3.7 Vision Transformer(ViT)
在前面的章节中,我们系统介绍了 Transformer 架构及其在自然语言处理中的核心组件。一个自然的问题是:这套基于自注意力的架构能否迁移到计算机视觉领域?2020 年,Dosovitskiy 等人在论文 "An Image is Worth 16x16 Words" 中给出了肯定的回答——Vision Transformer(ViT) 以一种极简的方式将图像转化为序列,直接复用标准 Transformer 编码器完成图像分类任务,在大规模数据集上取得了超越卷积神经网络(CNN)的性能。
ViT 的核心洞察在于:如果将图像切分为固定大小的补丁(patch),每个补丁就可以类比为自然语言中的一个词元(token)。有了这个对应关系,处理图像就转化为处理序列——Transformer 架构无需任何结构性修改即可直接应用。这一思路看似简单,却对计算机视觉产生了深远影响,也为后来的多模态大模型奠定了视觉编码的基础。
3.7.1 CNN 的归纳偏置与局限
在 ViT 出现之前,卷积神经网络(CNN)是计算机视觉的主导架构。CNN 的成功源于两个核心归纳偏置(inductive bias):
- 局部性(Locality):卷积核在小的空间邻域上滑动,天然假设相邻像素之间的关联最为密切。这使得 CNN 能够以极少的参数高效提取边缘、纹理等局部特征。
- 平移不变性(Translation Invariance):同一卷积核在整张图像上共享参数,意味着无论目标出现在图像的哪个位置,模型都能以相同的方式检测它。
这两个归纳偏置在数据量有限时是极强的先验知识,帮助 CNN 在 ImageNet 等基准上取得了长期统治地位。然而,它们也带来了三个核心局限:
- 感受野受限:单个卷积层的感受野仅覆盖卷积核大小的区域。要捕捉远距离的空间关系,必须堆叠大量卷积层,导致信息在逐层传递中衰减或失真。
- 全局建模能力不足:CNN 优先建模局部关系,对图像中远距离像素之间的直接依赖(如遮挡关系、物体间的相对大小)缺乏高效的捕捉机制。
- 模型扩展性差:CNN 架构通常需要精心手工设计(如 VGG、ResNet 等逐步加深的分阶段结构),简单地增加深度或宽度会遭遇优化困难和性能瓶颈,扩展效率远不如 Transformer 在 NLP 中展现的规模律(scaling law)。
ViT 的出发点正是:能否用 Transformer 的全局自注意力机制来弥补 CNN 在全局建模和模型扩展性上的不足?
3.7.2 ViT 的整体架构
ViT 的架构由三个模块组成:补丁嵌入层(Patch Embedding)、Transformer 编码器和分类头(Classification Head)。
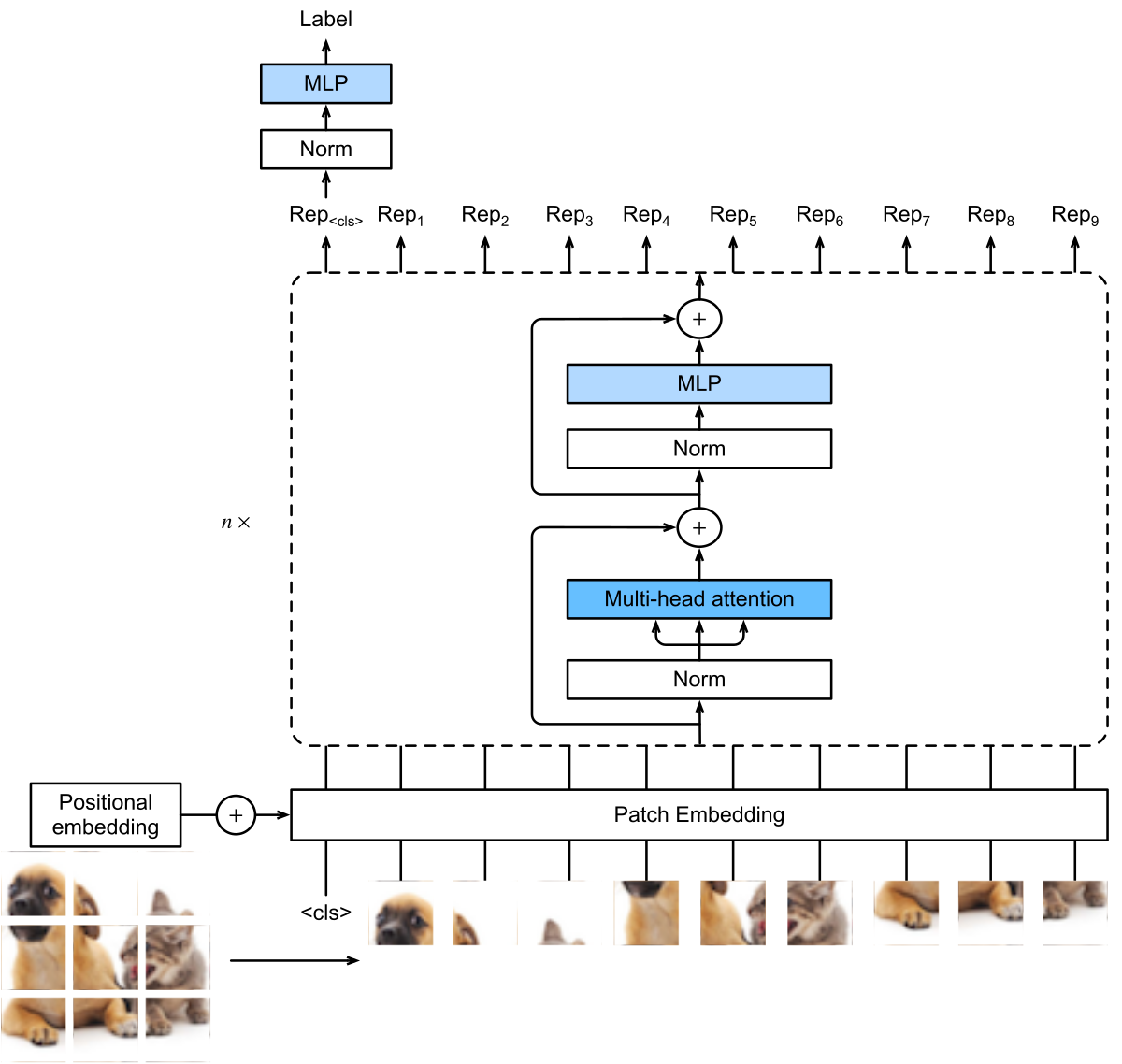
图 3-13:ViT 的完整架构。输入图像被分割为固定大小的补丁,每个补丁经线性投影后与一个特殊的 <cls> token 拼接,加上可学习的位置编码后送入 <cls> token 对应的输出经过层归一化和全连接层映射为分类标签。
具体流程如下:
- 图像分块:给定一张高
、宽 、通道数为 的输入图像,将其均匀切分为大小 的不重叠补丁,共得到 个补丁。 - 补丁嵌入:每个补丁被展平为一个
维向量,再通过一个可学习的线性投影映射到 维嵌入空间。 - 添加
<cls>token 与位置编码:在补丁嵌入序列的开头拼接一个可学习的维向量( <cls>token),然后对全部个向量加上可学习的位置编码。 - Transformer 编码器:将上述
个向量送入 层标准 Transformer 编码器。ViT 采用 Pre-Norm 结构,即在多头自注意力和 MLP 之前各施加一次层归一化,MLP 中使用 GELU 激活函数。 - 分类输出:取编码器最后一层中
<cls>token 对应位置的输出向量,经过层归一化和全连接层后得到最终的分类 logits。
3.7.3 补丁嵌入的数学形式与实现
补丁嵌入是 ViT 中将二维图像转化为一维序列的关键步骤。
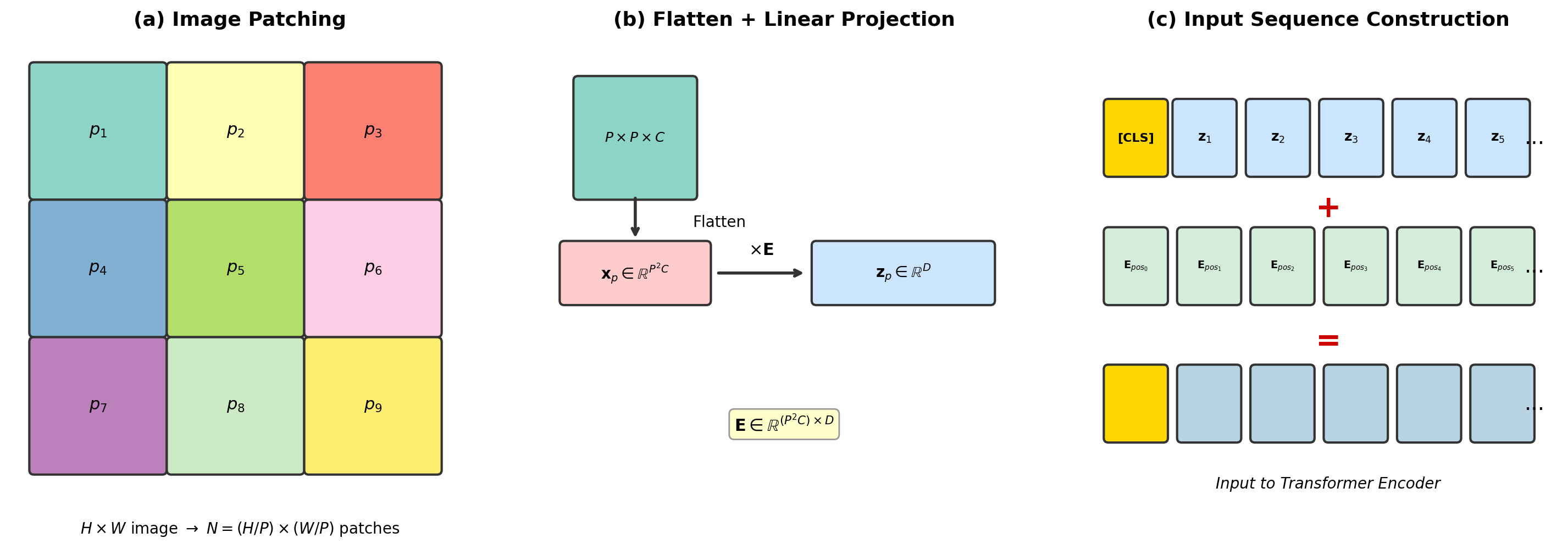
图 3-14:补丁嵌入的三步流程。(a) 将 [CLS] token,加上位置编码后构成 Transformer 编码器的输入。
数学形式。 设输入图像为
其中:
为可学习的线性投影矩阵,将每个展平的补丁从 维映射到 维; 为可学习的类别 token 向量; 为可学习的位置编码矩阵; 表示沿序列维度的拼接。
最终
实现技巧:用卷积等效实现补丁嵌入。 将图像切分为补丁、展平、线性投影这三步操作,等价于一个卷积核大小和步幅都等于补丁大小
以下是补丁嵌入的 PyTorch 实现:
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
"""将图像切分为补丁并投影到嵌入空间。
利用卷积操作等效实现"分块 + 展平 + 线性投影"。
Args:
img_size: 输入图像的边长(假设正方形),默认 224
patch_size: 补丁的边长,默认 16
in_channels: 输入图像的通道数,默认 3(RGB)
embed_dim: 嵌入维度 D,默认 768
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
embed_dim: int = 768,
):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
# 卷积核大小 = 步幅 = patch_size,等效于分块 + 线性投影
self.proj = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size,
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: (batch_size, C, H, W)
Returns:
(batch_size, num_patches, embed_dim)
"""
# proj 输出: (B, D, H/P, W/P) -> 展平空间维度 -> 转置
return self.proj(x).flatten(2).transpose(1, 2)代码解读。 nn.Conv2d 的卷积核大小和步幅均设置为 patch_size,因此输出特征图的空间尺寸恰好为 flatten(2) 将高和宽两个空间维度合并,transpose(1, 2) 将形状从
3.7.4 完整 ViT 的 PyTorch 实现
在补丁嵌入的基础上,完整的 ViT 实现还需要 <cls> token、位置编码、Transformer 编码器块和分类头。以下代码给出了一个自包含的实现:
class ViTMLP(nn.Module):
"""ViT 编码器中的前馈网络,使用 GELU 激活。"""
def __init__(self, embed_dim: int, mlp_dim: int, dropout: float = 0.1):
super().__init__()
self.fc1 = nn.Linear(embed_dim, mlp_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(mlp_dim, embed_dim)
self.drop = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.drop(self.fc2(self.drop(self.act(self.fc1(x)))))
class ViTBlock(nn.Module):
"""ViT 编码器块:Pre-Norm + Multi-Head Attention + Pre-Norm + MLP。"""
def __init__(
self,
embed_dim: int,
num_heads: int,
mlp_dim: int,
dropout: float = 0.1,
):
super().__init__()
self.ln1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(
embed_dim, num_heads, dropout=dropout, batch_first=True,
)
self.ln2 = nn.LayerNorm(embed_dim)
self.mlp = ViTMLP(embed_dim, mlp_dim, dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Pre-Norm: 归一化在子层之前
h = self.ln1(x)
x = x + self.attn(h, h, h, need_weights=False)[0]
x = x + self.mlp(self.ln2(x))
return x
class ViT(nn.Module):
"""Vision Transformer 完整实现。
Args:
img_size: 输入图像边长
patch_size: 补丁边长
in_channels: 输入通道数
num_classes: 分类类别数
embed_dim: 嵌入维度 D
num_layers: Transformer 编码器层数
num_heads: 多头注意力的头数
mlp_dim: MLP 中间层维度
dropout: Dropout 概率
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
num_classes: int = 1000,
embed_dim: int = 768,
num_layers: int = 12,
num_heads: int = 12,
mlp_dim: int = 3072,
dropout: float = 0.1,
):
super().__init__()
self.patch_embed = PatchEmbedding(
img_size, patch_size, in_channels, embed_dim,
)
num_patches = self.patch_embed.num_patches
# 可学习的 <cls> token 和位置编码
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(
torch.randn(1, num_patches + 1, embed_dim) * 0.02
)
self.pos_drop = nn.Dropout(dropout)
# Transformer 编码器
self.blocks = nn.Sequential(*[
ViTBlock(embed_dim, num_heads, mlp_dim, dropout)
for _ in range(num_layers)
])
# 分类头
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B = x.shape[0]
# 补丁嵌入: (B, N, D)
x = self.patch_embed(x)
# 拼接 <cls> token: (B, N+1, D)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls_tokens, x], dim=1)
# 加位置编码
x = self.pos_drop(x + self.pos_embed)
# Transformer 编码器
x = self.blocks(x)
# 取 <cls> token 的输出进行分类
return self.head(self.norm(x[:, 0]))关键设计说明。 (1) cls_token 和 pos_embed 都是可学习参数,通过反向传播优化。pos_embed 使用标准差为 0.02 的高斯分布初始化,这是 ViT 原始论文的做法。(2) ViT 采用 Pre-Norm 结构(与 3.2 节中讨论的现代 Transformer 一致),在自注意力和 MLP 之前施加层归一化。(3) MLP 使用 GELU 激活函数而非 ReLU,GELU 可视为 ReLU 的平滑近似版本,在 Transformer 系列模型中已成为标准选择。(4) 分类时仅使用 <cls> token 的输出——由于自注意力的全局交互特性,<cls> token 能够聚合所有补丁的信息。
3.7.5 CNN 与 Transformer 的适用性对比
ViT 的出现引发了一个核心问题:CNN 和 Transformer 分别适合什么场景?二者并非简单的替代关系,而是在不同条件下各有优势。
数据规模的影响。 这是二者差异的核心分水岭。ViT 原始论文的实验表明:在中等规模数据集(如 ImageNet-1K,约 130 万张图像)上单独训练时,ViT 的表现不如同等参数量的 ResNet。这是因为 Transformer 不具备 CNN 的局部性和平移不变性等归纳偏置,它需要从数据中自行学习这些模式。然而,当预训练数据集扩大到 JFT-300M(约 3 亿张图像)时,ViT 显著超越 ResNet。这揭示了一个关键规律:归纳偏置在数据稀缺时是优势,在数据充足时反而成为限制模型表达能力的瓶颈。
计算复杂度。 CNN 中卷积操作的复杂度与图像分辨率线性相关(
模型扩展性(Scalability)。 Transformer 架构的同质性(每一层结构完全相同)使其天然适合规模扩展——只需增加层数、嵌入维度和头数。ViT 在从 Base(86M 参数)到 Large(307M)再到 Huge(632M)的扩展过程中,性能持续平稳提升,展现了与 NLP 中类似的规模律特性。相比之下,CNN 架构的异质性使得扩展往往需要手工调整各阶段的通道数、分辨率和层数,缺乏统一的扩展策略。
下表总结了两种架构在关键维度上的对比:
| 维度 | CNN | Vision Transformer |
|---|---|---|
| 归纳偏置 | 强(局部性 + 平移不变性) | 弱(几乎无视觉先验) |
| 小数据表现 | 优(先验弥补数据不足) | 劣(需大量数据学习模式) |
| 大数据表现 | 受限(先验限制表达能力) | 优(充分发挥模型容量) |
| 全局建模 | 需多层堆叠 | 单层即可全局交互 |
| 计算复杂度 | ||
| 模型扩展性 | 需手工设计 | 同质架构,易于扩展 |
表 3-7:CNN 与 Vision Transformer 在关键维度上的对比。
ViT 在多模态 AI 中的角色。 ViT 的影响远超图像分类本身。在现代视觉语言模型(VLM)中,ViT 充当视觉编码器的角色:将输入图像编码为一系列高质量的视觉特征向量,这些向量通过多模态连接器与文本特征对齐后,送入大语言模型进行联合推理。以 CLIP 和 SigLIP 为代表的对比学习方法在大规模图文对数据上预训练 ViT,使其学会将视觉语义映射到与文本共享的嵌入空间中。实验表明,视觉编码器的质量对 VLM 的整体性能影响显著,采用更好的预训练 ViT 是提升多模态模型能力的最直接手段之一。
本节小结
本节介绍了 Vision Transformer(ViT)的核心思想、架构细节和工程实现:
- 核心思想:将图像切分为固定大小的补丁,每个补丁类比为一个词元,从而将图像理解问题转化为序列建模问题,直接复用标准 Transformer 编码器。
- 补丁嵌入的数学本质是将
的图像块展平后经线性投影映射到 维空间,工程上可用核大小和步幅均为 的卷积操作高效实现。 - ViT 的完整流程:图像分块
补丁嵌入 拼接 <cls>token加位置编码 层 Transformer 编码器(Pre-Norm + GELU) <cls>输出经分类头得到预测。 - CNN vs. Transformer 的核心权衡:CNN 的归纳偏置使其在小数据场景中占优,但限制了大规模扩展的潜力;Transformer 放弃了视觉先验,依赖数据驱动学习,在大数据大模型的范式下展现出更强的扩展性和更高的性能上限。
- 生态影响:ViT 不仅改变了计算机视觉的架构设计范式,更成为多模态大模型中视觉编码的标准组件,连接了视觉与语言两大模态。