1.4 正则化与泛化
深度学习的终极目标并非拟合训练数据,而是在未见过的测试数据上做出准确预测——这就是泛化(Generalization)。然而,现代深度网络往往拥有远多于训练样本的参数,具备将任意标签完全拟合的能力。在这种过参数化(over-parametrized)的背景下,如何防止模型"记住"训练噪声、而是"学到"数据背后的真实规律,就成了训练中最核心的问题。
正则化(Regularization)正是为此而生的一系列技术。它们从不同角度约束模型的复杂度:有的直接惩罚参数的大小(L1/L2 正则化、权重衰减),有的在训练过程中引入随机扰动(Dropout),有的从"软标签"的角度让模型不要过度自信(标签平滑),还有的通过精心设计的初始化来保证训练稳定性(Xavier/He 初始化)。本节将逐一展开这些技术,并在最后从 Lipschitz 稳定性的数学视角统一理解泛化的本质。
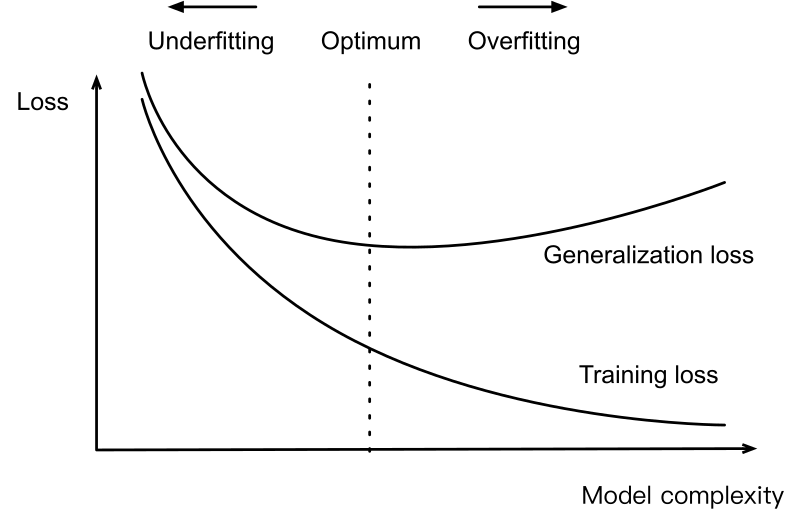
图 1-8:模型复杂度与训练/测试误差的典型关系。随着模型容量增大,训练误差持续下降,但测试误差在某一点后开始上升——这就是过拟合。正则化的目标正是延缓或消除这一拐点。
1.4.1 L1 与 L2 正则化
正则化最经典的形式是在原始损失函数
L1 正则化(也称 Lasso)添加参数绝对值之和:
L2 正则化(也称 Ridge)添加参数平方和:
其中
L1 与 L2 的行为差异。 虽然两者都在抑制参数增长,但机制截然不同。L1 惩罚的梯度为
从几何角度理解更为直观。考虑二维参数空间
在大模型实践中,L2 正则化是默认选择。一方面,稀疏性对于数十亿参数的大模型并非核心需求;另一方面,L2 正则化与接下来要讨论的权重衰减有深层联系,工程实现也更为方便。
1.4.2 权重衰减
权重衰减(Weight Decay)是另一种抑制参数过大的技术。它的做法比正则化更直接:在每步梯度更新时,额外将参数值乘以一个略小于 1 的系数进行衰减:
其中
与 L2 正则化的关系。 在标准 SGD 下,权重衰减与 L2 正则化数学上完全等价。若将 L2 项
这与权重衰减的公式一致。然而,对 Adam 等自适应优化器,两者不再等价。原因在于 Adam 会对梯度进行动量估计和方差归一化,如果将
AdamW 是当前大模型训练的标准优化器选择,它确保了权重衰减在自适应优化器中也能保持正确的正则化行为。
1.4.3 Dropout:随机失活
Dropout 是深度学习中最具标志性的正则化技术之一。其思想直截了当:在训练过程中,以概率
具体而言,设隐藏层某神经元的激活值为
除以
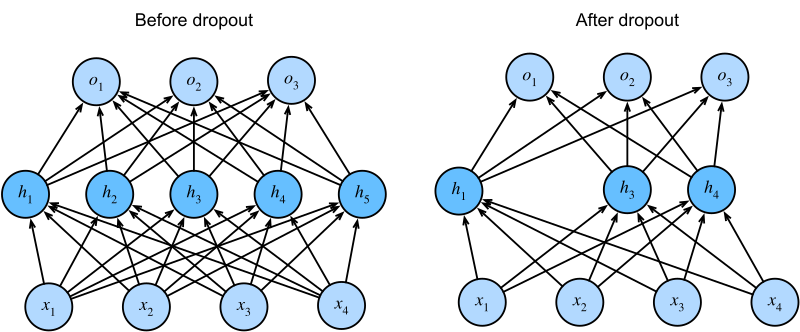
图 1-9:Dropout 的工作机制。左侧为标准全连接网络,右侧为应用 Dropout 后的网络——部分神经元被随机置零(虚线表示),网络在每次前向传播中实际使用的是一个"子网络"。
为什么 Dropout 有效? 有多种互补的解释。从集成学习的角度,每次 Dropout 都在训练一个不同的子网络,最终的模型等价于指数多个子网络的平均——这类似于 Bagging 的效果。从打破共适应(co-adaptation)的角度,Dropout 阻止了神经元之间形成过于固定的依赖关系,每个神经元都必须独立地学到有用的特征。从噪声注入的角度,Bishop(1995)证明了对输入添加噪声等价于 Tikhonov 正则化——Dropout 可以视为对隐藏层进行乘性噪声注入的推广。
在实践中,Dropout 率
1.4.4 参数初始化:Xavier 与 He
正则化技术约束的是训练过程中参数的行为,而参数初始化则决定了训练的起点。一个好的初始化方案需要满足两个条件:(1)打破对称性——如果所有参数初始化为相同的值,同一层的所有神经元将计算完全相同的梯度,永远无法分化出不同的特征;(2)维持信号稳定传播——确保前向传播的激活值和反向传播的梯度在各层之间既不会爆炸也不会消失。
梯度消失与爆炸。 考虑一个
其中
Xavier 初始化。 Glorot 和 Bengio(2010)从方差保持的角度推导了初始化方案。对于一个输入维度为
其中
对应的均匀分布形式为
He 初始化。 ReLU 激活函数会将所有负数输入置零,这相当于"杀死"了约一半的信号。为了补偿这一信息损失,Kaiming He 等人(2015)提出只考虑输入维度:
He 初始化是当前使用 ReLU 系列激活函数时的标准选择。PyTorch 中 nn.Linear 层默认使用的就是 He 初始化的变种。
截断正态分布。 在实际初始化中,通常使用截断正态分布(Truncated Normal),将超出
图 1-10:Dropout 的工作机制。训练时随机将部分神经元置零,迫使网络不过度依赖任何单个神经元。推理时使用完整网络。Dropout 在微调阶段仍然是重要的正则化手段。
1.4.5 z-loss 辅助正则项 [选读]
在大模型训练中,一个容易被忽视但实际影响显著的问题是 logits 的整体漂移。在 softmax 计算中,分类概率为
z-loss 正是为解决这一问题而设计的辅助正则项。设
其中
推导其梯度。 对某个 logit
可见,z-loss 对每个 logit 的梯度正比于其对应的 softmax 概率
在 MoE 模型中的应用。 在稀疏 Mixture-of-Experts(MoE)架构中,路由器(Router)需要决定将每个 token 分配给哪些专家。路由器的 logits 同样可能出现漂移或饱和问题。对路由器 logits 施加同类的 z-loss 惩罚(router z-loss)可以有效避免路由过于集中(某些专家被过度选中而其他专家闲置),从而维持专家负载的均衡。
1.4.6 标签平滑 [选读]
在标准的分类任务中,训练标签通常以 one-hot 向量的形式给出。例如,在一个
这种"极端自信"的训练信号存在几个问题:(1)logits 被推向极大绝对值,可能导致数值溢出;(2)模型对错误类别赋予概率 0 的同时,也丧失了捕捉类间相似性的能力;(3)模型在训练集上过度自信,在测试集上容易表现出过高的置信度(calibration 偏差)。
标签平滑(Label Smoothing)通过将 one-hot 标签"软化"来缓解这些问题。设平滑系数为
例如,在
推导其对交叉熵的影响。 使用软标签后,交叉熵损失变为:
将第二项改写:
其中
在 Transformer 的训练中,标签平滑是标配技巧。原始的 "Attention Is All You Need" 论文即使用了
1.4.7 Lipschitz 稳定性视角下的泛化
前面讨论的正则化技术各有侧重,但它们能否被统一到一个数学框架下?Lipschitz 连续性提供了这样一个视角。
一个函数
其中
Lipschitz 常数与泛化界。 泛化理论中的一个经典结论是:对于一个 Lipschitz 常数为
其中
深度网络的 Lipschitz 常数。 对于一个
其中
在这个框架下,前面讨论的各种正则化技术都获得了统一的解释:
- L2 正则化 / 权重衰减 直接限制了参数的范数,从而压缩了每层的算子范数
,降低了整体 Lipschitz 常数。 - Dropout 在训练过程中随机"删除"连接,等效于在每次前向传播中使用一个更小的权重矩阵,降低了有效的 Lipschitz 常数。
- 标签平滑 阻止 logits 趋向极端值,间接约束了网络最后几层的输出范围,也有助于控制 Lipschitz 常数。
- Xavier/He 初始化 通过使每层的输出方差保持稳定,确保了训练初期各层的雅可比矩阵特征值在 1 附近,避免 Lipschitz 常数在初始阶段就失控。
- z-loss 抑制 logits 的整体漂移,等价于控制了 softmax 层输入的范围,有助于维持数值稳定性和有效 Lipschitz 常数的可控性。
从这个视角来看,正则化技术的本质目标是一致的:控制模型函数的平滑程度,使其对输入的微小扰动保持稳健响应。一个具有小 Lipschitz 常数的模型,不会因为输入的些许变化就做出截然不同的预测,这正是泛化能力的数学内涵。
值得指出的是,现代大模型的泛化行为远比上述理论界所描述的更为复杂。经典的基于 VC 维或 Rademacher 复杂度的泛化界对于过参数化的深度网络往往过于宽松,无法解释实践中观察到的良好泛化性能。双下降(Double Descent)现象进一步表明,模型复杂度与泛化误差之间并非单调关系——过参数化的模型在拟合所有训练数据后,反而可能展现出更好的泛化能力。这暗示了 SGD 等优化算法本身可能提供了某种隐式正则化(Implicit Regularization),倾向于收敛到"更平坦"的损失函数极小值区域,而平坦极小值通常对应更小的有效 Lipschitz 常数和更好的泛化性能。这些前沿问题仍是当前深度学习理论研究的核心课题。
本节小结
本节系统梳理了深度学习中的主要正则化技术及其与泛化能力的联系:
| 技术 | 核心机制 | 适用场景 | 关键超参数 |
|---|---|---|---|
| L1 正则化 | 参数绝对值惩罚,产生稀疏解 | 特征选择、小模型 | |
| L2 正则化 | 参数平方惩罚,均匀缩小参数 | 通用场景,默认选择 | |
| 权重衰减 | 每步直接衰减参数值 | 配合 AdamW 使用 | |
| Dropout | 随机置零神经元输出 | 微调、中小数据集 | |
| Xavier 初始化 | 方差 | Sigmoid/Tanh 激活 | — |
| He 初始化 | 方差 | ReLU 及变体 | — |
| z-loss | 惩罚 | LLM 预训练、MoE 路由 | |
| 标签平滑 | 软化 one-hot 标签 | 分类任务全般 |
表 1-4:正则化技术一览。
这些技术看似各自独立,但从 Lipschitz 稳定性的视角可以获得统一理解:它们都在以不同方式控制模型函数的平滑度,防止模型对训练数据中的噪声做出过度敏感的反应。在实际的大模型训练中,这些技术通常不是二选一的关系,而是组合使用——例如,AdamW(权重衰减)+ He 初始化 + z-loss + 标签平滑,共同构成了一套经过实践检验的训练"配方"。理解每种技术的原理和适用场景,是灵活运用它们的前提。