2.4 自注意力与位置编码
上一节介绍了注意力机制的通用框架:查询与键匹配、softmax 归一化、对值加权求和。当查询、键、值三者都来自同一个序列时,这种特殊的注意力被称为自注意力(Self-Attention)。自注意力是 Transformer 的核心引擎——它让序列中的每个 token 都能直接"看到"其他所有 token,从而以
然而,自注意力本身是一个集合运算(set operation):它对输入 token 的处理与顺序无关。如果我们将句子"猫追狗"和"狗追猫"的 token 嵌入送入同一个自注意力层,在不引入位置信息的前提下,模型产生的输出是完全相同的。为了让模型"感知"token 的先后顺序,我们需要额外注入位置编码(Positional Encoding)。
本节将围绕两个主题展开:首先深入剖析自注意力的数学机制与因果掩码设计,然后系统介绍绝对位置编码与正弦位置编码的原理。
2.4.1 自注意力机制
从注意力到自注意力。 回顾上一节的缩放点积注意力公式:
在 Bahdanau 注意力或交叉注意力中,查询
其中
逐步展开计算过程。 为了建立清晰的数学直觉,我们将自注意力的计算分解为四个阶段:
第一步:线性投影。 对于输入序列中的第
三个投影矩阵互不共享参数,这使得同一个 token 可以在不同的"角色"中呈现不同的面貌——作为查询时表达"我在寻找什么信息",作为键时表达"我能提供什么信息",作为值时表达"我实际携带的内容"。
第二步:计算注意力分数。 对于位置
这个分数衡量了 token
将所有位置的分数组合成矩阵形式:
矩阵
第三步:softmax 归一化。 对分数矩阵的每一行进行 softmax,将原始分数转化为概率分布:
归一化后,
第四步:加权汇聚。 用注意力权重对值向量进行加权求和,得到第
矩阵形式为:
整个过程完全由矩阵乘法构成,没有循环依赖,所有 token 的更新可以在 GPU 上完全并行。这是自注意力相对于 RNN 的根本性优势。
自注意力的计算复杂度。 矩阵
2.4.2 因果注意力掩码
在自回归语言模型(如 GPT 系列)中,模型在预测第
数学定义。 定义一个下三角掩码矩阵
将掩码加到注意力分数矩阵上:
然后再对
以一个长度为 4 的序列为例,掩码后的注意力分数矩阵结构如下:
第 1 行(对应第 1 个 token 的查询)只有
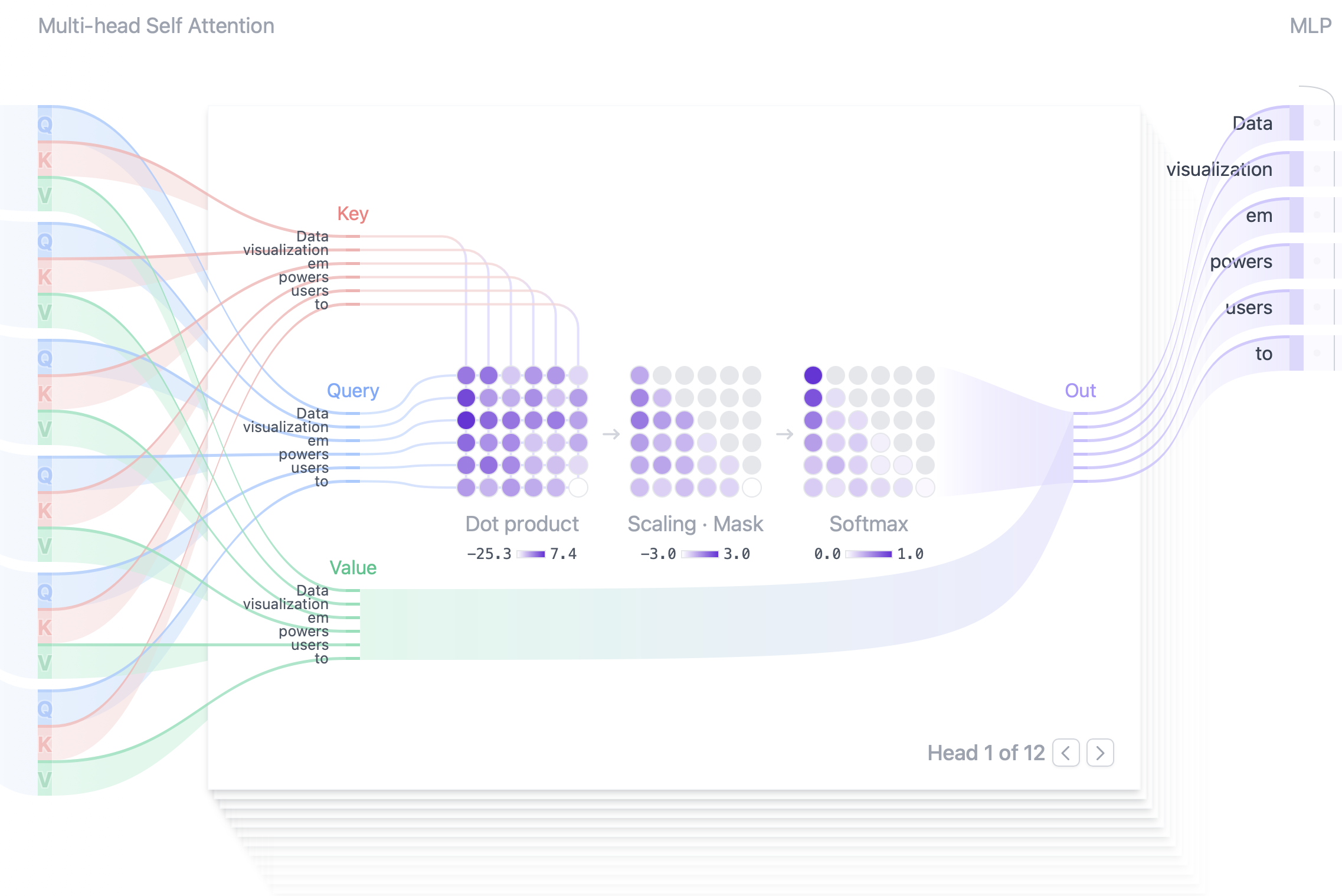
图 2-9:多头自注意力的完整计算流程可视化。输入序列的 Query、Key、Value 向量经点积计算注意力分数后,通过 Scaling 和 Mask 操作(将未来位置设为极小值),再经 Softmax 归一化得到注意力权重。注意下三角模式:每个 token 只能关注它自身及之前的 token。
为什么用加法而非乘法? 一种直觉的实现方式是将未来位置的分数直接乘以 0,但这在 softmax 之前是无效的——float("-inf")),利用指数函数的性质将其"消灭"。
因果掩码与自回归生成的关系。 因果掩码确保了模型在训练阶段的行为与推理阶段一致。训练时,整个序列被同时送入模型(称为"教师强制"),但因果掩码保证每个位置只依赖于它左侧的上下文。推理时,模型逐个生成 token,自然满足因果性。两种模式的数学等价性是自回归 Transformer 能够高效训练的关键。
2.4.3 位置编码的动机
自注意力是一个置换等变(permutation equivariant)的运算:如果我们将输入序列的 token 重新排列,输出也会相应地重新排列,但每个 token 的表示不会改变。形式化地,对于任意置换矩阵
这意味着自注意力无法区分"猫追狗"和"狗追猫"——两者的 token 集合相同,只是顺序不同。在自然语言中,顺序显然至关重要。因此,我们需要一种机制将 token 的位置信息注入到模型中。
位置编码的基本思想。 构造一个位置编码矩阵
加入位置信息后的
2.4.4 绝对位置编码
最直接的方案是可学习的绝对位置编码(Learned Absolute Positional Embedding):创建一个位置嵌入矩阵
图 2-11:可学习位置编码(Learned Positional Embedding)的可视化。每个位置对应一个可训练的嵌入向量,这些向量在训练过程中逐步学习到有意义的位置表示模式。GPT-2 和 BERT 均采用这种方案。
这种方法被 GPT-2 和 BERT 等早期模型采用,实现简单且效果良好。但它有一个根本性的局限:无法外推。如果训练时的最大序列长度为 512,那么位置 513 及以后的编码是未定义的——模型无法处理比训练时更长的序列。
2.4.5 正弦位置编码
为了克服可学习位置编码的外推局限性,原始 Transformer 论文(Vaswani et al., 2017)提出了一种基于正弦和余弦函数的固定位置编码方案。
公式定义。 对于位置
偶数维度使用正弦函数,奇数维度使用余弦函数。每对相邻维度
直觉解释:频率递减的"时钟"。 理解正弦位置编码的一个有力类比是多指针时钟:
- 编码向量的最低维度(
)对应的频率最高, ,波长为 ——类似于秒针,变化最快。 - 随着维度
增大,频率 指数级下降,波长指数级增长。中间维度类似于分针,最高维度类似于时针,变化极为缓慢。 - 当
接近 时,波长达到 ,远超常见的序列长度。
这种"多频率叠加"的设计使得每个位置都拥有一个独一无二的编码向量,类似于二进制计数中低位变化快、高位变化慢的模式——但使用连续的三角函数代替离散的 0/1 值,具有更好的平滑性和空间效率。
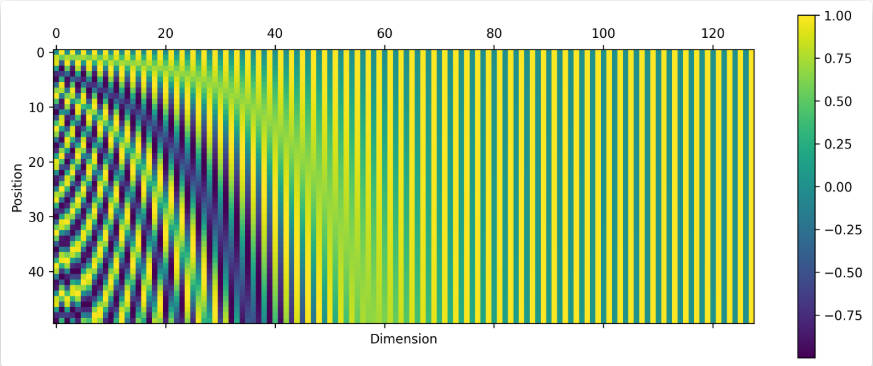
图 2-10:正弦位置编码矩阵的热力图。横轴为嵌入维度(Dimension),纵轴为位置索引(Position)。低维度(左侧)对应高频分量,随位置快速振荡;高维度(右侧)对应低频分量,变化极为缓慢。每一行(每个位置)的编码向量都是独一无二的,这保证了模型能区分不同位置的 token。
关键性质:编码相对位置信息。 正弦位置编码最重要的理论性质是:对于任意固定偏移量
具体来说,定义
这个
推导过程。 利用三角函数的和角公式:
令
写成矩阵形式即得上式。这意味着注意力机制可以通过学习到的线性变换来捕捉 token 之间的相对位置关系,而不必依赖绝对位置本身。
另一个视角:位置编码点积只依赖相对距离。 考虑两个位置
结果仅依赖于相对距离
图 2-12:旋转位置编码(RoPE)的可视化。RoPE 将二维子向量进行位置相关的旋转操作,使得 Q-K 内积自动包含相对位置信息。RoPE 是正弦位置编码的自然延伸,已成为 LLaMA、Mistral、Qwen 等现代 LLM 的标准配置(将在第 3 章详细介绍)。
2.4.6 PyTorch 实现
以下提供自注意力(含因果掩码)和正弦位置编码的自包含 PyTorch 实现。
import torch
import torch.nn as nn
import math
def causal_self_attention(
x: torch.Tensor,
W_q: nn.Linear,
W_k: nn.Linear,
W_v: nn.Linear,
dropout: nn.Dropout | None = None,
) -> torch.Tensor:
"""带因果掩码的单头自注意力。
Args:
x: 输入张量,形状 (batch, seq_len, d_model)
W_q, W_k, W_v: Q/K/V 的线性投影层
dropout: 可选的 Dropout 层
Returns:
output: 形状 (batch, seq_len, d_v)
"""
Q = W_q(x) # (batch, seq_len, d_k)
K = W_k(x) # (batch, seq_len, d_k)
V = W_v(x) # (batch, seq_len, d_v)
d_k = Q.size(-1)
# 计算注意力分数: (batch, seq_len, seq_len)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# 构造因果掩码: 上三角部分为 True
seq_len = x.size(1)
causal_mask = torch.triu(
torch.ones(seq_len, seq_len, device=x.device, dtype=torch.bool),
diagonal=1,
)
# 将未来位置的分数设为 -inf
scores = scores.masked_fill(causal_mask, float("-inf"))
# softmax 归一化
attn_weights = torch.softmax(scores, dim=-1)
if dropout is not None:
attn_weights = dropout(attn_weights)
# 加权汇聚
output = torch.matmul(attn_weights, V)
return output
class SinusoidalPositionalEncoding(nn.Module):
"""正弦位置编码。
构造一个形状为 (1, max_len, d_model) 的位置编码矩阵,
偶数维度使用 sin,奇数维度使用 cos,频率随维度指数递减。
该矩阵在初始化时计算完毕,不参与梯度更新。
Args:
d_model: 嵌入维度
max_len: 支持的最大序列长度
dropout: Dropout 概率
"""
def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.0):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 位置索引: (max_len, 1)
position = torch.arange(max_len, dtype=torch.float32).unsqueeze(1)
# 频率因子: (d_model/2,)
div_term = torch.exp(
torch.arange(0, d_model, 2, dtype=torch.float32)
* (-math.log(10000.0) / d_model)
)
# 计算位置编码矩阵
pe = torch.zeros(1, max_len, d_model)
pe[0, :, 0::2] = torch.sin(position * div_term)
pe[0, :, 1::2] = torch.cos(position * div_term)
# 注册为 buffer: 不参与训练,但随模型保存和迁移到 GPU
self.register_buffer("pe", pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: 输入嵌入,形状 (batch, seq_len, d_model)
Returns:
加上位置编码后的嵌入,形状 (batch, seq_len, d_model)
"""
x = x + self.pe[:, : x.size(1), :]
return self.dropout(x)代码解读。
causal_self_attention 函数演示了带因果掩码的自注意力完整流程:首先通过三个线性层将输入投影为 Q、K、V,计算缩放点积分数后,使用 torch.triu 生成上三角布尔掩码(对角线以上为 True),再用 masked_fill 将未来位置的分数设为
SinusoidalPositionalEncoding 类在初始化时一次性计算整个位置编码矩阵。核心技巧在于频率因子的计算:div_term = exp(arange(0, d_model, 2) * (-log(10000) / d_model)) 等价于 register_buffer 注册为模型的持久化状态,不参与梯度更新,但会随模型保存和设备迁移。
可以用以下代码验证并可视化:
import matplotlib.pyplot as plt
# ---- 验证因果自注意力 ----
d_model, d_k = 64, 64
batch_size, seq_len = 2, 8
W_q = nn.Linear(d_model, d_k, bias=False)
W_k = nn.Linear(d_model, d_k, bias=False)
W_v = nn.Linear(d_model, d_k, bias=False)
x = torch.randn(batch_size, seq_len, d_model)
output = causal_self_attention(x, W_q, W_k, W_v)
print(f"因果自注意力输出形状: {output.shape}")
# 输出: 因果自注意力输出形状: torch.Size([2, 8, 64])
# ---- 可视化正弦位置编码 ----
pe_module = SinusoidalPositionalEncoding(d_model=128, max_len=100)
pe_matrix = pe_module.pe[0].numpy() # (100, 128)
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
# 左图: 选取不同维度对的正弦/余弦曲线
for col in [4, 5, 6, 7]:
axes[0].plot(pe_matrix[:, col], label=f"dim {col}")
axes[0].set_xlabel("Position")
axes[0].set_ylabel("Encoding Value")
axes[0].set_title("Sinusoidal PE: Selected Dimensions")
axes[0].legend()
# 右图: 热力图
im = axes[1].imshow(pe_matrix.T, aspect="auto", cmap="RdBu")
axes[1].set_xlabel("Position")
axes[1].set_ylabel("Encoding Dimension")
axes[1].set_title("Sinusoidal PE: Heatmap")
plt.colorbar(im, ax=axes[1])
plt.tight_layout()
plt.savefig("sinusoidal_pe_visualization.png", dpi=150)
plt.show()在热力图中可以清晰地看到:低维度(图的底部)的交替频率很高,高维度(图的顶部)则变化极为缓慢,呈现出类似二进制计数器中"低位快变、高位慢变"的规律性模式。
本节小结
本节围绕自注意力和位置编码两个核心主题,建立了以下关键认识:
- 自注意力让序列中的每个 token 都能直接关注所有其他 token,通过
计算注意力分数、softmax 归一化、加权汇聚三步完成。整个过程完全由矩阵运算实现,可高度并行化,但时间和空间复杂度均为 。 - 因果掩码通过在 softmax 之前将未来位置的注意力分数设为
,确保自回归模型在训练和推理时都遵守"只看过去"的约束,是 GPT 类模型的关键设计。 - 位置编码弥补了自注意力对序列顺序的"无感",将位置信息通过加法注入到词嵌入中。可学习的绝对位置编码简单直接但无法外推;正弦位置编码通过多频率三角函数生成固定的编码向量,利用和角公式的线性变换性质天然编码了相对位置信息,并在理论上支持任意长度的序列。