",
"tool_call_id": "call_001",
"content": "src/train.py:45: loss = calculate_loss(logits, labels)\n..."
}除了 Function Calling 之外,另一种常见的工具调用范式是代码执行(Code as Actions):模型直接生成可执行代码,由沙盒环境运行后返回结果。Voyager 智能体正是采用这种方式——模型生成 JavaScript 代码,由 Mineflayer API 在 Minecraft 中执行。这种方式的优势是动作空间几乎无限大(任何合法代码都是合法动作),劣势是安全风险更高、需要更严格的沙盒隔离。
21.1.5 典型失败模式
理解智能体的理想工作方式之后,我们更需要认识它在实践中为什么会失败。以下四种失败模式在当前的 LLM 智能体系统中最为常见,它们也是第21章后续各节(§21.6-§21.11)工程体系要解决的核心问题。
失败模式一:上下文衰退(Context Rot)
当智能体执行了大量工具调用后,返回的结果(shell 日志、代码片段、API 响应等)不断累积,上下文窗口被逐渐塞满。即便现代模型标称支持 128K 甚至 1M token 的上下文长度,在实际的智能体场景中,过长的上下文会导致严重的性能退化:
- 注意力稀释:Transformer 的自注意力机制复杂度为
,当上下文达到数十万 token 时,模型的注意力被海量的冗余信息摊薄,无法聚焦到真正关键的指令上。 - 格式遗忘:模型开始忘记 System Prompt 中规定的输出格式——比如突然不再输出结构化的 JSON 工具调用,而是输出纯文本。
- 重复错误:模型重复调用刚才已经报错的工具,陷入相同的错误循环。
- 训练分布偏差:预训练数据中的高质量文本大多是短文本,模型对超长距离的逻辑依赖处理能力先天不足。
上下文衰退是智能体系统中最本质的工程挑战之一。§21.6 将详细介绍上下文工程(Context Engineering) 的五大策略来应对这一问题。
失败模式二:工具幻觉(Tool Hallucination)
大语言模型的"幻觉"问题在智能体场景中以一种更危险的形式出现——工具幻觉:
- 虚构工具:模型调用系统中根本不存在的工具(例如编造一个
analyze_sentiment函数); - 参数臆造:模型知道工具存在,但对参数进行"瞎猜",填入不合法的值;
- 结果编造:在被告知"某些信息不可获取"后,模型仍然无视约束,编造出看似合理的工具返回结果。
工具幻觉的根源在于:LLM 的训练目标是"生成统计上最可能的下一个 token",而不是"只在确定时才输出"。在智能体场景中,这种倾向会被放大——模型倾向于"做点什么"而不是承认"我不知道"。应对策略包括严格的工具 Schema 校验、在 System Prompt 中显式赋予模型"说不"的权限,以及设计友好的错误返回信息引导模型重新决策。
失败模式三:异步 Rollout 陈旧性(Stale Rollout)
在第18.4节中我们讨论过异步 Rollout 的样本陈旧性问题。当智能体系统采用强化学习进行训练时,策略模型在不断更新,而异步 Rollout worker 可能仍在使用旧版本的策略收集数据。这导致训练信号与当前策略之间存在时间差,可能引起训练不稳定甚至发散。
在推理时(而非训练时),类似的陈旧性问题同样存在:当智能体基于过时的环境信息做出决策时(例如代码已经被其他开发者修改,但智能体的缓存中还是旧版本),就会产生决策失配。
失败模式四:长任务 Doom Loop
当智能体在长任务中连续遭遇失败时,容易陷入一种"死循环":反复尝试相同的策略(或微小变体),每次都失败,但由于上下文中积累了大量失败记录,模型的推理能力进一步退化,形成恶性循环。这种现象被称为 Doom Loop(厄运循环)。
Doom Loop 的典型表现:
- 智能体尝试方案 A 失败;
- 微调方案 A 为 A'(只改了参数,没有改变本质思路)再次失败;
- 再微调为 A'' 继续失败;
- 上下文中已经充满了 A/A'/A'' 的失败记录,模型的注意力被这些冗余信息淹没;
- 最终智能体既无法跳出既有思路,也无法正常响应新的指令。
应对 Doom Loop 的关键策略包括:设置步数上限(超时强制停止)、升级重试协议(第 2 次失败必须切换本质不同的方案)、上下文压缩(定期清理失败记录,保留关键教训),以及人类介入检查点(Human-in-the-loop)。这些工程策略将在 §21.11 中系统讨论。
下面用一段代码演示如何在智能体循环中加入 Doom Loop 防护:
class RobustAgentLoop:
"""带有 Doom Loop 防护的智能体循环"""
def __init__(self, llm_call, tools, max_steps=20, max_retries_per_approach=2):
self.llm_call = llm_call
self.tools = tools
self.max_steps = max_steps
self.max_retries = max_retries_per_approach
def run(self, task: str) -> str:
context = [{"role": "user", "content": task}]
consecutive_failures = 0
last_error = None
for step in range(self.max_steps):
action = self.llm_call(context)
if action["type"] == "tool_call":
try:
result = self.tools[action["name"]](**action["arguments"])
consecutive_failures = 0 # 成功则重置计数
context.append({"role": "tool", "content": result})
except Exception as e:
consecutive_failures += 1
error_msg = str(e)
if consecutive_failures >= self.max_retries:
# 强制要求切换方案
context.append({
"role": "system",
"content": (
f"警告:连续 {consecutive_failures} 次失败,"
f"错误模式:{error_msg}。"
"请停止微调当前方案,采用本质不同的策略。"
)
})
consecutive_failures = 0
context.append({"role": "tool", "content": f"错误:{error_msg}"})
elif action["type"] == "final_answer":
return action["content"]
return "任务超时:已达最大步数限制"21.1.6 评估维度
如何衡量一个智能体系统的优劣?与单纯评估语言模型不同,智能体评估需要关注更多维度。以下六个指标构成了一个全面的评估框架:
1. 成功率(Success Rate)
最直接的指标:给定一组任务,智能体成功完成的比例是多少?"成功"的定义需要针对具体场景明确界定——对于编码智能体,成功可能意味着所有单元测试通过;对于问答智能体,成功可能意味着答案与标准答案匹配。
2. 自主性(Autonomy)
模型是否会主动调用工具来解决问题,而不是被动等待用户输入?一个高自主性的智能体应该能够自行分解任务、确定信息需求、选择合适的工具,并在工具返回结果不理想时主动重试或切换策略。
3. 可扩展性(Scalability)
随着可用工具数量的增长,智能体的表现是否保持稳定?当工具从 5 个增加到 50 个,模型是否还能准确地选择正确的工具?工具过多时,模型可能陷入"选择困难",表现反而下降。这一维度直接关系到智能体系统的工程上限。
4. Prompt 鲁棒性(Prompt Sensitivity)
对用户指令进行同义词替换或微调表述后,系统的行为是否保持一致?例如,"搜索最新论文"和"查找最近的学术文章"应该触发相同的工具调用。Prompt 鲁棒性低的智能体在实际部署中极不可靠——用户不会总是使用"标准"的措辞。
5. 幻觉率(Hallucination Rate)
当明确告知智能体"某些信息不可获取"时,它是否仍然编造答案?这一指标直接衡量了智能体在不确定情况下的诚实度。一个好的智能体应该能够区分"我知道"和"我不知道",在后一种情况下主动寻求信息而不是凭空编造。
6. LLM 敏感性(LLM Sensitivity)
同一套智能体框架在更换底层大模型(如从 GPT-4o 切换到 Claude Sonnet,或从闭源切换到开源模型)后,表现是否稳定?高度依赖特定模型"脾性"的智能体系统抗风险能力较差。
以下代码展示了一个简易的智能体评估框架:
from dataclasses import dataclass
@dataclass
class EvalResult:
"""单个测试用例的评估结果"""
task_id: str
success: bool
steps_taken: int
tools_called: list[str]
hallucination_detected: bool
def evaluate_agent(agent, test_cases: list[dict]) -> dict:
"""
评估智能体的多维指标。
参数:
agent: 智能体实例
test_cases: 测试用例列表,每个包含 task, expected_output,
available_tools, rephrased_task 等字段
返回:
包含六个维度得分的字典
"""
results = []
for case in test_cases:
output = agent.run(case["task"])
result = EvalResult(
task_id=case["id"],
success=check_success(output, case["expected_output"]),
steps_taken=agent.last_step_count,
tools_called=agent.last_tools_used,
hallucination_detected=check_hallucination(output, case),
)
results.append(result)
# 成功率
success_rate = sum(r.success for r in results) / len(results)
# 自主性:衡量模型主动调用工具的比例
autonomy = sum(
len(r.tools_called) > 0 for r in results
) / len(results)
# 幻觉率
hallucination_rate = sum(
r.hallucination_detected for r in results
) / len(results)
return {
"success_rate": success_rate,
"autonomy": autonomy,
"hallucination_rate": hallucination_rate,
"avg_steps": sum(r.steps_taken for r in results) / len(results),
}
def check_success(output: str, expected: str) -> bool:
"""检查输出是否匹配预期(简化版本)"""
return expected.lower() in output.lower()
def check_hallucination(output: str, case: dict) -> bool:
"""检测输出中是否包含编造的信息(简化版本)"""
if "unavailable_info" in case:
# 如果测试用例标注了不可获取的信息
for info in case["unavailable_info"]:
if info.lower() in output.lower():
return True # 模型编造了不可获取的信息
return False下表总结了六个评估维度及其在实际系统中的测量方式:
| 维度 | 测量方式 | 理想值 | 关注重点 |
|---|---|---|---|
| 成功率 | 标准测试集通过率 | 越高越好 | "成功"的定义需严格 |
| 自主性 | 主动工具调用占比 | 高 | 避免"等待投喂"型智能体 |
| 可扩展性 | 工具数 5→50 时成功率变化 | 稳定 | 大工具集下的鲁棒性 |
| Prompt 鲁棒性 | 同义改写后行为一致率 | 高 | 抗措辞干扰能力 |
| 幻觉率 | 编造不可获取信息的比例 | 越低越好 | 诚实度与安全性 |
| LLM 敏感性 | 更换模型后成功率变化 | 稳定 | 框架的可移植性 |
智能体评估本身也面临特殊挑战:由于 LLM 输出的非确定性,相同任务的多次运行可能产生不同结果。因此,评估器(Evaluator)本身往往也是一个智能体——使用 LLM-as-a-Judge 来判定任务是否成功。这与传统软件测试中确定性的 test suite 形成了鲜明对比,也带来了评估可靠性的二阶问题。
21.1.7 从基础框架到工程体系
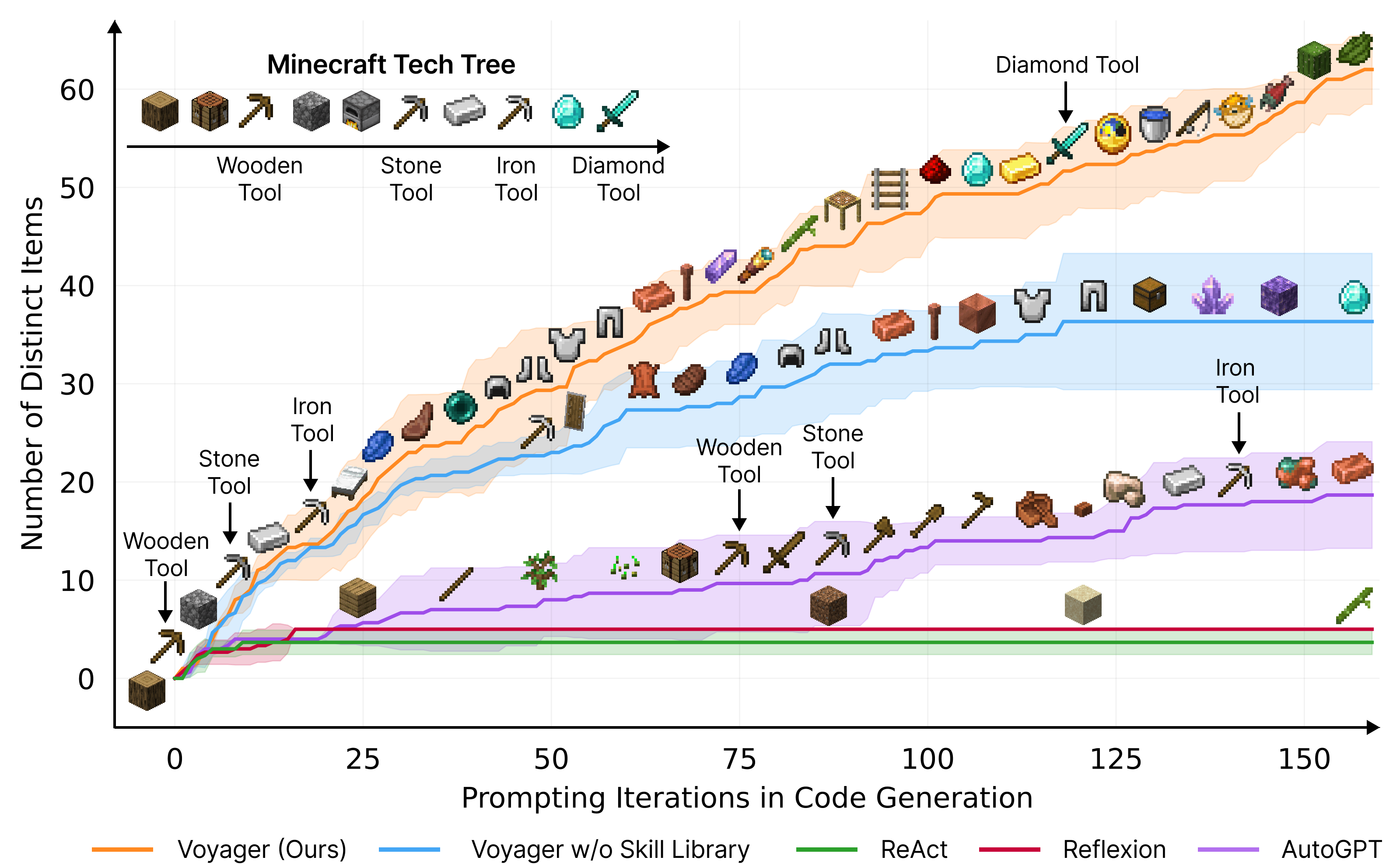
图 21-3:Voyager 展示了 LLM 智能体在开放世界中的惊人潜力——通过自主规划、代码执行和技能积累,它能在 Minecraft 中持续学习新能力。但从实验室原型到生产级系统,还需要系统性的工程支撑。
本节建立了智能体的理论基础:MDP/POMDP 的形式化框架给出了精确的数学语言,核心循环描述了运行时的动态过程,ReAct 框架提供了最广泛采用的实现范式,失败模式揭示了当前系统的脆弱性,评估维度则提供了衡量进步的标尺。
但理论和实践之间的鸿沟依然巨大。从 Voyager 在 Minecraft 中的惊艳表演,到 Claude Code、Cursor 等编码智能体的日常使用,再到企业级智能体系统的规模化部署,每一步都需要解决大量的工程挑战。在第21章的后续各节中,我们将逐一深入:
- §21.2 编码智能体:最成功的智能体应用类别
- §21.3 经典案例:从 Voyager 到医疗诊断的深度剖析
- §21.4 MCP 协议:标准化的工具集成框架
- §21.5 GRPO + Agent:将强化学习引入智能体训练
- §21.6 上下文工程:应对上下文衰退的五大策略
- §21.7-§21.11:记忆系统、工具设计、Agentic RL、Deep Research、工程实战
本节小结
智能体(Agent)是具备自主行动能力的智能系统,其核心在于感知-规划-动作-反馈-记忆的闭环循环。在数学上,智能体与环境的交互可以建模为 MDP 或 POMDP,其中 LLM 充当策略函数