20.1 评估方法论
"There is an evaluation crisis." —— Andrej Karpathy
当你训练完一个语言模型,自然会问一个看似简单的问题:这个模型到底有多好? 表面上,这不过是"给定一个固定模型,测量其表现"的机械操作。但正如 Karpathy 在社交平台上直言——评估正面临一场危机。MMLU 曾经好用但已经老旧,SWE-Bench Verified 方向正确但覆盖太窄,Chatbot Arena 一度被视为金标准却被发现存在协议漏洞和刷榜行为。我们其实并不真正知道当前的模型有多好。
图 20-1:Andrej Karpathy 指出当前 LLM 评估正处于危机之中——传统基准饱和、排行榜被操控、综合评估方法尚不成熟。
本节将建立一个系统的评估方法论框架。我们首先审视评估的多元面貌——从基准分数到排行榜再到人类偏好投票,理解这些不同信号各自在告诉我们什么;然后引入四个核心问题(输入、调用、评估、解读)作为分析任何评估方案的通用工具,为后续章节对具体基准和评估系统的深入讨论奠定方法论基础。
20.1.1 评估的多元面貌
打开任何一篇大模型的技术报告,你都会看到一张密密麻麻的基准分数表格——MMLU 多少分、MATH 多少分、Codeforces 百分位是多少。但如果你退后一步观察整个评估生态,会发现"模型好不好"这个问题有着截然不同的回答方式。
面貌一:官方基准报告。 模型发布方通常会选择一组标准化基准进行评测,然后在论文或博客中公布分数。下图展示了 DeepSeek-R1 与 OpenAI o1 系列在多项基准上的对比:
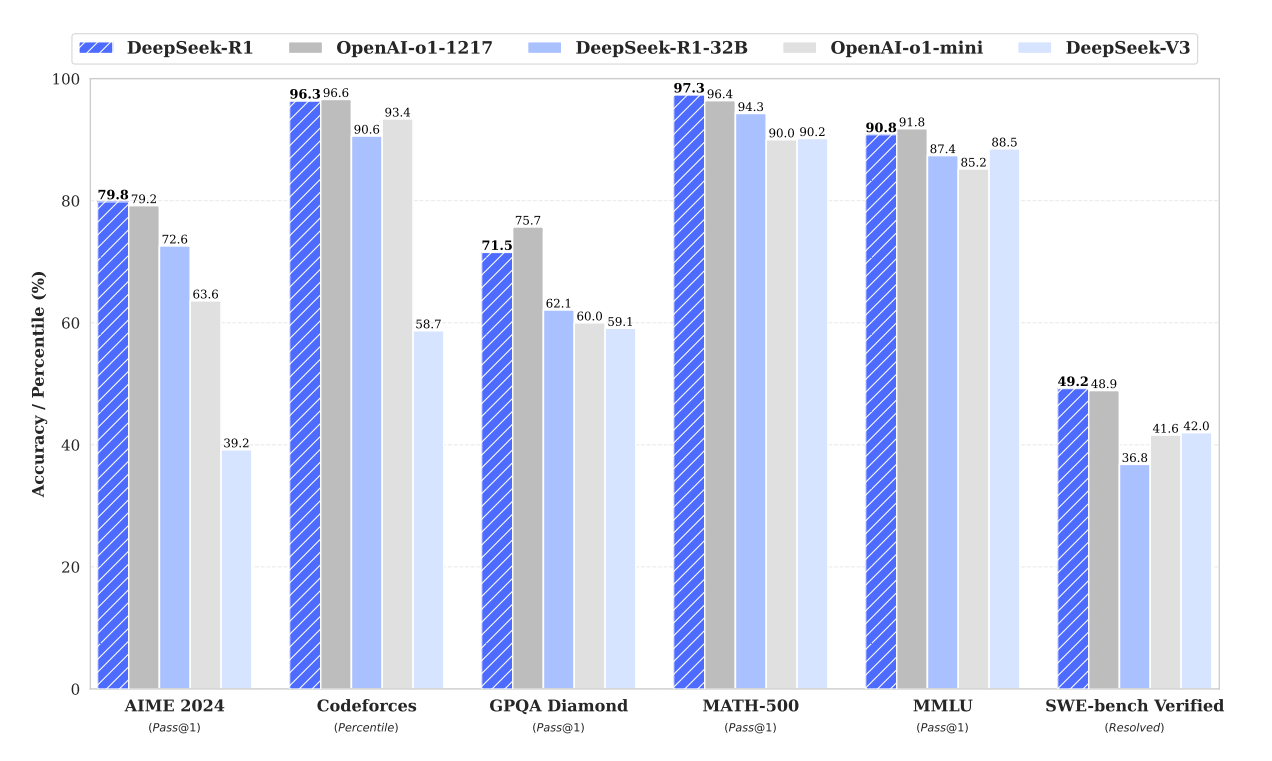
图 20-2:典型的模型发布基准报告。不同模型在 AIME、Codeforces、GPQA、MATH-500、MMLU、SWE-bench 等基准上的得分对比。注意不同模型选择评测的基准并不完全相同。
这种方式的优势是可量化、可复现(至少在理论上),但隐含两个问题:(1)模型发布方有动机挑选对自己有利的基准报告;(2)单个基准分数的含义往往不透明——"MMLU 90.8%"和"GPQA 71.5%"哪个更能说明模型的实际能力?
面貌二:聚合排行榜。 为了提供更全面的视角,研究者构建了将多个基准聚合在一起的排行榜。斯坦福的 HELM(Holistic Evaluation of Language Models) 是其中最具代表性的框架,它在统一条件下运行数十个基准,将结果整理为一张综合排行表。
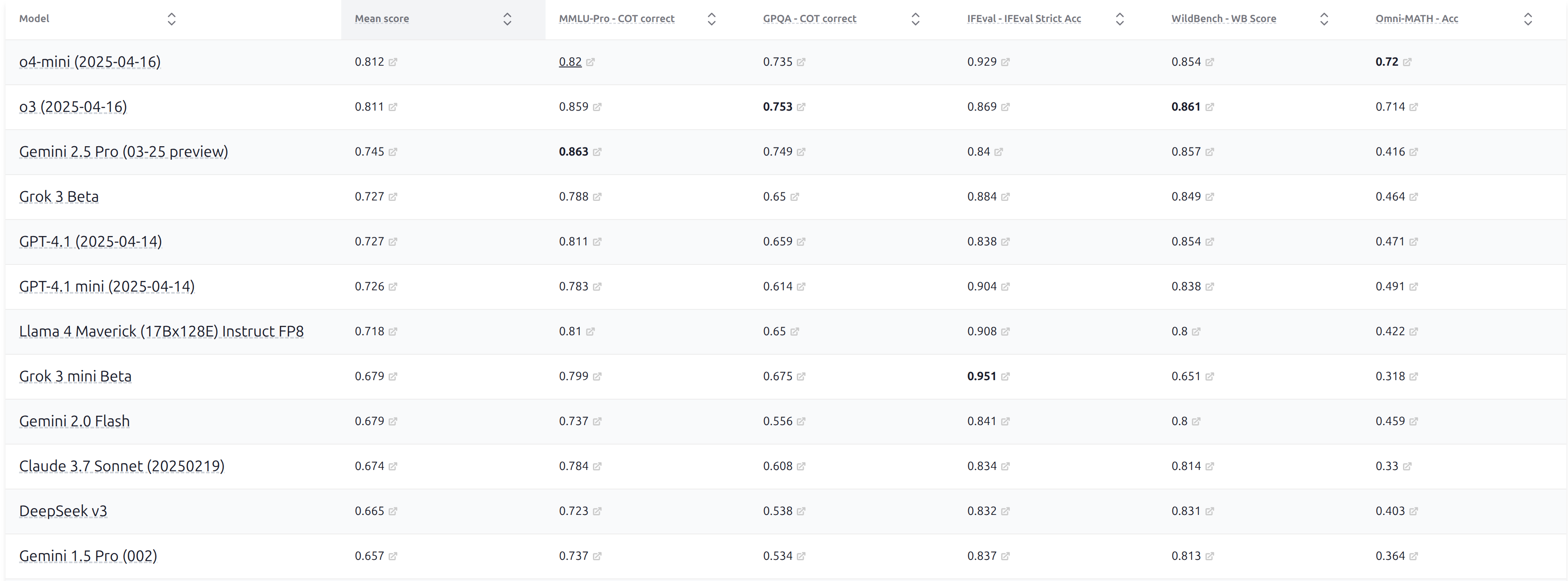
图 20-3:HELM 综合能力排行榜将 MMLU-Pro、GPQA、IFEval、WildBench 等多个基准的结果汇聚在一起,提供跨基准的横向对比。
聚合排行榜解决了"只看一个基准"的片面性,但也引入了新的问题:聚合权重如何确定? 不同基准的难度和区分度不同,简单平均可能掩盖关键差异。
面貌三:成本效益分析。 在实际部署中,模型的"好"不仅取决于准确率,还取决于推理成本。Artificial Analysis 等平台将模型的智能指数(多个基准的综合得分)与每百万 Token 的价格绘制成帕累托前沿图(Pareto frontier):
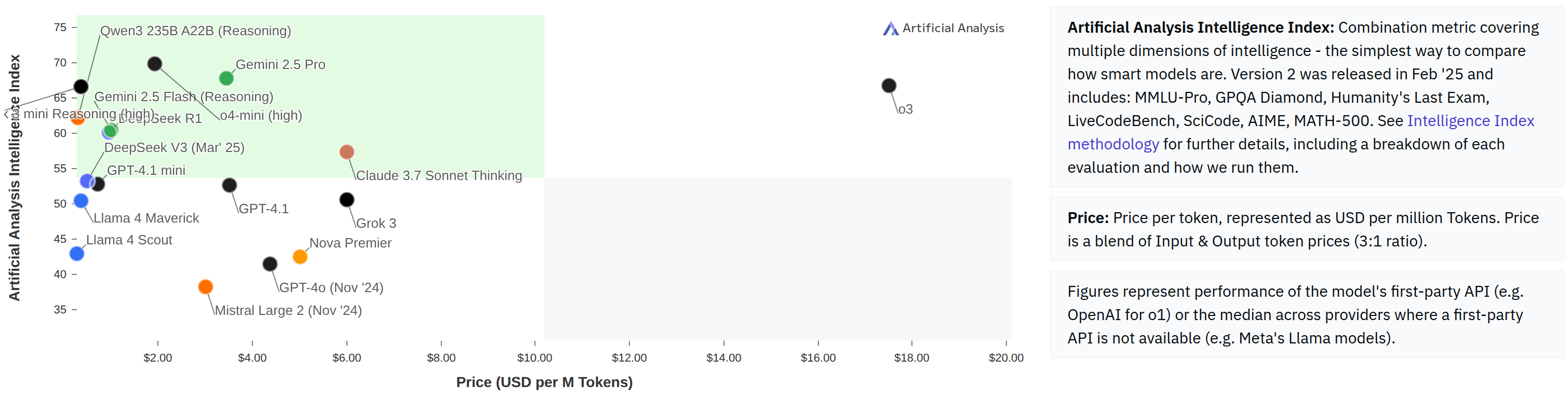
图 20-4:模型的智能指数与推理价格的帕累托前沿。O3 虽然强大但价格高昂,而部分模型可能以更低成本提供接近的性能——这种视角在工程落地中至关重要。
面貌四:人类偏好排名。 基准分数终究是对特定任务的度量,但用户真正关心的是"哪个模型用起来更顺手"。Chatbot Arena 采用了一种截然不同的范式——让真实用户在两个匿名模型的回复之间进行盲选,然后用 ELO 评分系统(源自国际象棋)计算模型的相对排名。
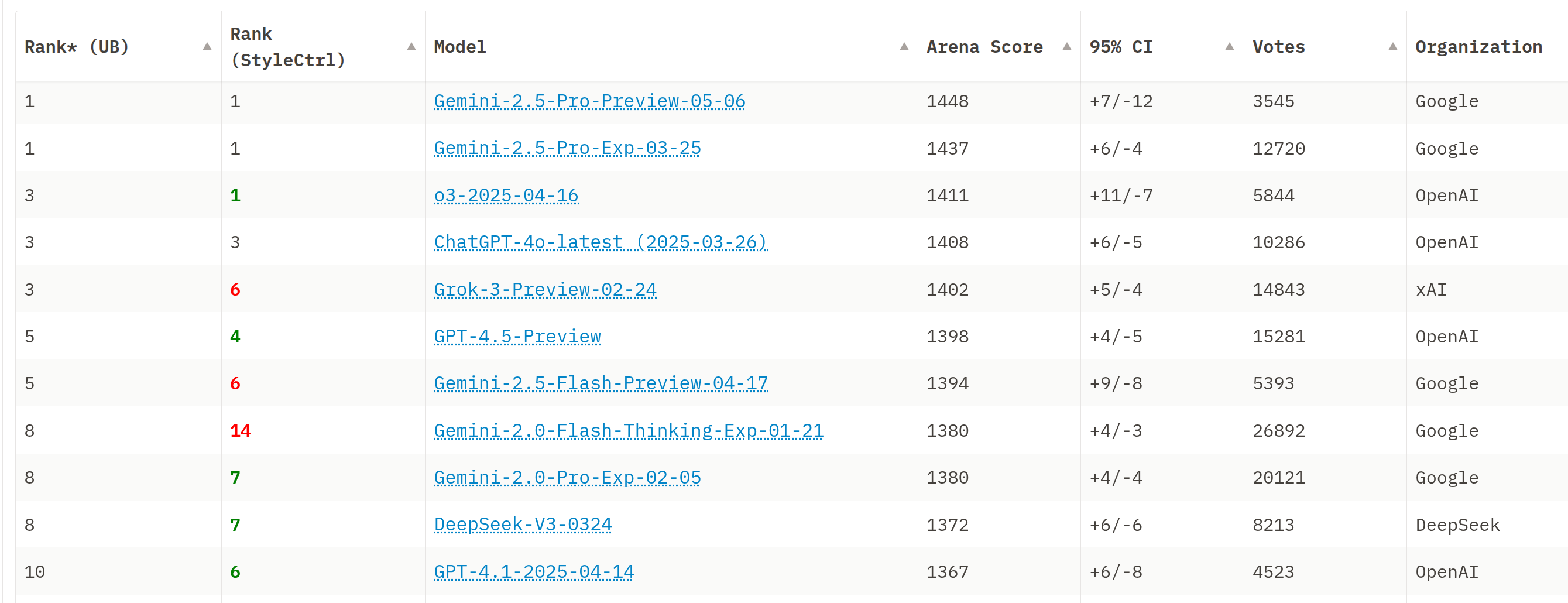
图 20-5:Chatbot Arena 排行榜基于大量真实用户的配对投票计算 ELO 评分。这种"以人为本"的评估方式已成为指令遵循能力评估的事实标准。
ELO 评分的核心公式如下。设模型 A 和 B 当前评分分别为
每次投票后,评分按实际结果
其中
面貌五:社交媒体"氛围"(Vibes)。 除了上述结构化评估,社交平台上流传的精选示例、模型翻车截图、病毒式传播的 demo 也在深刻影响公众和开发者对模型能力的判断。这种非正式数据虽然无法量化,却常常是推动模型迭代最强烈的信号之一。
下表总结了这五种评估面貌的特征:
| 评估面貌 | 典型来源 | 优势 | 局限 |
|---|---|---|---|
| 官方基准报告 | 模型论文/博客 | 可量化、可复现 | 选择性报告、单一基准含义不透明 |
| 聚合排行榜 | HELM、Open LLM Leaderboard | 多维度综合对比 | 聚合权重主观、更新滞后 |
| 成本效益分析 | Artificial Analysis | 兼顾性能与成本 | 价格波动大、依赖具体部署场景 |
| 人类偏好排名 | Chatbot Arena | 贴近真实用户感受 | 用户分布偏差、可被刷榜 |
| 社交媒体氛围 | X/Twitter、Reddit | 反应速度快、覆盖长尾场景 | 不可量化、样本偏差严重 |
表 20-1:LLM 评估的五种面貌及其特征对比。
关键洞察: 没有任何单一评估方式能够完整刻画一个模型的能力画像。基准分数提供精确但狭窄的度量,人类偏好捕捉整体感受但难以诊断具体弱点,成本分析关注落地可行性但忽略长尾能力。科学的评估方法论不是选择"最好的"评估方式,而是理解每种方式能告诉你什么、不能告诉你什么,然后根据你的目标组合使用。
20.1.2 评估的目的决定方法
在深入任何具体基准之前,我们需要先问一个元问题:你做评估是为了回答什么问题? 不同的评估目的,天然导向不同的方法选择。
| 评估者身份 | 核心目的 | 典型问题 | 适合的评估方式 |
|---|---|---|---|
| 终端用户/企业 | 购买决策 | Claude vs Gemini,哪个适合我的客服场景? | 领域定制基准 + 成本分析 |
| 研究者 | 度量原始能力 | AI 的推理能力是否在进步? | 标准化知识/推理基准 |
| 政策制定者 | 理解收益与风险 | 模型带来的价值和危害分别是什么? | 安全基准 + 红队测试 |
| 模型开发者 | 获取改进信号 | 模型在哪些方面还需改进? | 细粒度基准 + 误差分析 |
表 20-2:不同评估主体的目的与适配方法。
每种场景都涉及一个从抽象目标到具体评估的转化过程。例如,"衡量推理能力"这个抽象目标可以被转化为 GSM8K 数学题、ARC-AGI 视觉模式推理、或 Codeforces 编程竞赛——每种转化都做了不同的假设,也会得到不同的结论。
这意味着:评估没有"唯一真理"(No One True Evaluation)。你追踪什么指标,就会优化什么方向。这不仅是方法论的告诫,更是工程实践中的生存法则——顶级模型开发者都在紧盯评估指标,而指标的选择直接塑造了模型的进化方向。
20.1.3 四个核心问题:评估框架的解剖学
无论面对哪种评估方案——从简单的多选题基准到复杂的 Agent 评估系统——我们都可以用四个核心问题来系统地分析它。这四个问题构成了评估方法论的骨架:
问题一:输入从哪里来?(Inputs)
评估的第一个维度是测试输入的构造。需要考虑的问题包括:
- 覆盖范围:这些 Prompt 覆盖了哪些用例?是否包含了困难的长尾情况?
- 分布匹配:测试输入的分布是否与模型的实际使用场景匹配?标准化考试题与真实用户问题可能相去甚远。
- 格式适配:输入是否需要适配模型(如添加系统提示、组织为多轮对话格式)?
一个典型的反面案例是 MMLU——它的名字叫"Massive Multitask Language Understanding"(大规模多任务语言理解),但实际上测试的更多是知识记忆而非语言理解能力。一个语言理解能力很强但不了解外交政策的人,可能在 MMLU 上得分很低。
问题二:如何调用模型?(How to Call the LM)
同一个模型,用不同的方式调用可能得到截然不同的结果:
- 提示策略:Zero-shot(不给示例)、Few-shot(给几个示例)、Chain-of-Thought(引导逐步推理),三者的效果差异可能达到数十个百分点。
- 工具增强:是否允许模型使用搜索引擎、代码执行器、RAG 检索?
- 评估对象:你评估的是裸模型还是整个系统(模型 + Agent 脚手架 + 工具链)?
这个区分至关重要。BIG-Bench Hard (BBH) 的研究显示,如果不使用 Chain-of-Thought 提示,LLM 在这些高难度推理任务上的表现远低于人类;但一旦引入逐步推理提示,部分模型能够显著提升甚至超越人类平均水平。同一个模型,同一组题目,仅因调用方式不同,结论就从"远不如人"变成了"超越人类"。
# 示例:同一模型在不同提示策略下的评测对比
def evaluate_with_strategies(model, questions, strategies):
"""对比不同提示策略对评估结果的影响"""
results = {}
for strategy_name, prompt_fn in strategies.items():
correct = 0
for q in questions:
prompt = prompt_fn(q["question"], q.get("choices"))
response = model.generate(prompt)
if extract_answer(response) == q["answer"]:
correct += 1
results[strategy_name] = correct / len(questions)
return results
# 三种提示策略的构造
strategies = {
"zero_shot": lambda q, c: f"Question: {q}\nChoices: {c}\nAnswer:",
"few_shot": lambda q, c: (
"Q: What is 2+2?\nA: B) 4\n\n" # 示例
f"Q: {q}\nChoices: {c}\nA:"
),
"chain_of_thought": lambda q, c: (
f"Question: {q}\nChoices: {c}\n"
"Let's think step by step:\n"
),
}问题三:如何评判输出?(How to Evaluate Outputs)
模型给出了回复,如何判断它是"好"还是"坏"?这个看似简单的步骤实则暗藏大量决策:
- 参考答案的质量:参考答案是否无误?许多基准存在标注错误(SWE-Bench 的"Verified"版本就是为了修复原始数据集中的错误而推出的)。
- 指标选择:Pass@k(允许模型尝试 k 次,至少一次正确即算通过)与 Pass@1 的语义完全不同;前者衡量模型的能力上界,后者衡量单次调用的可靠性。
- 不对称错误:在医疗场景中,模型的幻觉(编造事实)远比"不知道"更危险。评估指标需要反映这种错误代价的不对称性。
- 开放式生成:对于"写一首诗"或"帮我润色这段文字"这类任务,根本不存在唯一的正确答案。此时需要引入 LLM-as-a-Judge(让另一个强大模型充当裁判)或人类评估。
问题四:如何解读结果?(How to Interpret)
即使完美地执行了前三步,结果的解读仍然充满陷阱:
- 分数的绝对含义:"MMLU 91%"意味着什么?这个模型可以安全部署了吗?分数与可靠性之间没有简单的映射关系。
- 泛化能力:高分是因为模型真的学会了,还是因为训练数据中已经"见过"测试集的内容(训练-测试污染,Contamination)?
- 评估对象的归属:如果一个 Agent 系统在 SWE-Bench 上取得了高分,功劳归于底层模型还是 Agent 框架?这个系统在换用不同模型后表现如何?

图 20-6:训练-测试污染检测的核心思路——利用数据点的可交换性(Exchangeability)。如果模型对测试集的特定排列表现出偏好(概率异常高),则可能在训练中见过该数据。
下表将四个核心问题及其关键子问题整理为一个检查清单:
| 核心问题 | 关键子问题 | 常见陷阱 |
|---|---|---|
| 输入 | 覆盖范围?分布匹配?格式适配? | 测试输入不代表真实使用场景 |
| 调用 | 提示策略?工具增强?评估的是模型还是系统? | 不同调用方式导致结论相反 |
| 评估 | 参考答案质量?指标选择?错误代价? | 标注噪声虚增/拉低分数 |
| 解读 | 分数含义?泛化性?归属? | 训练-测试污染导致分数失效 |
表 20-3:评估方法论的四个核心问题及其检查清单。
20.1.4 评估维度的分类体系
将上述方法论框架应用于 LLM 评估的全貌,我们可以将评估维度组织为一个系统的分类体系。
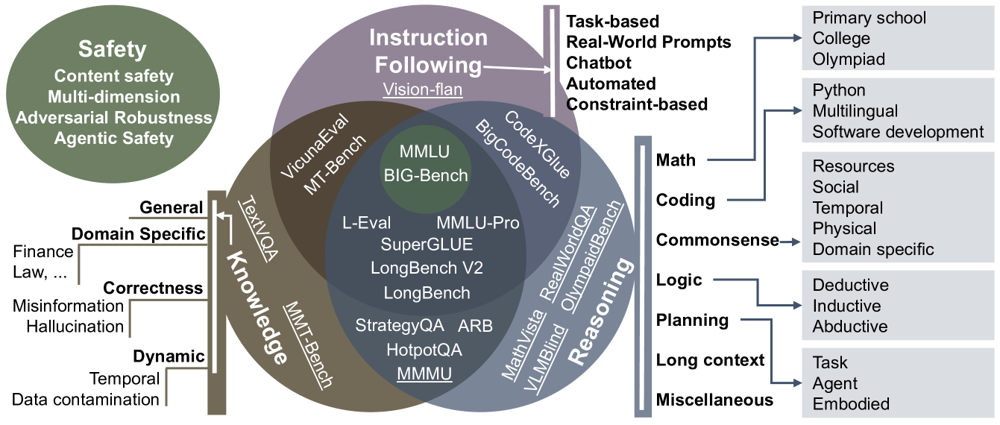
图 20-7:面向 LLM 的能力驱动评估基准分类示意图。评估维度涵盖知识(Knowledge)、推理(Reasoning)、指令遵循(Instruction Following)、安全(Safety)等核心能力,不同维度之间存在交互影响。
从早期 NLP 的单任务评测(句法解析、词义消歧),到 BERT 时代的多任务综合基准(GLUE、SuperGLUE),再到 GPT-3 之后的能力导向框架(MMLU、BIG-Bench),评估范式经历了三次重大转变:
从任务导向到能力导向。 传统评测面向"完形填空""情感分类"等具体任务;现代评测面向"知识记忆""逻辑推理""指令遵循""安全对齐"等抽象能力维度。
从静态到动态。 固定数据集很快被"学透"——模型在 GLUE 上超越人类只用了不到一年。动态评测框架(如 Dynabench 的人机对抗模式、持续更新的 Chatbot Arena)通过不断生成新测试样本来保持挑战性。
从性能到多维。 ChatGPT 之后,评估不仅关心模型"能否完成任务",更关心"是否合乎人类价值观"。TruthfulQA 检测幻觉倾向,HarmBench 测试安全防护,HELM 框架从有用性、诚实性、无害性、可信度等多维度进行整体评估。
能力与安全的双面性。 能力和安全往往是一枚硬币的两面。一个能够发现系统漏洞的 Agent 既可以被用于渗透测试(保护系统),也可以被用于恶意攻击。评估 CyBench 这类网络安全基准时,研究者要同时回答"模型能做什么"和"模型应该做什么"两个问题。
20.1.5 评估方法论的实践建议
综合以上讨论,我们总结出评估方法论的几条核心原则:
原则一:始终查看具体实例和预测。 不要只看聚合数字。深入到具体的题目和模型回答,往往能发现数字背后隐藏的问题——也许模型"答对了但理由是错的",也许某个高分来源于测试数据的系统性偏差。
原则二:明确你在评估什么。 在基础模型时代之前,评估的主要对象是方法(Methods)——给定标准数据集,比较不同学习算法。如今,评估的对象更多是模型或系统(Models/Systems),规则变成了"一切皆可"(Anything goes)。无论哪种情况,都需要明确定义"游戏规则"。
原则三:对评估本身保持怀疑。 评估的有效性(Validity)是一个递归问题——我们如何知道评估方案本身是好的?一个值得参考的做法是检查不同评估方式之间的相关性。例如,WildBench 与 Chatbot Arena 的相关系数高达 0.95,说明这两种方式在测量相似的东西。相关性低的评估方式则可能在捕捉不同的能力维度——这本身也是有价值的信息。
原则四:考虑完整的评估成本。 一次完整的 SWE-Bench 评估可能需要数千次 LLM 调用,成本达到数百美元。如果你只是想快速验证一个模型改进的效果,也许一个更轻量的代理基准就够了。评估策略本身也需要做成本效益分析。
# 示例:构建一个简单的多维评估报告
def generate_eval_report(model_name, eval_results):
"""
汇总多维评估结果为结构化报告。
Args:
model_name: 被评估模型名称
eval_results: dict, 各维度评估结果
例如: {"knowledge": 0.91, "reasoning": 0.78,
"instruction_following": 0.85, "safety": 0.93}
"""
print(f"=== Evaluation Report: {model_name} ===\n")
dimensions = {
"knowledge": "知识掌握",
"reasoning": "逻辑推理",
"instruction_following": "指令遵循",
"safety": "安全对齐",
}
for key, label in dimensions.items():
score = eval_results.get(key, None)
if score is not None:
bar = "█" * int(score * 20) + "░" * (20 - int(score * 20))
print(f" {label: <6} [{bar}] {score:.1%}")
else:
print(f" {label: <6} [未评估]")
avg = sum(eval_results.values()) / len(eval_results)
print(f"\n 综合均分: {avg:.1%}")
print(f" 最弱维度: {dimensions[min(eval_results, key=eval_results.get)]}")
print(f" 建议: 优先改进最弱维度以获得最大边际收益")
# 使用示例
generate_eval_report("MyModel-7B", {
"knowledge": 0.85,
"reasoning": 0.62,
"instruction_following": 0.88,
"safety": 0.91,
})小结
评估看似只是"跑个脚本、看个数字",实则是决定语言模型发展方向的关键力量。本节建立了评估方法论的核心框架:
- 评估有多元面貌——基准分数、聚合排行榜、成本效益分析、人类偏好排名、社交媒体氛围,各自捕捉模型能力的不同侧面,没有哪一种是"唯一真理"。
- 目的决定方法——用户的购买决策、研究者的能力度量、政策制定者的风险评估、开发者的改进信号,不同的问题需要不同的评估方案。
- 四个核心问题——输入从哪来、如何调用模型、如何评判输出、如何解读结果——构成了分析任何评估方案的通用检查清单。
- 评估维度已从单一性能走向多维体系——知识、推理、指令遵循、安全对齐缺一不可,而评估范式本身也在从静态走向动态、从人工走向自动化。
带着这套方法论工具,我们将在接下来的章节中逐一深入各类基准与评估系统——从知识与推理基准(MMLU、GPQA、ARC-AGI),到指令遵循评估(Chatbot Arena、AlpacaEval),再到安全评估与评估有效性分析。