0.2 LLM 生命周期
一个大语言模型从最初的"一堆随机数"到最终面向用户的产品,需要经历一条完整的工程与科学流水线。理解这条流水线——即 LLM 的生命周期——是深入学习大模型技术的逻辑起点。本节将从预训练、后训练、推理部署、评估四个阶段展开,同时穿插讨论计算规模在其中扮演的核心驱动角色。
0.2.1 苦痛的教训:计算规模的驱动作用
在逐一展开各阶段之前,我们先回答一个更根本的问题:为什么大模型的生命周期是今天这个样子?
2019 年,强化学习先驱 Rich Sutton 发表了一篇题为 The Bitter Lesson(苦痛的教训)的短文,总结了 AI 领域七十年发展中反复出现的一个规律:那些充分利用计算能力、可大规模扩展的通用方法,长远来看总是战胜了依赖人类专家知识的精巧方法。

Sutton 指出,无论是国际象棋、语音识别还是计算机视觉,研究者反复经历着同一个模式:早期依靠人类领域知识取得进展,随后被更简单、更通用但计算成本更高的方法所超越。他将 AI 的核心能力归结为两个要素——搜索(Search) 和 学习(Learning)——它们的共同特征是性能随计算资源的增加而持续提升。
这一观察被一个常见误读所扭曲:"规模就是一切,算法不重要。" 正如斯坦福 CS336 课程所强调的,更准确的解读是:能够有效利用规模的算法才最重要。 模型的最终性能可以近似表达为
效率的提升速度甚至超过了摩尔定律(Moore's Law):FlashAttention 仅凭内存访问模式的重构就将注意力计算加速 2--4 倍,在大规模训练中可节省数百万美元成本。因此,LLM 生命周期中每一个阶段的设计,都在回答同一个核心问题:在给定的计算和数据预算下,如何构建最好的模型?
这正是 Scaling Law(缩放定律)研究的核心关切。Kaplan 等人(2020)和 Hoffmann 等人(2022,即 Chinchilla 论文)先后给出了模型参数量
0.2.2 预训练:通用知识的涌现
预训练(Pre-training)是 LLM 生命周期中计算成本最高、时间跨度最长的阶段。其目标是让模型在海量无标注文本上学习语言的统计规律,从而获得广泛的通用知识和语言能力。
训练目标。 当前主流的预训练范式是因果语言建模(Causal Language Modeling, CLM),也称自回归语言建模:给定一段文本
这个看似简单的"预测下一个 token"目标,是 GPT 系列得以成功的基石。2018 年 OpenAI 发布的 GPT-1(1.17 亿参数)首次系统性地验证了"生成式预训练 + 下游微调"的范式,证明了即使使用最基础的语言建模目标,也能在 12 项 NLP 任务中的 9 项取得当时最优表现。随后 GPT-2 将参数量扩展到 15 亿,首次观察到了"零样本迁移"能力;GPT-3 进一步扩展到 1750 亿参数,展现出强大的 In-Context Learning(上下文学习)能力,无需任何梯度更新即可在 42 项 NLP 任务上取得优异表现。
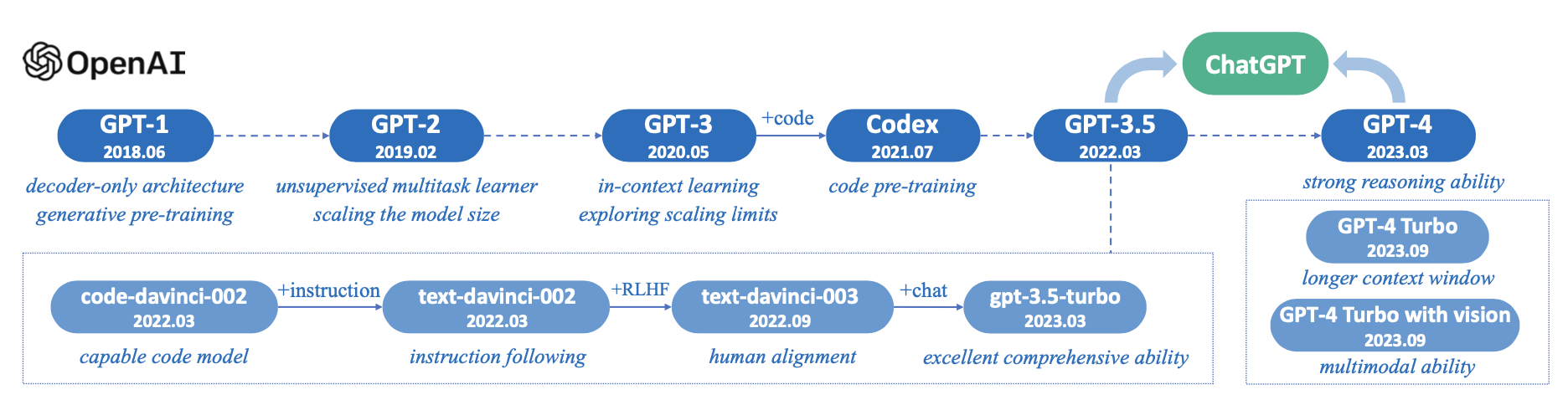
数据准备。 预训练的数据规模已从 GPT-1 时代的约 8 亿词增长到当前前沿模型的数十万亿 tokens,覆盖数百种语言。数据流水线通常包含"收集、清洗、去重、格式转换、质量过滤"五个环节。高质量数据对模型性能的影响远超模型结构差异——在 MMLU 等基准上,顶尖模型之间的性能差距往往源于数据质量而非架构。
计算规模与并行策略。 预训练阶段需要协调数千乃至数万张 GPU 持续运行数周甚至数月。为突破单卡显存限制,现代训练系统普遍采用混合并行策略:
- 数据并行(Data Parallelism):将数据分片到不同 GPU,同步梯度更新参数。DeepSpeed ZeRO 技术通过分区存储模型状态(权重、梯度、优化器),使单 GPU 可支持万亿参数模型的训练。
- 张量并行(Tensor Parallelism):Megatron-LM 将 Transformer 权重矩阵按行列拆分到不同 GPU,解决单卡无法容纳整个模型的问题。
- 流水线并行(Pipeline Parallelism):按层拆分模型到不同 GPU,通过微批次(micro-batch)实现不同批次的并行计算。
以 DeepSeek-V3 为例,其预训练阶段消耗约 266.4 万 H800 GPU 小时(按每 GPU 小时 2 美元计算约 533 万美元),占总训练成本的绝对多数。这一数据直观地说明了预训练是整个生命周期中的"重资产"环节。
大模型规模化的崛起背后,是算法、工程、软件、硬件四个维度的协同进化。Transformer 提供了适合并行的算法结构;CUDA 生态提供了连接算法与硬件的编程模型及高度优化的库(cuBLAS、cuDNN、NCCL);NVLink 提供了 GPU 间的高速互连通道;DeepSpeed 等框架则将底层复杂性封装为简单的配置接口。正是这种全栈协同,推倒了限制模型规模的技术壁垒。
0.2.3 后训练:从基座到助手
预训练模型(base model)虽然习得了丰富的语言知识和世界知识,但它本质上仍然只是一个"文字接龙"系统——给定前文,概率性地续写下一个 token。要将其转变为一个能理解用户意图、遵循指令、安全可靠的 AI 助手,需要经历后训练(Post-training)阶段。
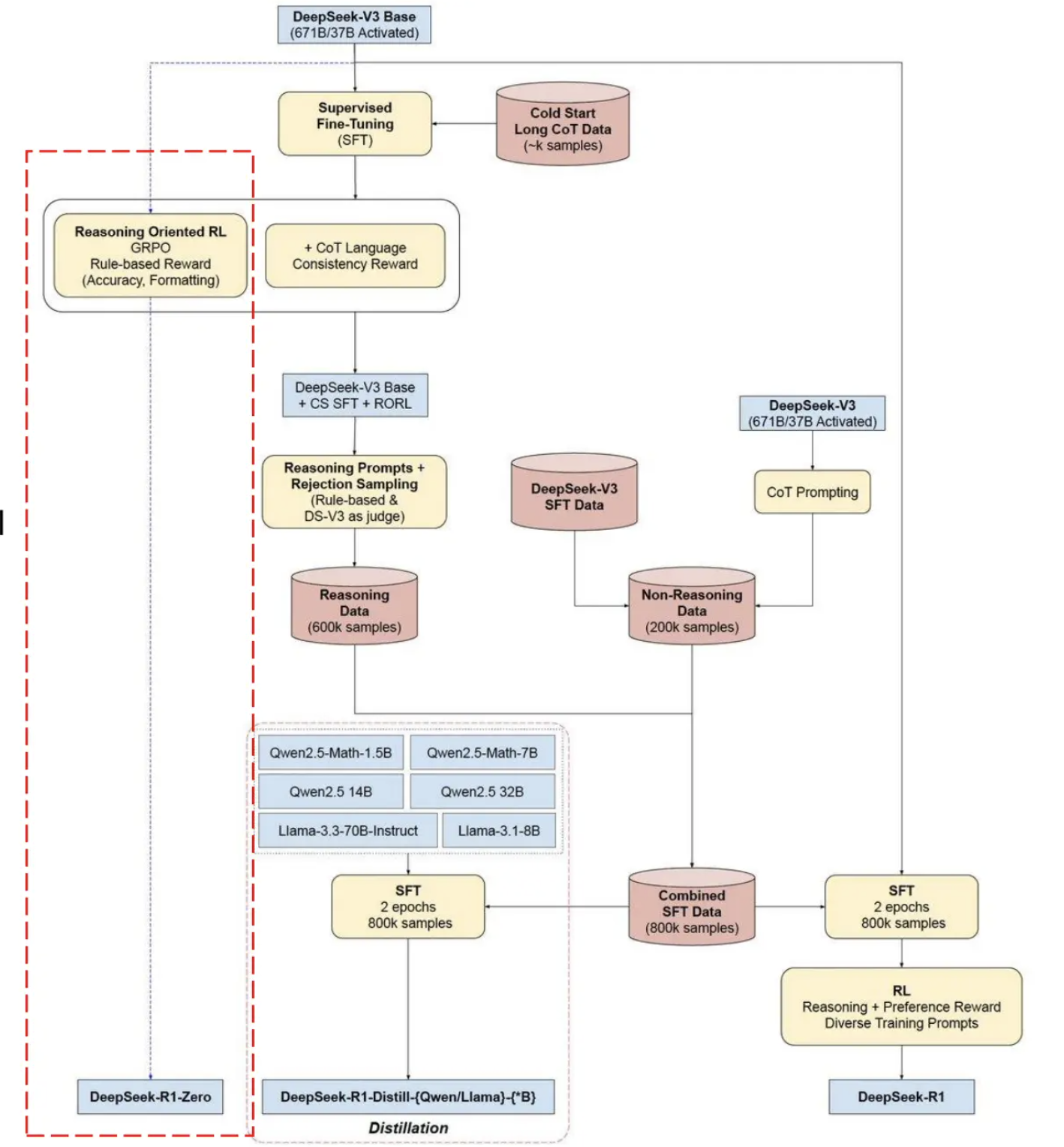
后训练通常包含以下几个核心步骤:
监督微调(Supervised Fine-Tuning, SFT)。 使用人工构造的高质量"指令-回答"对来训练模型,使其学会遵循特定的输入输出格式、理解用户指令并给出结构化的回答。SFT 阶段的数据量通常只有数万到数十万条——相比预训练的数十万亿 tokens,数据规模小了多个数量级。这一阶段的核心洞见是:基座模型已经在预训练中获取了足够的知识储备,后训练的作用是引导它以正确的方式释放这些知识。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)。 当 SFT 无法完全捕捉人类偏好时(例如,两个回答都语法正确但风格差异显著),RLHF 提供了一种更精细的优化机制。其流程通常是:首先训练一个奖励模型(Reward Model)来建模人类偏好(给定两个回答,哪个更好),然后利用强化学习算法(如 PPO 或更简洁的 DPO)优化策略模型使其最大化预期奖励。RLHF 是从 GPT-3 基座模型到 ChatGPT 产品的关键技术跃迁。
推理强化学习。 近期(以 OpenAI o1 和 DeepSeek-R1 为代表),后训练范式进一步延伸到推理能力的专项强化。通过在数学推理、代码编写等需要深度推理的任务上进行强化学习训练(典型如 GRPO 算法),模型学会了在生成过程中展开长链思考(Chain-of-Thought)。这一阶段所需的训练题目可能仅有数千道,但对推理能力的提升却极为显著。
参数高效微调。 对于计算资源有限的场景,LoRA(Low-Rank Adaptation)等技术冻结预训练参数,仅训练少量低秩矩阵,在多数任务上可达到全参数微调 90% 以上的性能,而计算成本仅为其 10%。这使得中小团队和特定领域的适配成为可能。
从训练成本的对比可以直观感受到"预训练为主、后训练为辅"的格局:以 DeepSeek-V3 为例,后训练阶段仅消耗约 5000 H800 GPU 小时(约 1 万美元),不到预训练成本的 0.2%。
0.2.4 推理部署:从实验室到生产环境
模型训练是一次性成本,而推理(Inference)的成本与用户调用次数成正比——对于大规模部署的模型,推理成本往往远超训练成本。因此,推理部署是 LLM 生命周期中工程复杂度最高的环节之一。
自回归生成的瓶颈。 LLM 的推理过程本质上是逐 token 的自回归生成:每次生成一个 token,都需要将其拼接到已有序列的末尾,然后再次前向传播来预测下一个 token。这种串行特性使得推理的延迟(latency)与生成长度线性相关,而吞吐量(throughput)则受限于 GPU 利用率。
关键优化技术。 围绕这一瓶颈,工业界发展出了一系列优化方法:
- KV Cache(键值缓存):避免在每次生成新 token 时重复计算之前所有 token 的注意力键值对,将自回归推理的计算复杂度从
降至 。 - 量化(Quantization):将模型权重从 FP16/BF16 压缩到 INT8 甚至 INT4,在精度损失可控的前提下大幅降低显存占用和计算量。
- 推测解码(Speculative Decoding):使用一个小型模型快速生成候选 token 序列,再由大模型并行验证,从而在不降低输出质量的前提下加速生成。
- 批处理优化:通过连续批处理(Continuous Batching)等技术,提高 GPU 的利用率和系统吞吐量。
成本驱动的演进。 推理成本的下降速度令人瞩目。以 GPT-3.5 级别的系统为例,推理成本在两年内下降了约 280 倍。这种降幅来自硬件迭代、算法优化和系统工程的共同作用,也使得大模型从实验室走向大规模商业化成为现实。
0.2.5 评估:闭环的关键一环
评估(Evaluation)贯穿 LLM 生命周期的始终——它不仅发生在模型发布前的验证阶段,还嵌入在预训练过程中(监控训练损失和验证集困惑度)、后训练过程中(检验对齐效果)以及部署后的持续监控中。
基础指标。 困惑度(Perplexity)是预训练阶段最常用的内在评估指标,定义为
困惑度越低,表示模型对文本的预测越准确。但低困惑度并不直接等同于高下游任务性能,因此还需要综合能力评估。
综合评估基准。 当前主流的评估体系覆盖多个维度:
- 知识与推理:MMLU(57 个学科领域)、GPQA(博士级专业知识)、ARC 等。
- 代码能力:HumanEval、SWE-bench 等。
- 数学推理:GSM8K、MATH、AIME 等。
- 安全与对齐:HELM Safety、AIR-Bench 等,检测偏见、毒性和事实性。
- 多模态能力:涉及图文音视频理解与生成的新兴基准。
评估的工程化。 在工业实践中,评估被整合进 MLOps 流水线,形成"训练、评估、调优、增量训练"的自动化闭环。实验跟踪系统(如 MLflow)和模型注册表确保了训练过程的可追溯性和可复现性,为迭代优化提供数据支撑。
0.2.6 生命周期的闭环与迭代
上述四个阶段并非简单的线性流水线,而是构成一个持续迭代的闭环:
- 预训练 生成基座模型,确定模型的知识容量上界;
- 后训练 将基座模型对齐到特定应用场景,释放其潜力;
- 推理部署 将模型交付给用户,产生实际使用数据;
- 评估 从基准测试和用户反馈中发现不足,指导下一轮迭代。
每一轮迭代都可能触发数据的重新收集与清洗、训练策略的调整、乃至模型架构的重新设计。高效的 AI 基础设施(AI Infra)可以将模型迭代周期从数月缩短至数周。
回到 Sutton 的教训:这个闭环的每一处改进,无论是更优的数据管道、更高效的并行策略、还是更精准的评估方法,最终都服务于同一个目标——在有限的计算与数据预算下,持续逼近更强的模型。这不是某一种"巧妙方法"的胜利,而是整个系统在 Scaling 维度上持续优化的结果。理解这一点,是进入后续各章深入学习的认知前提。