17.2 思维链提示(Chain-of-Thought)
上一节介绍了 Prompt Engineering 的基本范式——通过精心设计提示词来引导模型输出。但面对需要多步推理的复杂任务(如数学证明、逻辑推演),仅靠 few-shot 示例给出"问题-答案"对往往不够:模型倾向于直接跳到答案,跳过中间推导过程,导致正确率低下。思维链提示(Chain-of-Thought Prompting, CoT) 正是为解决这一瓶颈而提出的关键技术——它通过在提示中展示或激发中间推理步骤,让模型"一步一步地思考",从而显著提升复杂推理任务的表现。
本节将从 CoT 的核心思想出发,依次介绍 Few-shot CoT、Zero-shot CoT 的原理与实现,结合实验数据分析其效果,并讨论 CoT 在推理模型训练中的延伸应用。
17.2.1 从直觉到形式:CoT 的核心思想
人类在解决复杂问题时,很少一步到位。比如面对一道应用题,我们会先理解题意、列出等式、逐步化简,最后得到答案。CoT 的核心洞察是:如果在提示中展示这种分步推理的过程,模型也会学着生成类似的推理链,而非直接给出答案。
下图对比了标准提示与 CoT 提示的差异。左侧的标准提示仅在 few-shot 示例中给出最终答案,模型看到问题后直接跳到结论,回答错误。右侧的 CoT 提示在示例中加入了中间推理步骤(蓝色高亮部分),模型因此也展开了逐步推导,最终得到正确答案。
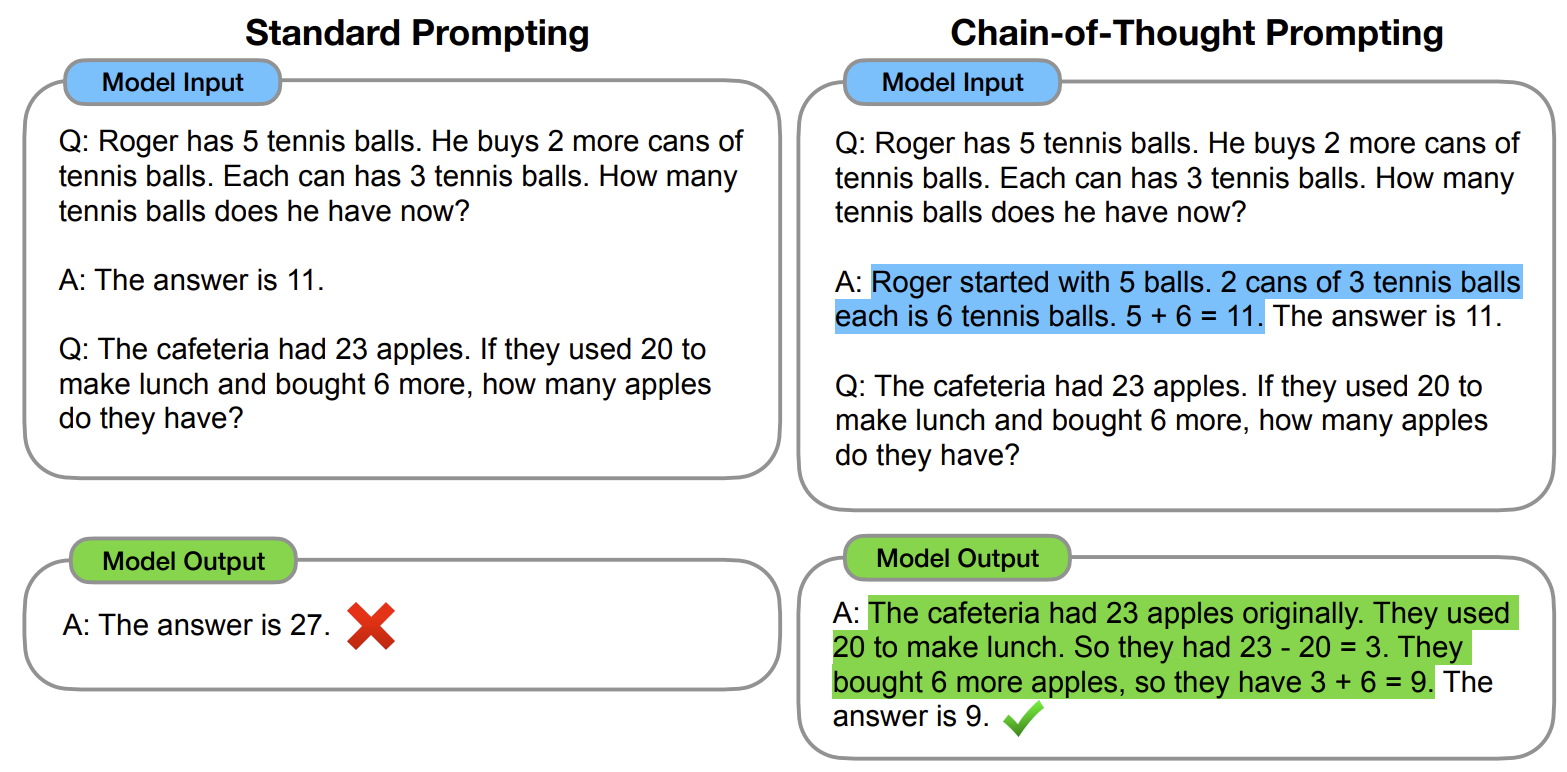
图 17-3:标准提示(左)与思维链提示(右)的对比。CoT 提示在 few-shot 示例中加入中间推理步骤,引导模型展开逐步推导。来源:Wei et al. (2022)。
这一想法由 Wei et al. (2022) 在论文 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" 中系统提出。他们的实验表明,在 GSM8K(小学数学)、StrategyQA(常识推理)等基准上,CoT 提示可以将大语言模型的准确率提升数十个百分点,且模型规模越大,CoT 的增益越显著——这与涌现能力(Emergent Ability)的观察一致。
17.2.2 Few-shot CoT:手工构造推理链
最直接的 CoT 实现方式是 Few-shot CoT:在提示中提供若干"问题 + 推理步骤 + 答案"的完整示例,让模型通过上下文学习(In-context Learning)模仿这种推理模式。
下面是一个典型的 Few-shot CoT 提示构造示例:
def build_fewshot_cot_prompt(question: str) -> str:
"""构造 Few-shot CoT 提示:2 个手工推理示例 + 待解问题"""
fewshot_examples = """Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 2 * 3 = 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
"""
return fewshot_examples + f"Q: {question}\nA:"
# 使用示例
question = "Half the value of 3x-9 is x+37. What is the value of x?"
prompt = build_fewshot_cot_prompt(question)
print(prompt)关键设计要点:
- 示例中包含完整推理链。每个示例不仅给出最终答案,还展示了从题目到答案的逐步推导过程。这是 CoT 与普通 few-shot 的本质区别。
- 推理步骤要具体且可验证。"Roger started with 5 balls. 2 cans of 3 tennis balls each is 2 * 3 = 6" 比模糊的 "计算一下可得" 更有效。
- 示例数量通常 2-8 个即可。过多示例会占用上下文窗口,过少则模型难以稳定习得推理模式。
- 答案格式统一。使用固定格式(如
The answer is X或\boxed{X})方便后续提取最终答案。
17.2.3 Zero-shot CoT:"Let's think step by step"
Few-shot CoT 需要为每类任务手工编写推理示例,这限制了其通用性。Kojima et al. (2022) 发现了一个令人惊讶的事实:仅需在问题后附加一句简单的提示语 "Let's think step by step",大语言模型就能在零样本条件下自动生成推理链。 这种方法被称为 Zero-shot CoT。
Zero-shot CoT 的实现极为简洁:
def build_zeroshot_cot_prompt(question: str) -> str:
"""构造 Zero-shot CoT 提示"""
system = (
"You are a helpful math assistant.\n"
"Answer the question and write the final result "
"on a new line as:\n\\boxed{ANSWER}\n"
)
return f"{system}\nQuestion:\n{question}\n\nAnswer:\n\nExplain step by step."
# 使用示例
question = "Half the value of 3x-9 is x+37. What is the value of x?"
prompt = build_zeroshot_cot_prompt(question)
print(prompt)在 MATH-500 基准测试(500 道竞赛级数学题)上,使用 Qwen3-0.6B 基座模型的实验结果如下:
| 方法 | 准确率 | 耗时 |
|---|---|---|
| 标准提示(贪心解码) | 15.2% | 10.1 min |
| Zero-shot CoT(添加 "Explain step by step.") | 40.6% | 84.5 min |
| 专用推理模型(贪心解码) | 48.2% | 182.1 min |
表 17-1:CoT 提示对 MATH-500 准确率的影响。数据来自 Raschka (2025) 在 DGX Spark 上的实验。
仅添加一句提示语,准确率就从 15.2% 跃升至 40.6%——接近专用推理模型的水平,而无需任何模型训练或微调。这验证了 CoT 的核心价值:通过增加推理时的计算量(生成更多中间 Token),可以用同一个模型换取显著更高的推理准确率。
为什么 CoT 有效? 直觉上,语言模型本质上是一个自回归的 Token 预测器,每生成一个 Token 相当于执行一次固定计算量的前向传播。对于需要多步推理的复杂问题,模型无法在单次前向传播中完成求解。CoT 通过让模型生成中间推理步骤,实质上是将一个复杂问题分解为多个简单的"单步预测",每一步的输出成为下一步推理的输入上下文——这使得模型能在有限的单步计算能力下,通过链式推理解决远超其"单步能力"的问题。
17.2.4 CoT 实战:从提示构造到答案提取
下面给出一个完整的、可运行的 CoT 推理流程,包含提示构造、模型调用和答案提取三个环节:
import re
def extract_boxed_answer(text: str) -> str:
"""从模型输出中提取 \\boxed{...} 格式的答案"""
pattern = r"\\boxed\{([^}]*)\}"
matches = re.findall(pattern, text)
return matches[-1].strip() if matches else text.strip().split("\n")[-1]
def cot_solve(question: str, call_llm_func, use_cot: bool = True) -> dict:
"""
使用 CoT 提示解决数学问题的完整流程。
参数:
question: 待解问题的文本
call_llm_func: 调用语言模型的函数,签名为 f(prompt) -> str
use_cot: 是否使用 CoT 提示
返回:
包含 prompt、full_response、extracted_answer 的字典
"""
system = (
"You are a helpful math assistant.\n"
"Answer the question and write the final result "
"on a new line as:\n\\boxed{ANSWER}\n"
)
prompt = f"{system}\nQuestion:\n{question}\n\nAnswer:\n"
if use_cot:
prompt += "\nExplain step by step."
# 调用模型生成
response = call_llm_func(prompt)
# 提取最终答案
answer = extract_boxed_answer(response)
return {
"prompt": prompt,
"full_response": response,
"extracted_answer": answer
}
# 模拟调用示例(实际使用时替换为真实 LLM 调用)
def mock_llm(prompt: str) -> str:
"""模拟 LLM 生成的 CoT 推理过程"""
return (
"To solve: half the value of 3x-9 is x+37.\n\n"
"Step 1: Write the equation.\n"
" (1/2)(3x - 9) = x + 37\n\n"
"Step 2: Multiply both sides by 2.\n"
" 3x - 9 = 2x + 74\n\n"
"Step 3: Subtract 2x from both sides.\n"
" x - 9 = 74\n\n"
"Step 4: Add 9 to both sides.\n"
" x = 83\n\n"
"\\boxed{83}"
)
result = cot_solve(
"Half the value of 3x-9 is x+37. What is the value of x?",
call_llm_func=mock_llm,
use_cot=True
)
print(f"提取的答案: {result['extracted_answer']}")
# 输出: 提取的答案: 83这个流程展示了 CoT 工程化的三个核心环节:(1) 提示构造——在系统指令中指定答案格式,在用户提示末尾添加 CoT 触发语;(2) 推理生成——模型自行展开分步推导;(3) 答案提取——用正则表达式从推理链末尾提取结构化答案。
17.2.5 CoT 的变体与增强技术
CoT 的基本思想催生了一系列增强技术,进一步提高推理质量:
自动化 CoT(Auto-CoT)。 Zhang et al. (2023) 提出通过聚类和自动生成的方式替代手工编写 few-shot 示例,降低了 Few-shot CoT 的人力成本,同时通过多样化示例避免了人工偏差。
最少到最多提示(Least-to-Most Prompting)。 Zhou et al. (2023) 提出先将复杂问题分解为若干子问题,再逐一解决的策略。与标准 CoT 的线性推理链不同,Least-to-Most 形成了一种层次化的推理结构,特别适合需要组合泛化(Compositional Generalization)的任务。
多路径 CoT 与自一致性。 Wang et al. (2023) 提出的自一致性(Self-Consistency)方法,通过采样多条推理路径并对最终答案进行多数投票(Majority Voting),显著提升了 CoT 的鲁棒性。在 MATH-500 上的实验显示:
| 方法 | 准确率 | 耗时 |
|---|---|---|
| CoT(单路径) | 40.6% | 84.5 min |
| CoT + 自一致性 (n=3) | 42.2% | 211.6 min |
| CoT + 自一致性 (n=5) | 48.0% | 452.9 min |
| CoT + 自一致性 (n=10) | 52.0% | 862.6 min |
表 17-2:CoT 与自一致性的组合效果。随着采样路径数增加,准确率持续提升,但计算开销也线性增长。
自一致性的核心思想是"正确答案比错误答案更容易被多条推理路径独立发现"。当采样路径从 3 增加到 10 时,基座模型的准确率从 42.2% 提升到 52.0%,甚至超过了专用推理模型(48.2%)。但计算开销也随之线性增长——这本质上是推理时间缩放(Test-Time Scaling)的一个典型体现。关于自一致性的详细实现,将在 §17.4 中深入讨论。
17.2.6 CoT 在推理模型中的角色
CoT 的影响力远不止于提示工程。在推理模型(Reasoning Model)的训练中,CoT 既是训练数据的核心组成,也是模型行为的触发机制。
作为训练数据。 监督微调(SFT)阶段,训练数据通常包含完整的推理轨迹(Reasoning Trace),本质上就是高质量的 CoT。模型通过学习这些推理轨迹,内化了"分步思考"的能力。
作为强化学习的提示模板。 在 DeepSeek-R1-Zero 的训练中,研究者设计了一种结构化的 CoT 提示模板,将推理过程封装在 <think> 和 </think> 标签之间,答案封装在 <answer> 和 </answer> 标签之间:

图 17-4:DeepSeek-R1-Zero 使用的结构化提示模板。该模板通过 <think> 标签引导模型先进行推理,再给出答案。改编自 DeepSeek-R1 技术报告 (DeepSeek-AI, 2025)。
这个设计的关键在于:模型在强化学习训练过程中,必须先在 <think> 区域展开推理,再在 <answer> 区域给出答案。奖励信号仅基于最终答案的正确性计算,但模型会自发地学会利用 <think> 区域进行越来越长、越来越精细的推理——随着训练的推进,平均响应长度从数百 Token 增长到近万 Token。这意味着 CoT 不仅是一种提示技巧,更是推理模型内在能力的基石。
17.2.7 CoT 的局限与适用边界
尽管 CoT 效果显著,但它并非万能:
对小模型效果有限。 CoT 的增益与模型规模强相关。在参数量低于约 10B 的模型上,CoT 的提升通常不明显,有时甚至可能降低准确率——小模型缺乏足够的内在知识来支撑多步推理。
推理步骤未必忠实反映模型内部计算。 模型生成的推理链是一种"可解释性叙事",但不一定反映其真实的内部表征。模型可能在某些情况下生成看似合理但实际上逻辑跳跃的推理链,并依然给出正确答案。
计算开销线性增长。 CoT 要求生成大量中间 Token,推理延迟和成本显著增加。如表 17-1 所示,CoT 将推理时间从 10.1 分钟增加到 84.5 分钟——这是"用计算换准确率"的直接体现。
对简单任务可能过度推理。 不需要多步推理的任务(如情感分类、简单检索),使用 CoT 反而可能引入不必要的推理步骤,增加出错风险和延迟。
因此,CoT 最适合需要多步推理的复杂任务——数学推导、逻辑推理、代码调试、规划任务等。对于简单任务,标准提示即可。
本节总结
思维链提示(CoT)的核心思想是引导模型生成中间推理步骤而非直接跳到答案。Few-shot CoT 通过在示例中展示推理链来引导模型,Zero-shot CoT 则仅需添加 "Let's think step by step" 即可激活模型的推理能力。实验表明,CoT 可以将 0.6B 参数的基座模型在 MATH-500 上的准确率从 15.2% 提升至 40.6%。CoT 还可与自一致性等技术组合,进一步提升准确率至 52.0%。更重要的是,CoT 不仅是一种提示工程技巧,它已成为推理模型训练的核心机制——无论是 SFT 阶段的推理轨迹数据,还是 RL 阶段的结构化提示模板,都以 CoT 为基础。下一节将深入讨论采样多样性控制(温度缩放与 Top-p 采样),它们是实现多路径 CoT 和自一致性投票的关键技术基础。