21.8 Agent 工具与结构化输出
在 §21.4 中,我们介绍了 MCP 协议如何将 AI 应用与外部工具之间的集成复杂度从
本节将从三个层次回答这些问题。首先,我们深入结构化输出(Structured Output)的底层原理——基于有限状态机(FSM)的引导解码(Guided Decoding),以及其工程实现 xgrammar。然后,我们回到 §21.4.6 留下的伏笔,详细展开 MCP 即代码 API(MCP-as-Code-API)这一突破上下文瓶颈的工程方案。最后,我们讨论 Agent 系统上线后不可回避的问题——数据回流与评估体系。
21.8.1 结构化输出的核心原理:FSM 引导解码
回顾大语言模型的生成过程:模型在每一步输出一个 logits 向量,长度等于词表大小(通常数万维),每个维度对应一个 token 的未归一化概率。采样策略(greedy、top-k、top-p 等)从中选出下一个 token,拼接到已有序列后,继续生成。
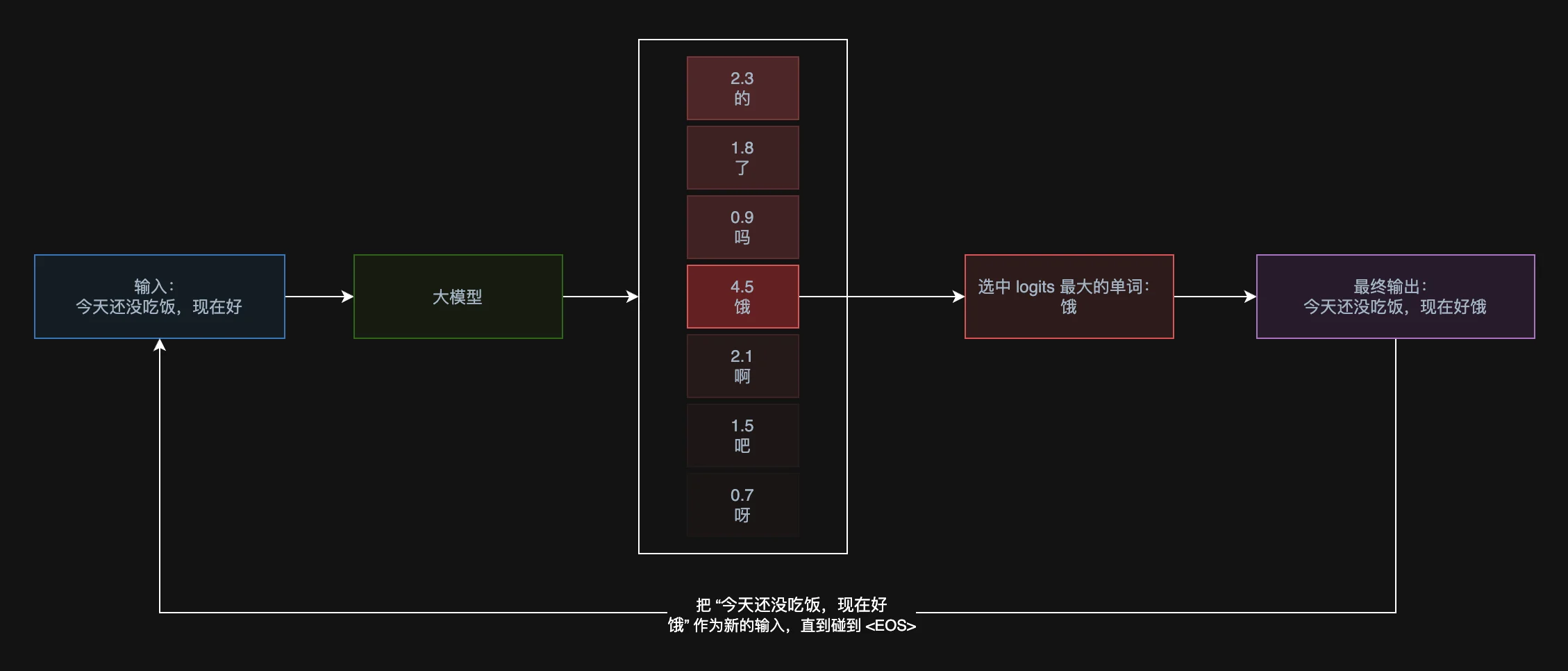
图 21-8a:大语言模型的自回归解码。输入"今天还没吃饭,现在好"后,模型输出一组 logits,选中概率最大的 token "饿",拼接后作为新的输入继续解码,直到遇到终止符 <EOS>。
这个过程有一个关键特征:模型对下一个 token 的选择是"软"的——它给出概率分布,但不保证任何格式约束。 如果我们希望模型输出合法的 JSON,模型可能在第 47 个 token 处输出一个多余的逗号,导致整个 JSON 解析失败。对于 Function Calling 这种必须精确到每个字符的场景,这是不可接受的。
FSM 引导解码(Finite State Machine Guided Decoding)的核心思想直截了当:将目标格式(JSON Schema、正则表达式、BNF 文法等)编译为等价的有限状态机,在每一步解码时,根据 FSM 的当前状态确定哪些 token 是"合法的下一步",然后将所有不合法 token 的 logits 设置为负无穷。这样,经过 softmax 归一化后,不合法 token 的概率为零,模型只能从合法 token 中选择。
用伪代码描述这一过程:
# FSM 引导解码的核心逻辑(伪代码)
def guided_decode(model, prompt, fsm):
"""
model: 大语言模型
prompt: 输入提示
fsm: 由目标格式编译而成的有限状态机
"""
state = fsm.initial_state # FSM 初始状态
tokens = tokenize(prompt)
while not fsm.is_accept_state(state):
# 1. 模型正常计算 logits
logits = model.forward(tokens)
# 2. 查询 FSM:当前状态下哪些 token 合法
valid_tokens = fsm.get_valid_tokens(state)
# 3. 将不合法 token 的 logits 设为负无穷
for i in range(len(logits)):
if i not in valid_tokens:
logits[i] = float('-inf')
# 4. 从过滤后的 logits 中采样
next_token = sample(logits)
tokens.append(next_token)
# 5. FSM 状态转移
state = fsm.transition(state, next_token)
return detokenize(tokens)这个方案的优雅之处在于:它不修改模型本身,只在采样阶段施加约束。 模型的权重、注意力机制、上下文理解能力完全不变,FSM 仅仅是在"最后一公里"——logits 到 token 的映射环节——过滤掉不合法的选项。这意味着结构化输出不需要额外的模型训练,任何已部署的模型都可以通过引导解码获得格式保证。
xgrammar:工业级 FSM 引导解码引擎
将"目标格式编译为 FSM"这一步在工程上并不简单。不同的格式(正则表达式、JSON Schema、BNF 文法)需要不同的编译策略,FSM 的状态数可能非常大,每步解码都需要快速查询合法 token 集合。这些挑战催生了 xgrammar——目前最主流的开源结构化解码引擎。
xgrammar 由 MLC 团队开发,已被 vLLM、SGLang、TensorRT-LLM 等主流大模型推理框架采用为默认的 Guided Decoding 后端。它的核心能力是将各种格式约束高效编译为 FSM,并在推理时以极低的开销执行 token 过滤。
21.8.2 四种约束类型:从选择题到形式文法
基于 FSM 引导解码的框架,vLLM 提供了四种开箱即用的约束类型,覆盖了从最简单到最复杂的结构化输出需求。
约束一:Choice(枚举选择)
最简单的约束——让模型从预定义的选项中做选择题。对应的 FSM 极其简单:初始状态出发,每个选项对应一条路径,路径上的每个 token 对应一次状态转移。
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
# 加载模型
llm = LLM(model="Qwen/Qwen2.5-1.5B-Instruct")
# 定义约束:模型只能输出 "yes" 或 "no"
params = GuidedDecodingParams(choice=["yes", "no"])
sampler = SamplingParams(guided_decoding=params)
prompt = "请问初音未来是真实的人类吗?请回答 yes 或 no。"
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
print(outputs[0].outputs[0].text)
# 输出:noChoice 约束看似简单,但在 Agent 系统中用途广泛:路由决策("需要调用工具吗?yes/no")、分类任务("这是 bug/feature/question?")、意图识别等场景都可以用它来消除模型输出的不确定性。
约束二:Regex(正则表达式)
正则表达式约束让模型的输出严格匹配指定的正则模式。FSM 的编译过程与编译原理中的正则-NFA-DFA 转换完全一致——先将正则表达式转换为非确定有限自动机(NFA),再通过子集构造法(Subset Construction)转换为确定有限自动机(DFA),最后在 DFA 上执行 token 过滤。
# 约束模型生成合法的邮箱地址
params = GuidedDecodingParams(regex=r"\w+@\w+\.com\n")
sampler = SamplingParams(guided_decoding=params, stop=["\n"])
prompt = "请帮我生成一个邮箱地址:"
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
print(outputs[0].outputs[0].text)
# 输出:Arya@Blacksmith.com正则表达式的表达能力足以覆盖大量实际场景:日期格式(\d{4}-\d{2}-\d{2})、电话号码、IP 地址、版本号等。对于这些场景,Regex 约束比 JSON Schema 更轻量高效。
约束三:JSON Schema
JSON 模式是结构化输出中最核心的约束类型,也是 Function Calling 的底层实现基础。当我们在 MCP Server 中定义工具的 inputSchema 时,本质上就是在定义一个 JSON Schema——引导解码器将这个 Schema 编译为 FSM,确保模型输出的 JSON 严格符合 Schema 定义的结构。
下面的例子展示了如何用 JSON Schema 约束来实现 Function Calling。假设我们有一个天气查询工具,其 Schema 定义了 name(工具名)和 parameters(参数)两个字段:
import json
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
def create_tool_decoder(tool_schemas):
"""根据工具 Schema 创建引导解码器"""
# 将多个工具的 Schema 组合为 anyOf 结构
combined = []
for schema in tool_schemas:
combined.append({
"type": "object",
"properties": {
"name": {
"type": "string",
"const": schema["function"]["name"]
},
"parameters": schema["function"]["parameters"]
},
"required": ["name", "parameters"]
})
full_schema = {
"type": "object",
"properties": {
"content": {"type": "string"},
"tool_calls": {
"type": "array",
"items": {"anyOf": combined}
}
},
"required": ["content"]
}
return SamplingParams(
guided_decoding=GuidedDecodingParams(json=full_schema),
temperature=0.3,
max_tokens=500
)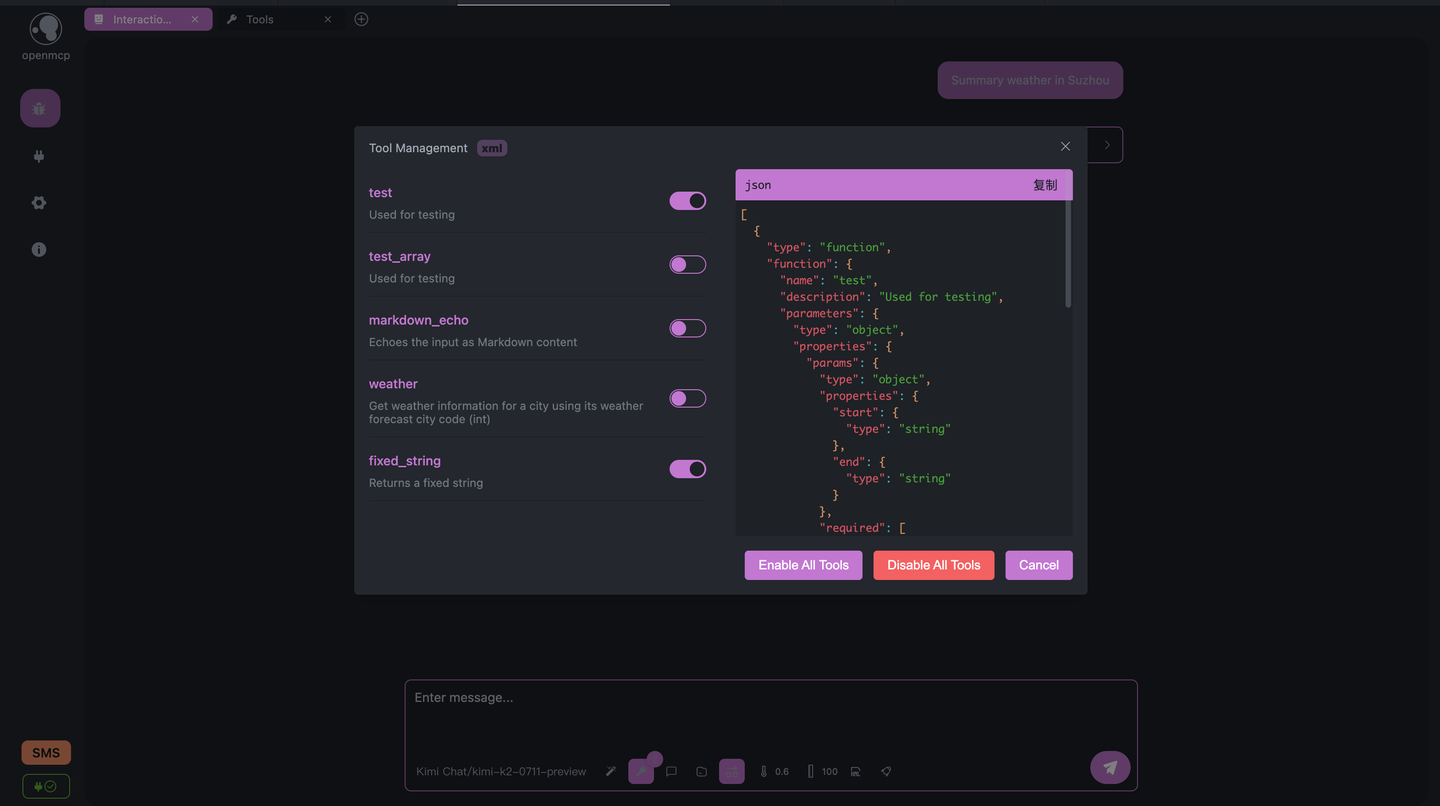
图 21-8b:MCP 客户端(OpenMCP)中的工具管理界面。左侧列出了当前连接的 MCP Server 提供的所有工具,右侧展示了选中工具的 JSON Schema。这个 Schema 将被传入引导解码器,确保模型输出严格符合工具的参数定义。
当模型接收到用户的问题"今天杭州天气如何?"时,引导解码器保证模型输出的每一个字符都不会违反 JSON Schema 的约束:
llm = LLM(model="Qwen/Qwen2.5-1.5B-Instruct")
# tool_schemas 来自 MCP Server 的 tools/list 响应
sampler = create_tool_decoder(tool_schemas)
prompt = "今天杭州天气如何?你应该通过调用工具来解决这个问题"
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
result = json.loads(outputs[0].outputs[0].text)
print(json.dumps(result, ensure_ascii=False, indent=2))输出:
{
"content": "今天杭州天气如何?",
"tool_calls": [
{
"name": "weather",
"parameters": {
"city_code": 101010100
}
}
]
}这就是 Function Calling 的底层原理:MCP Client 从 Server 获取工具的 JSON Schema,将其编译为 FSM,在模型解码时实施约束,保证模型输出的 tool_calls 字段可以被直接解析并执行。 理解了这一点,Function Calling 就不再是一个神秘的"模型能力",而是一个可以在任何模型上复现的工程实现。
约束四:Grammar(BNF 文法)
Grammar 约束是表达能力最强的类型,它接受巴科斯-诺尔范式(Backus-Naur Form, BNF)作为输入。学过编译原理的读者应该知道,BNF 可以描述任何上下文无关语言——这意味着你理论上可以约束模型输出 100% 符合 Python、SQL、C++ 等编程语言词法和语法规则的代码。
# 用 BNF 约束模型生成合法的 SQL 查询
simplified_sql_grammar = """
root ::= select_statement
select_statement ::= "SELECT " column " from " table " where " condition
column ::= "col_1 " | "col_2 "
table ::= "table_1 " | "table_2 "
condition ::= column "= " number
number ::= "1 " | "2 "
"""
param = GuidedDecodingParams(grammar=simplified_sql_grammar)
sampler = SamplingParams(
guided_decoding=param,
temperature=0.3,
max_tokens=500
)
prompt = "Generate an SQL query to show the username and email."
outputs = llm.generate(prompts=prompt, sampling_params=sampler)
print(outputs[0].outputs[0].text)
# 输出:SELECT col_1 from table_1 where col_2 = 1Grammar 约束虽然强大,但实际使用中需要权衡:编写完整的 BNF 文法是一项专业且繁琐的工作,对于大多数 Agent 场景,JSON Schema 已经足够。Grammar 更适合需要精确控制代码生成格式的专用场景,如 Text-to-SQL、DSL(领域特定语言)生成等。
四种约束类型的表达能力和使用成本可以概括为:
| 约束类型 | 表达能力 | 使用难度 | 典型场景 |
|---|---|---|---|
| Choice | 最低(有限枚举) | 最简单 | 路由决策、分类、是非判断 |
| Regex | 中低(正则语言) | 简单 | 格式化字符串、表单验证 |
| JSON | 中高(结构化数据) | 中等 | Function Calling、API 响应 |
| Grammar | 最高(上下文无关语言) | 较难 | 代码生成、DSL、SQL |
21.8.3 API 侧的结构化输出
上面讨论的方案都假设你能够直接控制模型的推理后端(如使用 vLLM 本地部署)。但对于通过 API 调用云端模型的场景呢?你无法直接操作 logits,那结构化输出还能实现吗?
答案是可以,但自由度受限。主流方案有三种。
方案一:JSON Output 模式。 部分 API 提供商(如 DeepSeek、OpenAI)支持在请求中设置 response_format 参数,指定输出为 JSON 格式。这本质上是提供商在后端为你运行了 JSON Schema 引导解码。
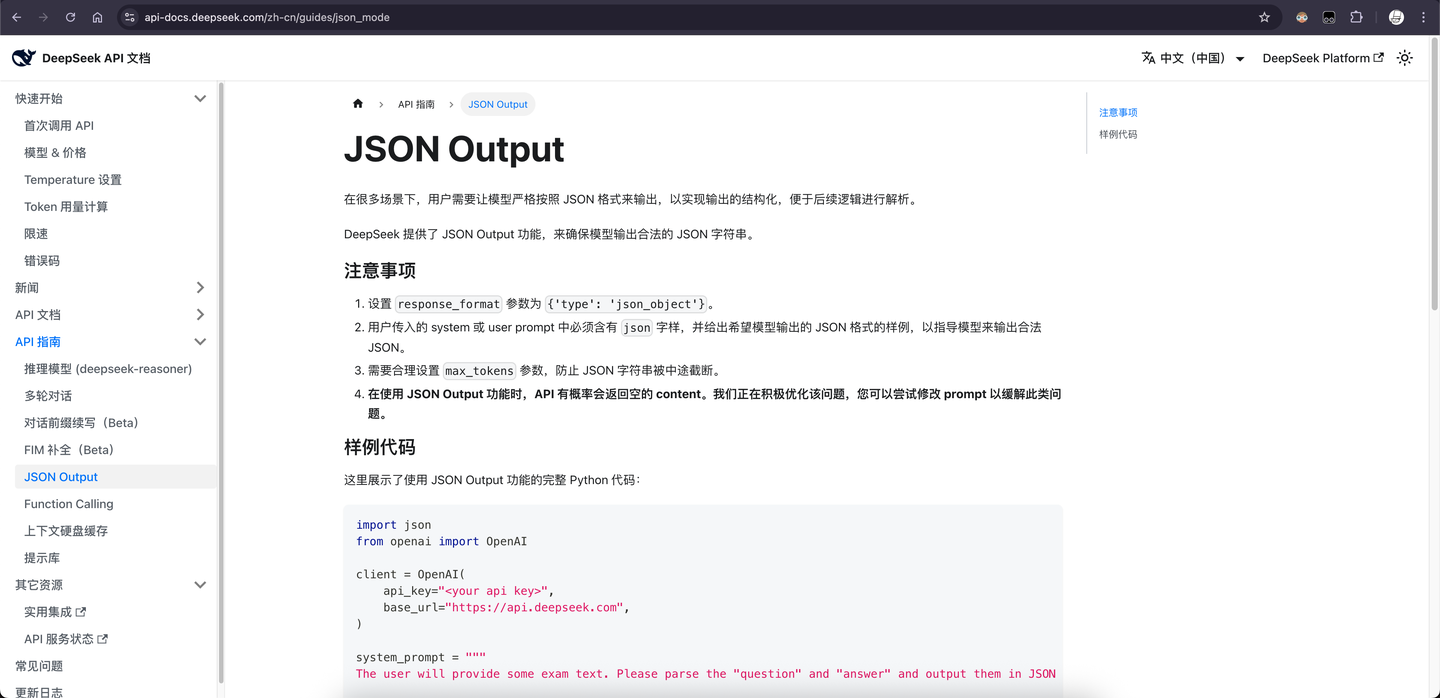
图 21-8c:DeepSeek API 文档中的 JSON Output 功能说明。通过设置 response_format 参数,可以让模型输出严格符合 JSON 格式的文本。这一功能的底层实现正是我们在上文讨论的 FSM 引导解码。
方案二:logit_bias 参数。 OpenAI 协议中定义了 logit_bias 参数,允许调用方对特定 token 的 logits 施加偏移。这是一种"软约束"——它增加或降低某些 token 被选中的概率,但不能保证绝对的格式正确性。
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "Is water wet?"}],
max_tokens=1,
logit_bias={"yes": 1000, "no": 1000},
temperature=0.1
)
print(response.choices[0].message.content.lower())logit_bias 是一种轻量的概率调控手段,但它无法替代 FSM 引导解码的硬约束。如果模型的"真实倾向"与偏置方向相悖太远,输出仍可能偏离预期。
方案三:借助 Function Calling 实现。 这是最通用的方案——大部分 API 提供商都实现了 Function Calling,而 Function Calling 本身就是基于 JSON Schema 引导解码实现的。因此,我们可以"借壳":定义一个虚拟函数,其参数结构就是我们希望模型输出的数据结构,然后从模型返回的 tool_calls 中提取参数。
社区中的 instructor 库将这一模式封装得非常优雅:
import instructor
from pydantic import BaseModel
from enum import Enum
# 定义期望的输出结构
class Category(str, Enum):
PHILOSOPHY = "哲学"
LITERATURE = "文学"
SCIENCE = "科学"
TECHNOLOGY = "技术"
class Book(BaseModel):
name: str
category: Category
isbn: str
# instructor 自动将 Pydantic 模型转换为 Function Calling Schema
client = instructor.from_provider(
"deepseek/deepseek-chat",
api_key="your-api-key"
)
response = client.chat.completions.create(
response_model=Book,
messages=[{"role": "user", "content": "帮我生成随机一本书的信息"}],
)
print(response)
# 输出:name='随机书籍' category=<Category.PHILOSOPHY: '哲学'> isbn='978-3-16-148410-0'instructor 的精妙之处在于:用户只需定义 Pydantic 数据模型,库自动完成"模型 → JSON Schema → Function Calling 请求 → 响应解析 → 类型化对象"的全链路转换。对于熟悉 ORM 框架的开发者来说,这种体验非常自然。
21.8.4 MCP 即代码 API:突破上下文瓶颈
在 §21.4.6 中,我们指出了 MCP 的核心局限之一:工具定义占满上下文窗口。 每个工具的描述(名称、说明、参数 Schema)动辄数百到数千 token。当 Agent 连接 20 个 MCP Server、每个 Server 提供 10-50 个工具时,仅工具定义就可能消耗超过 150,000 个 token——这几乎占满了大多数模型的上下文窗口,留给实际任务推理的空间所剩无几。
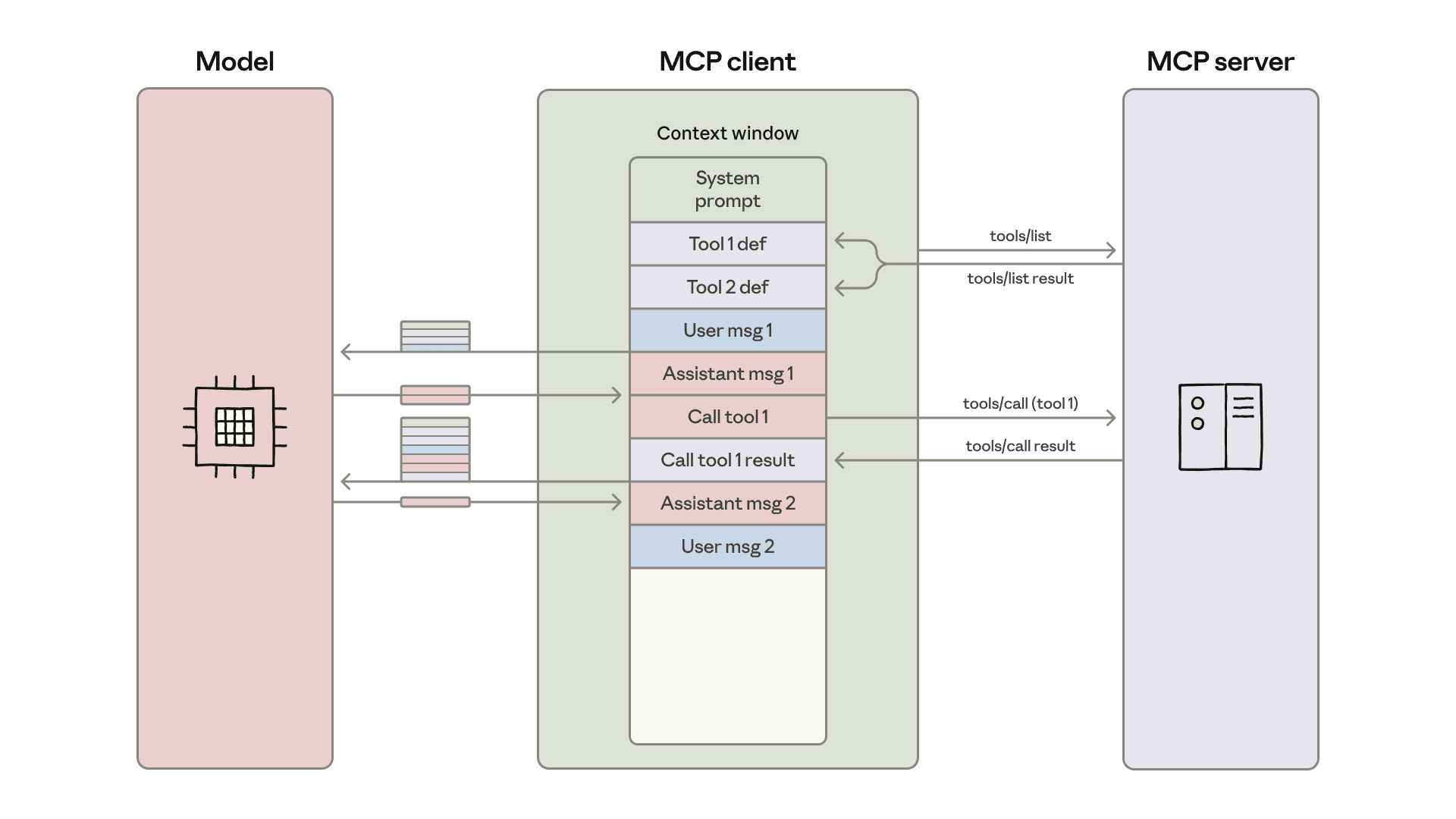
图 21-8d:传统 MCP 交互模式下的上下文膨胀。MCP Client 通过 tools/list 获取所有工具定义并注入 Context Window,随着连接的 Server 和工具数量增加,工具定义迅速占满上下文空间。
Anthropic 工程团队提出的 MCP 即代码 API(MCP-as-Code-API)方案从根本上改变了 Agent 与工具的交互模式。其核心思想是:不再将所有工具定义一次性塞入上下文,而是让 Agent 通过编写代码来按需发现和调用工具。
具体实现分为三个步骤:
第一步:生成文件树。 系统根据连接的 MCP Server 自动生成一棵虚拟文件树,每个 Server 对应一个目录,每个工具对应一个代码模块文件。文件树只包含工具名称和简短的一行描述,不包含完整的参数 Schema。
mcp_tools/
├── github/
│ ├── search_code.ts # Search code across repositories
│ ├── create_issue.ts # Create a new issue in a repository
│ ├── create_pr.ts # Create a pull request
│ └── list_commits.ts # List commits in a repository
├── filesystem/
│ ├── read_file.ts # Read contents of a file
│ ├── write_file.ts # Write contents to a file
│ └── list_directory.ts # List directory contents
└── postgres/
├── query.ts # Execute a SQL query
└── list_tables.ts # List all tables in database第二步:按需加载。 当 Agent 需要使用某个工具时,它像程序员浏览代码库一样,先探索文件树找到相关工具,然后"打开"对应的文件,此时才加载该工具的完整 Schema(包括参数定义、类型约束、描述等)。
// Agent 生成的代码示例
import { searchCode } from "./mcp_tools/github/search_code";
// 只有在实际需要调用时,才加载 search_code 的完整 Schema
const results = await searchCode({
query: "authentication middleware",
repo: "my-org/backend",
language: "python"
});
// 在执行环境中过滤结果,只返回关键信息给模型
const summary = results
.filter(r => r.score > 0.8)
.map(r => `${r.path}: ${r.snippet}`)
.join("\n");第三步:代码执行。 Agent 编写的代码在一个隔离的执行环境中运行。工具调用的返回结果先在执行环境中被处理(过滤、转换、聚合),只有精炼后的结果才被注入模型上下文。
这种方案带来了三个关键优势:
上下文节省。 传统方案需要将全部工具 Schema 注入上下文(约 150,000 token),MCP-as-Code-API 只需注入文件树索引(约 2,000 token),节省了 98.7% 的 token 开销。Agent 只在需要时按需加载个别工具的 Schema,且用完即释放。
数据隐私。 工具返回的原始数据(可能包含敏感信息)在执行环境中被处理和过滤,只有经过脱敏或聚合后的结果才进入模型上下文。敏感数据全程不暴露给模型。
复杂逻辑编排。 Agent 可以在代码中使用循环、条件分支、异常处理等编程结构来编排多个工具调用。例如"遍历所有仓库,对每个仓库检查最近的 commit,如果发现安全漏洞则创建 Issue"——这种逻辑在传统的逐步工具调用模式中需要多轮模型推理,而在代码执行模式中只需一次性生成代码即可完成。
技能沉淀。 这是 MCP-as-Code-API 一个常被忽略但极有价值的附加收益。Agent 成功完成的代码片段可以被保存为可复用的函数——类似于 Voyager(§21.1)的技能库(Skill Library)。下次遇到相似任务时,Agent 可以直接调用已沉淀的"技能",而不需要重新推理和编写代码。Agent 由此建立起一个不断进化的"高级能力工具箱"。
从架构视角看,MCP-as-Code-API 本质上是将 §21.6 Context Engineering 中讨论的"文件系统即上下文"策略应用到了工具管理领域:将海量工具定义卸载到文件系统中,上下文中只保留轻量的索引,按需检索。这进一步印证了一个通用原则:在 Agent 系统中,一切可以不放在上下文里的信息,都不应该放在上下文里。
21.8.5 数据回流与 Agent 评估体系
结构化输出解决了"Agent 如何正确调用工具"的问题,MCP-as-Code-API 解决了"Agent 如何高效管理大量工具"的问题。但 Agent 系统上线后,一个更根本的问题浮现了:你怎么知道它工作得好不好?
传统软件测试可以通过确定性的单元测试、集成测试来覆盖大部分场景。但 Agent 系统的特殊之处在于:模型的行为是概率性的,相同的输入在不同时间、不同模型版本下可能产生不同的输出。一个"通过测试"的 Agent 上线后,可能因为 API 提供商更新了模型权重而突然表现退化。
因此,Agent 的质量保证不能依赖于一次性测试,而需要 持续的数据回流(Data Reflux)和系统化的评估指标。在明确了架构特性和需求边界之后,Agent 的开发难度本身并不高,真正的难点在于验证。保持对线上 Agent 数据的持续采集,既能支撑后续的自动化 Prompt 工程(Auto-PE),也能为模型后训练构建 RLVR(Reinforcement Learning with Verifiable Rewards)训练集。
以下六个指标构成了 Agent 评估的基本框架:
1. Success Rate(任务成功率)
最直接的指标。定义明确的"成功"标准(如 Function Calling 参数正确且工具执行无报错),统计 Agent 完成任务的成功比例。这个指标是所有其他指标的基础——如果成功率本身不高,优化其他维度没有意义。
需要注意的是,"成功"的定义本身需要精心设计。对于确定性任务(如查询天气),可以通过比对返回值来判断。但对于开放式任务(如"帮我写一封邮件"),可能需要引入 LLM-as-a-Judge 来评判质量。
2. LLM Sensitivity(模型敏感性)
相同的 Agent 系统,底层模型从 GPT-4o 切换到 Claude Sonnet、再切换到 DeepSeek-V3,任务成功率会有多大波动?如果波动很大,说明 Agent 的架构设计过度依赖特定模型的特性(如特定的 System Prompt 格式、特定的 Function Calling 实现),可移植性差。
理想的 Agent 架构应当对底层模型具有一定的鲁棒性——核心逻辑不应该因为模型切换而崩溃。LLM Sensitivity 指标帮助开发者识别这些脆弱点。
3. Prompt Sensitivity(提示敏感性)
将用户指令进行同义词替换后(如"查一下北京天气"→"帮我看看北京今天天气怎么样"),Agent 的执行结果是否一致?如果替换后 Agent 无法正确识别意图或选错工具,说明系统的自然语言理解能力不够鲁棒,过度依赖关键词匹配而非语义理解。
4. Hallucination Rate(幻觉率)
这里的"幻觉"特指工具调用场景下的幻觉:当系统明确告知某些信息不可知时,模型是否会对工具参数进行臆造? 例如,用户问"纽约天气",但系统工具只支持中国城市。正确的行为是报告"无法处理该请求",而非在 city_code 参数中填入一个虚构的编码。
幻觉率是 Agent 可信度的核心衡量。一个高幻觉率的 Agent 不如一个会说"我不知道"的 Agent——后者至少不会产生误导性的执行结果。
5. Scalability(可扩展性)
随着可用工具数量的增长(从 5 个到 50 个到 500 个),相同任务的执行结果是否会退化?模型是否仍能在大量工具中准确选择正确的那一个?
这个指标直接关联 §21.8.4 讨论的上下文瓶颈问题。在传统的全量注入方案中,Scalability 通常在工具数超过一定阈值后急剧恶化。MCP-as-Code-API 方案在理论上缓解了这一问题,但"Agent 能否从文件树中准确找到需要的工具"这个新的能力维度仍需评估。
6. Autonomy(自主性)
模型是否会主动调用工具来完成任务,还是需要用户在 Prompt 中明确指示"请通过调用工具来解决"?自主性越高,用户体验越自然——用户不应该需要"教"Agent 去使用工具。
自主性与模型规模高度相关。在 §21.8.2 的 JSON 约束示例中我们提到,小模型(如 Qwen2.5-1.5B)往往需要额外的引导词才会尝试调用工具,而大模型(如 GPT-4o、Claude Sonnet)通常能自主判断何时需要工具辅助。
构建 Evaluator 系统
上述六个指标需要一套系统化的 Evaluator 来持续监控。与传统软件测试的 test suite 不同,Agent 的 Evaluator 本身也可以是一个 Agent——利用 LLM-as-a-Judge 来评判另一个 Agent 的行为质量。这使得评估系统具备了处理开放式、非确定性任务的能力,但也引入了新的挑战:评估者自身的可靠性如何保证?
一种务实的做法是分层评估:确定性指标(成功率、幻觉率)用传统的规则匹配和断言检查;模糊性指标(输出质量、用户体验)用 LLM-as-a-Judge;所有评估结果持续写入日志系统,支持按时间、按模型版本、按任务类型的多维分析。数据回流的价值不仅在于发现当前问题,更在于为后续的自动化 Prompt 优化和模型微调提供高质量的训练信号。
本节小结。 本节从三个层面讨论了 Agent 工具使用的核心工程问题。首先,结构化输出通过 FSM 引导解码在模型采样阶段施加格式约束,xgrammar 作为工业级后端支持 Choice/Regex/JSON/Grammar 四种约束类型,从最简单的选择题到最复杂的形式文法全覆盖。其次,MCP-as-Code-API 通过文件树发现和按需加载策略,将工具定义的上下文开销从约 150K token 压缩到约 2K token,同时带来数据隐私保护和技能沉淀等附加收益。最后,Agent 系统的质量保证不能依赖一次性测试,而需要围绕成功率、模型敏感性、提示敏感性、幻觉率、可扩展性和自主性六个维度建立持续的数据回流和评估体系。这三者共同构成了 Agent 工具使用从"能用"到"好用"再到"可信赖"的完整工程链路。