3.3 旋转位置编码(RoPE)
Transformer 的自注意力机制本质上是一个集合操作——它对输入 token 的处理与顺序无关。如果不注入位置信息,模型无法区分"猫追狗"和"狗追猫"。早期方法或是学习绝对位置向量再加到词嵌入上(如 BERT、GPT-2),或是使用固定的正弦余弦编码(如原始 Transformer),但这些方案在长度泛化方面均存在明显短板。
旋转位置编码(Rotary Position Embedding, RoPE)由 Su 等人(2021)在 RoFormer 中提出,其核心洞察是:通过对 Query 和 Key 向量施加与位置相关的旋转操作,使得两者内积自动包含相对位置信息。RoPE 不引入任何额外的可训练参数,形式简洁,且天然具备远程衰减特性。自 LLaMA 以来,RoPE 已成为几乎所有主流大语言模型(LLaMA、Mistral、Qwen、DeepSeek 等)的标准配置。
本节将从复数与旋转矩阵的数学基础出发,完整推导 RoPE 的数学形式,然后介绍面向长上下文场景的一系列扩展方案。
3.3.1 数学前置:复数与二维旋转 [必读]
理解 RoPE 需要一个关键的数学事实:复数乘法等价于二维旋转。本小节对此进行简要回顾。
复数的极坐标表示。 复数
其中
复数乘法的几何意义。 两个复数相乘时,模长相乘、辐角相加:
特别地,将一个复数乘以
与二维旋转矩阵的等价性。 设
写成矩阵形式,恰好对应标准的二维旋转矩阵:
旋转矩阵
- 结合性:
。 - 正交性:
,即转置等于逆旋转。
点积的复数视角。 两个二维向量的点积可以用复数表示为:
若分别对两个复数施加旋转
关键结论:旋转后的点积只依赖于角度差
3.3.2 RoPE 的数学推导 [必读]
有了上述数学工具,RoPE 的构造思路就十分自然了。
设计目标。 我们需要一种位置编码函数
二维情形。 根据 3.3.1 节的分析,如果将二维向量视为复数,对位置
内积确实只依赖于
推广到高维:分块对角旋转矩阵。 实际模型中,Query 和 Key 向量的维度
具体地,定义位置
其中每个
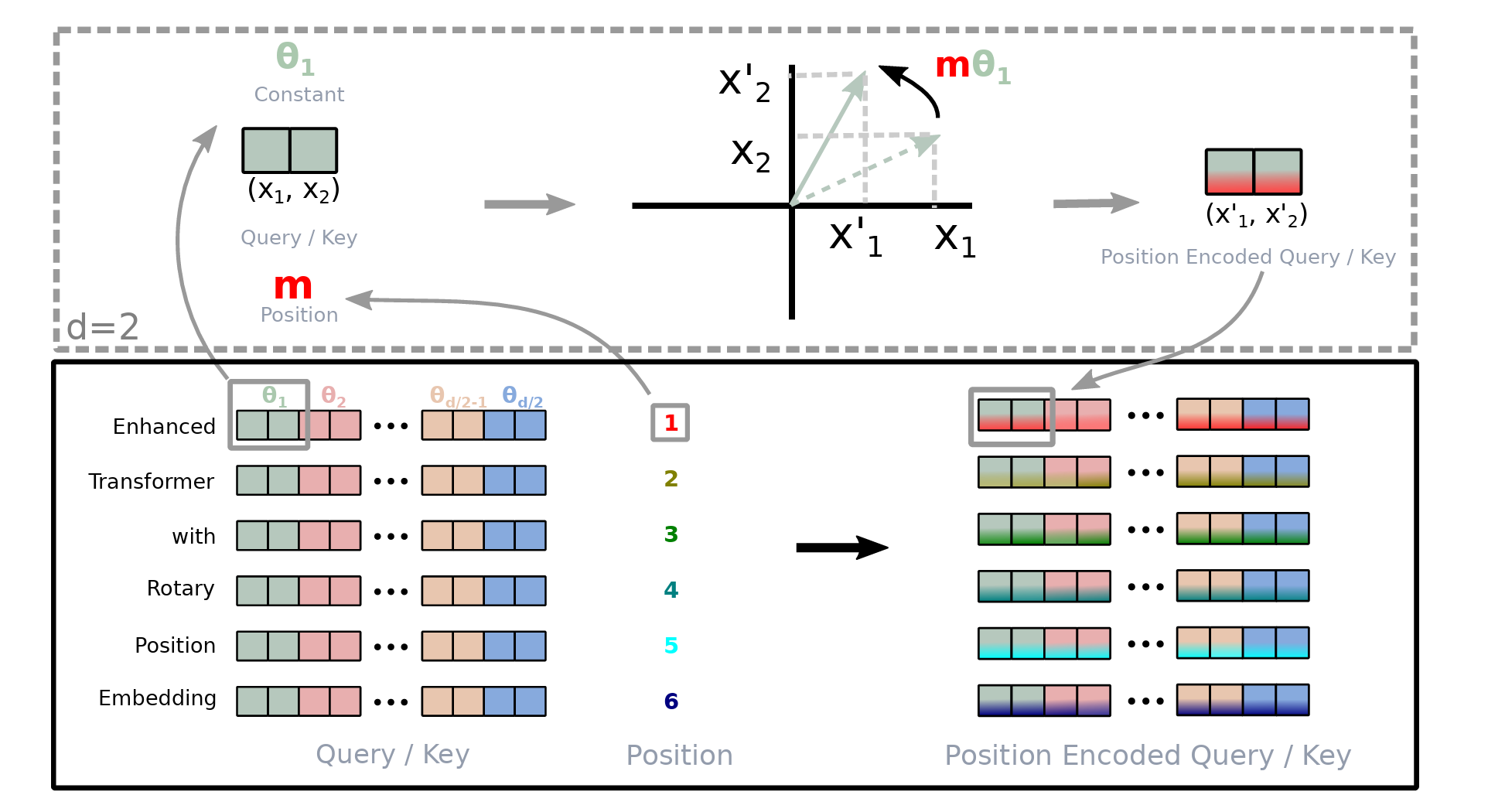
图 3-5:RoPE 的工作原理。上半部分展示单个二维子空间中,向量
将输入向量
频率的选取。 第
其中
时, ,角频率最高,对应最短波长——位置每变化 1,旋转角度就变化 1 弧度,类似时钟的"秒针"。 时, ,角频率最低,对应最长波长——位置变化许多步后旋转角度才发生明显变化,类似时钟的"时针"。
高频分量负责精确区分近距离的 token(局部位置感知),低频分量负责编码远距离的相对关系(全局位置感知)。这种多尺度的频率设计与原始 Transformer 的正弦位置编码有异曲同工之妙。
RoPE 的核心性质。 由于旋转矩阵的正交性和结合性:
结论:应用 RoPE 后的 Q、K 内积只取决于原始向量和相对位置差
远程衰减性。 在合适的基数
3.3.3 RoPE 的 PyTorch 实现
在实际工程中,RoPE 不需要显式构建分块对角矩阵(那样既浪费内存又低效),而是利用逐元素乘法和向量重排来等效实现。核心观察是,对二维子向量
这可以分解为两项的逐元素运算:
以下是一个自包含的 PyTorch 实现:
import torch
import torch.nn as nn
import math
def precompute_rope_frequencies(
dim: int,
max_seq_len: int,
base: float = 10000.0,
) -> tuple[torch.Tensor, torch.Tensor]:
"""预计算 RoPE 所需的 cos 和 sin 缓存。
Args:
dim: 每个注意力头的维度 (head_dim),必须为偶数
max_seq_len: 支持的最大序列长度
base: 频率基数,默认 10000
Returns:
freqs_cos: 形状 (max_seq_len, dim),cos 值
freqs_sin: 形状 (max_seq_len, dim),sin 值
"""
# 计算 D/2 个角频率: theta_d = base^{-2d/D}
freq_indices = torch.arange(0, dim, 2, dtype=torch.float32)
inv_freq = 1.0 / (base ** (freq_indices / dim)) # (dim/2,)
# 位置索引
positions = torch.arange(max_seq_len, dtype=torch.float32) # (max_seq_len,)
# 外积得到角度矩阵: (max_seq_len, dim/2)
angles = torch.outer(positions, inv_freq)
# 拼接两份以匹配完整维度: (max_seq_len, dim)
freqs_cos = torch.cat([angles.cos(), angles.cos()], dim=-1)
freqs_sin = torch.cat([angles.sin(), angles.sin()], dim=-1)
return freqs_cos, freqs_sin
def rotate_half(x: torch.Tensor) -> torch.Tensor:
"""将向量前半与后半交换并取负,用于高效实现旋转。
输入: (..., dim),其中 dim 为偶数
输出: (-x[..., dim//2:], x[..., :dim//2]) 拼接
"""
half = x.shape[-1] // 2
return torch.cat((-x[..., half:], x[..., :half]), dim=-1)
def apply_rotary_pos_emb(
q: torch.Tensor,
k: torch.Tensor,
cos: torch.Tensor,
sin: torch.Tensor,
) -> tuple[torch.Tensor, torch.Tensor]:
"""对 Query 和 Key 应用旋转位置编码。
Args:
q: (batch, num_heads, seq_len, head_dim)
k: (batch, num_heads, seq_len, head_dim)
cos: (seq_len, head_dim) 或可广播形状
sin: (seq_len, head_dim) 或可广播形状
Returns:
q_rotated, k_rotated: 与输入同形状
"""
# 调整 cos/sin 形状以支持广播: (1, 1, seq_len, head_dim)
cos = cos.unsqueeze(0).unsqueeze(0)
sin = sin.unsqueeze(0).unsqueeze(0)
q_rotated = q * cos + rotate_half(q) * sin
k_rotated = k * cos + rotate_half(k) * sin
return q_rotated, k_rotated代码解读。 precompute_rope_frequencies 根据基数 rotate_half 将向量 apply_rotary_pos_emb 利用恒等式
3.3.4 上下文长度扩展方案谱系 [选读]
标准 RoPE 在训练长度
为了统一描述,我们将 RoPE 的旋转角度抽象为
内插与外推的基本概念。 面对从
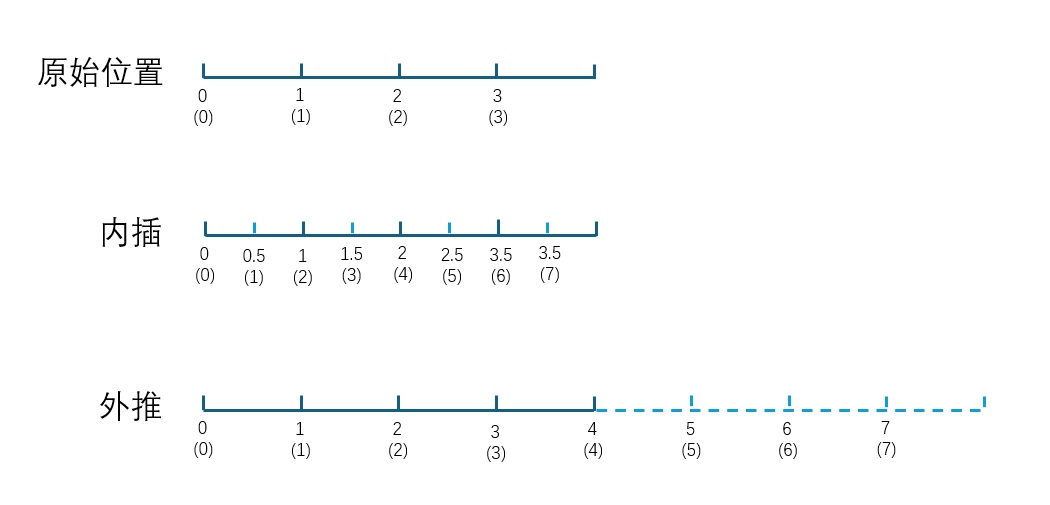
图 3-6:内插与外推的对比。原始模型支持 4 个位置。外推(Extrapolation)直接将取值范围从
- 外推:保持相邻位置间距为 1,直接使用超出训练范围的位置值。简单直接,但新位置对应的旋转角度是模型从未见过的,导致注意力分数严重失真。
- 内插:将扩展后的位置压缩回原始区间,所有编码值都落在训练分布内,但相邻位置的区分度被降低。
Position Interpolation(PI,位置内插)。 PI 是最直观的内插方案,其思想极其简单:将扩展后的位置
其中
PI 的优点是实现极简,只需对位置索引除以
NTK-aware Interpolation(NTK 感知插值)。 既然 PI 的问题在于对所有频率"一刀切"地缩放,更合理的做法是高频外推、低频内插——让高频分量保持原有频率以维持局部分辨率,对低频分量进行内插以覆盖更大的位置范围。
NTK-aware 方法用一个与分组
其中
然而 NTK-aware 存在一个隐患:某些极低频分量的波长
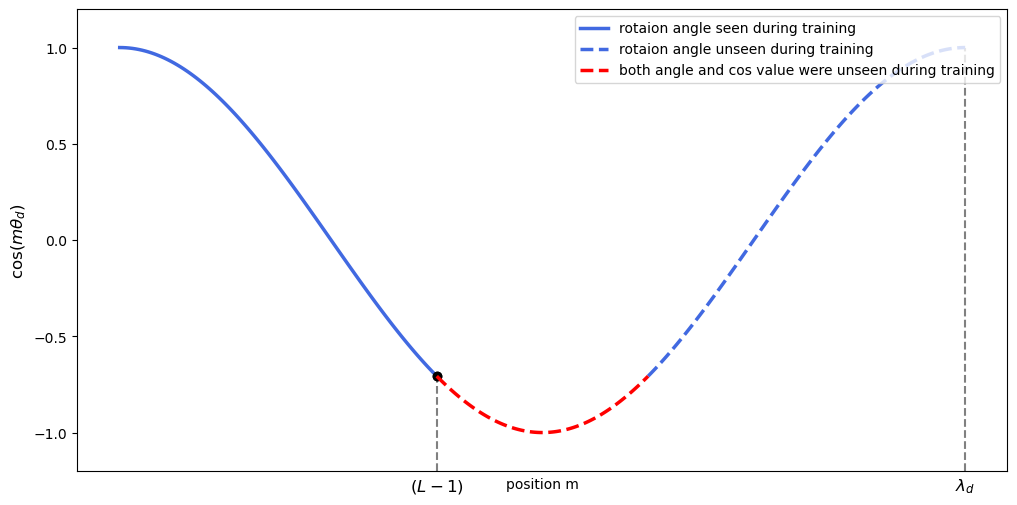
图 3-7:低频分量的外推问题。蓝色实线表示训练范围内见过的旋转角度,蓝色虚线表示外推产生的新角度(旋转值虽已在训练中出现过),红色虚线表示角度和对应的 cos/sin 值均为训练时未见过的区域。对波长超过训练长度的分量进行外推尤其危险。
NTK-by-parts Interpolation(分段 NTK 插值)。 为解决 NTK-aware 的过度外推问题,NTK-by-parts 引入了基于波长的精确分区策略:
其中
NTK-by-parts 对频率空间的三分法(高频外推、中频混合、低频内插)是后续 YARN 的直接基础。
YARN = NTK-by-parts + Attention Scaling。 YARN(Yet Another RoPE ExtensioN)在 NTK-by-parts 的基础上增加了一项关键改进:注意力分数的温度缩放。
仅修改频率会改变长序列下注意力分布的熵——扩展后每个 token 需要在更多位置间分配注意力,导致注意力变得过于分散。YARN 通过对注意力分数除以一个温度系数
温度系数的经验公式为:
在实现中,这等价于对 RoPE 后的 Q 和 K 向量统一乘以
其中
下表总结了各扩展方案的演进关系:
| 方案 | 核心思想 | 频率处理策略 | 局限性 |
|---|---|---|---|
| PI | 位置均匀内插 | 所有频率统一缩小 | 高频信息丢失 |
| NTK-aware | 按分组渐变插值 | 高频外推、低频内插(指数过渡) | 极低频过度外推 |
| NTK-by-parts | 波长分区 + 三段式 | 高频外推、中频混合、低频内插 | 注意力熵偏移 |
| YARN | 分区 + 温度修正 | 同 NTK-by-parts + attention scaling | 当前最佳实践 |
表 3-3:RoPE 上下文长度扩展方案的演进。每种方案都针对前一种的具体缺陷进行改进,形成了清晰的技术递进关系。
3.3.5 DeepSeek-R1 中 YARN 的工程实现 [选读]
DeepSeek-R1 采用 YARN 实现了 128K 上下文长度的支持。其工程实现与标准 YARN 公式存在若干细节差异,值得关注。
实现要点一:频率构造的双轨方式。 DeepSeek-R1 不直接按
其中 yarn_linear_ramp_mask 函数计算的线性过渡权重。高频分量
实现要点二:mscale 幅度缩放。 DeepSeek-R1 的 YARN 引入了两个缩放参数 mscale 和 mscale_all_dim,用于计算 Q/K 向量的幅度缩放因子。该缩放因子通过函数 yarn_get_mscale 计算:
最终缩放因子为 mscale 和 mscale_all_dim 参数。这提供了比标准 YARN 更精细的控制粒度。
实现要点三:过渡区间的参数映射。 标准 YARN 论文中 beta_slow(低频阈值,对应 beta_fast(高频阈值,对应 yarn_find_correction_range 函数,将周期数阈值转换为维度索引:
其中
以下是与 DeepSeek-R1 实现对齐的 YARN 频率计算核心代码:
import math
import torch
def deepseek_yarn_frequencies(
dim: int,
max_position: int,
base: float = 10000.0,
scale_factor: float = 40.0,
original_max_position: int = 4096,
beta_fast: float = 32.0,
beta_slow: float = 1.0,
mscale: float = 1.0,
mscale_all_dim: float = 0.0,
) -> tuple[torch.Tensor, torch.Tensor]:
"""DeepSeek-R1 风格的 YARN 频率计算。
Returns:
cos_cached, sin_cached: 形状均为 (max_position, dim)
"""
def find_correction_dim(num_rotations, dim, base, max_pos):
return (dim * math.log(max_pos / (num_rotations * 2 * math.pi))) / (
2 * math.log(base)
)
def find_correction_range(low_rot, high_rot, dim, base, max_pos):
low = math.floor(find_correction_dim(low_rot, dim, base, max_pos))
high = math.ceil(find_correction_dim(high_rot, dim, base, max_pos))
return max(low, 0), min(high, dim - 1)
def linear_ramp_mask(lo, hi, n):
if lo == hi:
hi += 1e-3
ramp = (torch.arange(n, dtype=torch.float32) - lo) / (hi - lo)
return torch.clamp(ramp, 0.0, 1.0)
def get_mscale(scale, m):
return 0.1 * m * math.log(scale) + 1.0 if scale > 1 else 1.0
# 基础频率
idx = torch.arange(0, dim, 2, dtype=torch.float32)
freq_extra = 1.0 / (base ** (idx / dim)) # 外推频率
freq_inter = 1.0 / (scale_factor * base ** (idx / dim)) # 内插频率
# 过渡区间:从 beta_fast 到 beta_slow
low, high = find_correction_range(
beta_fast, beta_slow, dim, base, original_max_position
)
mask = 1.0 - linear_ramp_mask(low, high, dim // 2)
# 混合频率:低频用内插,高频用外推,中间线性过渡
inv_freq = freq_inter * (1.0 - mask) + freq_extra * mask
# 计算角度矩阵
positions = torch.arange(max_position, dtype=torch.float32)
angles = torch.outer(positions, inv_freq) # (max_position, dim/2)
emb = torch.cat([angles, angles], dim=-1) # (max_position, dim)
# 幅度缩放
scale_value = get_mscale(scale_factor, mscale) / get_mscale(
scale_factor, mscale_all_dim
)
cos_cached = emb.cos() * scale_value
sin_cached = emb.sin() * scale_value
return cos_cached, sin_cached代码解读。 该实现的关键在于频率混合逻辑:首先计算外推频率(不除以 find_correction_range 将周期数阈值 beta_fast / beta_slow 转换为维度索引 low / high,确定过渡区间的起止位置。最后乘以 scale_value 完成 attention scaling。
本节小结
本节系统介绍了旋转位置编码(RoPE)及其扩展方案:
- 复数与旋转的等价性 提供了 RoPE 的数学基础:复数乘以单位复数
等价于二维旋转,旋转后向量的点积只依赖于角度差。 - RoPE 的核心设计 是将高维向量拆为
组二维子向量,每组以不同频率的旋转矩阵编码位置。应用 RoPE 后的 Q、K 内积自动包含相对位置信息,无需额外参数,计算开销极低。 - 高低频分量的物理意义:高频分量(
较小)负责局部位置辨识,低频分量( 较大)负责全局距离感知,二者协同构成多尺度的位置表征。 - 上下文扩展方案 沿"PI
NTK-aware NTK-by-parts YARN"的路径逐步改进,核心思想从"一刀切内插"演变为"按频率分区、高频外推低频内插",并最终通过 attention scaling 修正注意力分布的熵偏移。 - YARN 作为当前最成熟的方案,已在 DeepSeek-R1 等模型中得到大规模工程验证,仅需少量长文本数据微调即可实现上下文长度的数倍扩展。