6.6 Gated DeltaNet(线性注意力)
标准 Softmax 注意力的核心操作是计算
本节将从标准注意力的递推视角出发,推导 Gated DeltaNet 的状态更新公式,给出完整的 PyTorch 实现,并分析其与标准注意力在复杂度、KV 缓存和建模能力上的权衡。
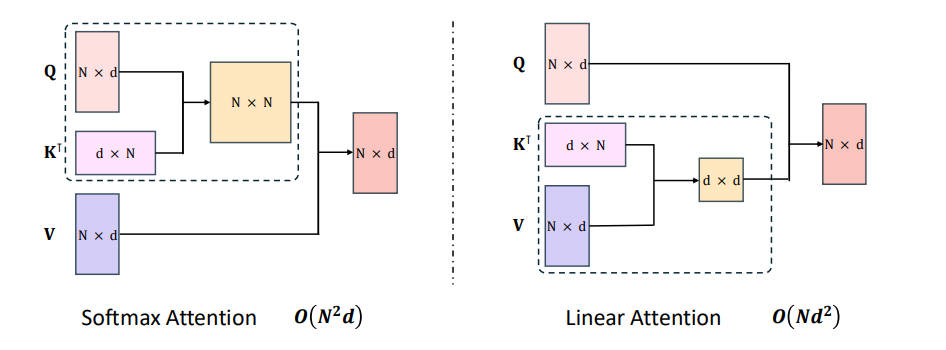
图 6-20:线性注意力与标准 Softmax 注意力的对比。线性注意力通过递推状态更新替代显式注意力矩阵,将单步推理复杂度从 O(n) 降至 O(1)。
6.6.1 从标准注意力到递推状态机制
标准注意力的瓶颈。 回顾缩放点积注意力的计算:
其中
线性注意力的核心思路。 如果我们去掉 Softmax,将注意力写成
更进一步,定义一个状态矩阵
其中
问题:信息只增不减。 上述朴素递推中,
6.6.2 Gated DeltaNet 的递推公式
Gated DeltaNet 在朴素线性注意力的基础上引入三个门控信号,完整的递推公式如下:
各符号含义:
| 符号 | 维度 | 含义 |
|---|---|---|
| 状态矩阵(每个头各自维护一个) | ||
| 标量(per head) | 衰减门(decay gate):控制旧记忆的保留比例, | |
| 更新门(update gate):控制新信息写入状态的强度 | ||
| 输出门(output gate):对注意力输出进行逐元素缩放 | ||
| — | 逐元素乘(Hadamard 积) |
逐步解读递推过程:
第一步:衰减旧状态。
第二步:计算 Delta(差值)。
第三步:写入新信息。
第四步:读取输出。
第五步:门控输出。
6.6.3 三个门控的计算方式
三个门控信号均由输入
衰减门
其中
更新门
即标准 Sigmoid 门控,逐维度控制更新幅度,
输出门
输出门不需要显式激活函数——它在最终输出时与 SiLU 复合使用,
6.6.4 PyTorch 实现
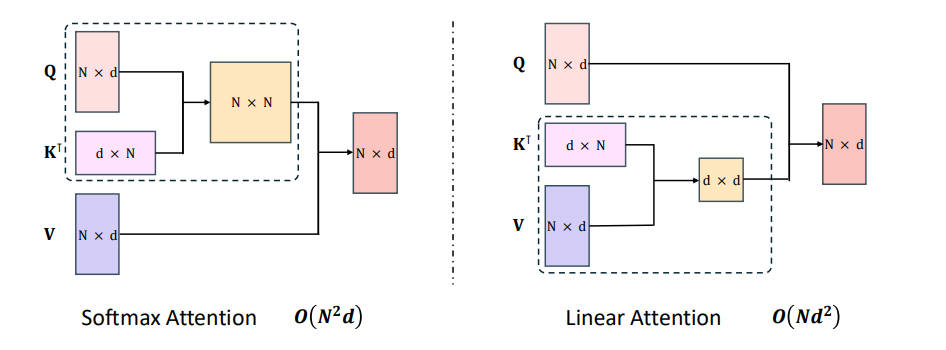
图 6-21:线性注意力与标准 Softmax 注意力的计算流程对比。线性注意力通过递推状态更新替代显式注意力矩阵,将计算复杂度从
以下是 Gated DeltaNet 的完整 PyTorch 实现。为突出递推机制的核心逻辑,省略了实际部署中常见的卷积混合(short convolution)模块:
import torch
import torch.nn as nn
import torch.nn.functional as F
def l2norm(x, dim=-1, eps=1e-6):
"""L2 归一化,用于 Query/Key 的归一化(类似 QKNorm)"""
return x * torch.rsqrt((x * x).sum(dim=dim, keepdim=True) + eps)
class GatedDeltaNet(nn.Module):
def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
# Q / K / V 投影(与标准注意力相同)
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 三个门控的投影
self.W_gate = nn.Linear(d_in, d_out, bias=False) # 输出门
self.W_beta = nn.Linear(d_in, d_out, bias=False) # 更新门
# 衰减门 alpha = exp(-A * softplus(W_alpha(x) + dt_bias))
self.W_alpha = nn.Linear(d_in, num_heads, bias=False)
self.dt_bias = nn.Parameter(torch.ones(num_heads))
A_init = torch.empty(num_heads).uniform_(0, 16)
self.A_log = nn.Parameter(torch.log(A_init))
# 输出归一化
self.norm = nn.RMSNorm(self.head_dim, eps=1e-6)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
b, n, _ = x.shape
# 线性投影
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# 计算三个门控信号
beta = torch.sigmoid(self.W_beta(x)) # (b, n, d_out)
alpha_log = -self.A_log.exp().view(1, 1, -1) * F.softplus(
self.W_alpha(x) + self.dt_bias
) # (b, n, num_heads)
alpha = alpha_log.exp() # (b, n, num_heads)
gate = self.W_gate(x) # (b, n, d_out)
# reshape 为多头形式: (b, num_heads, n, head_dim)
queries = queries.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
keys = keys.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
values = values.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
beta = beta.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
gate = gate.view(b, n, self.num_heads, self.head_dim).transpose(1, 2)
# QKNorm:L2 归一化 + 缩放,稳定递推数值
queries = l2norm(queries, dim=-1) / (self.head_dim ** 0.5)
keys = l2norm(keys, dim=-1)
# 初始化状态矩阵 S: (b, num_heads, head_dim, head_dim)
S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)
outs = []
for t in range(n):
k_t = keys[:, :, t] # (b, num_heads, head_dim)
q_t = queries[:, :, t] # (b, num_heads, head_dim)
v_t = values[:, :, t] # (b, num_heads, head_dim)
b_t = beta[:, :, t] # (b, num_heads, head_dim)
a_t = alpha[:, t] # (b, num_heads)
a_t = a_t.unsqueeze(-1).unsqueeze(-1) # (b, num_heads, 1, 1)
# Step 1: 衰减旧状态
S = S * a_t
# Step 2: 从状态中检索预测值,计算 delta
kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2) # S^T @ k_t
delta = (v_t - kv_mem) * b_t
# Step 3: 秩-1 更新写入状态
S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
# Step 4: 读取输出
y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2) # S @ q_t
outs.append(y_t)
# 合并时间步: (b, num_heads, n, head_dim)
context = torch.stack(outs, dim=2)
# 转置回 (b, n, num_heads, head_dim) 以便做 RMSNorm
context = context.transpose(1, 2).contiguous()
context = context.view(b, n, self.num_heads, self.head_dim)
# Step 5: RMSNorm + SiLU 输出门控
context = self.norm(context)
gate = gate.transpose(1, 2).contiguous()
gate = gate.view(b, n, self.num_heads, self.head_dim)
context = context * F.silu(gate)
# 合并多头并输出投影
context = context.view(b, n, self.d_out)
context = self.dropout(context)
return self.out_proj(context)代码要点解读:
- 状态矩阵
S的形状为(b, num_heads, head_dim, head_dim)——这是一个的方阵(per head),而非标准注意力中随序列长度增长的 矩阵。对于典型的 head_dim=128,每个头的状态仅占KB(bf16),远小于长序列的 KV 缓存。 l2norm对 Q 和 K 做 L2 归一化(类似 QKNorm),确保递推过程中数值不会爆炸或消失。Softmax 注意力天然具有归一化效果(注意力权重和为 1),但线性注意力失去了这一性质,因此需要显式归一化。kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)等价于矩阵-向量乘,利用逐元素乘 + 求和替代显式矩阵乘法。类似地, y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)等价于。 - 衰减门
的参数化: A_log(可学习)→exp得到→ 与 softplus(W_alpha(x) + dt_bias)相乘 → 取负 →exp得到。这种多层变换保证了数值稳定性,并允许模型灵活学习衰减速率。
6.6.5 与标准注意力的复杂度对比
下表对比了标准 Softmax 注意力与 Gated DeltaNet 在推理阶段的关键指标(head_dim,
| 指标 | Softmax 注意力 | Gated DeltaNet |
|---|---|---|
| 单步推理计算量 | ||
| 全序列计算量 | ||
| KV 缓存大小 | ||
| KV 缓存增长方式 | 每生成一个 token,缓存增加 | 无增长,仅维护固定大小的状态矩阵 |
| 全局上下文建模 | 完整——每个 token 直接关注所有历史 token | 受限——历史信息被压缩到 |
关键权衡: 当
6.6.6 KV 缓存对比:数值示例
以一个典型的中大规模模型配置进行量化对比:emb_dim=2048、num_heads=16、head_dim=128、n_layers=48、dtype=bf16(2 字节/元素)、batch_size=1。
标准注意力的 KV 缓存(随序列长度增长):
| 序列长度 | KV 缓存大小 |
|---|---|
| 4,096 | 1.50 GB |
| 32,768 | 12.00 GB |
| 131,072 | 48.00 GB |
Gated DeltaNet 的状态内存(固定):
这一数值与序列长度完全无关。即使在 128K 上下文长度下,标准注意力需要 48 GB KV 缓存,而 Gated DeltaNet 仅需约 25 MB 的固定状态——相差近 2000 倍。
当然,这里的比较仅针对线性注意力层。在混合架构(如 3:1 配置)中,全局注意力层仍然需要 KV 缓存,但总量减少为纯全局注意力架构的
6.6.7 混合架构:3:1 策略
图 6-22:状态空间模型(SSM)的递推架构。DeltaNet 与 Mamba 等模型共享递推状态更新的核心思想,通过固定大小的状态矩阵压缩全部历史信息。
纯线性注意力虽然效率极高,但其状态矩阵的有限容量使其在需要精确长距离检索的任务上(如从长文档中提取特定事实)表现不如全局注意力。因此 Qwen3-Next 和 Kimi Linear 均采用混合策略:每 4 个 Transformer 块中,3 个使用 Gated DeltaNet 线性注意力,1 个使用全局注意力(Qwen3-Next 使用带输出门控的标准多头注意力,Kimi Linear 使用 MLA),比例为 3:1。
这一设计的考量包括:
- 效率:全模型 75% 的注意力层为线性复杂度,整体计算量和 KV 缓存大幅减少。
- 上下文能力:每隔 3 层插入一个全局注意力层,为模型提供直接访问完整历史的通道,弥补线性注意力的信息压缩损失。
- 训练稳定性:Qwen3-Next 在全局注意力层中使用 Sigmoid 输出门控,消除了 Attention Sink(注意力权重集中在首 token)和 Massive Activation(激活值异常放大)等数值稳定性问题。
Kimi Linear 的改进:通道级衰减门。 Qwen3-Next 的衰减门
6.6.8 推理流程对比
将标准注意力和 Gated DeltaNet 的自回归推理流程并排对比,可以清晰看出两者在缓存机制上的根本差异:
标准注意力的推理(以第
- 计算新 token 的
。 - 将
追加到 KV 缓存: 。 - 计算
与缓存中所有 Key 的点积: 。 - Softmax + 加权求和得到输出。
Gated DeltaNet 的推理(以第
- 计算新 token 的
以及三个门控 。 - 更新状态矩阵:
,代价 。 - 从状态中查询输出:
,代价 。 - 门控输出:
。
整个过程无需存储任何历史 K/V 向量,仅需维护一个固定大小的状态矩阵
图 6-23:DeltaNet 的递推状态更新。状态矩阵通过门控遗忘和 Delta 规则增量更新,实现对序列信息的高效压缩存储。
本节小结
本节介绍了 Gated DeltaNet 线性注意力的原理与实现:
- 核心机制:用递推状态矩阵
替代 注意力矩阵。每步通过"衰减-检索-修正-写入-查询"五步递推更新状态,单步计算量为 ,全序列为 ,对序列长度线性。 - 三个门控:衰减门
(控制遗忘速率)、更新门 (控制写入强度)、输出门 (SiLU 激活,控制输出缩放)。Delta 规则(误差驱动更新)使状态更新具有选择性——已经记住的信息不会被重复写入。 - KV 缓存优势:Gated DeltaNet 的"缓存"是固定大小的状态矩阵(如
head_dim=128时每头仅 32 KB),不随序列长度增长。在 128K 上下文、48 层模型的配置下,标准注意力需要约 48 GB KV 缓存,而 Gated DeltaNet 仅需约 25 MB。 - 建模能力代价:固定大小的状态矩阵构成信息瓶颈,无法像全局注意力那样直接关注任意历史位置。因此实际部署中采用 3:1 混合策略(3 层线性注意力 + 1 层全局注意力),在效率和上下文建模能力之间取得平衡。
- 工业实践:Qwen3-Next 和 Kimi Linear 均采用此架构。Kimi Linear 进一步将 per-head 的标量衰减门改为 per-channel 的向量衰减门,提升了长上下文推理性能。