18.4 异步 Rollout 与样本陈旧性
在标准的 GRPO/PPO 训练循环中,生成(rollout)与训练(training)是严格串行的:模型先用当前策略生成一批补全(completion),计算奖励和优势,然后执行梯度更新,更新完毕后再生成下一批。这种"生成→训练→生成→训练"的同步模式在数学推理等轻量级任务上运行良好,但当训练场景扩展到 Agentic RL——涉及多轮环境交互、工具调用、沙箱执行——时,同步管线会暴露出致命的效率瓶颈。本节将深入讨论异步 rollout 的动机与架构设计、样本陈旧性(sample staleness)的理论分析与工程控制,以及 TRL 框架中 AsyncGRPO 的实现细节。
18.4.1 同步管线的瓶颈:长尾延迟
在同步 rollout 管线中,一个训练批次的所有样本必须全部生成完毕后,才能进入梯度更新阶段。这意味着整个批次的耗时由最慢的那条轨迹决定。
对于 Agentic RL 场景,这个问题尤为严重。下图展示了终端环境中大量 rollout 的耗时分布:大多数轨迹在数百秒内完成,但少数轨迹因为环境交互缓慢、编译超时或网络故障,耗时可达数千秒。
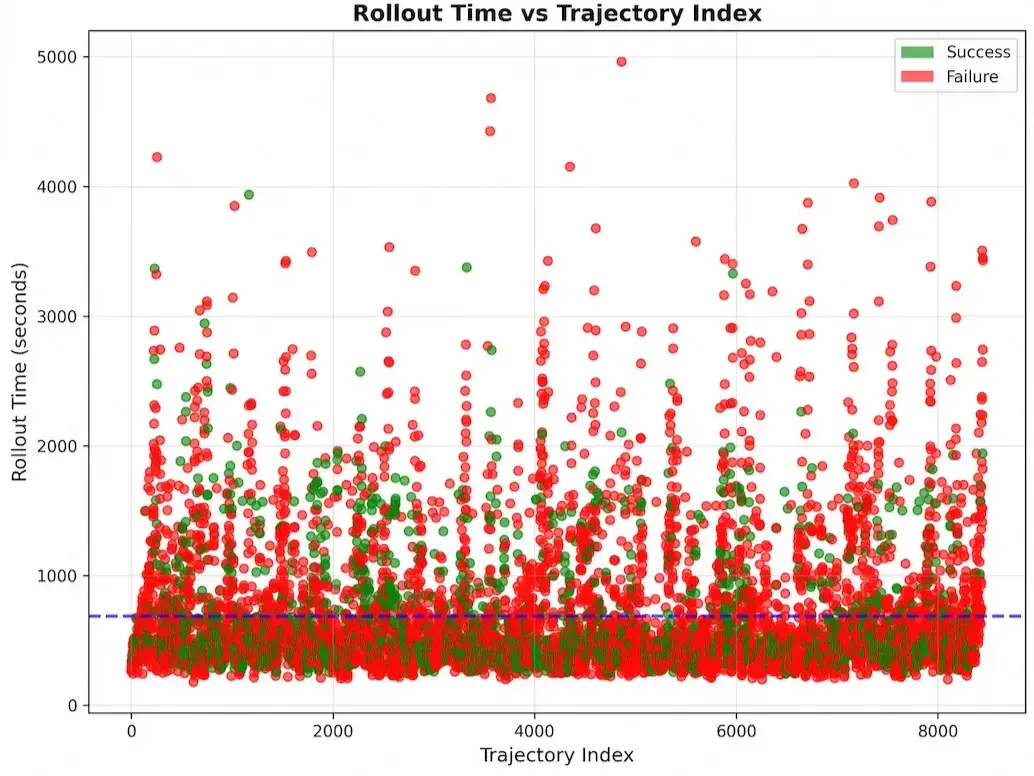
图 18-7:终端环境 rollout 耗时散点图。绿色为成功轨迹,红色为失败轨迹。少数极端耗时的轨迹构成显著的长尾,在同步管线中会成为拖尾瓶颈。
这种**长尾延迟(long-tail latency)**导致的后果十分直观:假设一个批次包含 64 条轨迹,其中 63 条在 30 秒内完成,但有 1 条需要 600 秒,那么所有 GPU 在剩余的 570 秒内都处于空闲等待状态。GPU 利用率骤降,训练吞吐量大打折扣。
即使在纯文本生成场景(不涉及环境交互),同步管线也存在效率问题。标准 GRPO 的训练循环可以表示为:
其中
18.4.2 异步解耦:生成与训练并行
异步 rollout 的核心思想是将生成和训练解耦为两个并行运行的流程,用一个队列(queue)连接二者:
- Rollout 工作线程(后台运行):持续向推理引擎发送提示词,接收生成结果,计算奖励和优势,然后将"训练就绪"的样本推入队列。
- 训练主循环(前台运行):从队列中取出样本,计算裁剪替代目标的损失,执行梯度更新。
这种设计使得训练循环不必等待所有生成完成,只要队列中有足够的样本就可以立即开始更新。有效步时间从串行求和变为取最大值:
当生成和训练的耗时相近时,异步管线可以将吞吐量提升近一倍。
下图对比了同步批处理 rollout 与异步队列调度 rollout 的区别。在批处理模式中,GPU 需要等待批次中最慢的任务完成(图中标记为 IDLE 的灰色区域);而在队列调度模式中,每个 GPU 在完成当前任务后立即开始下一个,大幅减少了空闲时间。
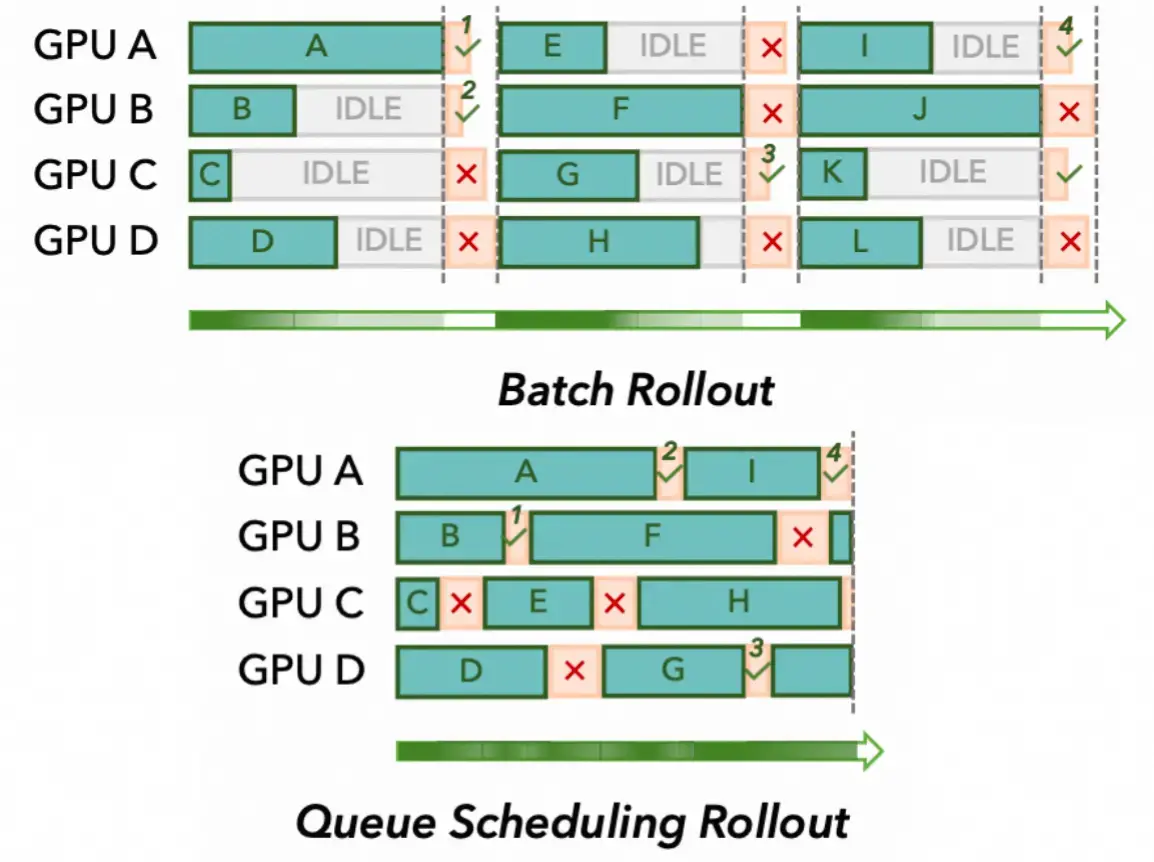
图 18-8:批处理 Rollout(上)与队列调度 Rollout(下)的对比。上方的同步模式中,GPU 必须等待最慢的任务(红色 X 标记为失败),产生大量空闲;下方的异步模式中,任务按先完成先处理的方式调度,GPU 利用率显著提升。
在更复杂的 Agentic RL 场景中,异步化需要更深层次的解耦。ROLL 框架将整个训练管线拆分为四个异步组件:
- 环境级异步 rollout:LLM 生成、环境交互与奖励计算各自独立,互不阻塞。
- 冗余并行环境:通过增加沙箱数量,避免单个慢环境成为全局瓶颈。
- 异步训练机制:rollout 与梯度更新在不同设备上并行推进。
- Train-Rollout 复用:通过时分复用(time-division multiplexing)让同一组 GPU 在推理和训练之间动态切换。
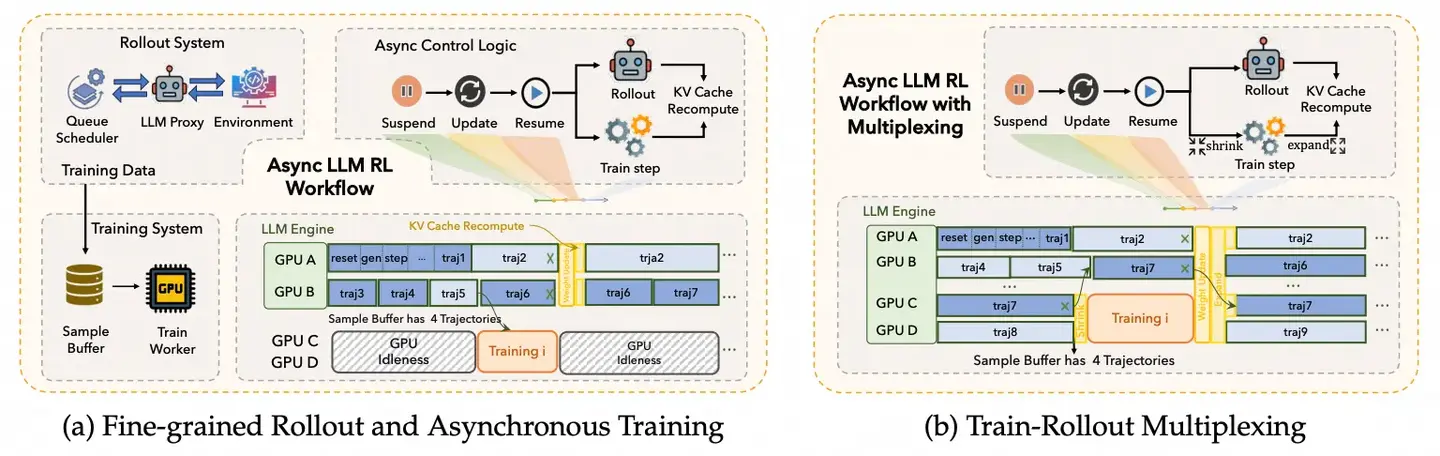
图 18-9:ROLL 框架的端到端异步训练管线。左侧为细粒度异步 rollout 与训练的解耦架构,右侧为 train-rollout 时分复用模式。
18.4.3 样本陈旧性的理论分析
异步管线带来了效率提升,但也引入了一个关键问题:样本陈旧性(sample staleness)。由于生成和训练并行进行,训练循环消费的样本可能是由若干步之前的旧策略生成的。模型参数已经更新了若干次,但用于计算损失的样本仍然基于旧策略的概率分布。
从策略梯度的角度看,标准的在线策略梯度为:
当样本由旧策略
这本质上是一个**离策略(off-policy)**问题——数据分布与当前策略不匹配。当
**重要性采样(importance sampling)**是校正分布偏移的标准工具。对每个样本引入重要性权重:
可以将离策略梯度校正为无偏估计。然而实践中,当
- 截断重要性采样(Truncated IS):
,将过大的权重裁剪到上限 。 - 遮蔽重要性采样(Masked IS):当
时直接令该样本权重为零,完全丢弃偏差过大的样本。
这两种策略对应了"有偏但低方差"与"无偏但丢弃信息"之间的取舍。
18.4.4 陈旧性控制:工程实践
在实际系统中,控制样本陈旧性需要算法与工程的双重手段。
最大陈旧度(max staleness)。 这是最直接的控制参数。每个样本在生成时记录当前的模型版本号(即已完成的权重更新次数),当训练循环消费该样本时,检查版本差值:
def should_discard(sample_version: int, current_version: int, max_staleness: int) -> bool:
"""判断样本是否因过度陈旧而应被丢弃。
Args:
sample_version: 生成该样本时的模型版本号
current_version: 当前模型版本号
max_staleness: 允许的最大版本差
Returns:
True 表示样本过于陈旧,应丢弃
"""
return (current_version - sample_version) > max_stalenessmax_staleness 的选择涉及效率与质量的权衡:值越大,允许更多样本被使用(减少浪费),但分布偏移越严重;值越小,样本越"新鲜",但可能导致大量生成的样本被丢弃。
在飞任务数(max inflight tasks)。 与 max_staleness 配合的另一个参数。它控制同时向推理引擎提交的请求数量。最优值应等于训练循环在样本变陈旧之前能消费的最大样本数:
其中
定期权重同步。 异步管线中,推理引擎使用的模型权重必须定期更新。训练侧每完成 weight_sync_steps 步梯度更新后,通过 NCCL 将最新权重传输到推理服务器。同步频率的选择同样是一个权衡:过于频繁会增加通信开销,过于稀疏会加剧样本陈旧性。
下面的伪代码展示了完整的异步训练循环控制逻辑:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import queue
import threading
class AsyncTrainingLoop:
"""异步训练循环的核心控制逻辑。"""
def __init__(self, model, inference_server, max_staleness=3, weight_sync_steps=1):
self.model = model
self.server = inference_server
self.max_staleness = max_staleness
self.weight_sync_steps = weight_sync_steps
self.sample_queue = queue.Queue(maxsize=1024)
self.current_version = 0
def rollout_worker(self, prompts):
"""后台线程:持续生成样本并推入队列。"""
for prompt in prompts:
completion = self.server.generate(prompt)
reward = compute_reward(completion)
advantage = compute_advantage(reward)
self.sample_queue.put({
"prompt": prompt,
"completion": completion,
"advantage": advantage,
"version": self.current_version, # 记录生成时的版本
})
def training_loop(self, total_steps):
"""主线程:从队列取样本并更新模型。"""
for step in range(total_steps):
# 从队列取样本,丢弃过于陈旧的
batch = []
while len(batch) < self.batch_size:
sample = self.sample_queue.get()
if not should_discard(sample["version"], self.current_version,
self.max_staleness):
batch.append(sample)
# 过于陈旧的样本被静默丢弃
loss = compute_grpo_loss(self.model, batch)
loss.backward()
self.model.step()
self.current_version += 1
# 定期同步权重到推理引擎
if self.current_version % self.weight_sync_steps == 0:
self.server.update_weights(self.model.parameters())18.4.5 TRL AsyncGRPO:实战参考
TRL 框架提供了 AsyncGRPOTrainer,将上述异步设计封装为开箱即用的训练器。它与标准 GRPOTrainer 实现相同的 GRPO 算法(优势计算、KL 估计、裁剪替代目标),但将 rollout 生成与训练循环解耦。
架构要求。 推理引擎(vLLM server)与训练进程必须运行在不同的 GPU 上。训练完成权重更新后,通过 NCCL 后端将参数传输到 vLLM 服务器,使后续生成反映最新策略。
以下是一个最小化的使用示例:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
# 终端 1:在 GPU 0 上启动 vLLM 推理服务器
# CUDA_VISIBLE_DEVICES=0 VLLM_SERVER_DEV_MODE=1 vllm serve Qwen/Qwen3-4B \
# --max-model-len 4096 \
# --logprobs-mode processed_logprobs \
# --weight-transfer-config '{"backend":"nccl"}'
# 终端 2:在 GPU 1 上启动训练
# CUDA_VISIBLE_DEVICES=1 accelerate launch train_async_grpo.py
from datasets import load_dataset
from trl.experimental.async_grpo import AsyncGRPOTrainer
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
trainer = AsyncGRPOTrainer(
model="Qwen/Qwen3-4B",
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()AsyncGRPOTrainer 的三个关键配置参数直接对应前文讨论的陈旧性控制机制:
| 参数 | 含义 | 默认行为 |
|---|---|---|
weight_sync_steps | 每隔多少训练步将权重同步到 vLLM 服务器 | 每步同步 |
max_staleness | 样本允许落后的最大权重更新次数 | 超过则丢弃 |
max_inflight_tasks | 同时提交给 vLLM 的最大请求数 | 自动计算为 |
表 18-4:AsyncGRPOTrainer 的核心陈旧性控制参数。
18.4.6 训练-推理不一致:另一种"陈旧性"
除了时间维度上的样本陈旧性,异步管线还面临一种更隐蔽的分布偏移来源:训练引擎与推理引擎的数值不一致。即使使用完全相同的模型权重,训练框架(如 PyTorch)和推理引擎(如 vLLM)在计算同一个 token 的概率时,可能给出不同的结果。
这种不一致源于两个引擎在精度格式和硬件优化上的不同取向:
- 推理引擎追求吞吐量最大化,通常采用低精度计算和硬件特化的 kernel,可能使用不同的浮点舍入策略。
- 训练引擎追求梯度计算的数值稳定性,通常保留更高精度的中间状态。
这种不一致将原本的在线策略问题转化为离策略问题。假设
即使
应对策略包括上文介绍的截断/遮蔽重要性采样,以及工程层面的优化——如在推理引擎中使用 FP32 语言模型头、确定性推理 kernel 等。
18.4.7 Agentic RL 中的端到端异步管线
在 Agentic RL 场景下,异步化的需求远比纯文本生成更为迫切,但设计也更复杂。核心挑战在于:
时间尺度的极端不均匀。 不同任务的 rollout 时间可能从几秒到几十分钟不等。一个"安装数据库并配置主从复制"的任务可能需要十几轮环境交互和数分钟执行时间,而一个"查找文件内容"的任务只需几秒。同步批处理模式下,快速任务必须等待慢速任务,导致 GPU 利用率可能低于 20%。
环境故障的不可预测性。 沙箱崩溃、网络超时、依赖安装失败等问题随机发生。在同步管线中,一个环境的故障会阻塞整个批次的训练更新。
多步交互的状态依赖。 与单轮生成不同,Agentic rollout 涉及多步"生成→执行→观察→再生成"的循环。整个轨迹的 LLM 生成、环境执行和奖励计算需要精心编排。
针对这些挑战,工业级 Agentic RL 系统通常采用以下设计原则:
- 先完成先入队:采用队列调度而非批处理,完成的轨迹立即入队参与训练,不等待同批次中的慢速任务。
- 冗余环境实例:启动多于所需数量的并行环境,使得个别环境的故障或延迟不会成为全局瓶颈。
- Mask & Filter 机制:对因环境故障而产生的异常轨迹进行遮蔽(梯度和奖励清零),避免噪声信号污染策略更新;对偶发超时等可恢复错误进行过滤(直接丢弃),并设置全局过滤比例上限(如 50%)防止数据不足。
- 细粒度解耦:将 LLM 推理、环境交互、奖励计算拆分为独立的异步组件,实现最细粒度的并行调度。
18.4.8 经验回放缓冲区:重用历史样本
除了实时生成的异步样本,另一种提升数据利用效率的技术是经验回放缓冲区(replay buffer)。在标准 GRPO 中,如果一个 prompt 的所有生成结果都获得相同的奖励(标准差为零),则该组样本无法提供有效的学习信号——优势值全部为零。
经验回放的核心思想是:将历史批次中高奖励且具有区分度的样本存入缓冲区,当当前批次出现零方差组时,用缓冲区中的高质量样本替换。这避免了"空转"训练步,确保每个训练步都能从有意义的对比信号中学习。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
class SimpleReplayBuffer:
"""简化版经验回放缓冲区。"""
def __init__(self, max_size=256):
self.buffer = []
self.max_size = max_size
def add(self, group):
"""存入高质量样本组(奖励标准差大于阈值)。"""
rewards = [s["reward"] for s in group]
# 只缓存有区分度且整体质量较高的组
if np.std(rewards) > 0.1 and np.mean(rewards) > 0.5:
self.buffer.append(group)
if len(self.buffer) > self.max_size:
self.buffer.pop(0) # FIFO 淘汰
def replace_if_needed(self, group):
"""如果当前组奖励无区分度,用缓冲区样本替换。"""
rewards = [s["reward"] for s in group]
if np.std(rewards) == 0 and len(self.buffer) > 0:
return self.buffer[np.random.randint(len(self.buffer))]
return group需要注意,回放样本同样面临陈旧性问题——它们由更早版本的策略生成,分布偏移可能更严重。因此缓冲区通常设置有限的容量,并采用 FIFO(先进先出)策略淘汰最旧的样本。
小结
本节围绕在线 RL 训练中的异步化和样本陈旧性两个核心问题展开了系统讨论。同步管线中生成与训练的串行交替导致 GPU 大量空闲,尤其在 Agentic RL 的长尾延迟场景下问题尤为突出。异步管线通过将生成与训练解耦为并行流程来解决效率瓶颈,但同时引入了样本陈旧性——数据由旧策略生成而当前策略已更新——这本质上是离策略学习问题。控制陈旧性的核心手段包括:设定最大陈旧度阈值丢弃过期样本、通过在飞任务数匹配生成与消费速率、定期同步权重到推理引擎、以及利用重要性采样校正分布偏移。TRL 的 AsyncGRPOTrainer 将这些设计封装为易用接口,而工业级 Agentic RL 系统(如 ROLL)则进一步实现了环境级解耦、冗余沙箱、Mask & Filter 等更细粒度的异步工程。理解并妥善管理"新鲜度与效率"之间的张力,是大规模在线 RL 训练工程化的关键一环。