14.3 推理模型蒸馏
在前两节中,我们分别讨论了黑盒蒸馏(仅利用教师输出文本)和白盒蒸馏(利用教师 logits 分布)的一般方法。本节将聚焦一个更具挑战性的细分场景——推理模型蒸馏(Reasoning Model Distillation)。所谓推理模型蒸馏,是指将大型推理模型(如 DeepSeek-R1 671B)的结构化思考能力迁移到小型模型中,使学生模型不仅学会"给出正确答案",还学会"像教师一样思考"。
推理模型蒸馏与普通 SFT 蒸馏的根本区别在于:教师输出中包含了显式的推理轨迹,通常以 <think>...</think> 标签包裹的思维链(Chain of Thought, CoT)形式呈现。学生模型需要同时学习两件事——推理过程的生成格式和推理内容本身的质量。这带来了数据格式约束、训练目标设计、成本控制等一系列推理蒸馏特有的技术问题。
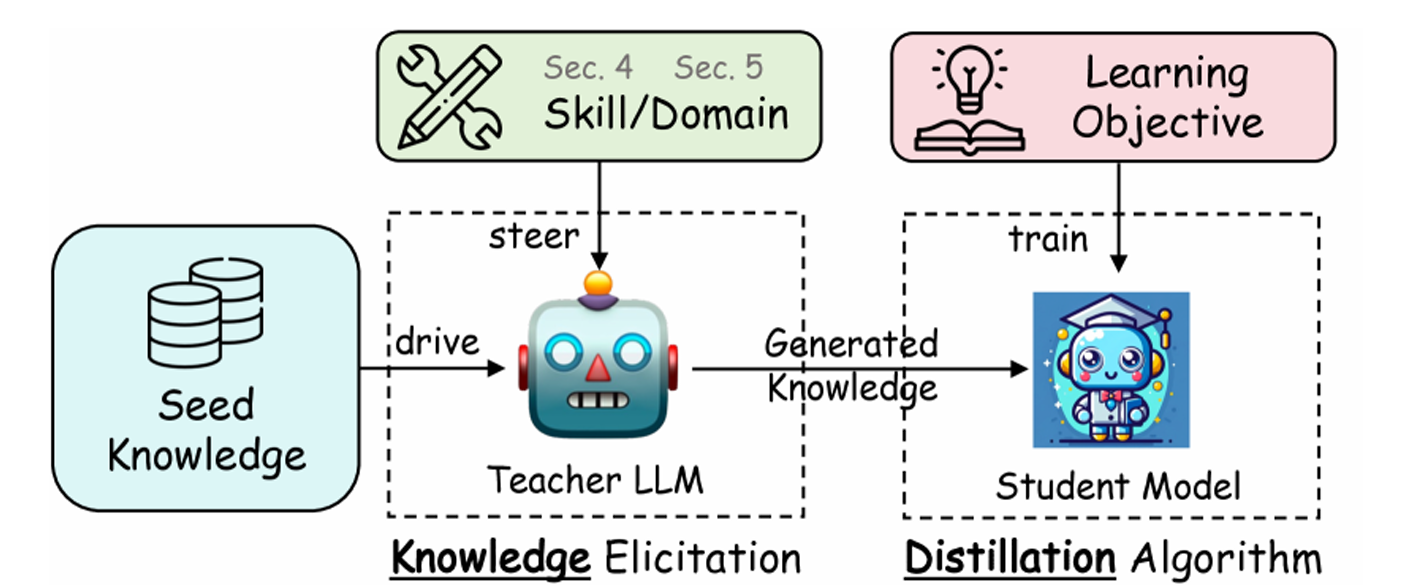
图 14-3:推理模型蒸馏的核心流程。教师模型基于种子知识生成带有思维链的推理数据,学生模型通过监督训练习得结构化推理能力。
14.3.1 推理蒸馏数据的结构设计
推理蒸馏数据与普通 SFT 数据最显著的区别在于其双段结构——每条数据包含教师的思考过程(thinking)和最终回答(content)两个独立字段。以数学推理为例,一条典型的蒸馏数据如下:
{
"problem": "If a > 1, find the sum of real solutions of sqrt(a - sqrt(a+x)) = x",
"gtruth_answer": "sqrt(a - 1/4) - 1/2",
"message_thinking": "To solve this equation, let's start by squaring both sides...",
"message_content": "The sum of real solutions is \\boxed{\\sqrt{a - 1/4} - 1/2}."
}其中 message_thinking 存储教师的完整推理过程——包括尝试、回溯、验证等思考轨迹;message_content 存储经过整理的最终回答。在训练时,需要将二者拼接为带有格式标签的完整序列:
def format_distilled_answer(entry, use_think_tokens=False):
"""将蒸馏数据的思考过程和最终回答拼接为训练目标"""
content = entry["message_content"].strip()
thinking = entry.get("message_thinking", "").strip()
# 清除可能已存在的标签,避免嵌套
for tag in ["<think>", "</think>"]:
content = content.replace(tag, "")
thinking = thinking.replace(tag, "")
if use_think_tokens:
# 使用显式标签包裹思考过程
return f"<think>{thinking}</think>\n\n{content}"
# 不使用标签时,直接拼接
if thinking:
return f"{thinking}\n\n{content}"
return content这个函数的核心设计决策是 use_think_tokens 参数。当启用时,教师的思考过程被 <think>...</think> 标签显式包裹,学生模型在训练中会学到:遇到推理问题时,先在 <think> 标签内展开详细思考,然后在 </think> 之后给出简洁的最终答案。这种格式约束对推理蒸馏至关重要,因为它教会了学生模型"何时开始思考、何时结束思考"的结构化能力。
14.3.2 思考格式约束训练
推理蒸馏中最核心的技术挑战是:如何让学生模型精确掌控推理格式的起止?这不仅是文本生成的问题,更是一个结构化控制的问题——模型必须学会在正确的时刻输出 <think> 和 </think> 标签,并在标签内展开有意义的推理。
思考标签 Token 的特殊处理。 DeepSeek-R1 在训练推理模型时,使用了格式奖励(Format Reward) 来强制模型将推理过程置于 <think> 和 </think> 标签之间。在蒸馏场景中,虽然不使用 RL,但可以通过对特殊标签 Token 施加更高的损失权重来达到类似效果。具体做法是:在标准的交叉熵损失基础上,对 <think>、</think> 等结构控制 Token 的预测错误施加 10 倍惩罚。
以下代码展示了这种加权损失的实现:
import torch
import torch.nn as nn
def compute_reasoning_weighted_loss(logits, targets, loss_mask, special_token_ids, device, weight=10.0):
"""对推理控制标签施加高权重的交叉熵损失
Args:
logits: 模型输出 [batch_size, seq_len, vocab_size]
targets: 目标 token ids [batch_size, seq_len]
loss_mask: 损失掩码 [batch_size, seq_len],1 表示需要计算损失
special_token_ids: 推理控制标签的 token id 列表(如 <think>, </think>)
device: 计算设备
weight: 特殊标签的损失权重倍数
"""
loss_fn = nn.CrossEntropyLoss(reduction="none")
# 计算每个位置的交叉熵损失
per_token_loss = loss_fn(
logits.view(-1, logits.size(-1)),
targets.view(-1)
).view(targets.size()) # [batch_size, seq_len]
# 找出目标序列中的特殊标签位置
flat_targets = targets.view(-1)
is_special = torch.isin(
flat_targets,
torch.tensor(special_token_ids, device=device)
) # [batch_size * seq_len] 的布尔张量
# 修改损失掩码:特殊标签位置的权重提升为 weight 倍
weighted_mask = loss_mask.clone().view(-1)
original_mask_sum = weighted_mask.sum() # 用未修改的掩码和作为归一化分母
weighted_mask[is_special] = weight
weighted_mask = weighted_mask.view(targets.size())
# 加权求和后归一化
loss = (per_token_loss * weighted_mask).sum() / original_mask_sum
return loss为什么分母使用未加权的掩码和? 这是一个容易被忽略但至关重要的设计选择。如果分母也使用加权后的掩码和,那么特殊标签的高权重会被归一化"稀释",实际梯度幅度不会增大。而使用未加权分母意味着分子被放大(部分 Token 乘以 10)而分母不变,相当于人为放大了特殊标签位置的梯度幅度,强迫模型优先学会正确预测这些结构控制标签。
以一个简化示例说明加权效果:
| Token 位置 | 原始损失 | 掩码 | 是否特殊 | 加权后掩码 | 加权损失项 |
|---|---|---|---|---|---|
| "首先" | 2.0 | 1.0 | 否 | 1.0 | 2.0 |
<think> | 3.0 | 1.0 | 是 | 10.0 | 30.0 |
| "我需要..." | 1.5 | 1.0 | 否 | 1.0 | 1.5 |
</think> | 2.5 | 1.0 | 是 | 10.0 | 25.0 |
| "答案是" | 1.0 | 1.0 | 否 | 1.0 | 1.0 |
- 未加权总损失:
- 加权后总损失:
可以看到,加权后模型的梯度会被特殊标签的预测错误强烈驱动,迫使模型优先学会在正确位置生成推理格式标签。
14.3.3 推理蒸馏的 tokenizer 选择
推理模型通常使用专门的 reasoning tokenizer(推理分词器),它在标准词表中额外注册了 <think> 和 </think> 等特殊标记。这与使用 base tokenizer(基础分词器)的学生模型存在差异。
在蒸馏训练中,是否使用 reasoning tokenizer 是一个关键选择:
# 根据是否启用思考标签选择对应的 tokenizer
tokenizer_variant = "reasoning" if use_think_tokens else "base"
tokenizer = load_tokenizer(which_model=tokenizer_variant)使用 reasoning tokenizer 时,<think> 和 </think> 各被编码为单个特殊 Token,而非多个子词碎片。这使得模型能够以最低的学习成本掌握格式控制——它只需要在正确位置预测一个 Token,而不是正确拼接多个字符。
以下是两种 tokenizer 编码同一段推理文本的差异示意:
text = "<think>先分析等式两边...</think>\n\n答案是 42。"
# base tokenizer: <think> 被拆分为多个子词
# ["<", "think", ">", "先", "分析", "等式", "两边", "...", "<", "/", "think", ">", ...]
# 12 个 token 仅用于格式控制
# reasoning tokenizer: <think> 和 </think> 各为单个特殊 token
# ["<think>", "先", "分析", "等式", "两边", "...", "</think>", ...]
# 仅 2 个 token 用于格式控制实验表明,使用 reasoning tokenizer 训练的学生模型在推理基准测试上表现更好——因为格式控制的认知负担更低,模型可以将更多"容量"分配给推理内容本身的学习。
14.3.4 蒸馏数据生成的两条路径
推理蒸馏数据的生成是整个流程中最耗时、最昂贵的环节。根据教师模型的部署方式,存在两条截然不同的路径:本地推理和云端 API 调用。
路径一:本地推理生成。 对于参数量可在本地运行的教师模型(如 DeepSeek-R1 的 8B/32B 蒸馏版),可以通过 Ollama 等本地推理引擎生成蒸馏数据。核心是启用 think: True 参数,让模型在推理时分离出思考过程:
import json
import urllib.request
def generate_with_local_model(problem, model="deepseek-r1:32b",
base_url="http://localhost:11434"):
"""通过本地 Ollama 服务生成带有思考过程的教师输出"""
# 构造 Ollama Chat API 的请求体,启用思考模式
payload = {
"model": model,
"messages": [{"role": "user", "content": problem}],
"think": True, # 启用思考模式,分离 thinking 和 content
"stream": False,
"options": {"num_predict": 8192, "temperature": 0.0}
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(
url=f"{base_url}/api/chat",
data=data,
headers={"Content-Type": "application/json"},
method="POST"
)
# 发送请求并从返回中分别提取思考过程和最终回答
with urllib.request.urlopen(req, timeout=600) as resp:
result = json.loads(resp.read().decode("utf-8"))
message = result["message"]
return {
"message_thinking": message.get("thinking", ""),
"message_content": message.get("content", "")
}本地生成的优势是零 API 成本,适合使用中等规模教师模型(如 32B)进行实验。缺点是受限于本地硬件——DeepSeek-R1 32B 需要约 60 GB 内存,且生成速度受 GPU 性能制约。
路径二:云端 API 调用生成。 对于超大规模的教师模型(如 DeepSeek-R1 671B、Qwen3-235B),必须通过云端 API 生成数据。以 OpenRouter 为例:
import json
import urllib.request
import os
def generate_with_api(problem, model="deepseek/deepseek-r1"):
"""通过 OpenRouter API 调用大型教师模型生成推理蒸馏数据"""
api_key = os.environ["OPENROUTER_API_KEY"]
# 构造 OpenAI 兼容格式的请求体
payload = {
"model": model,
"messages": [{"role": "user", "content": problem}],
"stream": False,
"max_tokens": 2048,
"temperature": 0.0
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(
url="https://openrouter.ai/api/v1/chat/completions",
data=data,
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
},
method="POST"
)
# 发送请求并解析响应中的推理过程与最终内容
with urllib.request.urlopen(req, timeout=600) as resp:
result = json.loads(resp.read().decode("utf-8"))
choice = result["choices"][0]["message"]
return {
"message_thinking": choice.get("reasoning_content", ""),
"message_content": choice.get("content", "")
}注意 API 返回中,不同服务商对思考过程字段的命名不一致:OpenRouter 使用 reasoning_content,Ollama 使用 thinking,其他平台可能使用 reasoning 等。实际工程中需要对多种字段名做兼容处理。
14.3.5 成本控制策略
推理蒸馏的数据生成成本主要来自教师模型的推理开销。推理模型的输出通常非常长——一道中等难度的数学题,思考过程可能长达 1000-2000 token,最终回答约 100-300 token。这意味着输出 token 成本远高于输入 token 成本。
以 DeepSeek-R1(671B)通过 OpenRouter 生成 MATH 数据集为例,成本估算如下:
| 项目 | 数值 |
|---|---|
| 平均输入长度 | ~11 token |
| 平均输出长度 | ~1524 token(含思考过程) |
| 输入价格 | $0.70 / 百万 token |
| 输出价格 | $2.50 / 百万 token |
| 生成 1000 条数据的成本 | ~$3.82 |
| 生成 12000 条数据的成本 | ~$46 |
表 14-4:使用 DeepSeek-R1 通过 OpenRouter 生成推理蒸馏数据的成本估算。
针对这一成本结构,有以下关键优化策略:
并行请求。 顺序生成 12000 条数据约需 100 小时。通过设置 --num_processes 50 使用 50 个并行线程,可将时间压缩到约 2 小时。实现方式是使用线程池并行发送 API 请求,同时保证结果按原始顺序写入:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import concurrent.futures
def parallel_generate(problems, num_processes=50, **kwargs):
"""并行生成蒸馏数据,支持断点续传"""
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=num_processes) as executor:
# 提交所有任务
futures = {
executor.submit(generate_with_api, p["problem"], **kwargs): i
for i, p in enumerate(problems)
}
# 按完成顺序收集结果
completed = {}
for future in concurrent.futures.as_completed(futures):
idx = futures[future]
completed[idx] = future.result()
# 按原始顺序整理结果
for i in range(len(problems)):
results.append(completed[i])
return results增量保存与断点续传。 推理蒸馏的数据生成周期很长(数小时到数十小时),进程随时可能被中断。因此必须实现增量写入——每完成一条就立即保存到磁盘,并支持通过 --resume 参数从中断点继续:
import json
from pathlib import Path
def save_incremental(rows, out_file):
"""增量保存:先写入临时文件,再原子替换"""
out_path = Path(out_file)
tmp_path = out_path.with_name(f"{out_path.name}.tmp")
with tmp_path.open("w", encoding="utf-8") as f:
json.dump(rows, f, indent=2, ensure_ascii=False)
tmp_path.replace(out_path) # 原子操作,避免写入中断导致数据损坏选择更高效的教师模型。 并非所有场景都需要最大的教师模型。实验数据表明,同家族的较小教师模型可能比跨家族的更大模型效果更好。例如,使用 Qwen3-235B 蒸馏 Qwen3-0.6B 的效果(MATH-500 准确率 45.0%)显著优于使用 DeepSeek-R1 671B 蒸馏同一学生模型的效果(30.6%)。这提示我们:在选择教师模型时,词表兼容性和架构相似性可能比绝对能力更重要。
控制输出长度。 推理模型的思考过程往往冗长。通过设置 max_tokens(API 调用)或 num_predict(本地推理)参数限制输出长度,可以在保证推理质量的前提下显著降低 token 消耗。实践中 2048-4096 token 的上限通常能覆盖大多数数学推理题。
14.3.6 推理蒸馏的完整训练流程
将上述组件整合,推理蒸馏的完整训练流程如下:
第一步:构建训练样本。 将蒸馏数据中的每条记录转换为 [prompt_ids] + [answer_ids] + [eos] 形式的 token 序列,同时记录 prompt 的长度,以便后续构建 loss mask:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
def build_training_examples(data, tokenizer, max_seq_len=2048, use_think_tokens=True):
"""将蒸馏数据转换为训练样本"""
examples = []
skipped = 0
for entry in data:
try:
# 构建 prompt
prompt = (
"You are a helpful math assistant.\n"
f"Answer the question and write the final result as: "
f"\\boxed{{ANSWER}}\n\nQuestion:\n{entry['problem']}\n\nAnswer:"
)
# 构建目标回答(含思考过程)
target = format_distilled_answer(entry, use_think_tokens=use_think_tokens)
prompt_ids = tokenizer.encode(prompt)
answer_ids = tokenizer.encode(target, add_special_tokens=False)
eos_id = [tokenizer.eos_token_id] if tokenizer.eos_token_id else []
token_ids = prompt_ids + answer_ids + eos_id
# 过滤超长样本
if len(token_ids) > max_seq_len or len(token_ids) < 2:
skipped += 1
continue
prompt_len = len(prompt_ids)
examples.append({"token_ids": token_ids, "prompt_len": prompt_len})
except (KeyError, TypeError, ValueError):
skipped += 1
print(f"构建完成:{len(examples)} 条有效样本,跳过 {skipped} 条")
return examples第二步:训练循环。 训练循环的核心是只在回答部分计算损失(prompt 部分的损失权重为 0),使用 AdamW 优化器和梯度裁剪:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
import torch.nn.functional as F
def train_one_example(model, example, device):
"""对单条样本计算 answer-only 交叉熵损失"""
token_ids = example["token_ids"]
prompt_len = example["prompt_len"]
# 输入是 token_ids[:-1],目标是 token_ids[1:]
input_ids = torch.tensor(token_ids[:-1], dtype=torch.long, device=device).unsqueeze(0)
target_ids = torch.tensor(token_ids[1:], dtype=torch.long, device=device)
logits = model(input_ids).squeeze(0) # [seq_len-1, vocab_size]
# 只在回答部分计算损失
answer_start = max(prompt_len - 1, 0)
answer_logits = logits[answer_start:]
answer_targets = target_ids[answer_start:]
loss = F.cross_entropy(answer_logits, answer_targets)
return loss
def train_distillation(model, train_examples, val_examples, device,
epochs=3, lr=1e-5, grad_clip=1.0):
"""推理蒸馏训练主循环"""
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
model.train()
for epoch in range(1, epochs + 1):
epoch_loss = 0.0
for i, example in enumerate(train_examples):
optimizer.zero_grad()
loss = train_one_example(model, example, device)
loss.backward()
# 梯度裁剪防止爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
optimizer.step()
epoch_loss += loss.item()
if (i + 1) % 100 == 0:
avg = epoch_loss / (i + 1)
print(f"[Epoch {epoch}] Step {i+1}, train_loss={avg:.4f}")
# epoch 结束后评估验证集
val_loss = evaluate(model, val_examples, device)
print(f"Epoch {epoch} 完成, val_loss={val_loss:.4f}")
torch.save(model.state_dict(), f"distill_epoch{epoch}.pth")
@torch.no_grad()
def evaluate(model, examples, device):
"""在验证集上计算平均损失"""
model.eval()
total_loss = sum(
train_one_example(model, ex, device).item() for ex in examples
)
model.train()
return total_loss / len(examples)关键训练超参数。 推理蒸馏的训练超参数选择与普通 SFT 有所不同:
| 超参数 | 推荐范围 | 说明 |
|---|---|---|
| 学习率 | 推理蒸馏使用更保守的学习率 | |
| 最大序列长度 | 2048 ~ 4096 | 推理轨迹通常比普通回答长得多 |
| 训练轮数 | 1 ~ 3 | 过多轮数容易过拟合(见下文实验) |
| 梯度裁剪 | 1.0 | 防止长序列导致的梯度爆炸 |
| 优化器 | AdamW | 标准选择 |
14.3.7 实验结果与分析
下表汇总了在 Qwen3-0.6B 学生模型上的推理蒸馏实验结果(使用 MATH-500 作为评测基准):
| 模型配置 | 教师模型 | 轮数 | MATH-500 准确率 | 验证损失 |
|---|---|---|---|---|
| Base(无蒸馏) | - | - | 15.2% | - |
| Reasoning(内置推理) | - | - | 48.2% | - |
| DeepSeek-R1 蒸馏 | DeepSeek-R1 (671B) | 1 | 30.6% | 0.5436 |
| DeepSeek-R1 蒸馏 | DeepSeek-R1 (671B) | 2 | 32.4% | 0.5349 |
| DeepSeek-R1 蒸馏 | DeepSeek-R1 (671B) | 3 | 33.6% | 0.5343 |
| Qwen3-235B 蒸馏 | Qwen3-235B-A22B | 1 | 45.0% | 0.4043 |
| Qwen3-235B 蒸馏 | Qwen3-235B-A22B | 2 | 43.8% | 0.3963 |
| Qwen3-235B 蒸馏 | Qwen3-235B-A22B | 3 | 44.2% | 0.3948 |
表 14-5:不同教师模型的推理蒸馏效果对比。训练配置:lr=1e-5,max_seq_len=2048,use_think_tokens=True,grad_clip=1.0。
图 14-4:推理蒸馏训练曲线示例。左图为训练 loss 的下降过程,中图为学习率调度,右图为每步耗时统计。
从实验结果可以提炼出几个关键发现:
发现一:教师-学生的架构亲和度至关重要。 同家族的 Qwen3-235B 蒸馏效果(45.0%)远优于跨家族的 DeepSeek-R1(30.6%),尽管后者的绝对推理能力更强。这说明在推理蒸馏中,tokenizer 兼容性、内部表示空间的对齐、以及推理风格的一致性比教师模型的绝对性能更加关键。
发现二:推理蒸馏对过拟合敏感。 Qwen3-235B 蒸馏在第 1 轮即达到峰值(45.0%),第 2-3 轮反而下降到 43.8%。验证损失持续降低但测试准确率下降,呈现出典型的过拟合信号。这提示推理蒸馏应该使用较少的训练轮数(1-2 轮),或引入 early stopping。
发现三:蒸馏效果极为显著。 即使只有 0.6B 参数的微型模型,经过 Qwen3-235B 蒸馏后在 MATH-500 上达到 45.0%,接近其自带推理模式(48.2%)的水平。而未蒸馏的 base 模型仅有 15.2%——蒸馏带来了近 3 倍的准确率提升。
14.3.8 蒸馏 vs. 纯 RL:两条通往推理能力的路径
推理蒸馏的另一个重要发现来自 DeepSeek-R1 的官方实验:在相同参数量下,蒸馏路线全面优于纯 RL 训练路线。
DeepSeek-R1 论文中对比了两种获取推理能力的方式——直接在小模型上进行大规模 RL 训练(DeepSeek-R1-Zero-Qwen-32B),以及使用 DeepSeek-R1 的 800k 蒸馏数据对同一小模型进行 SFT(DeepSeek-R1-Distill-Qwen-32B)。结果显示,蒸馏模型在 AIME 2024 上取得 72.6%(pass@1),而纯 RL 模型仅有 47.0%;在 MATH-500 上分别是 94.3% vs. 91.6%。
这一对比揭示了推理蒸馏的深层优势:
- 效率优势:蒸馏只需 SFT 训练,计算成本远低于大规模 RL
- 质量优势:教师模型经过 RL 训练后生成的推理轨迹质量极高,学生可以直接"站在巨人的肩膀上"
- 稳定性优势:SFT 训练过程稳定可控,不存在 RL 中常见的奖励破解(reward hacking)和训练不稳定等问题
DeepSeek-R1 团队据此得出一个重要结论:对于小模型而言,从高质量教师数据中学习(蒸馏)比自己从零开始探索(纯 RL)要高效得多。 RL 更适合用于训练大型教师模型,而蒸馏是将推理能力高效传递给小模型的最佳路径。
本节小结。 推理模型蒸馏的核心在于将教师模型的结构化思考能力——而非仅仅是最终答案——迁移给学生模型。相比普通 SFT 蒸馏,推理蒸馏引入了三个关键技术要素:(1)思考格式约束训练,通过 <think>...</think> 标签和特殊 Token 加权损失,教会模型掌控推理的起止;(2)专用 reasoning tokenizer,降低格式学习负担;(3)成本控制策略,通过并行请求、增量保存和教师模型选择优化数据生成开销。实验表明,即使是 0.6B 的微型模型,经过高质量推理蒸馏也能获得接近其内置推理模式的数学推理能力,而蒸馏路线在效率和效果上全面优于对小模型直接进行 RL 训练。