附录B:AlphaGo 与博弈 AI
围棋曾被视为人工智能的"圣杯"——一个简单到任何人都能学会规则、复杂到让最强算法束手无策的博弈问题。2016 年 3 月,DeepMind 的 AlphaGo 以 4:1 击败世界冠军李世石,成为人工智能历史上的标志性时刻。这一成就并非简单地"暴力计算"获胜,而是深度学习与蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)的精妙结合。本附录将完整回顾从 AlphaGo 到 MuZero 的技术演进脉络,并探讨这些思想如何在大语言模型的推理时代获得新生。
阅读本附录前:建议先阅读第 15 章(强化学习基础)中关于策略梯度、价值函数和 Actor-Critic 的内容。本附录会用到这些概念,但侧重于它们在博弈 AI 中的具体应用。
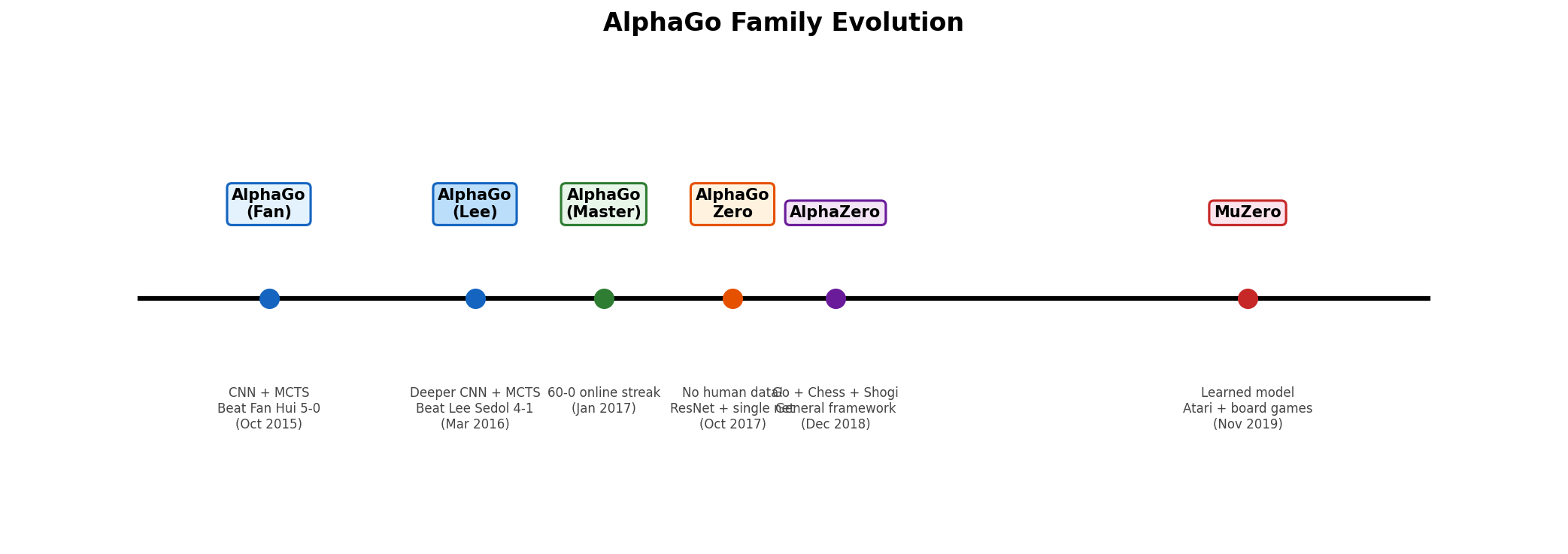
图 B-1:AlphaGo 家族的演化时间线,从依赖人类棋谱的 AlphaGo 到完全自学的 AlphaZero,再到学习环境模型的 MuZero。
B.1 围棋 AI 的历史挑战
围棋是一个
搜索空间的爆炸。围棋每步大约有 250 种合法走法(国际象棋约 35 种),一盘棋平均持续约 150 手。这意味着博弈树的规模约为
评估函数的困难。与国际象棋不同,围棋局面极难用手工规则评估。一个看似劣势的局面可能隐藏着精妙的反击手段,而一个看似安全的局面可能在数十手之后暴露致命弱点。棋子之间的远距离联系和复杂的"死活"问题让传统的启发式评估函数几乎无法奏效。
传统方法的进展与瓶颈。在 AlphaGo 之前,围棋 AI 的发展可以分为几个阶段:
| 时期 | 代表方法 | 棋力水平 |
|---|---|---|
| 1960s-1990s | 手工规则 + 模式匹配 | 业余初学者 |
| 2000s | 蒙特卡洛方法 (MC) | 业余低段 |
| 2006-2015 | MCTS (UCT) | 业余高段至职业低段 |
| 2016 | AlphaGo (深度学习 + MCTS) | 超越人类世界冠军 |
表 B-1:围棋 AI 棋力的历史演进。
2006 年 Rémi Coulom 提出的 MCTS 算法是围棋 AI 发展的一个重要转折点。它通过随机模拟(rollout)来估计局面价值,绕过了构造评估函数的难题。然而纯 MCTS 的棋力仍然有限,因为随机 rollout 的质量太低,难以准确反映局面的真实价值。

图 B-2:围棋棋盘。
B.2 蒙特卡洛树搜索(MCTS)
MCTS 是理解 AlphaGo 家族的核心基础。它的基本思想是:通过大量随机模拟来估计每个走法的好坏,而非试图穷举所有可能。
MCTS 的每次迭代包含四个阶段:
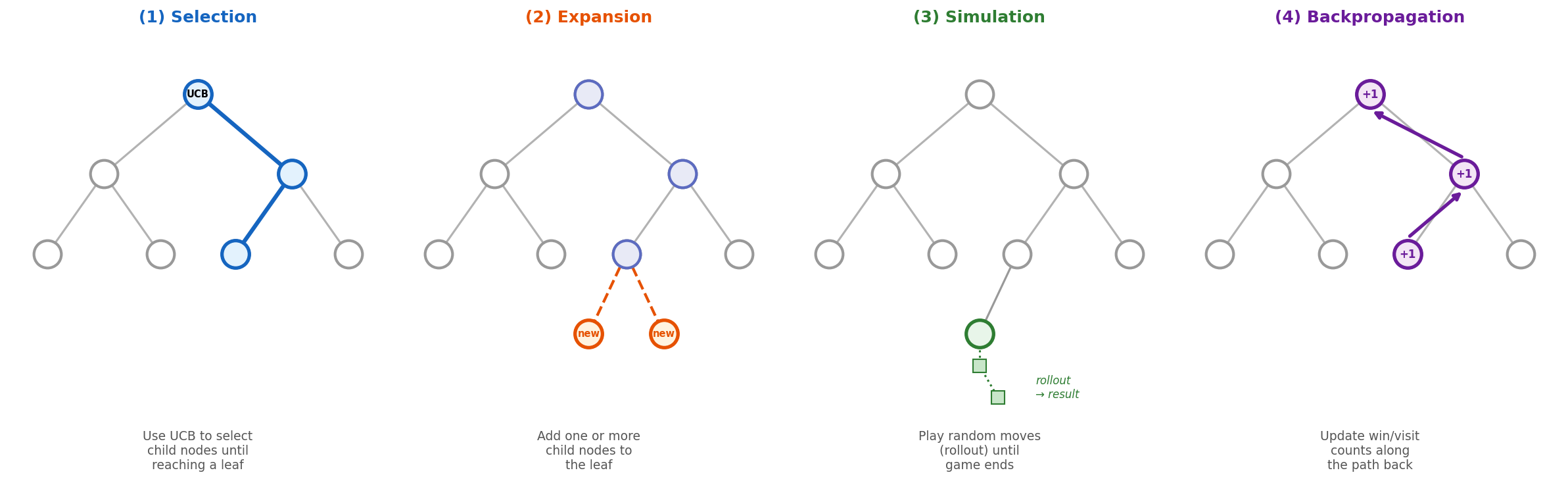
图 B-3:MCTS 的四个阶段——选择、扩展、模拟、回溯。每次迭代通过这四步逐步构建并精化搜索树。
(1)选择(Selection)。从根节点出发,根据特定策略选择子节点,直到到达一个尚未完全展开的节点。选择策略通常使用 UCB1(Upper Confidence Bound)公式:
其中
(2)扩展(Expansion)。在选定的叶子节点处,添加一个或多个新的子节点到搜索树中。
(3)模拟(Simulation / Rollout)。从新扩展的节点出发,使用某种策略(最简单的是随机走子)一路模拟到游戏结束,得到一个胜负结果。
(4)回溯(Backpropagation)。将模拟结果沿着选择路径回传,更新路径上每个节点的访问计数和胜率统计。
经过大量迭代后,根节点处访问次数最多的动作通常就是最优选择。MCTS 的一个关键优势是:它不需要评估函数,只需要一个环境模拟器来完成 rollout。但它的瓶颈也很明显——随机 rollout 的质量决定了估计的准确性。这正是深度学习介入的切入点。
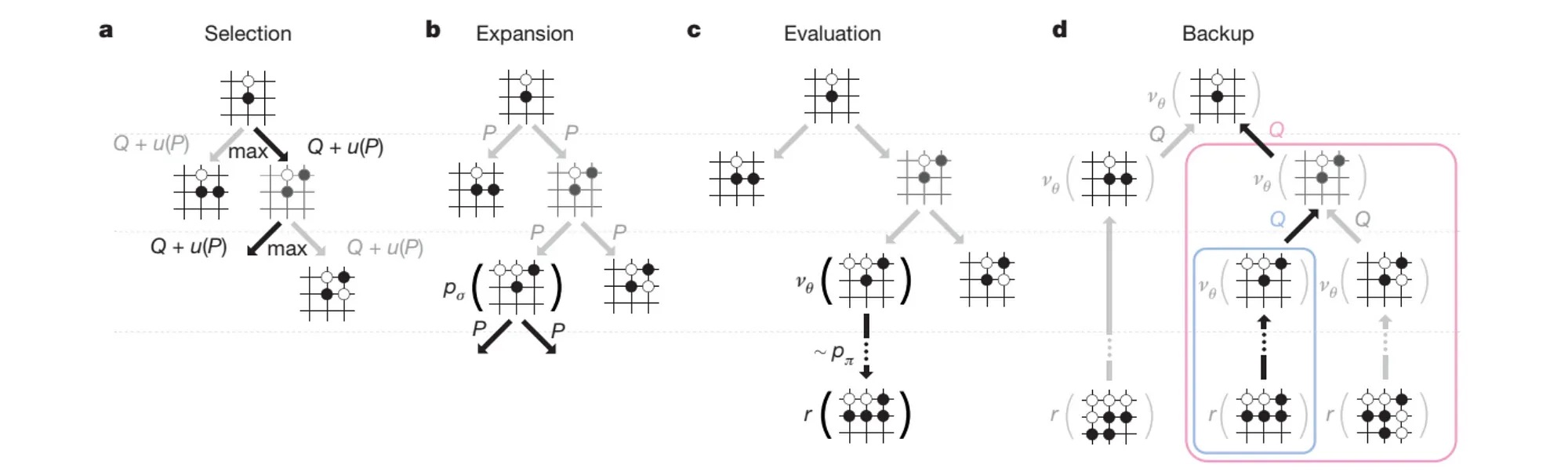
图 B-4:AlphaGo 论文中 MCTS 的四阶段示意图(来源:Silver et al., 2016)。(a) Selection 阶段使用
B.3 AlphaGo(2016):策略网络 + 价值网络 + MCTS
AlphaGo 的突破在于用深度卷积神经网络(CNN)来同时解决 MCTS 的两个瓶颈:一是提供高质量的走子先验(替代随机展开),二是提供准确的局面评估(替代低质量 rollout)。
B.3.1 棋盘状态的表示
AlphaGo 将棋盘状态编码为一个多通道的
- 局部性(locality):每颗棋子主要与周围的棋子发生交互
- 平移不变性(translation invariance):同样的局部模式(如"虎口"、"征子")在棋盘不同位置的含义相同
每个通道编码一种特征,例如:己方棋子位置、对方棋子位置、空位、各子的气数、上一步落子位置(用于劫争规则)等。这种多通道表示使得 CNN 可以直接处理棋盘局面,如同处理一张彩色图像。
B.3.2 四阶段训练流程
AlphaGo 的训练分为四个阶段,形成一条逐步提升的流水线:
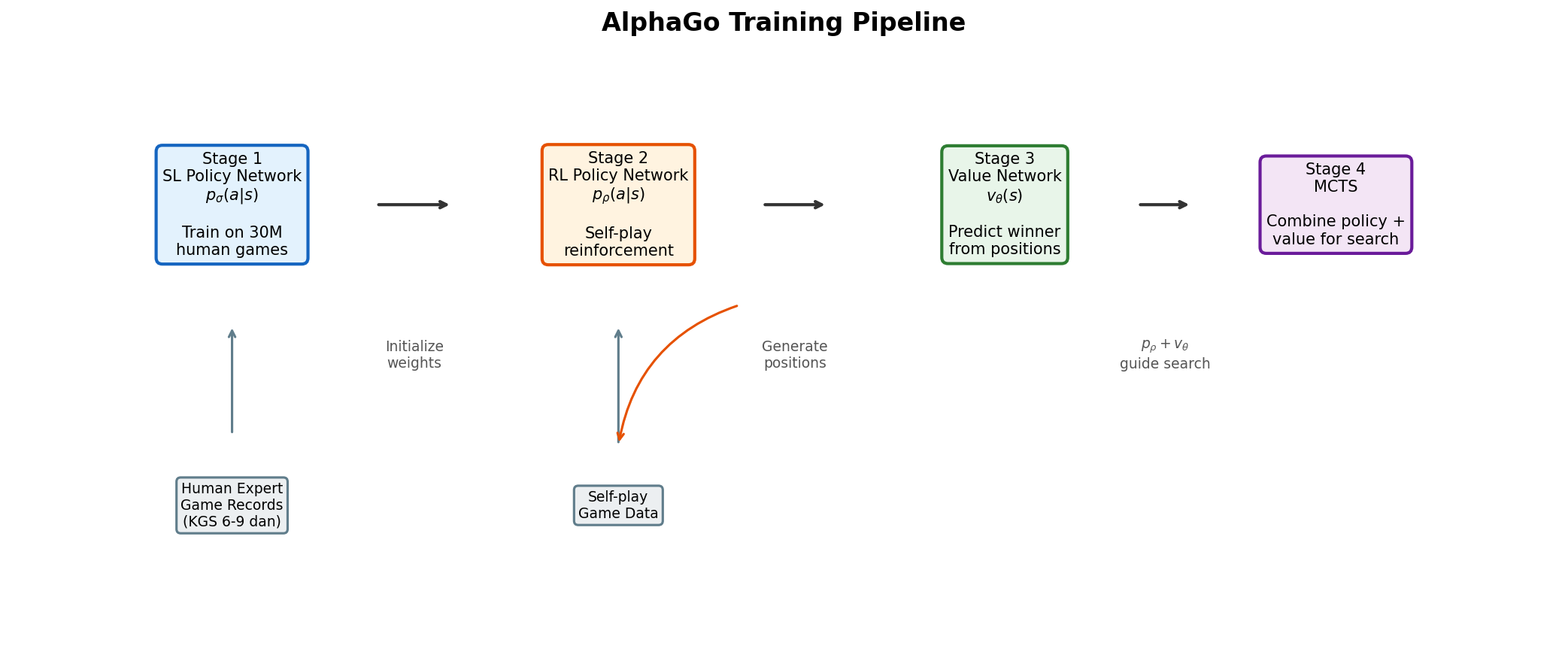
图 B-5:AlphaGo 的四阶段训练流水线。从人类棋谱出发监督训练策略网络,再通过自博弈强化学习训练增强版策略网络,进而训练价值网络,最终与 MCTS 搜索结合。
阶段 1:监督学习策略网络
使用来自 KGS 围棋服务器的约 3000 万局人类专家棋谱,训练一个 13 层 CNN 来预测人类的下一手。这本质上是一个
同时还训练了一个更小更快的 rollout 策略网络
阶段 2:强化学习策略网络
以 SL 策略网络的权重为初始化,通过自博弈(self-play)进行 REINFORCE 策略梯度训练。具体做法是让当前策略与历史版本的策略对弈,胜者获得
其中
阶段 3:价值网络
训练一个结构类似策略网络但输出为单一标量的 CNN,用于预测当前局面下 RL 策略网络自博弈的预期胜率:
训练数据来自 RL 策略网络自博弈产生的 3000 万个局面。需要注意的是,为了避免过拟合(连续局面高度相关),每盘棋只随机采样一个局面用于训练。
阶段 4:MCTS 搜索
在实际对弈时,AlphaGo 使用经过深度学习增强的 MCTS:
- 选择阶段使用策略网络的输出
作为先验,修改 UCB 公式为:
- 评估阶段结合价值网络和快速 rollout 两种评估:
其中
这种"神经网络 + 搜索"的组合产生了巨大的协同效应:策略网络缩小了搜索宽度(不再考虑所有 250 个走法),价值网络减少了搜索深度(不再需要模拟到终局),而 MCTS 框架则为神经网络的输出提供了系统性的纠错机制。
关键洞察:单独使用策略网络或价值网络的棋力都远不及 MCTS 搜索的组合效果。AlphaGo 论文中报告,纯策略网络的 Elo 评分约 2100,纯价值网络约 2200,而完整 MCTS 系统达到了约 3700——这正是"搜索"带来的力量。
B.4 AlphaGo Zero(2017):从零自博弈
AlphaGo Zero(Silver et al., 2017)是一次革命性的简化。它证明了一个惊人的结论:不需要任何人类棋谱,纯粹从随机初始化出发,仅通过自博弈就能超越所有人类棋手的水平。
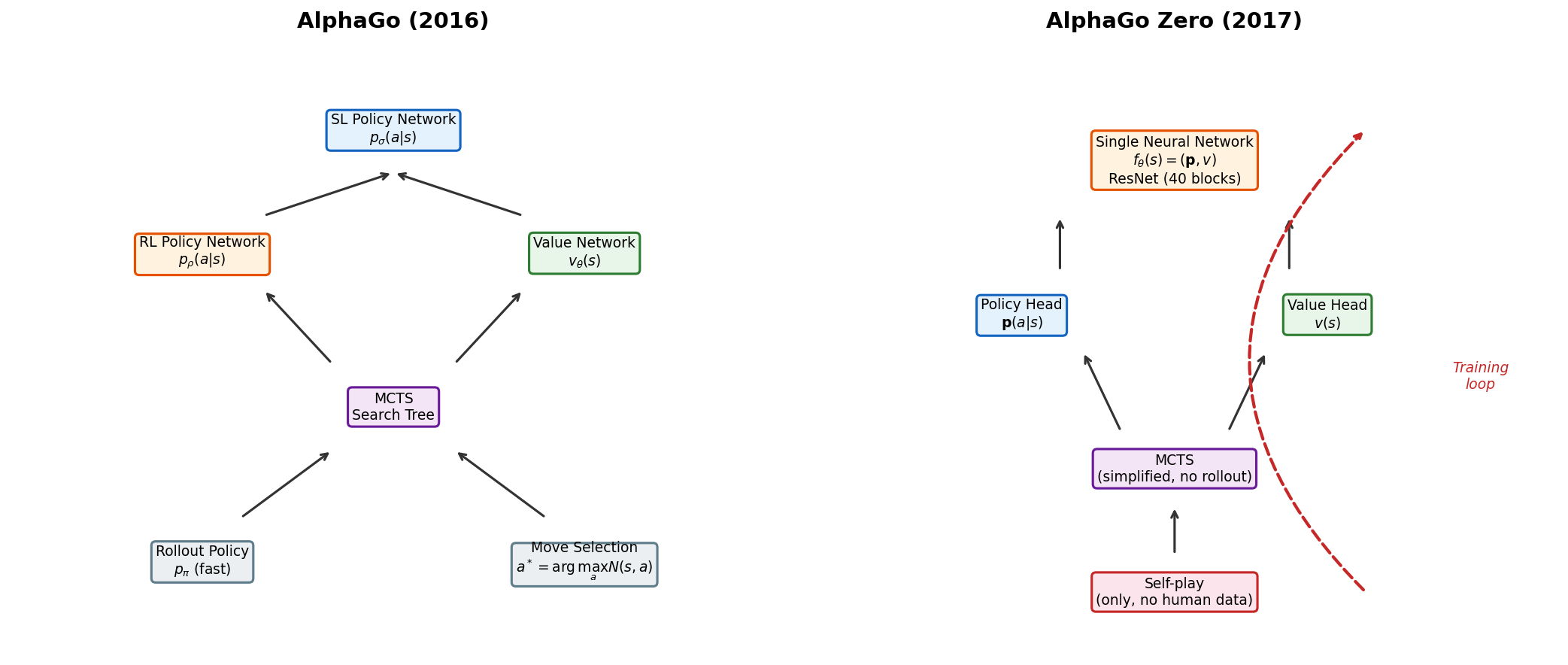
图 B-6:AlphaGo 原版与 AlphaGo Zero 的架构对比。Zero 版本用一个双头 ResNet 统一了策略网络和价值网络,去除了人类棋谱和 rollout。
B.4.1 关键简化
与 AlphaGo 相比,AlphaGo Zero 做了以下关键简化:
| AlphaGo | AlphaGo Zero | |
|---|---|---|
| 人类棋谱 | 3000 万局 | 无 |
| 网络结构 | 两个独立 CNN(13 层) | 一个双头 ResNet(40 个残差块) |
| 输入特征 | 手工设计的 48 个通道 | 仅黑白子位置(17 个通道) |
| 训练方法 | SL → RL → 价值网络(分阶段) | 统一的自博弈训练 |
| MCTS 评估 | 价值网络 + rollout 混合 | 仅价值网络(无 rollout) |
| 棋盘对称性 | 未利用 | 数据增强(8 种对称变换) |
表 B-2:AlphaGo 与 AlphaGo Zero 的关键差异。
B.4.2 统一的双头网络
AlphaGo Zero 使用单个深度残差网络(ResNet)同时输出策略和价值:
其中
- 策略头(Policy Head):卷积层 → 全连接层 → softmax →
- 价值头(Value Head):卷积层 → 全连接层 → tanh →
B.4.3 自博弈训练循环
AlphaGo Zero 的训练是一个优雅的闭环:
使用当前网络 + MCTS 进行自博弈,生成完整对局数据。MCTS 搜索产生的改进策略
成为策略头的训练目标,对局结果 成为价值头的训练目标。 训练网络以同时最小化策略损失和价值损失:
这个损失函数的第一项是价值预测的均方误差,第二项是策略的交叉熵损失(让网络学习 MCTS 的搜索结果),第三项是 L2 正则化。
- 用更新后的网络替换旧网络,继续自博弈。
这里有一个深刻的自我提升机制:MCTS 搜索的结果
B.4.4 训练结果
AlphaGo Zero 从完全随机开始,经过约 3 天的训练(490 万盘自博弈),就超越了击败李世石的 AlphaGo 版本。经过约 40 天的训练,它超越了此前最强的 AlphaGo Master(曾在线上以 60:0 击败所有人类顶尖棋手)。
最终 AlphaGo Zero 对阵 AlphaGo 的战绩是 100:0。
B.5 AlphaZero(2018):通用化博弈 AI
AlphaZero(Silver et al., 2018)将 AlphaGo Zero 的方法推广到了三种完全不同的棋类游戏——围棋、国际象棋和将棋(日本象棋)——使用完全相同的算法框架,仅改变游戏规则。
B.5.1 从围棋专用到通用框架
AlphaZero 相对于 AlphaGo Zero 的主要变化包括:
- 去除围棋特有的假设:不再利用棋盘的旋转/反射对称性进行数据增强,因为国际象棋和将棋不具备这种对称性。
- 统一的终局处理:支持胜/负/和三种结局(围棋通常没有和棋,但国际象棋和将棋有)。
- 连续更新:不再周期性地评估和替换最佳网络,而是始终使用最新的网络参数。
B.5.2 在国际象棋领域的突破
AlphaZero 在国际象棋上的表现尤其引人注目。仅经过 4 小时的训练,它就超越了 Stockfish——一个经过数十年手工调优的、当时最强的国际象棋引擎。在 1000 盘对弈中,AlphaZero 以 155 胜 6 负 839 和的成绩碾压 Stockfish。
更令人惊讶的是 AlphaZero 的"棋风"。国际象棋专家评价它的对局"充满了人类般的创造性":它会主动牺牲棋子换取长期的位置优势,展现出一种"直觉式"的棋感,而非传统引擎的"计算式"打法。这暗示了深度学习 + 搜索的范式可能发现了某些人类棋手凭直觉感知但难以形式化表达的策略模式。
B.5.3 统一框架的意义
AlphaZero 证明了一个重要的普适性结论:同一个算法框架(自博弈 + MCTS + 深度神经网络)可以在多种不同的博弈中达到超人水平,而不需要任何特定领域的专家知识。这与传统方法形成了鲜明对比——传统国际象棋引擎(如 Stockfish)依赖数十年积累的手工评估函数和开局库,传统围棋程序需要精心设计的模式库。
B.6 MuZero(2019):学习环境模型
MuZero(Schrittwieser et al., 2020)代表了这一系列工作的又一次飞跃。它解决了 AlphaZero 的一个关键限制:AlphaZero 需要完美地知道游戏规则(即拥有一个精确的环境模拟器来在 MCTS 中推进状态)。MuZero 去除了这一要求——它学习自己的环境模型。
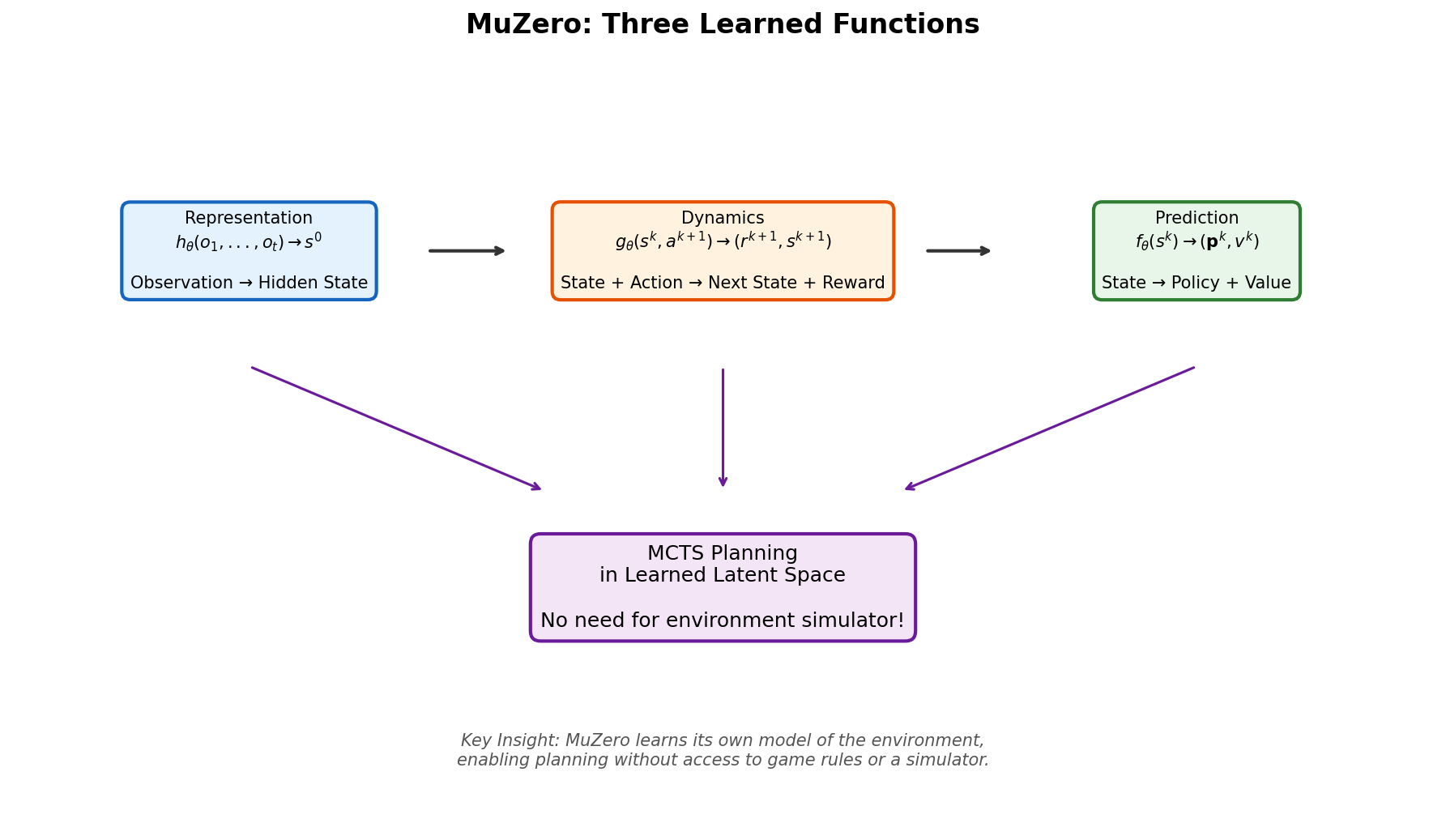
图 B-7:MuZero 的三个核心学习函数。Representation 将观测编码为隐状态,Dynamics 在隐空间中预测状态转移和奖励,Prediction 输出策略和价值。MCTS 规划完全在学习到的隐空间中进行。
B.6.1 三个核心函数
MuZero 学习三个神经网络函数:
表示函数(Representation)
动态函数(Dynamics)
预测函数(Prediction)
B.6.2 在隐空间中规划
MuZero 的 MCTS 搜索完全在学习到的隐空间(latent space)中进行。它不再需要调用真实的环境模拟器来推进状态,而是使用动态函数
- 无需知道游戏规则。MuZero 可以应用于任何环境,包括规则不透明的场景(如 Atari 游戏——你只能看到屏幕像素,不知道内部状态转移逻辑)。
- 隐状态可以只保留与决策相关的信息。真实的游戏状态可能包含大量冗余信息,而学习到的隐状态可以更加紧凑高效。
B.6.3 训练目标
MuZero 的训练通过在"展开"动态函数
其中
B.6.4 实验结果
MuZero 在棋类游戏(围棋、国际象棋、将棋)上匹配了 AlphaZero 的超人表现,同时在 57 款 Atari 游戏上达到了新的最优水平,超越了此前所有的模型驱动和无模型强化学习方法。
从 AlphaGo 到 MuZero 的简化之路:AlphaGo 需要人类棋谱 + 多个网络 + rollout + 环境模拟器;AlphaGo Zero 去掉了人类棋谱和 rollout;AlphaZero 去掉了领域特定假设;MuZero 最终去掉了对环境模拟器的依赖。每一步简化都伴随着更强的泛化能力。
B.7 技术总览:从 AlphaGo 到 MuZero
下表总结了四代系统的关键技术特征:
| 特征 | AlphaGo | AlphaGo Zero | AlphaZero | MuZero |
|---|---|---|---|---|
| 人类数据 | 需要 | 不需要 | 不需要 | 不需要 |
| 网络结构 | 独立的策略/价值 CNN | 双头 ResNet | 双头 ResNet | 表示+动态+预测 |
| 搜索中的评估 | 价值网络 + rollout | 仅价值网络 | 仅价值网络 | 仅价值网络 |
| 环境模拟器 | 需要 | 需要 | 需要 | 不需要(学习模型) |
| 游戏范围 | 仅围棋 | 仅围棋 | 围棋+象棋+将棋 | 棋类 + Atari |
| 训练方法 | SL → RL(分阶段) | 统一自博弈 | 统一自博弈 | 统一自博弈 |
表 B-3:AlphaGo 家族四代系统的关键技术对比。
B.8 从博弈 AI 到大语言模型:MCTS 思想的复用
AlphaGo 家族的成功不仅局限于博弈领域。其核心思想——将神经网络的直觉与系统性搜索相结合——正在大语言模型(LLM)的推理时代找到新的应用场景(参见第 17 章)。
B.8.1 推理即搜索
大语言模型的推理过程可以被类比为一棵搜索树:
| 博弈 AI 概念 | LLM 推理类比 |
|---|---|
| 棋盘状态 | 当前推理上下文(问题 + 已生成的思考步骤) |
| 动作 | 下一个推理步骤 / 下一段文本 |
| 策略网络 | LLM 的 next-token 分布 |
| 价值网络 | 过程奖励模型(PRM)的评分 |
| MCTS 搜索 | 树搜索 / 集束搜索 / Best-of-N 采样 |
| 自博弈改进 | RLVR(基于可验证奖励的强化学习) |
表 B-4:博弈 AI 与 LLM 推理的概念映射。
这个类比揭示了一个深层的结构对应关系。在 AlphaGo 中,策略网络提供搜索的方向,价值网络提供评估的锚点,MCTS 负责在两者之间进行系统化的权衡;在 LLM 推理中,语言模型本身扮演策略网络的角色,过程奖励模型(PRM)或结果奖励模型(ORM)扮演价值网络的角色,而各种搜索策略(如 Tree-of-Thought、beam search)则对应 MCTS 的角色。
B.8.2 推理时间缩放(Test-Time Scaling)
AlphaGo 家族的一个核心经验是:给予更多的搜索时间(计算量)可以持续提升决策质量。这一经验在 LLM 领域被称为推理时间缩放(test-time scaling)——通过在推理阶段投入更多计算来换取更好的输出质量。
OpenAI 的 o1 模型和 DeepSeek-R1 等推理模型验证了这一思路。它们通过训练让模型学会"深度思考"——在给出答案前生成长链条的推理步骤。这与 AlphaGo 的"搜索即改进算子"异曲同工:更多的搜索(思考)步骤带来更好的结果。
正如第 17 章所讨论的,当代推理模型存在两种范式:
- 外部搜索范式:显式地使用树搜索 + 评估函数,如 AlphaGo 的 MCTS。在 LLM 中对应于使用 PRM 引导的集束搜索。
- 内部推理范式:通过训练让模型将搜索过程内化为自然语言思维链,如 o1 和 DeepSeek-R1。模型不再需要外部搜索框架,而是学会了在一条连续的文本序列中完成"内部搜索"。
B.8.3 自博弈与自我改进
AlphaGo Zero 的自博弈训练思想——"用搜索结果作为训练信号来提升网络,再用提升后的网络进行更好的搜索"——同样在 LLM 训练中得到了复用。GRPO(Group Relative Policy Optimization,参见第 16 章)和 RLVR 框架的核心思路就是让模型从自身的探索中学习:对同一问题采样多条推理路径,根据最终答案的正确性计算相对优势,然后强化好的路径、抑制差的路径。
这本质上就是 AlphaGo 自博弈思想的"单人版"——没有对手,但有一个可验证的目标函数作为胜负的判定标准。
B.9 小结与启示
AlphaGo 家族的故事给我们留下了几条深远的启示:
搜索 + 学习 > 纯学习。无论是围棋还是语言推理,单靠神经网络的"直觉"(前馈推理)是不够的。与系统化搜索的结合可以带来质的飞跃。
自监督信号足以驱动超人表现。AlphaGo Zero 证明,在规则明确、结果可验证的领域,完全不需要人类标注数据。这一观察激发了 RLVR 在 LLM 推理训练中的广泛应用。
简化是通往泛化的路径。从 AlphaGo 到 MuZero 的每一代都在做减法——去除人类数据、去除手工特征、去除 rollout、去除环境模拟器——每次减法都带来更强的泛化能力。
计算是一种通用资源。AlphaGo 的 MCTS 和 LLM 的推理时间缩放都指向同一个结论:在推理阶段投入更多计算,可以系统性地提升输出质量。Richard Sutton 在 The Bitter Lesson 中的观察——"搜索和学习是可以无限扩展的两种通用方法"——在这里得到了反复验证。
围棋 AI 的故事远未结束。AlphaGo 家族开创的"深度学习 + 搜索"范式正在从博弈世界扩展到数学定理证明(AlphaProof)、蛋白质结构预测(AlphaFold)、芯片设计等更广泛的领域。而在大语言模型的语境下,如何将 MCTS 的精细搜索与 LLM 的强大生成能力更好地融合,仍然是一个充满想象空间的研究方向。