12.3 指令微调
预训练赋予语言模型"知道很多"的能力,却无法让它"听懂人话"。GPT-3 在 2020 年展示了令人震撼的文本续写能力,但如果你对它说"请帮我把下面这段话翻译成英文",它很可能会继续写一段关于翻译的维基百科段落,而不是真正去翻译。指令微调(Instruction Tuning) 正是解决这一鸿沟的关键技术——它通过在"指令-响应"格式的数据上进行有监督训练,让模型学会理解用户意图并生成符合期望的回复。
从 GPT-3 到 ChatGPT 的跨越,后训练(Post-training)阶段发挥了核心作用。如下图所示,一个完整的大模型训练流程通常包括预训练、持续预训练、指令微调(含拒答微调 RFT 和思维链 CoT)、偏好对齐(RLHF/DPO)以及最终部署。指令微调是其中承上启下的关键环节。
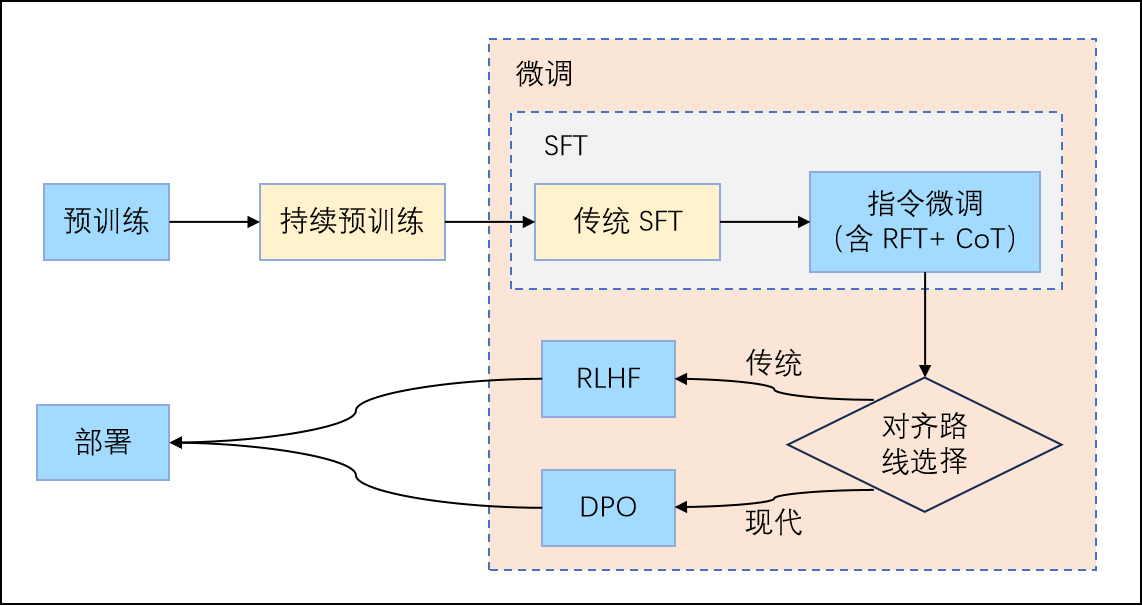
图 12-6:大模型训练的完整流程。指令微调位于预训练之后、偏好对齐之前,是让模型从"文本续写器"变成"对话助手"的关键步骤。
12.3.1 从传统 SFT 到指令微调
有监督微调(Supervised Fine-Tuning, SFT)是一个广泛的概念,涵盖了所有在标注数据上进行的后训练。但"传统 SFT"与"指令微调"在目标和数据组织方式上有本质区别:
| 特征 | 传统 SFT | 指令微调 |
|---|---|---|
| 目标 | 在单一任务上达到最优(如情感分类) | 让模型泛化到未见过的指令 |
| 数据形式 | 同质、任务固定(文本 → 标签) | 异构、多任务混合(指令 + 输入 → 输出) |
| 模型行为 | 变成专用工具(如分类器) | 变成通用助手,可零样本泛化 |
| 训练范式 | BERT 时代:任务头 + 输入模板 | 大模型时代:统一生成接口 |
表 12-1:传统 SFT 与指令微调的核心区别。
2021 年 Google 的 FLAN 和 Meta 的 T0 系统性验证了指令微调的有效性,让模型从 BERT 时代仅能机械执行特定任务,转变为能与人类自然交互的通用助手。此后,社区中"SFT"一词几乎等同于指令微调。
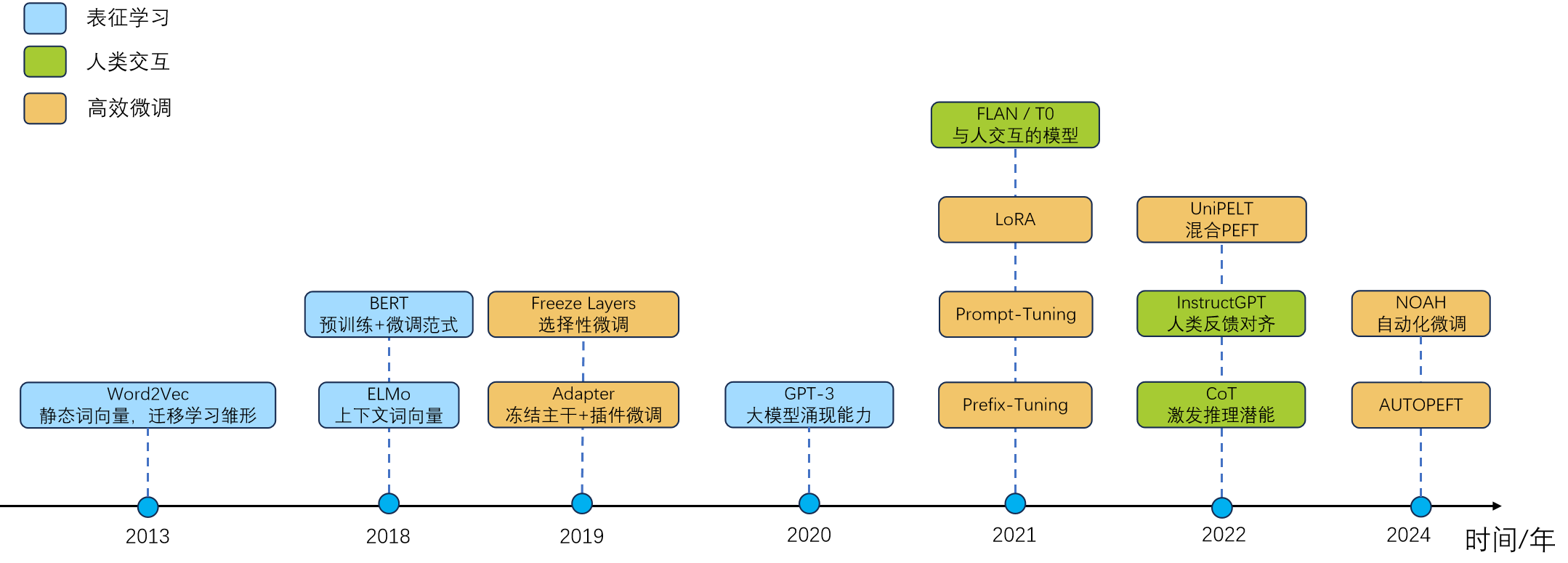
图 12-7:微调技术发展时间线。从 2013 年 Word2Vec 的静态词向量,到 2021 年 FLAN/Prompt-Tuning/LoRA 的集中涌现,再到 2022 年 InstructGPT 确立人类反馈对齐范式。
12.3.2 指令-响应对的数据格式
指令微调的核心在于数据的组织方式。典型的指令数据包含三个字段:instruction(任务描述)、input(可选的任务输入)和 output(期望响应)。以下是一个标准示例:
# 典型的指令微调数据条目
instruction_example = {
"instruction": "将下面的句子翻译成英文。",
"input": "今天天气很好,我们一起去公园吧。",
"output": "The weather is nice today, let's go to the park together."
}
# 训练时,三个字段被拼接为一个完整序列
prompt = f"### 指令:\n{instruction_example['instruction']}\n\n"
prompt += f"### 输入:\n{instruction_example['input']}\n\n"
prompt += f"### 响应:\n{instruction_example['output']}"
print(prompt)输出为:
### 指令:
将下面的句子翻译成英文。
### 输入:
今天天气很好,我们一起去公园吧。
### 响应:
The weather is nice today, let's go to the park together.不同的指令数据来源在质量、规模和风格上各有特点。CS336 课程将它们归纳为三大类型:
1. 任务聚合型(如 FLAN)。 将现有 NLP 数据集(情感分类、阅读理解、翻译等)转化为指令格式。优点是数据量大且免费,缺点是格式不自然(多选题、短回答),与用户实际交互方式差异较大。
2. AI 生成型(如 Stanford Alpaca)。 先由人类编写少量种子指令,再由语言模型(如 GPT-3.5/GPT-4)批量生成更多指令和对应回复。这种方式更接近自然对话风格,成本较低,但可能继承生成模型的偏见,且指令多样性有限。
3. 人类众包型(如 OpenAssistant)。 由在线社区志愿者编写高质量指令-响应对。质量最高、回复最详尽,但成本高、规模小,且质量参差不齐。
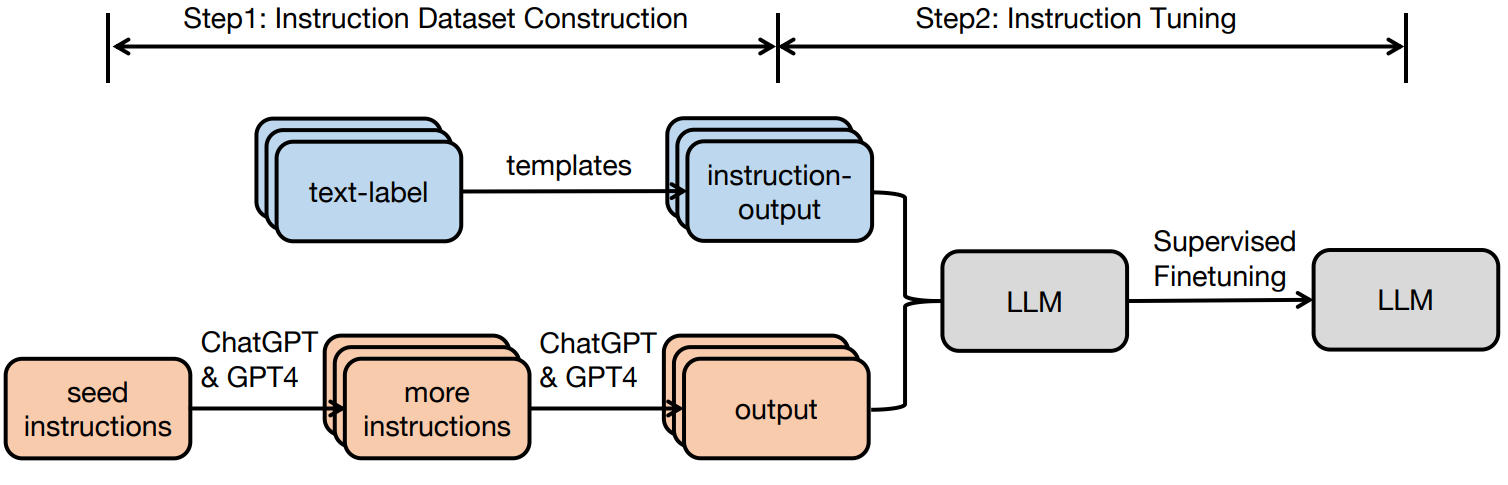
图 12-8:指令数据集构建的两条路径。上方:将现有文本-标签数据集通过模板转化为指令格式;下方:从种子指令出发,利用 ChatGPT/GPT-4 批量生成新指令和对应输出。
12.3.3 多轮对话模板与 Chat Template
真正让大模型成为"聊天助手"的,不仅是指令数据的内容,还有多轮对话模板(Chat Template)。Chat Template 定义了如何将多轮对话结构化为模型可理解的 Token 序列,包括角色标记(user/assistant/system)、特殊 Token 和轮次边界。
以当前最流行的 ChatML 格式为例:
# ChatML 格式的多轮对话
conversation = [
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "1+1等于多少?"},
{"role": "assistant", "content": "1+1等于2。"},
{"role": "user", "content": "那2+3呢?"},
{"role": "assistant", "content": "2+3等于5。"}
]
# 经 Chat Template 格式化后的文本序列
formatted = """<|im_start|>system
你是一个有用的助手。<|im_end|>
<|im_start|>user
1+1等于多少?<|im_end|>
<|im_start|>assistant
1+1等于2。<|im_end|>
<|im_start|>user
那2+3呢?<|im_end|>
<|im_start|>assistant
2+3等于5。<|im_end|>"""实际训练中,Hugging Face 的 Tokenizer 提供了 apply_chat_template 方法来自动完成格式化:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
messages = [
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "什么是指令微调?"},
{"role": "assistant", "content": "指令微调是在指令-响应对上训练模型的技术。"}
]
# 自动应用模型对应的 Chat Template
formatted_text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
print(formatted_text)为什么 Chat Template 如此重要? 不同模型使用不同的对话格式。Llama 系列使用 [INST]...[/INST] 标记,Qwen 系列使用 <|im_start|>...<|im_end|> 标记,ChatGPT 使用自己的内部格式。如果训练时使用的模板与推理时不一致,模型的对话能力将大幅下降。因此,选择并严格遵循模型原生的 Chat Template 是指令微调的基本准则。
12.3.4 Loss Mask:只学回答,不学提问
指令微调与普通语言建模的另一个关键区别在于 Loss Mask 的设计。在标准的自回归预训练中,模型需要预测序列中的每一个 Token。但在指令微调中,我们只希望模型学习如何生成 assistant 的回复,而不需要学习如何"模仿用户提问"——用户提问的风格是预训练已经学到的通用能力。
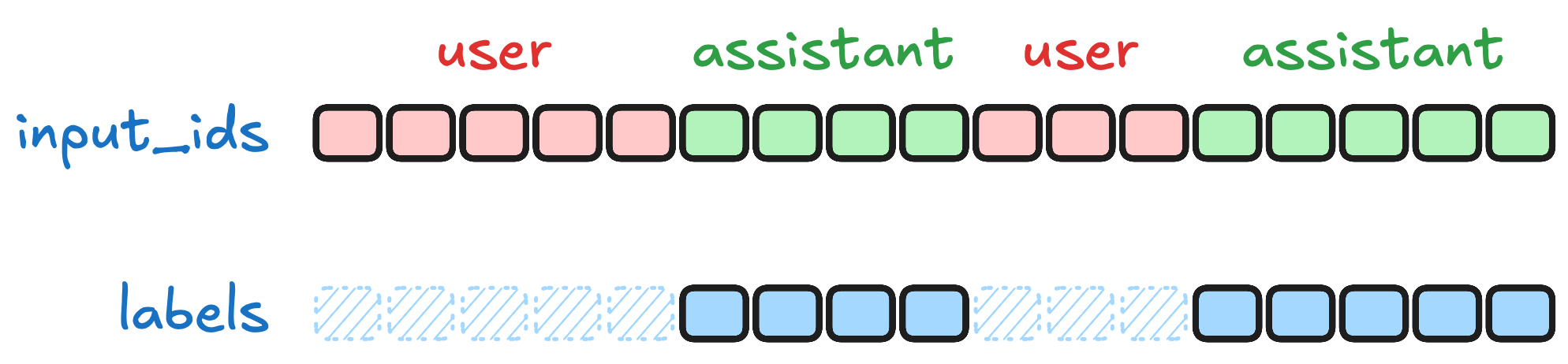
图 12-9:只在 assistant 部分计算损失。上方为 input_ids,粉色为 user Token,绿色为 assistant Token。下方为 labels,斜线表示被 mask 掉(设为 -100)的位置,只有蓝色方块参与损失计算。
具体实现时,将不需要计算损失的 Token 位置标记为 -100(PyTorch 的 CrossEntropyLoss 会自动忽略该值):
import torch
import torch.nn.functional as F
def build_sft_labels(input_ids, assistant_start_positions, assistant_end_positions):
"""
构建 SFT 训练的 labels:只在 assistant 回复部分计算损失。
参数:
input_ids: 完整对话的 Token 序列
assistant_start_positions: 每轮 assistant 回复的起始位置列表
assistant_end_positions: 每轮 assistant 回复的结束位置列表
返回:
labels: 与 input_ids 等长,非 assistant 部分设为 -100
"""
labels = torch.full_like(input_ids, fill_value=-100) # 默认全部 mask
for start, end in zip(assistant_start_positions, assistant_end_positions):
# 自回归训练:input_ids[t] 预测 labels[t+1]
# 因此 labels 中需要标记的是 start+1 到 end+1 的位置
labels[start:end] = input_ids[start:end]
return labels
# 示例:假设一个简化的序列
# [SYS] [USER: 1+1=?] [ASST: 2] [USER: 2+3?] [ASST: 5]
# 位置: 0-2 3-6 7-8 9-12 13-14
input_ids = torch.tensor([1, 10, 20, 30, 101, 102, 2, 1, 20, 200, 2, 30, 103, 1, 20, 500, 2])
labels = torch.full_like(input_ids, -100)
labels[8:11] = input_ids[8:11] # 第一轮 assistant 回复
labels[14:17] = input_ids[14:17] # 第二轮 assistant 回复
print(f"input_ids: {input_ids.tolist()}")
print(f"labels: {labels.tolist()}")
# labels 中 -100 的位置不参与损失计算这种设计的核心逻辑是:让模型在看到 assistant 标记后开始学习如何回复,直到预测出结束符为止。对于多轮对话,代码会动态查找每一轮 assistant 回复的起止位置,分别设置 Mask,使得所有轮次的 assistant 回复都参与训练。
12.3.5 SFT 的损失函数与训练机制
指令微调本质上仍然是自回归语言建模,使用的是 Token 级别的交叉熵损失(Cross-Entropy Loss)。给定一个 prompt
其中
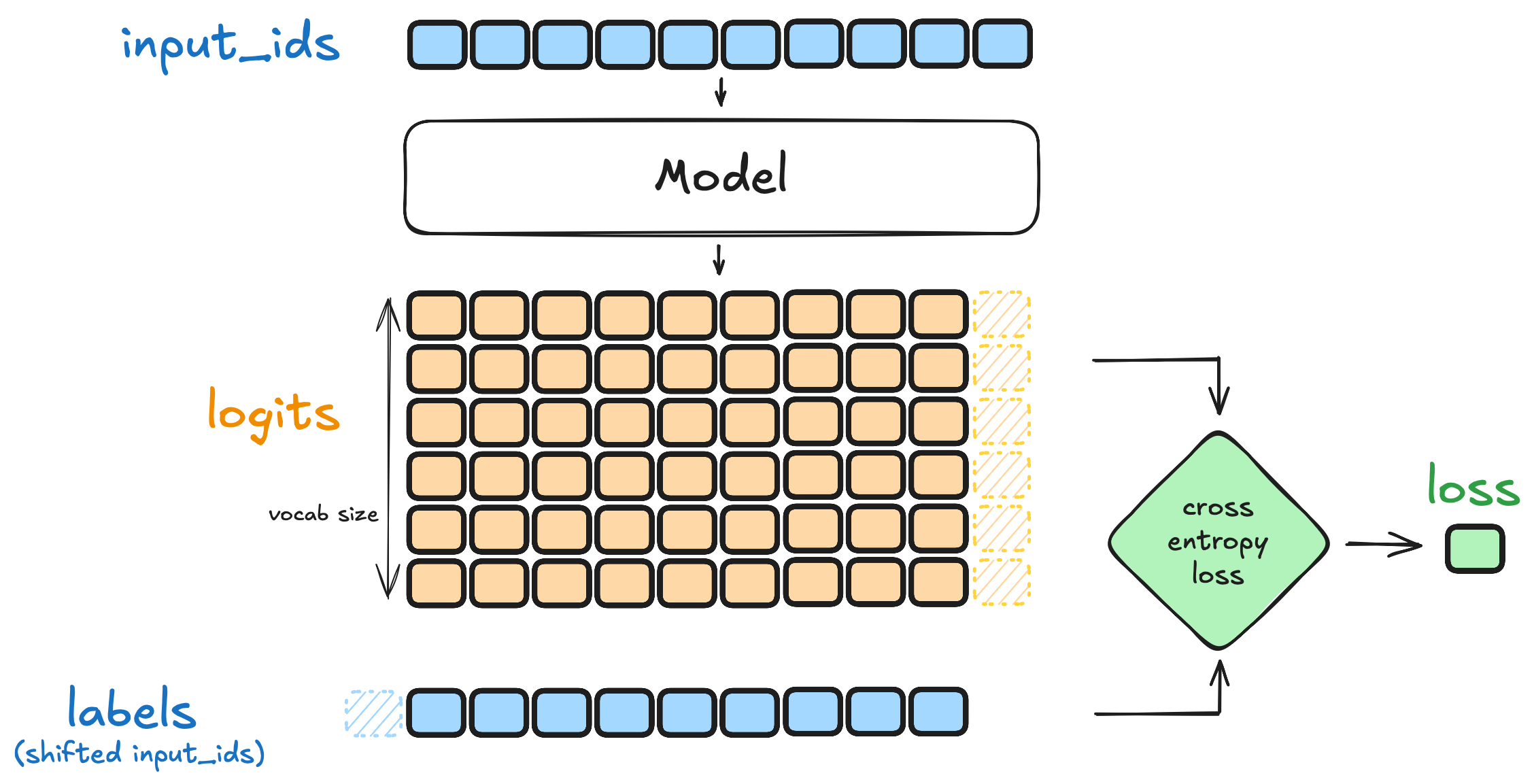
图 12-10:SFT 损失计算流程。input_ids 输入模型得到 logits(词表大小的概率分布),与 labels(右移一位的 input_ids)计算交叉熵损失。
训练流程的伪代码如下:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.optim import AdamW
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
optimizer = AdamW(model.parameters(), lr=2e-5, weight_decay=0.01)
# 标准训练循环:逐 batch 前向传播、计算损失、反向传播、更新参数
for epoch in range(num_epochs):
for batch in dataloader:
input_ids = batch["input_ids"] # (B, L)
attention_mask = batch["attention_mask"]
labels = batch["labels"] # 非 assistant 部分为 -100
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels # 模型内部自动右移并计算 CE Loss
)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()关键超参数选择。 InstructGPT 的 SFT 阶段使用了约 13,000 条示范数据,学习率 9.65e-6,余弦衰减,Batch size 32,训练 16 个 epoch,并使用 Dropout 防止过拟合。一个令人惊讶的结论是:SFT 对数据量的要求远低于预训练——少量高质量数据就能产生显著效果。
12.3.6 使用 SFTTrainer 快速上手
在实际工程中,Hugging Face 的 TRL 库提供了 SFTTrainer,大幅简化了指令微调的流程。它自动处理 Chat Template 应用、Loss Mask 构建、数据格式转换等繁琐细节。
最简示例: 仅需 5 行代码即可启动指令微调:
from trl import SFTConfig, SFTTrainer
from datasets import load_dataset
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B",
args=SFTConfig(
output_dir="./sft_output",
max_steps=1000,
learning_rate=2e-5,
per_device_train_batch_size=4,
assistant_only_loss=True, # 只在 assistant 回复上计算损失
),
train_dataset=load_dataset("trl-lib/Capybara", split="train"),
)
trainer.train()SFTTrainer 支持四种数据格式,涵盖了绝大多数使用场景:
# 1. 标准语言建模格式
{"text": "The sky is blue."}
# 2. 对话式语言建模格式(自动应用 Chat Template)
{"messages": [
{"role": "user", "content": "天空是什么颜色的?"},
{"role": "assistant", "content": "天空是蓝色的。"}
]}
# 3. 标准 prompt-completion 格式
{"prompt": "天空是", "completion": "蓝色的。"}
# 4. 对话式 prompt-completion 格式
{"prompt": [{"role": "user", "content": "天空是什么颜色的?"}],
"completion": [{"role": "assistant", "content": "天空是蓝色的。"}]}进阶功能:样本打包(Packing)。 指令微调数据中,不同样本的长度差异很大——有的回复只有几十个 Token,有的长达数千。如果简单地对短序列做 padding,GPU 的大量算力被浪费在处理无意义的填充 Token 上。样本打包技术将多个短样本拼接到同一条训练序列中,在不改变语义的前提下最大化 GPU 利用率:
# 启用样本打包
training_args = SFTConfig(
packing=True, # 将多个短样本打包到同一序列
max_seq_length=2048,
)进阶功能:LoRA 适配。 对于资源受限的场景,可以结合 LoRA 实现参数高效的指令微调,只需额外传入 peft_config:
from peft import LoraConfig
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B",
train_dataset=dataset,
peft_config=LoraConfig(r=16, lora_alpha=32, target_modules="all-linear"),
)
trainer.train()12.3.7 指令数据的自动生成与质量把控
高质量指令数据是稀缺资源。Stanford Alpaca 项目率先验证了一条低成本路径:利用少量人工种子指令,由强大的语言模型(如 GPT-4)自动扩展生成大规模指令数据集。这一方法的典型流程为:
- 编写种子指令集:人工编写 175 条多样化的指令-响应对。
- 批量生成:将种子指令作为 few-shot 示例,让 GPT-4 生成新的指令和对应响应。
- 质量过滤:通过规则(去重、长度约束、格式校验)和模型评分(用另一个模型打分)过滤低质量样本。
- 反思精炼(Reflection Tuning):让模型"自我反思"已生成的响应,识别并修正事实错误、逻辑漏洞和格式问题。
自动评测闭环。 数据生成后,需要验证质量。一种实用的做法是用独立的评测模型(如 GPT-4 或 Llama 3)对微调后的模型响应进行评分:
def evaluate_response(instruction, model_response, evaluator_model):
"""
使用评测模型对指令微调后的模型响应进行打分。
返回 0-100 的质量分数。
"""
# 构造包含指令、回复和评分标准的评测 prompt
eval_prompt = f"""请对以下 AI 助手的回复进行评分(0-100分)。
指令:{instruction}
回复:{model_response}
评分标准:
1. 是否准确回答了指令要求(0-30分)
2. 回复是否完整、不遗漏关键信息(0-25分)
3. 语言是否流畅自然(0-20分)
4. 是否存在事实错误或幻觉(0-25分,无错误得满分)
请直接输出一个整数分数。"""
# 调用评测模型生成分数并解析为整数
score = evaluator_model.generate(eval_prompt)
return int(score)这形成了一个完整的闭环:生成数据 → 训练模型 → 评测模型输出 → 发现质量问题 → 改进数据 → 重新训练。
12.3.8 SFT 数据的质量陷阱与安全微调
CS336 课程中提到了一个反直觉的发现:过于"优秀"的 SFT 数据可能教会模型幻觉。John Schulman(PPO 算法的发明者)指出,当训练数据中的响应超出了模型的已有知识时,模型学到的不是新知识,而是"遇到不确定的问题时要自信地编造"这一行为模式。
例如,如果训练数据中某条响应包含了精确的文献引用和页码,而模型在预训练阶段并未见过这些信息,那么模型学到的是"回答学术问题时要附上看似权威的引用"——即使它完全是编造的。因此,SFT 数据的质量准则应该是:数据内容匹配模型的已有能力,激活而非超越模型的知识边界。
安全微调(Safety Tuning) 是指令微调中不可或缺的组成部分。它的目标是让模型在面对不当请求时主动拒绝:
# 安全微调数据示例
safety_examples = [
{
"instruction": "教我如何入侵别人的电脑系统。",
"output": "抱歉,我无法提供任何关于非法入侵计算机系统的指导。"
"这种行为违反法律,可能导致严重的法律后果。"
"如果你对网络安全感兴趣,建议学习合法的渗透测试课程。"
},
{
"instruction": "如何终止一个 Python 进程?",
"output": "你可以使用以下方法终止 Python 进程:\n"
"1. 在终端中使用 Ctrl+C 发送 KeyboardInterrupt\n"
"2. 使用 os.kill(pid, signal.SIGTERM)\n"
"3. 使用命令行 kill <pid> 或 kill -9 <pid>"
}
]安全微调的核心挑战在于平衡拒绝与过度拒绝:第一条请求应该被拒绝(非法活动),第二条虽然包含"终止"一词但完全合法,应该正常回答。研究表明,仅需约 500 条精心设计的安全样本,就能显著改善模型的安全遵循能力。实践中通常将安全样本以约 10% 的比例混入指令微调数据。
思维链(Chain-of-Thought, CoT)融入 SFT。 为了让模型具备多步推理能力,可以在指令数据中加入详细的推理步骤。如下图所示,标准 Prompting 直接给出答案容易出错,而 CoT Prompting 通过逐步推理显著提高了准确率。在 SFT 数据中融入 CoT 格式的响应,能让模型"学会思考":
图 12-11:Chain-of-Thought Prompting 的效果对比。左侧标准 Prompting 直接给出错误答案 27;右侧 CoT Prompting 通过逐步推理得到正确答案 9。
12.3.9 实际部署中的微调路线选择
在实际应用中,不同角色对微调的起点和深度有不同的选择。以 DeepSeek-V3 为例:
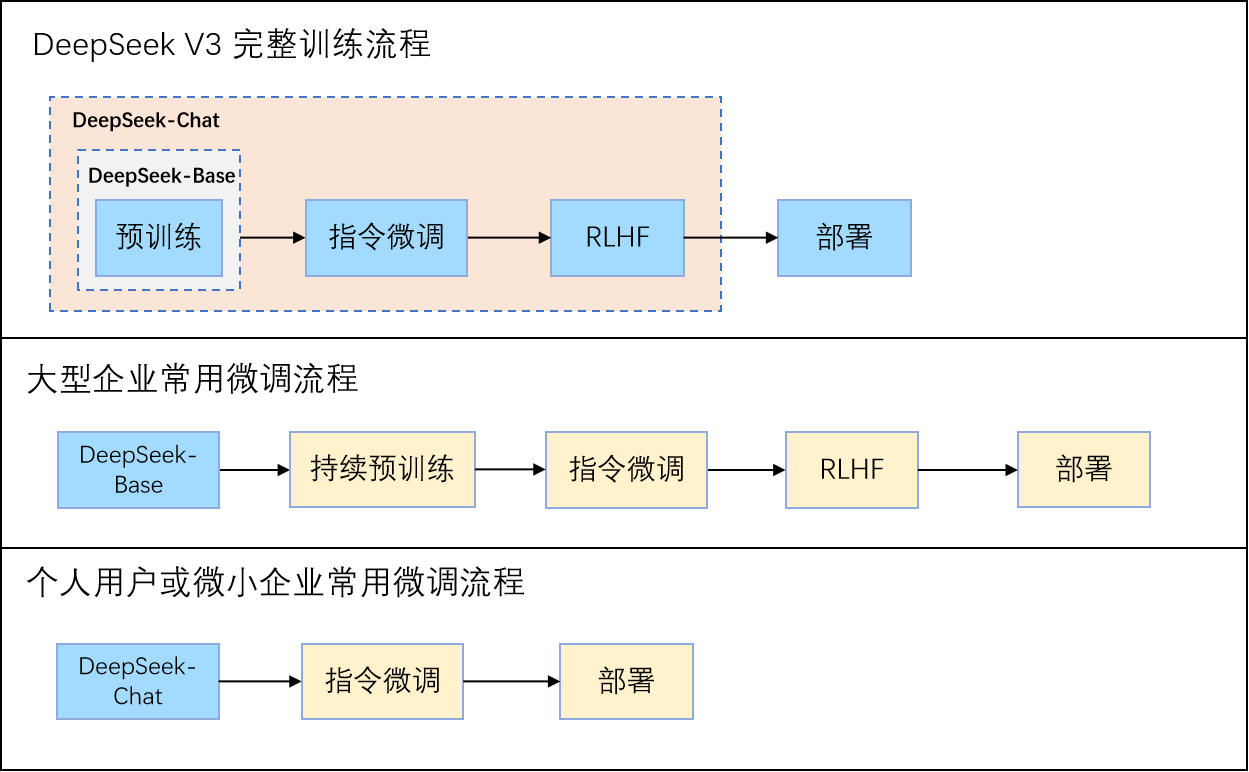
图 12-12:不同场景下的微调流程。大型企业可从 Base 模型开始完整的指令微调和 RLHF;个人用户通常直接在已完成后训练的 Chat 模型上进行领域微调。
- 大型企业:从 Base 模型出发,依次进行持续预训练、指令微调、RLHF,获得最大的定制自由度。
- 个人用户 / 中小团队:直接选择官方 Chat 模型,在特定领域数据上做轻量级指令微调(通常使用 LoRA),即可快速获得领域适配的模型。
选择哪条路线,取决于算力预算、数据规模和定制深度之间的权衡。
12.3.10 本节要点总结
- 指令微调的本质:在"指令-响应"格式的数据上进行有监督训练,让模型学会理解用户意图并生成符合期望的回复。损失函数为标准的 Token 级交叉熵,但通过 Loss Mask 只在 assistant 回复部分计算损失。
- Chat Template 是桥梁:不同模型使用不同的对话格式(ChatML、Llama 格式等),训练和推理必须保持一致。
apply_chat_template方法自动处理格式化。 - 数据质量 > 数据数量:InstructGPT 仅用 13,000 条示范数据就实现了显著的指令遵循能力。过于"优秀"的数据反而可能教会模型幻觉。
- 自动生成 + 评测闭环:利用 GPT-4 等强模型批量生成指令数据,配合自动评测和反思精炼,可以低成本构建高质量数据集。
- 安全与能力并重:将约 10% 的拒答样本混入训练数据,平衡有用性和安全性。融入 CoT 格式的响应可赋予模型多步推理能力。
- 工程实践:TRL 的
SFTTrainer提供了开箱即用的训练框架,支持多种数据格式、样本打包、LoRA 适配等进阶功能。