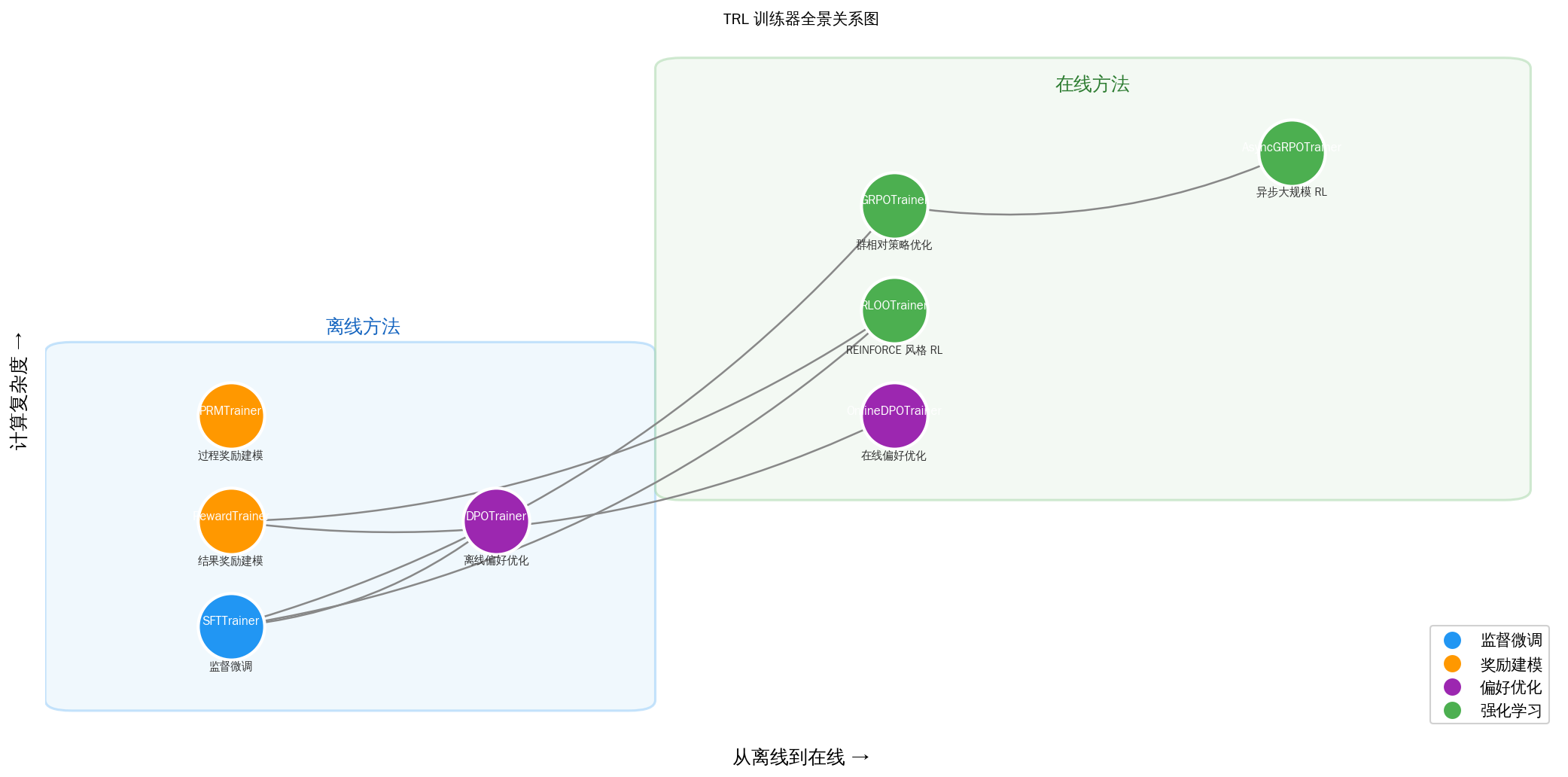
27.1 训练器速查表
TRL(Transformer Reinforcement Learning)是 Hugging Face 维护的后训练工具库,围绕大语言模型的"监督微调 → 奖励建模 → 偏好对齐 → 强化学习"全流程提供了一套统一的 Trainer API。本节将 TRL 中最核心的 8 个训练器逐一拆解,帮助读者在面对具体任务时快速选定合适的工具。
前置说明:本章各训练器的算法原理已在前面的章节中深入讨论(SFT 见第 12 章、DPO 见第 14 章、GRPO/RLOO 见第 15 章、奖励建模见第 13 章等)。本节聚焦于 TRL 实操层面——API 调用方式、数据格式要求与关键参数。
总览对比表
下表给出所有核心训练器的一览式对比:
| 训练器 | 方法 | 数据需求 | 是否在线 | 需要参考模型 | 推荐场景 |
|---|---|---|---|---|---|
| SFTTrainer | 监督微调 (Supervised Fine-Tuning) | 输入-输出对 / 对话数据 | 否 | 否 | 基础指令微调、领域适配 |
| RewardTrainer | 结果奖励建模 (Outcome RM) | 偏好对 (chosen/rejected) | 否 | 否 | 训练奖励模型 |
| PRMTrainer | 过程奖励建模 (Process RM) | 步骤级标签 (step labels) | 否 | 否 | 推理任务的过程监督 |
| DPOTrainer | 直接偏好优化 (DPO) | 偏好对 (chosen/rejected) | 否 | 是(自动创建) | 离线偏好对齐 |
| OnlineDPOTrainer | 在线 DPO | 提示 + LLM/RM 评判器 | 是 | 是 | 动态反馈的在线对齐 |
| RLOOTrainer | REINFORCE Leave-One-Out | 提示 + 奖励函数 | 是 | 是 | 轻量级在线 RL |
| GRPOTrainer | 群相对策略优化 (GRPO) | 提示 + 奖励函数 | 是 | 可选(默认关闭 KL) | 通用在线 RL(推荐首选) |
| AsyncGRPOTrainer | 异步 GRPO | 提示 + 奖励函数 | 是 | 可选 | 大规模异步 RL 训练 |
1. SFTTrainer —— 监督微调
核心原理:在标注的输入-输出对上最小化 token 级交叉熵损失,是所有后训练流程的起点。
数据格式:支持四种格式:
# 1. 标准语言建模
{"text": "天空是蓝色的。"}
# 2. 对话格式(自动应用 chat template)
{"messages": [{"role": "user", "content": "天空是什么颜色?"},
{"role": "assistant", "content": "蓝色。"}]}
# 3. 标准 prompt-completion
{"prompt": "天空是", "completion": "蓝色的。"}
# 4. 对话式 prompt-completion
{"prompt": [{"role": "user", "content": "天空是什么颜色?"}],
"completion": [{"role": "assistant", "content": "蓝色。"}]}最小代码示例:
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B",
args=SFTConfig(
output_dir="my-sft-model",
per_device_train_batch_size=4,
num_train_epochs=3,
learning_rate=2e-5,
),
train_dataset=load_dataset("trl-lib/Capybara", split="train"),
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
packing | 启用样本打包,提升 GPU 利用率 | False |
assistant_only_loss | 仅在 assistant 消息上计算损失 | False |
completion_only_loss | 默认 True,仅在 completion 上计算损失 | True |
max_length | 最大序列长度(VLM 训练建议设为 None) | 1024 |
peft_config | 传入 LoRA 等 PEFT 配置以进行适配器训练 | None |
推荐场景:基础指令微调、领域适配、对话模型训练、视觉语言模型微调。
2. RewardTrainer —— 结果奖励建模
核心原理:基于 Bradley-Terry 模型训练一个奖励函数,使其对 chosen 回复打更高分:
数据格式:偏好数据集,包含 chosen 和 rejected 字段:
# 标准偏好格式
{"prompt": "天空是什么颜色?",
"chosen": "蓝色。",
"rejected": "绿色。"}
# 对话偏好格式
{"chosen": [{"role": "user", "content": "天空是什么颜色?"},
{"role": "assistant", "content": "蓝色。"}],
"rejected": [{"role": "user", "content": "天空是什么颜色?"},
{"role": "assistant", "content": "绿色。"}]}最小代码示例:
from trl import RewardTrainer, RewardConfig
from datasets import load_dataset
trainer = RewardTrainer(
model="Qwen/Qwen3-0.6B",
args=RewardConfig(
output_dir="my-reward-model",
per_device_train_batch_size=8,
num_train_epochs=1,
learning_rate=1e-5,
),
train_dataset=load_dataset("trl-lib/ultrafeedback_binarized", split="train"),
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
center_rewards_coefficient | 添加辅助损失使奖励值均值趋近于零,推荐 1e-2 | None |
max_length | 最大序列长度 | 1024 |
peft_config | PEFT 配置(使用 LoRA 时需包含 modules_to_save=["score"]) | None |
推荐场景:训练结果级奖励模型,用于后续 RL 训练或 Best-of-N 采样。
3. PRMTrainer —— 过程奖励建模
核心原理:训练一个 token 分类模型,对推理过程的每一步给出正确/错误的判断,实现步骤级(process-level)监督。与 RewardTrainer 只评估最终结果不同,PRMTrainer 评估每个中间步骤的质量。
注意:PRMTrainer 目前是实验性 API(
trl.experimental.prm),接口可能发生变化。
数据格式:步骤级监督数据,包含 prompt、completions(步骤列表)和 labels(布尔/浮点标签列表):
{"prompt": "小明有45个苹果,分给3组,第一组15个...",
"completions": [
"Step 1: 第一组分到 15 个苹果。",
"Step 2: 第二组分到 18 个苹果。",
"Step 3: 第三组分到 45-15-18=12 个苹果。"
],
"labels": [True, True, True]}最小代码示例:
from trl.experimental.prm import PRMConfig, PRMTrainer
from transformers import AutoModelForTokenClassification, AutoTokenizer
from datasets import load_dataset
model = AutoModelForTokenClassification.from_pretrained(
"Qwen/Qwen2-0.5B", num_labels=2
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
trainer = PRMTrainer(
model=model,
args=PRMConfig(output_dir="my-prm-model"),
processing_class=tokenizer,
train_dataset=load_dataset("trl-lib/math_shepherd", split="train[:10%]"),
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
num_labels | 分类类别数(通常为 2:正确/错误) | 2 |
max_length | 最大序列长度 | 1024 |
推荐场景:数学推理、代码生成等需要逐步验证的场景,搭配 Best-of-N 或 MCTS 搜索使用。
4. DPOTrainer —— 直接偏好优化
核心原理:将 RLHF 中的奖励建模和策略优化合并为一步,直接在偏好对上优化策略模型,无需显式训练奖励模型:
数据格式:与 RewardTrainer 相同的偏好数据集(chosen/rejected),支持显式和隐式 prompt。
最小代码示例:
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
trainer = DPOTrainer(
model="Qwen/Qwen3-0.6B",
args=DPOConfig(
output_dir="my-dpo-model",
per_device_train_batch_size=4,
num_train_epochs=1,
learning_rate=5e-7,
beta=0.1,
),
train_dataset=load_dataset("trl-lib/ultrafeedback_binarized", split="train"),
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
beta | KL 惩罚系数,控制偏好信号强度 | 0.1 |
loss_type | 损失变体:sigmoid/hinge/ipo/robust 等 | "sigmoid" |
loss_weights | 多损失组合权重(如 MPO) | None |
precompute_ref_log_probs | 预计算参考模型的 log prob 以节省显存 | False |
sync_ref_model | 动态同步参考模型权重 | False |
支持的 loss 变体一览:
loss_type | 来源论文 | 简述 |
|---|---|---|
"sigmoid" | DPO 原文 | 标准 Bradley-Terry sigmoid 损失 |
"hinge" | RSO/SLiC | 铰链损失,beta 为 margin 的倒数 |
"ipo" | IPO | 恒等变换替代 logit 变换,减少过拟合 |
"robust" | Robust DPO | 对噪声偏好数据的无偏估计 |
"exo_pair" | EXO | 反向 KL 偏好优化 |
"nca_pair" | NCA | 优化绝对似然而非相对似然 |
推荐场景:离线偏好对齐的首选方法,已有高质量偏好数据时使用。
5. OnlineDPOTrainer —— 在线 DPO
核心原理:在每个训练迭代中,从当前策略采样两个回复,用 LLM 评判器(judge)或奖励模型打分选出 chosen/rejected,然后应用 DPO 损失。这使得反馈始终来自当前策略的生成,避免离线数据的分布偏移问题。
注意:OnlineDPOTrainer 目前在
trl.experimental.online_dpo模块中。
数据格式:仅需提示数据集(prompt-only),无需预先标注的偏好对。
最小代码示例:
from trl.experimental.online_dpo import OnlineDPOConfig, OnlineDPOTrainer
from trl.experimental.judges import PairRMJudge
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
judge = PairRMJudge() # 使用 PairRM 作为评判器
trainer = OnlineDPOTrainer(
model=model,
judge=judge,
args=OnlineDPOConfig(
output_dir="my-online-dpo-model",
learning_rate=5e-7,
beta=0.1,
max_new_tokens=128,
),
processing_class=tokenizer,
train_dataset=load_dataset("trl-lib/ultrafeedback-prompt", split="train"),
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
beta | DPO 的 KL 惩罚系数 | 0.1 |
max_new_tokens | 生成的最大 token 数 | 128 |
missing_eos_penalty | 未生成 EOS token 时的惩罚值 | None |
judge | 评判器(PairRM 或自定义 LLM judge) | — |
reward_funcs | 也可用奖励模型替代 judge | — |
推荐场景:需要在线反馈、数据持续更新的对齐场景;没有静态偏好数据但有评判器可用时。
6. RLOOTrainer —— REINFORCE Leave-One-Out
核心原理:基于经典 REINFORCE 算法的简化 RL 训练器。对每个 prompt 生成 G 个回复,使用 leave-one-out 基线减少梯度方差:
数据格式:提示数据集 + 奖励函数(或奖励模型)。
最小代码示例:
from trl import RLOOTrainer, RLOOConfig
from trl.rewards import accuracy_reward
from datasets import load_dataset
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
trainer = RLOOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
args=RLOOConfig(
output_dir="my-rloo-model",
per_device_train_batch_size=4,
num_generations=4, # 每个 prompt 生成 4 个回复
max_completion_length=256,
learning_rate=5e-7,
),
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
num_generations | 每个 prompt 的生成数量 G | 4 |
beta | KL 惩罚系数 | 0.05 |
epsilon | 裁剪范围(PPO 风格裁剪) | 0.2 |
max_completion_length | 生成的最大 token 数 | 256 |
use_vllm | 使用 vLLM 加速生成 | False |
推荐场景:轻量级在线 RL 训练,相比 PPO 实现更简单、超参更少,适合资源有限的场景。
7. GRPOTrainer —— 群相对策略优化
核心原理:对每个 prompt 采样一组(Group)回复,用组内奖励的均值和标准差做归一化作为 advantage 估计,然后应用带裁剪的策略梯度更新:
数据格式:提示数据集 + 一个或多个奖励函数。
最小代码示例:
from trl import GRPOTrainer, GRPOConfig
from trl.rewards import accuracy_reward
from datasets import load_dataset
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
args=GRPOConfig(
output_dir="my-grpo-model",
per_device_train_batch_size=4,
num_generations=8, # 每个 prompt 生成 8 个回复
max_completion_length=512,
learning_rate=5e-7,
),
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()自定义奖励函数示例:
import re
def format_reward(completions, **kwargs):
"""检查回复是否包含 <think>...</think><answer>...</answer> 格式。"""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
contents = [c[0]["content"] for c in completions]
return [1.0 if re.match(pattern, c) else 0.0 for c in contents]
def accuracy_reward(completions, ground_truth, **kwargs):
"""检查 \\boxed{} 中的答案是否正确。"""
matches = [re.search(r"\\boxed\{(.*?)\}", c) for c in completions]
extracted = [m.group(1) if m else "" for m in matches]
return [1.0 if e == gt else 0.0 for e, gt in zip(extracted, ground_truth)]
# 可传入多个奖励函数,最终奖励为加权求和
trainer = GRPOTrainer(
...,
reward_funcs=[format_reward, accuracy_reward],
# reward_weights=[0.3, 0.7], # 可选的权重
)关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
num_generations | 每个 prompt 的生成数量 G | 8 |
beta | KL 惩罚系数(0.0 表示不使用 KL 项) | 0.0 |
epsilon | PPO 风格裁剪范围 | 0.2 |
loss_type | 损失类型:"grpo"/"dapo"/"dr_grpo"/"sapo" | "grpo" |
scale_rewards | 是否按标准差缩放奖励 | True |
num_iterations | 每批数据的梯度更新轮数 mu | 1 |
use_vllm | 启用 vLLM 加速生成 | False |
vllm_mode | vLLM 模式:"colocate"(共享 GPU)/ "server"(独立进程) | "colocate" |
tools | 传入工具函数列表,启用 Agent 训练 | None |
损失类型变体:
loss_type | 来源 | 区别 |
|---|---|---|
"grpo" | DeepSeekMath | 原始 sample-level 归一化 |
"dapo" | DAPO | token-level 归一化,减少长回复偏差 |
"dr_grpo" | Dr. GRPO | 除以常数 L*G,完全消除长度偏差 |
"sapo" | SAPO (Qwen) | 软信任域替代硬裁剪,保留更多梯度信号 |
推荐场景:在线 RL 的标准推荐选择。适用于数学推理(DeepSeek-R1 风格)、代码生成、Agent 训练等需要可验证奖励的任务。
8. AsyncGRPOTrainer —— 异步 GRPO
核心原理:与 GRPOTrainer 使用相同的 GRPO 算法,但将生成和训练解耦为并行运行的两个阶段:
- 生成工作线程(后台):持续向 vLLM 服务器发送 prompt,计算奖励和 advantage,将就绪的样本推入队列。
- 训练循环(主进程):从队列拉取样本,计算损失并更新权重。
每隔 weight_sync_steps 步将更新后的权重同步到 vLLM 服务器,使后续生成反映最新策略。
注意:AsyncGRPOTrainer 目前在
trl.experimental.async_grpo模块中,且仅支持 FSDP2 分布式训练(不支持 DeepSpeed ZeRO)。
数据格式:与 GRPOTrainer 完全一致。
最小代码示例:
# train_async_grpo.py
from datasets import load_dataset
from trl.experimental.async_grpo import AsyncGRPOTrainer, AsyncGRPOConfig
from trl.rewards import accuracy_reward
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
trainer = AsyncGRPOTrainer(
model="Qwen/Qwen3-4B",
args=AsyncGRPOConfig(
output_dir="my-async-grpo-model",
per_device_train_batch_size=4,
max_completion_length=512,
),
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()启动方式(需要独立的 vLLM 服务器):
# 终端 1:在 GPU 0 上启动 vLLM 服务器
CUDA_VISIBLE_DEVICES=0 VLLM_SERVER_DEV_MODE=1 vllm serve Qwen/Qwen3-4B \
--max-model-len 4096 \
--logprobs-mode processed_logprobs \
--weight-transfer-config '{"backend":"nccl"}'
# 终端 2:在 GPU 1 上启动训练
CUDA_VISIBLE_DEVICES=1 accelerate launch train_async_grpo.py关键参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
weight_sync_steps | 每隔多少步向 vLLM 同步权重 | 1 |
max_staleness | 样本允许落后的最大权重更新次数 | 2 |
max_inflight_tasks | 并发请求上限 | 自动计算 |
推荐场景:大规模 RL 训练,拥有充足 GPU 资源时用于最大化训练吞吐量。
补充训练器速览
除上述 8 个核心训练器外,TRL 还提供了以下实验性训练器,适用于特定场景:
| 训练器 | 方法 | 特点 | 数据需求 |
|---|---|---|---|
| CPOTrainer | 对比偏好优化 (CPO) | DPO 的近似,加入 SFT 项提升 chosen 质量;含 SimPO 变体 | 偏好对 |
| KTOTrainer | Kahneman-Tversky 优化 | 不需要配对偏好数据,只需二元信号(好/坏) | 非配对偏好 |
| ORPOTrainer | 赔率比偏好优化 (ORPO) | 无需参考模型,将 SFT 和偏好优化合为一步 | 偏好对 |
| XPOTrainer | 探索性偏好优化 (XPO) | 在线 DPO + 探索奖励,鼓励模型探索新策略 | 提示 + judge |
这些训练器均在
trl.experimental模块中,API 可能随版本更新发生变化。
特性矩阵
下表从工程维度对比各训练器的关键特性支持情况:
| 特性 | SFT | Reward | PRM | DPO | OnlineDPO | RLOO | GRPO | AsyncGRPO |
|---|---|---|---|---|---|---|---|---|
| PEFT/LoRA 支持 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| vLLM 加速 | -- | -- | -- | -- | -- | ✅ | ✅ | ✅(必须) |
| 多 GPU 分布式 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅(仅 FSDP2) |
| DeepSpeed ZeRO | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| 视觉语言模型 | ✅ | -- | -- | ✅ | -- | ✅ | ✅ | -- |
| Tool Calling | ✅ | ✅ | -- | ✅ | -- | -- | ✅ | -- |
| Agent 训练 | -- | -- | -- | -- | -- | -- | ✅ | -- |
| 自定义奖励函数 | -- | -- | -- | -- | ✅ | ✅ | ✅ | ✅ |
| 异步奖励函数 | -- | -- | -- | -- | -- | ✅ | ✅ | ✅ |
| Liger Kernel | ✅ | -- | -- | ✅ | -- | -- | -- | -- |
选型决策树
面对一个具体的后训练任务,如何快速选定训练器?以下决策树提供了一个实用的选型指南:
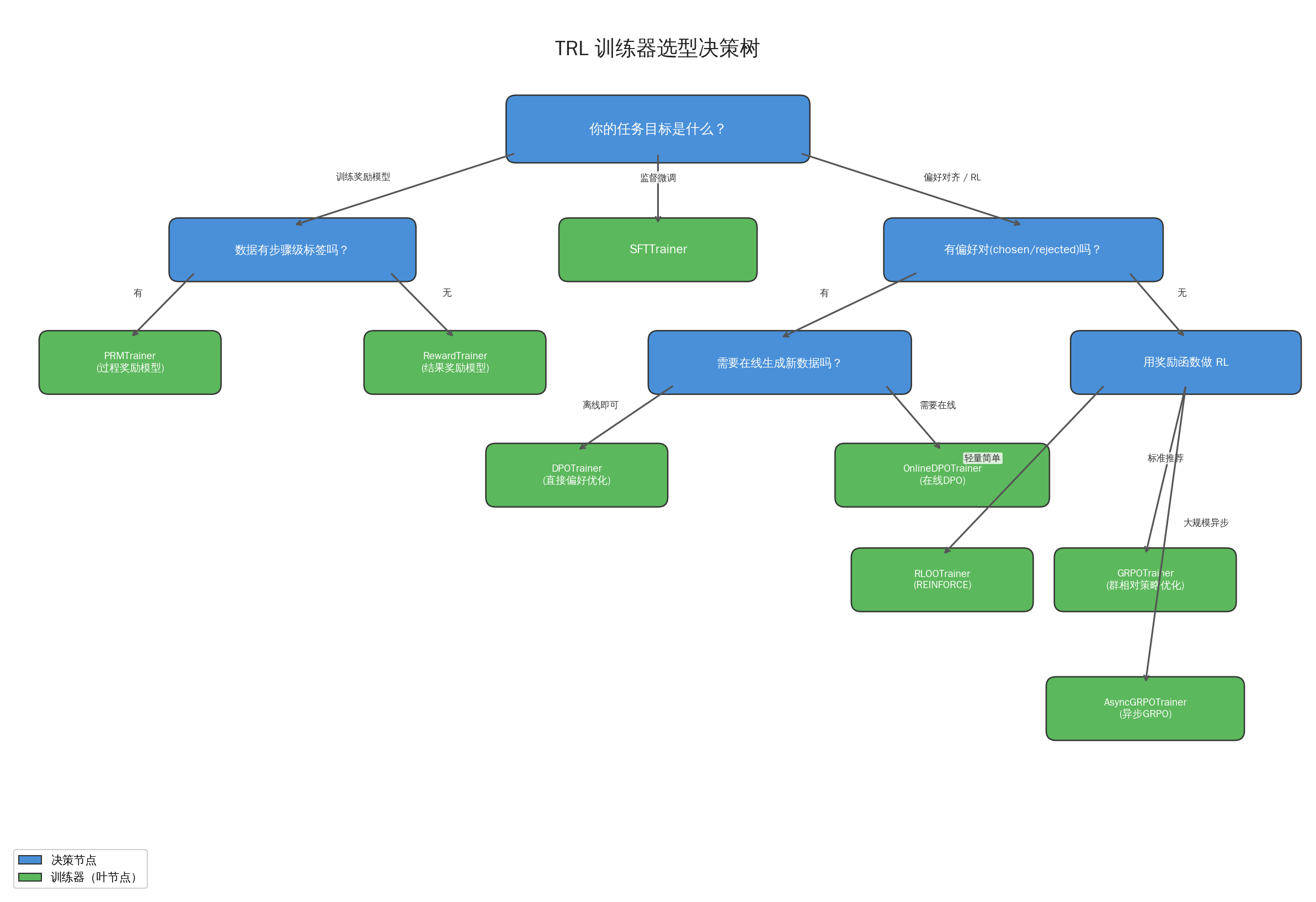
文字版决策流程:
1. 你的目标是什么?
├─ 训练奖励模型
│ ├─ 数据有步骤级标签? → PRMTrainer
│ └─ 仅有结果级偏好对? → RewardTrainer
├─ 监督微调 → SFTTrainer
└─ 偏好对齐 / RL
├─ 有偏好对 (chosen/rejected)?
│ ├─ 离线数据足够? → DPOTrainer
│ └─ 需要在线生成? → OnlineDPOTrainer
└─ 用奖励函数做 RL
├─ 轻量 / 简单 → RLOOTrainer
├─ 标准推荐 → GRPOTrainer
└─ 大规模异步 → AsyncGRPOTrainer典型训练流水线:
一个完整的 RLHF 流水线通常按如下顺序使用多个训练器:
基座模型 → [SFTTrainer] → SFT 模型
├─ [RewardTrainer] → 奖励模型 ─┐
└─ [GRPOTrainer + 奖励模型/函数] → 对齐模型或更简洁的无奖励模型路径:
基座模型 → [SFTTrainer] → SFT 模型 → [DPOTrainer] → 对齐模型小结
本节梳理了 TRL 提供的 8 个核心训练器(SFTTrainer、RewardTrainer、PRMTrainer、DPOTrainer、OnlineDPOTrainer、RLOOTrainer、GRPOTrainer、AsyncGRPOTrainer),从数据格式、API 用法、关键参数三个维度进行了速查式的介绍。几个实用建议:
- 从 SFT 开始:几乎所有对齐流程都以 SFTTrainer 为起点,先确保模型具备基本的指令遵循能力。
- 离线数据用 DPO,在线反馈用 GRPO:这是目前最主流的两条路径。
- GRPOTrainer 是在线 RL 的默认推荐:相比 RLOOTrainer,GRPO 的 group-level 归一化更稳定;相比已废弃的 PPOTrainer,GRPO 更节省显存。
- 大规模训练考虑 vLLM 加速:GRPOTrainer 和 RLOOTrainer 均支持 vLLM 的 colocate 或 server 模式,可显著提升生成吞吐。
- 实验性 API 注意版本兼容:PRMTrainer、OnlineDPOTrainer、AsyncGRPOTrainer 等位于
trl.experimental中,升级 TRL 时需关注接口变更。