20.2 评估方法
上一节从宏观层面讨论了评估的多元面貌和四个核心问题。本节将聚焦于"如何调用模型并提取答案"这一关键环节,系统介绍三种主流的选择题评估方法——字母匹配(Letter Matching)、对数概率评分(Log-Probability Scoring)和教师强制(Teacher Forcing),并深入讨论当评估超越客观题范畴时,如何利用**大模型作为评判者(LLM-as-Judge)**来实现开放式任务的自动化评估。最后,我们以 MMLU 基准测试为载体,给出三种评估方法的完整实现代码。
20.2.1 选择题评估的三种范式
在 MMLU、ARC、HellaSwag 等选择题基准测试中,核心任务是判断模型是否选中了正确答案。看似简单的"选 A/B/C/D",实际上存在三种本质不同的实现方式,它们在准确性、计算成本和对模型类型的适配性上各有权衡。
图 20-1:LLM 评估方法总览。从选择题评估到开放式评估,方法的复杂度和灵活性逐步提升。
方法一:字母匹配(Letter Matching)
这是最直觉的评估方式:将题目和选项拼接为 Prompt,让模型自由生成若干 Token,然后从生成文本中提取第一个出现的 A/B/C/D 字母,与正确答案比对。
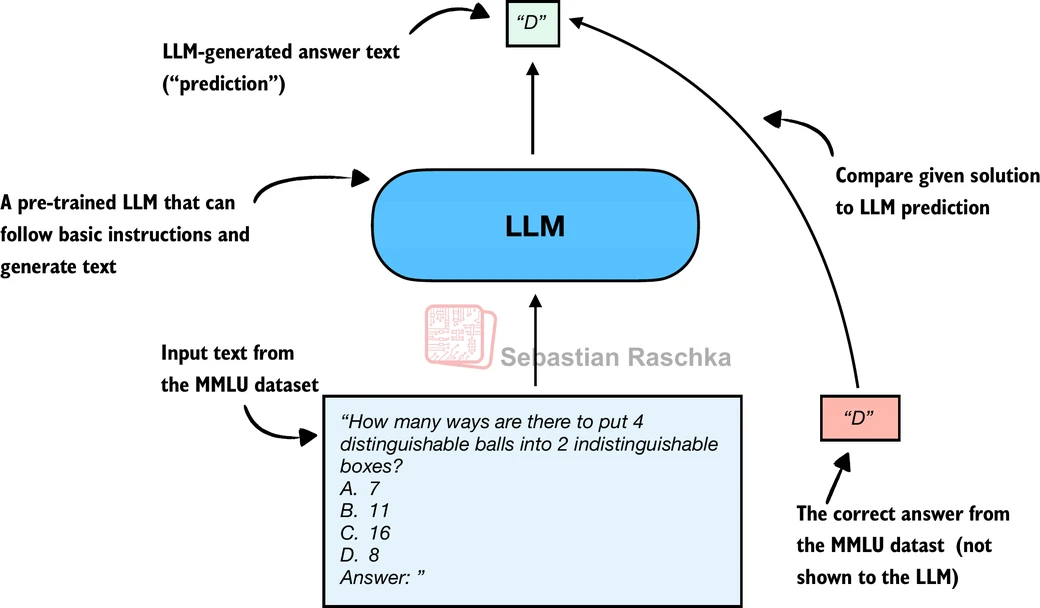
图 20-2:字母匹配方法。模型自由生成文本,从中提取首个合法字母作为预测。
其工作流程如下:
- 构造 Prompt:将问题、四个选项和"Answer: "后缀拼接在一起,末尾的空格引导模型直接输出字母。
- 自回归生成:调用模型生成最多 8 个 Token(留有余量应对模型可能输出的前缀文本)。
- 字母提取:逐字符扫描生成文本,找到第一个属于 {A, B, C, D} 的字母即为预测结果。
def format_prompt(example):
"""将 MMLU 样本格式化为选择题 Prompt"""
return (
f"{example['question']}\n"
f"A. {example['choices'][0]}\n"
f"B. {example['choices'][1]}\n"
f"C. {example['choices'][2]}\n"
f"D. {example['choices'][3]}\n"
"Answer: " # 末尾空格引导模型输出单个字母
)
def predict_choice_letter(model, tokenizer, input_ids, max_new_tokens=8):
"""生成文本并提取第一个 A/B/C/D 字母"""
pred = None
# 假设 generate_stream 是一个逐 Token 生成的生成器
for token_tensor in generate_stream(
model=model, token_ids=input_ids,
max_new_tokens=max_new_tokens
):
text = tokenizer.decode(token_tensor.squeeze(0).tolist())
for char in text:
if char.upper() in "ABCD":
pred = char.upper()
break
if pred:
break
return pred优点:实现简单,不需要访问模型内部的 logits,纯黑盒调用 API 即可。
缺点:模型可能不输出有效字母(尤其是未经指令微调的 base 模型),或在字母前添加多余文本导致提取出错。实测中,Qwen3 0.6B base 模型在 MMLU 高中数学子集上仅获得约 21% 的准确率——接近 25% 的随机猜测基线,这并非因为模型"不懂",而是因为 base 模型不擅长遵循"只输出一个字母"的指令格式。
方法二:对数概率评分(Log-Probability Scoring)
第二种方法绕过了生成过程,直接考察模型对每个候选字母的"内部信心"。具体做法是:将完整 Prompt 送入模型做一次前向传播,取最后一个位置的 logits,对 A/B/C/D 四个字母对应的 Token ID 提取对数概率(log-probability),选概率最高的字母作为预测。
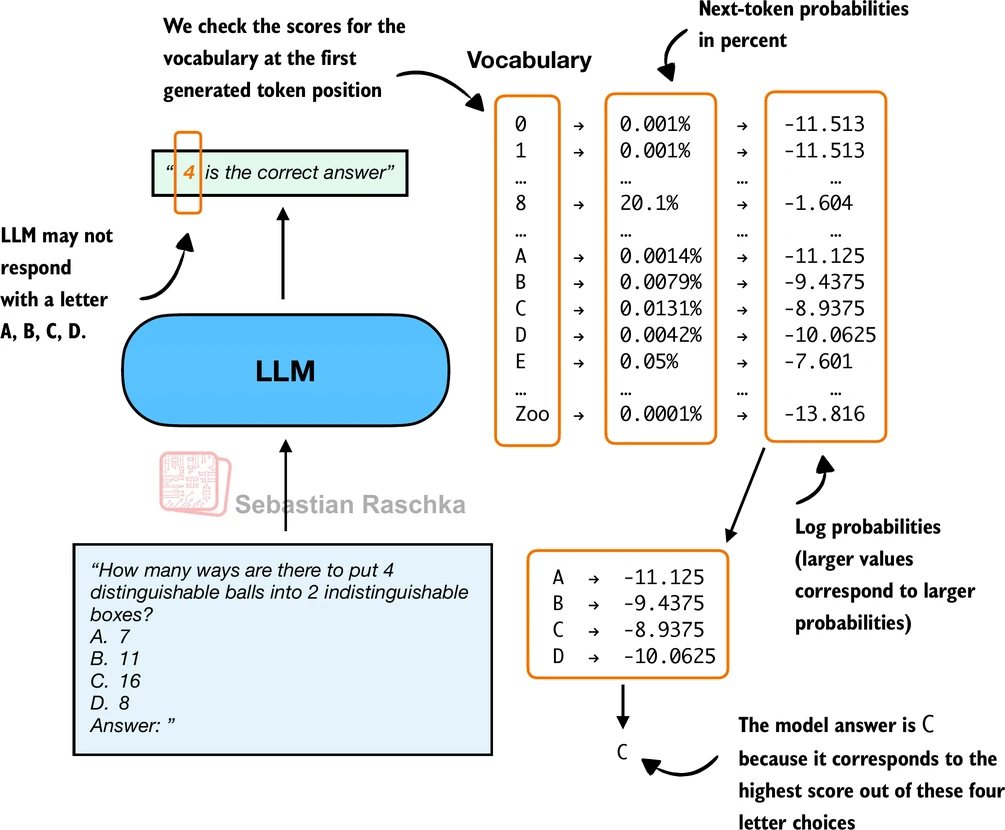
图 20-3:对数概率评分方法。取最后一个位置的输出分布,比较四个候选字母的对数概率。
实现中有一个微妙的细节:字母 "A" 在不同 tokenizer 中可能被编码为不同的 Token ID,因此需要通过拼接测试来确定每个字母在当前上下文中的首个新 Token ID:
import torch
def common_prefix_len(seq_a, seq_b):
"""计算两个 Token 序列的公共前缀长度"""
i = 0
n = min(len(seq_a), len(seq_b))
while i < n and seq_a[i] == seq_b[i]:
i += 1
return i
def first_new_token_id(tokenizer, prompt, prompt_ids, continuation):
"""找到将 continuation 拼接到 prompt 后产生的第一个新 Token ID"""
ids_full = tokenizer.encode(prompt + continuation)
j = common_prefix_len(ids_full, prompt_ids)
if j >= len(ids_full):
raise ValueError("拼接后未产生任何新 Token")
return ids_full[j]
def predict_choice_logprob(model, tokenizer, input_ids, prompt, prompt_ids):
"""通过对数概率评分选择答案"""
with torch.no_grad():
logits = model(input_ids) # [1, T, V]
next_logp = torch.log_softmax(logits[0, -1], dim=-1)
scores = {}
for letter in "ABCD":
tok_id = first_new_token_id(tokenizer, prompt, prompt_ids, letter)
scores[letter] = next_logp[tok_id].item()
return max(scores, key=scores.get), scores优点:只需一次前向传播,速度快且不依赖模型的指令遵循能力——即使 base 模型也能给出有意义的概率排序。同一模型在 MMLU 上从字母匹配的 21% 提升到了约 34%。
缺点:仅考虑单个字母 Token 的概率,忽略了完整答案文本的语义。对于推理模型(reasoning model)可能不够充分——推理模型通常需要看到完整答案才能给出合理的概率估计。
方法三:教师强制(Teacher Forcing)
第三种方法是最稳健的评分方式。它不再只看字母 Token 的概率,而是将每个选项的完整答案文本(如 "A. 7"、"B. 11"、"C. 16"、"D. 8")依次拼接到 Prompt 后,计算模型在"被强制喂入正确续写"条件下的平均对数概率,选得分最高的选项。
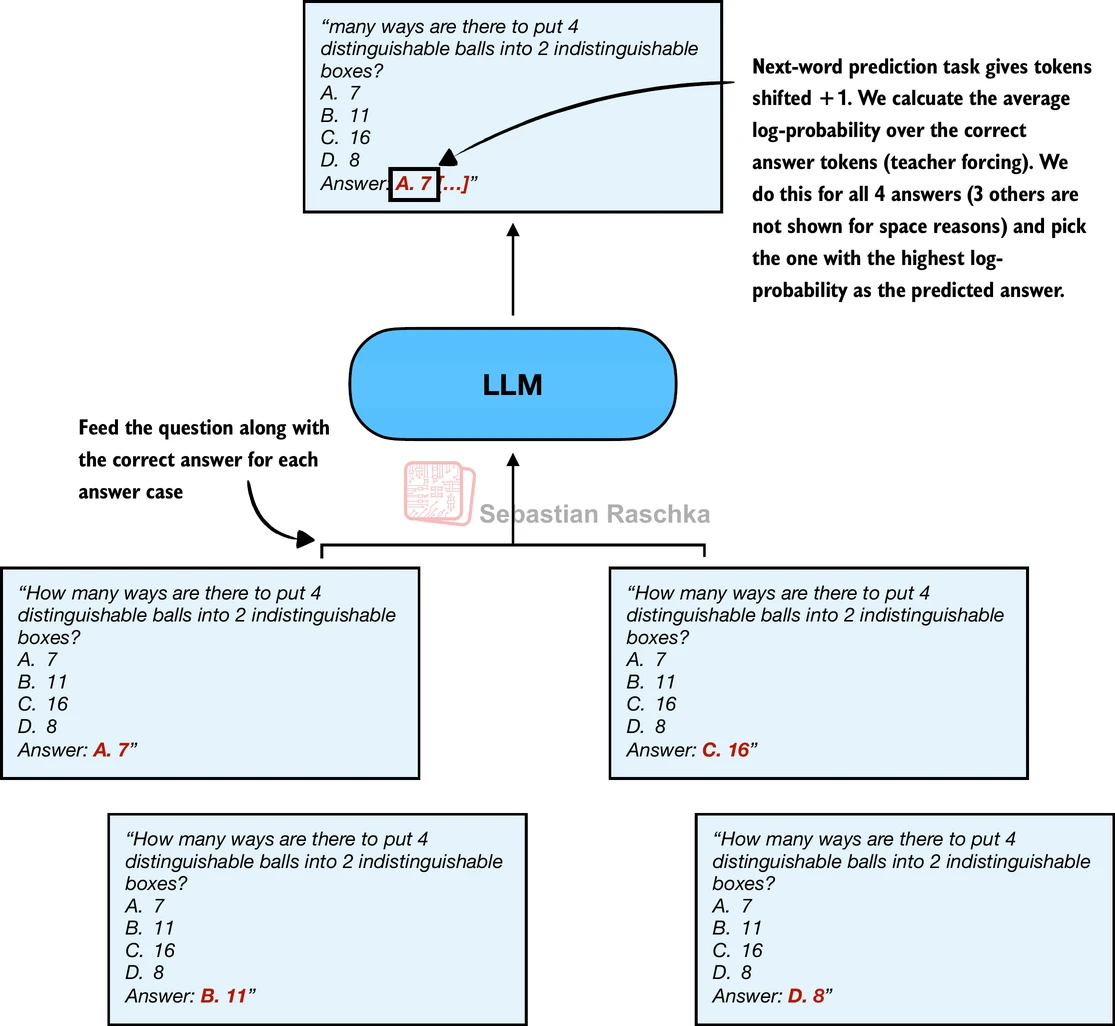
图 20-4:教师强制方法。将每个完整答案文本拼接到 Prompt 后,计算条件对数概率的平均值。
"教师强制"这个名称来源于训练阶段的同名技术——在训练时,我们将真实的下一个 Token 作为输入"强制喂给"模型,而非使用模型自己的预测。在评估中,这一思路的应用是:将候选答案的所有 Token 逐个作为"已知输入"传入模型,然后检查模型在每一步给出的对数概率。
数学上,对于一个包含
def avg_logprob_teacher_forced(model, tokenizer, input_ids, prompt, prompt_ids,
letter, choice_text):
"""计算教师强制条件下的平均对数概率"""
# 构造完整答案文本并提取续写 Token
answer_text = f"{letter}. {choice_text}"
ids_full = tokenizer.encode(prompt + answer_text)
j = common_prefix_len(ids_full, prompt_ids)
answer_ids = ids_full[j:] # 答案续写部分的 Token ID
if len(answer_ids) == 0:
return float("-inf")
device = input_ids.device
# 将 Prompt + 答案前缀(去掉最后一个 Token)拼接为输入
answer_prefix = torch.tensor(
answer_ids[:-1], dtype=torch.long, device=device
).unsqueeze(0)
combined = torch.cat([input_ids, answer_prefix], dim=1)
with torch.no_grad():
logits = model(combined).squeeze(0) # [seq_len, vocab_size]
logp = torch.log_softmax(logits, dim=-1)
prompt_len = input_ids.shape[1]
# 取 Prompt 最后一个位置到答案结束位置的 logp
steps = logp[prompt_len - 1 : prompt_len - 1 + len(answer_ids), :]
targets = torch.tensor(
answer_ids, dtype=torch.long, device=device
).unsqueeze(1)
return steps.gather(dim=1, index=targets).mean().item()
def predict_choice_teacher_forced(model, tokenizer, input_ids,
prompt, prompt_ids, example):
"""对四个选项分别计算教师强制得分,取最高分"""
scores = {}
for letter in "ABCD":
idx = ord(letter) - ord("A")
scores[letter] = avg_logprob_teacher_forced(
model, tokenizer, input_ids, prompt, prompt_ids,
letter, example["choices"][idx]
)
return max(scores, key=scores.get), scores优点:考虑了完整答案的语义信息,对推理模型尤其有效——推理模型在看到完整推理链时给出的概率更有区分度。
缺点:每道题需要 4 次前向传播(每个选项一次),计算量约为对数概率方法的 4 倍。
三种方法对比。 下表总结了三种方法的核心差异:
| 特征 | 字母匹配 | 对数概率 | 教师强制 |
|---|---|---|---|
| 前向传播次数 | 1 次 + 生成循环 | 1 次 | 4 次 |
| 需要 logits 访问 | 否 | 是 | 是 |
| 对 base 模型友好 | 差 | 好 | 好 |
| 对推理模型友好 | 差 | 一般 | 好 |
| 实际准确率(0.6B, 数学) | ~21% | ~34% | ~32% |
| 适用场景 | API 黑盒调用 | 快速评估 | 精确评估 |
表 20-1:MMLU 选择题三种评估方法对比。准确率数据基于 Qwen3 0.6B base 模型在 high_school_mathematics 子集上的测试结果。
另一个容易忽视的事实是,评估方法的选择本身就会影响结果。同一个模型在不同评估方法下的准确率可能相差 10 个百分点以上。因此在比较不同论文或排行榜的数据时,必须确认其使用的评估方法是否一致。
20.2.2 LLM 作为评判者(LLM-as-Judge)
选择题评估有一个本质局限:真实世界中大多数任务——写作、翻译、代码生成、开放问答——并没有唯一的标准答案。传统的 BLEU、ROUGE 等自动指标基于 n-gram 匹配,无法捕捉语义层面的质量差异。LLM-as-Judge(LLM 作为评判者)范式提出了一种全新思路:用一个更强大的 LLM 来充当评审,根据预设的评分标准(rubric)对候选模型的回答进行评分。
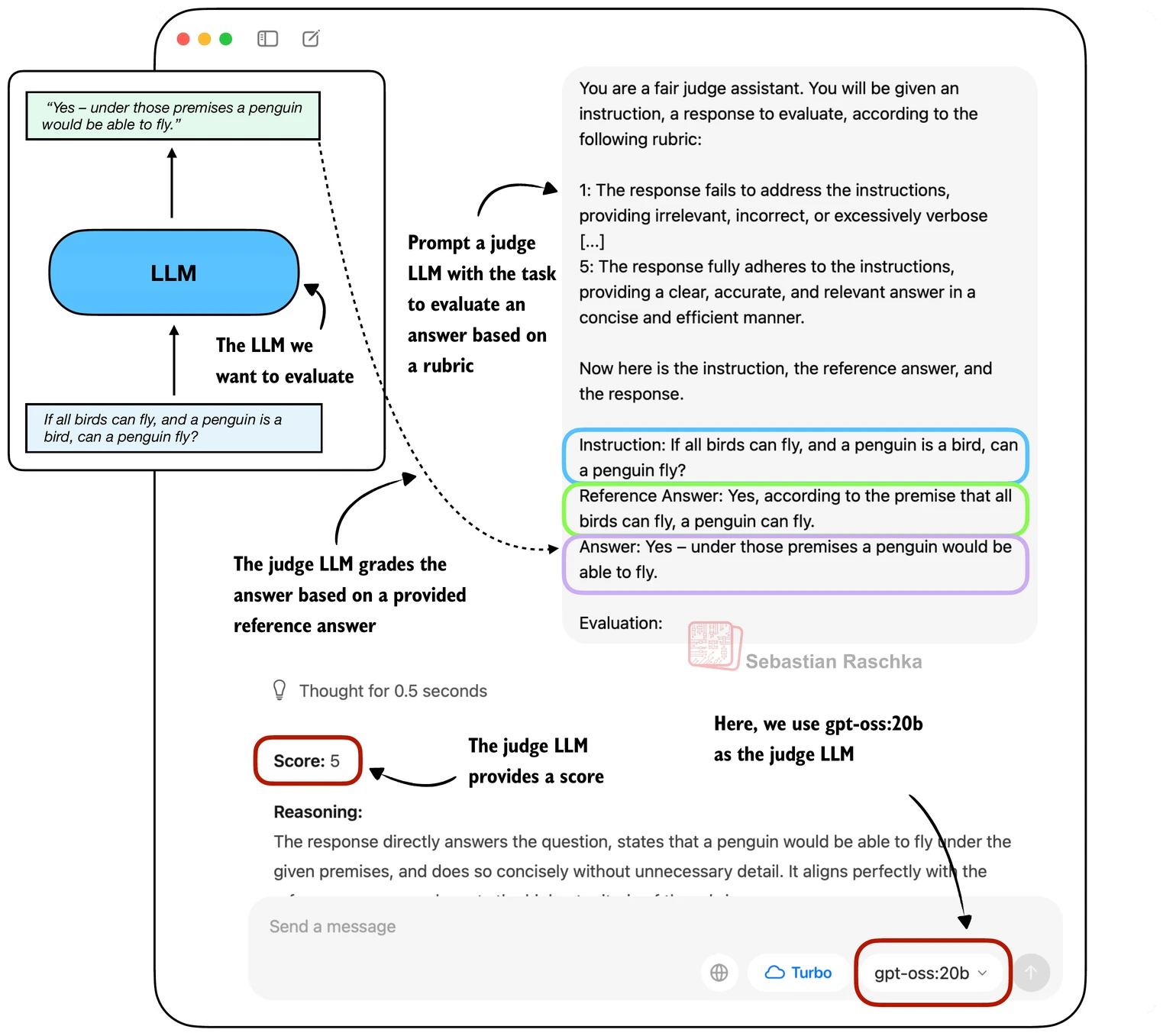
图 20-5:LLM-as-Judge 流程。候选模型生成回答后,由评审模型根据评分标准给出 1-5 分的评分。
评分标准(Rubric)设计。 LLM-as-Judge 的核心在于精心设计的评分标准。一个典型的 5 分制 rubric 如下:
| 分数 | 含义 |
|---|---|
| 1 分 | 回答未针对指令,内容不相关、错误或过度冗长 |
| 2 分 | 部分回应了指令,但存在重大错误、遗漏或无关细节 |
| 3 分 | 在一定程度上回应了指令,但不完整、部分正确或表述不清 |
| 4 分 | 基本遵循指令,仅有轻微错误、遗漏或清晰度不足 |
| 5 分 | 完全遵循指令,提供了清晰、准确、相关且简洁的回答 |
表 20-2:LLM-as-Judge 典型评分标准。
以下是一个完整的评审 Prompt 构造函数和评分解析逻辑:
import re
def build_judge_prompt(instruction, reference_answer, model_answer):
"""构造 LLM-as-Judge 的评审 Prompt"""
rubric = (
"You are a fair judge assistant. You will be given an instruction, "
"a reference answer, and a candidate answer to evaluate, according "
"to the following rubric:\n\n"
"1: The response fails to address the instruction, providing "
"irrelevant, incorrect, or excessively verbose content.\n"
"2: The response partially addresses the instruction but contains "
"major errors, omissions, or irrelevant details.\n"
"3: The response addresses the instruction to some degree but is "
"incomplete, partially correct, or unclear in places.\n"
"4: The response mostly adheres to the instruction, with only "
"minor errors, omissions, or lack of clarity.\n"
"5: The response fully adheres to the instruction, providing a "
"clear, accurate, and relevant answer in a concise and efficient "
"manner.\n\n"
"Now here is the instruction, the reference answer, and the response.\n"
)
return (
f"{rubric}\n"
f"Instruction:\n{instruction}\n\n"
f"Reference Answer:\n{reference_answer}\n\n"
f"Answer:\n{model_answer}\n\n"
f"Evaluation: "
)
def parse_score(judge_text, default=3):
"""从评审输出中提取 1-5 分的评分"""
m = re.search(r"([1-5])(?:\D|$)", judge_text)
return int(m.group(1)) if m else int(default)LLM-as-Judge 的常见变体。 根据评判维度和比较方式,LLM-as-Judge 可以分为以下几类:
- 单点评分(Pointwise Scoring):对单个回答独立打分(如上例),适用于绝对质量评估。
- 成对比较(Pairwise Comparison):同时给出两个模型的回答,让评审判断哪个更好,适用于偏好排序和竞技场评估。
- 参考辅助评判(Reference-Guided):提供参考答案帮助评审做出更准确的判断,对数学、编码等客观性较强的任务尤其重要。
TRL 框架提供了一套结构化的 Judge API,支持快速实现各类评判逻辑:
# TRL 框架中的 Pairwise Judge 使用示例
# pip install trl[judges]
from trl.experimental.judges import HfPairwiseJudge
judge = HfPairwiseJudge()
results = judge.judge(
prompts=[
"What is the capital of France?",
"What is the biggest planet in the solar system?"
],
completions=[
["Paris", "Lyon"], # 两个候选回答
["Saturn", "Jupiter"]
],
)
print(results) # [0, 1] 表示第一题选 completion[0],第二题选 completion[1]也可以自定义评判逻辑,例如实现一个偏好较短回答的评判者:
from trl.experimental.judges import BasePairwiseJudge
class PrefersShorterJudge(BasePairwiseJudge):
"""偏好更简短回答的自定义评判者"""
def judge(self, prompts, completions, shuffle_order=False):
return [
0 if len(pair[0]) > len(pair[1]) else 1
for pair in completions
]LLM-as-Judge 的已知偏差。 这种方法并非没有问题,已被观察到的系统性偏差包括:
- 位置偏差(Position Bias):评审倾向于偏好呈现在前面的回答。缓解方法是随机交换两个回答的顺序后取平均。
- 冗长偏差(Verbosity Bias):评审倾向于给更长的回答更高分数,即使更长的回答未必更好。
- 自我偏好(Self-Enhancement Bias):当评审模型与候选模型来自同一系列时,可能存在自我偏好。
- 有限推理能力:在数学和逻辑推理任务中,评审模型可能自身也无法正确判断答案的对错。
一个有趣的实践发现是:让 LLM 扣分比让 LLM 打分更有效。即不是问"这个回答值几分",而是问"这个回答扣几分、为什么扣",这种负向评审框架往往能得到更具辨别力的评分。
20.2.3 MMLU 三种评估方法完整实现
将上述三种方法整合为一个统一的评估框架,以下代码展示了如何在 MMLU 数据集上实现完整的评估流程。代码使用 Hugging Face datasets 库加载 MMLU 数据集,并支持切换不同的评估方法。
import time
import torch
from datasets import load_dataset, get_dataset_config_names
def evaluate_mmlu(model, tokenizer, device, method="logprob",
subsets="high_school_mathematics", split="test",
max_new_tokens=8, verbose_every=50):
"""
统一的 MMLU 评估函数,支持三种评估方法。
参数:
model: 语言模型
tokenizer: 分词器
device: 计算设备
method: 评估方法 ("letter" / "logprob" / "teacher_forced")
subsets: MMLU 子集名称,逗号分隔或 "all"
split: 数据集划分 ("test" / "validation")
max_new_tokens: 字母匹配方法的最大生成 Token 数
verbose_every: 每隔多少题打印一次进度
"""
# 解析子集列表
if subsets == "all":
subset_list = get_dataset_config_names("cais/mmlu")
elif "," in subsets:
subset_list = [s.strip() for s in subsets.split(",")]
else:
subset_list = [subsets]
total, correct = 0, 0
start = time.time()
for subset in subset_list:
ds = load_dataset("cais/mmlu", subset, split=split)
for ex in ds:
prompt = format_prompt(ex)
prompt_ids = tokenizer.encode(prompt)
input_ids = torch.tensor(
prompt_ids, device=device
).unsqueeze(0)
# 根据方法选择预测函数
if method == "letter":
pred = predict_choice_letter(
model, tokenizer, input_ids, max_new_tokens
)
elif method == "logprob":
pred, _ = predict_choice_logprob(
model, tokenizer, input_ids, prompt, prompt_ids
)
elif method == "teacher_forced":
pred, _ = predict_choice_teacher_forced(
model, tokenizer, input_ids, prompt, prompt_ids, ex
)
else:
raise ValueError(f"未知方法: {method}")
# 提取正确答案
ans = ex["answer"]
gold = "ABCD"[ans] if isinstance(ans, int) else str(ans).strip().upper()
total += 1
correct += int(pred == gold)
if verbose_every and total % verbose_every == 0:
print(f"[{method}] {total} 题, 准确率={correct/total:.3f} [{subset}]")
acc = correct / max(1, total)
elapsed = time.time() - start
print(f"\nMMLU {method} 准确率: {correct}/{total} = {acc:.2%} (耗时 {elapsed:.1f}s)")
return {
"method": method,
"accuracy": acc,
"num_examples": total,
"subsets": subset_list,
"split": split
}使用示例:
# 假设 model, tokenizer, device 已初始化
model.eval()
# 三种方法依次评估
for method in ["letter", "logprob", "teacher_forced"]:
result = evaluate_mmlu(
model, tokenizer, device,
method=method,
subsets="high_school_mathematics"
)
print(result)
print("---")随机猜测基线。 在解读 MMLU 分数时,一个重要的参照系是随机猜测的期望表现。对于 4 选 1 的题目,随机猜测的期望准确率为 25%。但在有限样本下,单次实验的准确率会围绕 25% 波动。以
这意味着约 68% 的随机猜测实验会落在
20.2.4 从竞技场到排行榜:Elo 与 Bradley-Terry
LLM-as-Judge 的成对比较模式自然引出了一个问题:如何将大量成对比较结果汇总为全局排行榜?LM Arena(前身 Chatbot Arena)等平台采用的方法是从国际象棋借来的 Elo 评分系统。
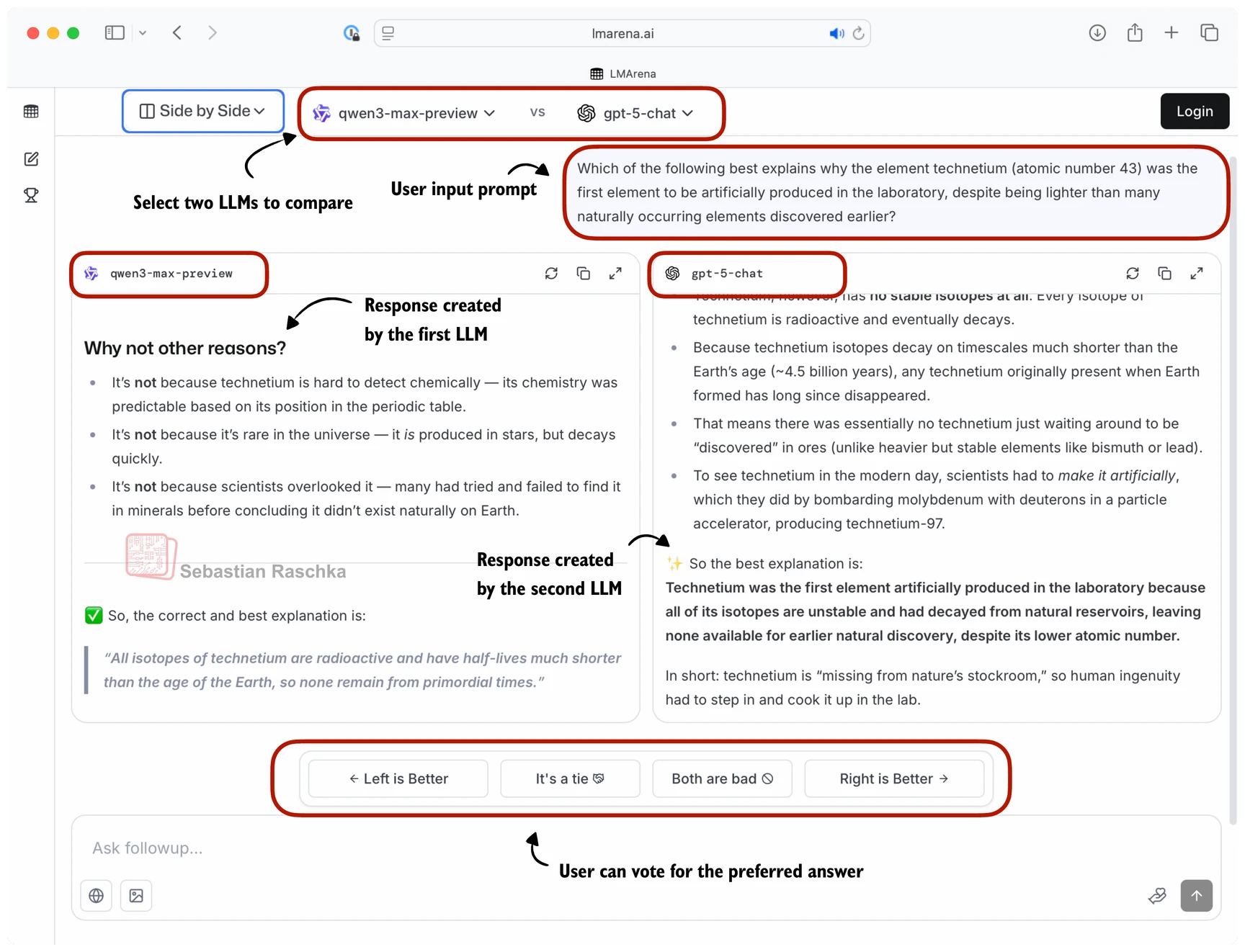
图 20-6:从成对比较到排行榜。人类或评审模型对两个模型的回答进行偏好判断,汇聚为全局 Elo 排名。
Elo 评分的核心思想。 每个模型初始化一个相同的评分(如 1000 分)。每次成对比较后,胜者加分、负者减分,加减的幅度取决于比赛前双方的评分差距——以弱胜强的加分远大于以强胜弱。
胜者的期望得分(Expected Score)计算公式为:
直觉理解:当
更新规则为:
其中
def elo_ratings(vote_pairs, k_factor=32, initial_rating=1000):
"""
根据成对比较结果计算 Elo 评分。
vote_pairs: [(winner, loser), ...] 格式的比赛记录
"""
# 初始化所有模型的评分
ratings = {
model: initial_rating
for pair in vote_pairs
for model in pair
}
for winner, loser in vote_pairs:
r_w, r_l = ratings[winner], ratings[loser]
# 胜者的期望得分
expected = 1.0 / (1.0 + 10 ** ((r_l - r_w) / 400.0))
# 更新评分
ratings[winner] = r_w + k_factor * (1 - expected)
ratings[loser] = r_l - k_factor * (0 - (1 - expected))
return ratings
# 使用示例
votes = [
("GPT-5", "Claude-3"),
("GPT-5", "Llama-4"),
("Claude-3", "Llama-3"),
("Llama-4", "Llama-3"),
("Claude-3", "Llama-3"),
("GPT-5", "Llama-3"),
]
ratings = elo_ratings(votes)
for model in sorted(ratings, key=ratings.get, reverse=True):
print(f"{model:10s} : {ratings[model]:.1f}")
# GPT-5 : 1043.7
# Claude-3 : 1015.2
# Llama-4 : 1000.7
# Llama-3 : 940.4Bradley-Terry 模型。 Elo 评分是一种在线、顺序更新的方法——评分结果依赖于比赛的顺序。LM Arena 后来切换到了 Bradley-Terry 模型,这是一种统计模型,通过最大似然估计来拟合所有模型的潜在能力参数
其中
import math
import torch
def bradley_terry(vote_pairs, device="cpu", lr=0.01, epochs=500):
"""
Bradley-Terry 模型:通过最大似然估计拟合模型能力参数。
返回 Elo 式的评分(以 1000 为中心)。
"""
models = sorted({m for pair in vote_pairs for m in pair})
n = len(models)
idx = {m: i for i, m in enumerate(models)}
winners = torch.tensor([idx[w] for w, _ in vote_pairs], dtype=torch.long)
losers = torch.tensor([idx[l] for _, l in vote_pairs], dtype=torch.long)
# 可学习参数(最后一个模型固定为 0 作为锚点)
theta = torch.nn.Parameter(torch.zeros(n - 1, device=device))
optimizer = torch.optim.Adam([theta], lr=lr, weight_decay=1e-4)
def scores():
return torch.cat([theta, torch.zeros(1, device=device)])
for _ in range(epochs):
s = scores()
delta = s[winners] - s[losers]
loss = -torch.nn.functional.logsigmoid(delta).mean()
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# 转换为 Elo 式评分
with torch.no_grad():
s = scores()
scale = 400.0 / math.log(10.0)
R = s * scale
R -= R.mean()
R += 1000.0
return {m: float(r) for m, r in zip(models, R.cpu().tolist())}Bradley-Terry 模型的优势在于:(1)评分结果不依赖比赛顺序;(2)可以自然地给出置信区间;(3)理论上更加合理。
本节小结
本节介绍了 LLM 评估中最核心的技术方法。字母匹配是最简单的黑盒方法,但受限于模型的指令遵循能力;对数概率评分通过直接访问模型内部的 logits 绕过了生成过程,是实践中最广泛使用的方法;教师强制进一步考虑了完整答案文本的语义,对推理模型更加友好。当评估超越客观题进入开放式任务时,LLM-as-Judge 提供了一种可扩展的自动化评估方案,尽管需要注意位置偏差、冗长偏差等系统性问题。最后,Elo 评分和 Bradley-Terry 模型将成对比较结果汇聚为全局排行榜,为模型间的横向比较提供了量化基础。评估方法的选择本身就是一个需要审慎决策的问题——不同方法可能导致截然不同的结论。