19.1 推理基本概念
在前面的章节中,我们花了大量篇幅讨论如何训练一个大语言模型。然而对于真正面向用户的应用来说,推理(Inference) 才是模型价值的兑现环节——用户提交一段提示(Prompt),模型据此生成响应(Response)。推理不仅仅是聊天机器人的对话,它广泛存在于代码补全、批量数据处理、模型评估,乃至强化学习中的样本生成等场景。
与训练相比,推理面临截然不同的计算特征和性能瓶颈。训练时所有 Token 都已知,可以在序列维度上大规模并行计算,充分利用 GPU 的算力,属于计算受限(Compute-Limited) 的工作负载。而推理是自回归(Autoregressive) 的:为了生成第
本节将系统介绍大模型推理的基本流程和核心性能指标,为后续讨论各种推理优化技术奠定基础。
19.1.1 自回归生成:推理的基本范式
大语言模型的推理过程本质上是一个自回归循环:模型每次前向传播只输出一个 Token,将该 Token 追加到已有序列末尾,再作为下一次前向传播的输入,如此反复直到生成终止符(如 <eos>)或达到最大长度限制。
一次完整的推理请求从文本到文本,中间经历三个步骤:(1)分词(Tokenization)——将用户的自然语言文本切分为 Token 序列并映射为整数 ID;(2)模型前向传播——Token ID 经过 Embedding 层变为向量表示,逐层通过 Transformer 网络,最终经 Logits 层映射到词表空间得到概率分布;(3)采样/解码——从概率分布中选取下一个 Token。
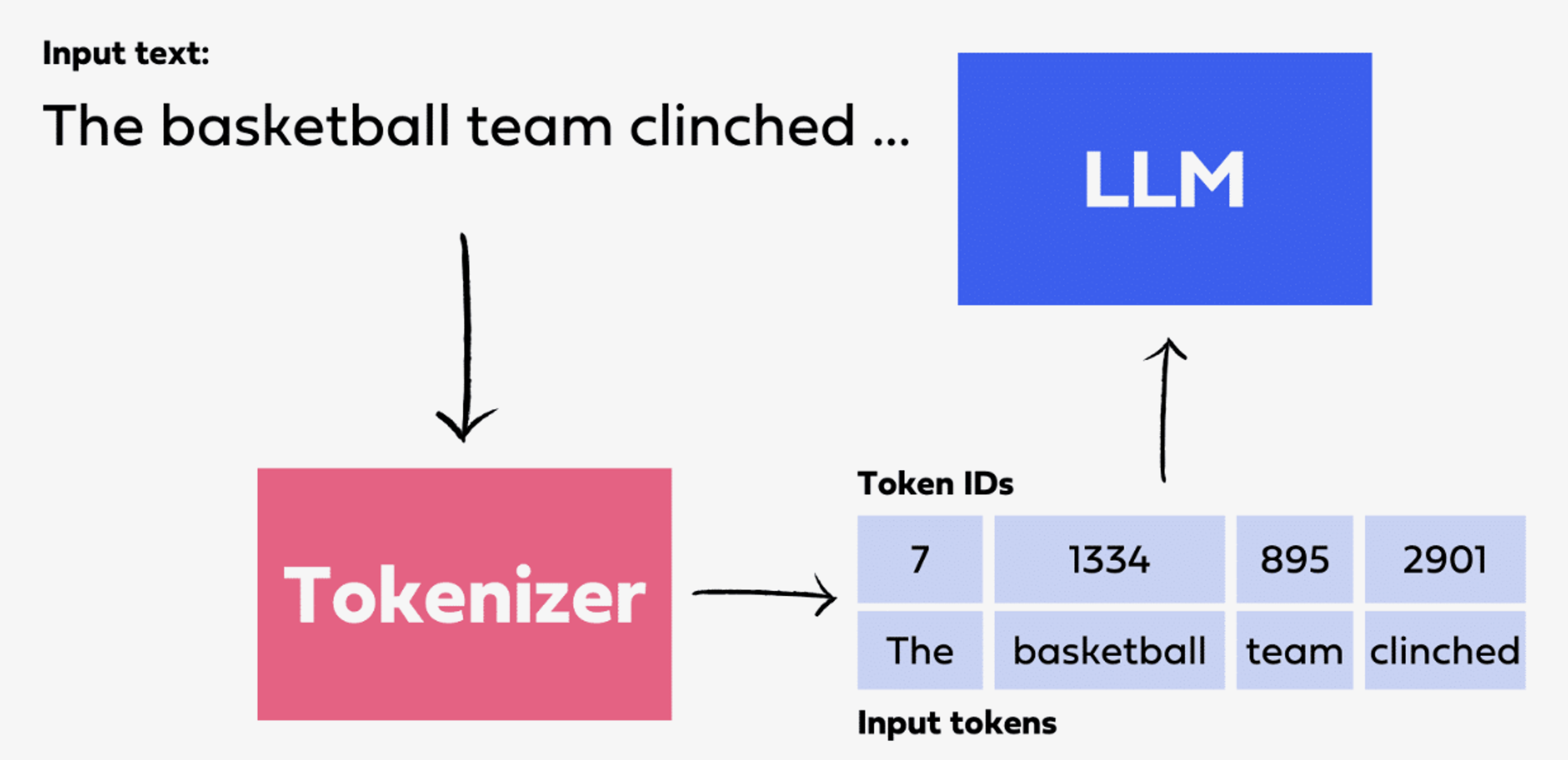
图 19-1a:推理的输入处理流程。文本首先经过 Tokenizer 切分为 Token 并转为 ID,然后送入 LLM 进行计算。
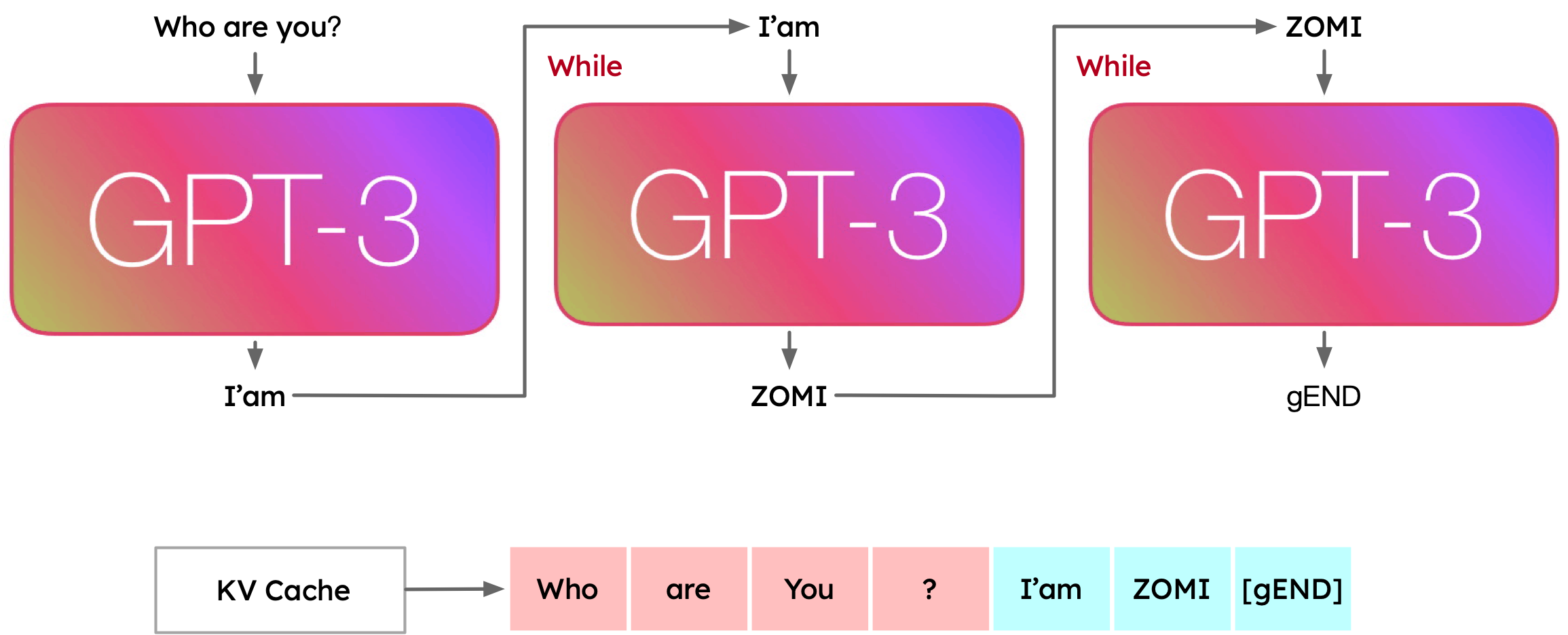
图 19-1b:自回归生成过程。模型每步输出一个 Token,输出与输入拼接后送入下一步。KV Cache 缓存了历史 Token 的键值对,避免重复计算。
用一段简化的 Python 伪代码来描述这个过程:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def autoregressive_generate(prompt: str, max_new_tokens: int = 50) -> str:
"""自回归生成的基本流程演示"""
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").eval()
input_ids = tokenizer.encode(prompt, return_tensors="pt")
eos_token_id = tokenizer.eos_token_id
with torch.no_grad():
for _ in range(max_new_tokens):
# 前向传播:输入完整序列,获得下一个 Token 的概率分布
logits = model(input_ids).logits # [batch, seq_len, vocab_size]
# 取最后一个位置的 logits,选择概率最大的 Token
next_token = torch.argmax(logits[:, -1, :], dim=-1, keepdim=True)
# 将新 Token 拼接到输入序列
input_ids = torch.cat([input_ids, next_token], dim=1)
if next_token.item() == eos_token_id:
break
return tokenizer.decode(input_ids[0], skip_special_tokens=True)
# 示例调用
print(autoregressive_generate("The future of AI is"))上述代码虽然概念清晰,但存在一个严重的效率问题:每一步都对整个序列做完整的前向传播,大量计算被重复执行。具体来说,当序列长度从
这正是引入 Prefill/Decode 两阶段划分和 KV Cache 的根本动机:将已经计算过的 Key/Value 缓存起来,后续步骤直接复用。
19.1.2 Prefill 与 Decode:推理的两个阶段
现代推理系统将自回归生成过程拆分为两个性质截然不同的阶段:预填充(Prefill) 和 解码(Decode)。这一划分是理解所有推理优化技术的基石。
Prefill 阶段(预填充)。 当用户请求到达时,推理系统首先将完整的 Prompt 一次性送入模型,并行处理所有输入 Token。这一阶段的核心任务有两个:(1)为每个 Transformer 层生成所有输入 Token 对应的 Key 和 Value 向量,写入 KV Cache;(2)基于完整的输入上下文,计算出第一个输出 Token 的概率分布。
从计算特征来看,Prefill 阶段涉及的矩阵运算形如
Decode 阶段(解码)。 在 KV Cache 已经建立之后,模型进入逐 Token 生成的循环。每一步只需要处理一个新 Token:计算该 Token 的 Query 向量,与 KV Cache 中存储的所有历史 Key/Value 做注意力计算,同时将新的 Key/Value 追加到缓存中。
Decode 阶段的矩阵运算退化为
对于 Decode 阶段的线性层,需要读取整个权重矩阵
下表总结了两个阶段的核心差异:
| 特征 | Prefill(预填充) | Decode(解码) |
|---|---|---|
| 处理的 Token 数 | 整个 Prompt( | 每步 1 个 |
| 矩阵运算类型 | GEMM(矩阵-矩阵乘法) | GEMV(矩阵-向量乘法) |
| 算术强度 | 高( | 极低( |
| 瓶颈类型 | 计算受限 | 内存受限 |
| GPU 利用率 | 高 | 低(大量空闲等待) |
| KV Cache 操作 | 初始化写入 | 读取 + 追加写入 |
| 对用户感知的影响 | 决定 TTFT | 决定生成速度 |
表 19-1:Prefill 与 Decode 阶段的核心对比。
理解这两个阶段的差异,可以用一个直观的类比:Prefill 好比考试时一口气读完整道大题的题干,大脑高度集中地处理信息;Decode 则好比逐字逐句地写出答案,每写一个字都要回头看一眼题干和已经写好的内容——写字的速度远慢于阅读题干的速度,而且大部分时间花在"回头看"上,而非"想"上。
这种"一快一慢"的两阶段特性,催生了许多针对性的优化策略。例如 PD 分离(Prefill-Decode Disaggregation) 将两个阶段部署在不同的硬件上,让计算密集的 Prefill 跑在算力强的 GPU 上,让内存密集的 Decode 跑在带宽高的设备上,从而同时优化两个阶段的效率。又如 Chunked Prefill 将过长的 Prompt 分块处理,避免 Prefill 阶段独占 GPU 而饿死正在 Decode 的请求。
19.1.3 推理性能指标
衡量推理系统的好坏需要一套标准化的性能指标。这些指标大致分为三类:延迟(Latency)、吞吐量(Throughput) 和 资源利用率(Utilization)。
延迟指标
首 Token 延迟(Time to First Token, TTFT)。 从用户提交请求到接收到第一个输出 Token 所经过的时间。TTFT 涵盖了请求排队、Prefill 计算以及网络传输等所有环节。对于对话式 AI 等实时交互应用,低 TTFT 是良好用户体验的前提——它决定了用户感知模型"开始思考"的速度。TTFT 主要由 Prefill 阶段的计算时间决定,因此与 Prompt 长度正相关。例如,当 Prompt 从 100 Token 增长到 10000 Token 时,Prefill 的计算量增长约 100 倍,TTFT 会显著上升。
逐 Token 延迟(Time Per Output Token, TPOT)。 在 Decode 阶段中,连续两个输出 Token 之间的平均时间间隔。TPOT 反映了模型"说话"的速度,直接影响用户的阅读体验。其计算方式为:
端到端延迟(End-to-End Latency)。 从请求发送到接收完整响应的总时间。它是 TTFT 和所有 Decode 步骤耗时的叠加:
其中
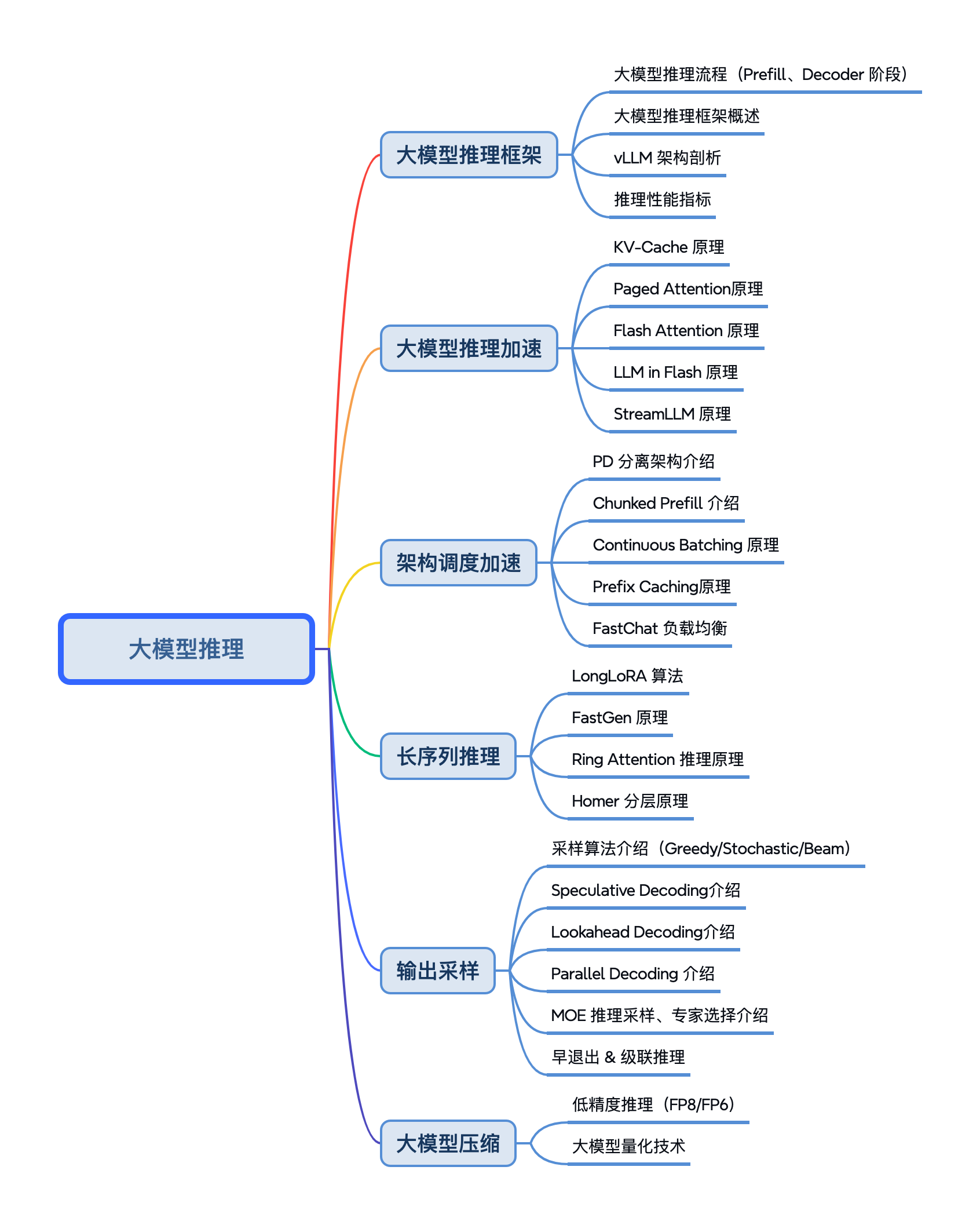
图 19-2:大模型推理技术全景。从推理框架、推理加速、调度优化到长序列推理、采样策略和模型压缩,构成了一个完整的优化体系。
吞吐量指标
每秒 Token 数(Tokens Per Second, TPS)。 衡量系统单位时间内处理的 Token 总量。TPS 可以进一步细分为 Prefill 阶段和 Decode 阶段的吞吐量:
其中
以一个具体数字来感受这些指标的量级:在 NVIDIA A100 上运行 Llama 2 13B 模型,Prompt 长度为 512 Token 时,典型的 TTFT 约为 200-300 ms(Prefill TPS 约 2000 Token/s),而 Decode 阶段的 TPOT 约为 30-50 ms(Decode TPS 约 20-30 Token/s)。可以看到,Prefill 的 TPS 比 Decode 高出近两个数量级,这正反映了两个阶段计算受限与内存受限的本质差异。
每秒请求数(Requests Per Second, RPS)。 从整个服务系统层面衡量吞吐能力。一次 API 调用无论 Prompt 多长、生成多少 Token,都计为一次请求。RPS 关注的不仅是 GPU 计算能力,还包括 CPU 调度、内存带宽、网络 I/O 等全链路因素,是评估高并发场景下系统整体性能的关键指标。
需要注意的是,TPS 和 RPS 并非独立指标。在固定硬件条件下,若每个请求平均生成
以下代码展示了如何实际测量这些推理性能指标:
import time
from typing import NamedTuple
class InferenceMetrics(NamedTuple):
ttft: float # 首 Token 延迟(秒)
tpot: float # 逐 Token 延迟(秒)
e2e_latency: float # 端到端延迟(秒)
tps_prefill: float # Prefill 阶段 TPS
tps_decode: float # Decode 阶段 TPS
num_output_tokens: int
def measure_inference(model, tokenizer, prompt: str, max_new_tokens: int = 100):
"""测量推理性能指标的简化实现"""
import torch
input_ids = tokenizer.encode(prompt, return_tensors="pt")
num_prompt_tokens = input_ids.shape[1]
# --- Prefill 阶段 ---
t_start = time.perf_counter()
with torch.no_grad():
outputs = model(input_ids, use_cache=True)
past_kv = outputs.past_key_values
next_token = torch.argmax(outputs.logits[:, -1, :], dim=-1, keepdim=True)
t_first_token = time.perf_counter()
ttft = t_first_token - t_start
# --- Decode 阶段 ---
generated_tokens = [next_token]
for _ in range(max_new_tokens - 1):
with torch.no_grad():
outputs = model(next_token, past_key_values=past_kv, use_cache=True)
past_kv = outputs.past_key_values
next_token = torch.argmax(outputs.logits[:, -1, :], dim=-1, keepdim=True)
generated_tokens.append(next_token)
if next_token.item() == tokenizer.eos_token_id:
break
t_end = time.perf_counter()
num_output = len(generated_tokens)
e2e = t_end - t_start
decode_time = t_end - t_first_token
tpot = decode_time / max(num_output - 1, 1)
return InferenceMetrics(
ttft=ttft,
tpot=tpot,
e2e_latency=e2e,
tps_prefill=num_prompt_tokens / ttft,
tps_decode=1.0 / tpot if tpot > 0 else float('inf'),
num_output_tokens=num_output,
)资源利用率
GPU 利用率。 衡量 GPU 计算单元在推理任务中的活跃时间比例。由于 Decode 阶段严重内存受限,单个请求的 GPU 利用率可能不足 5%,远低于训练时动辄 30-50% 的水平。通过 Continuous Batching 等调度优化,高负载下 GPU 利用率可以提升至 80% 以上。提升 GPU 利用率是推理优化的核心目标之一。
显存利用率。 大模型推理中,显存主要被三部分占用:(1)模型权重,例如一个 70B 参数的模型以 FP16 存储需要约 140 GB;(2)KV Cache,随序列长度和 Batch Size 动态增长,在长上下文场景下甚至超过模型权重本身;(3)激活值和中间状态,占比相对较小。高效的显存管理(如 PagedAttention)直接决定了系统能够支持的并发请求数和最大序列长度。
推理的显存结构与训练有本质区别。训练时显存的大头是优化器状态(Adam 的一阶矩和二阶矩约占参数量的 8 倍),而推理时没有优化器和梯度,显存大头转为模型权重和 KV Cache。因此推理的显存占用远小于训练——但 KV Cache 的动态增长特性使得显存管理变得更加复杂,因为系统必须在不知道每个请求最终生成多少 Token 的情况下预分配和回收显存。
19.1.4 吞吐量与延迟的权衡
在实际部署中,高吞吐量和低延迟往往是一对矛盾。理解这对矛盾,是设计推理系统的关键。
云端场景:吞吐优先。 对于云服务提供商来说,同时服务海量用户是首要目标。通过增大 Batch Size,多个请求共享一次权重加载的开销,可以显著提升 GPU 利用率和整体吞吐量。但更大的 Batch 意味着更多的 KV Cache 占用、更长的单次前向传播时间,单个请求的延迟会随之上升。
边缘场景:延迟优先。 对于个人设备或嵌入式终端,通常只有一个用户在交互,并发需求很低。此时优化的重点是降低每个 Token 的生成延迟,让用户感受到流畅的对话体验。像 llama.cpp 这类轻量级推理框架,便专注于在 CPU、Apple Silicon 等边缘硬件上实现极致的单请求推理速度,而非高并发吞吐。
思考模型的新挑战。 随着推理时间计算(Inference-Time Compute)范式的兴起,如 OpenAI 的 o1 系列模型,一次请求可能生成数千甚至上万个 Token 的"思考过程"。此时 Decode 阶段的耗时会急剧膨胀,TPOT 的优化价值被进一步放大——TPOT 每降低 1 毫秒,在 5000 Token 的输出上就能节省 5 秒的等待时间。
增大 Batch Size 的双刃剑效应。 从 Roofline 模型的视角来看,增大 Batch Size
其中
这个公式揭示了推理系统设计的核心矛盾:在有限的显存预算下,如何在 Batch Size(吞吐量)和序列长度(功能能力)之间找到最佳平衡点。举一个具体的例子:Llama 2 13B 模型(40 层,
19.1.5 从指标到优化:技术路线总览
理解了推理的两阶段特性和性能指标后,我们可以清晰地勾勒出后续章节将要展开的优化路线:
| 优化方向 | 核心思路 | 典型技术 | 影响的指标 |
|---|---|---|---|
| 减少数据搬运 | 缩小 KV Cache 体积 | GQA/MLA、量化 | TPOT、吞吐量 |
| 避免重复计算 | 缓存中间结果 | KV Cache、Prefix Caching | TTFT、TPOT |
| 提升并行度 | 让 GPU 同时处理更多请求 | Continuous Batching | 吞吐量、GPU 利用率 |
| 消除显存碎片 | 虚拟内存式管理 | PagedAttention | 最大 Batch Size |
| 加速 Decode | 用小模型猜测减少步数 | Speculative Decoding | TPOT |
| 分离两阶段 | 按计算特征匹配硬件 | PD 分离 | TTFT、TPOT |
表 19-2:推理优化技术路线总览。
小结
本节建立了大模型推理的基本概念框架,为后续深入各项优化技术提供了统一的语言和分析视角。核心要点如下:
- 自回归生成是大模型推理的基本范式,逐 Token 的生成方式天然受限于内存带宽而非计算能力。
- 推理分为 Prefill(计算受限,并行处理输入 Prompt)和 Decode(内存受限,逐步生成输出 Token)两个阶段,它们的计算特征截然不同,需要差异化的优化策略。
- 关键性能指标包括 TTFT(首 Token 延迟)、TPOT(逐 Token 延迟)、TPS(每秒 Token 数)和 RPS(每秒请求数),分别从延迟和吞吐两个维度评价系统性能。
- 吞吐量与延迟之间存在根本性的权衡,在有限的显存预算下平衡 Batch Size 与序列长度是推理系统设计的核心挑战。
后续章节将围绕这些概念,逐一展开 KV Cache 管理、注意力优化、调度策略、模型压缩等关键推理优化技术的原理与实现。在此之前,建议读者牢记本节建立的"Prefill 计算受限、Decode 内存受限"这一核心认知——它是理解几乎所有推理优化技术设计动机的出发点。