5.2 训练循环实现
上一节建立了预训练的理论基础——自回归建模定义了预测任务,交叉熵损失量化了预测误差。但从损失函数到一个能真正运行数天乃至数周的训练系统,中间还有大量工程问题需要解决:如何组织一个完整的训练循环?如何防止梯度爆炸导致训练崩溃?如何在训练中途保存状态以应对意外中断?又如何从中断点精确恢复,让训练"无缝续接"?本节将围绕这些问题,从最朴素的训练循环出发,逐步加入梯度裁剪、混合精度训练、学习率调度和检查点机制,最终构建一个具备工业级健壮性的训练框架。
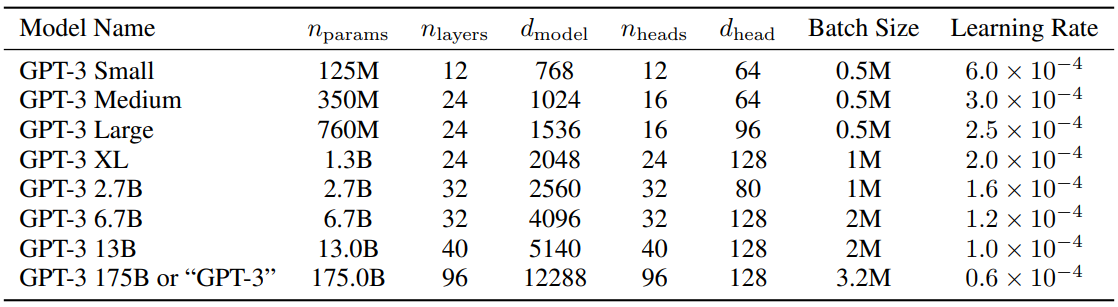
图 5-4:GPT 模型的典型配置参数。不同规模的 GPT-2 变体在嵌入维度、层数和注意力头数上的差异。
5.2.1 基础训练循环
一个最简训练循环的骨架只有四步:前向传播计算损失、反向传播计算梯度、优化器更新参数、清零梯度准备下一步。下面的代码实现了这一基础流程,并在固定间隔评估验证集损失:
import torch
import torch.nn.functional as F
def calc_loss_batch(input_batch, target_batch, model, device):
"""计算一个 batch 的交叉熵损失。"""
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch) # [B, T, V]
loss = F.cross_entropy(
logits.flatten(0, 1), target_batch.flatten()
)
return loss
@torch.no_grad()
def evaluate_model(model, train_loader, val_loader, device, eval_batches):
"""在训练集和验证集上各取 eval_batches 个 batch 计算平均损失。"""
model.eval()
total_train, total_val = 0.0, 0.0
for i, (x, y) in enumerate(train_loader):
if i >= eval_batches:
break
total_train += calc_loss_batch(x, y, model, device).item()
for i, (x, y) in enumerate(val_loader):
if i >= eval_batches:
break
total_val += calc_loss_batch(x, y, model, device).item()
model.train()
return total_train / eval_batches, total_val / eval_batches
def train_simple(model, train_loader, val_loader, optimizer,
device, num_epochs, eval_freq=100, eval_batches=5):
"""最简训练循环:前向 → 反向 → 更新 → 定期评估。"""
model.train()
global_step = 0
for epoch in range(num_epochs):
for input_batch, target_batch in train_loader:
# 1. 前向传播
loss = calc_loss_batch(input_batch, target_batch, model, device)
# 2. 反向传播
loss.backward()
# 3. 更新参数
optimizer.step()
# 4. 清零梯度
optimizer.zero_grad()
global_step += 1
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_batches
)
print(f"Step {global_step:6d} | "
f"Train loss: {train_loss:.4f} | "
f"Val loss: {val_loss:.4f}")这段代码足以让一个小模型在小数据集上完成训练。但在真实的大模型预训练中,它至少面临三个严重缺陷:梯度可能在某一步突然爆炸到极大值,导致参数被更新到"无人区"而无法恢复;全程使用 float32 精度,显存占用和计算速度都远非最优;没有任何持久化机制,一旦进程被杀死,所有训练进度归零。接下来逐一解决这些问题。
5.2.2 梯度裁剪
梯度爆炸(gradient explosion) 是深度模型训练中最常见的不稳定现象之一。当某一步的输入恰好触发了模型中多层参数的共振放大效应时,反向传播计算出的梯度范数可能突然从正常值(如 1.0)跳到数千甚至数万,一步更新就足以摧毁已经训练了数天的模型参数。
全局范数裁剪(global norm clipping)是解决这一问题的标准方法。其核心思想是:在优化器更新参数之前,检查所有参数梯度拼接后的全局
数学定义。 设模型所有参数的梯度为
裁剪操作为
这一操作保持了梯度的方向不变,仅缩放其大小。直观地理解:梯度裁剪不会改变模型"想往哪里走",只是在步子太大时把它拉住,相当于给训练过程加了一个安全阀。
为什么是全局范数而非逐参数裁剪? 逐参数裁剪(对每个参数张量独立裁剪)会改变不同参数之间梯度的相对比例,破坏梯度方向。例如,如果嵌入层的梯度为 10.0、注意力层的梯度为 0.1,逐参数裁剪可能将前者裁到 1.0 而后者保持不变,使更新方向发生严重偏转。全局范数裁剪对所有参数使用同一个缩放因子,确保梯度方向完全不变。
在 PyTorch 中,全局范数裁剪只需一行代码:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)这个函数的返回值是裁剪前的全局范数,可以用于监控训练稳定性。实践中,常见的 max_norm 取值为 1.0(GPT-2、GPT-3、LLaMA 系列的默认选择),也有部分工作使用 0.5 或 2.0。将训练过程中每一步的梯度范数记录下来并绘制曲线,是诊断训练不稳定问题的重要手段——如果梯度范数频繁触发裁剪,通常意味着学习率过大或数据中存在异常样本。
5.2.3 混合精度训练
图 5-5:GPT 解码器架构。多层 Transformer 块堆叠构成自回归语言模型,每层包含多头注意力和前馈网络两个子层。
现代 GPU(如 NVIDIA A100、H100)的 float16/bfloat16 计算吞吐量是 float32 的 2 到 4 倍,且半精度参数的显存占用减半。混合精度训练(mixed precision training) 充分利用这一硬件特性,在不损失训练效果的前提下大幅提升速度和显存效率。
混合精度的核心思路是:前向传播和反向传播在低精度下完成(加速计算),参数更新在 float32 下完成(保证精度)。 PyTorch 通过 torch.amp.autocast 上下文管理器实现这一切——进入上下文后,矩阵乘法等算子自动使用低精度执行,而损失计算、归约等对精度敏感的操作仍保持 float32。
但直接使用 float16 半精度有一个致命问题:梯度下溢。float16 能表示的最小正数约为 GradScaler 正是为解决这一问题而设计的——它在反向传播前将损失放大数万倍,使梯度被同步放大到 float16 的可表示范围内;在优化器更新前再将梯度缩放回原始大小。同时,GradScaler 会自动检测梯度中是否出现了 inf 或 NaN——如果检测到,说明当前的缩放因子过大,它会跳过本步更新并降低缩放因子。
| 精度类型 | 最小正数 | 梯度下溢风险 | 是否需要 GradScaler |
|---|---|---|---|
| float32 | 几乎不存在 | 不需要 | |
| float16 | 非常严重 | 必须使用 | |
| bfloat16 | 几乎不存在 | 不需要 |
表 5-2:不同精度类型的梯度下溢风险与 GradScaler 使用建议。
需要特别注意 bfloat16 的特殊地位:它的指数位与 float32 相同(都是 8 位),因此可表示的数值范围一致,不存在梯度下溢问题;但其尾数只有 7 位(float16 为 10 位),精度稍低。由于不需要 GradScaler,bfloat16 的训练代码更简洁、更不容易出错,是 2024 年以来大模型预训练的主流选择(LLaMA-3、DeepSeek-V2、Qwen-2 等均使用 bfloat16)。
5.2.4 学习率调度
直接使用固定学习率训练大语言模型几乎必然失败。训练初期,优化器(如 AdamW)的动量估计尚未稳定,若学习率过大,第一步的参数更新就可能导致损失爆炸为 NaN。训练后期,模型已接近收敛,若学习率仍然过大,参数会在最优点附近剧烈震荡而无法稳定。学习率调度(learning rate scheduling) 通过在训练过程中动态调整学习率来解决这两个问题。
线性预热(Linear Warmup)。 在训练最初的若干步(通常为总步数的 3%–10%),学习率从接近零线性增长到目标峰值
预热的作用是让优化器有足够的时间积累梯度统计信息(AdamW 需要约
余弦退火(Cosine Decay)。 预热结束后,学习率按余弦曲线平滑衰减到最小值
余弦衰减的优势在于:前期衰减缓慢,模型有充足的时间在高学习率下快速学习;后期衰减加速,帮助模型收敛到更平坦的极小值,提升泛化能力。最小学习率
将两个阶段组合,就是当前大模型预训练的标准学习率策略——"线性预热 + 余弦退火"(GPT-3、LLaMA、Qwen、DeepSeek 等均采用此方案):
import math
def get_lr(step, total_steps, warmup_steps, lr_max, lr_min=None):
"""线性预热 + 余弦退火学习率调度。
Args:
step: 当前训练步数
total_steps: 训练总步数
warmup_steps: 预热步数
lr_max: 峰值学习率
lr_min: 最小学习率,默认为 lr_max / 10
"""
if lr_min is None:
lr_min = lr_max / 10
if step < warmup_steps:
# 线性预热:从 0 线性增长到 lr_max
return lr_max * step / warmup_steps
else:
# 余弦退火:从 lr_max 平滑衰减到 lr_min
progress = (step - warmup_steps) / (total_steps - warmup_steps)
cosine_decay = 0.5 * (1 + math.cos(math.pi * progress))
return lr_min + (lr_max - lr_min) * cosine_decay在训练循环中,每一步通过 param_group['lr'] 手动设置学习率即可:
for step in range(total_steps):
lr = get_lr(step, total_steps, warmup_steps, lr_max)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# ... 前向、反向、更新 ...5.2.5 检查点保存与恢复
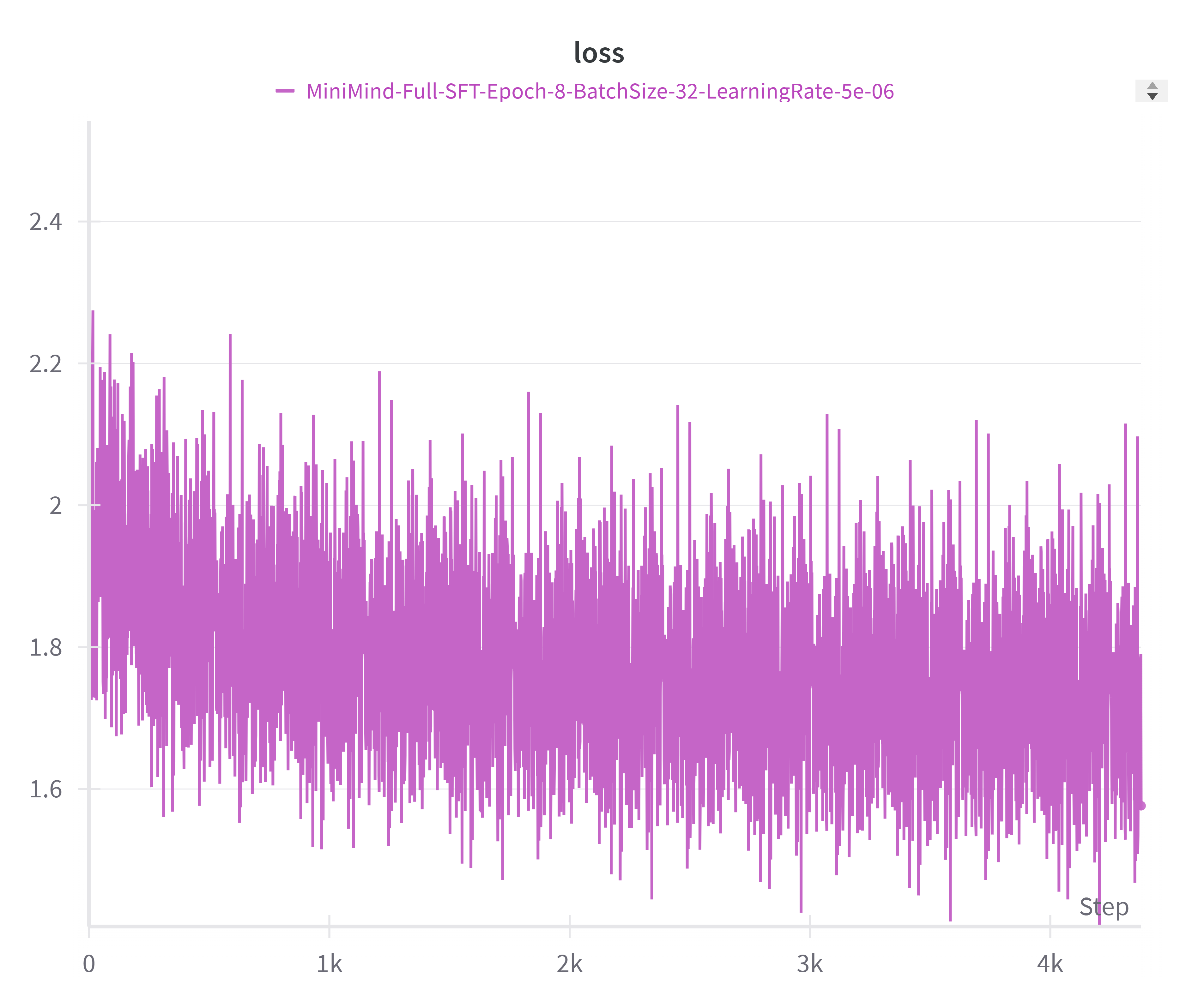
图 5-6:监督微调(SFT)阶段的损失曲线。在预训练基础上进行指令微调,损失快速下降后趋于平稳。
训练大语言模型可能需要数周时间。在这一时间跨度内,硬件故障、进程被杀、断电等意外中断几乎是不可避免的。检查点(checkpoint) 机制通过定期将训练状态的完整快照保存到磁盘,确保训练可以从最近一次保存点恢复,而非从头开始。
一个完整的检查点应包含什么? 仅保存模型权重是不够的。要让训练从中断点完全无缝地继续——相同的参数、相同的优化器状态、相同的学习率、相同的随机性——检查点必须包含以下所有组件:
| 组件 | 关键性 | 不保存的后果 |
|---|---|---|
模型参数 model.state_dict() | 必需 | 训练成果完全丢失 |
优化器状态 optimizer.state_dict() | 必需 | AdamW 的动量和二阶矩估计归零,恢复后损失剧烈波动 |
| 训练步数 / epoch 数 | 必需 | 学习率调度错乱,日志不连续 |
| 学习率调度器状态 | 建议 | 学习率从错误的位置开始衰减 |
| GradScaler 状态 | 混合精度时必需 | 缩放因子重新探索,可能导致前几步梯度全是 NaN |
| 随机数生成器状态 | 完全可复现时必需 | 数据加载顺序和 dropout 模式不一致 |
| 当前损失值 | 建议 | 无法判断恢复是否正确 |
表 5-3:检查点各组件的重要性及不保存时的后果。
保存检查点:
import os, torch
def save_checkpoint(model, optimizer, step, epoch, loss, scaler=None,
save_dir="checkpoints"):
"""保存训练检查点。"""
os.makedirs(save_dir, exist_ok=True)
checkpoint = {
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"step": step,
"epoch": epoch,
"loss": loss,
"rng_state": torch.random.get_rng_state(),
}
if torch.cuda.is_available():
checkpoint["cuda_rng_state"] = torch.cuda.get_rng_state()
if scaler is not None:
checkpoint["scaler_state_dict"] = scaler.state_dict()
# 原子化写入:先写临时文件,再重命名,防止写入过程中断导致文件损坏
path = os.path.join(save_dir, f"ckpt_step_{step}.pt")
tmp_path = path + ".tmp"
torch.save(checkpoint, tmp_path)
os.replace(tmp_path, path) # 原子操作
print(f"Checkpoint saved: {path}")代码中使用了原子化写入策略:先将检查点写入临时文件,写入完成后再通过 os.replace 重命名为最终文件名。os.replace 在大多数文件系统上是原子操作,可以防止在写入过程中断电导致检查点文件不完整——如果写入被中断,磁盘上只有临时文件被破坏,上一个完整的检查点不受影响。
加载检查点并恢复训练:
def load_checkpoint(path, model, optimizer, device, scaler=None):
"""从检查点恢复训练状态。"""
checkpoint = torch.load(path, map_location=device, weights_only=False)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
if scaler is not None and "scaler_state_dict" in checkpoint:
scaler.load_state_dict(checkpoint["scaler_state_dict"])
# 恢复随机数状态以保证可复现性
if "rng_state" in checkpoint:
torch.random.set_rng_state(checkpoint["rng_state"])
if "cuda_rng_state" in checkpoint and torch.cuda.is_available():
torch.cuda.set_rng_state(checkpoint["cuda_rng_state"])
start_step = checkpoint["step"]
start_epoch = checkpoint["epoch"]
loss = checkpoint["loss"]
print(f"Resumed from step {start_step}, epoch {start_epoch}, "
f"loss {loss:.4f}")
return start_step, start_epoch检查点管理策略。 实践中不应无限保存所有检查点,也不应只保留最新的一个。推荐的做法是保留最近的
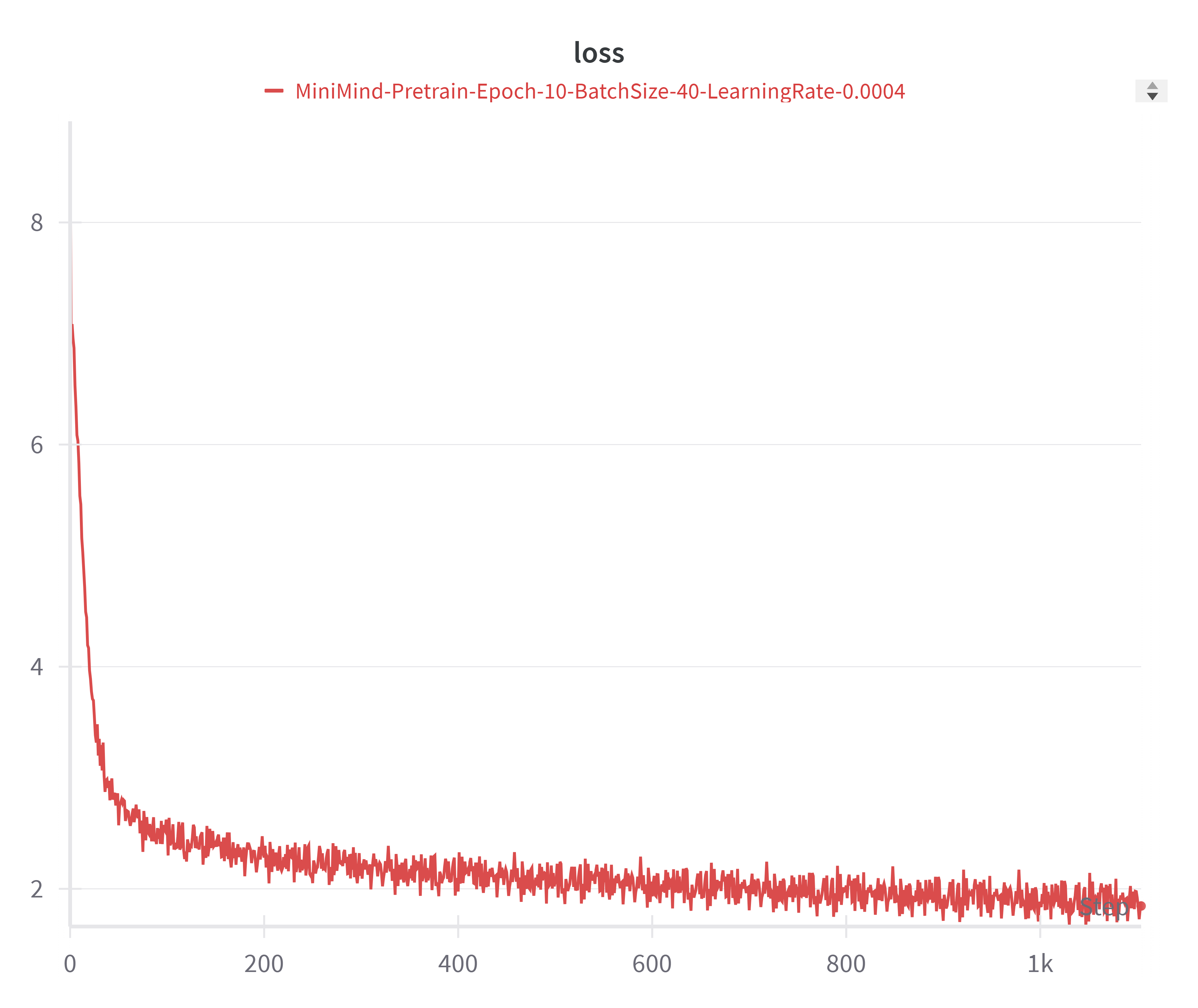
图 5-7:不同隐藏维度模型的预训练损失曲线对比。更大的模型(d=768)比更小的模型(d=512)收敛到更低的损失值。
5.2.6 完整训练循环
将以上所有组件整合在一起,就得到一个具备工业级健壮性的完整训练循环。下面的代码包含了梯度裁剪、混合精度训练(兼容 float32/float16/bfloat16)、学习率调度、定期评估和检查点保存与恢复:
import os
import math
import torch
import torch.nn.functional as F
from torch.amp import autocast, GradScaler
def get_lr(step, total_steps, warmup_steps, lr_max, lr_min=None):
"""线性预热 + 余弦退火。"""
if lr_min is None:
lr_min = lr_max / 10
if step < warmup_steps:
return lr_max * step / warmup_steps
progress = (step - warmup_steps) / max(total_steps - warmup_steps, 1)
return lr_min + (lr_max - lr_min) * 0.5 * (1 + math.cos(math.pi * progress))
def calc_loss_batch(input_batch, target_batch, model, device):
"""计算单个 batch 的交叉熵损失。"""
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
return F.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
@torch.no_grad()
def evaluate(model, data_loader, device, max_batches=50):
"""评估模型在给定数据集上的平均损失。"""
model.eval()
total_loss, count = 0.0, 0
for i, (x, y) in enumerate(data_loader):
if i >= max_batches:
break
total_loss += calc_loss_batch(x, y, model, device).item()
count += 1
model.train()
return total_loss / max(count, 1)
def save_checkpoint(model, optimizer, scaler, step, epoch, loss,
save_dir="checkpoints"):
"""原子化保存检查点。"""
os.makedirs(save_dir, exist_ok=True)
ckpt = {
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"step": step, "epoch": epoch, "loss": loss,
"rng_state": torch.random.get_rng_state(),
}
if scaler is not None:
ckpt["scaler_state_dict"] = scaler.state_dict()
if torch.cuda.is_available():
ckpt["cuda_rng_state"] = torch.cuda.get_rng_state()
path = os.path.join(save_dir, f"ckpt_step_{step}.pt")
tmp_path = path + ".tmp"
torch.save(ckpt, tmp_path)
os.replace(tmp_path, path)
def load_checkpoint(path, model, optimizer, scaler, device):
"""从检查点恢复所有训练状态。"""
ckpt = torch.load(path, map_location=device, weights_only=False)
model.load_state_dict(ckpt["model_state_dict"])
optimizer.load_state_dict(ckpt["optimizer_state_dict"])
if scaler is not None and "scaler_state_dict" in ckpt:
scaler.load_state_dict(ckpt["scaler_state_dict"])
if "rng_state" in ckpt:
torch.random.set_rng_state(ckpt["rng_state"])
if "cuda_rng_state" in ckpt and torch.cuda.is_available():
torch.cuda.set_rng_state(ckpt["cuda_rng_state"])
return ckpt["step"], ckpt["epoch"]
def train(
model,
train_loader,
val_loader,
optimizer,
device,
num_epochs,
# 学习率调度
lr_max=5e-4,
warmup_steps=100,
# 梯度裁剪
max_grad_norm=1.0,
# 混合精度:'float32' | 'float16' | 'bfloat16'
dtype='bfloat16',
# 评估与日志
eval_freq=500,
eval_batches=20,
log_freq=10,
# 检查点
save_freq=1000,
save_dir="checkpoints",
resume_from=None,
):
"""完整训练循环:梯度裁剪 + 混合精度 + 学习率调度 + 检查点。"""
# ---- 混合精度设置 ----
use_amp = (dtype != 'float32')
amp_dtype = {'float16': torch.float16,
'bfloat16': torch.bfloat16}.get(dtype, torch.float32)
# GradScaler 仅在 float16 时启用
scaler = GradScaler(enabled=(dtype == 'float16'))
# ---- 计算总步数 ----
steps_per_epoch = len(train_loader)
total_steps = num_epochs * steps_per_epoch
lr_min = lr_max / 10
# ---- 断点恢复 ----
start_step, start_epoch = 0, 0
if resume_from is not None:
start_step, start_epoch = load_checkpoint(
resume_from, model, optimizer, scaler, device
)
print(f"Resumed from step {start_step}, epoch {start_epoch}")
# ---- 训练主循环 ----
model.train()
global_step = start_step
for epoch in range(start_epoch, num_epochs):
for input_batch, target_batch in train_loader:
# 如果是恢复训练,跳过已完成的 batch
batch_in_epoch = global_step - epoch * steps_per_epoch
if epoch == start_epoch and batch_in_epoch < (start_step % steps_per_epoch):
global_step += 1
continue
# 1. 更新学习率
lr = get_lr(global_step, total_steps, warmup_steps, lr_max, lr_min)
for pg in optimizer.param_groups:
pg['lr'] = lr
# 2. 前向传播(混合精度)
with autocast(device_type=device.type, dtype=amp_dtype,
enabled=use_amp):
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
# 3. 反向传播(GradScaler 自动缩放损失)
optimizer.zero_grad()
scaler.scale(loss).backward()
# 4. 梯度裁剪(需先 unscale)
scaler.unscale_(optimizer)
grad_norm = torch.nn.utils.clip_grad_norm_(
model.parameters(), max_norm=max_grad_norm
)
# 5. 参数更新
scaler.step(optimizer)
scaler.update()
global_step += 1
# ---- 日志 ----
if global_step % log_freq == 0:
print(f"Epoch {epoch+1}/{num_epochs} | "
f"Step {global_step}/{total_steps} | "
f"Loss: {loss.item():.4f} | "
f"LR: {lr:.2e} | "
f"Grad norm: {grad_norm:.2f}")
# ---- 评估 ----
if global_step % eval_freq == 0:
val_loss = evaluate(model, val_loader, device, eval_batches)
print(f" >> Validation loss: {val_loss:.4f} | "
f"PPL: {math.exp(val_loss):.2f}")
# ---- 保存检查点 ----
if global_step % save_freq == 0:
save_checkpoint(model, optimizer, scaler,
global_step, epoch, loss.item(), save_dir)
# 训练结束,保存最终检查点
save_checkpoint(model, optimizer, scaler,
global_step, num_epochs, loss.item(), save_dir)
print(f"Training complete. Total steps: {global_step}")整个流程可以用下面的步骤链条来概括:
几个需要特别注意的实现细节:
scaler.unscale_必须在梯度裁剪之前调用。GradScaler在反向传播时将梯度放大了数万倍,如果不先调用unscale_恢复原始尺度就做裁剪,裁剪阈值将形同虚设——被放大数万倍的梯度范数远超任何合理的max_norm值,每一步都会被裁剪,训练实际上变成了固定步长的梯度下降。optimizer.zero_grad()的位置。 上面的代码将zero_grad放在反向传播之前而非优化器更新之后。两种写法在功能上等价,但前者更清晰地表达了语义:"在计算新梯度之前,确保旧梯度已被清除。"- bfloat16 下 GradScaler 自动禁用。 当
dtype='bfloat16'时,GradScaler(enabled=False)使得scaler.scale(loss)直接返回原始 loss,scaler.step(optimizer)直接调用optimizer.step()——整个 scaler 变成一个透明的直通层,不增加任何开销。这使得同一套代码可以无缝切换三种精度。
使用示例。 假设模型和数据加载器已经准备好:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GPTModel(config).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4, weight_decay=0.1)
# 从头训练
train(model, train_loader, val_loader, optimizer, device,
num_epochs=10, lr_max=5e-4, warmup_steps=200, dtype='bfloat16')
# 从检查点恢复训练
train(model, train_loader, val_loader, optimizer, device,
num_epochs=10, resume_from="checkpoints/ckpt_step_5000.pt")5.2.7 检查点最佳实践
图 5-8:d=768 隐藏维度模型的预训练损失曲线。更大的隐藏维度提供了更强的表达能力,使损失收敛到更低的水平。
在大规模训练中,检查点的保存和管理本身就是一项需要精心设计的工程任务。以下是几条经过实践检验的准则:
保存频率的权衡。 保存过于频繁会因磁盘 I/O 拖慢训练速度(尤其是大模型的参数量可达数十 GB);保存间隔过大则意味着中断时丢失更多进度。一个常见的经验法则是:保存间隔不超过训练总时长的 1%——如果完整训练需要 100 小时,则至少每 1 小时保存一次。
滚动保留策略。 保留最近的
import glob
def cleanup_checkpoints(save_dir, keep_last=3):
"""只保留最近的 keep_last 个检查点。"""
ckpts = sorted(glob.glob(os.path.join(save_dir, "ckpt_step_*.pt")))
for old in ckpts[:-keep_last]:
os.remove(old)分布式训练中的检查点。 在多 GPU 训练(如 DDP)中,所有 GPU 上的模型参数是同步的,因此只需在主进程(rank 0)上保存检查点,避免多个进程同时写文件造成冲突或磁盘压力:
if torch.distributed.get_rank() == 0:
save_checkpoint(model, optimizer, scaler, step, epoch, loss)保存前验证完整性。 在关键节点(如训练结束、验证损失创新低时),可以保存后立即尝试加载,验证检查点文件未损坏。虽然增加了少量时间开销,但对于长达数周的训练来说,这份保险是值得的。
本节小结
本节从一个最简训练循环出发,逐步构建了一个具备工业级健壮性的完整预训练框架:
- 基础训练循环由四个步骤组成:前向传播计算损失、反向传播计算梯度、优化器更新参数、清零梯度。这是所有后续增强的骨架。
- 梯度裁剪通过在更新前检查梯度的全局
范数并在超过阈值时等比例缩小,防止单步更新摧毁模型参数。全局范数裁剪保持梯度方向不变,是 GPT、LLaMA 等模型的标准选择( max_norm=1.0)。 - 混合精度训练利用 GPU 的低精度计算单元加速训练并节省显存。float16 需配合
GradScaler防止梯度下溢;bfloat16 因指数范围与 float32 一致,无需额外处理,是当前主流选择。 - 学习率调度采用"线性预热 + 余弦退火"策略:预热阶段让优化器稳定积累统计信息,余弦退火阶段帮助模型平滑收敛到更优的极小值。
- 检查点机制定期将训练的完整状态(模型参数、优化器状态、随机数状态等)保存到磁盘。使用原子化写入防止文件损坏,使用滚动保留策略控制磁盘占用,确保训练可以从任何中断点无缝恢复。
这些组件共同构成了从"能跑"到"能稳定跑数周"的关键工程基础设施。下一节将讨论训练完成后如何将模型输出的 logits 转化为实际的文本——即解码策略。