8.2 创新架构
前一节介绍了 Transformer 架构内部的各种效率优化——从 GQA 压缩 KV 缓存,到滑动窗口注意力降低计算量。但这些方法的共同局限在于:它们仍然在 Softmax 注意力的框架内做文章,无法从根本上突破
这些架构的共同目标是:训练时保持高效并行性,推理时实现常数内存和常数时间复杂度——即所谓"不可能三角"的同时达成。我们将从最基础的状态空间模型(SSM)理论出发,依次展开 Mamba 系列、RWKV 系列、RetNet 和线性注意力的技术脉络,最后以一张统一对比表收束全局。
8.2.1 状态空间模型(SSM):从连续系统到离散递推
状态空间模型是所有后续创新架构的数学基石。理解 SSM 的连续-离散对偶性,是理解 Mamba、RWKV 等模型设计动机的前提。
核心思想。 SSM 将序列建模问题抽象为一个线性动力系统:输入信号
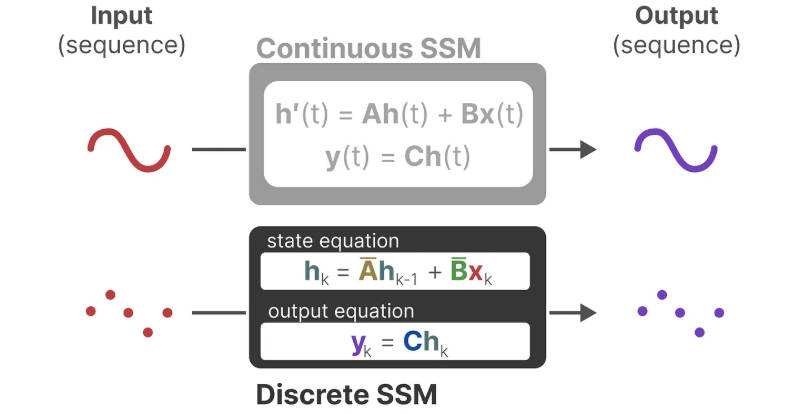
图 8-5:状态空间模型的连续形式与离散形式。上方为连续时间 SSM,通过微分方程
[选读] 连续到离散的完整推导。 连续时间 SSM 由四个参数
为了在数字计算机上处理离散序列,需要将连续系统离散化。最常用的方法是零阶保持(Zero-Order Hold, ZOH),其假设输入信号在每个离散步长
当
三种等价计算形式。 离散 SSM 具有三种等价的计算形式,这一性质是后续所有架构设计的基础:
- 递推形式(Recurrent):逐步更新
,适合自回归推理——每步 时间和内存。 - 卷积形式(Convolutional):将递推展开,输出
可表示为输入 与核 的卷积,适合并行训练。 - 并行扫描形式(Parallel Scan):利用前缀和算法在 GPU 上高效并行计算递推,时间复杂度
。
S4(Structured State Space for Sequence modeling)是将 SSM 成功应用于深度学习的里程碑工作。它通过对
LTI 的局限性。 S4 及其变体均属于线性时不变(Linear Time-Invariant, LTI)系统——参数
8.2.2 Mamba 系列:选择性状态空间与状态空间对偶
Mamba:选择性 SSM。 Mamba 的核心洞察是:让 SSM 参数成为输入的函数,从而将 LTI 系统升级为时变(time-varying)系统。具体而言,Mamba 将
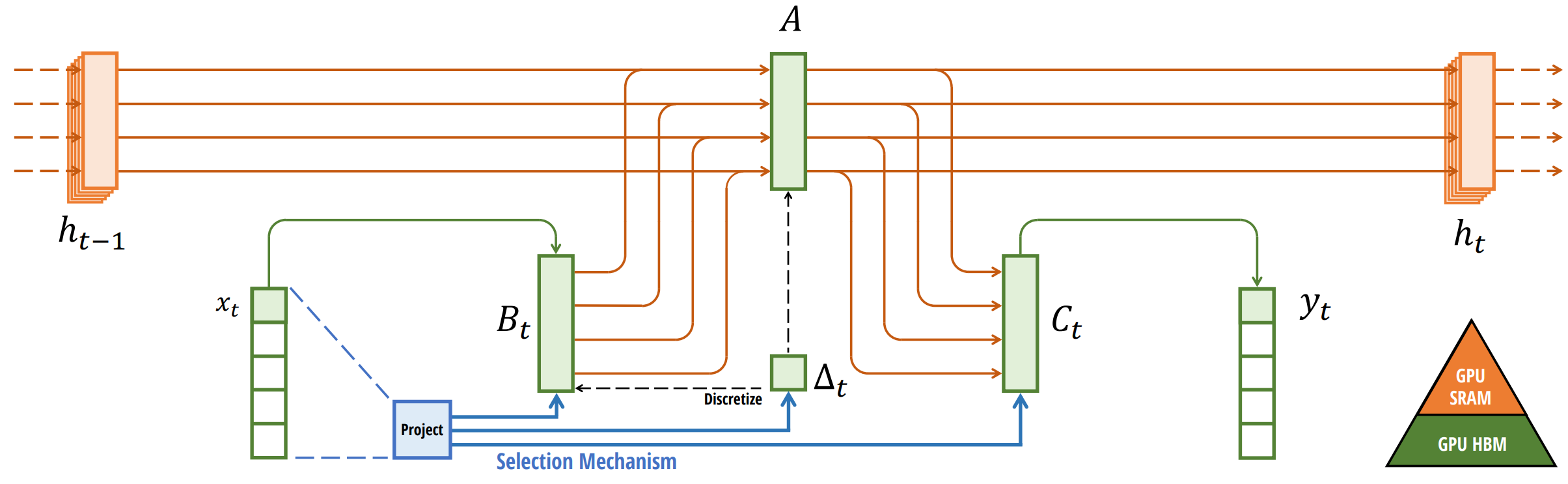
图 8-6:Mamba 的选择性状态空间模型架构。输入
这一修改的语义直觉是:
选择性带来的代价是:参数不再是时不变的,卷积形式不再适用。Mamba 通过一个精心设计的硬件感知并行扫描算法(hardware-aware parallel scan)解决了这一问题——该算法在递推模式下执行计算,但通过控制 GPU 不同层级存储之间的数据搬运(避免将扩展状态
架构简化。 Mamba 同时对网络拓扑做了激进的简化:去掉了独立的 MLP 块,将 SSM 层与门控线性投影融合为单一的"Mamba Block"——输入经过线性投影扩展维度后,一路经因果卷积和 SSM 处理,另一路作为门控信号,最终逐元素相乘后投影回原始维度。这种设计使整个架构成为一个同质化的堆叠,而非 Transformer 中注意力层与 FFN 层的交替。
Mamba-2:状态空间对偶。 Mamba-2 揭示了 SSM 与线性注意力之间的深层联系——状态空间对偶(State Space Duality, SSD)。其核心递推为:
其中
等价地写成矩阵形式:
Mamba-2 还将
Gated Delta Networks(GDN)。 GDN 将两种互补的记忆管理机制——门控衰减与 Delta 规则——融合为一个统一的更新规则。其核心递推为:
其中
两种机制的互补性在于:门控衰减
Qwen3.5 模型已经将 Gated DeltaNet 作为线性注意力层的核心组件投入量产,标志着这一机制从研究论文正式进入工业级部署。
8.2.3 RWKV 系列:从 RNN 复兴到广义 Delta 规则
RWKV(Receptance Weighted Key Value)是一条独立于 Mamba 的技术路线,由彭博(Bo Peng)发起并开源于 Linux 基金会。RWKV 的设计哲学与 Mamba 殊途同归:训练时像 Transformer 一样并行,推理时像 RNN 一样高效——但其技术路径从线性注意力的变形出发,而非从连续状态空间模型。经过七代迭代,RWKV 的状态演化规则从简单的标量衰减逐步升级为广义 Delta 规则,表达能力持续逼近甚至超越同规模 Transformer。
RWKV-4(Dove):元素级衰减与通道方向注意力。 RWKV 的命名源自其四个核心组件:Receptance(R,接受度门控)、Weight(W,位置权重衰减)、Key(K)和 Value(V)。RWKV-4 的时间混合(time-mixing)模块核心递推为:
其中
RWKV-4 的关键特征是:(1)衰减
| 特性 | 推理时间复杂度 | 推理空间复杂度 | 训练时间复杂度 | 训练并行性 |
|---|---|---|---|---|
| Transformer | 可并行 | |||
| Linear Transformer | 可并行 | |||
| RWKV / Mamba / RetNet | 可并行 |
表 8-4:RWKV 与 Transformer 的复杂度对比。
RWKV-5(Eagle):矩阵级状态。 RWKV-5 的核心升级是将向量级状态扩展为矩阵级状态(matrix-valued states),递推变为:
其中
RWKV-6(Finch):数据相关的动态衰减。 RWKV-6 的关键突破是将固定衰减升级为数据相关的动态衰减:
其中
从 RWKV-5 到 RWKV-6 的演进,在更广泛的架构谱系中也与 GLA(Gated Linear Attention)完全对齐——两者的状态递推公式
RWKV-7(Goose):广义 Delta 规则。 RWKV-7 是截至目前最先进的 RWKV 版本,其核心递推引入了广义 Delta 规则:
与 RWKV-6 的
RWKV-7 的几项关键创新:
- 向量级门控。 状态转移矩阵的特征值可以超出
区间(即广义特征值,Generalized Eigenvalue),赋予了模型隐式的位置编码能力——不同通道可以产生振荡性的记忆模式,而非单调衰减。 - 解耦的擦除键与写入键。 在标准 Delta 规则中,擦除和写入使用同一个键
;RWKV-7 将两者解耦为独立的 和 ,增加了记忆操作的灵活性。 - 超越
的表达能力。 理论证明表明,RWKV-7 仅用常数层即可识别所有正则语言,这超越了标准 Transformer 在广泛接受的复杂性猜想( )下的能力上限。
实验结果显示,2.9B 参数的 RWKV-7 在多语言任务上达到了 3B 规模的新 SoTA,在英语下游任务上匹配当前 3B 最佳水平——尽管其训练 token 数远少于同级别的 Llama-3.2-3B 和 Qwen2.5-3B。
8.2.4 RetNet:递推式注意力与三种计算范式
RetNet(Retentive Network)由微软研究院提出,其核心贡献是设计了一种保留机制(Retention),同时支持并行、递推和分块递推三种计算范式——直接对应训练、推理和长序列处理三个场景。
从递推推导并行形式。 RetNet 的出发点是一个标准的线性递推:
将
其中
三种计算范式。
- 并行形式(训练用):
,与 Softmax 注意力形式相似,可充分利用 GPU 矩阵乘法加速,但将 Softmax 替换为确定性的指数衰减掩码 。 - 递推形式(推理用):
, 。推理时只需维护一个 的状态矩阵 ,内存和计算均为 ——无需 KV 缓存,解码延迟与序列长度无关。 - 分块递推形式(长序列训练用):将序列划分为大小为
的块,块内用并行形式计算,块间用递推传递状态。兼顾了训练速度和内存效率。
多尺度保留(Multi-Scale Retention)。 RetNet 为不同的注意力头分配不同的衰减系数
RetNet 在 7B 规模的实验中,解码速度是 Transformer 的 8.4 倍,内存节省 70%。然而,RetNet 的衰减系数
8.2.5 线性注意力:理论基础与核心变体
线性注意力是上述所有创新架构的最底层数学抽象。理解其核心技巧——利用矩阵乘法结合律改变计算顺序——是理解整个领域的钥匙。
从 Softmax 注意力到核化注意力。 标准 Softmax 注意力的第
将
关键的复杂度跃迁发生在这一步:原始公式必须先计算
因果线性注意力与 RNN 等价。 对于自回归场景,需要施加因果约束:第
这正是一个隐状态为矩阵
核函数的选择。 特征映射
(原始线性注意力论文的选择) (Random Feature Attention 的简化) - 直接去掉
,在 、 上施加 L2 归一化或 RMSNorm,确保内积有界
性能差距与弥补策略。 朴素的线性注意力在语言建模上显著弱于 Softmax 注意力。根本原因是:状态矩阵
后续研究沿三条路线弥补这一差距:
- 引入衰减项。
(RetNet、Mamba-2)。衰减使模型主动遗忘旧信息,缓解记忆饱和,但代价是远程信息被指数级衰减。 - 引入 Delta 规则。
(DeltaNet)。通过"先删后写"实现精确替换,提升检索能力,但缺乏快速清空记忆的机制。 - 融合两者。
(Gated DeltaNet、RWKV-7)。兼具全局衰减和选择性更新,是当前性能最强的线性注意力变体。
8.2.6 统一对比与设计谱系
下表将本节讨论的所有架构置于同一坐标系下对比:
| 架构 | 状态演化公式 | 衰减类型 | 动态依赖 | 状态规模 | 广义特征值 |
|---|---|---|---|---|---|
| RWKV-4 | 静态标量 | 否 | 向量 | 否 | |
| RetNet | 静态标量 | 否 | 矩阵 | 否 | |
| RWKV-5 | 静态向量 | 否 | 矩阵 | 否 | |
| Mamba | 动态 | 是 | 矩阵 | 否 | |
| RWKV-6 / GLA | 动态向量 | 是 | 矩阵 | 否 | |
| Mamba-2 | 动态标量 | 是 | 矩阵 | 否 | |
| DeltaNet | Delta 规则 | 是 | 矩阵 | 否 | |
| Gated DeltaNet | 门控 + Delta | 是 | 矩阵 | 是 | |
| RWKV-7 | 广义 Delta | 是 | 矩阵 | 是 |
表 8-5:创新架构的状态演化规则统一对比。"动态依赖"指衰减项是否随输入变化;"广义特征值"指状态转移矩阵的特征值是否可超出
从这张表中可以提炼出三条清晰的演进主线:
主线一:从静态到动态。 RWKV-4/5 和 RetNet 使用固定衰减,Mamba 和 RWKV-6 将衰减变为输入的函数——这是性能提升最显著的单一改进。动态衰减使模型获得了"选择性注意力"——面对信息密度不均的文本时,可以在重要 token 处减缓衰减、在冗余 token 处加速遗忘。
主线二:从标量到矩阵。 RWKV-4 的向量状态到 RWKV-5 的矩阵状态,Mamba-2 的标量衰减到 GLA 的对角矩阵衰减——状态规模和衰减结构的精细度持续提升。更大的状态意味着更多的记忆容量,更精细的衰减意味着更灵活的遗忘策略。
主线三:从加性更新到 Delta 更新。 前期模型仅做"加性写入"(
8.2.7 总结
本节从状态空间模型的数学基础出发,系统梳理了 Transformer 之外的创新序列建模架构。几个核心结论值得铭记:
SSM 是数学基石,不是架构本身。 连续 SSM 的离散化产生了线性递推,线性递推与线性注意力通过状态空间对偶(SSD)联系在一起。Mamba、RWKV、RetNet 看似路径不同,但在统一的数学框架下可以写成同一族状态递推公式的不同参数化——它们之间的差异主要在于"衰减结构"和"更新规则"这两个维度上的设计选择。
"不可能三角"已被打破。 RetNet 首先提出、Mamba 和 RWKV 进一步验证了一个关键事实:训练并行性、推理效率和模型质量可以同时达成。这三族架构均实现了
训练、 推理,并在语言建模基准上逼近或匹配同规模 Transformer。 纯替代尚未成功,混合是务实路径。 尽管理论上这些架构可以完全替代 Transformer,但工业实践中更常见的是混合策略——如 Qwen3.5 用 Gated DeltaNet 处理 75% 的层、用 Softmax 注意力处理 25% 的层。其原因在于:线性注意力在"精确远程匹配"这一能力上仍有本质短板(状态矩阵的秩限制),少量全局注意力层可以以极低的代价弥补这一缺陷。
推理效率优势随序列增长而放大。 这些架构的核心价值不在短序列——对于 2K-4K 长度的文本,Softmax 注意力配合 FlashAttention 已经足够高效。真正的优势场景是超长序列(64K+)和端侧部署:前者因为 KV 缓存的线性增长使 Transformer 的内存消耗不可承受,后者因为内存和算力预算极为有限。RWKV-7 在 GPU 上的推理能耗比同规模 Transformer 低约 30%,在未来存内计算芯片上有望进一步扩大这一优势。
创新架构的竞赛远未结束。从 RWKV-7 的广义 Delta 规则到 Titans 的双状态记忆系统,状态递推的表达能力仍在快速提升。但竞赛的终极评判标准不是理论复杂度,而是在同等训练计算预算下的下游任务质量——在这个维度上,Transformer 凭借其海量的工程优化积累和成熟的 scaling law 理解,仍然是需要追赶的标杆。