5.1 预训练目标与损失函数
大语言模型的预训练本质上是一个自监督学习过程——模型在海量无标签文本上学习语言的统计规律,不需要任何人工标注。这一过程的核心问题是:用什么样的训练目标来驱动模型学习?用什么样的损失函数来量化模型的预测误差?又用什么样的指标来评估模型学到了多少语言知识?本节将围绕自回归语言建模、交叉熵损失和困惑度评估这三个紧密相连的概念,从数学原理到代码实现进行系统阐述。
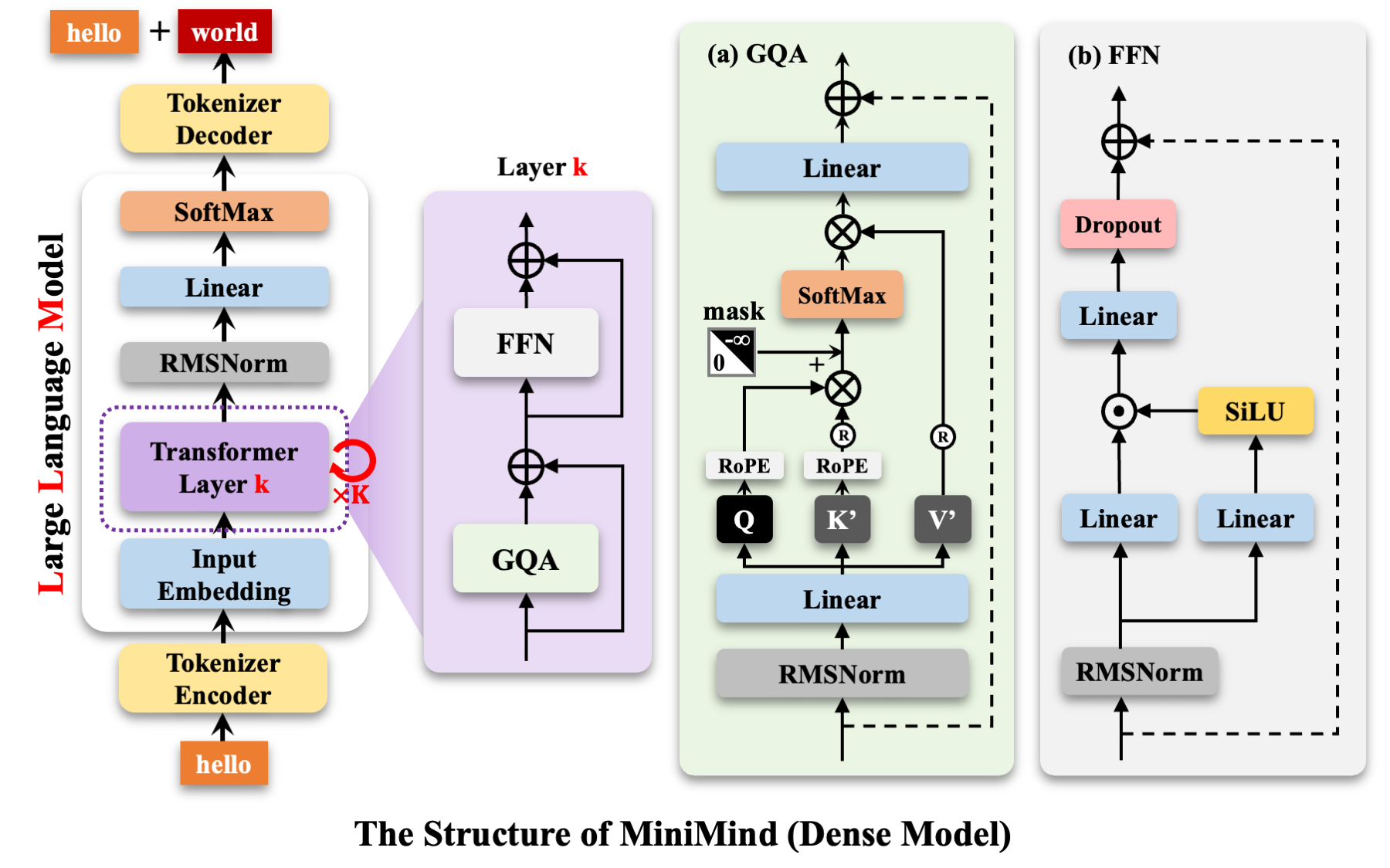
图 5-1:大语言模型结构概览。输入 token 经嵌入层映射为向量,通过多层 Transformer 解码器,最终输出下一个 token 的概率分布。
5.1.1 自回归语言建模
语言建模的概率框架。 语言模型的目标是对 token 序列的联合概率分布进行建模。给定一个长度为
以一个具体的四词序列为例:
这一分解本身没有做任何近似——它是联合概率的恒等变换。关键在于如何建模每一步的条件概率
从 N-gram 到神经网络。 早期的语言模型依赖马尔可夫假设对上式做截断近似。例如,二元语法(bigram)假设
神经语言模型彻底改变了这一局面。基于 Transformer 解码器的大语言模型使用因果注意力机制,在每个位置
其中
自回归与教师强制。 "自回归"(autoregressive)的含义是:模型逐个 token 地生成序列,每一步的输出依赖于此前所有的真实 token。在训练阶段,采用"教师强制"(teacher forcing)策略——每一步的输入是真实的前缀序列而非模型自身的预测,这使得所有位置的损失可以并行计算,极大地提升了训练效率。具体而言,给定训练序列
这一"输入-目标平移"设计是自回归语言模型最核心的数据组织方式:
输入: [The, cat, sat, on, the]
目标: [cat, sat, on, the, mat]模型在每个位置
5.1.2 交叉熵损失
从最大似然到交叉熵。 最大似然估计(MLE)要求最大化训练数据的对数似然:
等价地,最小化负对数似然(NLL):
在每个位置
由于
这表明:在 one-hot 标签下,交叉熵损失与负对数似然完全等价。 整个序列的平均损失为:
交叉熵的信息论含义。 从信息论的角度看,交叉熵
其中
详细推导:从 logits 到损失值。 将 softmax 的定义代入交叉熵,可以得到损失关于 logits 的显式表达。设位置
这就是 log-sum-exp 形式。在数值实现中,为防止指数运算溢出,通常减去 logits 的最大值
这一数值稳定的计算方式已被封装在 PyTorch 的 torch.nn.functional.cross_entropy 中,它直接接受未经 softmax 的 logits 作为输入,内部完成 softmax 和对数运算。
PyTorch 实现。 下面的代码展示了如何在 GPT 风格的语言模型中计算一个 batch 的交叉熵损失:
import torch
import torch.nn.functional as F
def calc_loss_batch(input_batch, target_batch, model, device):
"""计算一个 batch 的交叉熵损失。
Args:
input_batch: 输入 token 索引,形状 [batch_size, seq_len]
target_batch: 目标 token 索引,形状 [batch_size, seq_len]
model: 语言模型,输出 logits 形状 [batch_size, seq_len, vocab_size]
device: 计算设备
Returns:
标量损失值
"""
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch) # [batch_size, seq_len, vocab_size]
# 将 logits 展平为 [batch_size * seq_len, vocab_size]
# 将 target 展平为 [batch_size * seq_len]
loss = F.cross_entropy(
logits.flatten(0, 1), # [B*T, V]
target_batch.flatten() # [B*T]
)
return loss这段代码的关键操作是 flatten:模型输出的 logits 形状为 [batch_size, seq_len, vocab_size],而 F.cross_entropy 要求输入为 [N, C](N 为样本数,C 为类别数)。通过 flatten(0, 1) 将 batch 维和序列维合并,每个位置的预测被视为一个独立的分类问题。F.cross_entropy 默认对所有位置取平均,返回一个标量损失值。
在完整的训练循环中,还需要在整个数据集上累积损失以监控训练进度:
def calc_loss_loader(data_loader, model, device, num_batches=None):
"""在数据加载器上计算平均损失。"""
total_loss = 0.0
if len(data_loader) == 0:
return float("nan")
if num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i >= num_batches:
break
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
return total_loss / num_batches5.1.3 困惑度评估
图 5-2:困惑度随训练步数的变化。困惑度是交叉熵损失的指数化表示,数值越低表示模型对下一个 token 的预测越准确。
定义与推导。 困惑度(perplexity, PPL)是评估语言模型性能的标准指标。它被定义为测试集上每个 token 的平均交叉熵损失的指数:
其中
利用对数与指数的关系
这是每个 token 的逆概率的几何平均值。这一形式揭示了困惑度的直观含义:模型在预测下一个 token 时,平均面临的有效选项数量。
边界情况分析。 困惑度的取值范围和三种典型场景如下:
| 场景 | 条件 | 困惑度 |
|---|---|---|
| 理想模型 | 每步都以概率 1 预测正确 token | PPL = 1 |
| 均匀随机猜测 | 在词表 | PPL = |
| 完全错误 | 给正确 token 分配概率 0 | PPL |
表 5-1:困惑度在不同场景下的取值。
第二种场景值得深入理解:如果模型完全没有学到语言规律,在每一步都以
以 GPT-2 的词表大小
困惑度与交叉熵的换算。 由于
import torch
# 假设 cross_entropy_loss 是模型在验证集上的平均交叉熵损失
cross_entropy_loss = 3.5
perplexity = torch.exp(torch.tensor(cross_entropy_loss))
print(f"交叉熵损失: {cross_entropy_loss:.4f}")
print(f"困惑度: {perplexity:.2f}")
# 输出:
# 交叉熵损失: 3.5000
# 困惑度: 33.12下面给出一个完整的评估函数,计算模型在给定数据集上的困惑度:
def evaluate_perplexity(model, data_loader, device):
"""计算模型在数据集上的困惑度。"""
model.eval()
total_loss = 0.0
total_tokens = 0
with torch.no_grad():
for input_batch, target_batch in data_loader:
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
# 使用 sum reduction 以精确统计 token 级别的损失
loss = F.cross_entropy(
logits.flatten(0, 1),
target_batch.flatten(),
reduction="sum"
)
total_loss += loss.item()
total_tokens += target_batch.numel()
avg_loss = total_loss / total_tokens
perplexity = torch.exp(torch.tensor(avg_loss)).item()
model.train()
return perplexity注意这里使用了 reduction="sum" 并手动统计 token 总数,而非 reduction="mean"。这是因为当不同 batch 的序列长度不一致时,直接对各 batch 的 mean loss 取平均会引入偏差——短序列的 batch 和长序列的 batch 被赋予了相等的权重,而正确的做法是按 token 数加权平均。
图 5-3:预训练损失曲线示例。横轴为训练步数,纵轴为交叉熵损失。损失在初期快速下降,后期逐渐趋于平稳。
使用困惑度的注意事项。 困惑度的比较必须在严格受控的条件下进行,否则数值没有可比性:
- 相同的测试集。 不同文本的"内在难度"不同。科学论文的困惑度通常低于社交媒体文本,因为前者的用词更规范、可预测性更强。
- 相同的分词方式。 不同的分词器会产生不同长度的 token 序列。一个将 "don't" 切分为
["do", "n't"]的分词器与切分为["don", "'t"]的分词器,其困惑度不具备可比性,因为分母(序列长度)不同。 - 词表大小的影响。 更大的词表意味着更高的困惑度基线。在比较不同模型时,需要考虑词表大小差异带来的影响。
本节小结
本节围绕大语言模型预训练的核心机制,阐述了三个层层递进的概念:
- 自回归语言建模是当前主流大语言模型的预训练范式。通过链式法则将联合概率分解为逐步的条件概率预测,模型在每个位置基于所有前文 token 预测下一个 token。训练时采用教师强制策略,将输入序列右移一位构造目标序列,使所有位置的损失可并行计算。
- 交叉熵损失是驱动模型学习的优化目标。它等价于负对数似然,衡量模型预测分布与真实分布之间的差异。在 one-hot 标签下,交叉熵简化为对正确 token 的负对数概率。PyTorch 的
F.cross_entropy直接接受 logits 输入,内部完成数值稳定的 log-softmax 运算。 - 困惑度是交叉熵损失的指数变换(
),提供了更直观的评估视角——它表示模型在每一步平均面临的有效选择数量。理想模型的困惑度为 1,均匀随机猜测的困惑度等于词表大小。比较困惑度时必须控制测试集、分词方式和词表大小等变量。
三者的关系可以用一句话概括:自回归建模定义了预测任务,交叉熵损失量化了预测误差,困惑度将误差转化为可解释的评估指标。 它们共同构成了大语言模型预训练的理论基石。