19.6 推理引擎框架对比
完成模型训练只是大模型生命周期的一半——另一半是让模型高效地服务于真实用户。随着 LLM 应用需求在 2023 年后爆发式增长,如何将动辄数百亿参数的模型以高吞吐(Throughput)和低延迟(Latency)的方式部署上线,成为工程落地的核心挑战。传统的 PyTorch 框架以"简单易用"为目标,远不能满足生产级推理对显存管理、请求调度、多卡协同的严苛要求。于是,一系列专门为 LLM 推理设计的框架应运而生。
本节将系统对比当前主流的推理引擎框架——vLLM、SGLang、TGI、TensorRT-LLM、LMDeploy、llama.cpp 及其上层封装 Ollama,分析它们的架构设计理念、关键能力差异与适用场景,并介绍 torch.compile 这一轻量级推理加速手段,帮助读者在实际部署中做出合理的技术选型。
19.6.1 推理框架的诞生逻辑
在深入对比之前,有必要厘清"推理引擎""推理服务"和"推理框架"三个经常混用的概念。
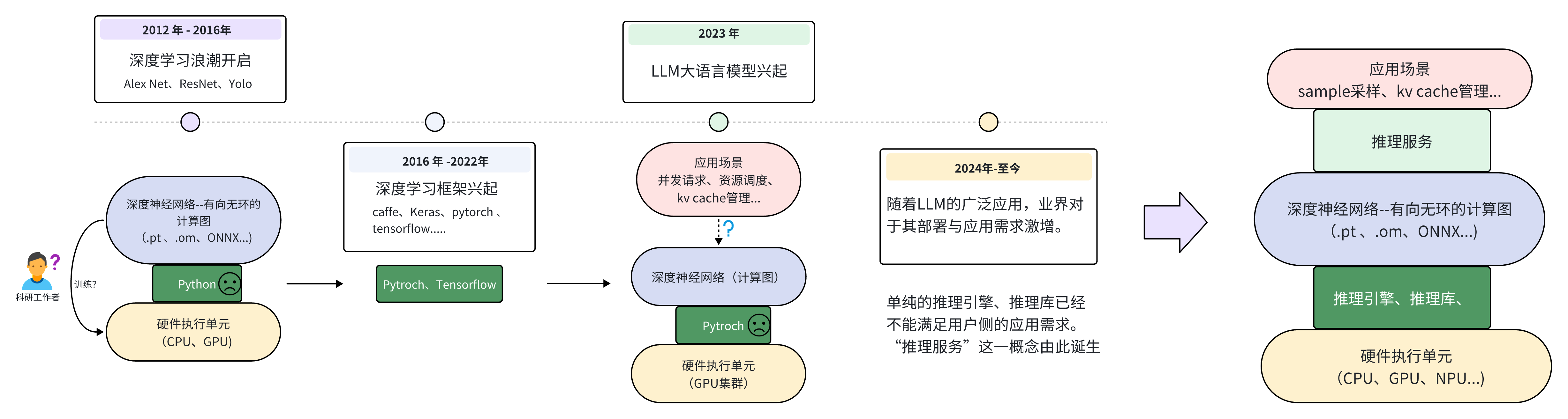
图 19-18:从深度学习框架到大模型推理框架的演进。2023 年 LLM 应用需求爆发后,业界需要同时解决推理引擎(底层硬件加速)和推理服务(上层请求调度、KV Cache 管理、采样策略)两个层面的问题。
- 推理引擎(Inference Engine):负责底层运行时优化,包括算子融合、内存管理、硬件加速等。TensorRT 是典型的推理引擎。
- 推理服务(Inference Server):负责上层应用逻辑,包括请求队列管理、Continuous Batching、采样策略、Web API 等。Ollama 是典型的推理服务。
- 推理框架(Inference Framework):同时包含推理引擎和推理服务的完整解决方案。vLLM、SGLang 均属此类。
大部分现代推理框架兼具引擎和服务两层能力,但侧重点各有不同。例如 llama.cpp 最初是纯引擎,后来也加入了服务层;Ollama 则是纯服务层,底层依赖 llama.cpp 作为推理后端。
19.6.2 核心能力矩阵
下表从多个维度对比当前六大主流推理框架的核心能力(截至 2025 年中):
| 能力维度 | vLLM | SGLang | TGI | TensorRT-LLM | LMDeploy | llama.cpp |
|---|---|---|---|---|---|---|
| PagedAttention | 首创 | 支持 | 部分 | 支持 | 支持 | N/A |
| Continuous Batching | 支持 | 支持 | 支持 | 支持 | 支持 | 有限 |
| Prompt Cache / Prefix Caching | 支持 | 支持(RadixAttention) | 部分 | 支持 | 支持 | 支持 |
| Constrained Decoding(受约束解码) | 支持 | 支持 | 部分 | 有限 | 有限 | 支持 |
| Streaming(流式输出) | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 多模态支持 | 支持 | 支持 | 部分 | 支持 | 良好 | 支持 |
| 投机解码(Speculative Decoding) | 支持 | 支持 | 有限 | 支持 | 有限 | 支持 |
| 张量并行(TP) | 支持 | 支持 | 支持 | 支持 | 支持 | 有限 |
| 支持模型数(families) | ~72 | ~29 | ~26 | ~52 | ~30 | ~63 |
| 主要语言 | Python + CUDA | Python + C++ + CUDA | Python + Rust | C++ | Python + C++ + CUDA | C++ + C |
| GitHub Star(k,截至 2025-06) | ~49 | ~15 | ~10 | ~11 | ~6.5 | ~82 |
| Contributors(截至 2025-06) | ~1200 | ~480 | ~164 | ~233 | ~113 | ~1165 |
表 19-4:主流 LLM 推理框架能力对比矩阵。
以下逐一介绍各框架的设计理念与核心特性。
19.6.3 vLLM:社区标杆与 PagedAttention
vLLM 由加州大学伯克利分校 Sky Computing Lab 发起,是目前社区最活跃、模型支持最完善的推理框架。其核心贡献是 PagedAttention——一种借鉴操作系统虚拟内存分页思想的 KV Cache 管理算法。
为什么需要 PagedAttention? 传统推理框架采用连续内存静态预分配方式管理 KV Cache:为每个请求预先分配 (max_seq_len, hidden_dim) 大小的连续显存块。这会导致三类严重浪费:(1)预留空间闲置——为尚未生成的 Token 预留的内存长期空闲;(2)内部碎片——实际序列长度远短于预分配的最大长度;(3)外部碎片——频繁分配释放后,空闲内存碎片化,无法满足新请求。

图 19-19:传统连续内存管理下的 KV Cache 碎片问题。Request A 和 Request B 各自预分配了最大长度的连续空间,大量 slot 从未被使用(internal fragmentation),两个请求之间的间隙也无法被利用(external fragmentation)。
PagedAttention 的核心思想。 将所有请求的 KV Cache 统一拆分为固定大小的物理块(Block),每个块存储固定数量 Token 的 Key/Value 向量(通常 16 或 32 个 Token)。物理块在显存中可以非连续存储。系统为每个请求维护一张块表(Block Table),记录逻辑块到物理块的映射关系——就像操作系统用页表管理虚拟地址到物理页的映射一样。
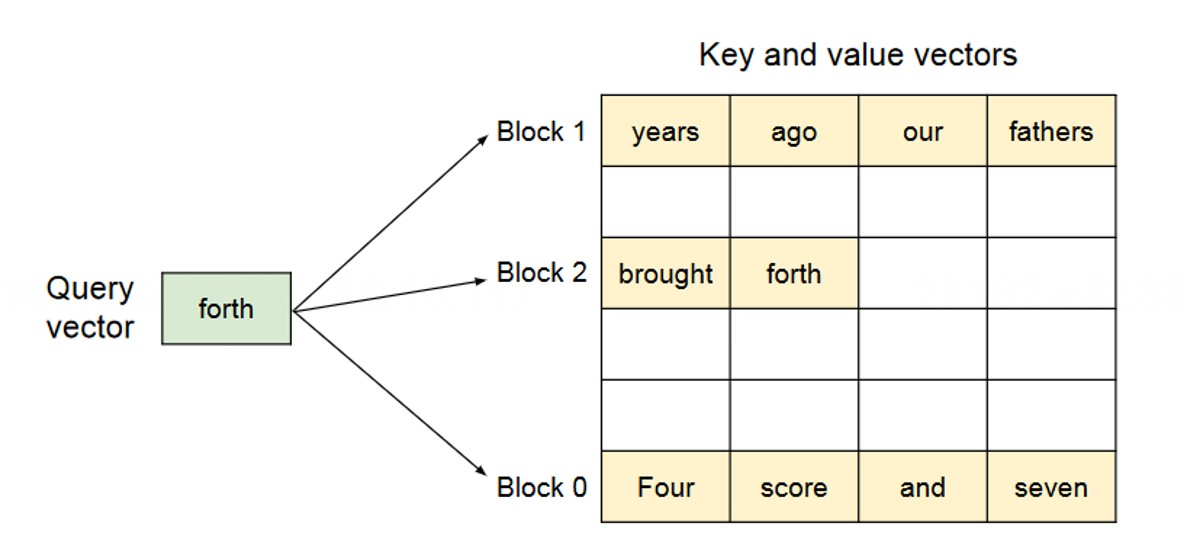
图 19-20:PagedAttention 的核心机制。Query vector 通过 Block Table 索引到分散在显存不同位置的 Key/Value 物理块,实现"逻辑连续、物理分散"的内存管理,彻底消除外部碎片。
这一设计带来两大优势:彻底消除外部碎片(物理块无需连续排列)和支持细粒度内存共享(多个请求可通过写时复制共享相同的 Prompt 前缀物理块),最终将 KV Cache 的显存浪费率从传统方案的 60%–80% 降低到接近 4%(Kwon et al., Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP 2023)。
vLLM 快速启动示例:
# 安装 vLLM
pip install vllm
# 启动 OpenAI 兼容的 API 服务
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.9 \
--max-model-len 8192启动后即可通过标准 OpenAI API 格式发送请求:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[{"role": "user", "content": "用一句话解释 PagedAttention"}],
stream=True, # 流式输出
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)vLLM 与训练框架的集成。 vLLM 不仅用于独立推理服务,还被深度集成到强化学习训练流程中。例如 TRL 框架的 GRPO 训练器可以直接启动 vLLM 服务来加速在线采样:
# 在 GPU 0-3 上启动 vLLM 推理服务
CUDA_VISIBLE_DEVICES=0,1,2,3 trl vllm-serve \
--model Qwen/Qwen2.5-7B \
--tensor-parallel-size 4
# 在 GPU 4-7 上运行训练(需分开设备避免 NCCL 冲突)
CUDA_VISIBLE_DEVICES=4,5,6,7 accelerate launch train.py训练脚本中只需设置 use_vllm=True 即可让训练器通过 HTTP 调用 vLLM 生成补全样本,训练完成后自动将更新的权重同步回 vLLM 服务端,实现训推一体的高效流水线。
19.6.4 SGLang:极致吞吐的挑战者
SGLang 同样来自 UCB 团队,定位为以极致吞吐为目标的推理框架。它在 vLLM 的基础上进行了多项系统级优化,在高并发场景下的 GPU 利用率可达 80% 以上。
SGLang 的核心优化思路:
- 多进程 ZMQ 通信:将 CPU 侧的调度逻辑(Token 管理、请求路由)通过 ZeroMQ 消息队列与 GPU 侧的计算解耦,用多进程传输中间数据来掩盖 CPU 调度开销,避免了 vLLM 早期版本中"CPU 调度时 GPU 空闲"的串行瓶颈。
- RadixAttention:一种基于基数树(Radix Tree)的 Prefix Caching 机制,比 vLLM 的 Prefix Caching 更高效地在多个请求间共享公共前缀的 KV Cache,特别适合多轮对话和 Few-shot 场景。
- 代码简洁性:SGLang 在支持主流功能的前提下,代码量比 vLLM 精简得多,对二次开发友好。
SGLang 快速启动示例:
# 安装 SGLang
pip install sglang[all]
# 启动服务(同样兼容 OpenAI API 格式)
python -m sglang.launch_server \
--model-path Qwen/Qwen2.5-7B-Instruct \
--tp 2 \
--port 8000SGLang 还提供了一套独特的前端编程语言,允许用户以 Python 函数的方式定义复杂的 LLM 程序(包含分支、循环、JSON Schema 约束等),框架在后端自动优化执行计划:
import sglang as sgl
@sgl.function
def multi_turn_qa(s, question_1, question_2):
s += sgl.system("你是一个有帮助的助手。")
s += sgl.user(question_1)
s += sgl.assistant(sgl.gen("answer_1", max_tokens=256))
s += sgl.user(question_2)
s += sgl.assistant(sgl.gen("answer_2", max_tokens=256))
# 批量执行多组对话,框架自动共享公共前缀的 KV Cache
states = multi_turn_qa.run_batch([
{"question_1": "什么是 Transformer?", "question_2": "它和 RNN 有什么区别?"},
{"question_1": "什么是 Transformer?", "question_2": "它在 CV 领域有哪些应用?"},
])19.6.5 其他主流框架
TGI(Text Generation Inference)。 Hugging Face 官方推理框架,最大优势是与 Hugging Face 生态的无缝集成,支持一键部署 Hub 上的模型。但 TGI 使用 Rust 实现后端调度逻辑,Python 开发者二次开发门槛较高;其 CPU/GPU 调度串行设计导致吞吐性能一般;开发团队投入有限,版本更新节奏较慢。适合对 Hugging Face 生态依赖较重、不需要极致性能的场景。
# TGI 通常通过 Docker 部署
docker run --gpus all -p 8080:80 \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id Qwen/Qwen2.5-7B-Instruct \
--num-shard 2TensorRT-LLM。 NVIDIA 官方推出的推理框架,专门针对 NVIDIA GPU 深度优化。支持 PyTorch 和 TensorRT 两种后端,在 NVIDIA 硬件上能榨取最大性能。2025 年 3 月完全开源后社区活跃度有所提升。缺点是仅支持 NVIDIA 硬件,且早期 C++ 代码占比极高(94%),对 Python 开发者不够友好。
LMDeploy。 由 OpenMMLab 团队开发,在 C++ 层面实现了调度和执行 Runtime,高负载下 GPU 利用率可稳定在 95%。对多模态模型和国产 GPU 硬件的支持较好,但开发人员较少,功能丰富度不及 vLLM 和 SGLang。
# LMDeploy 快速启动
pip install lmdeploy
lmdeploy serve api_server Qwen/Qwen2.5-7B-Instruct \
--tp 2 \
--server-port 800019.6.6 llama.cpp 与 Ollama:本地部署方案
与前述面向云端高并发场景的框架不同,llama.cpp 专注于边缘侧推理部署——个人 PC、Mac、手机等资源受限设备。
llama.cpp 的设计哲学:
- 轻量无依赖:仅使用自研的 GGML 张量库构建,无任何第三方库依赖,编译部署极其简单。
- 极致量化:支持 1.5-bit 到 8-bit 的多级整数量化(GGUF 格式),在精度和速度之间提供灵活的权衡。一个 7B 模型经 4-bit 量化后仅需约 4GB 内存,普通笔记本即可运行。
- 广泛硬件支持:覆盖 x86 CPU(AVX 指令集加速)、ARM(Apple Silicon 原生支持)、NVIDIA/AMD/Intel GPU、Vulkan、华为 NPU 等,是跨平台兼容性最强的方案。
# 下载 GGUF 量化模型并运行
./llama-cli -m qwen2.5-7b-instruct-q4_k_m.gguf \
-p "请解释什么是大语言模型" \
-n 256 --temp 0.7
# 启动 OpenAI 兼容的本地 API 服务
./llama-server -m qwen2.5-7b-instruct-q4_k_m.gguf \
--host 0.0.0.0 --port 8080Ollama 是构建在 llama.cpp 之上的一站式本地推理服务,提供类似 Docker 的模型管理体验。用户无需关心模型格式转换、量化参数等底层细节,一条命令即可完成模型下载和运行:
# 安装 Ollama 后,一键运行模型
ollama run qwen2.5:7b
# 也可通过 API 调用
curl http://localhost:11434/api/chat -d '{
"model": "qwen2.5:7b",
"messages": [{"role": "user", "content": "你好"}],
"stream": true
}'Ollama 的核心价值不在于推理性能(底层仍是 llama.cpp),而在于用户体验:自动管理模型文件、提供 Web 界面、支持多模型切换、与 Open WebUI 等前端无缝集成。它是个人开发者和小团队快速体验本地 LLM 的首选方案。
19.6.7 torch.compile:轻量级推理加速
在上述专业推理框架之外,PyTorch 自身提供了 torch.compile——一种基于 TorchInductor 编译器的即时编译(JIT)加速手段。它不需要改变模型代码,只需一行调用即可获得显著的推理加速。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.6B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.6B")
# 一行代码启用编译加速
model = torch.compile(model)
inputs = tokenizer("大语言模型是", return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))torch.compile 的加速效果。 下表展示了在不同硬件和配置下,编译加速对推理速度的影响(基于 Qwen3-0.6B 模型的实测数据):
| 配置 | 硬件 | 无编译(tokens/sec) | 启用 torch.compile(tokens/sec) | 加速比 |
|---|---|---|---|---|
| KV Cache | Mac Mini M4 CPU | 28 | 68 | 2.4x |
| KV Cache | NVIDIA H100 GPU | 48 | 141 | 2.9x |
| KV Cache + 优化模型 | NVIDIA H100 GPU | 56 | 177 | 3.2x |
表 19-5:torch.compile 在不同配置下的推理加速效果。
可以看到,torch.compile 在 GPU 上可带来接近 3 倍的加速,在 CPU 上也有约 2.4 倍的提升。其原理是 TorchInductor 将 Python 级的 PyTorch 操作编译为高效的 C++/CUDA/Triton Kernel,消除了 Python 解释器开销和冗余的内存分配。
适用场景与局限。 torch.compile 适合以下场景:不需要高并发服务能力,只需要加速单次或小批量推理;快速原型验证,不想引入额外推理框架依赖;需要保持与 HuggingFace Transformers 代码完全兼容。但它不支持 Continuous Batching、PagedAttention 等系统级优化,因此在高并发服务场景下仍然需要专业推理框架。
19.6.8 关键能力深入:Prompt Cache 与 Constrained Decoding
除了 PagedAttention 和 Continuous Batching 这两项基石技术,还有两项在实际生产中至关重要的能力值得展开。
Prompt Cache(提示缓存)。 在多轮对话、Few-shot 推理等场景中,大量请求共享相同的系统提示(System Prompt)或示例前缀。如果每个请求都重新计算这些公共前缀的 KV Cache,会造成巨大的计算浪费。Prompt Cache 技术将已计算过的前缀 KV Cache 保留在显存中,后续请求命中相同前缀时直接复用,跳过 Prefill 阶段。vLLM 通过 --enable-prefix-caching 参数启用此功能;SGLang 则更进一步,使用 RadixAttention 以基数树结构管理缓存,支持任意前缀的自动匹配与共享,在多轮对话场景下效率更高。
Constrained Decoding(受约束解码)。 当 LLM 需要输出结构化数据(如 JSON、SQL、正则表达式匹配的文本)时,自由采样可能产生格式错误的输出。受约束解码在每步采样时,根据预定义的语法规则(如 JSON Schema、正则表达式、上下文无关文法)屏蔽不合法的 Token,确保输出严格符合格式要求。vLLM 和 SGLang 均内置了基于有限状态机(FSM)的约束解码引擎,支持 guided_json、guided_regex 等参数:
# vLLM 中使用 JSON Schema 约束输出
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[{"role": "user", "content": "给出三个中国城市的名称和人口"}],
extra_body={
"guided_json": {
"type": "object",
"properties": {
"cities": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"population": {"type": "integer"}
},
"required": ["name", "population"]
}
}
},
"required": ["cities"]
}
},
)19.6.9 关键能力深入:Continuous Batching
Continuous Batching(连续批处理) 是几乎所有现代推理框架的核心调度技术,值得单独展开。
传统的 Static Batching(静态批处理) 将一组请求打包为一个 Batch,等所有请求都生成完毕后才处理下一批。由于不同请求的输出长度差异巨大,先完成的请求不得不空等最慢的请求,GPU 利用率极低。
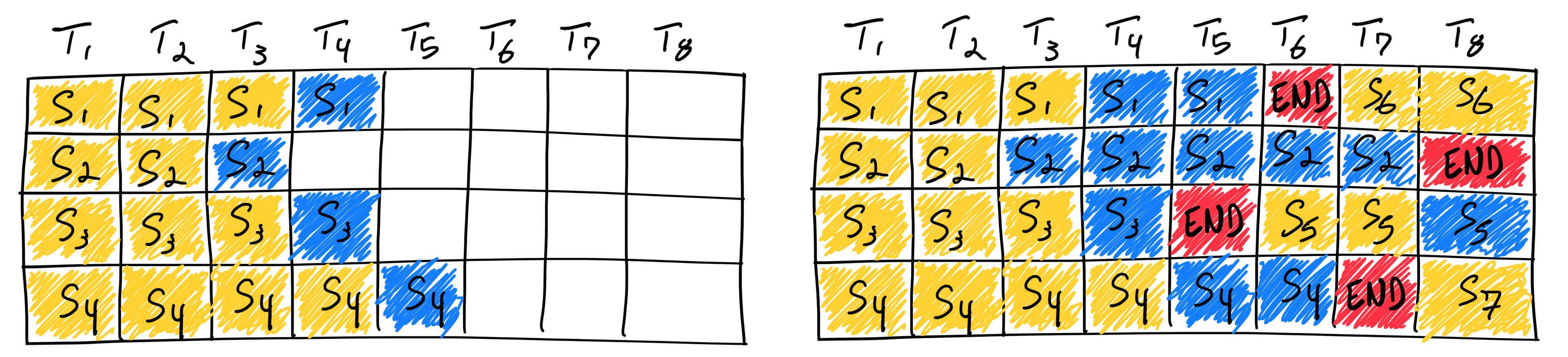
图 19-21:静态批处理(左)与连续批处理(右)的对比。左图中 S2 和 S3 提前完成但必须等待 S4,造成大量 GPU 空闲;右图中完成的请求立即被新请求替换(S5、S6、S7),GPU 保持满载。
Continuous Batching 的核心思想是将调度粒度从"请求级"细化到"迭代级(Iteration-level)":每完成一轮 Decode 迭代,调度器就检查是否有请求已完成(生成了结束符),如果有,立即将其从 Batch 中移除并插入新的等待请求。这一机制最早由 OSDI'22 的 Orca 论文提出,后被 vLLM、SGLang 等框架广泛采用。
结合 PagedAttention 的动态内存管理,Continuous Batching 能在满足延迟 SLO(Service Level Objective,服务水平目标)的前提下将系统吞吐量提升数倍。
19.6.10 选型决策指南
面对众多框架,如何选择?以下是基于场景的推荐:
| 部署场景 | 推荐方案 | 理由 |
|---|---|---|
| 云端高并发服务 | vLLM 或 SGLang | 成熟的 PagedAttention + Continuous Batching,社区活跃 |
| 追求极致吞吐 | SGLang | 多进程调度架构,高负载下 GPU 利用率最高 |
| NVIDIA 硬件深度优化 | TensorRT-LLM | 官方优化,充分发挥硬件算力 |
| 多模态模型 + 国产 GPU | LMDeploy | C++ Runtime 高效稳定,硬件兼容性好 |
| Hugging Face 生态一键部署 | TGI | 与 Hub 无缝集成,开箱即用 |
| 个人 PC / Mac 本地部署 | Ollama(llama.cpp) | 轻量无依赖,极致量化,跨平台 |
| 快速原型 / 小批量推理 | torch.compile | 零额外依赖,一行代码加速 |
| RLHF/GRPO 训推一体 | vLLM + TRL | 训练框架原生集成,权重自动同步 |
表 19-6:推理框架选型决策指南。
推理框架的生态演进非常迅速。vLLM 和 SGLang 正在快速趋同——前者在提升吞吐性能,后者在补齐模型覆盖度。选型时应以实际基准测试结果为准,而非仅凭框架宣称的性能数字。
小结
本节从推理框架的诞生逻辑出发,系统对比了 vLLM、SGLang、TGI、TensorRT-LLM、LMDeploy、llama.cpp/Ollama 六大方案,并介绍了 torch.compile 这一轻量替代方案。核心要点有三:(1)PagedAttention 通过借鉴操作系统分页机制,从根本上解决了 KV Cache 显存碎片问题,是云端推理框架的基石技术;(2)Continuous Batching 将调度粒度从请求级细化到迭代级,配合 PagedAttention 可成倍提升系统吞吐量;(3)框架选型没有绝对最优解——云端高并发选 vLLM/SGLang,本地轻量部署选 llama.cpp/Ollama,快速原型验证用 torch.compile,关键是根据实际场景的并发量、硬件条件和开发效率需求做出权衡。