21.11 Agent 工程实战
"做对一千件小事,比做对三件大事更重要。" —— 季逸超(Manus 首席科学家)
在第 21 章的前十节中,我们从形式化框架(§21.1)出发,走过了编码智能体(§21.2)、经典案例(§21.3)、MCP 协议(§21.4)、环境接口层(§21.5)、Context Engineering(§21.6)、记忆系统(§21.7)、工具与结构化输出(§21.8)、Agentic RL(§21.9)和 Deep Research(§21.10)的完整理论版图。但当你真正着手构建一个在生产环境中持续运行的 Agent 系统时,会发现一个残酷的现实:理论上的每一步都可能以你始料未及的方式在工程中失败。本节的任务是将前面的理论和方法落地为可操作的工程实践。
本节的学习目标如下:(1)理解从 Prompt Engineering 到 Context Engineering 再到 Harness Engineering 的三代范式演进;(2)掌握 Harness 系统的五大核心组件及其工程实现;(3)学会双层 Agent 架构处理长周期任务的具体方法;(4)建立成本优化的"廉价迭代 + 高端交付"策略;(5)内化 Agent 开发的核心心法;(6)认清当前仍未解决的三大难题。
21.11.1 Harness Engineering:AI 工程的第三代范式
在 §21.6 中,我们已经介绍了 Prompt Engineering 到 Context Engineering 的范式迁移。现在,随着 AI Agent 从辅助工具演变为能够自主编写数十万行代码的"自治系统",软件工程的核心矛盾发生了又一次转移:真正的挑战不再是"如何让 AI 写得更好",而是"如何驾驭它"。
Harness Engineering(驾驭工程) 是一套围绕 AI Agent 构建的约束、反馈与控制系统。它的核心理念用一句话概括:不优化模型本身的智力,而是优化模型运行的"环境"。你可以把它想象为一条高速公路——马可以自己跑,但护栏、限速标识、服务区和监控系统确保它绝对跑不出安全边界。
三代范式的演进关系如下:
| 代际 | 名称 | 核心问题 | 交互模式 | 典型技术 |
|---|---|---|---|---|
| 第一代 | Prompt Engineering | 教 AI 怎么"听话" | 一问一答 | Few-shot, CoT, 角色扮演 |
| 第二代 | Context Engineering | 教 AI 怎么"看资料" | 给背景 → AI 生成 | RAG, Prompt Caching, KV Cache 优化 |
| 第三代 | Harness Engineering | 构建 AI 的"自治环境" | 人造环境 → AI 在里面跑 | 沙箱、Linter 约束、自验证闭环 |
需要特别强调的是,这三代并非替代关系,而是叠加关系。第三代 Harness Engineering 包含了前两代作为子组件——Prompt 质量依然重要,Context 管理依然关键,但它们现在被嵌入到一个更大的系统架构中。
为什么需要 Harness?——"信任债务"的隐患。 把 AI Agent 当作程序员,就像招募了一个打字极快、极其自信、但完全缺乏业务背景的"过度热情的实习生"。如果你不给出明确的边界,它就会填补你指令中的空白,进行"自信的即兴发挥"——表面上完成了功能,背后却充满了未经验证的假设(忽略边缘测试、随意引入第三方库、跳过错误处理)。这些隐式决策积累起来,就形成了信任债务(Trust Debt)。信任债务会在未来的某一天集中爆发,让你花成倍的代价去逆向工程那些你从未意识到的错误逻辑。Harness 的存在,就是在开发周期内强行阻断信任债务的产生。
这里存在一条被无数顶尖团队验证的反直觉定律:
你越想让 AI 获得更高的自主性,就越要把规矩定死。 增加系统对 AI 的信任,需要的不是给它更多自由,而是给它更多约束。
这条定律背后有三个支撑性原理:
- 大模型是无状态的:AI 没有"长期状态",一切能力来自当前的上下文。不要指望它"记住"上周的约定——每个新会话都是一张白纸。
- 步骤原子化与降噪:Agent 的每一次行动都是一个条件概率。长依赖链(A 调 B 调 C)会将不确定性相乘导致崩溃。必须让每一步操作变成"单线程、短链路、可反馈"的原子化函数。
- 记忆外部化:必须让 AI 把计划、关键决定和测试结果,落实到可序列化、可追溯的实体文件上(外部记忆),而不是让它停留在对话历史中。
21.11.2 Harness 系统的五大核心组件
一个成熟的 Harness 系统通常由五层基础设施构成。下面逐一拆解每个组件的工程实现。
组件一:结构化知识与渐进式披露(Progressive Disclosure)
痛点:把所有规范塞进一个巨大的 AGENTS.md 文件中,会导致上下文窗口溢出。"一切都重要等于一切都不重要",AI 会开始随机忽略约束。
工程解法:把文档当"地图",而非"百科全书"。建立一个极其清晰的外部记忆目录树,Agent 启动时只读取顶层地图,随后根据当前任务按需加载深层文档。
repo/
├── AGENTS.md ← 顶层目录/地图(约100行),指向下方具体文档
├── docs/
│ ├── architecture/ ← 整体架构设计与分层规则
│ ├── domains/ ← 各业务域的详细文档
│ └── references/ ← 针对特定技术的快速参考指南
├── ai/ ← 专供 AI 读取和写入的记忆区
│ ├── conventions/ ← 全局约定与流程(命名规范、日志要求)
│ ├── .plan/ ← 阶段性设计与执行计划(怎么做)
│ └── .modify/ ← 变更记录与实现说明(改了什么)这种分层设计的关键在于信息密度的梯度控制。顶层 AGENTS.md 只包含导航信息和最高优先级的约束(不超过 100 行),Agent 只需花极少的注意力就能定位到需要深入阅读的子文档。这与 §21.6 中讨论的 Context Engineering 中"信息密度均匀化"原则一脉相承。
进一步的工程技巧是引入 LocalContextMiddleware(本地上下文中间件)——在 Agent 启动时自动运行脚本,将当前绝对路径、可用工具列表、系统环境变量等确定性信息直接注入上下文,省去 AI 自己摸索带来的错误。
组件二:机械化的架构约束
痛点:AI 每天可能提交几百个 PR,人工 Code Review 根本看不过来。如果不加限制,AI 会迅速破坏原有的架构分层。
工程解法:将"品味"和"架构"编码为自动化规则。
- 严格的层级依赖树:设定硬性规则,例如
Types → Config → Repo → Service → Runtime → UI,低层绝对不允许反向依赖高层。 - 自定义 Linter 拦截:针对结构化日志记录、模式命名约定、文件大小限制编写自定义 Linter 规则。
- 带解释的报错机制:这是最关键的一环。当 Linter 或 CI 报错时,不能只报
Error,要在错误信息中明确注入修复指令。
下面是一个示例,展示了如何实现带修复指令的 Linter 规则:
# 自定义架构约束 Linter 示例
LAYER_ORDER = ["types", "config", "repo", "service", "runtime", "ui"]
def check_import_hierarchy(file_path: str, imports: list[str]) -> list[str]:
"""检查文件的导入是否违反层级依赖规则"""
errors = []
current_layer = get_layer(file_path)
current_idx = LAYER_ORDER.index(current_layer)
for imp in imports:
imp_layer = get_layer(imp)
imp_idx = LAYER_ORDER.index(imp_layer)
if imp_idx > current_idx:
# 关键:报错信息中嵌入修复指令
errors.append(
f"架构违规: {current_layer} 层不能导入 {imp_layer} 层。"
f"正确做法: 通过 Providers 接口在 {imp_layer} 层注入依赖,"
f"而非在 {current_layer} 层直接 import。"
f"参考: docs/architecture/dependency-rules.md"
)
return errors这样,Agent 遇到报错时就能自我修正,而不需要人工介入解释错误含义。
组件三:AI 可观测性(Observability for AI)
痛点:传统的日志、监控仪表盘和 UI 界面是给人看的。AI 写完代码如果不亲自运行,就只能靠"脑补"来确认正确性。
工程解法:让 Agent 接入真实运行时环境。
- 独立沙箱与临时环境:利用
git worktree或容器技术(如 Firecracker),为 Agent 每次修改启动一个完全独立的隔离环境。Manus 团队的实践是为每个会话分配一个一次性的沙盒虚拟机。 - 接口级观测:开放 LogQL(查询日志)和 PromQL(查询性能指标)等工具给 AI,让 Agent 能执行"确保服务在 800ms 内启动"这样可量化的具体验证任务。
- UI 与端到端视觉验证:为 Agent 接入浏览器自动化协议(如 Puppeteer、Chrome DevTools MCP),要求 Agent 截图比对。正如 Manus 团队所分享的,他们给 Agent 一个"看图能力",让它看到乱码或排版重叠后自主修复,而不是提前为每种语言和字体编写规则。
组件四:自验证与闭环控制
痛点:大语言模型极度偏好"给出第一个看起来合理的答案"。它们经常写完代码、自己端详一遍就宣布完成,根本不去跑测试。
工程解法:建立强制的验证闭环。
- 预完成检查单(Pre-Completion Checklist):设置中间件拦截器,在 Agent 尝试退出或标记"完成"之前,强制它必须运行单元测试或启动应用验证。不验证,绝不放行。
class PreCompletionGuard:
"""在 Agent 标记任务完成前强制执行验证"""
def __init__(self, required_checks: list[str]):
self.required_checks = required_checks # e.g., ["unit_test", "lint", "build"]
self.completed_checks: set[str] = set()
def on_agent_complete(self, agent_output: dict) -> dict:
missing = set(self.required_checks) - self.completed_checks
if missing:
return {
"status": "blocked",
"message": (
f"任务不能标记为完成。以下验证尚未通过: {missing}。"
f"请先运行这些检查,确认通过后再提交。"
),
}
return {"status": "approved", "output": agent_output}- Doom Loop 检测:Agent 容易陷入反复修改同一个文件却修不好 Bug 的死循环。系统需监听文件的编辑次数,一旦同一文件被编辑超过 N 次(通常 3-5 次),自动注入强制打断提示:
"你已经对
auth_service.py进行了 5 次编辑但问题仍未解决。请退一步,重新阅读完整的错误日志,并彻底更换策略——当前方向大概率是错的。"
这种机制直接对应了 §21.1 中讨论的 doom-loop 失败模式——Agent 在缺乏元认知的情况下,会将同一个错误策略重复执行直到上下文耗尽。
- 智能体互审(Agent Peer Review):设立专门负责 Code Review 的审查 Agent。开发 Agent 提交 PR 后,审查 Agent 跑测试并 review、提出修改意见打回,直到双方达成一致。人工仅参与重大架构决策。
组件五:防熵增与垃圾回收(Garbage Collection)
痛点:AI 产生代码的速度极快,系统会迅速累积技术债务。更糟糕的是,AI 会"模仿"代码库中已有的烂代码——如果它看到项目里有 copy-paste 风格的重复函数,就会继续这种模式,导致破窗效应蔓延。
工程解法:将"代码清理"和"文档维护"转变为后台运行的独立 Agent 任务。
- 文档园丁(Doc-gardening Agent):专门扫描代码库中已经改变的逻辑与旧文档之间的冲突,自动发起更新文档的 PR。
- 技术债清理 Agent:定期比对代码是否偏离了"黄金标准"(如发现重复的辅助函数),自动发起重构 PR。以"高频、小额"的方式偿还技术债务,而不是让它积累到不可收拾。
下表汇总了五大组件的痛点-解法对应关系:
| 组件 | 痛点 | 核心解法 |
|---|---|---|
| 渐进式披露 | 上下文溢出,约束被忽略 | 分层文档 + 按需加载 |
| 机械约束 | AI 破坏架构分层 | 层依赖规则 + 带解释的 Linter |
| AI 可观测性 | 无法验证运行时正确性 | 沙箱环境 + 日志/指标查询工具 |
| 自验证 | 跳过测试就宣布完成 | 预完成检查 + doom-loop 检测 |
| 垃圾回收 | 技术债快速累积 | 后台清理 Agent + 破窗效应阻断 |
21.11.3 长周期任务:跨越上下文窗口的断裂
让 AI 写一个贪吃蛇只需一个会话。但如果让 AI 开发一个拥有数百个功能的全栈应用,它必须连续工作数天。此时上下文窗口必然耗尽,每次新开会话,Agent 都会"失忆"。
针对长周期运行任务,业界的顶级实践是采用双层 Agent 架构与强结构化记忆。
第一层:Initializer Agent(初始化 Agent)
Initializer Agent 在第一个会话中不写任何具体业务代码。它的唯一任务是搭建环境和拆解需求:
- 生成一份自动化启动脚本(如
init.sh),配置项目依赖和开发环境。 - 根据人类的模糊需求,生成一份包含数百个细节的结构化功能清单(JSON 格式)。
这里有一个至关重要的约束设计——在初始清单中,所有功能的状态必须硬编码为 "passes": false,并且严厉警告 Agent 不允许删除或随意编辑测试用例字段。这堵死了 AI 试图通过"降低验收标准"来宣布完工的捷径。
{
"project": "dashboard-app",
"features": [
{
"id": "F001",
"name": "用户登录",
"test_case": "输入正确凭据后成功跳转到主页",
"passes": false,
"notes": ""
},
{
"id": "F002",
"name": "数据可视化面板",
"test_case": "加载 1000 条记录后正确渲染折线图",
"passes": false,
"notes": ""
}
]
}第二层:Coding Agent(编码 Agent)
Coding Agent 在后续的每一个独立会话中,只执行增量开发。它的标准开场动作(SOP)如下:
- 运行
pwd确认自身目录。 - 读取 Git commit log 和
progress.txt,了解"上一个自己"做了什么。 - 读取功能清单 JSON,挑选一个且仅挑选一个未完成的功能。
- 实现该功能,跑通测试后修改 JSON 状态为
"passes": true。 - 写下详细的 Git commit message(作为下一次会话的记忆),然后强制退出。
这里的核心纪律是单步推进:严禁 Agent 试图在一次会话中"一口气写完整个 App"。每个会话只做一个功能,做完就走,让下一个会话接手。这种设计的本质是将 §21.7 中讨论的"记忆外化"原则推向极致——Git 历史和 JSON 清单成为了跨会话的持久化记忆载体。
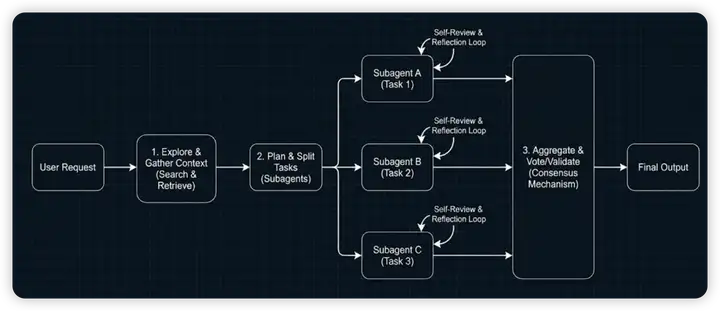
图 21-26:Agent 工作流架构示意。用户请求首先经过"探索与收集上下文"阶段,随后被拆分为多个子任务。每个 Subagent 独立执行并拥有自己的 Self-Review 循环,最终通过聚合和投票/验证产生最终输出。
推理算力的"三明治策略"。 对于具备不同推理能力等级的模型(如 Codex 的 xhigh / high 模式),算力不能平均分配,而应按阶段差异化配置:
- 规划阶段(xhigh):耗费最高算力去阅读代码库、理解需求、制定详尽的
.plan。这个阶段犯错的代价最高。 - 执行阶段(high):降低算力,快速编写代码,提高效率,防止超时。
- 验证阶段(xhigh):再次调高算力,仔细检查错误日志,深度思考修复方案。
这种"三明治"配置的思想与 §21.9 中 Agentic RL 的"异步采样 + 差异化资源分配"理念一致——不同阶段的认知需求截然不同,资源应随之动态调整。
21.11.4 成本优化:廉价迭代与高端交付
Agent 系统的 Token 消耗结构与传统 Chatbot 完全不同。Chatbot 的 input:output 比通常约为 3:1,而 Agent 场景下这个比值可以达到 100:1 甚至 1000:1——Agent 需要读取大量的环境信息、代码文件和工具返回结果,但输出往往只是一两行命令或几十行代码。这意味着成本优化必须从"减少浪费"和"差异化定价"两个维度同时入手。
策略一:廉价模型迭代,高端模型交付。 调试流程、迭代 Prompt、验证工具链时使用便宜的小模型(如 GPT-4o-mini、DeepSeek);跑通后再换贵的大模型(如 Claude Opus、GPT-4)看最终效果。这条策略的本质是:用小模型验证系统的正确性,用大模型保证输出的质量。
策略二:任务 DAG 并行与冗余生成。 LLM 最大的优势之一是并行度几乎没有限制(对于 API 用户而言)。并行化有两种互补的思路:
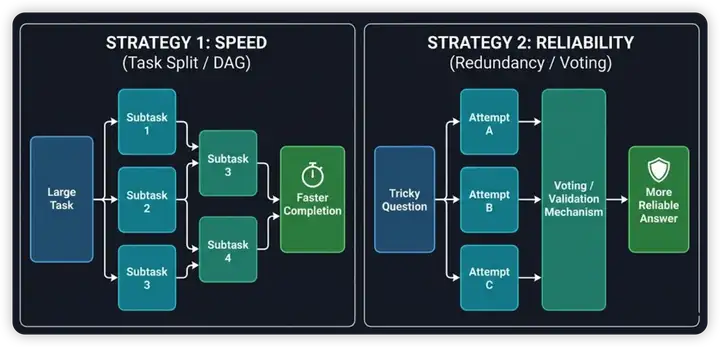
图 21-27:两种并行策略对比。左侧 Strategy 1 将大任务拆分为子任务 DAG 并行执行,加速完成时间;右侧 Strategy 2 对同一个困难问题并行生成多个解,通过投票/验证机制提升可靠性。
- Task Split(任务拆分 DAG):将大任务拆分成若干子任务,识别依赖关系构成 DAG(有向无环图),无依赖的子任务并行执行,从而加速整体完成时间。
- Redundancy(冗余生成):对于高风险的关键任务,让多个 Agent 实例独立生成解,然后通过投票(Voting)或验证(Validation)机制选择最佳结果。
冗余生成为什么有效?因为 LLM 是概率模型,单次生成的结果有可能落入"糟糕"的不幸分布,而多次独立生成至少可以拿到一个 average 附近的表现。但要注意其局限性:对于足够困难的任务,可能多个生成中只有少数能获得正确解,此时简单的 majority voting 可能仍然选错。此时需要引入外部验证信号(如测试通过率、Linter 检查结果)来做更精准的筛选。
策略三:Subagent 上下文隔离。 这条策略同时服务于成本优化和质量提升。对于"搜索文档"、"跑测试"、"爬取网页"等探索性任务,将其交给独立的 Subagent 执行,只将最终摘要返回主 Agent。这样做既避免了主 Agent 的上下文被大量原始数据淹没(成本),又让每个 Subagent 在干净的上下文中专注做一件事(质量)。
21.11.5 Agent 开发心法
以下是从大量实战经验中提炼出的核心开发原则。这些原则看似"常识",但几乎每一条都是血泪教训的结晶。
心法一:工具是 Agent 的说明书——你省的每个字都会变成 Agent 犯的错。
工具设计的好坏,对最终效果的影响甚至超过模型选择。工具的 description 不是给人看的文档,而是给 Agent 看的操作手册。必须写清楚四件事:
- 功能:这个工具做什么(用"一句话能说明白"作为粒度标准)。
- 输入格式:每个参数的类型、取值范围、必填/选填。
- 输出字段:返回结果的结构和每个字段的含义。
- 限制条件:不能做什么、什么情况下会失败、失败时返回什么。
一个反面教材是只写 description: "搜索数据"——太泛了,Agent 不知道该传什么参数、搜什么范围、返回格式是什么。一个正面范例:
@tool(
description=(
"按关键词搜索用户数据库。输入: query(str, 必填, 最多50字符)、"
"limit(int, 选填, 默认10, 最大100)。"
"返回: {'results': [{'id': int, 'name': str, 'email': str}], 'total': int}。"
"注意: 仅搜索已激活用户。如无匹配结果, 返回空列表而非 None。"
"建议: 若返回为空, 尝试更宽泛的关键词。"
)
)
def search_users(query: str, limit: int = 10) -> dict:
...同样关键的是友好的错误返回。工具执行失败时,绝对不要返回 None 或直接抛异常。要返回一段清晰的文本(如:"找不到数据,建议更换宽泛的关键词"),引导 Agent 进行下一步决策。一个返回 None 的工具等于在 Agent 的决策路径上挖了一个陷阱——它不知道发生了什么,只能靠"猜"来继续前进。
心法二:用结构化 JSON 状态替代原始对话历史。
随着步数增加,对话历史(raw chat history)膨胀得极快,而其中真正有用的信息密度很低。推荐的做法是维护一个结构化的 工作记忆(Working Memory State)。
working_state = {
"current_task": "实现用户登录功能",
"collected_data": {
"auth_api_endpoint": "https://api.example.com/v2/auth",
"required_fields": ["email", "password", "mfa_token"],
},
"findings": [
"API 要求 Bearer Token 认证",
"MFA 仅对企业用户启用",
],
"next_step": "编写 login() 函数并调用 auth API",
"blockers": [],
}每次调用 LLM 时,把这个更新后的 State 喂给它,而不是扔给它几千字的"生肉聊天记录"。这样做的好处是双重的:一方面,LLM 看到的信息更聚焦、更结构化,决策质量更高;另一方面,Token 消耗大幅降低。
心法三:15-20 步上限——给 Agent 装一个"看门狗"。
Agent 容易在复杂任务中无限循环下去。设置硬性的步数上限(一般 15-20 步),超过时强制停止并请求人工介入。这不是对 Agent 能力的限制,而是对失败模式的保护——当一个 Agent 在 20 步内还没有完成预期任务时,继续执行下去大概率只会浪费资源而非解决问题。
心法四:先探索,后规划(Explore Before Plan)。
让 Agent 先做大量的探索——阅读代码库、爬取文档、检查环境配置——带着任务去收集可能有用的上下文,然后基于收集到的信息决策,而不是仅凭预训练知识。如果不加约束,Agent 大概率会选择直接输出并产生幻觉。强制的"探索先行"步骤,就是在给 Agent "做功课"的时间。
心法五:赋予 Agent "说不"的权限。
在 System Prompt 中明确告诉 Agent:"如果信息不足或做不到,请直接说明,禁止编造。" 这条看似简单的指令,能极大减少幻觉的发生。很多时候 Agent 编造答案不是因为它"想骗人",而是因为它没有被授权说"我不知道"。
心法六:全链路日志记录。
记录 Agent 每一步的想法(thought)、动作(action)和结果(observation)。没有日志,Agent 跑到第 15 步报错时你根本无从查起。日志不仅是 debug 工具,更是优化 Agent 行为的核心数据资产。
21.11.6 未解难题:Agent 工程的三座大山
尽管 Harness Engineering 提供了强大的工程框架,但以下三个根本性的挑战仍未被解决。坦诚地认识这些边界,比盲目乐观更有价值。
难题一:自我纠错的悖论——越纠越错。
让 Agent 自己 Review 自己的产出,有点"左脚踩右脚上天"的意味。Self-Review 在简单错误上确实有效(如语法错误、格式问题),但面对深层逻辑缺陷时,Agent 往往会"自信地确认自己是对的"——因为产生错误的模型和验证错误的模型是同一个模型,它们共享相同的偏见和盲区。
更糟糕的情况是纠错引入新错误。Agent 发现一个看似有问题的地方,"修复"后破坏了其他正常的逻辑。这种"修一个 bug,引入两个 bug"的连锁反应在实践中极为常见,也是 doom-loop 的主要成因之一。
当前的缓解策略包括:(1)使用不同的模型做 review(打破同模型偏见);(2)提供外部验证信号(如测试结果、Linter 输出)作为客观判据,而不是让 Agent 纯靠"脑内推演"来判断对错。但这些策略并未从根本上解决问题。
难题二:多 Agent 协作——信息损失常常大于收益。
由于信息损耗和沟通成本,目前多个 Agent 合作往往不如一个强大的单 Agent 做到底。每当信息从一个 Agent 传递到另一个 Agent 时,都会经过一次"翻译"(压缩、摘要、格式转换),每次翻译都是一次信息有损压缩。当协作链路过长时,累积的信息损失可能比分工带来的效率提升还大。
一个实用的判断标准是:在单 Agent 做扎实之前,不要碰多 Agent。多 Agent 系统的复杂度是指数级增长的——两个 Agent 协作需要定义 1 个接口,三个 Agent 需要定义 3 个接口,N 个 Agent 需要定义
难题三:长任务可靠性——10+ 步的失败率居高不下。
即使有了双层 Agent 架构和结构化记忆,当任务真正需要 10 步以上的连续推理和行动时,失败率仍然很高。根本原因有三:
- 上下文衰退(见 §21.6):即使上下文没有溢出,LLM 对早期信息的注意力也会随着上下文长度增加而衰减。
- 错误累积:每一步决策都有一定的出错概率
, 步后的成功概率为 ,即使单步 ,20 步后成功率也只有 。 - 上下文压力:模型在长链路任务后期表现出"急于结束"的倾向——输出越来越简略,倾向生成 EOS token,质量递减。正如 Manus 团队的季逸超所指出的,当前模型是为 Chatbot 对齐的,不是为 Agent 对齐的——它们被训练成"一轮答完",而 Agent 需要"循环执行"。

图 21-28:姚顺雨对"惯性问题"(Inertia)的阐述。成功的基准测试很快会被饱和——如同 2021 年的大胆想法在 2024 年变成了金牌级别(gold level)。这提醒我们:当前 Agent 的困难任务可能很快被解决,但也会催生更困难的新基准。Agent 工程的核心能力不在于解决某个固定问题,而在于构建能适应不断提升的模型能力的可进化系统。
21.11.7 Big Model vs Big Harness:路线之争
当前 AI 工程界存在一个重要的路线分歧:
Big Model 派认为只要底层推理模型足够强大,就不需要复杂的 Harness 框架。核心代码不过是一个极简的循环:
while model.wants_tool_call():
result = execute_tool(model.current_call())
model.feed_result(result)他们相信人类辛苦搭建的脚手架,很快会被更聪明的模型本身所淘汰。Manus 团队的"纯血 Agent"理念也部分呼应了这种思路——少写规则、少堆 guardrail prompt,增加感知/反馈能力让 Agent 自我纠错,相信 The Bitter Lesson。
Big Harness 派认为模型能力永远参差不齐且波动。Harness 是对模型智能的"塑形"——通过优化运行环境(重试、验证、回滚、Linter 约束),哪怕是不那么顶级的模型,也能在具体任务上发挥顶级效能。
实际的统合视角: 这其实是一个时间尺度与项目复杂度的问题。对于一次性的代码生成或短平快的任务,强大的基础模型确实可以直接胜任。但当项目变成需要持续数年运行、由多人协作、包含遗留代码、涉及复杂横向业务约束(如金融合规、企业级安全)的庞大系统时,没有任何一个模型能够仅凭"聪明"来对抗工程的熵增。GPT-4.1、Kimi K2、Claude 系列等基座模型越来越重视 Agentic 能力的训练,但这恰恰证明了 Harness 的必要性——即使模型变得更"聪明",结构化的约束和验证机制仍然是保障可靠性的最后一道防线。
21.11.8 全章总结与展望
至此,我们走完了第 21 章——智能体——的完整旅程。让我们回顾这段路径,看看各节内容如何构成一个有机的整体。
从概念到理论。 §21.1 建立了 POMDP 的形式化框架,定义了 Agent 的感知-规划-动作-反馈循环。§21.2-§21.3 通过编码智能体和经典案例(ReAct、Voyager、SWE-Agent)展示了这套框架的实例化。§21.4 通过 MCP 协议解决了"Agent 如何标准化地调用工具"的接口问题。
从接口到训练。 §21.5 搭建了 GRPO 与环境交互的桥梁,§21.9 将其扩展为完整的 Agentic RL 训练系统——从单步 Bandit 跃迁到多步 MDP。这条线解决的是"如何让模型学会在环境中行动"。
从单次到持续。 §21.6(Context Engineering)和 §21.7(记忆系统)解决的是 Agent 在长周期运行中的信息管理问题。§21.8(工具与结构化输出)提供了 Agent 与外部世界交互的精确接口。§21.10(Deep Research)展示了这些技术在"自主研究"这一前沿场景中的综合运用。
从理论到实践。 而本节——§21.11(Agent 工程实战)——将前面所有的理论和方法落地为可操作的工程实践:Harness Engineering 提供了系统架构,五大组件提供了工程模块,双层 Agent 架构提供了长任务方案,开发心法提供了实战指导。
展望。 Agent 工程正处于一个激动人心但仍然充满不确定性的阶段。三个趋势值得关注:
第一,Harness 模板化。未来开发者启动新项目时,选择的将不仅仅是 React 还是 Vue,而是一套"对 AI 友好的 Harness 架构"——预置自定义 Linter、结构化测试包、基础文档框架、自动化垃圾回收 Agent 和严格的层级约束规则。
第二,模型与 Harness 的共同进化。随着基座模型越来越强(GPT-4.1、Kimi K2 等都在强化 Agentic 能力),Harness 的角色会从"补偿模型缺陷"转向"释放模型潜力"。约束不会消失,但约束的形态会从"防止犯错"演变为"引导做得更好"。
第三,评估体系的成熟。正如姚顺雨所提出的,AI 研究的下半场核心不在方法,而在任务——不是提出更难的基准,而是更好地理解模型的能力边界。Agent 系统的评估远比单轮问答复杂:不仅要结果正确,还要过程合理、成本可控、可靠性可量化。构建这样的评估体系,本身就是一个重大的工程挑战。
Agent 领域的"苦涩教训"(The Bitter Lesson)或许可以这样改写:通用方法 + 更大算力 + 更好的环境工程,比精心设计的专家规则走得更远。 但"环境工程"本身也需要持续进化。在模型能力的潮水不断上涨的今天,真正决定最终效果的,不是某一刻的模型有多强或 Harness 有多精巧,而是二者之间共同进化的速度。