6.7 注意力技术对比总表
前面六节分别拆解了 KV Cache、GQA、MLA、滑动窗口注意力、MoE 和 Gated DeltaNet 的原理与实现。单独看每项技术各有亮点,但工程实践中的真正难题是选型——面对具体的模型规模、部署场景和硬件预算,应该组合哪些技术?本节先给出总表,再从计算复杂度、KV 缓存和建模能力三个维度展开分析,最后给出场景选型建议。
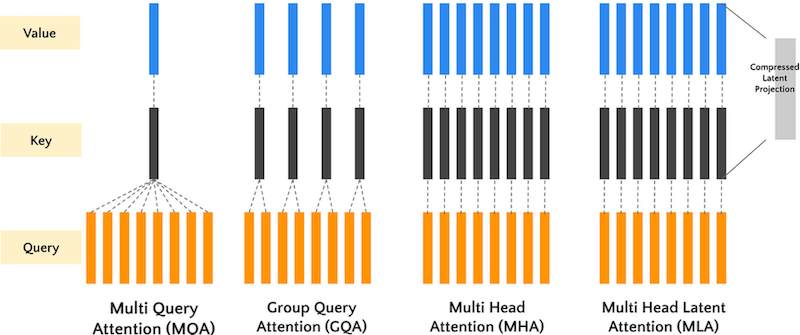
图 6-24:各种注意力优化技术的整体对比。从 MHA 到 GQA、MLA、SWA 和线性注意力,每种技术在内存效率和建模能力上各有权衡。
6.7.1 总表
| 技术 | 计算复杂度 | KV 缓存(相对 MHA) | 代表模型 | 核心取舍 |
|---|---|---|---|---|
| MHA | 基线 | GPT-2/3 | 表达力最强,缓存与计算开销最高 | |
| GQA | 减少约 75% | Llama 2/3、Qwen2.5/3 | 几乎不损精度,当前最主流方案 | |
| MLA | 减少 75%+ | DeepSeek-V2/V3/R1 | 极致压缩缓存,但实现复杂度高 | |
| SWA | 固定(不随 | Gemma 3、OLMo 2 | 缓存恒定,但无法直接访问窗口外信息 | |
| MoE | 不影响(作用于 FFN) | DeepSeek-V3、Qwen3-MoE | 扩展容量而非优化注意力,与上述技术正交 | |
| DeltaNet | 常数( | Qwen3-Next、Kimi Linear | 消除二次方开销,但精确检索能力弱于 Softmax |
符号:
6.7.2 计算复杂度分析
二次方阵营 vs. 线性阵营。 MHA、GQA、MLA 同属
SWA 将注意力限定在宽度
Gated DeltaNet 对
MoE 不改变注意力复杂度,而是将 FFN 层(通常占总计算量 60-70%)的激活参数降至
6.7.3 KV 缓存分析
缓存是长序列推理的核心瓶颈。 以 70B MHA 模型(80 层、64 头、头维度 128、BF16)处理 32K 序列为例,KV 缓存约为:
这已超过单张 A100-80G 的全部显存。压缩 KV 缓存不是锦上添花,而是让长序列推理成为可能的前提。
GQA 将 KV 头数降至
MLA 将所有头的 KV 联合投影到低维向量
SWA 的缓存恒定为
Gated DeltaNet 仅维护每头
MoE 与缓存的间接关系。 MoE 不直接影响 KV 缓存,但 MoE 模型通常参数总量大、层数多,若注意力层用 MHA 则缓存极为可观。因此 MoE 几乎总与 GQA 或 MLA 搭配——DeepSeek-V3 选择 MLA + MoE,Qwen3-MoE 选择 GQA + MoE。
6.7.4 建模能力权衡
GQA 的精度损失。 多个 Query 头共享 KV 等价于施加对称性约束,限制了不同头学习差异化注意力模式的自由度。在
MLA 的低秩正则化效应。 压缩维度
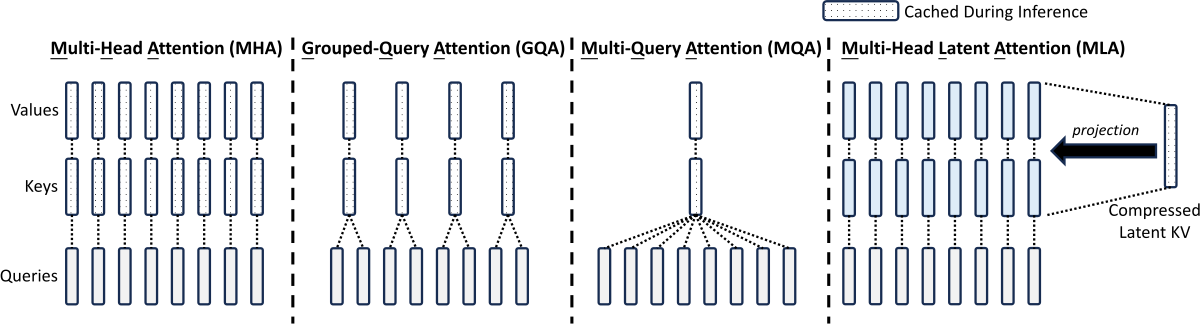
图 6-25:MHA、GQA 和 MLA 的注意力头结构对比。MHA 每个头独立拥有 KV,GQA 多头共享 KV 组,MLA 通过低维潜向量压缩所有头的 KV。
SWA 的信息可达性限制。 窗口外 token 完全不可见。虽然经过
Softmax → DeltaNet 的根本变化。 Softmax 通过尖峰特性实现任意精细的选择性关注,而线性注意力以"叠加"方式存储历史——类似全息图,所有信息叠加在同一张底片上,检索时引入干扰。在 needle-in-a-haystack 等精确检索任务上差距明显,这是当前所有生产模型都采用混合架构而非纯线性的根本原因。
6.7.5 场景选型建议
场景一:通用预训练(7B-70B)。 推荐 GQA + MoE。GQA 成熟度最高,vLLM、TensorRT-LLM、SGLang 均有深度优化;MoE 在不增加单 token 计算量的前提下扩展容量。这一组合已被 Llama 3、Qwen2.5-MoE、Mixtral 等模型验证。追求极致缓存压缩且有 kernel 开发能力的团队可选 MLA + MoE(DeepSeek-V3 路线)。
场景二:超长上下文(128K+)。 推荐 SWA/全局混合 + GQA。SWA 层大幅降低平均开销,全局层每 5-6 层插入一个作为信息锚点(Gemma 3 方案)。进一步延伸到 1M+ 上下文且可容忍一定检索精度损失时,可考虑混合线性注意力架构(少量 Softmax 层 + 大量 DeltaNet 层)。
场景三:边缘部署(手机/端侧)。 推荐 GQA(大
场景四:流式对话。 重点关注 Decode 阶段延迟。Decode 是内存带宽瓶颈,KV 缓存越小每步读取数据越少。GQA/MLA 压缩缓存大小,SWA 限制每步读取条目数,DeltaNet 每步仅读写
6.7.6 组合案例
上述技术并非互斥,实际模型通常组合使用。下表列出代表性案例:
| 模型 | 注意力 | FFN | 组合策略 |
|---|---|---|---|
| Llama 3 70B | GQA( | 稠密 SwiGLU | 最简方案,仅用 GQA 压缩缓存 |
| DeepSeek-V3 | MLA | MoE(256 专家,top-8) | 极致压缩 + 极致容量 |
| Gemma 3 27B | SWA + 全局交替 | 稠密 | 长序列优化,全局层作信息锚点 |
| Qwen3-Next | GQA + DeltaNet 混合 | 稠密 | 线性层为主,Softmax 层保底 |
没有任何一种技术是"银弹"。真实的选型是在精度、效率、工程复杂度和硬件适配之间寻找平衡点,这些技术提供了一个丰富的工具箱,允许工程师根据约束条件自由组合。
6.7.7 总结
GQA 是当前默认选择。 实现简单、生态成熟、精度损失可忽略,除非有明确理由否则优先考虑。
MLA 缓存压缩更极致,但工程门槛高。 适合有 kernel 开发资源的大团队,门槛随开源实现成熟正在降低。
SWA 是长序列的重要补充,不宜单独使用。 与全局注意力层混合部署是标准做法,全局层间隔频率是关键超参数。
MoE 与注意力优化正交。 解决容量问题而非注意力效率问题,可与任何方案自由搭配。
线性注意力代表未来方向,但尚未成为主流。 精确检索短板使纯线性架构不可行,混合架构是过渡方案。
选型核心框架:先确定硬约束(显存、延迟、序列长度),再在满足约束的方案中选工程复杂度最低的。 一个深度优化过的 GQA 实现,往往比未充分优化的 MLA 实现在实际部署中表现更好。