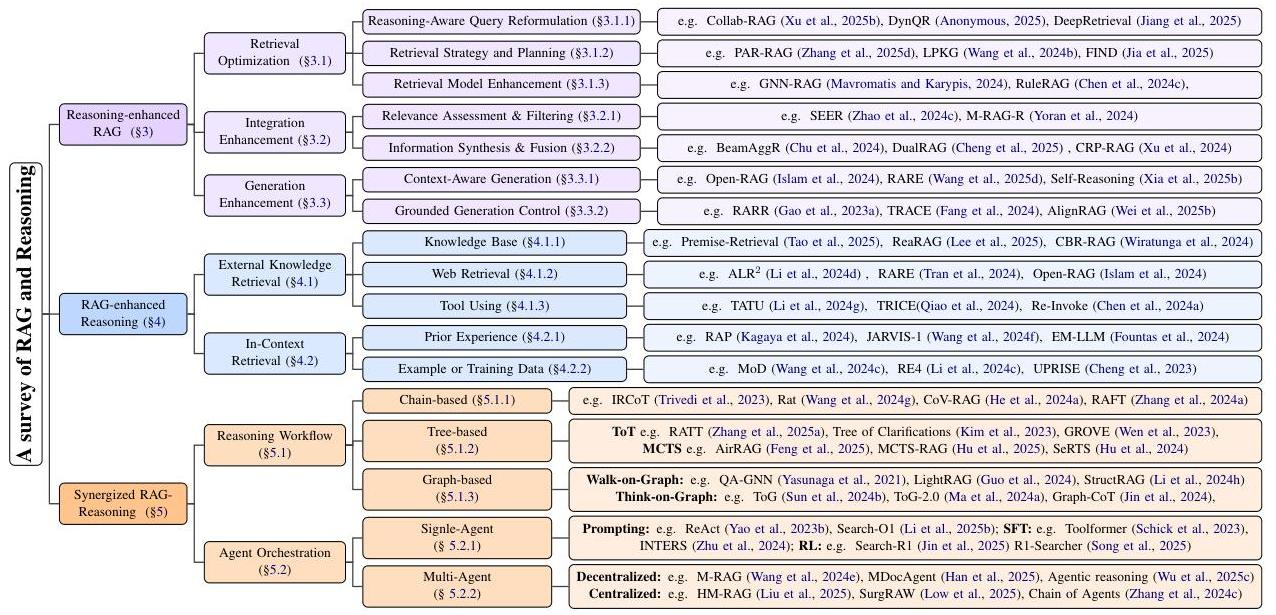
22.3 RAG 深化
"大多数 RAG 教程的终点,恰好是真正困难的起点。"
在 §22.1 中,我们建立了 RAG 的基本框架——检索器、生成器和融合策略三大核心模块;在 §22.2 中,我们深入了解了向量数据库的索引机制与相似度搜索原理。如果说前两节让你能够"让 RAG 跑起来",那么本节的目标是让你理解如何让 RAG 真正可用。从 Chunking 策略到噪声过滤,从混合检索到 Rerank,从查询改写到答案接地,再到 RAG 与推理的深度融合以及知识图谱的协同——本节将系统地拆解 RAG 在工程落地中面临的九大核心问题,并进一步探讨 Agentic RAG 和知识图谱增强等前沿方向。
本节的学习目标如下:(1)掌握 RAG 九大核心问题的原理与工程解法;(2)理解 Agentic RAG 的三种集成模式;(3)认识知识图谱如何补充纯向量检索的语义缺陷;(4)建立对企业级 RAG 差距的清醒认知。
22.3.1 九大核心问题:从"能跑"到"能用"
现实中的 RAG 系统,绝大多数教程只覆盖了"加载文档 → 切块 → 嵌入 → Top-K 检索 → 拼接 Prompt → 生成回答"的最小流程。但这个流程在真实场景中几乎总会暴露以下痛点:切块策略不合理导致信息丢失、检索结果充满噪声、同义词和跨语言表达无法匹配、排序不精确、多文档融合混乱、用户意图理解不准、生成结果缺乏事实依据、系统好坏无法量化评估。这些才是决定一个 RAG 系统能否上线的关键。
下面逐一拆解这九大核心问题。
问题一:Chunking 策略——怎么切才不丢信息?
Chunking(分块)是 RAG 流水线的第一步,也是影响最深远的一步。切块策略的本质是在语义完整性和检索粒度之间寻找平衡:块太大,检索时会混入大量无关信息,降低精度;块太小,语义信息被割裂,上下文丢失。
三种基础分块策略各有适用场景:
固定长度分块(Fixed-size Chunking):最简单的方法,以字符数或 Token 数为单位顺序切割,相邻块之间保留重叠部分(Overlap)以避免语义断裂。适合内容结构均匀的纯文本文档。
语义分块(Semantic Chunking):根据语义边界(如段落分隔、句号、换行符)切割,尝试让每个块包含一个完整的语义单元。适合结构化程度较高的文档。
基于内容的分块(Content-aware Chunking):根据文档的内在结构特征进行切割,例如 Markdown 按标题层级、代码按函数定义、医疗病历按章节。这种方法能最好地保留领域语义,但需要针对不同文档类型定制解析器。
确定分块大小时需要考虑三个关键因素。第一是任务偏好:问答任务倾向于短块(100-300 Token),因为答案通常集中在一小段文本中;摘要任务则倾向于长块(500-1000 Token),需要更完整的上下文。第二是编码器偏好:不同的 Embedding 模型对输入长度的处理能力不同,超出最优长度范围的文本,嵌入质量会下降。第三是查询偏好:用户查询的长度和复杂度应当与块的粒度大致匹配——短查询配短块,长查询配长块。
下面的代码示例展示了一个带重叠的语义分块实现:
import re
from typing import List
def semantic_chunk(text: str, max_size: int = 300, overlap: int = 50) -> List[str]:
"""
按语义边界(句号、换行)切分文本,保持每块不超过 max_size 字符,
相邻块之间保留 overlap 个字符的重叠。
"""
# 按句号、问号、感叹号、换行等分句
sentences = re.split(r'(?<=[。!?\n])', text)
sentences = [s.strip() for s in sentences if s.strip()]
chunks = []
current_chunk = ""
for sent in sentences:
# 如果当前块加上新句子不超过限制,继续拼接
if len(current_chunk) + len(sent) <= max_size:
current_chunk += sent
else:
if current_chunk:
chunks.append(current_chunk)
# 新块从上一个块的末尾 overlap 个字符开始,保持上下文连贯
if chunks and overlap > 0:
current_chunk = chunks[-1][-overlap:] + sent
else:
current_chunk = sent
if current_chunk:
chunks.append(current_chunk)
return chunks
# 测试
sample_text = (
"检索增强生成是一种优化大型语言模型输出的机制。"
"它通过利用外部知识数据库来增强模型的功能。"
"RAG 旨在解决幻觉问题、知识更新困难等局限性。"
"通过检索权威的外部信息,使模型响应更加准确和可信赖。"
)
chunks = semantic_chunk(sample_text, max_size=80, overlap=20)
for i, c in enumerate(chunks):
print(f"Chunk {i}: [{len(c)}字] {c}")进阶技巧:递归字符分割。 在实际工程中,递归字符分割(Recursive Character Text Splitting)是一种被广泛采用的策略:按优先级从高到低尝试分隔符(\n\n → \n → 。 → , → ),优先保留高层级的语义结构。如果按段落分割后单个块仍然超出大小限制,则降级到按句子分割,以此类推。
问题二:噪声过滤——如何减少无关检索?
即使使用了高质量的 Embedding 模型,检索结果中也不可避免地会混入噪声——那些在向量空间中距离较近、但实际上与查询无关的文档块。噪声块被塞入 Prompt 后,不仅浪费宝贵的上下文窗口,还可能误导模型生成错误答案。
噪声过滤的核心策略包括:
- 相似度阈值过滤:设定一个最低相似度分数(如余弦相似度 > 0.6),低于阈值的结果直接丢弃,而非盲目取 Top-K。
- Metadata 过滤:利用文档的元数据(如时间戳、文档类型、来源标签)进行预筛选。例如,用户询问"最新政策"时,可以先按时间排序,只在近一年的文档中检索。
- 去重与合并:当多个检索结果来自同一文档的相邻块时,合并它们以减少冗余,同时恢复更完整的上下文。
- LLM 相关性判断:将候选块逐一提交给小模型,让它判断"这段文本是否能回答用户的问题",过滤掉被判为不相关的块。
import numpy as np
def filter_by_threshold(
query_embedding: np.ndarray,
doc_embeddings: np.ndarray,
doc_texts: list,
threshold: float = 0.6,
top_k: int = 5,
) -> list:
"""
结合相似度阈值和 Top-K 的检索过滤策略。
先按余弦相似度排序,再过滤低于阈值的结果。
"""
# 计算余弦相似度(假设向量已归一化)
scores = query_embedding @ doc_embeddings.T
# 按分数降序排列
ranked_indices = np.argsort(scores)[::-1]
results = []
for idx in ranked_indices:
if scores[idx] < threshold:
break # 后续分数只会更低,提前终止
results.append({
"text": doc_texts[idx],
"score": float(scores[idx]),
})
if len(results) >= top_k:
break
return results问题三:混合检索——BM25 + Embedding 的互补
单一的检索方式都有盲区。稀疏检索(如 BM25)基于词频统计,擅长精确的关键词匹配,但无法理解语义——"引擎盖"和"前机舱盖"在 BM25 看来毫无关联。密集检索(基于 Embedding 的语义检索)擅长捕捉语义相似性,但在精确的专业术语、数字编号、人名地名等匹配上反而不如 BM25。
混合检索(Hybrid Retrieval)的思路是同时执行两种检索,然后将结果融合。典型的融合方式是倒数排名融合(Reciprocal Rank Fusion, RRF):
其中
from collections import defaultdict
def reciprocal_rank_fusion(
rankings: list[list[str]], k: int = 60
) -> list[tuple[str, float]]:
"""
倒数排名融合(RRF):合并多个检索器的排名结果。
参数:
rankings: 每个检索器返回的文档 ID 排名列表
k: 平滑常数,防止排名第一的文档权重过大
返回:
按融合分数降序排列的 (doc_id, score) 列表
"""
rrf_scores = defaultdict(float)
for ranking in rankings:
for rank, doc_id in enumerate(ranking, start=1):
rrf_scores[doc_id] += 1.0 / (k + rank)
sorted_results = sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
return sorted_results
# 示例:BM25 和语义检索各返回 5 个文档
bm25_ranking = ["doc_3", "doc_7", "doc_1", "doc_5", "doc_9"]
semantic_ranking = ["doc_1", "doc_3", "doc_8", "doc_5", "doc_2"]
fused = reciprocal_rank_fusion([bm25_ranking, semantic_ranking])
print("RRF 融合结果:")
for doc_id, score in fused[:5]:
print(f" {doc_id}: {score:.4f}")
# doc_3 和 doc_1 在两个排名中都靠前,融合后排名最高问题四:Rerank——精排的价值
初始检索(无论 BM25 还是 Embedding)追求的是召回率——宁可多捞一些,不要漏掉。但这些候选结果的排序精度有限。Rerank(重排序) 使用专门的交叉编码器(Cross-Encoder)对"查询-文档"对进行精细打分,从候选集中挑选出真正最相关的结果。
Cross-Encoder 与 Bi-Encoder 的关键区别在于:Bi-Encoder(如标准的 Embedding 模型)分别编码查询和文档,然后用点积/余弦相似度比较;Cross-Encoder 将查询和文档拼接后一起输入 Transformer,通过全注意力机制捕捉两者之间的细粒度交互。Cross-Encoder 的精度远高于 Bi-Encoder,但计算成本也高得多——对每个候选文档都要做一次完整的前向传播。因此,Rerank 通常作为检索管道的第二阶段:先用 Bi-Encoder 粗检索 Top-20/50,再用 Cross-Encoder 精排 Top-3/5。

import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def rerank_documents(
query: str,
candidate_texts: list[str],
model_name: str = "BAAI/bge-reranker-v2-m3",
top_k: int = 3,
) -> list[dict]:
"""
使用 Cross-Encoder 重排序候选文档。
参数:
query: 用户查询
candidate_texts: 粗检索返回的候选文档文本列表
model_name: Reranker 模型名称
top_k: 返回排名最高的文档数
返回:
重排后的 top_k 文档及其得分
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval()
# 构造 (query, document) 配对
pairs = [[query, text] for text in candidate_texts]
inputs = tokenizer(
pairs, padding=True, truncation=True,
return_tensors="pt", max_length=512
)
with torch.no_grad():
scores = model(**inputs).logits.view(-1).numpy()
# 按得分降序排列,取 top_k
ranked = sorted(
enumerate(scores), key=lambda x: x[1], reverse=True
)[:top_k]
return [
{"text": candidate_texts[idx], "score": float(score)}
for idx, score in ranked
]问题五:召回改进——捞得更全
召回率是检索系统的生命线。如果相关文档根本没有被检索到,后续的 Rerank 和生成都无济于事。提升召回的核心手段包括:
多向量表示:一个文档块可以生成多个嵌入向量(例如 ColBERT 的 Token 级别嵌入),查询时对每个 Token 向量分别匹配,取最大相似度(MaxSim),从而捕捉更细粒度的语义匹配。
父子块关联:将文档按层级结构组织——父块是完整的段落或章节,子块是细粒度的句子。检索时用子块匹配查询,但返回父块给生成器,既保证检索精度又保证上下文完整性。
假设性文档嵌入(HyDE):先让 LLM 根据查询生成一个"假设性答案",然后用这个答案的嵌入向量去检索。其直觉是:答案的嵌入比问题的嵌入更接近真实文档的嵌入空间。
动态 Top-K:根据查询的复杂度自适应调整 K 值。简单的事实性问题用小 K(3-5),复杂的综合性问题用大 K(10-20)。
问题六:多文档融合——如何整合异构证据?
当检索返回的多个文档块来自不同来源、不同时间甚至互相矛盾时,简单的拼接会让生成器困惑。多文档融合的策略包括:
- 去冗余拼接:检测候选块之间的文本重叠度,合并高度重复的块,保留信息量最大的版本。
- 分层摘要:先让 LLM 对每个候选块生成一句话摘要,然后将摘要集合作为上下文输入生成器。这种"Map-Reduce"式的融合适合候选块数量较多(>10)的场景。
- 来源标注:在拼接的上下文中为每个块标注来源(如
[来源: 《用户手册》第3页]),引导生成器在回答中引用出处,便于用户验证。 - 矛盾检测与标记:当多个来源的信息存在冲突时,显式标记矛盾点,让生成器在回答中说明不同来源的差异,而非随机选择一个。
问题七:查询改写——理解用户的真实意图
用户的原始查询往往模糊、口语化、甚至包含错别字。直接用原始查询检索,很可能错过最相关的文档。查询改写(Query Rewriting) 通过 LLM 将用户查询转化为更适合检索的形式。
常见的改写策略包括:
- 查询扩展:将一个模糊查询扩展为多个具体查询。例如"大模型怎么训练"可以扩展为"大语言模型预训练数据集""Transformer 模型训练流程""LLM 微调方法",分别检索后合并结果。
- 子问题分解:将复杂查询拆分为多个子问题,每个子问题独立检索后聚合。例如"比较 BERT 和 GPT 的架构差异和训练方式"可以拆分为"BERT 的架构特点""GPT 的架构特点""BERT 的训练方式""GPT 的训练方式"。
- Step-Back Prompting:先让 LLM 将具体问题抽象为更高层次的问题,用抽象问题检索获取背景知识,再结合具体问题检索的结果生成最终回答。
def query_rewrite(original_query: str, llm_generate) -> list[str]:
"""
使用 LLM 将原始查询改写为多个检索友好的子查询。
参数:
original_query: 用户原始查询
llm_generate: LLM 生成函数,接收 prompt 返回文本
返回:
改写后的查询列表
"""
prompt = f"""你是一个查询改写助手。请将以下用户查询改写为3个更适合文档检索的子查询。
要求:
1. 每个子查询覆盖原始查询的不同方面
2. 使用准确的技术术语
3. 每行一个子查询,不要编号
用户查询: {original_query}
改写后的子查询:"""
response = llm_generate(prompt)
sub_queries = [q.strip() for q in response.strip().split("\n") if q.strip()]
return sub_queries[:3] # 最多返回 3 个问题八:答案接地(Grounding)——让回答有据可查
RAG 的核心承诺是"基于事实生成",但即使提供了参考文档,LLM 仍然可能"越界"——在回答中混入自身参数记忆中的信息,而这些信息可能是过时的或错误的。答案接地就是确保生成内容严格来源于检索到的文档。
工程上实现接地的关键技术包括:
- 引用标注:要求模型在回答中标注每个陈述的来源(如
[参考: 文档A第3段]),没有来源支撑的陈述自动标记为不可靠。 - 后验事实核查:生成回答后,用 NLI(自然语言推理)模型逐句检查回答是否能从参考文档中推断出来。分类为"蕴含(Entailment)"的句子保留,"矛盾(Contradiction)"或"中立(Neutral)"的句子标记警告。
- Prompt 约束:在 System Prompt 中明确指示"只能使用提供的参考资料回答,如果资料中没有答案,请明确说明无法回答"。这条看似简单的指令对减少越界生成非常有效。
问题九:RAG 评估——怎么知道系统好不好?
RAG 系统的评估是最常被忽视但最重要的环节。评估需要从检索质量和生成质量两个维度分别衡量。
检索质量的核心指标:
| 指标 | 定义 | 直觉 |
|---|---|---|
| Recall@K | 前 K 个结果中包含相关文档的比例 | 有没有捞到? |
| Precision@K | 前 K 个结果中相关文档的比例 | 捞到的准不准? |
| MRR | 第一个相关文档排名的倒数 | 最相关的排多前? |
| NDCG@K | 考虑排名位置的归一化折损累积增益 | 排序质量如何? |
生成质量的评估更复杂,常用的框架是 RAGAS(Retrieval Augmented Generation Assessment),它定义了四个核心指标:
- 忠实度(Faithfulness):生成的回答是否与检索到的上下文一致,是否存在幻觉?
- 答案相关性(Answer Relevancy):生成的回答是否真正回答了用户的问题?
- 上下文精度(Context Precision):检索到的上下文中有多大比例是回答问题所必需的?
- 上下文召回(Context Recall):回答问题所需的信息是否都被检索到了?
def evaluate_retrieval(
queries: list[str],
ground_truth_docs: list[set],
retrieved_docs: list[list],
k: int = 5,
) -> dict:
"""
计算检索质量的核心指标。
参数:
queries: 查询列表
ground_truth_docs: 每个查询的真实相关文档 ID 集合
retrieved_docs: 每个查询检索到的文档 ID 列表(按排名排列)
k: 评估的截断位置
返回:
包含 Recall@K, Precision@K, MRR 的评估结果
"""
recalls, precisions, mrrs = [], [], []
for gt_set, retrieved in zip(ground_truth_docs, retrieved_docs):
top_k = retrieved[:k]
hits = set(top_k) & gt_set
recall = len(hits) / len(gt_set) if gt_set else 0
precision = len(hits) / k
recalls.append(recall)
precisions.append(precision)
# MRR: 第一个命中的排名倒数
mrr = 0
for rank, doc_id in enumerate(top_k, start=1):
if doc_id in gt_set:
mrr = 1.0 / rank
break
mrrs.append(mrr)
return {
f"Recall@{k}": sum(recalls) / len(recalls),
f"Precision@{k}": sum(precisions) / len(precisions),
"MRR": sum(mrrs) / len(mrrs),
}下表汇总九大问题的核心解法:
| 核心问题 | 关键解法 | 改善的维度 |
|---|---|---|
| Chunking 策略 | 语义分块 + 递归字符分割 | 检索精度 |
| 噪声过滤 | 相似度阈值 + Metadata 预筛 | 上下文质量 |
| 混合检索 | BM25 + Embedding + RRF 融合 | 召回率 |
| Rerank | Cross-Encoder 精排 | 排序精度 |
| 召回改进 | 多向量 / 父子块 / HyDE | 召回率 |
| 多文档融合 | 去重拼接 / 分层摘要 / 来源标注 | 生成质量 |
| 查询改写 | 扩展 / 分解 / Step-Back | 检索召回 |
| 答案接地 | 引用标注 / NLI 核查 / Prompt 约束 | 忠实度 |
| RAG 评估 | RAGAS 框架 / 检索 + 生成双维度 | 系统可观测性 |
22.3.2 Agentic RAG:检索与推理的深度融合
传统 RAG 是一条固定的流水线:检索 → 融合 → 生成。这种"一次检索、一次生成"的模式在面对复杂问题时力不从心——有些问题需要多轮检索、有些需要先推理再检索、有些需要在推理过程中动态决定何时检索。Agentic RAG 将 RAG 从固定管道升级为智能体驱动的自适应系统,让检索和推理以更灵活的方式交互。
根据检索与推理的主导关系,Agentic RAG 可以划分为三种集成模式。
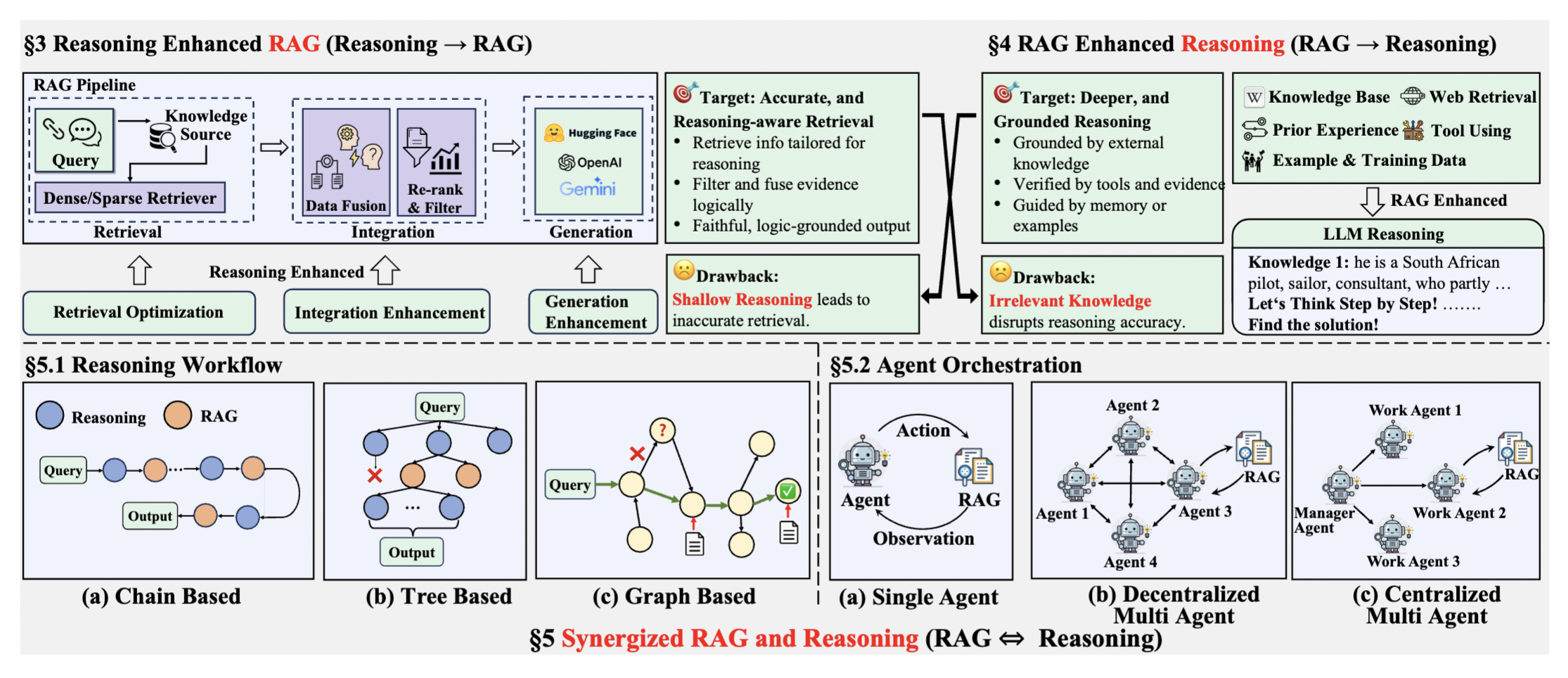
模式一:推理增强型 RAG(推理 → RAG)
在这种模式下,推理技术被用于优化 RAG 管道的每个组件。核心洞察是:RAG 的检索、融合、生成三个阶段都可以从更精细的推理中受益。
检索优化:利用推理能力重构查询。复杂的查询被分解为更简单的子查询,或通过 Chain-of-Thought(CoT)提示来澄清模糊查询。此外,推理还指导检索策略——模型可以自适应地决定"是否需要检索""检索什么信息""使用哪个数据源"。
融合增强:将推理应用于评估检索文档的相关性、过滤噪声以及综合异构证据。例如,使用 NLI 模型评估文档与查询的蕴含关系,或用 LLM 对多个候选文档进行可信度排序。
生成增强:确保最终输出既有事实依据又逻辑连贯。包括选择性地利用检索信息(忽略不相关的检索结果)、以及基于事实的生成控制(自动生成引文链接到源文档)。
模式二:RAG 增强型推理(RAG → 推理)
这种模式的核心认识是:推理失败往往不是因为逻辑不足,而是因为知识不足。通过检索外部知识来填补 LLM 推理链中缺失的前提。
外部知识检索:从结构化知识库(如 Wikidata)、实时网络搜索、或专业数据库中获取推理所需的事实信息。例如,数学推理任务中,检索相关的定理和公式作为推理的前提。
上下文内检索:利用模型操作上下文中已有的知识,包括过去的成功推理经验和 Few-shot 示例。模型可以从类似问题的成功解答中学习推理模式,提升当前问题的推理质量。
工具集成:RAG 不仅检索文本,还可以检索和调用工具。例如,在需要数值计算的推理中,检索并调用计算器工具确保数值精度。
模式三:协同 RAG-推理(RAG ⇔ 推理)
最先进的模式实现了检索和推理的双向、迭代交互——推理不断完善检索策略,同时新检索到的信息塑造后续的推理过程。这是真正的"闭环"系统。
协同模式下的推理工作流采用多种复杂结构:
链式(Chain-based):推理和检索步骤交替进行,形成
推理 → 检索 → 推理 → 检索 → ...的链条。每一步推理产生新的检索需求,每一步检索提供新的推理素材。树式(Tree-based):从初始问题出发,探索多条推理路径,每条路径可能触发不同的检索请求。最终通过投票或验证机制选择最优的推理路径。
图式(Graph-based):推理过程构成有向图结构,节点之间可以共享检索结果和中间推理结论。这种结构特别适合需要整合多个知识点的复杂推理任务。
在智能体编排层面,协同 RAG-推理有两种架构:
单智能体系统:一个 LLM 同时承担推理和检索协调的角色,自主决定何时检索、检索什么、如何整合结果。优势是决策统一,劣势是上下文负担重。
多智能体框架:专业化的 Agent 分工协作——检索 Agent 负责信息获取,推理 Agent 负责逻辑推演,协调 Agent 负责任务调度。可以是去中心化的(Agent 之间对等通信)或分层的(有一个中心协调者)。
class AgenticRAG:
"""
Agentic RAG 的简化实现:
模型在推理过程中自主决定是否需要检索,
以及何时停止检索进入最终生成。
"""
def __init__(self, llm_generate, retriever, max_rounds: int = 3):
self.llm = llm_generate
self.retriever = retriever
self.max_rounds = max_rounds
def answer(self, query: str) -> str:
context_blocks = []
current_query = query
for round_idx in range(self.max_rounds):
# Step 1: 让 LLM 判断是否需要检索
decision_prompt = f"""根据以下信息,判断是否需要检索更多资料来回答用户问题。
已有资料: {context_blocks if context_blocks else '无'}
用户问题: {query}
当前分析焦点: {current_query}
请回答 SEARCH(需要检索)或 ANSWER(可以回答),并简要说明理由。
如果选择 SEARCH,请给出一个优化后的检索查询。
决策:"""
decision = self.llm(decision_prompt)
if "ANSWER" in decision.upper():
break
# Step 2: 提取优化后的查询并检索
search_query = self._extract_search_query(decision, current_query)
new_docs = self.retriever(search_query, top_k=3)
context_blocks.extend(new_docs)
# Step 3: 让 LLM 基于新信息更新分析焦点
refine_prompt = f"""基于以下新检索到的资料,分析用户问题还有哪些方面未被覆盖。
用户问题: {query}
新资料: {new_docs}
请给出下一步应该检索的方向。"""
current_query = self.llm(refine_prompt)
# 最终生成
final_prompt = f"""请基于以下参考资料回答用户问题。
参考资料: {context_blocks}
用户问题: {query}
回答:"""
return self.llm(final_prompt)
def _extract_search_query(self, decision_text: str, fallback: str) -> str:
# 从决策文本中提取优化后的检索查询
lines = decision_text.strip().split("\n")
for line in lines:
if "检索查询" in line or "SEARCH" in line.upper():
query = line.split(":", 1)[-1].strip() if ":" in line else ""
if query:
return query
return fallback22.3.3 知识图谱 + RAG:语义关系的结构化补充
纯向量检索的根本局限在于:它只能捕捉表面语义相似性,而无法理解实体之间的结构化关系。举一个具体的例子:在算法竞赛领域,LCA(Lowest Common Ancestor,最近公共祖先)这一算法有三种常见称呼——英文缩写"LCA"、英文全称"Lowest Common Ancestor"、中文名"最近公共祖先"。标准的 Embedding 模型很可能无法将这三种表述映射到足够接近的向量空间位置,导致用户用其中一种称呼提问时,无法检索到使用另一种称呼撰写的文档。
知识图谱(Knowledge Graph, KG)通过显式地建模实体之间的关系来补充这一缺陷。在 KG 中,"LCA""Lowest Common Ancestor""最近公共祖先"被链接到同一个实体节点,它们是该实体的别名(Alias)。更进一步,KG 可以表达"LCA 是树上的经典算法""LCA 的前置知识包括 DFS 和树的基本遍历""LCA 的进阶应用包括倍增法和 Tarjan 离线算法"这类结构化关系。
知识图谱在 RAG 中的三大作用:
第一,实体别名管理——解决"同一概念多种表达"的问题。 系统维护一个别名列表,当不同文本块提到同一实体但使用不同表达时,自动合并去重。这样用户无论使用英文、中文还是缩写提问,都能检索到对应实体的所有相关文档。在工程实现上,可以利用 Neo4j 等图数据库的 Cypher 查询语言,通过 reduce() 操作高效合并别名列表。
# Neo4j Cypher: 合并实体别名
# 当新文档提到 "最近公共祖先" 时,将其添加到已有实体 "LCA" 的别名列表中
MERGE_ALIAS_QUERY = """
MATCH (e:Entity {canonical_name: $canonical_name})
SET e.aliases = REDUCE(
merged = e.aliases,
new_alias IN $new_aliases |
CASE WHEN new_alias IN merged THEN merged ELSE merged + new_alias END
)
RETURN e.canonical_name, e.aliases
"""
# 示例调用(伪代码)
# graph_db.run(MERGE_ALIAS_QUERY,
# canonical_name="LCA",
# new_aliases=["最近公共祖先", "Lowest Common Ancestor", "最低公共祖先"]
# )
# 结果: LCA 节点的 aliases = ["LCA", "最近公共祖先", "Lowest Common Ancestor", "最低公共祖先"]第二,多跳关系查询——补充向量检索的"一跳"局限。 向量检索本质上是"一跳"操作——找到与查询最相似的文档块。但很多问题需要跨越多个关系才能回答。例如"LCA 算法用到了哪些基础数据结构?"——需要先从 LCA 出发找到"前置知识"关系指向的 DFS,再从 DFS 找到"所需数据结构"关系指向的栈和递归。知识图谱的图遍历天然支持这种多跳查询。
第三,代码与知识的关联。 在代码检索场景中,代码块通常难以直接进行有效的向量检索(代码的"语义"与自然语言的"语义"差异很大)。通过知识图谱,可以将代码片段链接到对应的算法实体节点,用户提问时先通过自然语言检索定位到算法实体,再通过实体的关系边找到对应的代码实现。
知识图谱 + RAG 的多路检索架构:
实际系统通常采用并行的多路检索:
- 向量检索路:处理语义模糊的开放式查询,擅长"找到大致相关的内容"。
- 知识图谱路:处理涉及实体关系的结构化查询,擅长"精确定位实体和关系"。
- 关键词检索路(可选):处理包含精确术语的查询,如代码函数名、API 名称。
三路检索的结果经过统一的 Rerank 阶段融合,然后送入生成器。
class KGAugmentedRAG:
"""
知识图谱增强的 RAG 系统:
向量检索 + 图检索 双路并行,结果融合后生成。
"""
def __init__(self, vector_retriever, graph_db, llm_generate):
self.vector_retriever = vector_retriever
self.graph_db = graph_db
self.llm = llm_generate
def answer(self, query: str) -> str:
# 路径 1: 向量检索
vector_results = self.vector_retriever(query, top_k=5)
# 路径 2: 实体识别 + 图检索
entities = self._extract_entities(query)
graph_results = []
for entity in entities:
# 先查别名,找到规范实体名
canonical = self._resolve_alias(entity)
# 多跳查询:获取实体的描述、前置知识、相关代码
neighbors = self.graph_db.query(
"MATCH (e:Entity {canonical_name: $name})"
"-[r]->(related) "
"RETURN e.description, type(r), related.description "
"LIMIT 10",
name=canonical,
)
graph_results.extend(neighbors)
# 融合两路结果
combined_context = self._merge_results(vector_results, graph_results)
# 生成回答
prompt = f"""基于以下参考资料回答问题。
向量检索结果: {vector_results}
知识图谱信息: {graph_results}
用户问题: {query}
回答:"""
return self.llm(prompt)
def _extract_entities(self, text: str) -> list[str]:
"""使用 LLM 从查询中提取关键实体"""
prompt = f"从以下文本中提取关键技术实体(算法名、数据结构名等),用逗号分隔: {text}"
result = self.llm(prompt)
return [e.strip() for e in result.split(",") if e.strip()]
def _resolve_alias(self, entity: str) -> str:
"""通过别名列表解析实体的规范名称"""
result = self.graph_db.query(
"MATCH (e:Entity) WHERE $alias IN e.aliases "
"RETURN e.canonical_name LIMIT 1",
alias=entity,
)
return result[0] if result else entity
def _merge_results(self, vector_results, graph_results):
"""合并向量检索和图检索的结果,去重"""
seen = set()
merged = []
for item in vector_results + graph_results:
text = str(item)
if text not in seen:
seen.add(text)
merged.append(item)
return merged22.3.4 企业 RAG 差距:教程与现实的鸿沟
学习 RAG 的过程中,有一个容易产生的错觉需要被戳破:你在教程中看到的"效果很好",很可能不是 RAG 在起作用,而是模型自身在起作用。
当前的大语言模型(如 GPT-4、Claude、DeepSeek)本身就具备极其广泛的知识储备。在很多教程的演示场景中,即使检索完全不工作,模型仅凭自身参数记忆就能给出八九不离十的答案。于是开发者看到"回答正确"就以为 RAG 系统很厉害,实际上可能只是"模型自己懂,跟检索没关系"。
典型的企业 RAG 项目中,教程往往不覆盖但实际至关重要的环节包括:
| 教程通常覆盖 | 实际还需要 |
|---|---|
| 文档加载 + 默认切块 | 针对业务文档的定制化 Chunking 策略 |
| 单一 Embedding 模型 | 混合检索(BM25 + 多种 Embedding) |
| 固定 Top-K = 5 | 动态 K 值 + 相似度阈值过滤 |
| 无 Rerank | Cross-Encoder 精排 |
| 单文档问答 | 多文档融合 + 矛盾检测 |
| 无查询改写 | Query Rewriting + 子问题分解 |
| 无评估体系 | 端到端的 RAGAS 评估 + A/B 测试 |
| 无可观测性 | 检索日志 + 生成质量监控 + 用户反馈闭环 |
如何判断 RAG 是否真正在起作用? 最简单的方法是做消融实验:用相同的问题集,分别测试"有 RAG"和"无 RAG(纯模型)"两种配置。如果两者的回答质量没有显著差异,说明你的检索模块没有提供有效信息——要么检索不到相关文档,要么检索到的文档模型本来就知道。真正体现 RAG 价值的场景是:
- 私域知识:企业内部文档、最新的产品手册、未公开的技术规范——这些信息模型在训练时不可能见过。
- 时效性信息:模型训练数据有截止日期,之后发生的事件需要 RAG 提供实时信息。
- 精确引用:需要标注信息来源(如"参见手册第 307 页")的场景,纯模型无法做到。
- 长尾知识:高度专业化的领域知识,模型可能学得不够深入。
建立评估驱动的开发流程。 一个成熟的企业 RAG 项目,其开发流程应该是评估驱动的:
- 基线建立:先用纯模型(无 RAG)在真实问题集上测试,建立性能基线。
- 增量验证:每加入一个 RAG 组件(Chunking 策略、混合检索、Rerank、查询改写),都与基线对比,量化改进幅度。
- 端到端监控:上线后持续监控检索召回率、答案忠实度、用户满意度。
- 反馈迭代:收集用户标注的"好答案"和"坏答案",用于优化检索和生成。
def ablation_study(
questions: list[str],
ground_truth: list[str],
model_only_fn,
rag_fn,
metric_fn,
) -> dict:
"""
RAG 消融实验:对比纯模型 vs RAG 的性能差异。
参数:
questions: 测试问题集
ground_truth: 标准答案
model_only_fn: 纯模型生成函数
rag_fn: RAG 系统生成函数
metric_fn: 评估指标函数(如 BLEU、ROUGE、人工评分)
返回:
两种配置的性能对比
"""
model_scores, rag_scores = [], []
for q, gt in zip(questions, ground_truth):
# 纯模型回答
model_answer = model_only_fn(q)
model_scores.append(metric_fn(model_answer, gt))
# RAG 回答
rag_answer = rag_fn(q)
rag_scores.append(metric_fn(rag_answer, gt))
avg_model = sum(model_scores) / len(model_scores)
avg_rag = sum(rag_scores) / len(rag_scores)
delta = avg_rag - avg_model
return {
"model_only_avg": avg_model,
"rag_avg": avg_rag,
"improvement": delta,
"rag_effective": delta > 0.05, # 改进超过 5% 才认为 RAG 有效
}22.3.5 完整 RAG 管道:从理论到代码
为了将本节讨论的所有技术串联起来,下面给出一个完整的高级 RAG 管道实现,涵盖语义分块、混合检索、Rerank 和带引用的生成。
"""
完整的高级 RAG 管道示例。
依赖: pip install rank-bm25 sentence-transformers numpy
"""
import re
import numpy as np
from collections import defaultdict
from rank_bm25 import BM25Okapi
# ======================== Step 1: 语义分块 ========================
def semantic_chunk_documents(
documents: list[dict], max_size: int = 300, overlap: int = 50
) -> list[dict]:
"""
对文档列表进行语义分块,保留来源元数据。
每个文档格式: {"text": "...", "source": "..."}
"""
all_chunks = []
for doc in documents:
sentences = re.split(r'(?<=[。!?\n])', doc["text"])
sentences = [s.strip() for s in sentences if s.strip()]
current_chunk = ""
for sent in sentences:
if len(current_chunk) + len(sent) <= max_size:
current_chunk += sent
else:
if current_chunk:
all_chunks.append({
"text": current_chunk,
"source": doc["source"],
})
current_chunk = (
current_chunk[-overlap:] + sent if overlap > 0
else sent
)
if current_chunk:
all_chunks.append({
"text": current_chunk,
"source": doc["source"],
})
return all_chunks
# ======================== Step 2: 混合检索 ========================
class HybridRetriever:
"""BM25 + Embedding 混合检索器"""
def __init__(self, chunks: list[dict], embedding_fn):
self.chunks = chunks
self.texts = [c["text"] for c in chunks]
# BM25 索引
tokenized = [list(t) for t in self.texts] # 中文按字符分词(简化)
self.bm25 = BM25Okapi(tokenized)
# 语义嵌入索引
self.embeddings = embedding_fn(self.texts)
# 归一化
norms = np.linalg.norm(self.embeddings, axis=1, keepdims=True)
self.embeddings = self.embeddings / (norms + 1e-9)
self.embedding_fn = embedding_fn
def search(self, query: str, top_k: int = 10) -> list[dict]:
# BM25 检索
query_tokens = list(query)
bm25_scores = self.bm25.get_scores(query_tokens)
bm25_ranking = np.argsort(bm25_scores)[::-1][:top_k]
# 语义检索
q_emb = self.embedding_fn([query])
q_emb = q_emb / (np.linalg.norm(q_emb) + 1e-9)
sem_scores = (q_emb @ self.embeddings.T).flatten()
sem_ranking = np.argsort(sem_scores)[::-1][:top_k]
# RRF 融合
rrf_scores = defaultdict(float)
k = 60
for rank, idx in enumerate(bm25_ranking, 1):
rrf_scores[idx] += 1.0 / (k + rank)
for rank, idx in enumerate(sem_ranking, 1):
rrf_scores[idx] += 1.0 / (k + rank)
sorted_indices = sorted(
rrf_scores.keys(), key=lambda x: rrf_scores[x], reverse=True
)
results = []
for idx in sorted_indices[:top_k]:
results.append({
"text": self.chunks[idx]["text"],
"source": self.chunks[idx]["source"],
"rrf_score": rrf_scores[idx],
})
return results
# ======================== Step 3: 带引用的生成 ========================
def generate_with_citations(
query: str,
retrieved_chunks: list[dict],
llm_generate,
) -> str:
"""
基于检索结果生成带引用标注的回答。
"""
# 构造带编号的参考资料
context_lines = []
for i, chunk in enumerate(retrieved_chunks, 1):
context_lines.append(f"[{i}] (来源: {chunk['source']}) {chunk['text']}")
context = "\n\n".join(context_lines)
prompt = f"""请基于以下参考资料回答用户问题。要求:
1. 每个陈述后标注引用来源,格式如 [1]、[2]
2. 如果参考资料中没有足够信息,明确说明
3. 不要使用参考资料之外的知识
参考资料:
{context}
用户问题: {query}
回答:"""
return llm_generate(prompt)
# ======================== 使用示例 ========================
if __name__ == "__main__":
# 模拟文档
docs = [
{"text": "RAG 通过检索外部知识来增强大模型的生成能力。它能减少幻觉并提供最新信息。",
"source": "RAG概述.pdf"},
{"text": "BM25 是一种基于词频的检索算法。它通过 TF-IDF 变体计算查询与文档的相关性。",
"source": "检索算法.pdf"},
{"text": "向量数据库使用近似最近邻搜索来加速高维向量的相似度查询。常见的索引方法包括 HNSW 和 IVF。",
"source": "向量数据库.pdf"},
]
# 分块
chunks = semantic_chunk_documents(docs, max_size=200, overlap=30)
print(f"分块结果: {len(chunks)} 个块")
# 后续需要真实的 Embedding 模型和 LLM
# 此处仅展示管道结构,实际运行需替换 embedding_fn 和 llm_generate22.3.6 本节总结
本节系统地拆解了 RAG 从"能跑"到"能用"的完整技术图谱。核心要点回顾如下:
九大核心问题 构成了 RAG 工程化的基石:Chunking 策略决定信息粒度,噪声过滤和混合检索决定召回质量,Rerank 决定排序精度,查询改写弥补意图理解的缺陷,多文档融合处理异构证据,答案接地保障忠实度,评估体系提供量化反馈。这九个环节环环相扣,任何一个短板都会成为系统的瓶颈。
Agentic RAG 将 RAG 从固定管道升级为自适应系统。三种集成模式——推理增强 RAG(推理 → RAG)、RAG 增强推理(RAG → 推理)、协同 RAG-推理(RAG ⇔ 推理)——代表了检索与推理融合的三个演进阶段,其中协同模式通过双向迭代实现了最深度的整合。
知识图谱 + RAG 通过结构化的实体关系补充了纯向量检索的语义盲区。实体别名管理解决了同义词问题,多跳关系查询支撑了复杂推理,代码-知识关联扩展了检索的覆盖面。
企业 RAG 差距 提醒我们保持清醒:模型自身的强大可能掩盖了检索模块的缺陷。通过消融实验验证 RAG 的真实贡献、建立评估驱动的开发流程,是从"演示效果好"迈向"生产可靠"的必经之路。
RAG 不是一个"搭完就结束"的系统,而是一个需要持续优化的工程。正如本节开头所说:教程的终点,才是真正困难的起点。