25.4 部署与服务
训练完成的模型如果只能在训练脚本中调用,那它的实用价值就大打折扣。真正让模型"活起来"的关键一步,是将其包装成可访问的服务——无论是一个兼容 OpenAI 协议的 API 端点、一个浏览器中的聊天界面,还是一条 ollama 命令即可拉起的本地推理。本节将系统介绍从训练产物到生产可用服务的完整部署链路,涵盖模型格式转换、API 服务搭建、Web 前端开发,以及主流第三方推理引擎(vLLM、llama.cpp、ollama)的接入方法。
25.4.1 部署全景架构
在动手之前,先建立对整个部署链路的全局认知。下图展示了从训练产物到最终用户之间的完整路径:
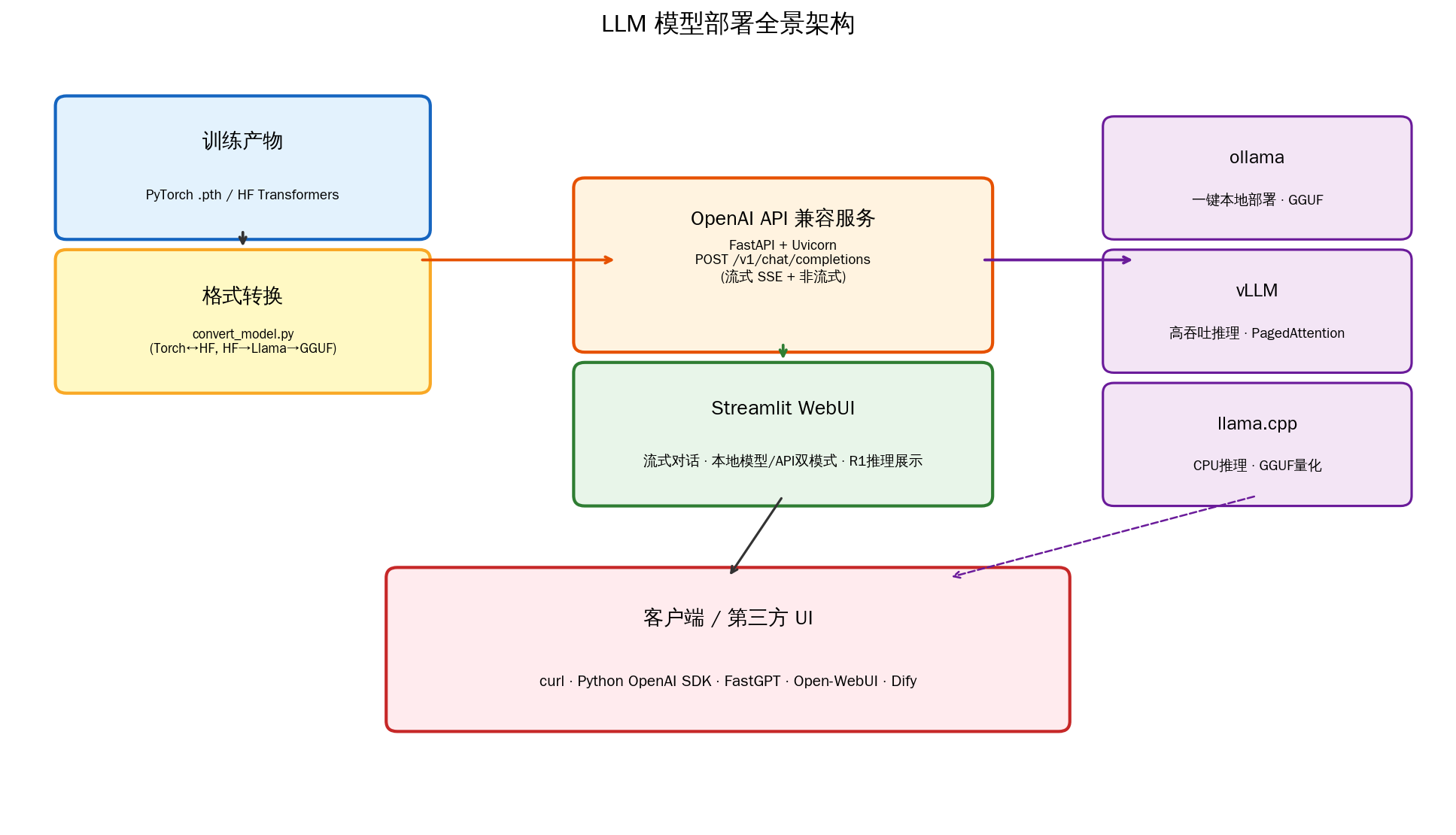
左侧是训练阶段的产物——PyTorch 原生权重(.pth 文件)或 HuggingFace Transformers 格式的模型目录。中间是两条并行的服务路径:自建 API 服务(FastAPI + Uvicorn)可以提供 OpenAI 兼容接口,配合 Streamlit 构建轻量级聊天界面;第三方推理引擎(vLLM、llama.cpp、ollama)则提供高性能或跨平台的推理能力。右侧是最终的客户端,可以是 curl 命令、Python OpenAI SDK,也可以是 FastGPT、Open-WebUI、Dify 等成熟的第三方 Chat UI。
连接这些路径的桥梁是模型格式转换。不同的推理引擎要求不同的模型格式,因此格式转换是部署的第一步,也是最容易踩坑的环节。
25.4.2 模型格式转换
训练时通常使用 PyTorch 原生格式保存权重(一个 .pth 文件包含所有参数的 state_dict),但部署时需要根据目标引擎选择合适的格式。下图展示了主要的转换路径:
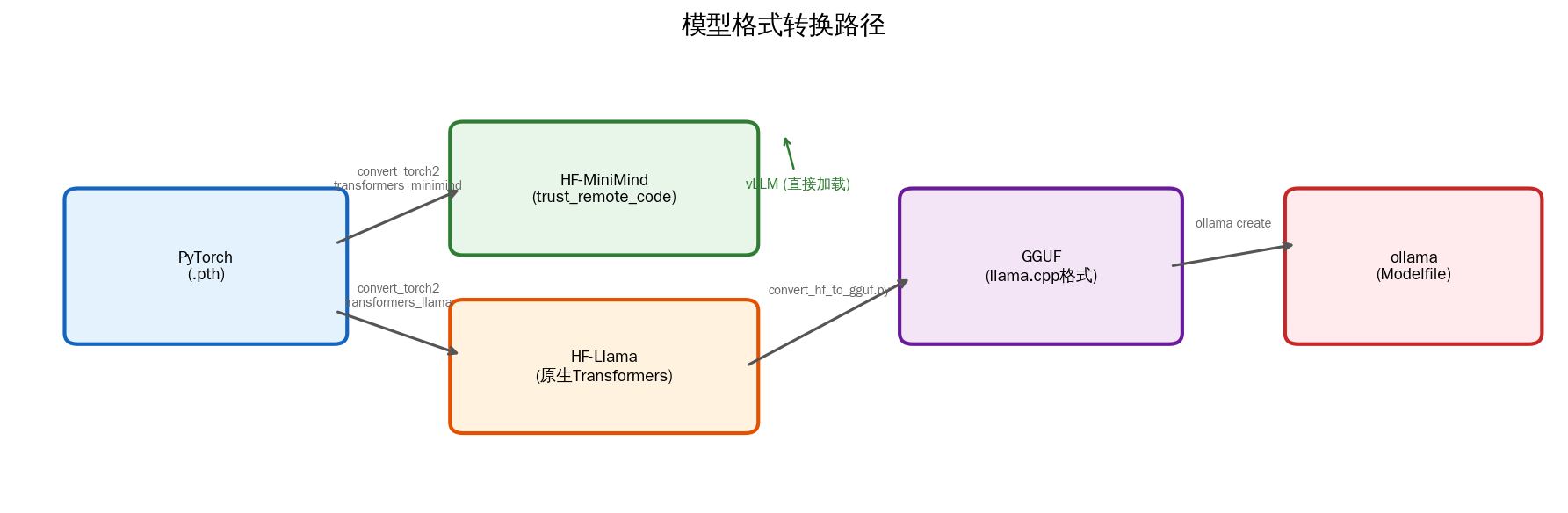
整个格式生态可以归纳为四种格式和三条转换链路:
| 格式 | 说明 | 适用场景 |
|---|---|---|
PyTorch .pth | 原生训练产物,包含完整 state_dict | 训练、调试 |
| HF-MiniMind | Transformers 格式 + 自定义模型代码 | API 服务、vLLM(需 trust_remote_code) |
| HF-Llama | 标准 LlamaForCausalLM 结构 | llama.cpp 转换、广泛兼容 |
| GGUF | llama.cpp 的量化格式 | llama.cpp 推理、ollama 部署 |
转换链路一:PyTorch → HF-MiniMind(自定义 Transformers 格式)
这条路径保留了自定义的 MiniMindConfig 和 MiniMindForCausalLM 类。加载时需要 trust_remote_code=True,因为模型代码不在 Transformers 官方库中。核心步骤是:注册自定义类到 AutoClass,加载 .pth 权重,转换为 float16 精度后调用 save_pretrained 保存:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 注册自定义模型类(关键步骤)
MiniMindConfig.register_for_auto_class()
MiniMindForCausalLM.register_for_auto_class("AutoModelForCausalLM")
# 实例化并加载权重
model = MiniMindForCausalLM(config)
state_dict = torch.load("full_sft_512.pth", map_location="cpu")
model.load_state_dict(state_dict, strict=False)
# 转为半精度并保存
model = model.to(torch.float16)
model.save_pretrained("MiniMind2-Small", safe_serialization=False)
# 复制分词器
tokenizer = AutoTokenizer.from_pretrained("model/")
tokenizer.save_pretrained("MiniMind2-Small")转换链路二:PyTorch → HF-Llama(标准 Transformers 格式)
这条路径将自定义架构映射到标准的 LlamaForCausalLM。由于 MiniMind 的架构与 Llama 高度相似(RMSNorm + RoPE + GQA + SwiGLU),参数可以直接对应,无需额外适配层。转换后的模型可以被任何支持 Llama 的工具直接加载,无需 trust_remote_code:
from transformers import LlamaConfig, LlamaForCausalLM
llama_config = LlamaConfig(
vocab_size=6400,
hidden_size=512,
intermediate_size=1408, # SwiGLU: 64 * ceil(512*8/3 / 64)
num_hidden_layers=8,
num_attention_heads=8,
num_key_value_heads=2,
max_position_embeddings=8192,
rms_norm_eps=1e-5,
rope_theta=1e6,
tie_word_embeddings=True
)
llama_model = LlamaForCausalLM(llama_config)
llama_model.load_state_dict(state_dict, strict=False)
llama_model = llama_model.to(torch.float16)
llama_model.save_pretrained("MiniMind2-Small-Llama")需要注意 intermediate_size 的计算方式:SwiGLU 的中间维度为
转换链路三:HF-Llama → GGUF(llama.cpp 格式)
GGUF(GPT-Generated Unified Format)是 llama.cpp 项目定义的模型格式,支持多种量化级别。转换使用 llama.cpp 自带的 convert_hf_to_gguf.py 脚本:
# 将 HF 格式转换为 GGUF
python convert_hf_to_gguf.py ./MiniMind2-Small-Llama
# 可选:进一步量化(Q4_K_M 是精度与体积的良好平衡点)
./llama-quantize ./MiniMind2.gguf ./Q4-MiniMind2.gguf Q4_K_M量化的效果非常显著。以 MiniMind2(104M 参数)为例,float16 模型约 208 MB,Q4_K_M 量化后仅约 60 MB,体积缩小到原来的不到 30%,推理速度也有明显提升,而精度损失在小模型上几乎不可察觉。
25.4.3 搭建 OpenAI API 兼容服务
有了 Transformers 格式的模型,就可以搭建一个兼容 OpenAI Chat Completions API 的服务端。这样做的好处是巨大的:任何支持 OpenAI API 的客户端(Python SDK、curl、FastGPT、Open-WebUI、Dify 等)都可以无缝对接你的自训练模型,无需修改一行客户端代码。
服务端核心实现
服务端基于 FastAPI + Uvicorn 构建,只需实现一个 POST 端点 /v1/chat/completions。下图展示了流式请求的完整处理流程:
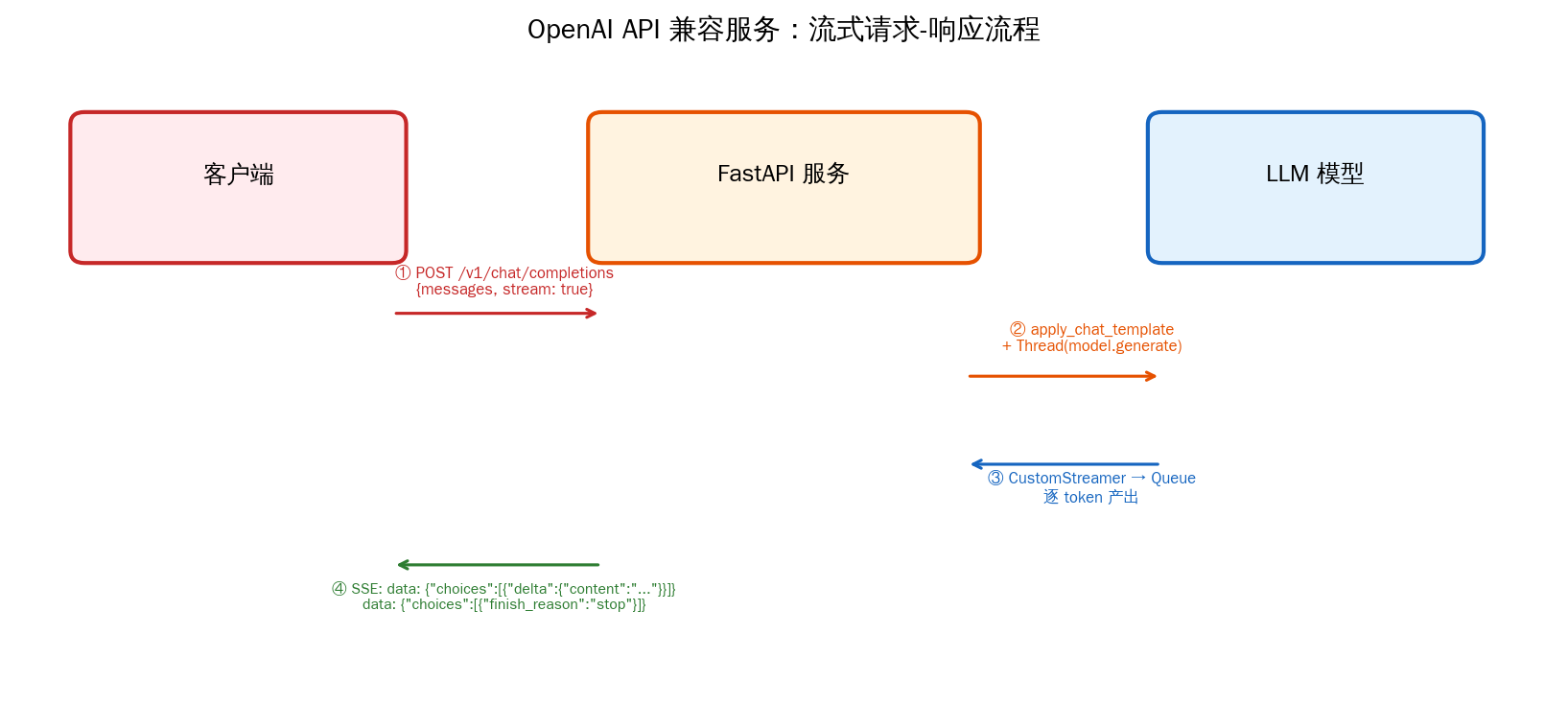
整个流程分为四步:客户端发送 POST 请求(包含 messages 和 stream 参数)→ FastAPI 服务调用 apply_chat_template 拼装 prompt → 在子线程中启动 model.generate,通过 CustomStreamer + Queue 逐 token 产出 → 服务端以 SSE(Server-Sent Events)格式流式返回每个 token。
请求体定义是 OpenAI API 规范的子集(包含 model、messages、temperature、top_p、max_tokens、stream 等字段)。流式生成的关键在于 CustomStreamer + Queue 的组合——Transformers 的 model.generate 是一个阻塞调用,如果在主线程中运行会导致 FastAPI 无法及时返回响应。解决方案是在子线程中运行生成,通过线程安全的 Queue 传递每个解码后的 token:
from threading import Thread
from queue import Queue
from transformers import TextStreamer
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
class CustomStreamer(TextStreamer):
"""继承 TextStreamer,将解码后的文本逐块放入 Queue"""
def __init__(self, tokenizer, queue):
super().__init__(tokenizer, skip_prompt=True, skip_special_tokens=True)
self.queue = queue
def on_finalized_text(self, text: str, stream_end: bool = False):
self.queue.put(text)
if stream_end:
self.queue.put(None) # 哨兵值,标记生成结束
def generate_stream_response(messages, temperature, top_p, max_tokens):
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)[-max_tokens:]
inputs = tokenizer(prompt, return_tensors="pt", truncation=True).to(device)
queue = Queue()
streamer = CustomStreamer(tokenizer, queue)
def _generate():
model.generate(inputs.input_ids, max_new_tokens=max_tokens,
do_sample=True, temperature=temperature,
top_p=top_p, streamer=streamer)
Thread(target=_generate).start()
while True:
text = queue.get()
if text is None:
yield json.dumps({"choices": [{"delta": {}, "finish_reason": "stop"}]})
break
yield json.dumps({"choices": [{"delta": {"content": text}}]})
app = FastAPI()
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatRequest):
if request.stream:
return StreamingResponse(
(f"data: {chunk}\n\n" for chunk in generate_stream_response(
request.messages, request.temperature,
request.top_p, request.max_tokens)),
media_type="text/event-stream"
)
else:
# 非流式:直接调用 model.generate 后一次性返回完整文本
prompt = tokenizer.apply_chat_template(
request.messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
ids = model.generate(inputs["input_ids"], max_new_tokens=request.max_tokens)
answer = tokenizer.decode(ids[0][inputs["input_ids"].shape[1]:],
skip_special_tokens=True)
return {"model": "minimind",
"choices": [{"message": {"role": "assistant", "content": answer}}]}启动服务只需一行命令:
python serve_openai_api.py # 默认监听 0.0.0.0:8998客户端调用
服务启动后,可以使用标准的 OpenAI Python SDK 进行调用,只需将 base_url 指向本地服务:
from openai import OpenAI
client = OpenAI(api_key="any-string", base_url="http://127.0.0.1:8998/v1")
response = client.chat.completions.create(
model="minimind",
messages=[{"role": "user", "content": "请介绍一下自己"}],
stream=True,
temperature=0.7,
max_tokens=2048
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="")也可以用 curl 直接测试:
curl http://127.0.0.1:8998/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "minimind",
"messages": [{"role": "user", "content": "世界上最高的山是什么?"}],
"temperature": 0.7,
"max_tokens": 512,
"stream": true
}'25.4.4 Streamlit 聊天界面
API 服务面向程序化调用,但有时候我们需要一个更直观的聊天界面来交互式地测试和展示模型。Streamlit 是 Python 生态中最轻量的 Web 应用框架,几十行代码就能搭建一个功能完整的 Chat UI。
MiniMind 的 Streamlit 界面支持两种模式:本地模型直接在 GPU 上加载推理,API 模式通过 OpenAI SDK 调用远程服务端。这种双模式设计使得同一个界面既能作为本地调试工具,也能作为远程服务的前端展示。
核心代码结构如下:
import streamlit as st
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
# 侧边栏配置
st.sidebar.title("模型设定调整")
history_num = st.sidebar.slider("历史对话轮数", 0, 6, 0, step=2)
max_tokens = st.sidebar.slider("最大序列长度", 256, 8192, 8192)
temperature = st.sidebar.slider("Temperature", 0.6, 1.2, 0.85, step=0.01)
model_source = st.sidebar.radio("模型来源", ["本地模型", "API"])
# 模型加载(带缓存,避免每次交互重新加载)
@st.cache_resource
def load_model(model_path):
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
return model.eval().cuda(), tokenizer
# 聊天主循环
if prompt := st.chat_input("给模型发送消息"):
# 拼装对话历史
messages = st.session_state.chat_messages[-(history_num + 1):]
if model_source == "本地模型":
# 本地推理:使用 TextIteratorStreamer 实现流式输出
inputs = tokenizer(
tokenizer.apply_chat_template(messages, tokenize=False,
add_generation_prompt=True),
return_tensors="pt"
).to("cuda")
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True,
skip_special_tokens=True)
Thread(target=model.generate,
kwargs={"input_ids": inputs.input_ids,
"streamer": streamer,
"max_new_tokens": max_tokens}).start()
placeholder = st.empty()
answer = ""
for token_text in streamer:
answer += token_text
placeholder.markdown(answer)
else:
# API 模式:通过 OpenAI SDK 调用远程服务
from openai import OpenAI
client = OpenAI(api_key="none", base_url=api_url)
response = client.chat.completions.create(
model=model_id, messages=messages, stream=True
)
for chunk in response:
# 逐 token 更新界面
pass启动 Streamlit 界面同样只需一行命令:
pip install streamlit
streamlit run web_demo.pyStreamlit 会自动在浏览器中打开一个交互式聊天窗口,左侧是模型参数调整面板(Temperature、最大长度、历史轮数等),主区域支持流式对话展示。对于推理模型(如 R1 系列),界面还支持将 <think>...</think> 标签中的推理过程折叠显示,让用户可以展开查看模型的思维链。
25.4.5 第三方推理引擎
自建 API 服务虽然灵活,但在性能和易用性上有明显局限:单线程生成无法充分利用 GPU 并行能力,也不支持批量请求(batching)。工业级部署通常借助专业的推理引擎。以下介绍三个最主流的选择。
vLLM:高吞吐 GPU 推理
vLLM 是目前最流行的高性能 LLM 推理框架,其核心技术 PagedAttention 将 KV Cache 分页管理,避免了传统连续内存分配造成的显存碎片化问题,显著提升了并发吞吐量。对于 Transformers 格式的模型,vLLM 可以直接加载并以 OpenAI API 形式对外提供服务:
# 安装 vLLM
pip install vllm
# 以 OpenAI API 形式启动服务
vllm serve ./MiniMind2 \
--model-impl transformers \
--served-model-name "minimind" \
--port 8998启动后,客户端代码与前文完全相同——只需将 base_url 指向 vLLM 的端口即可。--model-impl transformers 参数告诉 vLLM 使用 Transformers 后端加载模型(因为 MiniMind 使用了自定义模型类)。对于转换为标准 Llama 格式的模型,可以省略此参数以获得更好的性能优化。
vLLM 相比自建 FastAPI 服务的主要优势包括:
- 连续批处理(Continuous Batching):自动将多个并发请求合并为一个 batch 推理,GPU 利用率远高于逐请求串行处理
- PagedAttention:KV Cache 按页分配和释放,显存利用率接近理论最优
- Tensor Parallelism:支持多卡推理,通过
--tensor-parallel-size N参数即可将模型切分到 N 张 GPU 上 - 前缀缓存(Prefix Caching):相同 system prompt 的请求可以复用 KV Cache,减少重复计算
llama.cpp:CPU 友好的跨平台推理
llama.cpp 是用纯 C/C++ 实现的 LLM 推理库,最大特点是无需 GPU 即可运行。它通过 GGUF 格式的量化模型,可以在笔记本电脑的 CPU 上以可接受的速度运行推理。对于 MiniMind 这样的小模型,CPU 推理的延迟完全可以满足交互式对话的需求。
使用 llama.cpp 部署分为两步。首先将 HF-Llama 格式转换为 GGUF(如 25.4.2 节所述),然后直接在命令行运行推理:
# 命令行交互式对话
./llama-cli -m ./MiniMind2.gguf -sys "You are a helpful assistant"有一个需要注意的技术细节:llama.cpp 的 convert_hf_to_gguf.py 脚本内部维护了一个已知 tokenizer 的白名单。如果自定义模型的 tokenizer 不在白名单中,转换会失败。解决方法是在脚本的 get_vocab_base_pre 函数末尾加入一个兜底逻辑:
# 在 get_vocab_base_pre 函数最后添加
if res is None:
res = "qwen2" # 使用已有的 tokenizer 类型作为兜底这个修改不影响模型推理的正确性,只是告诉转换脚本如何处理 tokenizer 的元数据。
ollama:一键本地部署
ollama 是面向终端用户的大模型运行工具,将模型管理、下载、推理整合到一个简洁的 CLI 中。如果说 vLLM 面向的是开发者和工程团队,那么 ollama 面向的就是"我只想用一行命令跑起来"的用户。
使用 ollama 部署自训练模型需要先准备 GGUF 文件(通过 llama.cpp 转换),然后创建一个 Modelfile 来描述模型的配置:
FROM ./Q4-MiniMind2.gguf
SYSTEM """You are a helpful assistant"""
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
{{ .Response }}<|im_end|>
"""Modelfile 中的三个字段各有用途:FROM 指定 GGUF 模型文件路径,SYSTEM 定义默认的系统提示词,TEMPLATE 定义对话模板(必须与训练时的 chat template 一致,否则模型输出会严重退化)。
接下来只需两条命令即可完成部署:
# 创建本地模型
ollama create -f minimind.modelfile minimind-local
# 启动对话
ollama run minimind-local
>>> 你叫什么名字
我是一个语言模型...如果不想自己转换,也可以直接使用社区已经上传到 Ollama Hub 的预构建模型:
ollama run jingyaogong/minimind2ollama 底层实际上使用了 llama.cpp 作为推理引擎,因此它同样支持 CPU 推理和 GPU 加速。它的附加价值在于模型管理——自动下载、版本控制、磁盘缓存——以及开箱即用的 API 服务(默认监听 localhost:11434,兼容 OpenAI 格式)。
25.4.6 模型分发与部署方案选型
部署解决的是"如何运行",而模型分发解决的是"如何让别人获取"。目前最主流的两个模型托管平台是 HuggingFace Hub 和 ModelScope(魔搭社区)。
 |  |
|---|
HuggingFace Hub 是国际社区的事实标准,所有主流框架(Transformers、vLLM、llama.cpp)都原生支持从 Hub 下载模型。对于国内用户,ModelScope 提供了镜像和加速能力。一个完整的模型仓库应包含 config.json(架构参数)、pytorch_model.bin 或 model.safetensors(模型权重)、tokenizer.json(词表)、tokenizer_config.json(分词器配置)等文件,使用 huggingface_hub 库的 upload_folder 方法即可一键上传整个目录。
面对多种部署方案,如何选择?以下是基于不同场景的推荐:
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 本地快速调试 | 自建 FastAPI 服务 | 代码透明,方便断点调试和日志追踪 |
| 交互式演示 | Streamlit WebUI | 零前端经验即可搭建,支持实时调参 |
| 生产级 GPU 服务 | vLLM | 连续批处理 + PagedAttention,吞吐量远超单线程 |
| 无 GPU 设备(笔记本/边缘设备) | llama.cpp | 纯 CPU 推理,支持量化,跨平台 |
| 一键本地体验 | ollama | 一条命令启动,自带模型管理和 API 服务 |
| 对接第三方 Chat UI | 自建 API 或 vLLM | 兼容 OpenAI 协议,FastGPT/Open-WebUI/Dify 无缝接入 |
对于 MiniMind 这样的小模型(26M~145M 参数),各方案的性能差异不太显著——即便是自建 FastAPI 服务,单次推理延迟也在毫秒到秒级别。但随着模型规模增大,vLLM 的优势会愈发明显:当并发请求数从 1 增加到 10 时,vLLM 的总吞吐量几乎线性增长,而单线程 FastAPI 服务的吞吐量基本不变。
25.4.7 本节小结
本节完整介绍了从训练产物到生产可用服务的部署链路。核心知识点包括:模型格式转换(PyTorch → HF-MiniMind/HF-Llama → GGUF)是部署的基础,不同目标引擎需要不同格式;OpenAI API 兼容服务基于 FastAPI + Uvicorn 实现,通过 CustomStreamer + Queue + 子线程实现流式生成,使自训练模型能够无缝对接 OpenAI 生态的所有客户端工具;Streamlit WebUI 提供了零前端门槛的聊天界面;vLLM、llama.cpp、ollama 三大第三方引擎分别覆盖了高吞吐 GPU 推理、跨平台 CPU 推理、一键本地部署三种核心场景。在下一节中,我们将从部署回到评估,系统比较不同训练方法(SFT、DPO、PPO、GRPO)在 MiniMind 上的实际效果差异。